Pengantar Feature Engineering
- Get link
- X
- Other Apps
Pengantar Feature Engineering
Hi, machine learning enthusiast!
Setelah melewati berbagai macam perjalanan mulai dari dasar machine learning, machine learning workflow, berbagai macam metode supervised learning hingga clustering tentunya Anda sudah lebih percaya diri ‘kan?
“Tetaplah merasa bodoh, agar kita belajar. Tetaplah merasa lapar, agar kita berusaha.” — Steve Jobs, Former CEO Apple.
Walaupun sudah merasa lebih percaya diri, tetapi bukan berarti Anda dapat berhenti belajar. Untuk melanjutkan perjalanan seumur hidup (belajar), mari kita mulai kembali menata ilmu machine learning di kelas ini.
Pada modul ini, Anda akan mempelajari teknik feature engineering, sebuah langkah krusial dalam machine learning dan data science yang berperan penting dalam meningkatkan performa model.
Bayangkan ini seperti memasak—data adalah bahan-bahannya, dan feature engineering adalah proses mengolah bahan tersebut agar menjadi hidangan yang lezat dan mantap. Dari ekstraksi fitur hingga transformasi data, kita akan membahasnya dengan tuntas agar Anda semakin mahir dalam mempersiapkan data yang optimal untuk model Anda.
Jadi, siapkan semangat dan camilan favorit Anda, mari kita mulai petualangan baru ini. Ingatlah, sambil belajar, jangan lupa menikmati prosesnya—belajar dengan gembira, karena ilmu akan lebih mudah diserap jika hati riang.
Semangat terus dan nikmati perjalanan ini!
[Story] Andai Aku Bisa
Diana dan Bilqis telah melalui perjalanan panjang dalam belajar machine learning. Mereka sudah memahami berbagai metode seperti supervised learning yang membutuhkan data berlabel untuk melatih model, serta unsupervised learning, yaitu model harus mencari pola dari data yang tidak memiliki label. Namun, mereka merasa ada satu hal yang kurang dalam meningkatkan akurasi model yang sedang dikembangkan. Apakah itu?
Suatu hari, Diana dan Bilqis sedang berdiskusi di ruang perpustakaan kampus tentang berbagai macam proyek yang telah mereka kerjakan. Hampir semua model machine learning mereka cukup memuaskan, tetapi mereka yakin ada cara untuk lebih mengoptimalkan performa model.
Pemikiran ini muncul ketika mereka sedang mengulas salah satu model machine learning yang memiliki performa kurang baik ketika dijalankan kembali.

Diana dan Bilqis akhirnya mengulas secara detail kode yang mereka bangun, mereka membutuhkan waktu yang cukup lama untuk menemukan kekurangan dari model machine learning tersebut. Langkah demi langkah mereka lakukan, mulai dari menjalankan dan melatih ulang model, mengganti dataset, hingga mengganti proporsi pembagian dataset. Namun, percobaan yang mereka lakukan belum menemukan hasil yang memuaskan.

Waktu berlalu begitu cepat ketika mereka berusaha memperbaiki model yang bermasalah, akhirnya mereka membandingkan model yang bermasalah dengan model lainnya. Diana bertugas untuk membandingkan model tersebut dengan masalah klasifikasi, sedangkan Bilqis bertugas untuk membandingkan model dengan masalah regresi.
Pilihan untuk membandingkan model machine learning menjadi titik balik untuk mengatasi permasalahan yang mereka alami. Akhirnya mereka menyadari terdapat sebuah perbedaan dari model yang memiliki permasalahan tersebut.

Berangkat dari temuan Diana, akhirnya Bilqis menyadari suatu hal bahwa tidak semua dataset yang mereka gunakan sudah siap untuk digunakan. Mereka mengingat kembali materi yang sudah diajarkan oleh salah satu dosen mengenai teknik feature engineering.

Sambil mengangguk setuju, Bilqis berkata, “Aku juga berpikir begitu. Menurutku, kita perlu lebih memahami bagaimana memanipulasi fitur yang kita miliki supaya lebih relevan untuk model. Misalnya, kita bisa mencoba scaling atau normalization untuk fitur numerik, atau mungkin melakukan one-hot encoding untuk fitur kategori.”
Mereka kemudian mulai mempelajari lebih dalam tentang feature engineering, memulai dari dasar. Mereka mempelajari teknik seperti feature selection—bagaimana memilih data yang memiliki peran penting dari berbagai macam fitur. Mereka juga mempelajari feature transformation, di mana mereka bisa mengubah fitur kategorikal menjadi numerik sehingga dapat dipelajari oleh model machine learning.
Seiring berjalannya waktu, mereka mulai mempraktikkan apa yang telah mereka temukan. Diana dan Bilqis mencoba berbagai metode scaling, encoding, bahkan membuat fitur baru berdasarkan intuisi mereka terhadap data.
Hasilnya model mereka menunjukkan peningkatan signifikan. Akurasi prediksi volume banjir meningkat, dan error rate berkurang drastis.

Bilqis tersenyum, puas dengan hasil kerja mereka. “Iya, ternyata ini kunci yang kita butuhkan. Sekarang model kita tidak hanya bekerja dengan data mentah, tapi data yang sudah dioptimalkan untuk hasil yang lebih baik.”
Dengan keberhasilan ini, Diana dan Bilqis semakin semangat untuk melanjutkan proyek mereka. Mereka menyadari bahwa mempelajari machine learning bukan hanya soal memahami model dan algoritma, tapi juga bagaimana mereka bisa menggunakan data dengan bijak melalui teknik feature engineering yang tepat.

Diana dan Bilqis sudah melangkah sangat jauh, tentunya Anda juga tidak ingin ketinggalan dengan perkembangan mereka ‘kan? Oleh karena itu, Anda juga harus bergegas karena tidak ada waktu untuk berleha-leha ketika semua orang sedang berusaha di dunia ini. So, silakan nikmati perjalanan Anda di modul Feature Engineering ini, ya. Setiap langkah yang Anda pijak merupakan bentuk perubahan agar menjadi pribadi yang lebih baik.
Pendahuluan Feature Engineering
Hi AI enthusiast!
Pada materi ini, kita akan mendalami lebih jauh mengenai proses feature engineering. Feature engineering atau rekayasa fitur adalah langkah penting dalam pengembangan model machine learning yang sukses. Andrew Ng, seorang profesor terkemuka dalam bidang kecerdasan buatan dari Stanford University dan pendiri Google Brain menekankan bahwa "Menciptakan fitur-fitur yang baik adalah pekerjaan yang sulit, memakan waktu, dan membutuhkan pengetahuan mendalam dari seorang pakar di bidang tersebut. Dalam banyak kasus, machine learning terapan pada intinya adalah proses rekayasa fitur."
Dari pernyataan tersebut dapat disimpulkan bahwa rekayasa fitur tidak hanya memakan waktu, tetapi juga membutuhkan keterampilan khusus dan pemahaman yang mendalam tentang data serta domain masalah yang sedang dihadapi. Proses ini melibatkan ekstraksi informasi penting dari data mentah, sehingga model machine learning dapat memahami pola-pola yang relevan dan memberikan hasil yang akurat. Oleh karena itu, rekayasa fitur merupakan salah satu aspek yang paling menentukan dalam kualitas model machine learning.
Dalam materi ini, Anda akan diperkenalkan dengan berbagai teknik rekayasa fitur tambahan yang akan melengkapi apa yang telah dibahas di modul sebelumnya. Tujuannya adalah untuk memperluas pengetahuan Anda tentang bagaimana cara memaksimalkan potensi data melalui rekayasa fitur yang efektif.
Sebelum menyelam lebih dalam, mari kita mulai dengan satu pertanyaan yang mungkin tebersit di benak Anda, “Apa sih feature engineering itu?”
Sederhananya, feature engineering adalah proses yang sangat penting dalam machine learning, yaitu ketika data mentah atau kotor diubah menjadi fitur-fitur yang dapat digunakan oleh model untuk melakukan prediksi. Proses ini melibatkan pemilihan, transformasi, dan penciptaan fitur-fitur yang relevan serta bermakna dari data yang tersedia. Tujuan utamanya adalah untuk memaksimalkan performa model dengan menyediakan input yang paling representatif dan informatif.

Harapannya dengan mempelajari teknik feature engineering, Anda dapat membuat sebuah model machine learning yang lebih komprehensif dan andal. Jika Anda ingat, proses feature engineering ini masih tergolong tahapan awal pada proses pembangunan model machine learning. Perhatikan kembali gambar machine learning workflow berikut.
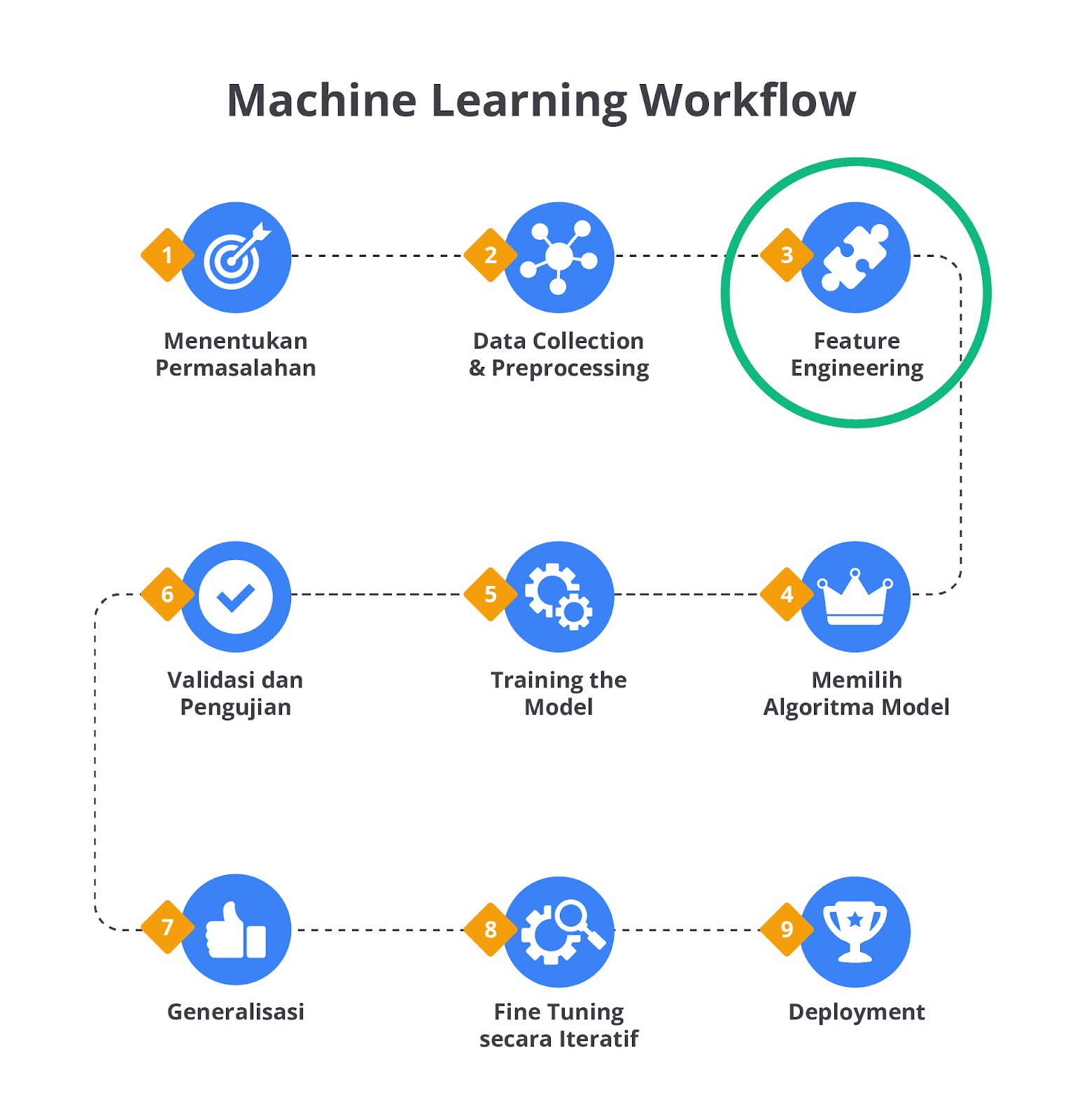
Seperti yang sudah kita pelajari pada modul Machine Learning Workflow, tahapan feature engineering memiliki irisan dengan tahapan EDA dan pre-processing. Pada modul-modul sebelumnya, proses feature engineering ini tidak disebutkan secara eksplisit agar Anda lebih fokus terhadap pemecahan masalah dan pembuatan model machine learning. Namun, bukan berarti tahapan ini tidak ada, ya. Silakan ulas kembali modul-modul sebelumnya jika Anda penasaran terkait proses yang sudah dilalui.
Lalu, mengapa feature engineering ini menjadi satu modul tersendiri? Sekali lagi, feature engineering merupakan jantung dari pengembangan model machine learning yang andal dan optimal. Hal ini dikarenakan proses feature engineering melibatkan berbagai teknik untuk mengubah data mentah menjadi fitur-fitur yang dapat dimanfaatkan oleh model.
Dengan pendekatan yang tepat, feature engineering dapat meningkatkan performa model dan memungkinkan prediksi yang lebih akurat. Masih ingatkah Anda dengan realita bahwa data di industri tidak seindah di Kaggle (open source dataset)?

Dengan melakukan feature engineering Anda dapat menciptakan, mengubah, dan memilih fitur yang relevan sehingga dapat membantu model memahami pola dalam data dengan lebih baik, meningkatkan akurasi prediksi, dan memastikan bahwa model dapat digeneralisasikan dengan baik pada data baru. Meskipun banyak model modern memiliki kemampuan untuk mengekstraksi fitur secara otomatis, feature engineering tetap memberikan dampak yang signifikan terutama ketika pengetahuan domain dapat diterapkan dengan baik.
Dengan memproses dan mentransformasi data, Anda dapat mengurangi noise yang berpotensi mengaburkan pola penting dan meningkatkan hubungan (korelasi) yang benar-benar berharga antara setiap variabel. Proses ini juga membantu menyesuaikan data dengan algoritma yang akan digunakan sehingga model dapat bekerja lebih optimal dengan data yang telah diolah.
Mengurangi risiko overfitting juga merupakan salah satu manfaat utama dari feature engineering. Dengan melakukan pemilihan fitur yang tepat dan eliminasi fitur yang tidak relevan, dapat mencegah model menjadi terlalu kompleks. Hal ini dapat membantu dalam mengoptimalkan kinerja model agar lebih efisien sehingga memungkinkan model mencapai performa yang sangat baik dengan fitur-fitur yang tepat tanpa memerlukan komputasi yang besar (efisiensi).
Nah, sampai di sini sudah paham kan mengapa feature engineering ini penting? So, jangan memandang sebelah mata untuk tahapan ini, ya.
“In theory, theory and practice are the same. In practice, they are not.” — Albert Einstein.
Kutipan di atas menyiratkan bahwa meskipun dalam teori, segala sesuatu tampak berjalan dengan sempurna dan sesuai rencana. Kenyataannya, saat teori tersebut diterapkan dalam situasi praktis, sering kali muncul kesulitan, ketidaksesuaian, atau hal-hal tak terduga yang tidak diprediksi oleh teori.
Untuk menghindari permasalahan tersebut, mari kita melangkah menuju tahapan praktik agar Anda lebih terbiasa menangani permasalahan yang ada. Pada materi berikutnya, Anda akan memulai perjalanan panjang terkait feature engineering yang dimulai dari tahapan feature selection. Sudah tidak sabar ‘kan? Yuk, langsung berangkat. Semangat!
Teknik Pemilihan Fitur (Feature Selection)
Teknik Pemilihan Fitur (Feature Selection) adalah proses pemilihan subset fitur yang paling relevan atau penting untuk digunakan dalam model machine learning. Tujuannya adalah untuk meningkatkan performa model dengan menghilangkan fitur yang tidak relevan, redundan, atau kotor (biasa disebut noise). Dengan demikian, kita bisa mengurangi kompleksitas model, meningkatkan akurasi, dan mempercepat proses pelatihan.
Pemilihan fitur sangat penting karena model machine learning yang dilatih dengan fitur yang tidak relevan atau terlalu banyak fitur, memungkinkan untuk mengalami masalah seperti overfitting yaitu kondisi ketika model terlalu cocok dengan data pelatihan sehingga tidak dapat melakukan generalisasi dengan baik untuk data baru. Dengan melakukan feature selection, kita dapat menghasilkan model yang lebih simpel, cepat, dan efektif.
“Ini kan sama-sama mengurangi fitur sebelum melatih model, lalu apa bedanya dengan feature extraction?”. Pertanyaan yang bagus, mari kita bahas!

Feature selection dan feature extraction adalah dua teknik yang sering digunakan untuk mengurangi jumlah variabel dalam analisis data, tetapi dengan pendekatan yang berbeda. Pada feature extraction, pengurangan jumlah variabel dilakukan dengan menciptakan fitur baru melalui kombinasi fitur-fitur yang sudah ada.
Teknik ini menghasilkan representasi baru dari data, yang bertujuan untuk menangkap informasi penting dengan cara yang lebih ringkas. Sebagai contoh, metode seperti Principal Component Analysis (PCA) mengubah data asli menjadi beberapa komponen utama yang mewakili variasi terbesar.
Di sisi lain, feature selection mengurangi jumlah variabel dengan memilih fitur-fitur yang paling relevan dari dataset tanpa memodifikasinya. Metode ini tidak menciptakan fitur baru, melainkan menyaring fitur-fitur yang ada untuk mempertahankan yang paling relevan. Sampai di sini pastinya Anda sudah paham perbedaan feature extraction dan feature selection, ‘kan?
Nah, feature selection ini juga terbagi menjadi dua subset utama yaitu unsupervised feature selection dan supervised feature selection. Namun, Perlu Anda catat bahwa metode ini berbeda dengan unsupervised learning ataupun supervised learning yang ada sudah Anda pelajari pada modul-modul sebelumnya.
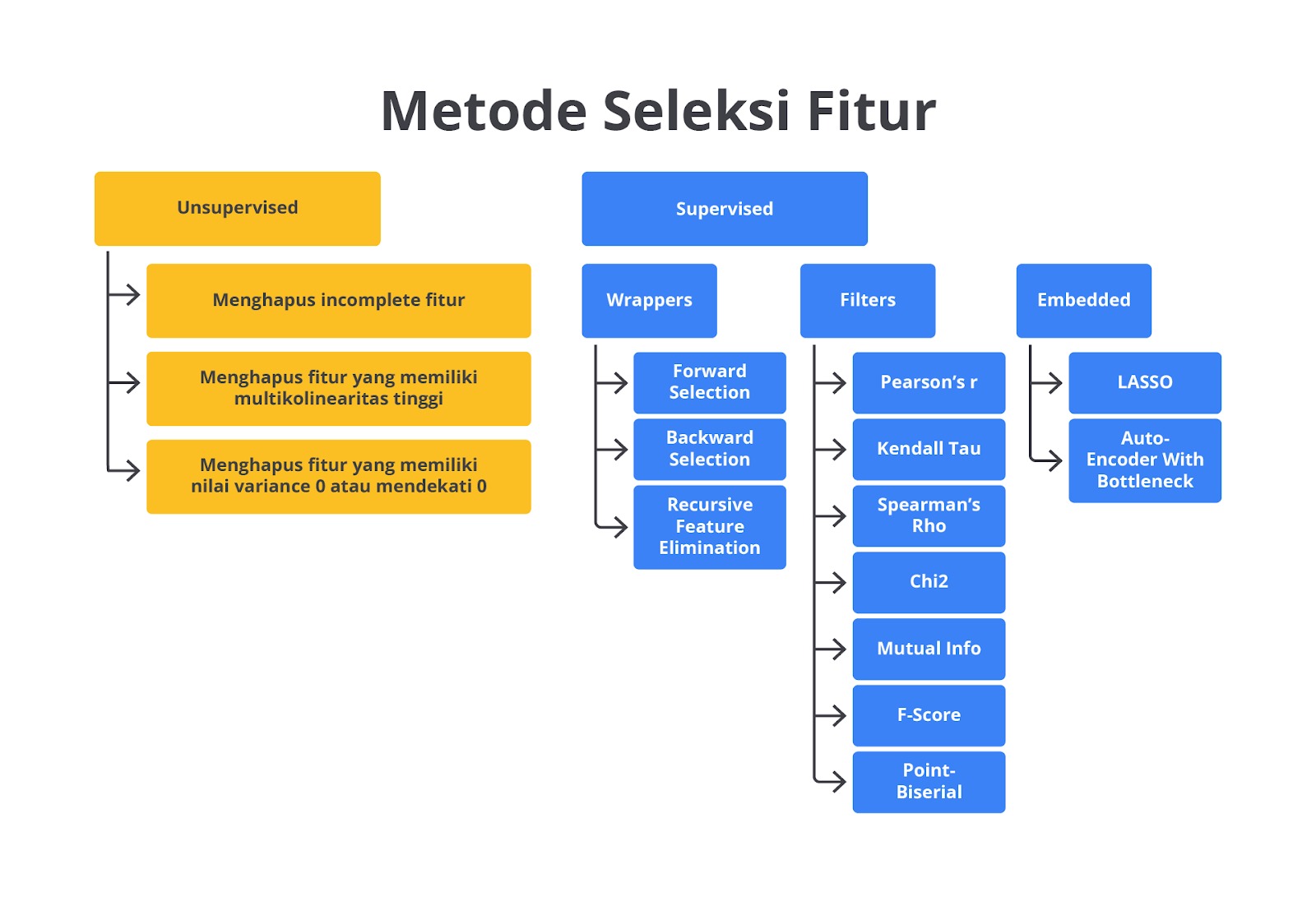
Unsupervised feature selection adalah proses memilih fitur dari dataset tanpa menggunakan label atau informasi target (output). Metode ini berbeda dengan supervised feature selection karena fiturnya dipilih berdasarkan hubungannya dengan variabel target yang sudah diketahui.
Tujuan utama dari unsupervised feature selection adalah mengurangi dimensionalitas data dengan mengidentifikasi fitur-fitur yang paling relevan atau signifikan untuk meningkatkan efisiensi algoritma machine learning dan mempermudah visualisasi data tanpa menghiraukan label target.
Beberapa pendekatan umum yang digunakan dalam unsupervised feature selection meliputi teknik-teknik berikut.
- Drop Incomplete Features: fitur yang "incomplete" atau tidak lengkap mengacu pada kolom dalam dataset yang memiliki banyak missing values (nilai yang hilang). Fitur-fitur ini sering kali dianggap tidak informatif atau bahkan dapat merusak performa model machine learning jika tidak ditangani dengan benar. Meskipun menghapus fitur yang tidak lengkap bukanlah cara yang baik untuk menangani data yang hilang, hal ini acapkali menjadi pilihan tercepat. Selain itu, jika terlalu banyak data yang hilang, teknik ini masuk akal untuk dilakukan karena fitur-fitur seperti itu kemungkinan besar tidak penting.
- Drop Features with High Multicollinearity: multicollinearity adalah kondisi ketika dua atau lebih fitur dalam dataset sangat berkorelasi satu sama lain. Hal ini bisa menyebabkan masalah dalam model regresi atau model lain yang sensitif terhadap hubungan linear antara fitur seperti regresi linear atau logistik. Ketika fitur-fitur ini terlalu berkorelasi, mereka memberikan informasi yang redundan (berlebihan) sehingga dapat menyebabkan model menjadi tidak stabil atau sulit untuk diinterpretasikan.
- Drop Features with (Near-)Zero Variance: fitur dengan variansi yang sangat rendah atau mendekati nol merupakan fitur yang nilai-nilainya hampir tidak berubah di seluruh dataset. Dengan kata lain, fitur ini tidak memiliki banyak variasi dan tidak memberikan banyak informasi yang berguna untuk model.
- Variance Thresholding: fitur-fitur dengan variansi yang sangat rendah dapat diabaikan karena tidak memberikan banyak informasi baru.
- Principal Component Analysis (PCA): meskipun PCA secara teknis bukan metode seleksi fitur, ini sering digunakan untuk mengurangi dimensionalitas dengan mentransformasi fitur ke dalam komponen utama yang lebih sedikit. Namun, tetap merepresentasikan variasi terbesar dalam data.
- Clustering-based Methods: fitur-fitur yang secara bersama-sama membentuk kelompok (klaster) dalam data dapat dipilih sebagai fitur representatif berdasarkan clustering seperti k-means.
- Correlation-based Selection: fitur-fitur yang sangat berkorelasi satu sama lain dapat direduksi menjadi satu fitur untuk mengurangi redundansi.
Dengan pendekatan unsupervised feature selection, kita bisa mengidentifikasi fitur yang memberikan informasi penting dalam data tanpa perlu mengetahui hasil akhir atau label klasifikasi.
Lalu, apa kabar dengan supervised feature selection? Seperti yang sudah dijelaskan di atas,
Supervised feature selection adalah proses memilih fitur yang paling relevan dari dataset dengan memanfaatkan informasi dari label atau target variabel. Hal ini berarti pemilihan fitur dilakukan dengan memperhatikan hubungan antara setiap fitur dan variabel target.
Tujuannya adalah untuk meningkatkan performa model machine learning dengan menghilangkan fitur yang tidak relevan, redundan, atau bahkan merugikan karena tidak memiliki hubungan sama sekali dengan fitur target.
Secara umum supervised feature selection terbagi menjadi tiga teknik, yaitu filter, wrapper, dan embedded.
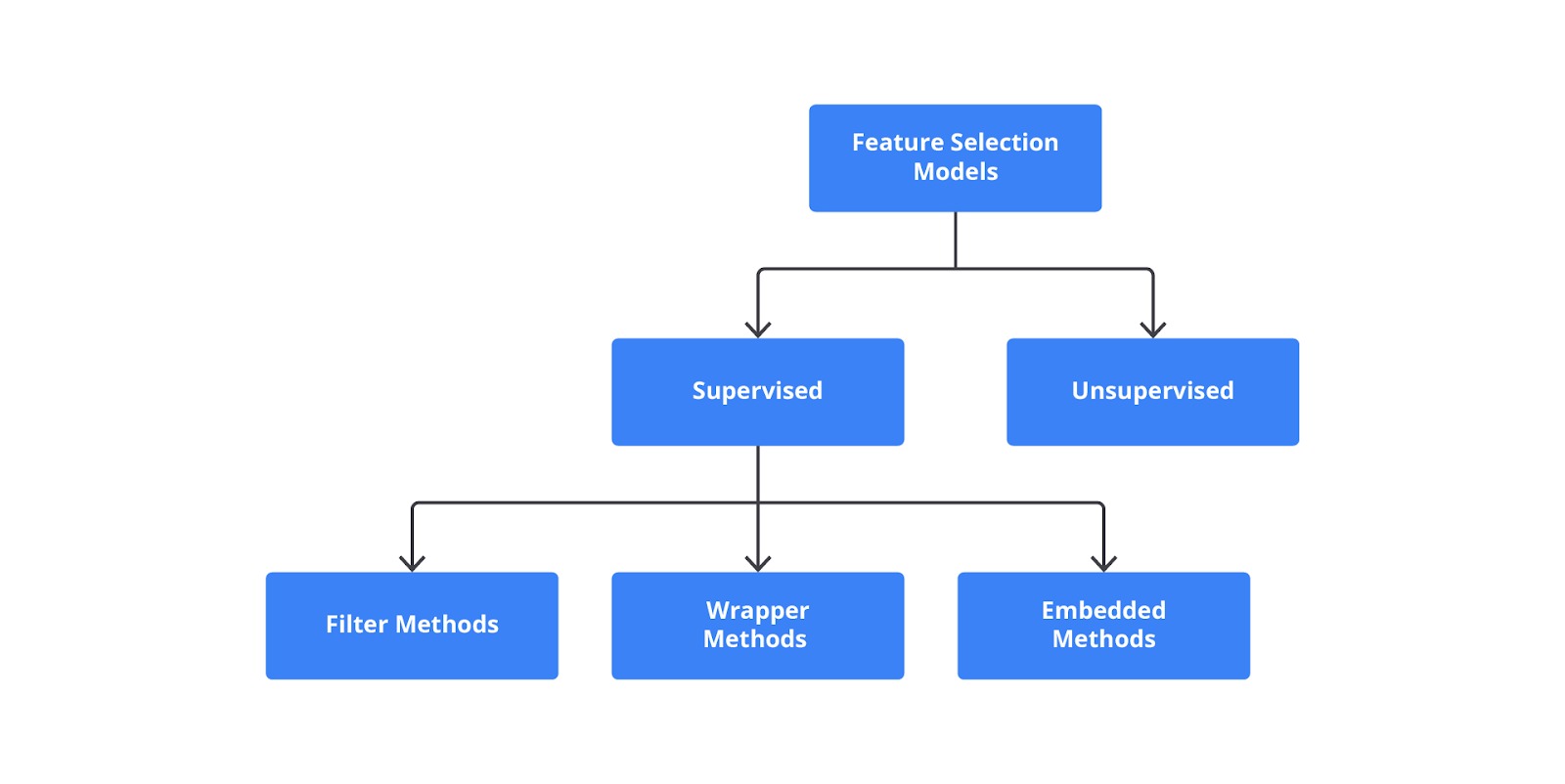
Metode di atas akan membantu mengidentifikasi fitur yang paling relevan untuk model sehingga dapat meningkatkan kinerja, mengurangi kompleksitas, dan mempercepat waktu pelatihan.
Sambil menyelam minum air, sembari mempelajari maksud dari masing-masing metode tersebut, alangkah baiknya Anda juga memahami implementasinya. Namun, sebelum berangkat, mari kita persiapkan amunisinya terlebih dahulu dengan mengimpor library yang akan digunakan.
- import numpy as np
- import pandas as pd
- from sklearn.datasets import load_iris
- from sklearn.feature_selection import SelectKBest, chi2
- from sklearn.feature_selection import RFE
- from sklearn.linear_model import LogisticRegression
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.model_selection import train_test_split
- from sklearn.preprocessing import StandardScaler
- from sklearn.datasets import load_wine
Selanjutnya, Anda perlu memilih dataset yang akan digunakan. Pada kasus ini, kita akan menggunakan dataset load_wine() dari Scikit.
- # Memuat dataset Wine Quality
- data = load_wine()
- X, y = data.data, data.target
Untuk memudahkan interpretasi mari kita ubah dataset tersebut menjadi sebuah DataFrame.
- # Mengubah menjadi DataFrame untuk analisis yang lebih mudah
- df = pd.DataFrame(X, columns=data.feature_names)
- df['target'] = y
- df
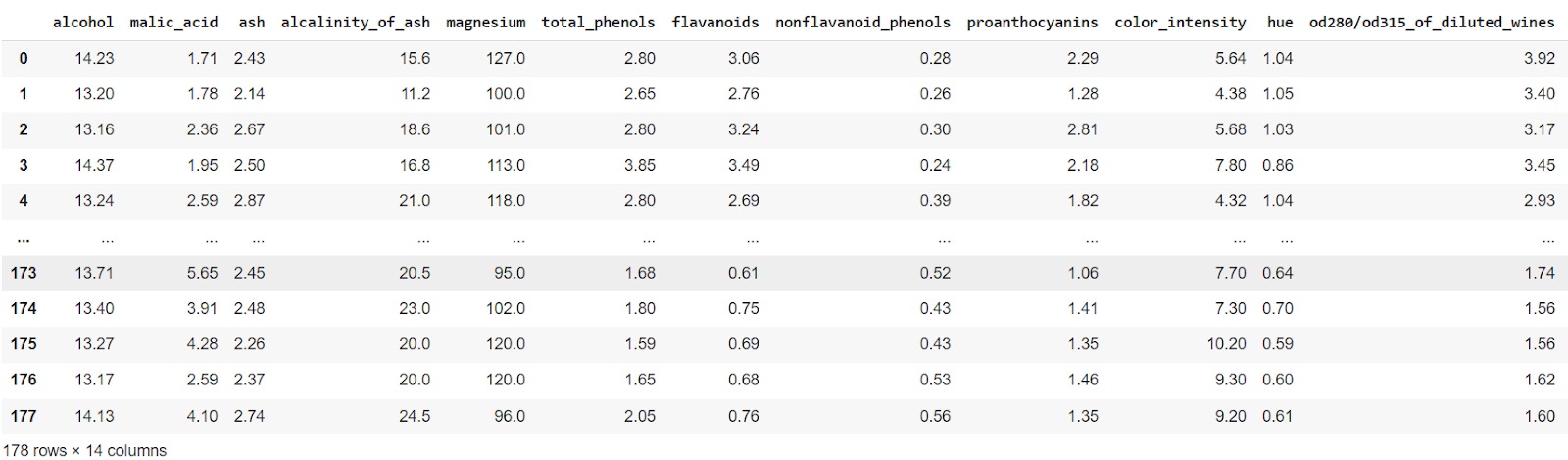
Dataset ini memiliki 178 baris dan 13 kolom fitur independen serta satu kolom dependen (target). Masih ingatkah tahapan terakhir persiapan data sebelum melatih model? Yup! Anda perlu membagi dataset menjadi data latih dan data uji. Pada kasus ini, kita akan membagi ukuran dataset menjadi 80% data uji dan 20% data latih. Silakan eksplorasi mandiri untuk proporsi lainnya ya.
- # Pembagian data
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Backpack sudah penuh dan persiapan sudah lengkap. Sekarang, mari kita bahas satu per satu metode feature selection agar lebih jelas.
Filter Methods
Filter methods adalah teknik untuk menilai relevansi fitur secara independen dari model yang akan digunakan. Metode ini menggunakan statistik untuk memilih fitur tanpa melibatkan algoritma machine learning. Hal ini membuat proses pemilihan fitur dengan lebih cepat dan efisien, terutama untuk dataset besar.
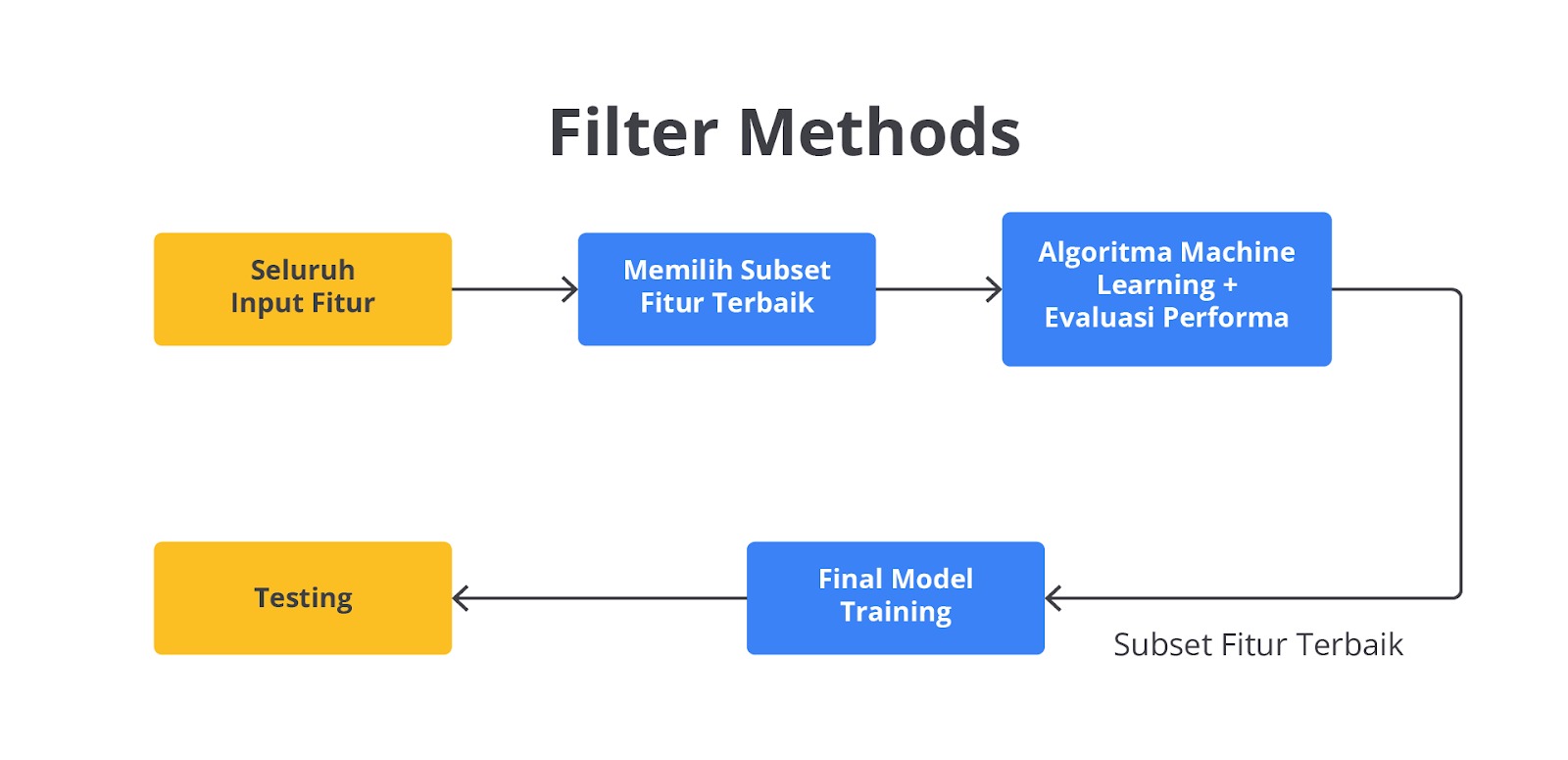
Metode ini akan menilai relevansi fitur secara independen dari model yang akan digunakan kelak. Pada dasarnya filter methods menggunakan statistik untuk memilih fitur tanpa melibatkan algoritma machine learning sehingga membuatnya lebih cepat dan efisien dalam memproses dataset khususnya untuk dataset dengan ukuran yang besar. Contohnya termasuk penggunaan korelasi untuk menghitung hubungan antara setiap fitur dan label target, serta chi-square untuk menguji independensi antara fitur dan label.
Selain itu, teknik mutual information dapat digunakan untuk mengukur ketergantungan antara fitur dan label. Eitss, tidak sampai di situ, metode ini juga dapat menghitung variance threshold dengan memilih fitur yang memiliki varians lebih tinggi dari ambang tertentu lalu mengeliminasi fitur dengan informasi rendah.
Metode ini memiliki beberapa kekurangan dan kelebihan seperti berikut.
- Kekurangan
- Karena beroperasi secara independen, filter methods mungkin melewatkan interaksi data yang mungkin penting untuk prediksi.
- Anda perlu melakukan perhitungan metriks yang tepat dan sesuai dengan algoritma yang akan digunakan. Hal ini karena memilih metrik yang sesuai untuk data dan tugas Anda sangat penting untuk kinerja yang optimal.
- Kelebihan
- Metode filter tidak membutuhkan daya komputasi yang besar sehingga ideal untuk set data yang besar dengan kondisi keterbatasan hardware.
- Metode-metode ini sering kali sudah ada di dalam library machine learning yang populer sehingga akan mempermudah pekerjaan Anda sebagai machine learning engineer.
- Metode filter dapat digunakan dengan semua jenis model machine learning sehingga Anda tidak perlu takut salah. Namun, hal ini bukan berarti Anda dapat melakukan konsep All in One Methods, ya.
Setelah mengetahui konsep dasarnya, mari kita coba implementasikan filter methods pada dataset yang telah disiapkan sebelumnya menggunakan kode berikut.
- # ------------------- Filter Methods -------------------
- # Menggunakan SelectKBest
- filter_selector = SelectKBest(score_func=chi2, k=2) # Memilih 2 fitur terbaik
- X_train_filter = filter_selector.fit_transform(X_train, y_train)
- X_test_filter = filter_selector.transform(X_test)
- print("Fitur yang dipilih dengan Filter Methods:", filter_selector.get_support(indices=True))
Kode di atas akan mencari fitur terbaik berdasarkan nilai yang sudah ditentukan, agar lebih jelas mari kita bahas lebih detail.
- SelectKBest
SelectKBest adalah salah satu metode dari filter methods yang umum digunakan untuk memilih fitur terbaik berdasarkan skor statistik tertentu.- Parameter score_func=chi2 berarti metode ini menggunakan Chi-squared (χ²) sebagai fungsi skor. Chi-squared adalah metode uji statistik yang digunakan untuk mengukur independensi antara dua variabel kategorikal.
- Parameter k=2 artinya kita hanya akan memilih 2 fitur terbaik dari semua fitur yang ada di dataset. Dengan kata lain, ini akan menyeleksi dua fitur dengan skor tertinggi berdasarkan hasil uji Chi-squared.
Kedua parameter ini bisa Anda sesuaikan dengan studi kasus dan trial and error ya.
- fit_transform(X_train, y_train)
- fit(X_train, y_train) merupakan metode yang akan menghitung skor Chi-squared untuk setiap fitur pada data pelatihan (X_train) terhadap target (y_train).
- transform(X_train) merupakan fungsi yang bertugas untuk menyalin data dari X_train, tetapi pada kasus ini hanya memiliki fitur yang tersimpan pada filter_selector.
Hasilnya adalah sebuah dataset pelatihan baru (X_train_filter) yang hanya mengandung dua fitur terbaik hasil perhitungan Chi-squared.
- transform(X_test)
Fungsi transform(X_test) digunakan untuk mentransformasikan dataset uji (X_test) dengan memilih fitur yang sama yang dipilih dari dataset pelatihan. - get_support(indices=True)
- Fungsi get_support(indices=True) digunakan untuk mendapatkan indeks dari fitur-fitur yang dipilih. Dalam hal ini, fitur yang dipilih adalah dua fitur dengan skor tertinggi berdasarkan uji Chi-squared.
Fungsi ini akan mencetak indeks fitur yang dipilih dari dataset awal yang bisa digunakan untuk memahami fitur mana yang dipertahankan setelah proses seleksi. Sehingga, output akhir dari kode ini merupakan dataset yang sudah difilter dan informasi angka indeks dari fitur yang dipilih.

Sampai di sini, Anda sudah memiliki sebuah dataset yang terdiri dari dua buah fitur dengan skor independensi paling besar. Tahan sejenak rasa ingin tahu Anda, karena pada akhir materi ini kita akan membandingkan performa dari ketiga metode feature selection.
Wrapper Methods
Wrapper methods bertugas untuk mengevaluasi subset fitur berdasarkan kinerja model machine learning. Metode ini lebih berat secara komputasional tetapi sering kali memberikan hasil yang lebih baik karena mempertimbangkan interaksi antara fitur.
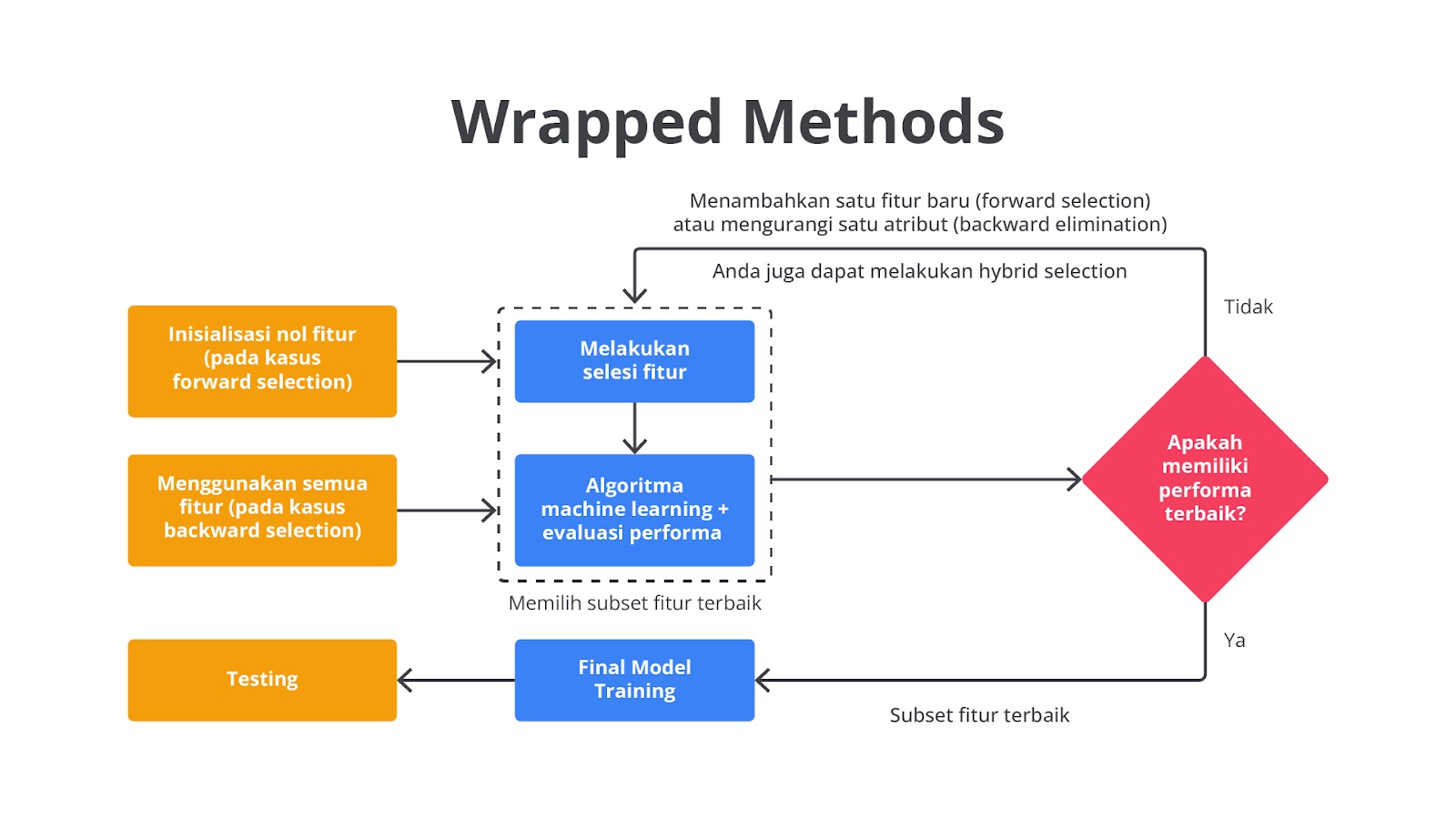
Seperti yang dapat Anda lihat pada gambar di atas, metode ini akan mengevaluasi subset fitur berdasarkan kinerja model machine learning yang dipilih. Metode ini secara iteratif akan menambah atau menghapus fitur dengan tujuan untuk menemukan kombinasi yang menghasilkan kinerja model terbaik. Dalam penggunaannya Anda dapat menggunakan beberapa teknik untuk memaksimalkan proses feature selection.
Salah satu teknik yang umum digunakan pada metode ini adalah Recursive Feature Elimination (RFE) di mana proses iteratif akan menghapus fitur yang kurang penting dengan membangun model secara berulang. Metode lain yaitu forward selection dan backward elimination yang berfokus pada penambahan atau penghapusan fitur berdasarkan performa model dengan melakukan evaluasi menggunakan teknik cross-validation. Last but not least, untuk dataset kecil, exhaustive feature selection dapat dilakukan meskipun metode ini berat secara komputasional karena mencakup semua kombinasi fitur.
Metode ini memiliki beberapa kekurangan dan kelebihan seperti berikut.
- Kekurangan
- Mengevaluasi kombinasi fitur yang berbeda dapat memakan waktu dan sumber daya yang besar terutama untuk data dengan ukuran besar.
- Menyesuaikan fitur pada model tertentu dapat menyebabkan model overfitting yaitu model yang memiliki kinerja buruk pada data yang yang belum pernah dilihat.
- Kelebihan
- Wrapper methods secara langsung mempertimbangkan bagaimana fitur memengaruhi model sehingga berpotensi menghasilkan performa yang lebih baik dibandingkan dengan metode filter.
- Metode-metode ini dapat diadaptasi ke berbagai jenis model dan metriks evaluasi.
Setelah memahami konsep wrapper mari kita coba implementasikan method ini pada dataset yang telah disiapkan sebelumnya menggunakan kode berikut.
- # Menggunakan RFE (Recursive Feature Elimination)
- model = LogisticRegression(solver='lbfgs', max_iter=5000)
- rfe_selector = RFE(model, n_features_to_select=2) # Memilih 2 fitur
- X_train_rfe = rfe_selector.fit_transform(X_train, y_train)
- X_test_rfe = rfe_selector.transform(X_test)
- print("Fitur yang dipilih dengan Wrapper Methods:", rfe_selector.get_support(indices=True))
Mirip dengan filter methods pada materi sebelumnya, kode di atas akan mencari dua buah fitur yang paling relevan berdasarkan perhitungan Recursive Feature Elimination. Namun, metode ini menghasilkan indeks fitur yang berbeda jika kita bandingkan dengan filter methods.
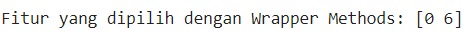
Mengapa hal ini bisa terjadi? Tenang saja ini merupakan hal yang wajar, perbedaan ini disebabkan kedua metode ini menggunakan perhitungan matematis yang berbeda. Chi2 akan mengukur hubungan antara fitur dan target secara independen tanpa menggunakan model pembelajaran mesin dan tidak mempertimbangkan interaksi antar fitur. Lalu, RFE akan menghitung menggunakan model machine learning dan secara iteratif memilih fitur terbaik.
Embedded Methods
Terakhir Embedded methods menggabungkan pemilihan fitur dengan pelatihan model. Metode mengambil pendekatan “why not both?” sehingga memasukkan pemilihan fitur secara langsung ke dalam proses pelatihan model. Hal ini memungkinkan model untuk mempelajari hubungan antara fitur dan variabel target bersamaan dengan memilih fitur mana yang paling relevan dengan target.
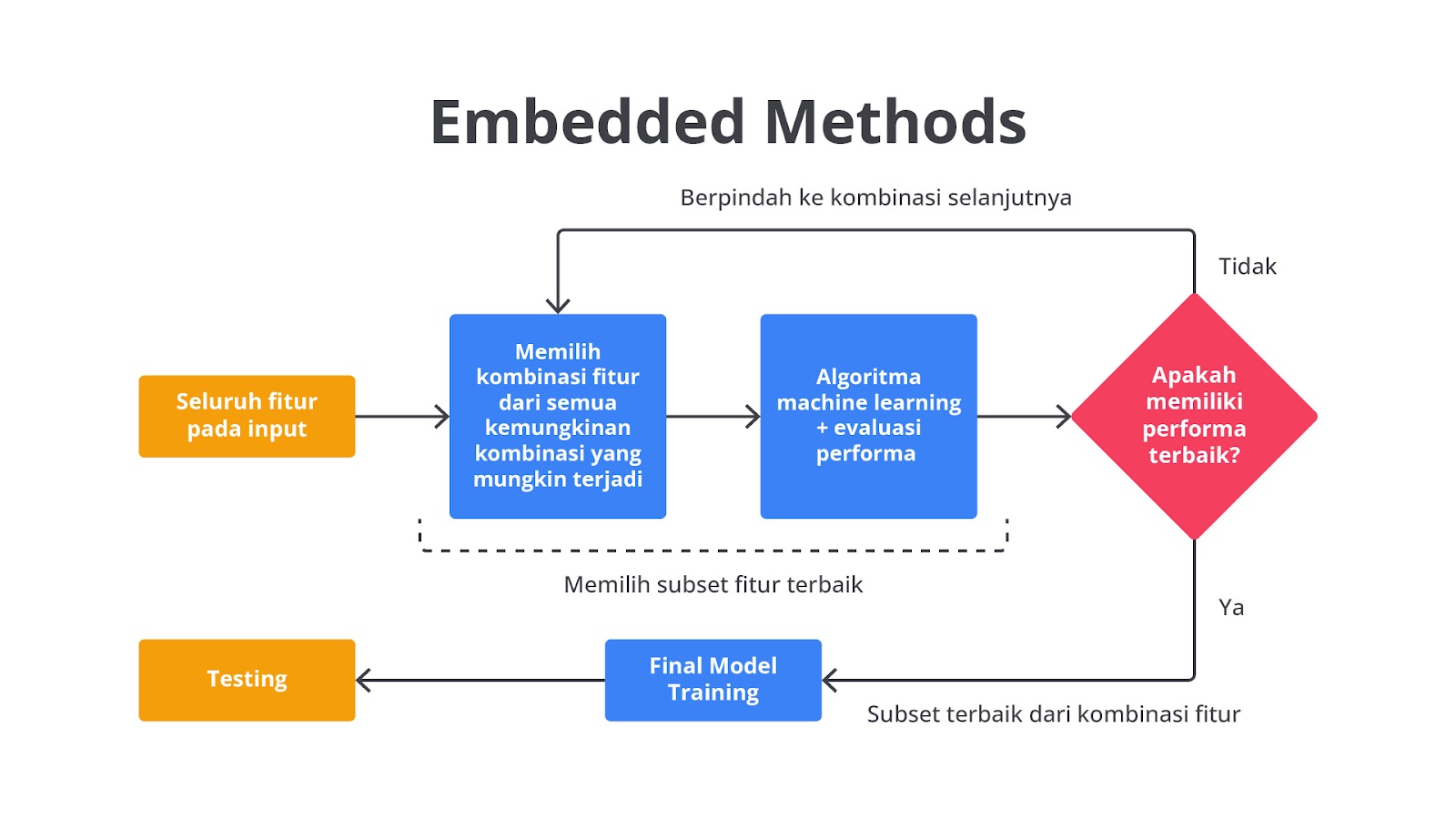
Metode ini melakukan pemilihan fitur saat model dibangun yang memberikan kelebihan dalam hal efisiensi dan efektivitas. Contohnya adalah dengan menggunakan teknik regularisasi seperti Lasso Regression (L1 Regularization) yang menggunakan penalti untuk mengatur bobot fitur menjadi nol, sehingga secara otomatis memilih fitur yang paling penting. Perhitungan yang dilakukan mirip dengan lasso regression pada modul Supervised Learning - Regresi. Jika, Anda ingin bernostalgia dengan rumus matematikanya, silakan ulas kembali materinya, ya.
Selain teknik regularisasi, metode ini juga dapat menggunakan teknik Tree-Based. Tree-Based Methods adalah teknik dalam machine learning yang menggunakan struktur pohon untuk membuat keputusan dan memprediksi hasil.
Metode ini memiliki beberapa kekurangan dan kelebihan seperti berikut.
- Kekurangan
- Metode embedded dapat lebih sulit untuk diinterpretasikan dibandingkan dengan metode filter sehingga lebih sulit untuk memahami mengapa fitur tertentu dipilih.
- Tidak semua algoritma machine learning menerima hasil dari metode embedded.
- Kelebihan
- Mirip dengan wrapper methods, teknik ini memanfaatkan proses pembelajaran untuk mengidentifikasi fitur yang relevan sehingga dapat memberikan hasil yang lebih baik.
Terakhir setelah menamatkan konsep embedded, mari kita coba implementasikan method ini pada dataset yang telah disiapkan sebelumnya menggunakan kode berikut.
- # ------------------- Embedded Methods -------------------
- # Menggunakan Random Forest untuk mendapatkan fitur penting
- rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
- rf_model.fit(X_train, y_train)
- # Mendapatkan fitur penting
- importances = rf_model.feature_importances_
- indices = np.argsort(importances)[::-1]
- # Menentukan ambang batas untuk fitur penting
- threshold = 0.05 # Misalnya, ambang batas 5%
- important_features_indices = [i for i in range(len(importances)) if importances[i] >= threshold]
- # Memindahkan fitur penting ke variabel baru
- X_important = X_train[:, important_features_indices] # Hanya fitur penting dari data pelatihan
- X_test_important = X_test[:, important_features_indices] # Hanya fitur penting dari data pengujian
- # Mencetak fitur yang dipilih
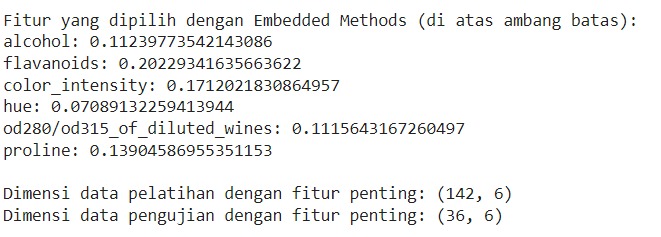
- print("Fitur yang dipilih dengan Embedded Methods (di atas ambang batas):")
- for i in important_features_indices:
- print(f"{data.feature_names[i]}: {importances[i]}")
- # X_important sekarang berisi hanya fitur penting
- print("\nDimensi data pelatihan dengan fitur penting:", X_important.shape)
- print("Dimensi data pengujian dengan fitur penting:", X_test_important.shape)
Secara garis besar, kode di atas akan menjalankan beberapa langkah hingga akhirnya mendapatkan fitur yang paling relevan menurut perhitungannya.
Pertama, kode di atas menggunakan algoritma Random Forest dari scikit-learn untuk melatih model klasifikasi. Algoritma Random Forest dipilih karena secara otomatis dapat menghitung kepentingan fitur selama proses pelatihan dijalankan. Pada kasus ini, model dilatih menggunakan data pelatihan (X_train dan y_train) dengan parameter n_estimators=100, yang berarti model akan membangun 100 pohon keputusan secara paralel. Selain itu, kode ini juga mengatur random_state=42 untuk memastikan hasil yang konsisten di setiap kali menjalankan kode.
Setelah model dilatih, Anda bisa mendapatkan informasi tentang peran fitur menggunakan atribut feature_importances_. Nilai ini menunjukkan seberapa penting setiap fitur dalam membantu model membuat keputusan (pada kasus ini klasifikasi). Fitur dengan nilai feature_importance yang lebih tinggi memiliki pengaruh yang lebih besar terhadap prediksi model.
Untuk menampilkan fitur terpenting, nilai feature_importance perlu diurutkan dari yang tertinggi ke terendah menggunakan np.argsort(importances)[::-1] sehingga Anda akan mendapatkan indeks fitur berdasarkan urutan kontribusinya.
Selanjutnya, Anda perlu menetapkan ambang batas (threshold). Pada kasus ini, kita sepakat menentukan nilai sebesar 0.05 yang artinya kita hanya akan mempertahankan fitur yang memiliki nilai kepentingan di atas 5%. Bagaimana caranya memilih fiturnya? Tugas ini akan dieksekusi oleh baris kode [i for i in range(len(importances)) if importances[i] >= threshold] yang bertugas untuk memilih indeks fitur yang memenuhi kriteria tersebut.
Setelah fitur-fitur penting dipilih, Anda perlu memindahkan data yang berisikan fitur yang dianggap penting ke dalam variabel baru. X_important adalah versi dari X_train yang hanya berisi fitur-fitur yang dianggap penting, dan hal yang sama dilakukan untuk data pengujian (X_test_important).
Kode di atas juga mencetak daftar fitur yang dipilih beserta nilai kontribusinya sehingga kita bisa melihat fitur mana saja yang dianggap signifikan oleh model Random Forest. Terakhir, kode akan mencetak dimensi dari data pelatihan dan pengujian setelah seleksi fitur dengan tujuan memberikan gambaran tentang seberapa banyak fitur yang telah disaring.
Sehingga, hasil akhir dari kode di atas kurang lebih seperti berikut.
Nah, sampai di sini Anda sudah mengetahui konsep beserta contoh penerapannya pada studi kasus sederhana. Namun, seperti terasa ada yang kurang ya? Benar, sampai di sini semuanya belum terasa jelas karena tidak ada perbandingan dari masing-masing metode terkait evaluasi performanya. Oleh karena itu, mari kita bahas performa ketiganya agar lebih terbayang.
Karena kita akan melakukan proses evaluasi sebanyak tiga kali, alangkah baiknya membuat sebuah fungsi agar dapat digunakan berulang kali.
- # Evaluasi dengan fitur terpilih dari masing-masing metode
- def evaluate_model(X_train, X_test, y_train, y_test, model):
- model.fit(X_train, y_train)
- accuracy = model.score(X_test, y_test)
- return accuracy
Kode di atas merupakan sebuah fungsi yang akan melakukan pelatihan dan mendapatkan metriks evaluasi (accuracy) seperti yang sudah Anda biasa lakukan pada modul-modul sebelumnya, tetapi dibungkus pada sebuah fungsi.
Selanjutnya, mari kita latih model machine learning berdasarkan fitur yang telah ditentukan oleh masing-masing metode feature selection menggunakan kode berikut.
- # Model Logistic Regression untuk Filter Methods
- logistic_model_filter = LogisticRegression(max_iter=200)
- accuracy_filter = evaluate_model(X_train_filter, X_test_filter, y_train, y_test, logistic_model_filter)
- # Model Logistic Regression untuk Wrapper Methods
- logistic_model_rfe = LogisticRegression(max_iter=200)
- accuracy_rfe = evaluate_model(X_train_rfe, X_test_rfe, y_train, y_test, logistic_model_rfe)
- # Model Random Forest untuk Embedded Methods
- accuracy_rf = evaluate_model(X_important, X_test_important, y_train, y_test, rf_model)
Untuk melihat performa ketiga model tersebut Anda dapat menggunakan perintah print() sederhana atau menambahkan teks agar mempermudah pemahaman pembaca seperti berikut.
- print(f"\nAkurasi Model dengan Filter Methods: {accuracy_filter:.2f}")
- print(f"Akurasi Model dengan Wrapper Methods: {accuracy_rfe:.2f}")
- print(f"Akurasi Model dengan Embedded Methods: {accuracy_rf:.2f}")

Seperti yang dapat Anda lihat masing-masing metode memiliki performa yang berbeda. Hal ini karena penggunaan fitur yang berbeda pada proses pelatihan model machine learning. Karena embedded methods memiliki akurasi sempurna, mungkin Anda berpikir “Ya sudah aku pakai embedded methods saja untuk semua kasus.” Eiitss, tidak semudah itu kawan, meskipun embedded methods bisa digunakan dalam berbagai skenario, tetapi tidak semua masalah cocok menggunakan metode ini. Ada beberapa hal yang menjadi pertimbangan ketika Anda akan melakukan feature selection.
- Jenis Model: tidak semua algoritma mendukung embedded methods, contohnya linear regression standar atau k-nearest neighbors (KNN) karena algoritma tersebut tidak memiliki mekanisme bawaan untuk memilih fitur. Untuk model-model tersebut, Anda perlu menggunakan feature selection secara independen (seperti filter atau wrapper methods).
- Ukuran dan Kompleksitas Data: jika data sangat besar atau kompleks, embedded feature selection bisa memakan waktu dan sumber daya komputasi yang lebih besar. Dalam beberapa kasus, menggunakan teknik lain seperti filter methods untuk mereduksi dimensi data di awal bisa lebih efisien.
- Kebutuhan Interpretabilitas: beberapa model dengan embedded feature selection (misalnya, Random Forest) bisa menghasilkan model yang sulit diinterpretasi. Jika interpretabilitas sangat penting, gunakan teknik lain yang lebih sesuai.
- Tipe Fitur: jika fitur yang ada memiliki tipe yang sangat berbeda-beda misalnya numerik dan kategorikal, embedded feature selection dalam model tertentu mungkin tidak bekerja dengan baik.
Jadi semua metode di atas memiliki kelebihannya masing-masing, ketika kelak Anda menggunakan data yang lebih kompleks serta fitur yang lebih banyak, belum tentu embedded methods menjadi pilihan terbaik. Karena pada dasarnya, pembangunan machine learning tidak hanya bergantung kepada performa, tetapi juga efisiensi biaya dan optimisasi bisnis. So, jangan lupa untuk berlatih dan mempertajam kemampuan Anda, ya!
Encoding Variabel ke Numerik
Setelah dataset dibersihkan, masih ada beberapa tahap yang perlu dilakukan agar dataset benar-benar siap untuk diproses oleh model machine learning. Biasanya, dataset Anda akan terdiri dari dua jenis data: kategorik dan numerik. Contoh data numerik adalah: ukuran panjang, suhu, nilai uang, hitungan dalam bentuk angka, dll, yang terdiri dari bilangan integer (seperti -1, 0, 1, 2, 3, dan seterusnya) atau bilangan float (seperti -1.0, 2.5, 39.99, dan seterusnya).
Setiap nilai dari data dapat diasumsikan memiliki hubungan dengan data lain karena data numerik dapat dibandingkan dan memiliki ukuran yang jelas. Misal, Anda dapat mengatakan bahwa panjang 39 m lebih besar dibanding 21 m. Jenis data ini terdefinisi dengan baik, dapat dioperasikan dengan metode statistik, dan mudah dipahami oleh komputer.
Jenis data lain yang sering kita temui adalah data kategorik. Data kategorik adalah data yang berupa kategori dan berjenis string, tidak dapat diukur atau didefinisikan dengan angka atau bilangan. Contoh data kategorik adalah sebuah kolom pada dataset yang berisi perkiraan cuaca seperti cerah, berawan, hujan, atau berkabut.
Contoh lain dari data kategorik adalah jenis buah misalnya apel, pisang, semangka, dan jeruk. Pada jenis data ini, kita tidak bisa mendefinisikan operasi perbandingan seperti lebih besar dari, sama dengan, dan lebih kecil dari. Dan dengan demikian, kita juga tidak dapat mengurutkan dan melakukan operasi statistik terhadap data jenis ini.
Umumnya, model machine learning tidak dapat mengolah data kategorik, sehingga kita perlu melakukan konversi data kategorik menjadi data numerik. Banyak model machine learning seperti Regresi Linear dan Support Vector Machine (kedua model ini sudah dibahas pada modul-modul sebelumnya, silakan cek kembali ya!) yang hanya menerima input numerik sehingga tidak bisa memproses data kategorik. Salah satu teknik untuk mengubah data kategorik menjadi data numerik adalah dengan menggunakan Encoding.
Encoding dalam machine learning adalah proses mengonversi data non-numerik (kategorikal atau teks) menjadi bentuk numerik. Tujuan utamanya agar data tersebut dapat dimengerti oleh komputer sehingga dapat menjadi model yang dapat digunakan. Hal ini sangat penting karena sebagian besar algoritma machine learning bekerja dengan angka untuk menghitung jarak, perhitungan statistik, dan pengambilan keputusan.
Ketika Anda membiarkan data non-numerik untuk dilatih, ia akan menimbulkan masalah karena model machine learning biasanya hanya dapat memproses data dalam bentuk numerik. Itulah sebabnya, data non-numerik harus diubah menjadi angka agar dapat digunakan dalam proses pelatihan model.

Secara umum komputer dan model machine learning hanya dapat menangani angka. Oleh karena itu, jika dataset mengandung kolom-kolom non-numerik, seperti kategori (contoh: "Merah", "Biru", "Hijau") perlu diubah menjadi angka agar dapat diproses oleh algoritma. Tanpa encoding yang tepat, model dapat memberikan hasil yang buruk atau bahkan gagal berfungsi. Lalu, bagaimana cara menentukan teknik encoding yang tepat? Tenang, kita akan memulai semuanya dari dasar, sekarang saatnya Anda mengetahui perbedaan dari masing-masing teknik encoding.
Ada berbagai macam teknik encoding yang yang memiliki karakteristik berbeda-beda. Namun, pada materi ini, kita hanya akan membahas tujuh buat teknik yang paling sering digunakan ketika membangun model machine learning. Perhatikan gambar berikut untuk memahami perbedaanya secara singkat.
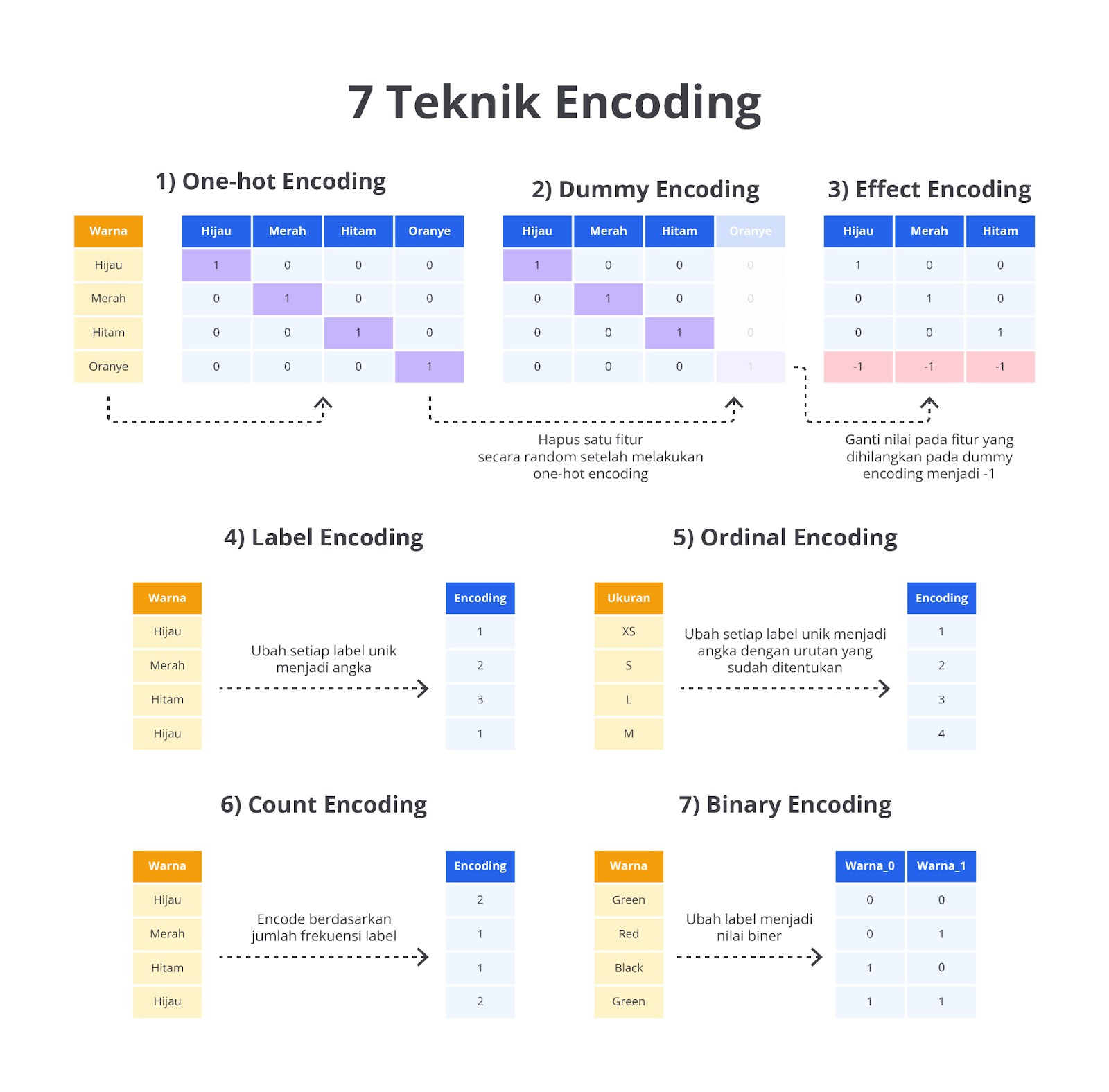
Sekilas dari gambar di atas, Anda sudah mengetahui perbedaannya ‘kan? Namun, itu adalah hasil akhirnya saja sehingga terlihat sangat mudah. Pada materi ini, kita tidak akan berhenti sampai di situ. Agar Anda memiliki pemahaman yang lebih dalam, mari kita bahas semua teknik encoding dengan lebih detail beserta contoh implementasinya.
One-Hot Encoding
One-Hot Encoding adalah salah satu metode paling umum yang digunakan dalam setiap kasus machine learning dan data science untuk menangani data kategorikal. One-Hot Encoding mengubah setiap nilai unik dari kolom kategorikal menjadi biner pada kolom baru. Setiap kolom biner tersebut berisi nilai 0 atau 1 yang menunjukkan apakah kategori tersebut ada dalam baris itu atau tidak.
Sebagai contoh, jika kita memiliki kolom dengan tiga kategori yaitu Merah, Kuning, dan Hijau, One-Hot Encoding akan membuat tiga kolom biner yang masing-masing merepresentasikan kategori tersebut. Jika suatu baris memiliki kategori Merah, kolom Warna_Merah nilainya akan 1, dan kolom Kuning dan Hijau nilainya 0.

Seperti yang sudah Anda pelajari tahapan encoding ini memiliki peran yang krusial dalam pembangunan model machine learning. Salah satunya karena kebanyakan algoritma machine learning terutama yang berbasis jarak seperti K-Nearest Neighbors atau Support Vector Machine tidak dapat menangani data kategorikal dalam bentuk string atau teks karena tidak ada definisi matematis dari jarak antara string.
Jika Anda hanya mengubah kategori menjadi angka menggunakan metode seperti Label Encoding, model dapat menganggap bahwa ada urutan atau hubungan numerik antara kategori, padahal kategori tersebut sebenarnya independen. One-Hot Encoding dapat memastikan bahwa tidak ada asumsi urutan atau hubungan antara kategori, dan setiap kategori dianggap sebagai entitas yang unik dan independen.
Namun, One-Hot Encoding juga memiliki kekurangan yang cukup mengganggu. Salah satu masalah terbesar teknik One-Hot Encoding yaitu ketika kolom kategorikal memiliki banyak nilai unik (biasa disebut High Cardinality), jumlah kolom biner yang dihasilkan bisa sangat banyak.
Hal ini menyebabkan masalah dalam efisiensi komputasi dan memori karena jumlah fitur yang sangat besar. Misalnya, jika Anda memiliki 1000 kategori yang berbeda, Anda akan memiliki 1000 kolom baru setelah One-Hot Encoding yang bisa menghambat performa model, terutama pada dataset besar.
Secara umum, ada beberapa hal yang perlu Anda perhatikan ketika akan menggunakan teknik One-Hot Encoding.
- Data kategorikal memiliki jumlah kategori yang relatif kecil.
- Tidak ada urutan antar kategori.
- Model machine learning yang digunakan cocok untuk data high-dimensional seperti neural networks dan tree-based models.
Sampai di sini tentu Anda sudah paham ‘kan tentang konsep dasar One-Hot Encoding? Nicee, selanjutnya kita akan kembali melangkah ke teknik encoding lainnya agar Anda memiliki pengetahuan dan tidak melakukan All in One Methods ketika membangun model machine learning.
Dummy Encoding
Dummy Encoding merupakan salah satu teknik encoding yang digunakan untuk mengubah data kategorikal menjadi format numerik, khususnya yang digunakan dalam model machine learning.
Seperti One-Hot Encoding, Dummy Encoding menghasilkan kolom-kolom biner (0 dan 1) untuk setiap kategori. Namun, perbedaannya terletak pada Dummy Encoding satu kategori akan dihapus atau digunakan sebagai kategori referensi (baseline). Tujuan utama Dummy Encoding adalah untuk menghindari masalah multikolinearitas yang bisa terjadi pada model regresi atau model linier lainnya.
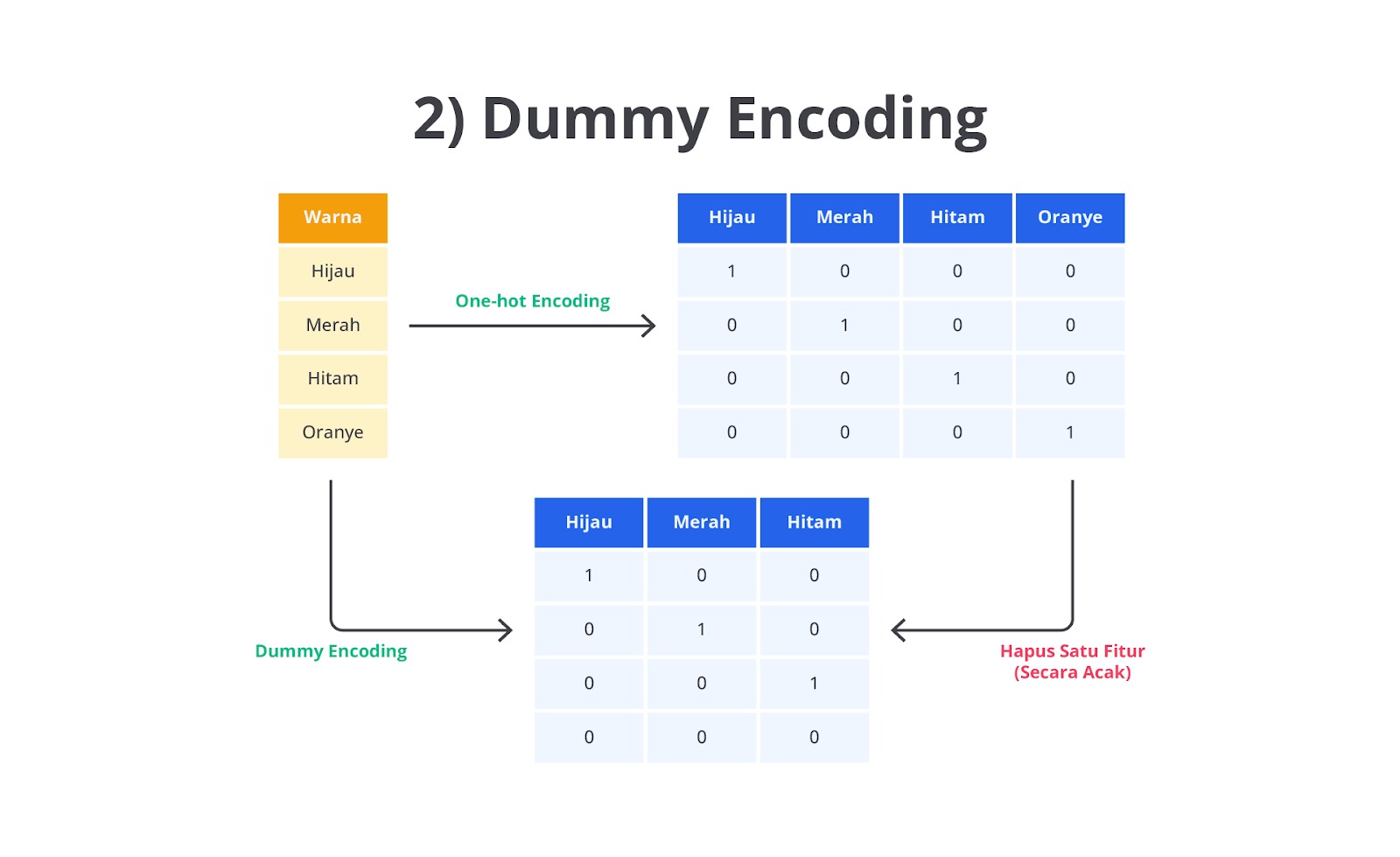
Dummy Encoding memiliki peran yang sangat penting ketika Anda bekerja dengan model linier, seperti regresi linier atau regresi logistik. Jika kita menggunakan One-Hot Encoding hasilnya setiap kolom yang dihasilkan dari kategori tersebut memungkinkan menjadi kombinasi linier satu sama lain sehingga menyebabkan multikolinearitas. Seperti yang Anda ketahui, multikolinearitas terjadi ketika ada hubungan linier yang kuat antara dua atau lebih variabel independen (fitur) sehingga dapat mengacaukan hasil estimasi koefisien dalam model regresi.
Dengan menghapus satu kategori secara acak, Dummy Encoding dapat menghindari masalah ini karena nilai dari kategori yang dihapus bisa diprediksi dari kolom lainnya. Dalam analisis regresi, kategori yang dihapus ini bertindak sebagai baseline atau referensi, dan koefisien dari kategori lainnya menunjukkan pengaruhnya relatif terhadap kategori baseline tersebut.
Effect Encoding
Effect Encoding atau juga dikenal sebagai Deviation Encoding atau Contrast Coding adalah teknik encoding yang digunakan untuk menangani data kategorikal seperti One-Hot dan Dummy Encoding. Seperti teknik sebelumnya, Effect Encoding berperan untuk mengubah data kategorikal menjadi format numerik. Namun, terdapat perbedaan penting dalam proses pengubahan kategori menjadi nilai numerik. Effect Encoding menggunakan metode yang berbeda dengan Dummy Encoding yaitu menghilangkan satu kategori dan menggantikannya dengan nilai 0, menggunakan nilai -1 sebagai representasi untuk kategori referensi atau baseline.
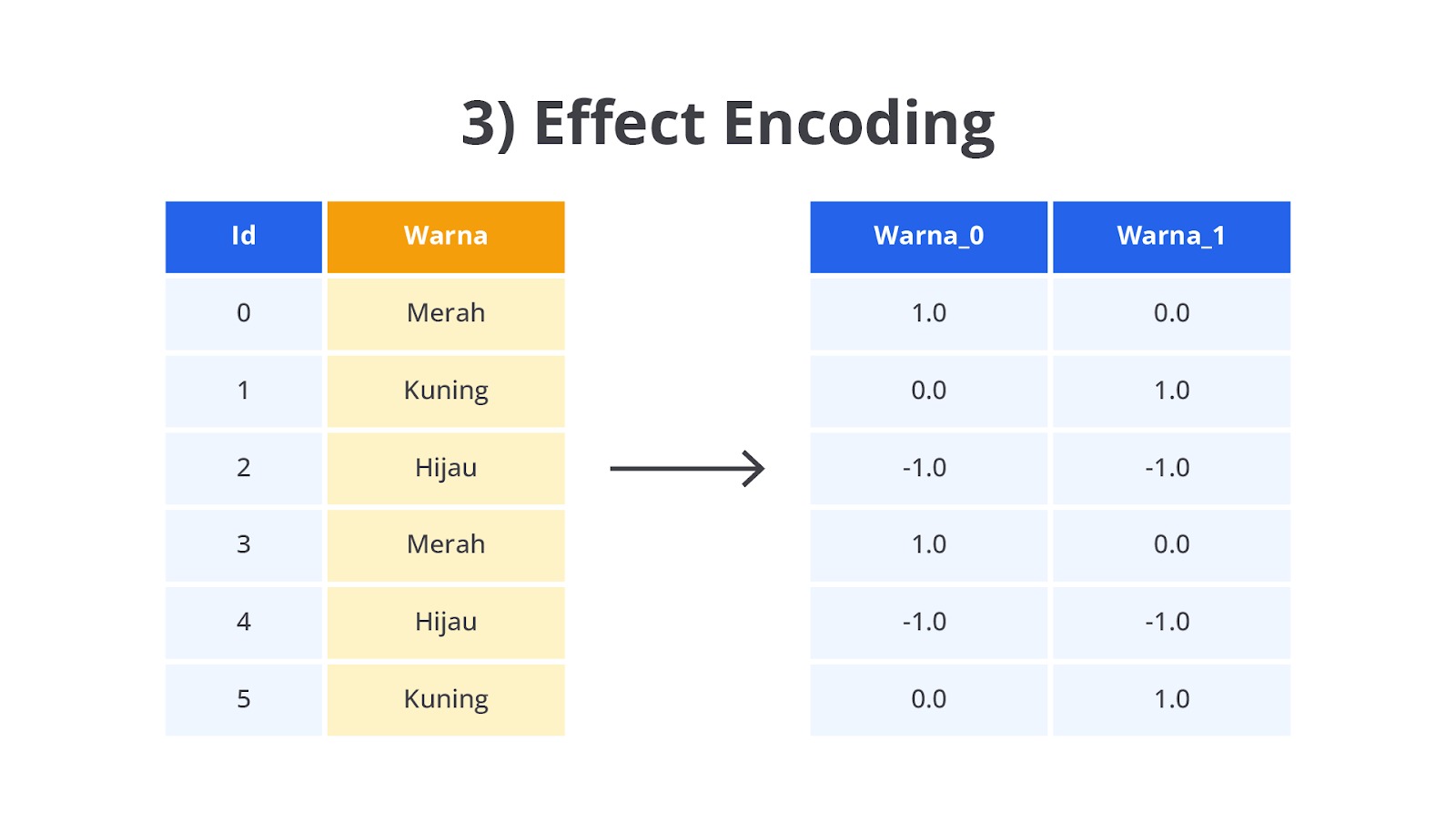
Dalam Effect Encoding, kategori-kategori dalam kolom data kategorikal diubah menjadi kolom-kolom biner (1, 0, -1), tetapi ada satu perbedaan besar yang perlu Anda ketahui jika dibandingkan dengan Dummy Encoding seperti berikut.
- Alih-alih menghapus kategori referensi, effect encoding akan mengganti kategori baseline (atau referensi) menjadi nilai -1 dalam setiap kolom biner lainnya.
- Kategori-kategori lainnya diberi nilai 1 jika mereka sesuai dengan kategori tersebut dan 0 jika tidak termasuk kategori tersebut.
Dengan Effect Encoding, nilai -1 pada kategori baseline memastikan bahwa rata-rata koefisien model untuk semua kategori yang di-encode sama dengan 0. Artinya, setiap kategori yang di-encode dalam Effect Encoding merepresentasikan efek dari kategori tersebut relatif terhadap rata-rata keseluruhan, bukan terhadap kategori baseline (seperti dalam Dummy Encoding).
Pertanyaan umum yang biasanya muncul sampai materi ini adalah “Kapan menggunakan effect encoding?” Anda sebaiknya menggunakan Effect Encoding ketika memiliki kasus seperti berikut.
- Anda menginginkan nilai koefisien yang mengacu pada rata-rata. Jika Anda membangun model regresi dan ingin koefisien untuk setiap kategori menunjukkan perbedaan dari rata-rata keseluruhan, Effect Encoding adalah pilihan yang tepat.
- Bekerja dengan ANOVA atau analisis statistik. Effect Encoding sering digunakan dalam analisis statistik seperti ANOVA, di mana kita ingin mengetahui apakah kategori tertentu memiliki efek yang signifikan terhadap variabel dependen dibandingkan dengan rata-rata keseluruhan.
- Anda menginginkan simetri dalam representasi kategori. Jika Anda tidak ingin menghapus kategori referensi seperti pada teknik Dummy Encoding, Effect Encoding memberikan representasi yang lebih simetris dengan tetap menyertakan kategori referensi melalui nilai -1.
Sebetulnya masih banyak lagi parameter yang dapat menjadi pertimbangan ketika Anda memilih Effect Encoding. Untuk lebih lengkapnya, silakan baca pada paper berikut: Categorical Variables in Regression Analysis: A Comparison of Dummy and Effect Coding.
Label Encoding
Label Encoding adalah salah satu metode encoding yang digunakan untuk mengonversi data kategorikal menjadi numerik dalam proses pembuatan model machine learning. Metode ini sangat sederhana dan banyak digunakan, terutama untuk menangani data kategorikal yang bersifat ordinal di mana terdapat urutan antar kategori, tetapi juga dapat digunakan untuk data kategorikal non-ordinal.
Label Encoding bekerja dengan mengganti setiap kategori dengan nilai numerik unik. Kategori pertama akan diberi nilai 0, kategori kedua diberi nilai 1, dan seterusnya. Teknik ini mengubah data menjadi bentuk yang bisa dibaca oleh algoritma machine learning karena sebagian besar algoritma tidak dapat bekerja dengan data kategorikal dalam bentuk string.
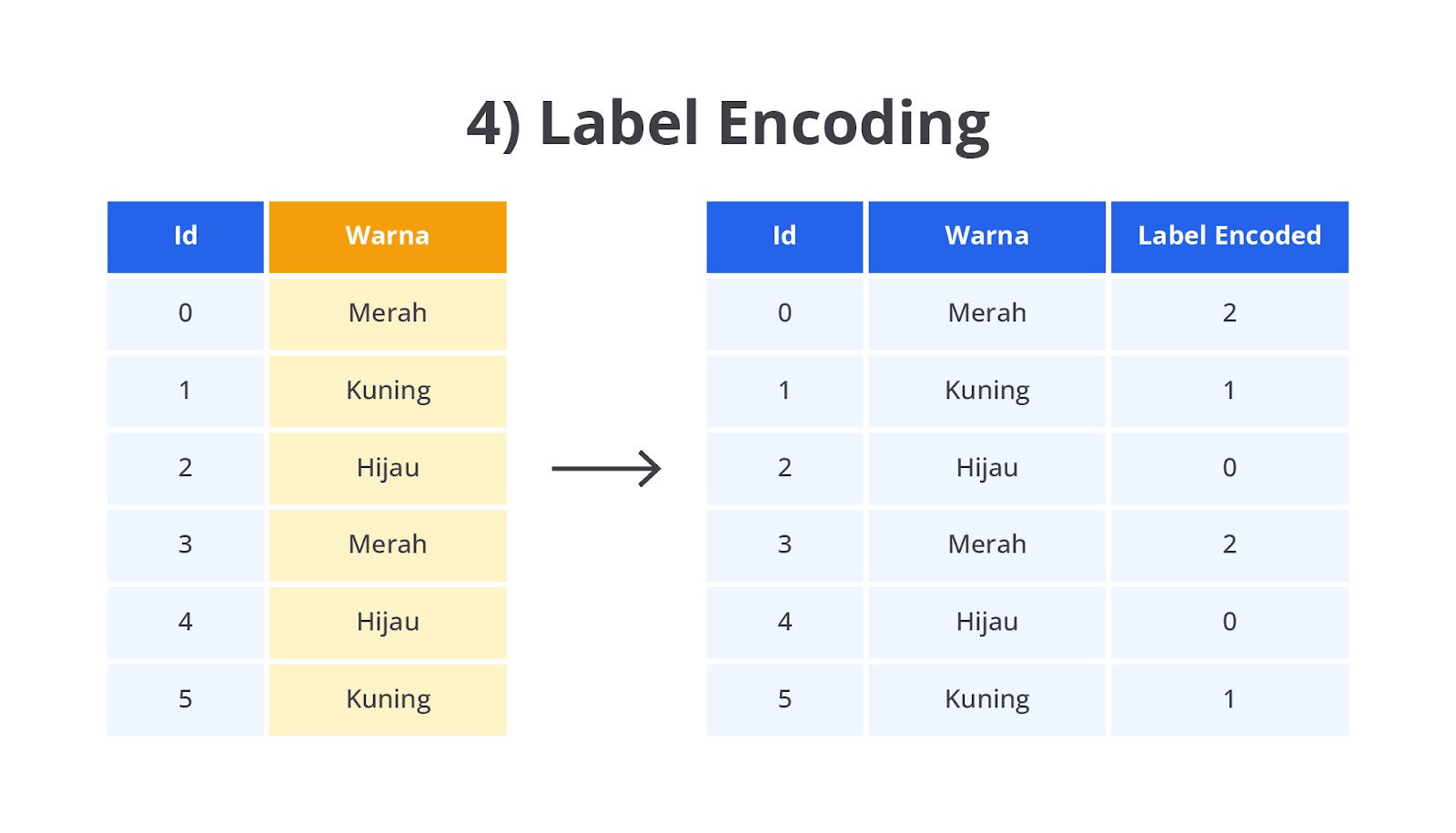
Label Encoding memungkinkan kita untuk melakukan pengubahan kategorikal menjadi numerik dengan cara yang sederhana dan cepat. Label Encoding biasanya digunakan ketika data kategorikal bersifat ordinal atau jumlah kategori relatif sedikit.
Lalu, bagaimana jika kategori tidak memiliki urutan yang logis seperti warna pada contoh kasus di atas? By default, fungsi LabelEncoder() akan mengurutkan data nominal berdasarkan urutan abjad pada variabel target.
| Penting untuk dicatat bahwa nilai numerik yang diberikan tidak memiliki nilai matematis apa pun yang melekat pada target yang diubah. Artinya, operasi matematika dasar seperti penjumlahan, pengurangan, perkalian, atau pembagian tidak ada gunanya. Sehingga Anda dapat mepertimbangkan teknik encoding lainnya ketika memiliki data nominal. |
Eiitss, pada teknik ini data ordinal masih diurutkan berdasarkan pengetahuan komputer, lalu bagaimana jika Anda memiliki urutan sendiri atau bahkan ingin mengikuti preferensi umum yang tidak dapat disediakan oleh algoritma ini? Tenang, pada teknik encoding berikutnya Anda dapat lebih leluasa untuk mengurutkan target sesuai keinginan.
Ordinal Encoding
Ordinal Encoding adalah salah satu metode encoding yang digunakan untuk mengonversi data kategorikal menjadi data numerik dalam proses pembuatan model machine learning. Berbeda dengan Label Encoding yang hanya mengubah kategori menjadi angka secara acak tanpa memperhatikan urutan, Ordinal Encoding digunakan khusus untuk data ordinal yang kategorinya memiliki urutan atau hierarki jelas.
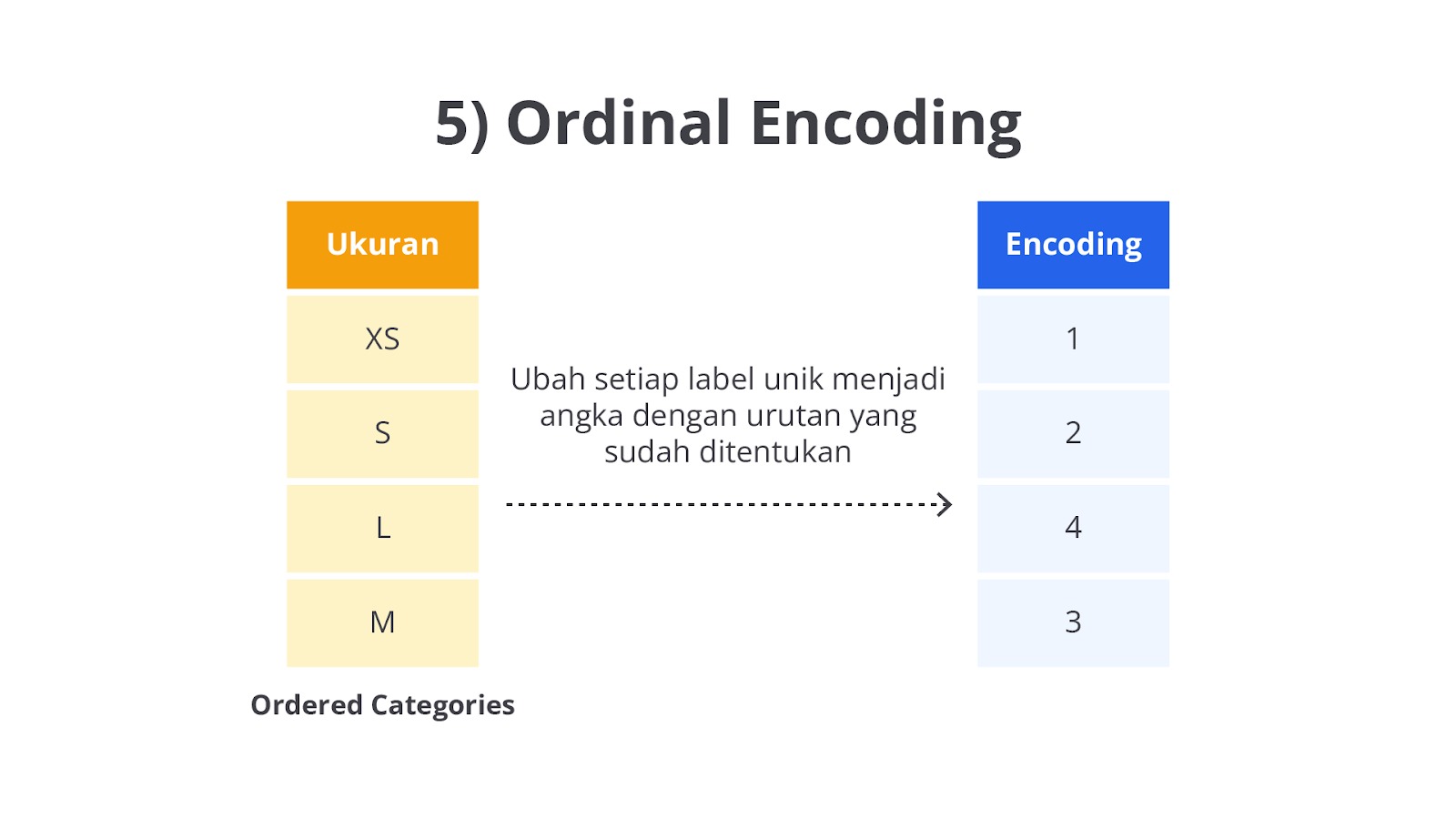
Dalam Ordinal Encoding, setiap kategori diberikan nilai numerik berdasarkan urutan yang logis dan alami dari kategori tersebut. Angka yang lebih kecil menunjukkan kategori yang lebih rendah, dan angka yang lebih besar menunjukkan kategori yang lebih tinggi dalam urutan tersebut. Pada kasus ini agar contoh kasusnya serupa dengan metode sebelumnya, kita akan mengasumsikan urutan warna dengan kondisi Merah < Kuning < Hijau (walaupun secara teknis ini tidak bisa diurutkan).
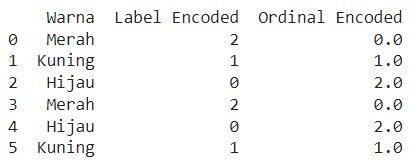
Seperti yang dapat Anda lihat pada gambar di atas hasil dari ordinal encoding ini memiliki output yang berbeda dengan label encoding. Hal ini karena kita telah menentukan urutan “Warna” sehingga memiliki nilai yang berbeda. Lalu, apa kelebihan dari teknik ordinal encoding ini?
Jika kategori target memiliki urutan (bertipe ordinal) tetapi Anda menggunakan teknik encoding lain seperti One-Hot Encoding atau Label Encoding (tanpa urutan), model machine learning tidak dapat memanfaatkan hubungan urutan dari kategori tersebut. Sebaliknya, dengan Ordinal Encoding urutan antara kategori tetap diperhitungkan sehingga model dapat belajar dari urutan tersebut.
Count Encoding
Count Encoding atau dikenal juga sebagai Frequency Encoding adalah salah satu metode encoding yang digunakan untuk mengonversi data kategorikal menjadi data numerik berdasarkan frekuensi kemunculan kategori di dalam dataset. Berbeda dengan metode seperti One-Hot Encoding atau Label Encoding, Count Encoding mengubah setiap kategori menjadi nilai numerik yang merepresentasikan berapa kali kategori tersebut muncul dalam kolom data.
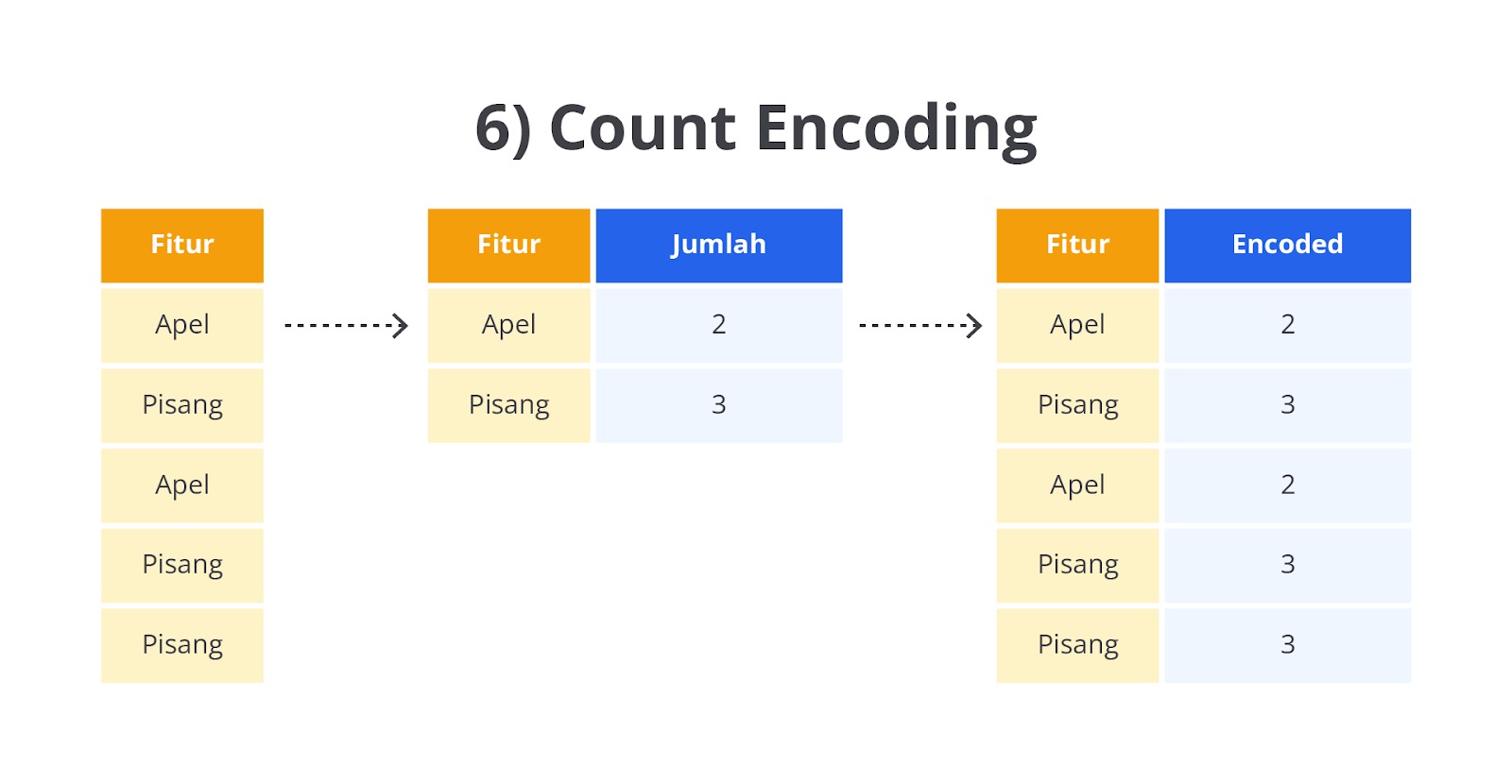
Count Encoding sangat berguna ketika ada banyak kategori unik di dalam suatu kolom, atau dalam dataset dengan kondisi high cardinality (kategori dengan jumlah yang sangat banyak). Dengan Count Encoding, kita mengurangi kompleksitas dataset tanpa menambah dimensi seperti yang terjadi pada One-Hot Encoding.
Pada dasarnya, Count Encoding akan menggantikan setiap kategori dengan jumlah kemunculannya di dalam dataset. Mari kita implementasikan teknik count encoding ini terhadap contoh data yang telah kita gunakan sejauh ini. Perhatikan gambar berikut.

Data yang kita gunakan pada contoh kasus ini yaitu Merah, Kuning, Hijau, Merah, Hijau, dan Kuning. Teknik ini akan menghitung berapa kali setiap kategori muncul sehingga menghasilkan ketentuan seperti berikut.
- Merah muncul 2 kali.
- Kuning muncul 2 kali.
- Hijau muncul 2 kali.
Sehingga akan menghasilkan data seperti berikut (perhatikan kolom Count Encoded).

Di sini, Merah, Kuning, dan Hijau masing-masing digantikan dengan angka 2 karena masing-masing muncul dua kali.
Perlu Anda perhatikan, teknik count encoding berpotensi tidak bekerja dengan optimal pada model berbasis jarak seperti KNN atau ketika ada potensi overfitting pada kategori yang jarang muncul.
Binary Encoding
Binary Encoding merupakan salah satu metode encoding yang digunakan untuk mengubah data kategorikal menjadi bentuk numerik dengan cara yang lebih efisien dibandingkan One-Hot Encoding atau Label Encoding. Binary Encoding bekerja dengan menggabungkan pendekatan Label Encoding dan One-Hot Encoding. Proses awalnya dimulai dari mengubah kategori menjadi angka menggunakan Label Encoding, dan kemudian angka-angka tersebut diubah ke bentuk biner. Setiap digit biner dari hasil encoding ini dipecah ke dalam kolom baru.
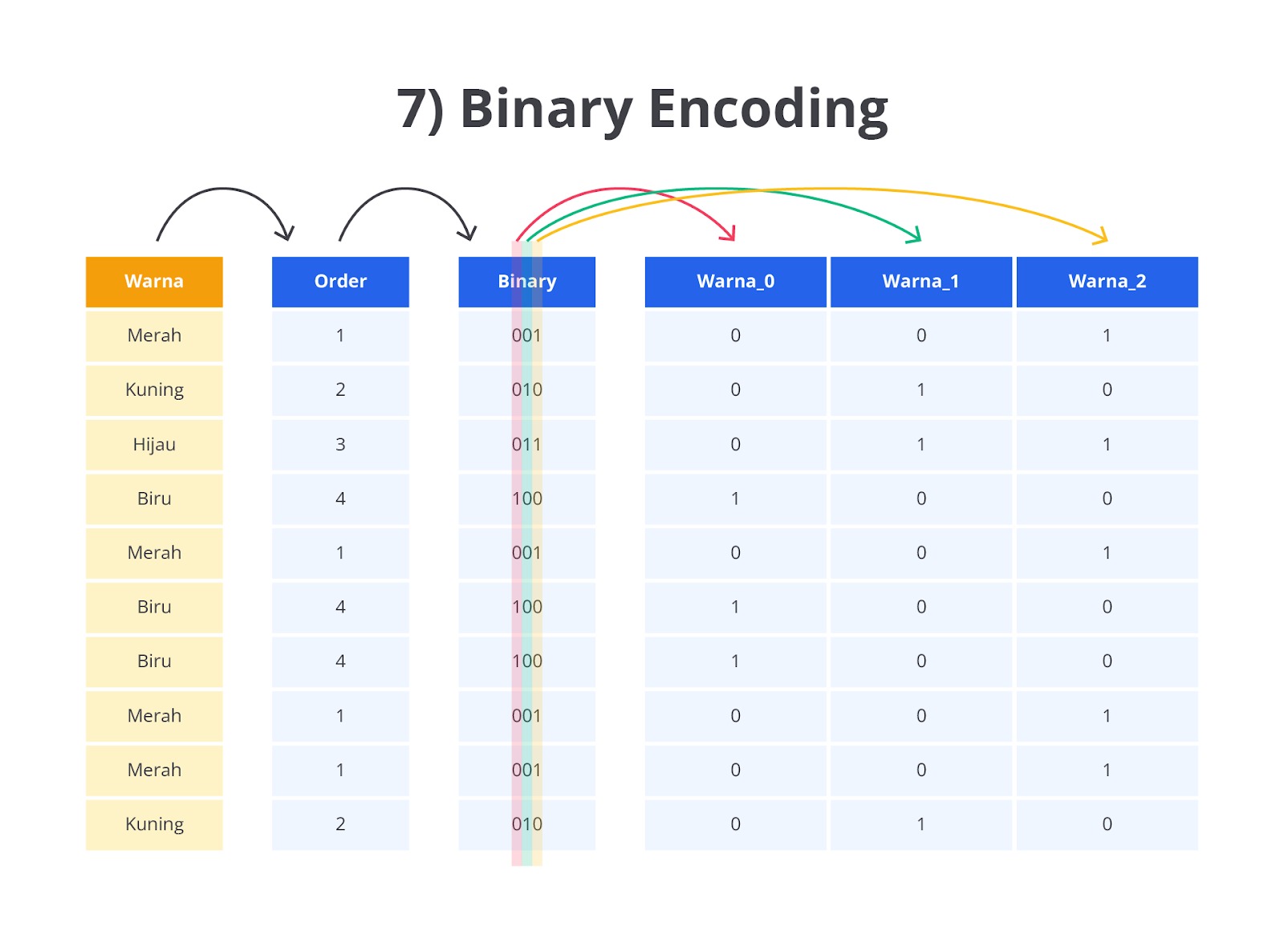
Metode ini dirancang untuk menangani data dengan data yang memiliki banyak kategori unik dengan cara yang lebih hemat ruang dan efisien daripada One-Hot Encoding yang bisa menghasilkan banyak kolom ketika ada banyak kategori.
Seperti yang dapat Anda lihat pada gambar di atas, teknik binary encoding akan dilakukan dalam dua langkah utama, yaitu label encoding dan konversi ke biner. Berikut penjelasan lebih detail terkait kedua tahapan yang dilalui oleh teknik binary encoding.
- Label Encoding: setiap kategori dalam kolom data kategorikal diubah menjadi angka integer yang unik. Sebagai contoh, jika kategori terdiri dari Merah, Kuning, Hijau, komputer akan memberi mereka angka 1, 2, dan 3 secara berurutan.
- Konversi ke Biner: setelah setiap kategori diberi angka melalui Label Encoding, angka-angka tersebut kemudian diubah ke bentuk biner. Setiap digit biner ini kemudian dipecah menjadi kolom terpisah, di mana setiap kolom mewakili satu digit dalam angka biner tersebut.
Sebagai contoh, jika Merah diberi nilai 1, Kuning diberi nilai 2, dan Hijau diberi nilai 3, representasi biner dari angka-angka tersebut adalah seperti berikut.
- 1 dalam biner: 01
- 2 dalam biner: 10
- 3 dalam biner: 11
Binary Encoding kemudian memecah setiap digit biner ini ke dalam kolom baru sehingga akan memberikan kolom baru seperti berikut.
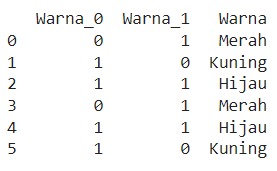
Setelah mempelajari berbagai teknik encoding mulai dari One-Hot, Dummy, Label, hingga Binary, dan Count Encoding, Anda kini memiliki bekal yang kuat untuk mengonversi data kategorikal menjadi numerik. Setiap teknik memiliki keunggulan tersendiri, dan tugas Anda adalah memilih teknik yang tepat sehingga dapat meningkatkan performa model machine learning.
Perlu Anda catat encoding bukan hanya langkah teknis, tetapi fondasi untuk pembangunan model yang lebih andal dan akurat.
Tetap semangat dan terus bereksperimen, dengan bekal ini jangan sampai salah pilih teknik, ya. Teruslah belajar dan bersiaplah menghadapi tantangan data berikutnya yaitu Binning pada materi berikutnya. See you~
Binning Numerik ke Kategorikal
Seperti yang sudah dipelajari pada materi Encoding Variabel ke Numerik tentunya Anda merasa bahwa semua permasalahan sudah dapat diselesaikan ‘kan? Eitsss, Anda tidak sepenuhnya salah dengan pemahaman tersebut. Namun, perlu Anda ketahui bahwa masih terdapat metode yang dapat membantu meningkatkan performa pembangunan model machine learning yaitu binning.
Binning digunakan untuk mengubah data numerik kontinu menjadi kategori atau interval diskrit. Tujuannya adalah untuk menyederhanakan data numerik dengan memisahkannya menjadi beberapa kelompok atau bin berdasarkan rentang atau distribusi nilai tertentu.
Bayangkan Anda memiliki data usia mulai dari 0 tahun hingga 100 tahun. Jika Anda mengubah data tersebut menggunakan encoding tentu akan menghasilkan data yang sangat banyak ‘kan? Nah, dengan menggunakan binning data tersebut dapat dibagi menjadi beberapa kelompok seperti “Anak-Anak”,"Remaja", "Dewasa", dan "Lansia".
| Rentang Usia | Label |
|---|---|
0-18 | Anak-Anak |
19-35 | Remaja |
36-55 | Dewasa |
56-100 | Lansia |
Binning digunakan dalam proses pembangunan model machine learning ketika kita ingin menyederhanakan data numerik kontinu atau menangani variabel yang memiliki variasi nilai yang luas. Salah satu alasan utamanya adalah untuk mengurangi variasi kecil yang tidak signifikan yang dapat mengganggu pola utama dalam data.
Dengan membagi data menjadi kategori atau kelompok, Anda dapat lebih fokus pada tren utama. Selain itu, binning juga berguna dalam menangani outlier, di mana nilai-nilai ekstrim yang jauh dari data lain dapat dikelompokkan dalam bin tertentu agar tidak memengaruhi model secara signifikan. Terakhir, binning sering digunakan karena kategori diskrit yang dihasilkan akan lebih mudah diolah dan diinterpretasikan dibandingkan dengan data numerik mentah.
Sampai di sini, apakah Anda sudah paham betul perbedaan encoding dan binning? Tenang saja karena keduanya sangat mudah dibedakan. Secara sederhana metode binning ini berfokus pada penyederhanaan data numerik, sementara encoding yang sebelumnya kita pelajari menangani variabel kategorikal.
Secara umum, teknik binning ini terbagi menjadi dua kelompok besar yaitu unsupervised binning dan supervised binning.
Unsupervised binning dan supervised binning merupakan dua pendekatan yang berbeda dalam mengelompokkan data numerik ke dalam kategori (binning). Unsupervised binning tidak mempertimbangkan target variabel saat mengelompokkan data melainkan hanya berdasarkan pada distribusi atau rentang dari fitur yang sedang diolah.
Metode ini sering menggunakan teknik seperti equal-width binning yang membagi data menjadi interval dengan lebar yang sama, atau equal-frequency binning yang memastikan setiap bin memiliki jumlah data yang sama. Unsupervised binning cocok digunakan ketika kita tidak memiliki informasi tentang target variabel atau ingin membagi data secara netral.
Di sisi lain, supervised binning memanfaatkan informasi dari variabel target untuk menentukan rentang atau batasan binning agar lebih optimal. Pendekatan ini mencari cara untuk membagi data sehingga setiap bin dapat memaksimalkan kemampuan fitur dalam memprediksi target variabel. Salah satu metode yang umum digunakan dalam supervised binning adalah entropy based binning yang menentukan batas bin berdasarkan bagaimana fitur memisahkan target.
Supervised binning berguna untuk meningkatkan kinerja model prediktif dengan membentuk bin yang lebih relevan untuk klasifikasi atau regresi. Singkatnya, perbedaan utama terletak pada apakah target variabel diperhitungkan dalam proses binning atau tidak.
Agar lebih jelas, mari kita bahas dan praktikkan beberapa teknik binning mulai dari equal-width binning, equal-frequency binning, hingga entropy based binning.
Equal-Width Binning
Equal-width binning adalah metode binning yang membagi rentang nilai data numerik menjadi beberapa bin yang memiliki lebar interval yang sama. Dalam metode ini, rentang total dari data dihitung, kemudian rentang ini dibagi secara merata ke dalam sejumlah bin tertentu. Jumlah data dalam setiap bin tidak perlu sama, tetapi lebar intervalnya tetap seragam.
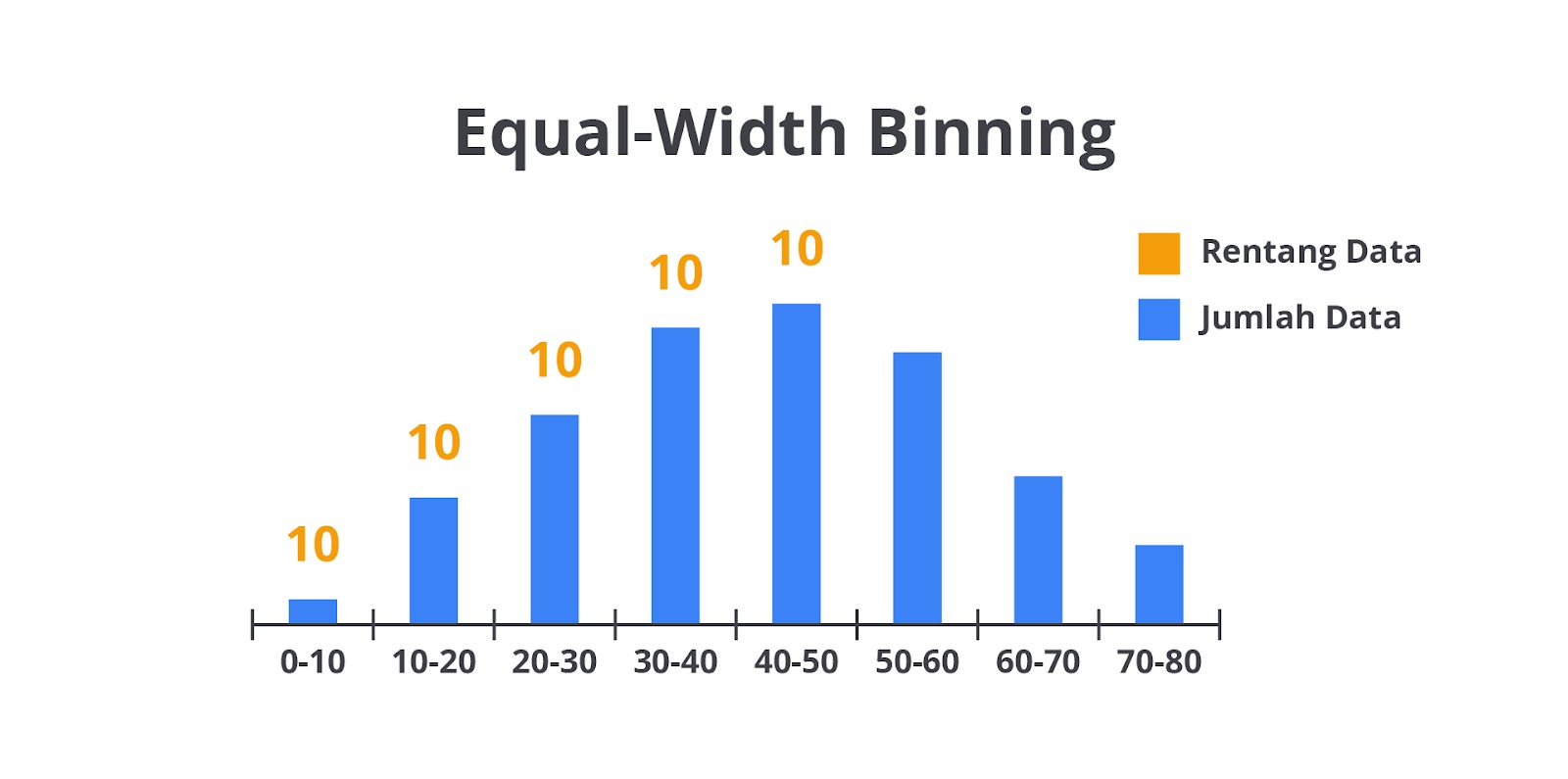
Misalkan Anda memiliki data usia yaitu [5, 12, 17, 22, 27, 33, 38, 42, 50, 57]. Lalu, ketika Anda ingin membagi data tersebut menjadi tiga bin dengan equal-width binning, langkah yang dapat dilakukan adalah seperti berikut.
- Nilai minimum: 5, nilai maksimum: 57.
- Rentang data: 57 - 5 = 52.
- Jika kita ingin 3 bin, maka lebar setiap bin adalah 52 / 3 = 17.33.
- Jadi, bin pertama adalah [5, 22.33], bin kedua [22.34, 39.67], dan bin ketiga [39.68, 57].
Berdasarkan rentang ini, data akan di-binned sebagai berikut.
- Bin 1 (5-22.33): [5, 12, 17]
- Bin 2 (22.34-39.67): [22, 27, 33, 38]
- Bin 3 (39.68-57): [42, 50, 57]
Mudah ‘kan? Teknik ini tidak memerlukan komputasi dan perhitungan yang sangat besar, karena pada dasarnya hanya membagi rentang bin secara merata. Kekurangan dari teknik ini yaitu tidak memperhatikan distribusi data. Jika data terdistribusi tidak merata, beberapa bin bisa sangat padat, sementara bin lain bisa kosong atau hampir kosong.
Equal-Frequency Binning
Equal-frequency binning adalah metode binning yang membagi data menjadi beberapa bin sehingga setiap bin berisi jumlah data yang sama atau hampir sama. Lebar interval bin tidak seragam, tetapi data di dalam setiap bin akan terdistribusi secara merata berdasarkan frekuensi.
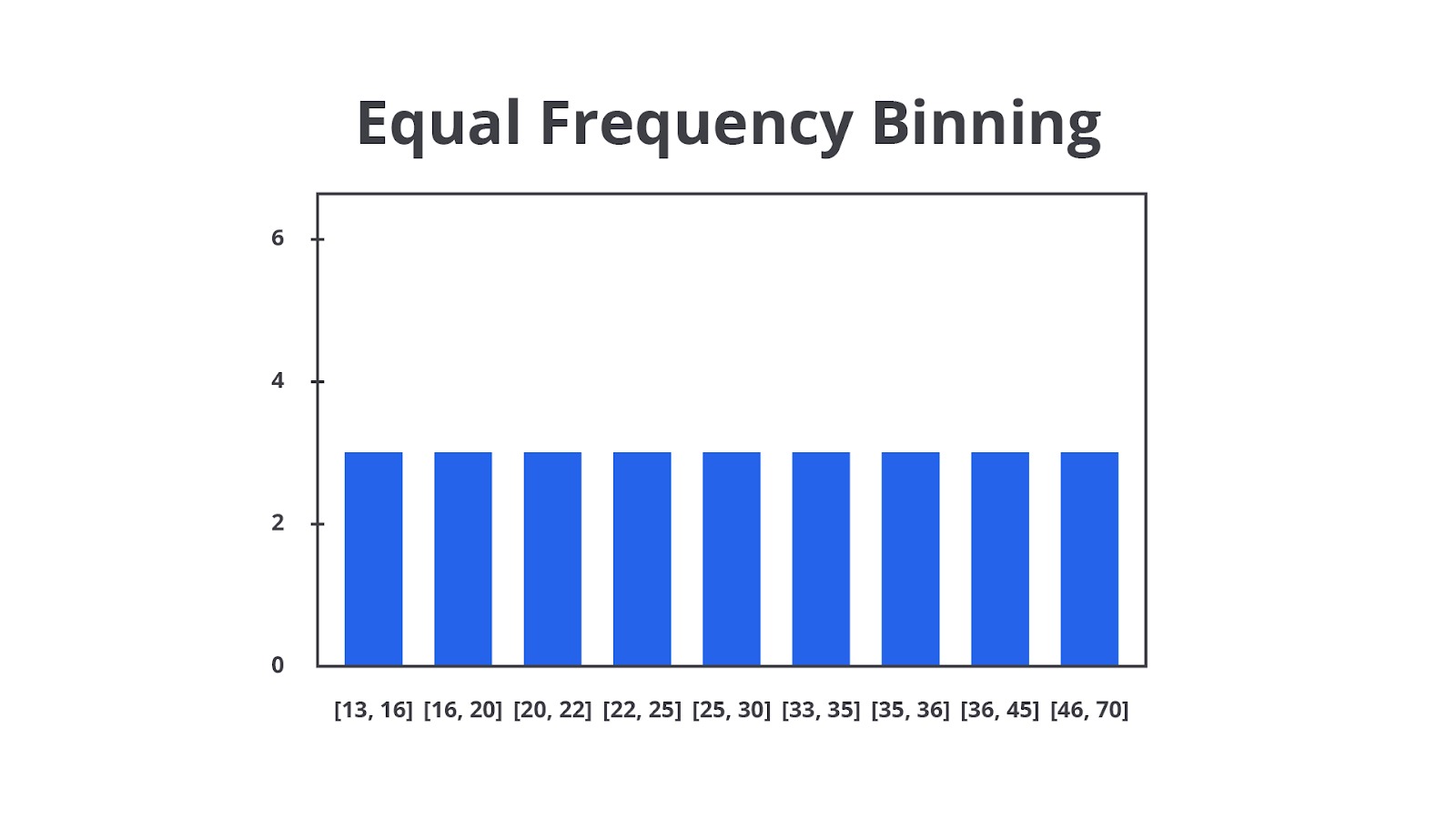
Mari kita implementasikan menggunakan data yang sama pada contoh sebelumnya yaitu data usia = [5, 12, 17, 22, 27, 33, 38, 42, 50, 57] dan ingin membaginya menjadi 3 bin.
- Data diurutkan: [5, 12, 17, 22, 27, 33, 38, 42, 50, 57].
- Karena ada 10 data dan kita ingin 3 bin, maka setiap bin harus berisi sekitar 10/3 ≈ 3-4 data.
Bin-nya akan dibagi seperti ini:
- Bin 1: [5, 12, 17] (3 data).
- Bin 2: [22, 27, 33, 38] (4 data).
- Bin 3: [42, 50, 57] (3 data).
Berbanding terbalik dengan equal-width, teknik ini memang membagi jumlah data secara merata, tetapi ada satu kekurangan ketika Anda ingin mempertahankan distribusi data yaitu lebar (jumlah data) pada setiap bin akan menjadi bervariasi sehingga dapat membuat interpretasi lebih sulit.
Sampai di sini sudah jelas kan perbedaan dari kedua teknik ini? Benar, keduanya tidak membutuhkan perhitungan matematika yang kompleks. Kedua teknik ini hanya menggunakan pembagian dasar sebagai senjata utamanya. Secara garis besar, keduanya akan membagi pembagian data dengan adil berdasarkan masing-masing parameternya. Berikut contoh lainnya dari penggunaan equal-width dan equal-frequency binning.

Entropy-Based Binning
Last but not least, salah satu metode yang mempertimbangkan hubungan binning dengan variabel lainnya yaitu entropy-based binning. Entropy-based binning adalah metode binning yang mempertimbangkan target variabel dalam pembangunan model supervised learning.
Metode ini membagi data berdasarkan seberapa baik nilai dalam setiap bin memisahkan kelas target. Entropi digunakan sebagai ukuran ketidakpastian atau "kekacauan" dalam distribusi kelas pada masing-masing bin. Binning ini bertujuan untuk meminimalkan entropi dalam setiap bin sehingga nilai di dalam bin lebih seragam terhadap target kelas.
Langkah-langkah Entropy-Based Binning secara umum seperti berikut.
- Urutkan data berdasarkan nilai fitur numerik.
- Tentukan berapa banyak bin yang diinginkan.
- Tentukan titik split dengan menghitung entropi dalam bin yang berbeda. Split dilakukan di tempat yang meminimalkan entropi.
- Ulangi proses untuk menambah bin, jika diperlukan.
Mari asumsikan kita memiliki data berikut dengan target apakah seseorang akan membeli produk (Yes/No).
- Usia: [18, 22, 25, 28, 35, 37, 40, 42, 50, 57]
- Target (Yes/No): [No, No, Yes, No, Yes, Yes, Yes, No, Yes, Yes]
Dari data di atas, kita dapat simpulkan bahwa terdapat enam data “Yes” dan empat data “No”. Langkah pertama yang perlu Anda lakukan adalah menghitung probabilitas untuk setiap kelas (pada kasus ini “Yes” dan “No”). Pada kasus ini terbagi menjadi 0.6 untuk “Yes” dan 0.4 untuk “No”.
Tahapan selanjutnya, Anda perlu menghitung nilai entropy dari keseluruhan dataset yang digunakan. Entropi adalah ukuran ketidakpastian dalam sebuah dataset. Konsep ini berasal dari teori informasi dan sering digunakan dalam algoritma seperti decision tree untuk menentukan seberapa informatif suatu atribut dalam memisahkan data.
Secara umum, semakin rendah nilai entropi, semakin "teratur" data tersebut, sedangkan semakin tinggi entropi maka semakin "acak" data tersebut sehingga lebih sulit untuk memisahkan fiturnya dengan mudah. Secara matematis, rumus entropy dapat ditulis seperti berikut.
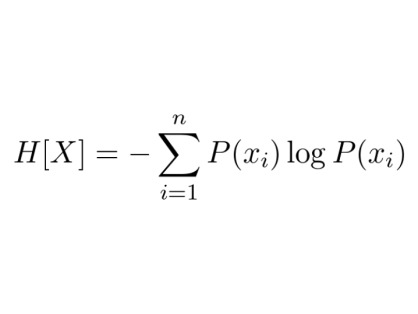
Berdasarkan nilai probabilitas yang telah dihitung sebelumnya, mari kita masukkan angka tersebut lalu hitung menggunakan rumus entropy sehingga menghasilkan angka seperti berikut.
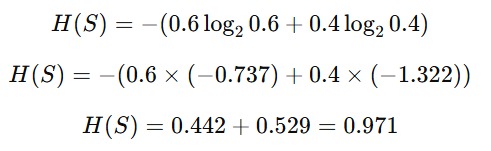
Jadi, entropi total dari dataset ini adalah 0.971. Selanjutnya, kita ingin membagi data berdasarkan usia. Anda perlu memilih salah satu titik split, misalnya di antara usia 25 dan 28, sehingga dua bin terbentuk yaitu bin_1 Usia <= 25 dan bin_2 Usia > 25.
Tahapan berikutnya, Anda perlu menghitung masing-masing nilai entropy pada setiap bin.
- bin_1 (Usia ≤ 25)
- Data: [18, 22, 25]
- Target: [No, No, Yes]
- 2 orang tidak membeli (No), 1 orang membeli (Yes).
- Probabilitas pYes = 1/3, pNo = 2/3.
Sehingga, entropi untuk bin_1 menghasilkan nilai seperti berikut.
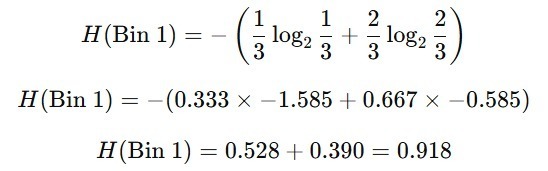
- bin_2 (Usia > 25)
- Data: [28, 35, 37, 40, 42, 50, 57]
- Target: [No, Yes, Yes, Yes, No, Yes, Yes]
- 5 orang membeli (Yes), 2 orang tidak membeli (No).
- Probabilitas pYes = 5/7, pNo = 2/7.
Sehingga, entropi untuk bin_2 menghasilkan nilai seperti berikut.
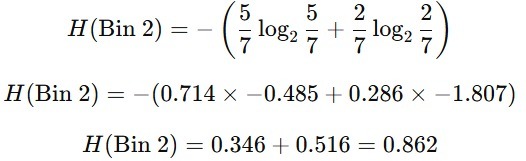
Langkah terakhir untuk menentukan fitur terbaik pada tahapan ini adalah mencari nilai information gain. Information gain adalah penurunan entropi setelah data dibagi menjadi bin. Secara matematis rumus information gain dapat ditulis seperti berikut.
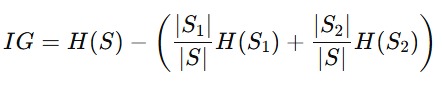
Jika diartikan, rumus di atas memiliki peran seperti berikut.
- H(S) adalah entropi total sebelum binning (pada kasus ini 0.971).
- H(S1) dan H(S2) adalah entropi dari masing-masing bin.
- ∣S1∣ dan ∣S2∣ adalah jumlah data dalam masing-masing bin.
- |S| adalah jumlah total data.
Pada contoh kasus ini, jumlah data pada bin_1 = 3, bin_2 = 7 dan total data = 10. Sehingga, dari angka tersebut Anda dapat mendapatkan nilai information gain seperti berikut.
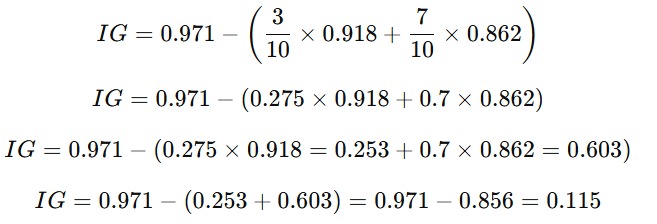
Dari perhitungan di atas, Anda mendapatkan nilai information gain pada fitur Usia sebesar 0.115. Sebenarnya Anda bisa mencoba beberapa titik pemisahan (split point) lain di usia yang berbeda, menghitung entropi untuk masing-masing bin, dan memilih split yang memberikan information gain tertinggi. Split yang menghasilkan information gain tertinggi adalah yang dipilih untuk membagi data karena memberikan penurunan ketidakpastian terbesar.
Pada kasus lainnya dengan fitur yang lebih banyak, Anda perlu menghitung nilai information gain pada setiap fitur. Jika split ini menghasilkan information gain tertinggi dibandingkan split lainnya, fitur tersebut akan dipilih sebagai titik binning yang optimal.
Nah, sampai di sini, Anda sudah mengetahui berbagai tipe binning pada data numerik. Sejujurnya masih terdapat banyak sekali teknik yang dapat Anda gunakan untuk melakukan binning. Namun, materi ini merupakan fondasi awal karena ke depannya Anda perlu melakukan eksplorasi secara mandiri agar terus berkembang sehingga dapat mengikuti perkembangan teknologi yang sangat pesat. So, jangan sampai kehabisan bensin ya, semangat!
Scaling Fitur
Scaling feature pada machine learning adalah proses menyesuaikan rentang atau skala nilai-nilai fitur agar berada dalam rentang tertentu yang lebih seragam. Proses ini memiliki peran yang cukup penting karena banyak algoritma machine learning sensitif terhadap perbedaan skala antara fitur.
Jika nilai pada masing-masing fitur tidak di-scaling, algoritma yang Anda gunakan mungkin akan memberikan bobot lebih pada fitur dengan rentang nilai yang lebih besar padahal tidak selalu berarti fitur tersebut lebih penting. Scaling membantu memastikan bahwa semua fitur memiliki kontribusi yang seimbang dalam proses training model machine learning.
Salah satu alasan mengapa scaling ini penting karena algoritma seperti K-Nearest Neighbors (KNN), K-Means clustering, dan Support Vector Machines (SVM) menggunakan jarak seperti Euclidean atau Minkowski untuk membuat sebuah pola. Fitur yang memiliki skala lebih besar akan mendominasi pengukuran jarak dan dapat mengaburkan informasi dari fitur yang lebih kecil skalanya.
Secara umum terdapat dua teknik yang dapat Anda gunakan untuk mengubah skala data agar konsisten yaitu normalisasi dan standardisasi. Perhatikan perbedaan pada gambar berikut.
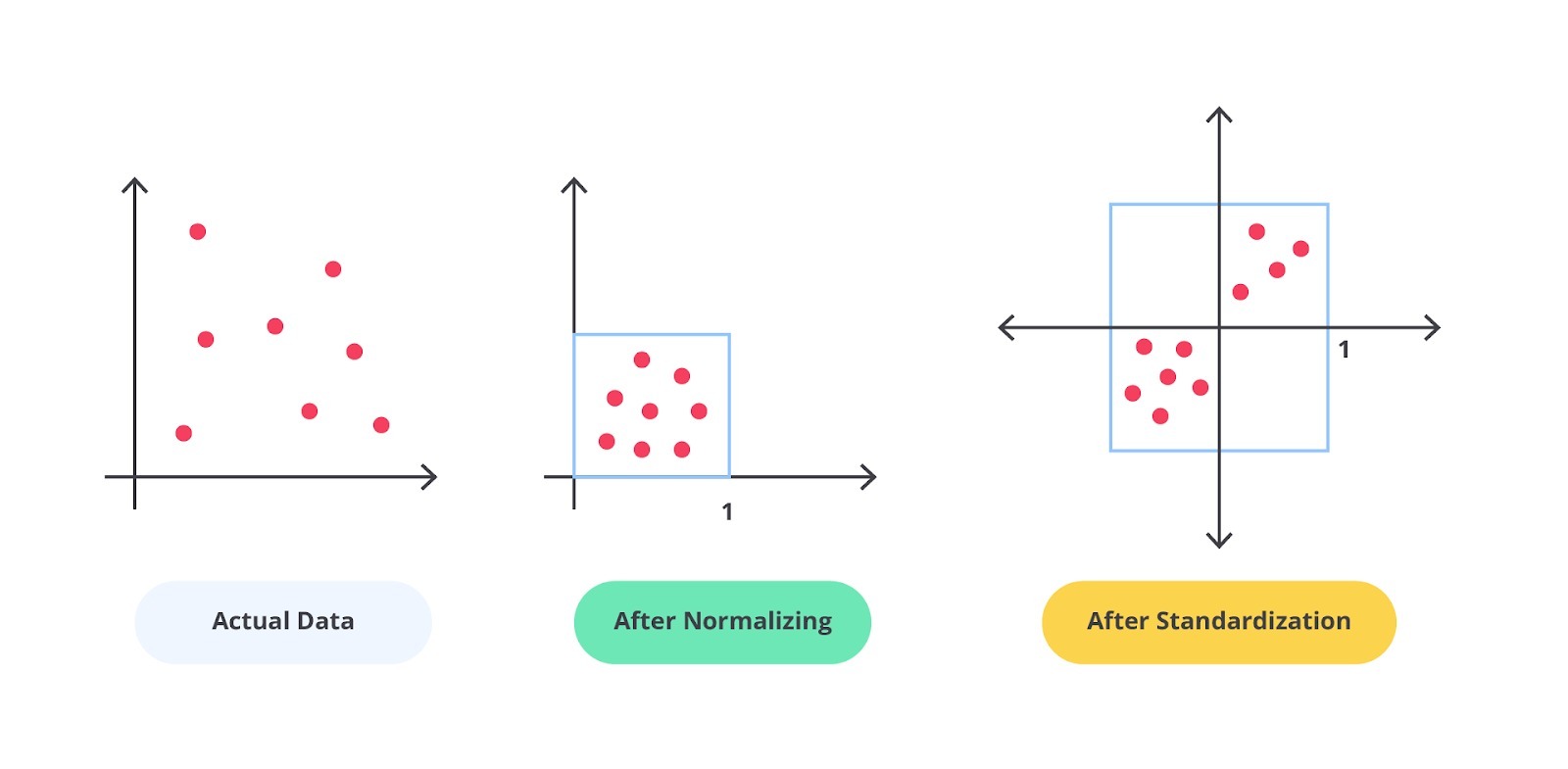
Terlihat jelas perbedaannya ‘kan? Sederhananya, normalisasi merupakan proses pengubahan skala data dari rentang asli sehingga semua nilai berada dalam rentang 0 dan 1. Di lain sisi, standardisasi data melibatkan pengubahan skala distribusi nilai sehingga rata-rata nilai yang dianalisis adalah 0 dan memiliki nilai standar deviasi sebesar satu.
Mari kita implementasikan kedua teknik scaling ini agar Anda lebih terbayang perbedaannya menggunakan kode berikut.
- from sklearn.preprocessing import MinMaxScaler, StandardScaler
- # Contoh data
- data = [[10], [2], [30], [40], [50]]
- # Min-Max Scaling
- min_max_scaler = MinMaxScaler()
- scaled_min_max = min_max_scaler.fit_transform(data)
- print("Min-Max Scaling:\n", scaled_min_max)
- # Standardization
- standard_scaler = StandardScaler()
- scaled_standard = standard_scaler.fit_transform(data)
- print("\nStandardization:\n", scaled_standard)
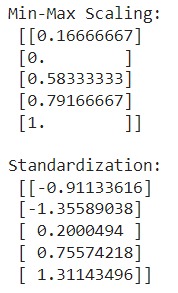
Seperti yang dapat Anda lihat, data dummy yang digunakan memiliki skala yang berbeda tergantung dengan teknik scaling yang digunakan. Mudah ‘kan? Good job!
Pada kelas ini, Anda hanya akan memahami kedua metode ini sampai di sini. Jika Anda penasaran terkait perhitungan matematis dan penjelasan yang lebih detail, silakan lanjutkan pembelajaran di kelas Belajar Fundamental Deep Learning, ya.
Penanganan Outlier
Selain konversi data kategorik menjadi numerik, ada teknik lain dalam proses pengembangan machine learning yang perlu Anda ketahui yaitu penanganan outlier. Dalam statistik, outlier adalah sebuah nilai yang jauh berbeda dari kumpulan nilai lainnya dan dapat mengacaukan hasil dari sebuah analisis statistik. Outlier dapat disebabkan oleh kesalahan dalam pengumpulan data atau nilai tersebut benar ada dan memang unik dari kumpulan nilai lainnya.
Apa pun alasan kemunculannya, Anda perlu tahu cara mengidentifikasi dan memproses outlier. Ini adalah bagian penting dalam persiapan data di dalam machine learning. Salah satu cara termudah untuk mengecek apakah terdapat outlier dalam data kita adalah dengan melakukan visualisasi.

Dapat dilihat dengan jelas bahwa terdapat satu sampel yang jauh berbeda dengan sampel-sampel lainnya. Setelah mengetahui bahwa di data kita terdapat outlier, kita dapat mencari lalu menghapus sampel tersebut dari dataset.
Dengan munculnya permasalahan ini, penanganan outlier merupakan langkah penting yang perlu Anda lakukan dalam proses pengembangan machine learning. Outlier dapat secara signifikan memengaruhi performa model machine learning karena mereka dapat menyebabkan model overfitting atau mengacaukan proses analisis. Oleh karena itu, memahami cara mendeteksi dan menangani outlier adalah kunci untuk menghasilkan model yang lebih akurat dan robust.
Misalnya, jika sebagian besar nilai penghasilan dalam dataset berada di kisaran Rp5.000.000 hingga Rp10.000.000, tetapi ada beberapa individu yang memiliki penghasilan di atas Rp100.000.000, nilai tersebut bisa dianggap sebagai outlier. Lalu, bagaimana cara mengatasi permasalahan tersebut? Terdapat beberapa metode yang dapat Anda lakukan untuk mendeteksi outlier seperti metode statistik dan visualisasi data.
- Metode Statistik
Metode statistik sederhana dapat digunakan untuk mendeteksi outlier dalam dataset univariat. Ini melibatkan identifikasi titik-titik data yang berada jauh dari distribusi utama. Salah satu perhitungan statistik yang dapat Anda gunakan adalah perhitungan interquartile range (IQR).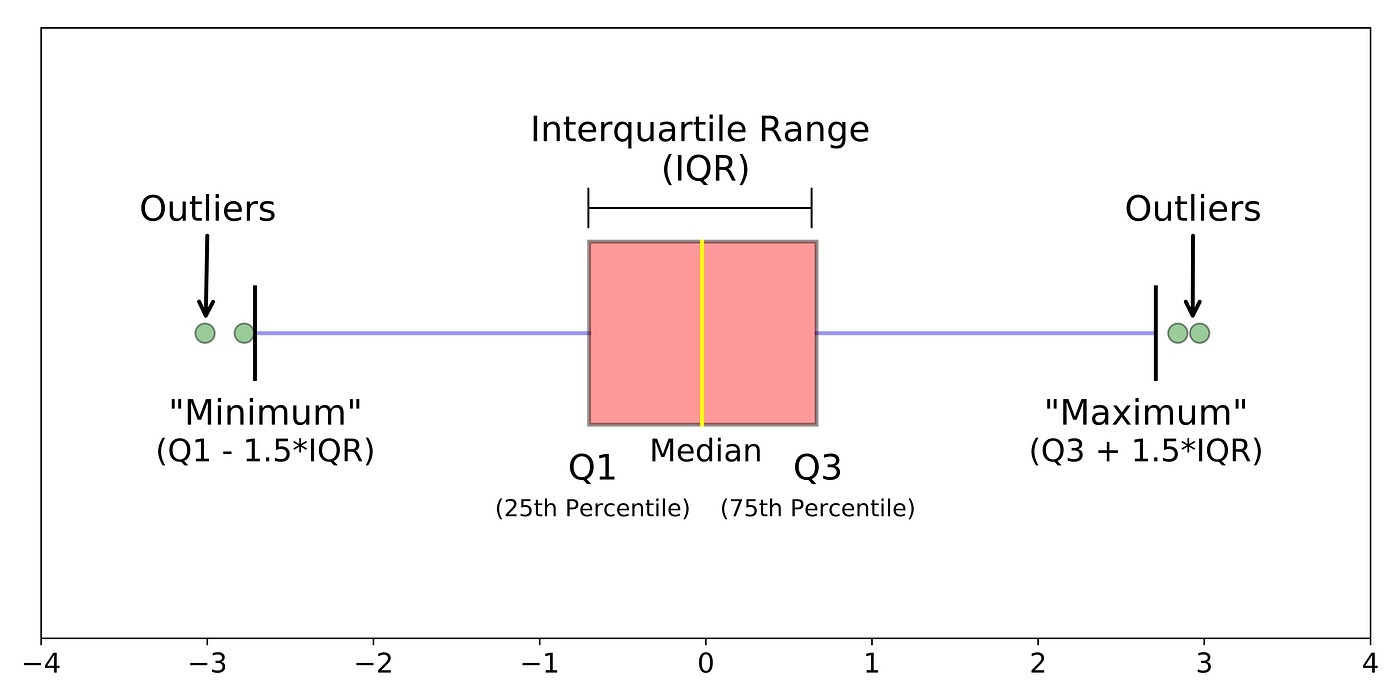
IQR digunakan untuk mendeteksi outlier dengan menghitung rentang antara kuartil pertama (Q1) dan kuartil ketiga (Q3). Nilai di luar batas ini dianggap sebagai outlier. Contohnya ketika Anda memiliki data Q1 = 25 dan Q3 = 75, nilai batas outliernya akan seperti berikut.- IQR = 75 - 25 = 50.
- Batas bawah = 25 - 1.5 * 50 = -50.
- Batas atas = 75 + 1.5 * 50 = 150.
Setiap nilai di luar -50 dan 150 adalah outlier. Seru kan belajar matematika? Tahan dahulu semangat Anda karena perhitungan lebih dalamnya akan Anda pelajari pada kelas Machine Learning Terapan. Sampai di sini, mungkin Anda perlu meningkatkan pengetahuan dasar lainnya terlebih dahulu.
- Visualisasi Data
Visualisasi data adalah cara efektif untuk mendeteksi outlier secara manual. Anda dapat dengan mudah mendeteksi outlier dengan menggunakan visualisasi data seperti Boxplot, Scatterplot, Histogram, dan lain sebagainya.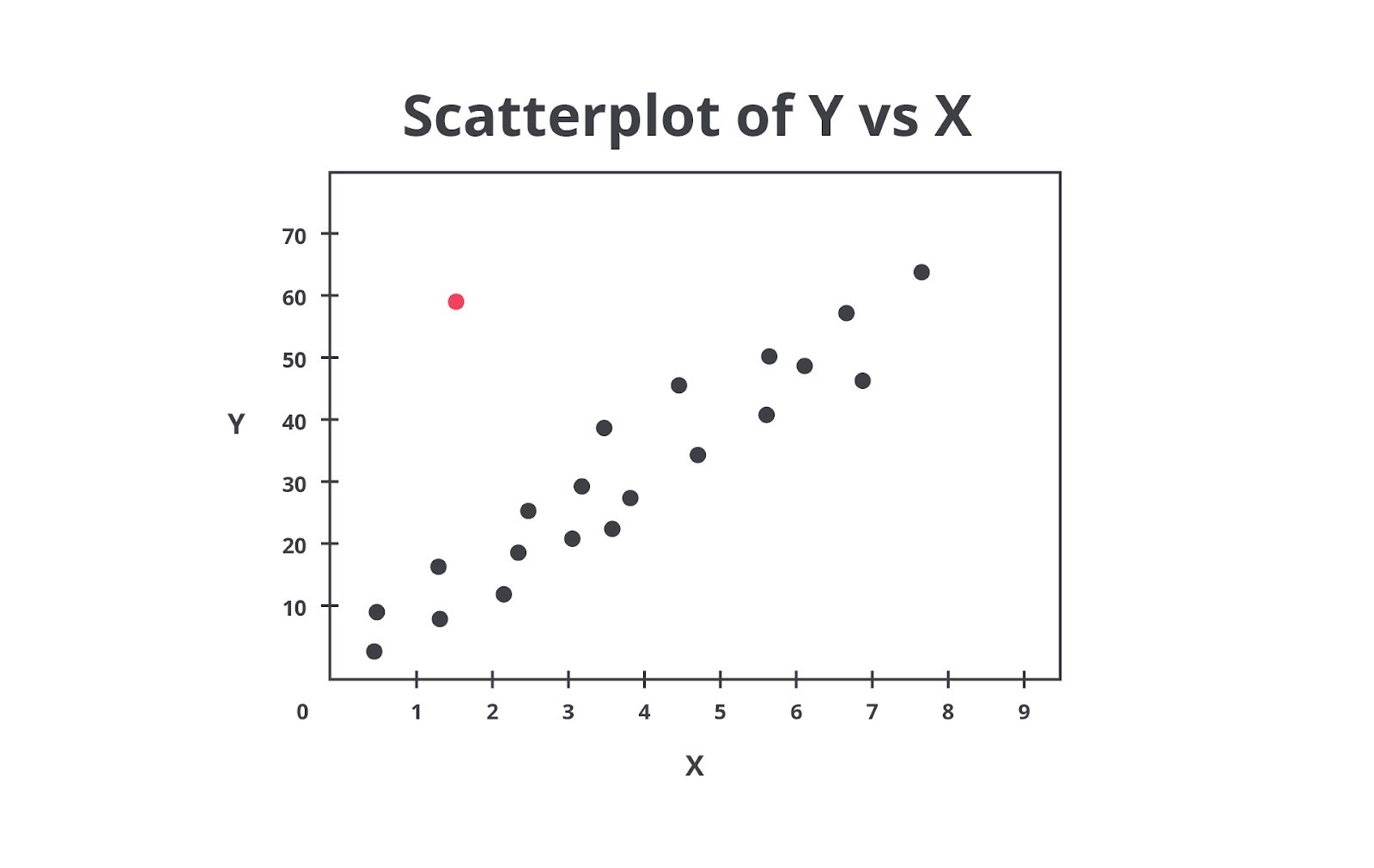
Setelah outlier terdeteksi, ada beberapa cara untuk menanganinya, tergantung pada sifat outlier dan tujuan analisis. Tanpa berlama-lama, mari kita bahas satu per satu beberapa cara yang biasanya digunakan untuk mengatasi outlier.
- Menghapus Outlier
Salah satu metode paling umum yaitu menghapus outlier dari dataset. Ini bisa dilakukan jika Anda yakin bahwa outlier tersebut dihasilkan dari kesalahan pengukuran atau jika outlier tersebut tidak relevan dengan analisis yang sedang dilakukan. Namun, menghapus outlier harus dilakukan dengan hati-hati. Menghapus terlalu banyak data dapat mengurangi ukuran dataset dan menyebabkan hilangnya informasi penting. - Transformasi Data
Kadang-kadang, Anda juga bisa mengatasi outlier dengan melakukan transformasi data. Transformasi ini bisa mengurangi pengaruh outlier tanpa harus menghapusnya. Namun, metode ini bukanlah metode terbaik karena dengan mengubah skala data hanya akan memperkecil nilainya saja dan tetap menjadi outlier. - Capping
Capping adalah metode di mana nilai outlier dibatasi ke nilai maksimum atau minimum tertentu (seperti pada perhitungan IQR sebelumnya). Biasanya, dari pada menghapus data, nilai yang melampaui batas akan diubah menjadi nilai Q1 atau Q3. - Imputasi
Pilihan lain daripada menghapus atau mengubah outlier, Anda bisa melakukan imputasi atau menggantinya dengan nilai yang lebih wajar, seperti mean, median, atau mode dari data lainnya. - Model-Based Approach
Beberapa model machine learning mampu menangani outlier secara inheren salah satu contohnya adalah algoritma Random Forest. Algoritma random forest lebih tahan terhadap outlier karena hanya memperhitungkan pemisahan data berdasarkan aturan split dan tidak terpengaruh oleh nilai yang memiliki karakteristik berbeda.
Penanganan outlier perlu dilakukan dengan hati-hati karena setiap metode yang dipilih akan memengaruhi performa model yang Anda buat. Hal ini tergantung pada konteks data dan tujuan analisis. Berikut adalah beberapa poin penting yang perlu Anda pertimbangkan ketika menangani outlier.
- Kapan tidak menghapus outlier: jika outlier memiliki peran penting misalnya seperti fraud detection atau deteksi anomali, mereka sebaiknya tidak dihapus. Outlier bisa menjadi poin data yang memberikan informasi berharga karena sejatinya data yang ada di lapangan memiliki karakteristik tersebut.
- Data domain: sebelum memutuskan bagaimana menangani outlier, sangat penting untuk memahami konteks domain data. Misalnya, dalam data keuangan, outlier bisa menjadi hal normal karena adanya individu dengan penghasilan yang sangat tinggi.
- Model yang digunakan: beberapa model tidak terpengaruh oleh outlier, seperti decision tree atau random forest sehingga dalam kasus seperti ini, penanganan outlier mungkin tidak diperlukan.
Sampai di sini, Anda perlu berlatih sebanyak mungkin untuk mendapatkan intuisi serta pengalaman dari masing-masing metode penanganan yang Anda gunakan. Semakin banyak berlatih, maka Anda semakin andal untuk memilih metode penanganan terbaik. Psstt, untuk materi lebih lengkap mengenai penanganan outlier, silakan lanjutkan pembelajaran pada kelas Belajar Fundamental Deep Learning. Sampai jumpa di level berikutnya, sayonara!
Oversampling dan Undersampling
Hi calon engineer masa depan!
Tak terasa Anda sudah melalui perjalanan yang cukup panjang pada modul ini, kami harap Anda masih memiliki semangat yang membara dan menyala sampai titik ini. Karena materi kali ini kita akan membahas suatu permasalahan yang seringkali terjadi ketika Anda membangun model machine learning.
Sampai pada modul ini, mungkin Anda telah melakukan beberapa latihan mandiri untuk membangun model machine learning yang ada pada modul-modul sebelumnya. Anda juga telah bersahabat dengan open source dataset seperti Kaggle, UCI, dan lain sebagainya. Namun, apakah Anda pernah menemukan sebuah dataset yang memiliki proporsi tidak seimbang seperti berikut?
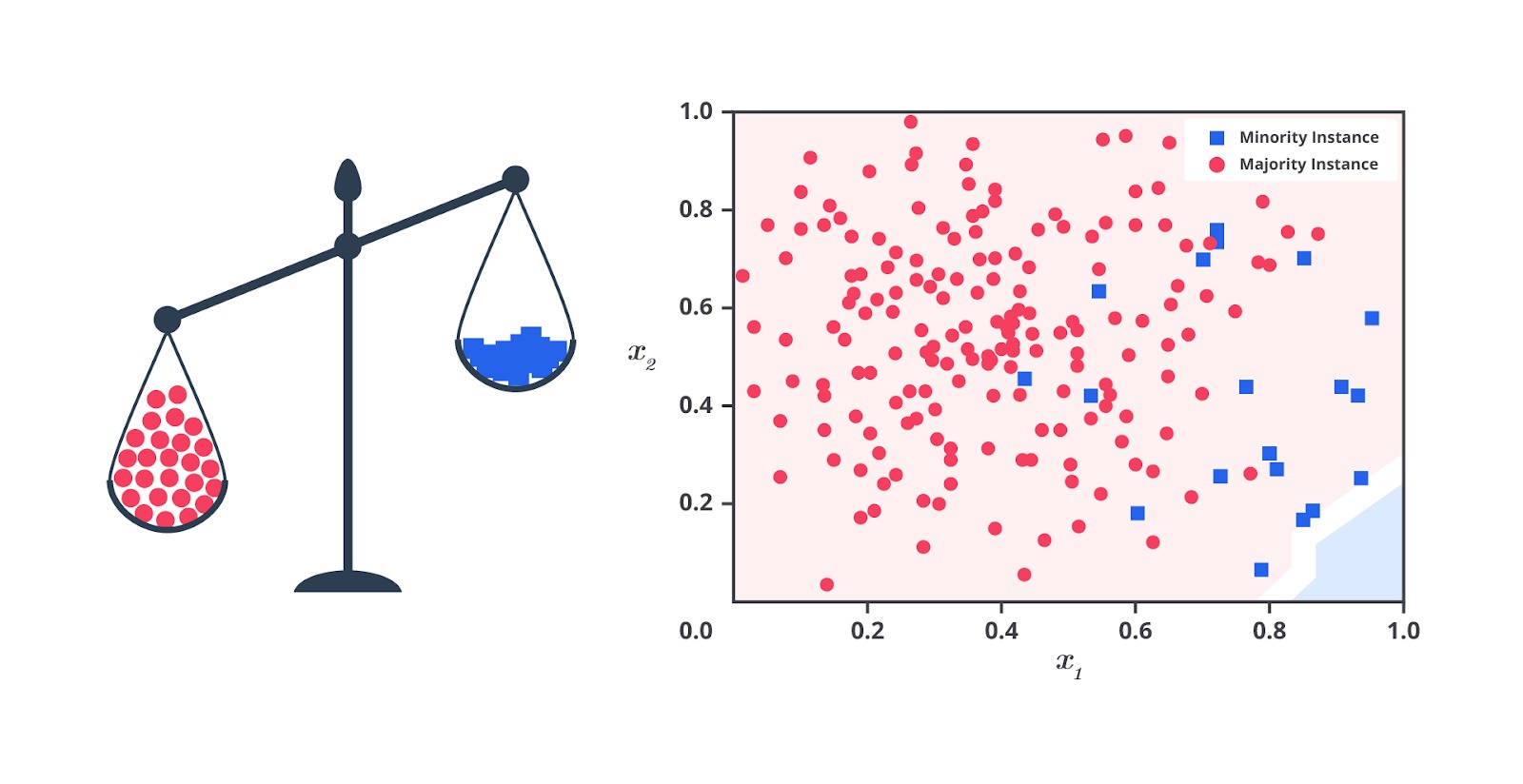
Permasalahan tersebut sangat wajar dan seringkali terjadi ketika Anda menggunakan data publik atau lebih parah ketika melakukan scraping secara mandiri karena dataset tersebut tidak sesuai dengan ekspektasi. Dataset yang memiliki masalah seperti ini biasanya disebut dengan imbalance dataset.
Imbalanced Dataset adalah situasi ketika jumlah data pada satu kelas jauh lebih sedikit atau lebih banyak dibandingkan dengan kelas lainnya. Ini sering terjadi dalam masalah klasifikasi, khususnya dalam binary classification (klasifikasi dua kelas) ketika satu kelas (sering disebut minoritas) memiliki jauh lebih sedikit sampel dibandingkan kelas lainnya (disebut mayoritas). Namun, masalah ini juga tidak menutup kemungkinan terjadi pada masalah klasifikasi lebih dari dua kelas atau multi kelas, ya.
Ketika dataset tidak seimbang, algoritma machine learning cenderung lebih baik dalam memprediksi kelas mayoritas dan mengabaikan atau salah mengklasifikasikan kelas minoritas. Ini terjadi karena sebagian besar algoritma secara alami berusaha memaksimalkan akurasi yang mungkin bukan metrik yang tepat untuk dataset yang tidak seimbang.
Misalnya, jika 95% dari data termasuk dalam kelas mayoritas dan hanya 5% dalam kelas minoritas, model yang selalu memprediksi kelas mayoritas dapat mencapai akurasi 95% tanpa pernah memprediksi kelas minoritas dengan benar.
Google secara resmi memberikan tiga buah level untuk kondisi imbalance yang berbeda-beda dihitung dari proporsi ketidakseimbangannya.

Pada situsnya, Google memberikan saran untuk tetap melakukan pembangunan model machine learning pada dataset yang tidak seimbang. Hal ini dibutuhkan agar Anda memiliki baseline model sehingga dapat membandingkan hasil dari dataset yang imbalance dengan eksperimen kedepannya. Setelah itu, Anda perlu mencoba beberapa teknik untuk mengatasi permasalahan imbalance dataset seperti oversampling atau undersampling.
Oversampling
Oversampling adalah metode yang menambahkan sampel pada kelas minoritas sehingga jumlahnya menjadi seimbang dengan kelas mayoritas. Teknik ini bekerja dengan cara memperbanyak data dari kelas minoritas agar model memiliki kesempatan yang lebih baik untuk belajar dari data tersebut.
Terdapat berbagai macam teknik oversampling yang dapat Anda gunakan seperti Random Oversampling atau Synthetic Minority Over-sampling Technique (SMOTE). Mari kita bahas perbedaan dari kedua metode yang sering digunakan untuk melakukan oversampling.
- Random Oversampling
Dalam teknik ini, data dari kelas minoritas secara acak di-duplicate atau digandakan hingga jumlahnya seimbang dengan kelas mayoritas. Ini adalah teknik sederhana dan sering kali efektif. Contohnya jika Anda memiliki 100 data pada kelas mayoritas dan 10 data pada kelas minoritas, random oversampling akan memilih beberapa sampel dari kelas minoritas dan menambahkannya ke dataset hingga kelas minoritas juga memiliki 100 sampel.Metode ini sangat mudah digunakan dan tidak memerlukan komputasi yang terlalu besar, tetapi perlu Anda ingat metode ini juga memiliki kekurangan yaitu dapat menyebabkan overfitting karena sampel yang sama di-duplicate berkali-kali, membuat model terlalu "mengingat" data daripada belajar dari pola yang sebenarnya. - Synthetic Minority Over-sampling Technique (SMOTE)
SMOTE adalah teknik oversampling yang lebih canggih dan kompleks, di mana data sintetis (baru) dibuat untuk kelas minoritas daripada hanya menduplikasi sampel yang ada. Teknik ini menghasilkan sampel baru dengan melakukan interpolasi antara dua data minoritas yang ada untuk membuat data yang baru. SMOTE akan membantu mengatasi masalah overfitting yang umum pada random oversampling.
Contohnya, jika Anda memiliki dua titik data minoritas di suatu ruang fitur, SMOTE akan menghasilkan sampel baru yang berada di antara kedua titik tersebut sehingga menciptakan variasi baru.
Undersampling
Berbanding terbalik dengan oversampling, undersampling adalah metode yang mengurangi jumlah sampel dari kelas mayoritas agar sesuai dengan jumlah sampel di kelas minoritas. Teknik ini bekerja dengan menghapus sebagian data dari kelas mayoritas untuk menciptakan keseimbangan antara kelas-kelas.
Sama halnya dengan oversampling, metode ini juga memiliki beberapa teknik yang biasanya digunakan ketika Anda ingin mengatasi permasalahan imbalance dataset dengan cara mengurangi data mayoritas seperti random undersampling atau cluster centroids.
- Random Undersampling
Random undersampling adalah metode sederhana yang menghapus sejumlah sampel dari kelas mayoritas secara acak hingga jumlahnya seimbang dengan kelas minoritas. Contohnya, jika Anda memiliki 100 sampel pada kelas mayoritas dan hanya 10 sampel pada kelas minoritas, random undersampling akan menghapus 90 sampel dari kelas mayoritas sehingga kedua kelas memiliki jumlah yang seimbang.Metode ini memiliki kekurangan karena berpotensi menghilangkan informasi penting dari kelas mayoritas karena menghapus data yang relevan. Selain itu, metode ini dapat menyebabkan underfitting jika terlalu banyak data mayoritas dihapus sehingga model kehilangan kemampuan untuk memahami pola dalam kelas mayoritas. - Cluster Centroids
Cluster centroids adalah teknik undersampling yang lebih kompleks. Alih-alih secara acak menghapus sampel dari kelas mayoritas, teknik ini menggunakan algoritma clustering (seperti K-Means) untuk mengelompokkan data mayoritas, lalu memilih centroid dari setiap cluster sebagai representasi dari kelas mayoritas.
Konsep yang digunakan oleh cluster centroids ini sama halnya dengan metode clustering yang telah Anda pelajari sebelumnya pada materi Unsupervised Learning - Clustering. Namun, tujuan dari pengelompokkan ini untuk mengurangi dataset dengan memilih anggota terdekat dengan centroids.
Dengan menggunakan metode ini, dataset akan mempertahankan representasi data mayoritas dengan lebih baik daripada random undersampling karena tidak sepenuhnya menghapus sampel, tetapi memilih representasi yang lebih penting dan serupa dengan centroids.
Bagai belati bermata dua, metode ini juga memiliki kekurangan yang perlu Anda ketahui. Pertama, metode ini lebih kompleks dan membutuhkan lebih banyak komputasi dibandingkan random undersampling. Kedua, jika data mayoritas memiliki pola yang sangat beragam, teknik ini mungkin tidak selalu mencerminkan keanekaragaman pola tersebut dengan baik (bias sampling).
Sampai di sini, Anda sudah mengetahui metode penanganan ketika menghadapi permasalahan imbalance dataset. Seperti yang Anda sudah pelajari, imbalanced dataset merupakan masalah umum dalam machine learning yang dapat mengakibatkan model yang bias terhadap kelas mayoritas.
Teknik-teknik seperti oversampling dan undersampling adalah solusi umum untuk menangani ketidakseimbangan ini, dengan oversampling menambah sampel di kelas minoritas dan undersampling mengurangi sampel dari kelas mayoritas. Selain itu, teknik seperti SMOTE, Random Undersampling, dan Cluster Centroids memberikan pendekatan yang lebih kompleks untuk menangani ketidakseimbangan ini. Pemilihan teknik yang tepat tergantung pada karakteristik data dan tujuan analisis.
Eitss, walaupun Anda sudah mengetahui berbagai metode untuk penanganan kasus imbalance dataset, tetapi kami tetap menyarankan untuk melakukan pengumpulan data agar data yang Anda gunakan sepenuhnya asli (terjadi di dunia nyata) dan bukan data sintetis. Namun, jika hal tersebut tidak memungkinkan, jangan sungkan untuk melakukan sampling, ya.

SMOTE (Synthetic Minority Over-Sampling Technique)
Hai, apakah Anda sudah menuntaskan materi Oversampling dan Undersampling dengan baik? Kereeenn, selanjutnya Anda akan mempelajari salah satu teknik yang biasa digunakan ketika menghadapi situasi imbalance dataset.
Seperti yang Anda tahu dalam situasi imbalanced dataset, model machine learning yang Anda buat cenderung bias terhadap kelas mayoritas karena kelas tersebut memiliki lebih banyak data untuk dipelajari. Jika kita menggunakan metode random oversampling, data minoritas hanya akan diduplikasi tanpa pola sehingga berisiko membuat model overfit. Overfit adalah kondisi model menjadi terlalu menyesuaikan dengan data yang ada sehingga kinerjanya buruk pada data yang belum pernah dilihat (data test).
Synthetic Minority Over-sampling Technique (SMOTE) adalah teknik oversampling yang dirancang untuk menangani masalah imbalanced dataset pada machine learning. Berbeda dengan random oversampling yang hanya menduplikasi sampel dari kelas minoritas, SMOTE menghasilkan sampel sintetis (baru) berdasarkan data yang sudah ada di kelas minoritas. Dari hal itu terciptalah variasi baru di dalam dataset dan mengurangi risiko overfitting yang mungkin terjadi jika kita hanya menduplikasi data secara acak.
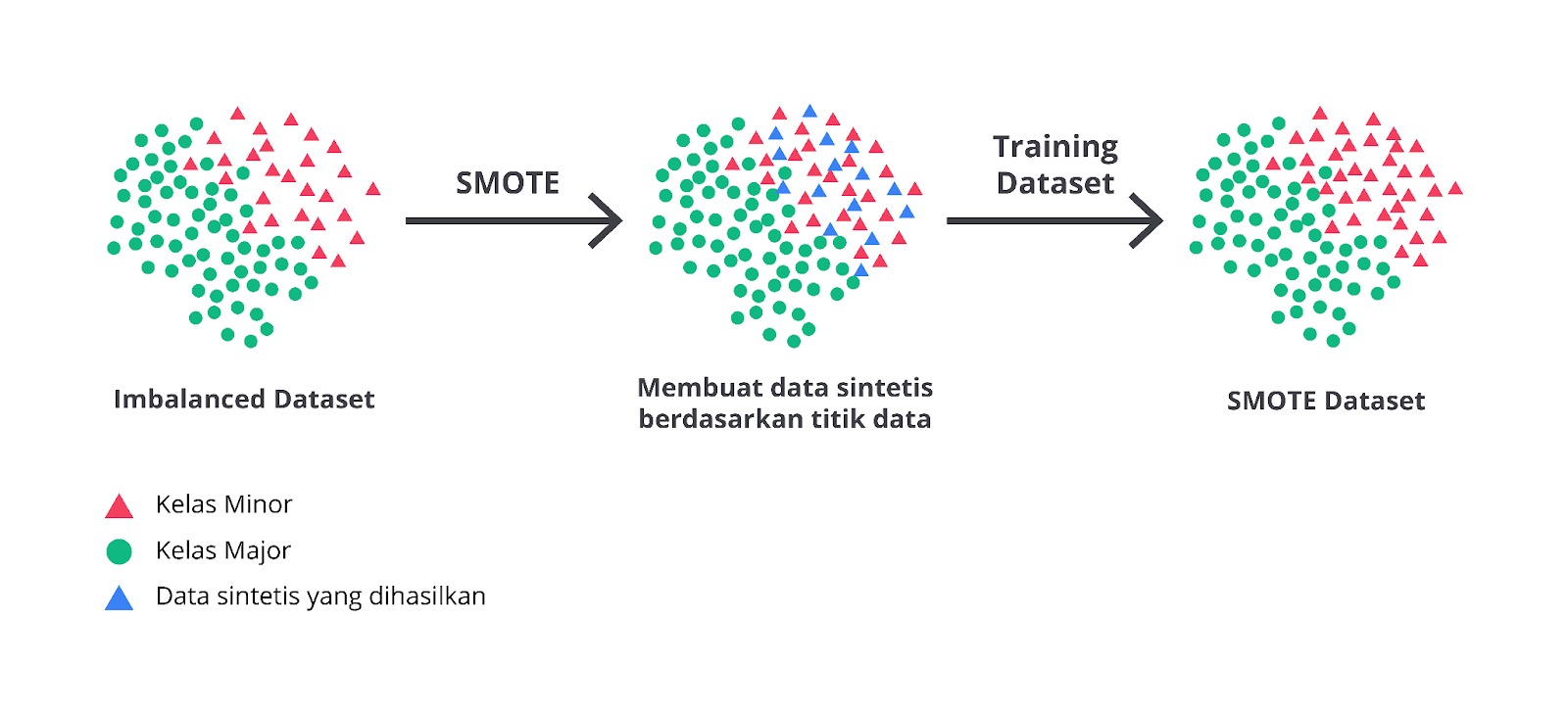
Sebenarnya metode SMOTE juga bekerja dengan cara yang tidak terlalu rumit. Secara umum, metode ini memiliki tiga buah langkah yang harus dilakukan hingga menghasilkan data yang seimbang.
- Ambil Sampel dari Kelas Minoritas: setiap sampel minoritas yang ada akan memilih beberapa tetangga terdekatnya. Biasanya, tahapan ini dihitung menggunakan K-Nearest Neighbors (KNN) atau K-Means.
- Interpolasi Data: buat sampel sintetis baru dengan melakukan interpolasi antara sampel minoritas dan tetangga terdekatnya. Interpolasi dilakukan dengan mengambil titik di sepanjang garis lurus yang menghubungkan dua data minoritas.
- Tambahkan Sampel Sintetis ke Dataset: sampel baru ini ditambahkan ke dataset, sehingga jumlah data di kelas minoritas bertambah hingga proporsional dengan kelas mayoritas.
Agar Anda lebih memahami proses yang terjadi pada teknik ini, mari kita lakukan perhitungan sederhana menggunakan teknik SMOTE. Bayangkan Anda memiliki dua titik dari kelas minoritas yaitu Titik_A = (2, 4) dan Titik_B = (4, 8). Dengan SMOTE, Anda dapat membuat titik sintetis baru di antara A dan B. Misalkan interpolasi dilakukan pada posisi 60% dari A ke B sehingga titik baru (sintetis) tersebut akan berada di nilai berikut.
Titiksintetis = A + 0.6 × (B−A)
= (2,4) + 0.6 × ((4,8) − (2,4))
= (2,4) + 0.6 × (2,4) = (3.2, 6.4)
Hasilnya, titik sintetis yang muncul berada di (3.2, 6.4). Agar lebih mudah memahaminya, perhatikan gambar berikut.
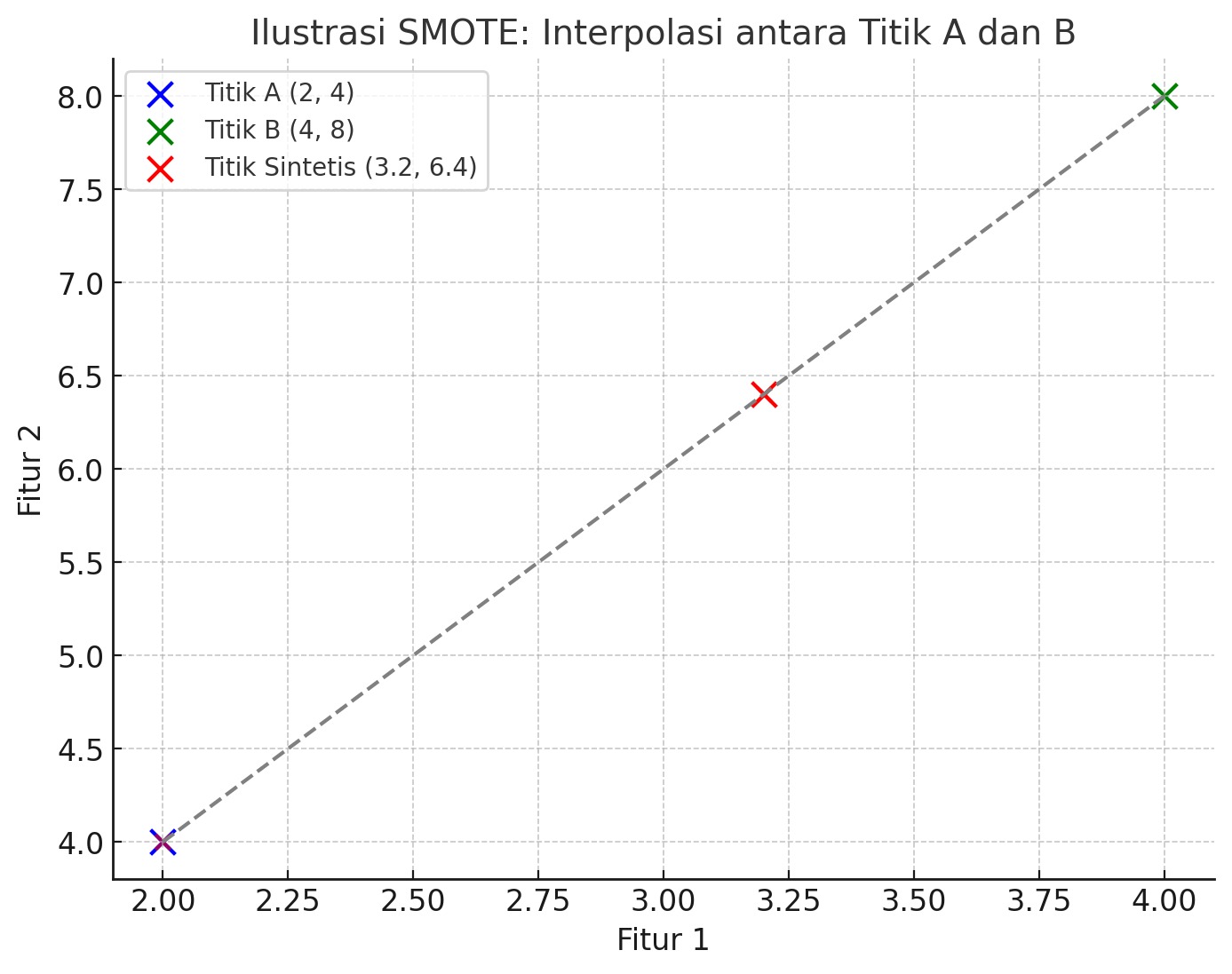
Cukup jelas kan perhitungan yang dilakukan? Memang sangat mudah kok. Bersamaan dengan kemudahan ini terdapat beberapa kelebihan dan kekurangan yang membayang-bayangi teknik ini.
Kelebihan utama SMOTE adalah kemampuannya untuk mengurangi overfitting yang sering terjadi pada random oversampling. Dengan menciptakan data sintetis melalui interpolasi antara titik-titik minoritas, model machine learning dapat mempelajari lebih banyak pola yang relevan. Selain itu, SMOTE sangat cocok untuk data yang memiliki banyak fitur (high-dimensional data) karena interpolasi dilakukan dalam ruang fitur yang lebih kompleks. Hal tersebut dapat menciptakan sampel sintetis yang lebih representatif jika dibandingkan dengan random oversampling.
Tak hanya kelebihan, SMOTE juga memiliki beberapa kekurangan yang perlu Anda ketahui. Salah satu masalah utamanya adalah risiko menciptakan sampel sintetis yang tidak realistis, terutama jika interpolasi dilakukan antara titik-titik yang berbeda secara signifikan. Hal ini dapat menyebabkan model mempelajari pola yang tidak akurat.
Selain itu, SMOTE tidak dapat menangani outlier dengan baik. Jika titik data minoritas yang digunakan dalam interpolasi adalah outlier, data sintetis yang dihasilkan bisa menjadi tidak relevan.
Proses interpolasi SMOTE juga memerlukan perhitungan tambahan seperti mencari data terdekat yang bisa meningkatkan waktu komputasi terutama pada dataset yang besar.
Dengan berbagai macam kelebihan dan kekurangannya, teknik ini tetap menjadi salah satu yang paling populer untuk menangani permasalahan imbalance dataset. Nah, bagaimana dengan Anda? Apakah sudah puas? Bagus jika Anda belum puas. Teruslah belajar dan jangan mudah puas dengan perubahan yang sudah Anda lakukan karena akan selalu ada hal yang harus diperbaiki dan dikembangkan.
Sebagai materi penutup, selanjutnya Anda akan melakukan implementasi sebagai bentuk latihan dari materi yang sudah dikuasai sampai saat ini. Tentunya, akan ada berbagai macam rintangan yang akan Anda hadapi. Namun, tenang saja karena kami akan selalu menemani setiap perjalanan Anda sampai akhir. Jadi, jika ada yang ingin ditanyakan jangan sungkan untuk menggunakan forum diskusi, ya.
Latihan: Studi Kasus Feature Engineering
Selamat datang kembali! Akhirnya Anda sampai di penghujung materi modul Teknik Feature Engineering. Walaupun sudah memahami berbagai macam teori, Anda perlu melakukan berbagai macam praktik agar ilmu yang dimiliki dapat digunakan dengan sangat baik. Hal ini diharapkan dapat meningkatkan progress belajar dengan signifikan sehingga Anda memiliki kemampuan yang lebih baik dari pada sebelumnya.
Setelah sekian purnama Anda mencari ilmu terkait feature engineering, inilah saat yang tepat untuk berlatih membangun model machine learning yang lebih optimal.
Tidak seperti latihan-latihan yang telah Anda lalui di modul sebelumnya, pada modul ini, Anda akan berlatih menggunakan data dummy yang dihasilkan oleh fungsi make_classification(). Fungsi tersebut bertugas untuk menghasilkan data secara acak dengan karakteristik yang dapat disesuaikan.
Seperti biasa, untuk menunjang materi ini silakan import beberapa library berikut.
- impor pandas sebagai pd
- impor numpy sebagai np
- dari sklearn.datasets impor make_classification
- dari sklearn.model_selection impor train_test_split
- dari sklearn.feature_selection impor SelectKBest, f_classif
- dari sklearn.preprocessing impor OneHotEncoder, StandardScaler, KBinsDiscretizer
- dari sklearn.compose impor ColumnTransformer
- dari sklearn.pipeline impor Pipeline
- dari imblearn.over_sampling impor SMOTE
- dari koleksi impor Counter
- dari sklearn.ensemble impor RandomForestClassifier
Pada kasus ini, tulislah kode berikut untuk membuat dataset yang akan digunakan pada latihan.
- X, y = make_classification(n_samples=1000, n_features=15, n_informative=10, n_redundant=2,n_clusters_per_class=1, weights=[0.9], flip_y=0, random_state=42)
Alasan penggunaan fungsi tersebut agar Anda dapat mengenal kondisi dataset lainnya berbeda dari data yang sudah disediakan open data seperti Kaggle. Namun, Anda juga dapat melakukan latihan ini pada dataset yang berbeda jika ingin mendapatkan pengalaman yang lebih maksimal.
Setelah menjalankan kode di atas, Anda akan memiliki 1000 data dengan 15 fitur independen dan satu fitur dependen yang berbeda-beda. By default, fungsi ini akan membuat dua buah kelas yang berbeda, tetapi Anda juga bisa menentukan jumlah kelas dengan mengatur nilai n_classes, ya.
Karena pada akhir materi ini kita akan belajar mengenai salah satu metode oversampling, Anda perlu mengatur nilai weights (rasio) untuk membagi jumlah data pada masing-masing kelas. Pada kasus ini, kita akan membagi 90% data untuk kelas pertama, dan 10% data untuk kelas kedua.
Selanjutnya, Anda perlu mengubah nilai acak yang yang tersimpan dengan tipe data array menjadi DataFrame agar lebih mudah diolah dan dicerna oleh orang lain.
- # Menyusun dataset menjadi DataFrame untuk kemudahan
- df = pd.DataFrame(X, columns=[f'Fitur_{i}' for i in range(1, 16)])
- df['Target'] = y
- # Misalkan kita punya beberapa fitur kategorikal (simulasi fitur kategorikal)
- df['Fitur_12'] = np.random.choice(['A', 'B', 'C'], size=1000)
- df['Fitur_13'] = np.random.choice(['X', 'Y', 'Z'], size=1000)
- df
Kode di atas akan memetakan nilai acak yang dihasilkan oleh fungsi make_classification() ke DataFrame yang sudah dibangun sehingga akan menghasilkan dataset seperti berikut.
Selanjutnya, Anda perlu memisahkan fitur independen dan dependen untuk mempermudah proses feature engineering yang akan dilakukan.
- # Memisahkan fitur dan target
- X = df.drop('Target', axis=1)
- y = df['Target']
Saat ini, Anda sudah memiliki sebuah dataset yang siap untuk digunakan pada proses feature engineering. Untuk memastikan proporsi data yang ada, silakan cek menggunakan kode berikut.
- # Melihat distribusi kelas
- print("Distribusi kelas sebelum SMOTE:", Counter(y))

Karena dataset ini memiliki fitur yang cukup banyak, pilihlah fitur (feature selection). Anda dapat menggunakan berbagai macam teknik feature selection yang sebelumnya sudah dipelajari pada materi feature selection. Namun, pada latihan ini mari kita gunakan teknik embedded agar terbiasa dengan teknik yang paling kompleks.
- # ------------------- Embedded Methods -------------------
- # Menggunakan Random Forest untuk mendapatkan fitur penting
- rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
- X_integer = X.drop(['Fitur_12', 'Fitur_13'], axis=1)
- rf_model.fit(X_integer, y)
- # Mendapatkan fitur penting
- importances = rf_model.feature_importances_
- indices = np.argsort(importances)[::-1]
- # Menentukan ambang batas untuk fitur penting
- threshold = 0.05 # Misalnya, ambang batas 5%
- important_features_indices = [i for i in range(len(importances)) if importances[i] >= threshold]
- # Menampilkan fitur penting beserta nilainya
- print("Fitur yang dipilih dengan Embedded Methods (di atas ambang batas):")
- for i in important_features_indices:
- # Jika X asli berbentuk DataFrame, maka kita ambil nama kolom
- print(f"{X_integer.columns[i]}: {importances[i]}")
- # Mendapatkan nama kolom penting berdasarkan importance
- important_features = X_integer.columns[important_features_indices]
- # Memindahkan fitur penting ke variabel baru
- X_important = X_integer[important_features] # Hanya fitur penting dari data pelatihan
- # X_important sekarang berisi hanya fitur penting
- print("\nDimensi data pelatihan dengan fitur penting:", X_important.shape)
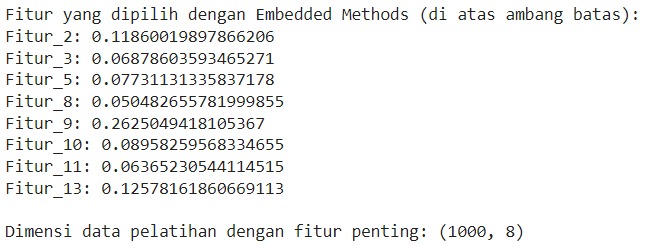
Kode di atas memiliki karakteristik yang sangat mirip dengan contoh kode pada materi feature selection. Di sini, kita menentukan ambang batas hubungan antara variabel sebesar 5% sehingga mendapatkan delapan fitur dengan tipe data numerik. Eiitts, jika Anda penasaran terkait penjelasan kode di atas secara lebih detail, silakan ulas kembali materi feature selection, ya.
Lalu, bagaimana dengan nasib data yang bertipe kategorikal? Tenang, kita tidak akan melupakan mereka. Setelah proses pemilihan fitur numerik dilakukan, Anda perlu menggabungkan data numerik dan kategorikal seperti semula.
- X_Selected = pd.concat([X_important, X['Fitur_12']], axis=1)
- X_Selected = pd.concat([X_Selected, X['Fitur_13']], axis=1)
- X_Selected
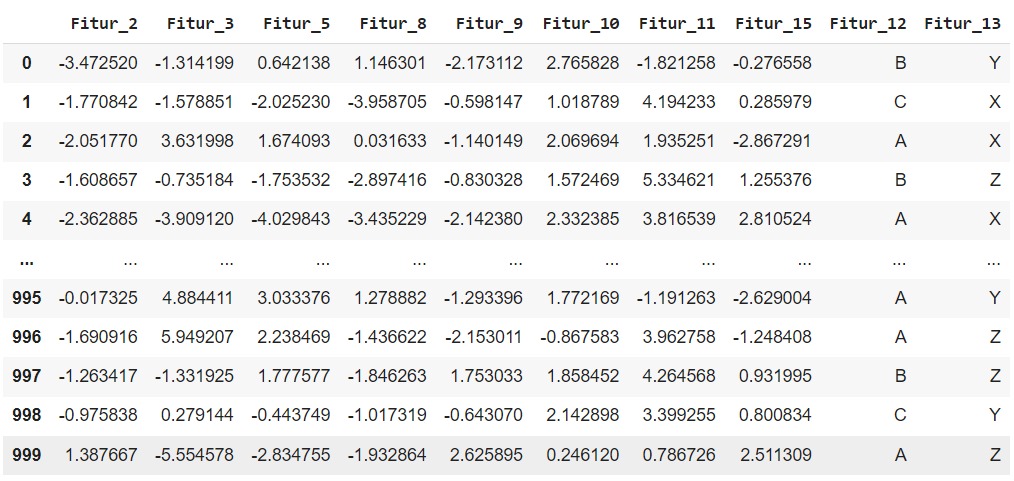
Waiit, apakah Anda menyadari keanehan dari output di atas? Yup, masih terdapat data kategorikal pada dataset di atas. Apakah itu sebuah masalah? Jelas itu sebuah masalah. karena seperti yang sudah Anda pelajari di awal kelas ini bahwa machine learning tidak menerima input berupa kategorikal atau string.
Untuk menyelesaikan permasalahan tersebut, Anda dapat melakukan encoding terhadap fitur dengan tipe data kategorikal. Pada latihan ini, mari kita gunakan Label Encoding karena berasumsi bahwa kategori yang ada memiliki urutan yang logis (hal ini karena kita menggunakan dummy dataset).
- from sklearn.preprocessing import LabelEncoder
- label_encoder = LabelEncoder()
- # Melakukan Encoding untuk fitur 12
- X_Selected['Fitur_12'] = label_encoder.fit_transform(X_Selected['Fitur_12'])
- # print(label_encoder.inverse_transform(X_Selected[['Fitur_12']]))
- # Melakukan Encoding untuk fitur 13
- X_Selected['Fitur_13'] = label_encoder.fit_transform(X_Selected['Fitur_13'])
- # print(label_encoder.inverse_transform(X_Selected[['Fitur_13']]))
- print(X_Selected)
Sampai di sini, semua fitur yang Anda miliki sudah bertipe integer atau numerik. Dengan kondisi seperti ini, dataset yang Anda gunakan sebenarnya sudah siap untuk dilatih. Namun, sebelum melatih dataset tersebut, alangkah baiknya Anda melakukan pengecekan outlier agar model yang dibangun memiliki performa optimal.
Agar lebih terbayang proses pembelajaran ini, salinlah terlebih dahulu dataset yang akan digunakan sebelum mengubahnya. Tujuannya agar Anda dapat membandingkan karakteristik sebelum dan sesudah menangani outlier. Pertama-tama, mari kita mulai dengan menyalin dataset dan menghapus Fitur_12 dan Fitur_13 yang merupakan data hasil encoding.
- import matplotlib.pyplot as plt
- import seaborn as sns
- import pandas as pd
- # Memilih kolom numerik
- numeric_columns = X_Selected.select_dtypes(include=['float64', 'int64']).columns
- numeric_columns = numeric_columns.drop(['Fitur_12', 'Fitur_13'])
- # Membuat salinan data untuk menjaga data asli tetap utuh
- X_cleaned = X_important.copy()
Selanjutnya, mari kita deteksi outlier dengan menggunakan visualisasi data BoxPlot. Dengan menggunakan visualisasi, Anda tidak perlu memberikan effort yang besar kepada otak (beban kognitif) karena pada dasarnya hanya dengan melihat visualisasi Anda sudah dapat mendeteksi outliers.
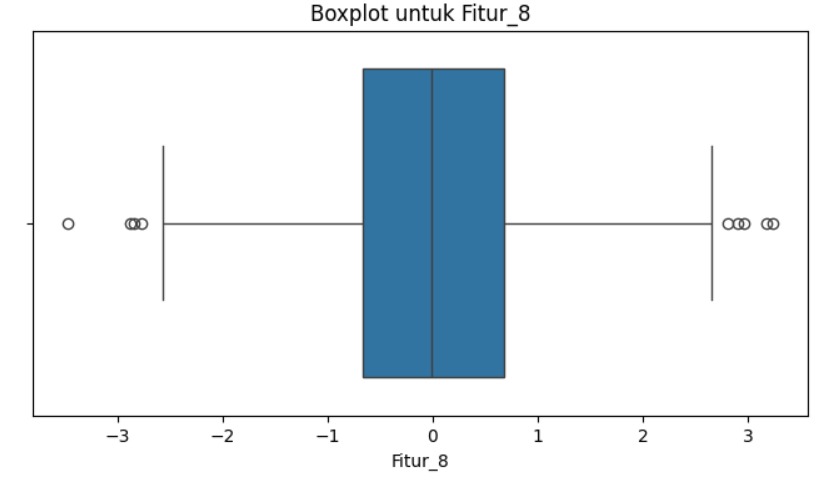
Seperti yang dapat dilihat pada visualisasi di atas, secara langsung dapat disimpulkan bahwa terdapat beberapa nilai outlier pada Fitur_8. Untuk melihat data lengkapnya, silakan ikuti dan jalankan kodenya secara mandiri karena output yang dihasilkan berupa gambar yang cukup besar.
Masih ingatkah Anda bagaimana cara mengatasi outlier pada materi sebelumnya? Benar, salah satu caranya adalah menggunakan teknik interquartile range (IQR). Teknik ini akan mencari nilai batas bawah dan batas atas sehingga Anda dapat menghapus nilai yang berada di luar jangkauan.
- for col in numeric_columns:
- # Melihat outlier dengan IQR (Interquartile Range)
- Q1 = X_important[col].quantile(0.25)
- Q3 = X_important[col].quantile(0.75)
- IQR = Q3 - Q1
- lower_bound = Q1 - 1.5 * IQR
- upper_bound = Q3 + 1.5 * IQR
- # Identifikasi outlier
- outliers = X_cleaned[(X_cleaned[col] < lower_bound) | (X_cleaned[col] > upper_bound)]
- # Menghapus outlier dari DataFrame
- X_cleaned = X_cleaned.drop(outliers.index)
- y = y.drop(outliers.index)
Dengan menghapus nilai outlier, Anda memiliki rentang data yang lebih baik dibandingkan dengan sebelum dihilangkan. Untuk memvalidasi perbedaan tersebut, mari kita visualisasikan sekali lagi kolom Fitur_8, lalu bandingkan dengan BoxPlot sebelum outlier dihapus.
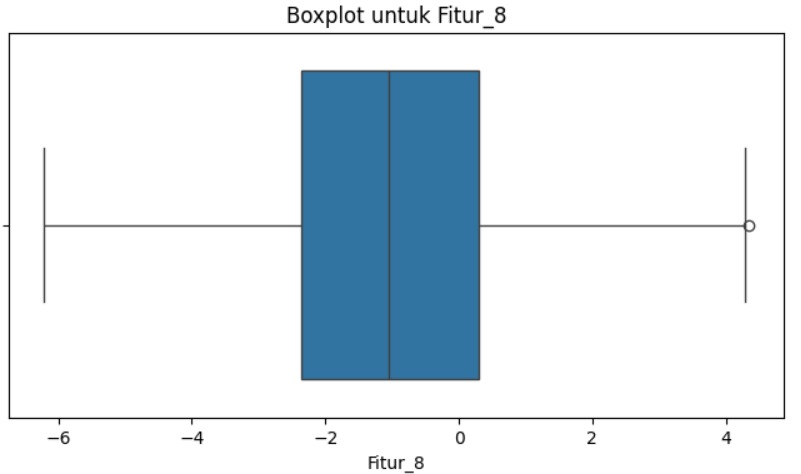
Dari gambar di atas, cukup menggambarkan perbedaannya ‘kan? Jika Anda masih belum yakin, mari kita lihat jumlah data setelah outlier dihilangkan menggunakan kode berikut.
- X_cleaned
Jumlah data yang Anda miliki sekarang berjumlah 949 data, jumlah ini mungkin akan berbeda dengan latihan mandiri yang dilakukan karena menggunakan fungsi yang menghasilkan data berbeda. Setidaknya, Anda sudah mengetahui bahwa kode sebelumnya dapat menghilangkan outlier yang ada pada dataset.
Setelah berhasil menghilangkan outlier, mungkin Anda merasa bahwa dataset sudah siap untuk dilatih. Eits, sampai di sini, Anda belum melihat distribusi data. Karena data yang kita gunakan merupakan hasil randomize dari fungsi make_classification(), distribusi data yang dihasilkan belum tentu baik. Selain itu, terdapat permasalahan yang sudah kita tentukan sejak awal pembuatan dataset ini yaitu imbalance dataset.
Seperti yang sudah Anda ketahui, kita sudah menentukan pembagian dataset pada pada kasus ini dengan proporsi 90-10, 90% untuk kelas pertama dan 10% untuk kelas kedua. Permasalahan ini perlu Anda selesaikan dengan melakukan oversampling atau undersampling sehingga dataset yang digunakan memiliki proporsi yang seimbang.
Pada kasus ini, kita akan menggunakan teknik SMOTE yang sebelumnya sudah Anda pelajari pada materi Synthetic Minority Oversampling Technique.
- # Inisialisasi SMOTE
- smote = SMOTE(random_state=42)
- # 3. Melakukan oversampling pada dataset
- X_resampled, y_resampled = smote.fit_resample(X_cleaned, y)
- # Menampilkan distribusi kelas setelah SMOTE
- print("Distribusi kelas setelah SMOTE:", Counter(y_resampled))
- # Mengubah hasil menjadi DataFrame untuk visualisasi atau analisis lebih lanjut
- X_resampled = pd.DataFrame(X_resampled)
- y_resampled = pd.Series(y_resampled, name='Target')

Seperti yang dapat Anda lihat, dataset yang digunakan sudah memiliki proporsi yang seimbang ditandai dengan kedua kelas memiliki jumlah yang sama yaitu 875 data. Selanjutnya, Anda perlu mengecek distribusi data dari kedua kelas tersebut agar dapat mengidentifikasi distribusi data dengan lebih baik.
Pada latihan kali ini, Anda dapat menggunakan kode berikut untuk membuat visualisasi distribusi data.
- # 1. Visualisasi distribusi data sebelum scaling menggunakan histogram
- plt.figure(figsize=(10, 6))
- for col in X_resampled.columns:
- sns.histplot(X_resampled[col], kde=True, label=col, bins=30, element='step')
- plt.title('Distribusi Data Sebelum Scaling (Histogram)')
- plt.legend()
- plt.show()
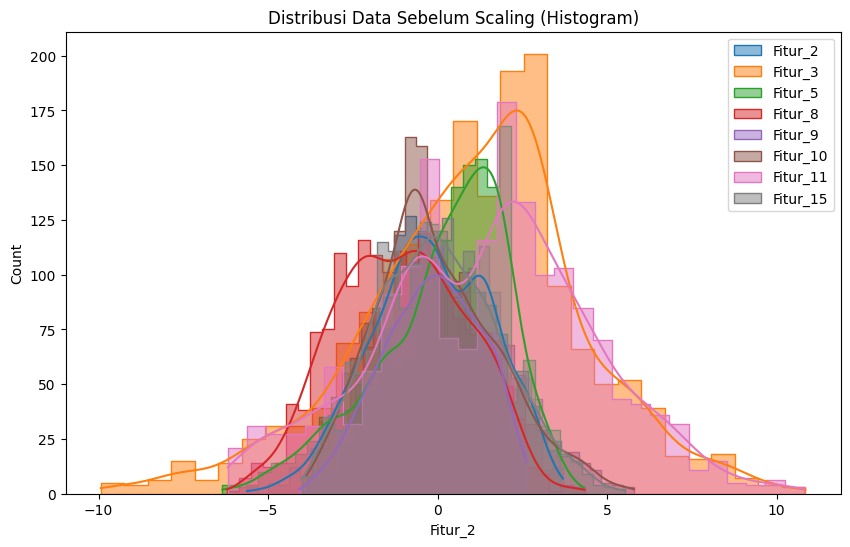
Ternyata distribusi data yang dihasilkan memiliki rentang yang berbeda-beda. Hal ini akan menjadi sebuah masalah karena masing-masing fitur memiliki skala yang berbeda juga. Untuk mengatasi permasalahan tersebut, Anda dapat menggunakan scaling fitur seperti normalisasi atau standardisasi agar distribusi data menjadi lebih baik. Pada kesempatan kali ini, kita akan menggunakan standardisasi agar skala data memiliki skala yang sama serta standar deviasi mendekati satu.
- # Scaling: Standarisasi fitur numerik menggunakan StandardScaler
- scaler = StandardScaler()
- # Melakukan scaling pada fitur penting
- X_resampled[important_features] = scaler.fit_transform(X_resampled[important_features])
Setelah Anda melakukan standardisasi seharusnya distribusi data menjadi lebih baik. Untuk melihat perbedaannya, mari kita buat sebuah visualisasi seperti sebelumnya agar dapat melakukan perbandingan.
- # 1. Visualisasi distribusi data setelah scaling menggunakan histogram
- plt.figure(figsize=(10, 6))
- untuk setiap kolom dalam X_resampled.columns:
- sns.histplot(X_resampled[col], kde=True, label=col, bins=30, element='step')
- plt.title('Distribusi Data Setelah Scaling (Histogram)')
- plt.legend()
- plt.show()
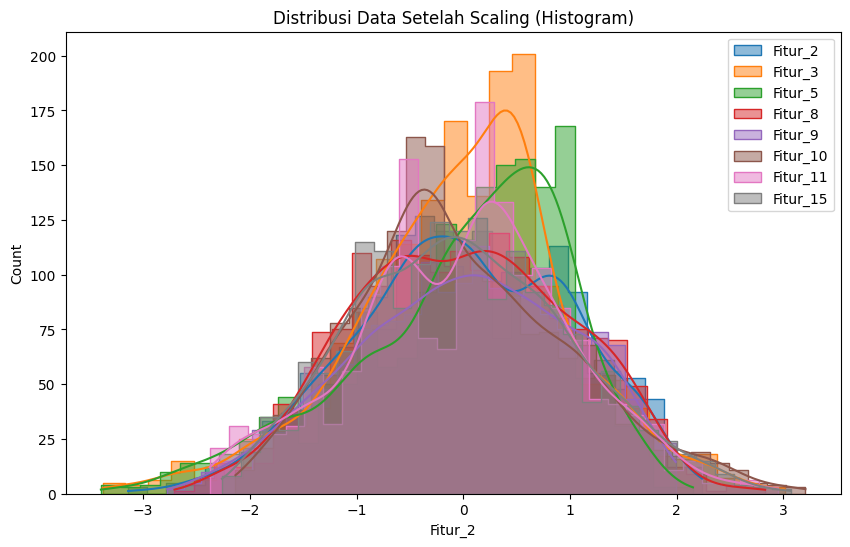
Sampai di sini sudah sangat terlihat ‘kan perbedaannya? Untuk memastikan kembali standardisasi dilakukan dengan baik, silakan Anda gunakan kode berikut untuk melihat karakteristik data dengan lebih detail.
- X_resampled.describe(include='all')
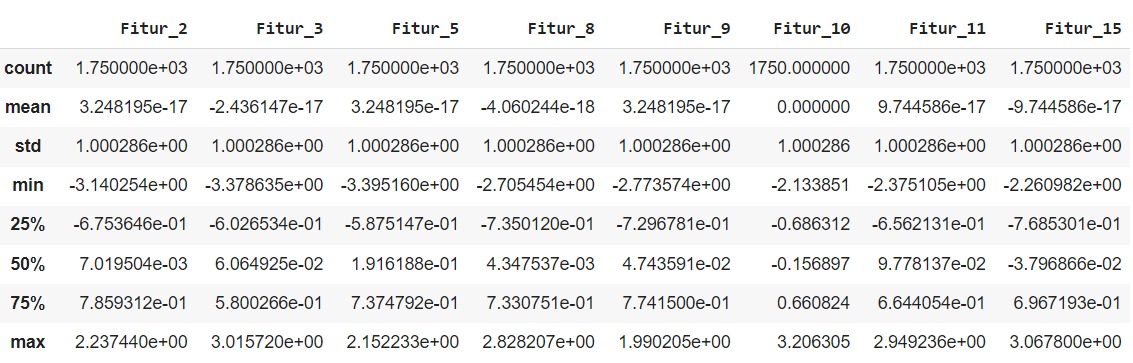
Seluruh fitur yang ada kini sudah memiliki rentang yang serupa dan memiliki standar deviasi mendekati satu. Hal ini berarti proses standardisasi yang Anda lakukan sudah berjalan dengan baik.
Pheew, perjalanan yang cukup panjang ‘kan? Sampai di titik ini, dataset yang Anda miliki sudah lebih siap untuk dilatih menggunakan berbagai macam algoritma klasifikasi. Sebagai penutupan, kami sangat menyarankan untuk terus berlatih menggunakan berbagai macam dataset yang ada di dunia ini. Hal tersebut berguna untuk meningkatkan intuisi sebagai seorang machine learning engineer sehingga kelak Anda dapat menghadapi berbagai macam rintangan yang ada ketika membangun model machine learning.
Tidak terasa saat ini kita sudah berada di penghujung modul feature engineering. Sungguh perjalanan yang luar biasa karena Anda sudah mempelajari berbagai macam metode yang dapat mengoptimalkan proses pembangunan model machine learning.
Proses pembelajaran merupakan kegiatan yang dilakukan seumur hidup. Walaupun Anda sudah menyelesaikan modul ini, bukan berarti semuanya telah berakhir. Pada modul berikutnya, Anda akan mempelajari metode lain untuk mengoptimalkan model machine learning yaitu mengatasi overfitting dan underfitting. Permasalahan tersebut sering kali terjadi ketika Anda tidak melakukan feature engineering dengan baik. Oleh karena itu, jangan sungkan untuk kembali melihat-lihat materi pada modul ini kelak, ya.
Selamat bersenang-senang di modul berikutnya. Sampai jumpa!
Rangkuman Teknik Feature Engineering
Pendahuluan Feature Engineering
Feature engineering adalah proses yang sangat penting dalam machine learning, di mana data mentah atau kotor diubah menjadi fitur-fitur yang dapat digunakan oleh model untuk melakukan prediksi. Proses ini melibatkan pemilihan, transformasi, dan penciptaan fitur-fitur yang relevan serta bermakna dari data yang tersedia. Tujuan utamanya adalah untuk memaksimalkan performa model dengan menyediakan input yang paling representatif dan informatif.
Dengan melakukan feature engineering Anda dapat menciptakan, mengubah, dan memilih fitur yang relevan sehingga dapat membantu model memahami pola dalam data dengan lebih baik, meningkatkan akurasi prediksi, dan memastikan bahwa model dapat digeneralisasikan dengan baik pada data baru. Meskipun banyak model modern memiliki kemampuan untuk mengekstraksi fitur secara otomatis, feature engineering tetap memberikan dampak yang signifikan terutama ketika pengetahuan domain dapat diterapkan dengan baik.
Dengan memproses dan mentransformasi data, Anda dapat mengurangi noise yang mungkin mengaburkan pola penting dan meningkatkan hubungan (korelasi) yang benar-benar berharga antara setiap variabel. Proses ini juga membantu menyesuaikan data dengan algoritma yang akan digunakan sehingga model dapat bekerja lebih optimal dengan data yang telah diolah.
Mengurangi risiko overfitting juga merupakan salah satu manfaat utama dari feature engineering. Dengan melakukan pemilihan fitur yang tepat dan eliminasi fitur yang tidak relevan, dapat mencegah model menjadi terlalu kompleks. Hal ini dapat membantu dalam mengoptimalkan kinerja model agar lebih efisien sehingga memungkinkan model mencapai performa yang sangat baik dengan fitur-fitur yang tepat tanpa memerlukan komputasi yang besar (efisiensi).
Teknik Pemilihan Fitur (Feature Selection)
Teknik Pemilihan Fitur (Feature Selection) adalah proses pemilihan subset fitur yang paling relevan atau penting untuk digunakan dalam model machine learning. Tujuannya adalah untuk meningkatkan performa model dengan menghilangkan fitur yang tidak relevan, redundan, atau kotor (biasa disebut noise). Dengan demikian, kita bisa mengurangi kompleksitas model, meningkatkan akurasi, dan mempercepat proses pelatihan.
Pemilihan fitur sangat penting karena model machine learning yang dilatih dengan fitur yang tidak relevan atau terlalu banyak fitur, memungkinkan untuk mengalami masalah seperti overfitting yaitu kondisi ketika model terlalu cocok dengan data pelatihan sehingga tidak dapat melakukan generalisasi dengan baik untuk data baru. Dengan melakukan feature selection, kita dapat menghasilkan model yang lebih simpel, cepat, dan efektif.
Encoding Variabel ke Numerik
Encoding dalam machine learning adalah proses mengonversi data non-numerik (kategorikal atau teks) menjadi bentuk numerik.
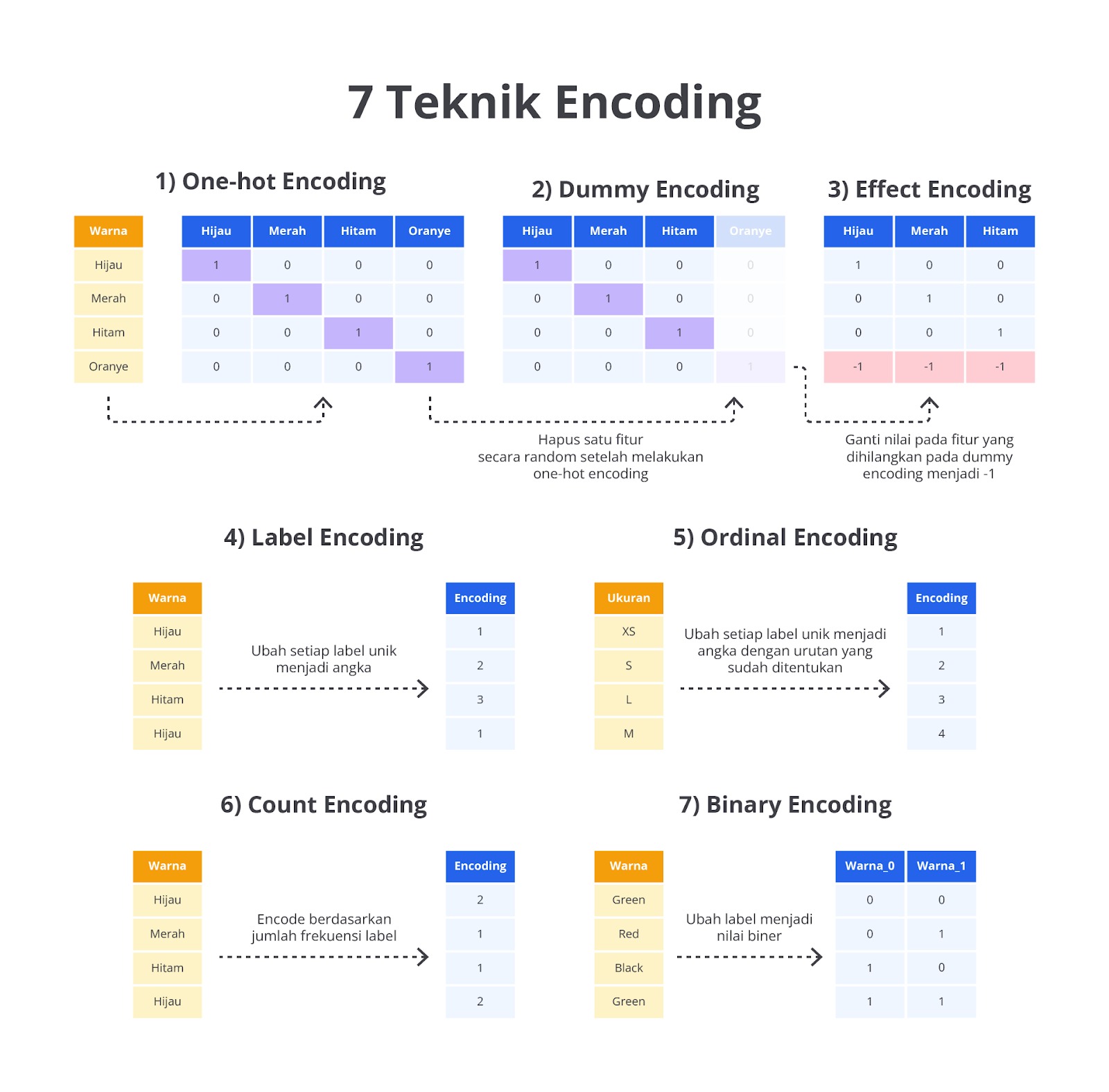
Tujuan utamanya agar data tersebut dapat dimengerti oleh komputer sehingga dapat menjadi model yang dapat digunakan. Hal ini sangat penting karena sebagian besar algoritma machine learning bekerja dengan angka untuk menghitung jarak, perhitungan statistik, dan pengambilan keputusan.
Binning Numerik ke Kategorikal
Binning digunakan untuk mengubah data numerik kontinu menjadi kategori atau interval diskrit. Tujuannya adalah untuk menyederhanakan data numerik dengan memisahkannya menjadi beberapa kelompok atau bin berdasarkan rentang atau distribusi nilai tertentu.
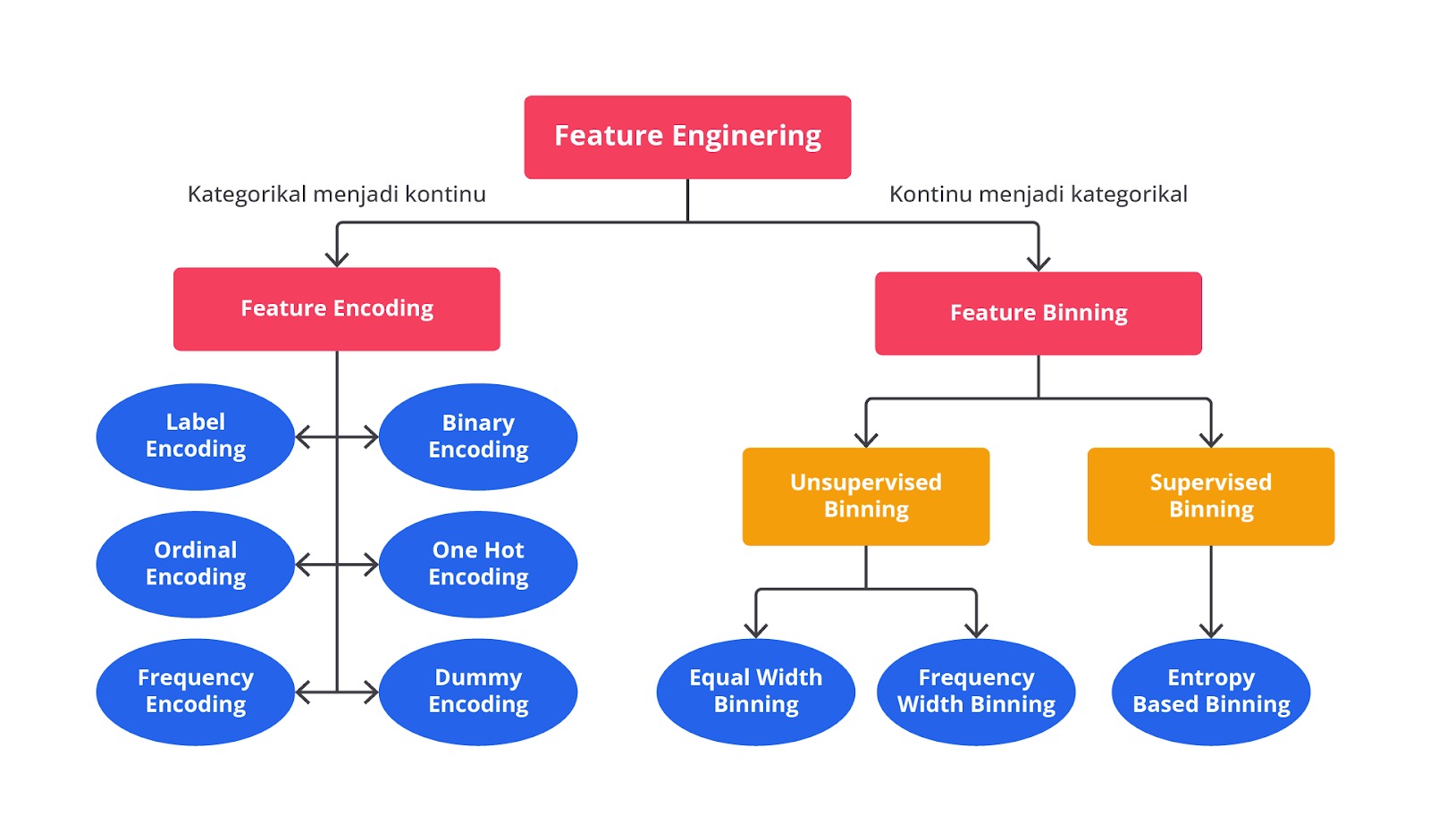
Scaling Fitur
Scaling feature pada machine learning adalah proses menyesuaikan rentang atau skala nilai-nilai fitur agar berada dalam rentang tertentu yang lebih seragam. Proses ini memiliki peran yang cukup penting karena banyak algoritma machine learning sensitif terhadap perbedaan skala antara fitur.
Jika nilai pada masing-masing fitur tidak di-scaling, algoritma yang Anda gunakan mungkin akan memberikan bobot lebih pada fitur dengan rentang nilai yang lebih besar padahal tidak selalu berarti fitur tersebut lebih penting. Scaling membantu memastikan bahwa semua fitur memiliki kontribusi yang seimbang dalam proses training model machine learning.
Secara umum terdapat dua teknik yang dapat Anda gunakan untuk mengubah skala data agar konsisten yaitu normalisasi dan standardisasi. Perhatikan perbedaan pada gambar berikut.
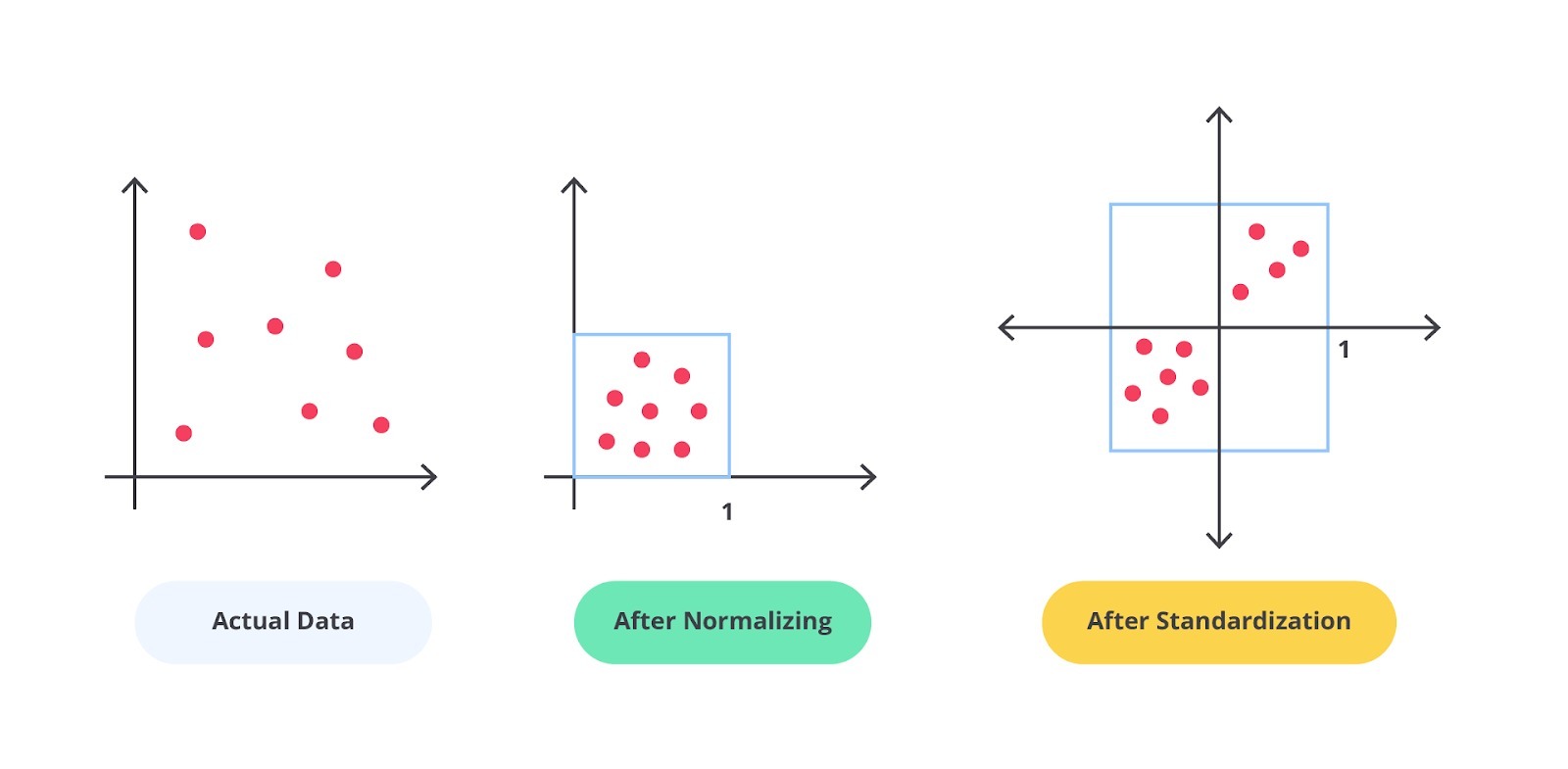
Penanganan Outlier
Dalam statistik, outlier adalah sebuah nilai yang jauh berbeda dari kumpulan nilai lainnya dan dapat mengacaukan hasil dari sebuah analisis statistik. Outlier dapat disebabkan oleh kesalahan dalam pengumpulan data atau nilai tersebut benar ada dan memang unik dari kumpulan nilai lainnya.
Apa pun alasan kemunculannya, Anda perlu tahu cara mengidentifikasi dan memproses outlier. Ini adalah bagian penting dalam persiapan data di dalam machine learning. Salah satu cara termudah untuk mengecek apakah terdapat outlier dalam data kita adalah dengan melakukan visualisasi.

Dapat dilihat dengan jelas bahwa terdapat satu sampel yang jauh berbeda dengan sampel-sampel lainnya. Setelah mengetahui bahwa di data kita terdapat outlier, kita dapat mencari lalu menghapus sampel tersebut dari dataset.
Oversampling dan Undersampling
Imbalanced Dataset adalah situasi ketika jumlah data pada satu kelas jauh lebih sedikit atau lebih banyak dibandingkan dengan kelas lainnya. Ini sering terjadi dalam masalah klasifikasi, khususnya dalam binary classification (klasifikasi dua kelas) ketika satu kelas (sering disebut minoritas) memiliki jauh lebih sedikit sampel dibandingkan kelas lainnya (disebut mayoritas). Namun, masalah ini juga tidak menutup kemungkinan terjadi pada masalah klasifikasi lebih dari dua kelas atau multi kelas, ya.
Ketika dataset tidak seimbang, algoritma machine learning cenderung lebih baik dalam memprediksi kelas mayoritas dan mengabaikan atau salah mengklasifikasikan kelas minoritas. Ini terjadi karena sebagian besar algoritma secara alami berusaha memaksimalkan akurasi yang mungkin bukan metrik yang tepat untuk dataset yang tidak seimbang.
Misalnya, jika 95% dari data termasuk dalam kelas mayoritas dan hanya 5% dalam kelas minoritas, model yang selalu memprediksi kelas mayoritas dapat mencapai akurasi 95% tanpa pernah memprediksi kelas minoritas dengan benar.
Google secara resmi memberikan tiga buah level untuk kondisi imbalance yang berbeda-beda dihitung dari proporsi ketidakseimbangannya.

Pada situsnya, Google memberikan saran untuk tetap melakukan pembangunan model machine learning pada dataset yang tidak seimbang. Hal ini dibutuhkan agar Anda memiliki baseline model sehingga dapat membandingkan hasil dari dataset yang imbalance dengan eksperimen kedepannya. Setelah itu, Anda perlu mencoba beberapa teknik untuk mengatasi permasalahan imbalance dataset seperti oversampling atau undersampling.
Oversampling
Oversampling adalah metode yang menambahkan sampel pada kelas minoritas sehingga jumlahnya menjadi seimbang dengan kelas mayoritas. Teknik ini bekerja dengan cara memperbanyak data dari kelas minoritas agar model memiliki kesempatan yang lebih baik untuk belajar dari data tersebut.
Undersampling
Berbanding terbalik dengan oversampling, undersampling adalah metode yang mengurangi jumlah sampel dari kelas mayoritas agar sesuai dengan jumlah sampel di kelas minoritas. Teknik ini bekerja dengan menghapus sebagian data dari kelas mayoritas untuk menciptakan keseimbangan antara kelas-kelas.
SMOTE (Synthetic Minority Over-Sampling Technique)
Synthetic Minority Over-sampling Technique (SMOTE) adalah teknik oversampling yang dirancang untuk menangani masalah imbalanced dataset pada machine learning. Berbeda dengan random oversampling yang hanya menduplikasi sampel dari kelas minoritas, SMOTE menghasilkan sampel sintetis (baru) berdasarkan data yang sudah ada di kelas minoritas. Dari hal itu terciptalah variasi baru di dalam dataset dan mengurangi risiko overfitting yang mungkin terjadi jika kita hanya menduplikasi data secara acak.
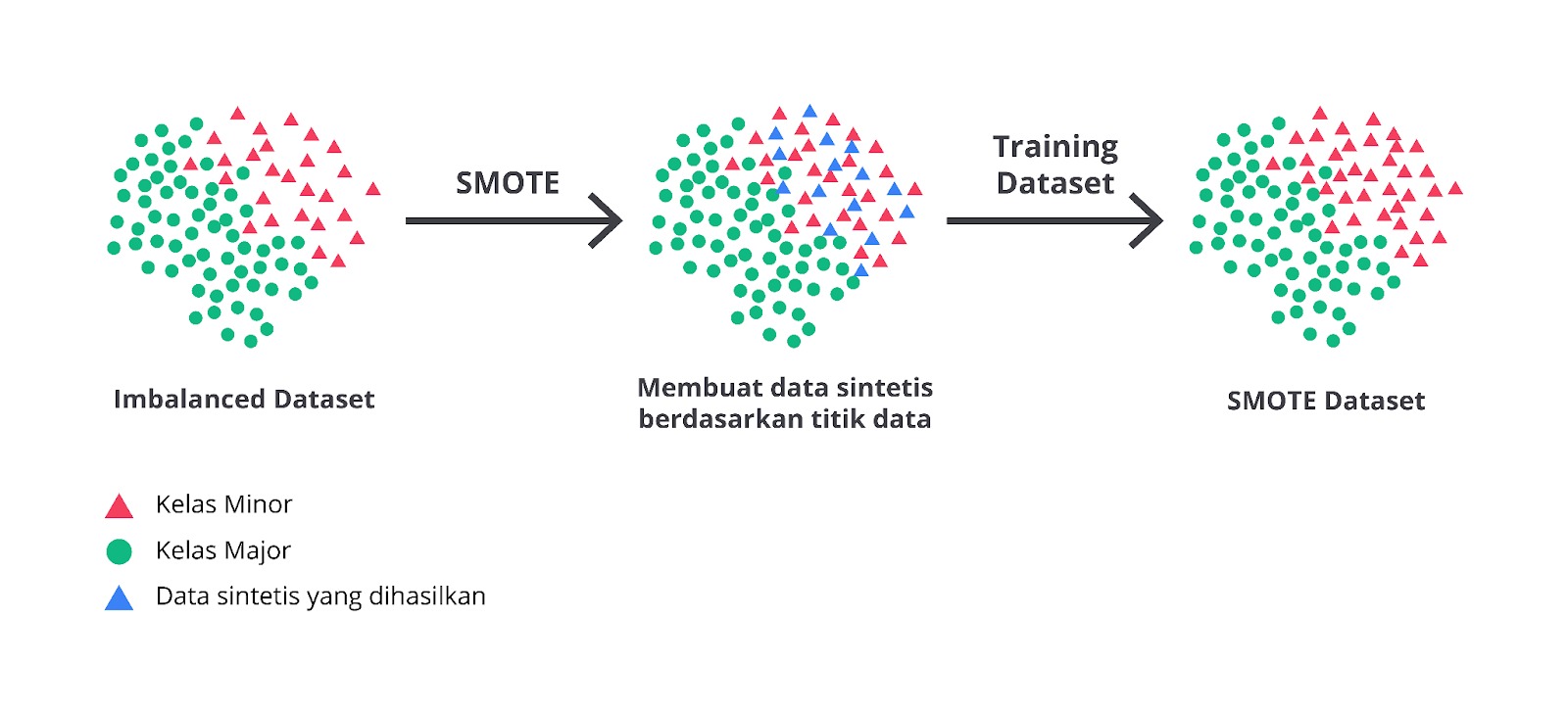
Sebenarnya metode SMOTE juga bekerja dengan cara yang tidak terlalu rumit. Secara umum, metode ini memiliki tiga buah langkah yang harus dilakukan hingga menghasilkan data yang seimbang.
- Ambil Sampel dari Kelas Minoritas: setiap sampel minoritas yang ada akan memilih beberapa tetangga terdekatnya. Biasanya, tahapan ini dihitung menggunakan K-Nearest Neighbors (KNN) atau K-Means.
- Interpolasi Data: buat sampel sintetis baru dengan melakukan interpolasi antara sampel minoritas dan tetangga terdekatnya. Interpolasi dilakukan dengan mengambil titik di sepanjang garis lurus yang menghubungkan dua data minoritas.
- Tambahkan Sampel Sintetis ke Dataset: sampel baru ini ditambahkan ke dataset, sehingga jumlah data di kelas minoritas bertambah hingga proporsional dengan kelas mayoritas.
Agar Anda lebih memahami proses yang terjadi pada teknik ini, mari kita lakukan perhitungan sederhana menggunakan teknik SMOTE.
Bersambung ke:
Pendahuluan Overfitting dan Underfitting
- Get link
- X
- Other Apps



Comments
Post a Comment