Pendahuluan Overfitting dan Underfitting
- Get link
- X
- Other Apps
Pendahuluan Overfitting dan Underfitting
Halo machine learning learner!
Semoga Anda dalam keadaan baik dan tetap semangat! Selamat datang kembali dalam perjalanan mempelajari machine learning. Pada modul kali ini, kita akan membahas topik yang sangat penting, yaitu overfitting dan underfitting. Kedua istilah ini sering muncul ketika kita membahas performa model machine learning, baik saat model bekerja dengan optimal maupun saat gagal memberikan prediksi yang tepat.
Sebelum melangkah lebih jauh, mari kita pahami dulu pentingnya konsep ini. Pernah mendengar ungkapan "terlalu fokus pada hal-hal kecil hingga melupakan gambaran besar"?
Overfitting memiliki sifat yang serupa, yaitu model terlalu terfokus pada data latih dan akhirnya gagal menggeneralisasi. Sebaliknya, underfitting terjadi ketika model terlalu sederhana dan tidak dapat menangkap pola yang ada. Keduanya bisa memengaruhi kualitas model yang kita bangun.
Bayangkan saja, Anda sudah menghabiskan banyak waktu dan tenaga untuk membangun model, tetapi prediksi yang dihasilkan malah jauh dari harapan? Rugi dong! Oleh karena itu, memahami cara menghindari kesalahan seperti ini sangat penting untuk memastikan hasil kerja keras Anda tidak sia-sia.
Sekarang waktunya kita menyelami lebih dalam topik tentang overfitting dan underfitting. Kita akan mempelajari penyebab kedua masalah ini muncul serta cara terbaik untuk menghindarinya. Modul ini dirancang untuk memberikan pemahaman mendalam sehingga Anda dapat lebih mudah mengidentifikasi dan memperbaiki model machine learning yang kurang optimal.
Semoga dengan mengikuti materi ini, Anda bisa membuat model yang lebih akurat dan efisien dalam berbagai kasus nyata. Jangan lupa untuk selalu siapkan catatan penting selama belajar dan tentunya tetap jaga semangat, ya!
[Story] Salah Prediksi Terus, Kenapa ya?
Di kantin kampus yang ramai, Diana dan Bilqis duduk santai di meja favorit mereka. Diana menikmati kebab ayamnya yang disajikan dengan banyak sayuran, sementara Bilqis baru saja mendapatkan burger double cheese yang menggiurkan.
“Yuk, makan dulu, tapi sebelum itu, aku mau cerita soal proyek kita yang terakhir, deh,” kata Diana sambil memotong kebabnya.
Bilqis menelan gigitannya dan mengangguk, “Oke, ada apa?”
“Jadi, ingat proyek klasifikasi churn yang kita kerjakan bulan lalu? Kita udah coba berbagai macam model, dari Logistic Regression sampai Random Forest, tapi hasilnya selalu salah prediksi. Gimana pun kita setting, modelnya tetap tidak akurat,” kata Diana dengan nada frustrasi.
“Ah, iya! Aku juga bingung, kenapa, ya, hasilnya gak pernah memuaskan,” jawab Bilqis sebelum menggigit burgernya. “Padahal kita udah coba cross-validation, tapi tetap aja aneh.”
“Betul banget. Aku pikir masalahnya bisa jadi karena kita gak cukup memperhatikan masalah overfitting dan underfitting,” kata Diana sambil menambahkan saus ke kebabnya.
Bilqis menyeka sisa saus di tangan sambil bertanya, “Overfitting dan underfitting? Apa tuh, Sist?”
“Gini, bayangkan kamu lagi belajar masak,” jelas Diana sambil memegang kebabnya. “Kalau kamu overfit, artinya kamu sudah terlalu sering bikin mi instan cuma dengan telur doang. Jadi, kamu jago banget bikin mie instan dengan telur, tapi kalau disuruh bikin mie instan yang lebih bervariasi—misalnya dengan cabai, bakso, dan sayur—kamu akan kebingungan.”
Bilqis mengernyitkan dahi, “Hmm, jadi overfitting itu kayak, kalau kita cuma bisa masak satu jenis makanan aja dan gak bisa beradaptasi dengan variasi yang lebih banyak? Jadi kalau ada yang lain, kita gak ngerti?”
“Yup, persis!” kata Diana sambil menyeka tangan dengan tisu. “Nah, kalau underfitting itu kebalikannya. Bayangkan kamu belajar masak, tapi kamu cuma belajar resep yang super gampang, seperti mi instan tanpa tambahan apa-apa. Ketika ada yang minta kamu bikin lasagna atau sushi, kamu jadi bingung dan tidak tahu cara membuatnya karena belum memahami teknik atau bahan yang lebih kompleks.”

Bilqis mengangguk pelan, tetapi terlihat masih berpikir keras. “Oke, jadi underfitting itu kayak belajar hal-hal yang terlalu mudah, jadi pas ada yang susah, kita belum siap, ya?”
“Betul banget!” Diana melanjutkan dengan semangat. “Jadi kita butuh keseimbangan. Kita harus latihan dengan berbagai resep dan teknik supaya bisa siap menghadapi berbagai tantangan masak. Jangan cuma jago satu jenis masakan atau cuma belajar yang terlalu gampang.”
Bilqis mengunyah burgernya sambil berpikir, “Hmm, aku mulai paham, nih. Jadi kita harus latihan di banyak hal supaya kita bisa masak berbagai macam hidangan, ya?”
“Bingo!” Diana berseru sambil tersenyum lebar. “Dan kita bisa cek keterampilan kita dengan bikin hidangan yang berbeda-beda. Kalau bisa berhasil dengan resep yang baru, berarti kita udah siap.”
Bilqis tersenyum lebar, “Oke, jadi kita perlu belajar dengan cara yang bervariasi, supaya kita bisa lebih siap menghadapi berbagai tantangan. Ini bisa jadi solusi buat masalah churn di perusahaan XYZ kita, kan?”
“Persis! Dengan cara itu, kita bakal bisa bantu perusahaan dengan lebih efektif,” kata Diana dengan penuh semangat.
Mereka berdua melanjutkan makan sambil merencanakan langkah selanjutnya. Diana mengusulkan, “Gimana kalau kita bikin beberapa model dengan variasi data? Jadi kita bisa lihat model mana yang paling fleksibel dan enggak gampang terjebak di masalah overfitting atau underfitting.”
Bilqis menyetujui dengan antusias, “Iya, itu ide yang bagus! Kita bisa coba berbagai jenis data dan teknik. Semakin banyak variasi, semakin bagus hasilnya.”
Diana mengangguk, “Setuju! Ayo kita bikin rencana dan mulai eksperimen. Semangat baru ini bakal bikin kita lebih siap menghadapi semua tantangan!”
Dengan semangat baru serta pemahaman yang lebih baik tentang overfitting dan underfitting, Diana dan Bilqis siap menghadapi tantangan baru. Mereka yakin, kali ini mereka bakal menemukan solusi yang tepat untuk masalah klasifikasi churn.
Definisi dan Konsep Dasar
Dalam machine learning, tujuan utama kita adalah membangun model yang mampu menggeneralisasi dengan baik dari data yang telah dilatih untuk membuat prediksi akurat terhadap data yang belum pernah dilihat sebelumnya. Namun, sering kali model kita gagal dalam mencapai keseimbangan antara mempelajari pola-pola penting dari data dan menghindari pemahaman berlebihan terhadap data latih. Inilah yang memunculkan dua masalah umum dalam machine learning, yaitu overfitting dan underfitting.
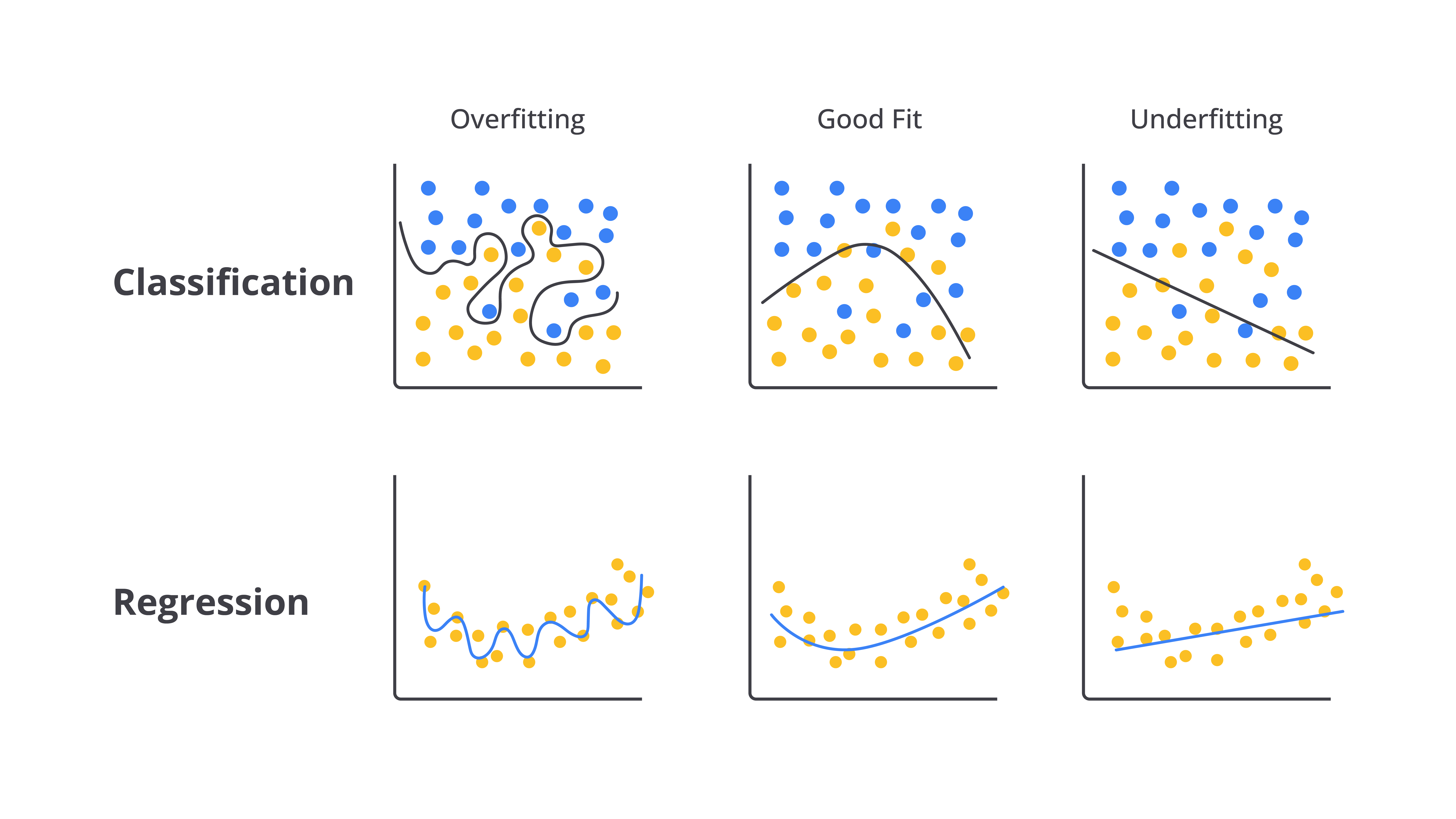
Seperti gambar yang Anda lihat di atas, overfitting dan underfitting dapat terjadi pada berbagai jenis model, termasuk classification dan regression yang telah kita pelajari dalam modul sebelumnya. Namun, first thing first, apa perbedaan keduanya?
Apa Itu Overfitting dan Underfitting?
Overfitting terjadi ketika model machine learning terlalu menyesuaikan diri dengan data latih sehingga ia tidak hanya menangkap pola utama, tetapi juga menangkap noise atau detail yang tidak relevan. Hal ini sering terjadi ketika data latih terlalu spesifik atau terbatas atau ketika model terlalu kompleks, misalnya menggunakan terlalu banyak fitur atau algoritma yang terlalu canggih untuk data yang ada. Akibatnya, model kehilangan kemampuan untuk melakukan generalisasi dengan baik terhadap data baru.
Model yang mengalami overfitting akan menunjukkan performa sangat baik pada data latih karena sudah "menghafal" setiap detail, termasuk anomali atau pola yang sebenarnya tidak signifikan. Namun, ketika diuji dengan data baru (data uji), model ini gagal memberikan prediksi akurat karena tidak mampu menggeneralisasi pola yang lebih umum. Dengan kata lain, model tersebut hanya bagus untuk data yang telah dilihatnya, tetapi buruk dalam menghadapi data yang belum pernah ditemui sebelumnya.
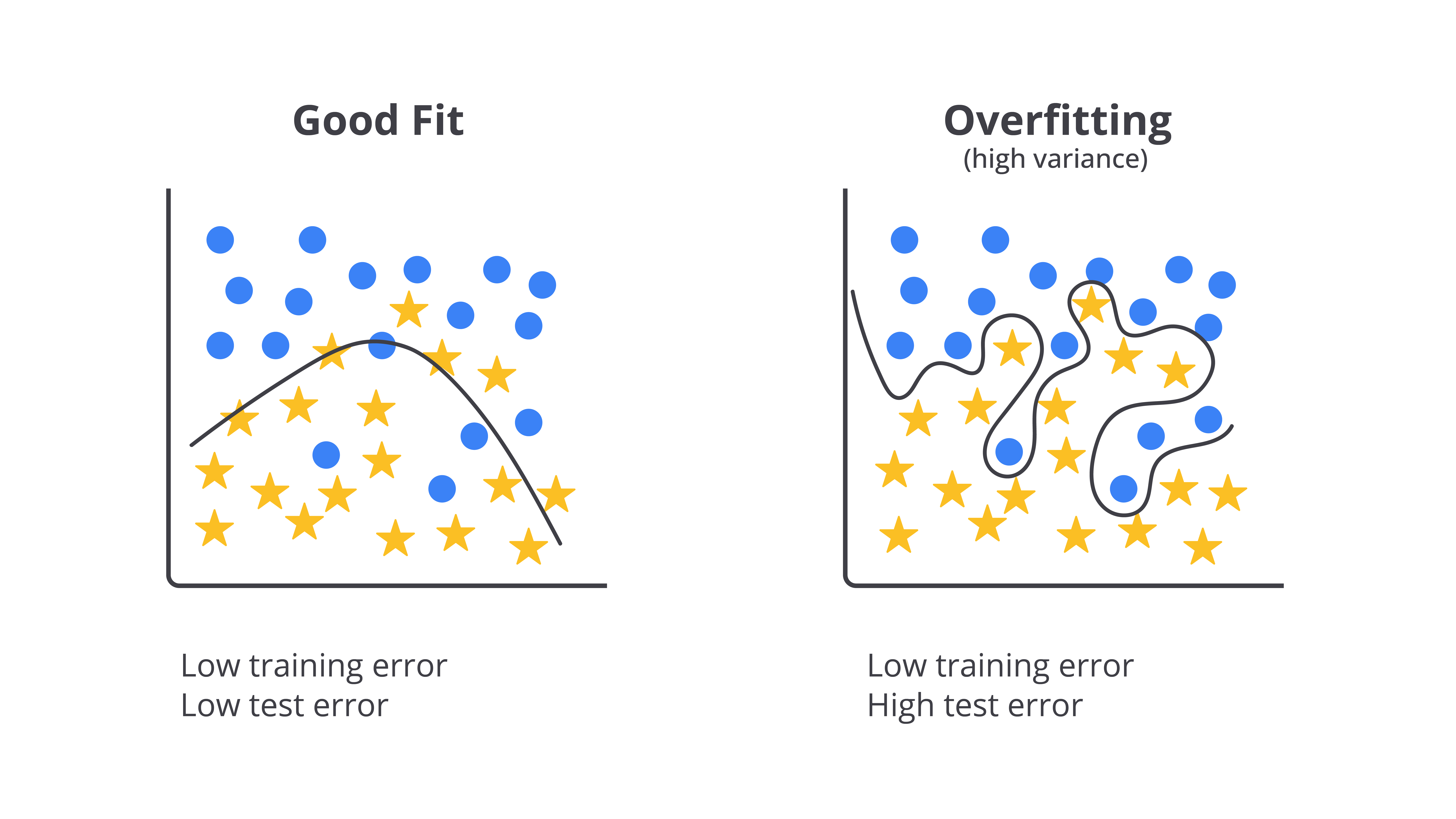
Bayangkan Anda sedang belajar untuk ujian matematika dengan menghafal semua soal latihan yang diberikan guru, termasuk soal-soal dengan angka sangat spesifik. Saat ujian tiba, soalnya memang mirip, tetapi angka-angkanya berbeda. Karena terlalu fokus menghafal angka-angka dari soal latihan, Anda kesulitan menyelesaikan soal ujian yang sedikit berbeda. Ini seperti overfitting—model terlalu "menghafal" data latih, termasuk detail-detail kecil yang sebenarnya tidak penting sehingga tidak bisa beradaptasi dengan data baru.
Misalnya, jika Anda membuat model untuk memprediksi harga makanan di pasar, model yang overfit akan mengingat seluruh harga-harga pada data latih. Itu termasuk harga yang mungkin tidak wajar, seperti harga makanan yang tiba-tiba sangat mahal atau sangat murah. Saat dihadapkan pada data uji yang baru, model tidak bisa membuat prediksi dengan baik karena terlalu fokus terhadap harga-harga spesifik dari data latih.
Underfitting, di sisi lain, adalah situasi ketika model gagal menangkap pola yang signifikan dalam data karena model tersebut terlalu sederhana. Ini terjadi ketika model memiliki kompleksitas yang terlalu rendah atau tidak dilatih dengan cukup baik. Model underfit sering kali tidak mampu mempelajari hubungan antara fitur-fitur dan target sehingga baik pada data latih maupun data uji, performanya sangat buruk. Model ini gagal mengenali pola penting dalam data dan hasilnya tidak dapat memberikan prediksi yang akurat.
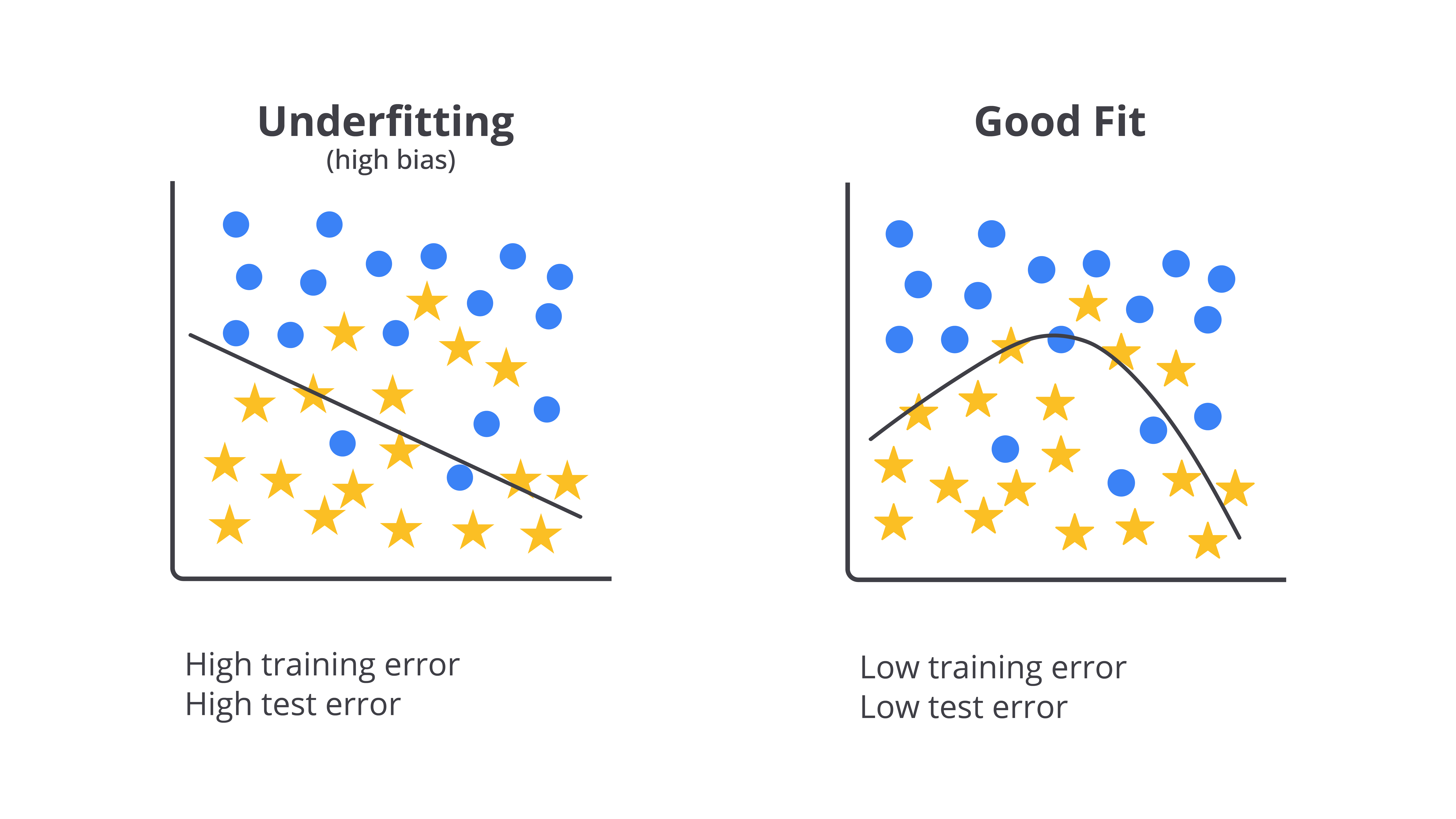
Bayangkan Anda belajar untuk ujian matematika, tetapi hanya mempelajari konsep-konsep dasar tanpa berusaha memahami soal-soal yang lebih rumit. Saat ujian tiba, karena persiapan terlalu sederhana, Anda kesulitan menjawab soal-soal yang lebih sulit meskipun pola dan konsepnya sudah diajarkan. Ini seperti underfitting, yaitu ketika model terlalu sederhana dan gagal memahami pola penting dalam data sehingga tidak bisa memberikan jawaban yang baik saat dihadapkan pada data baru.
Misalnya, jika Anda membuat model untuk memprediksi harga makanan di pasar, tetapi hanya menggunakan satu fitur, seperti ukuran makanan, tanpa mempertimbangkan faktor lain, seperti kualitas atau lokasi, prediksi model akan sangat tidak akurat karena model tersebut tidak menangkap faktor-faktor penting untuk membuat prediksi secara tepat.
Good fit adalah kondisi ideal ketika model machine learning mampu menangkap pola signifikan dalam data tanpa terlalu terikat pada detail yang tidak relevan atau terlalu sederhana. Model dalam kondisi good fit akan menunjukkan performa yang baik pada data latih maupun data uji. Ini mengindikasikan bahwa model tersebut dapat menggeneralisasi pola dengan baik dari data yang telah dilatih dan tetap memberikan prediksi akurat dalam data baru.
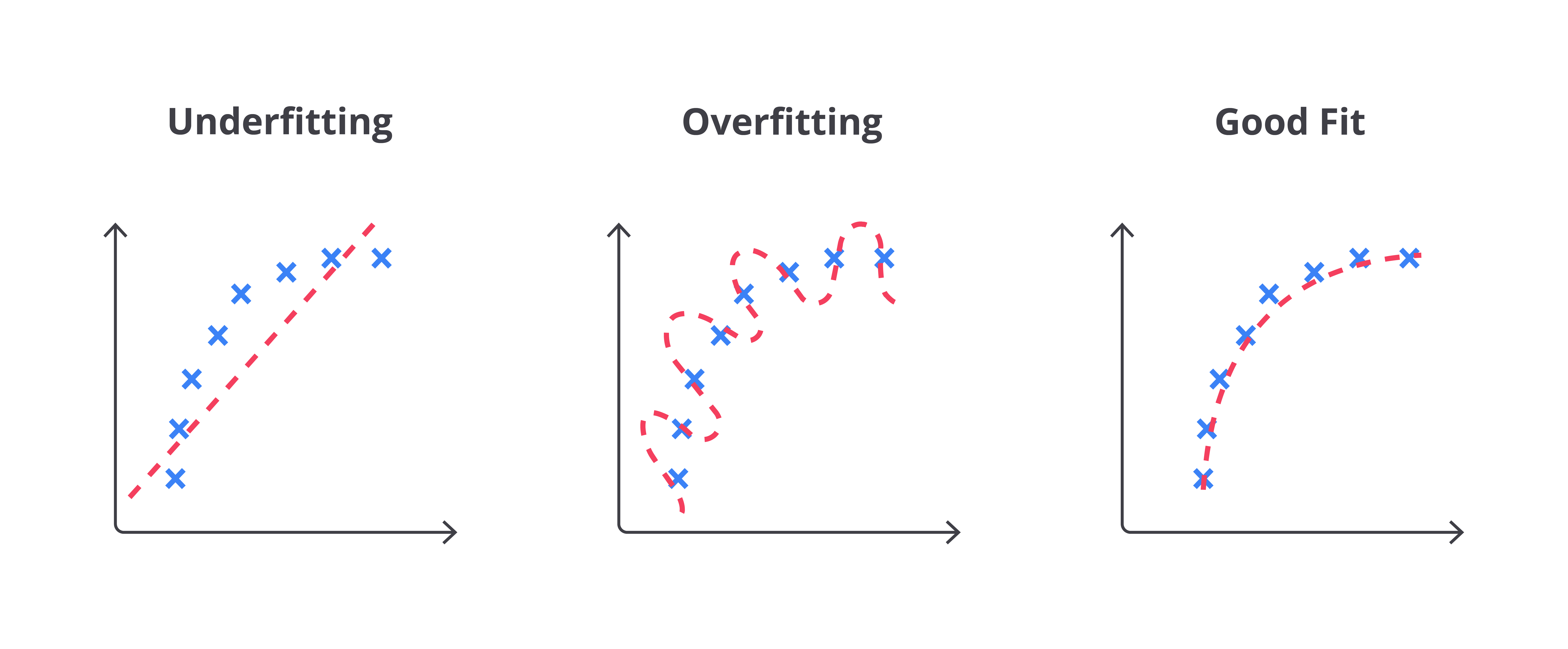
Bayangkan Anda mempersiapkan diri untuk ujian matematika dengan cara yang seimbang: memahami konsep-konsep dasar, mengerjakan soal latihan, dan mempelajari berbagai variasi soal tanpa terlalu menghafal angka-angka spesifik. Ketika ujian tiba, Anda bisa menjawab soal-soal dengan baik karena mengerti pola dan konsep, serta menyesuaikan jawaban dengan soal yang sedikit berbeda. Ini seperti good fit—model belajar cukup dari data latih, menangkap pola penting, dan mampu membuat prediksi akurat pada data baru tanpa terganggu oleh detail yang tidak relevan.
Misalnya, jika Anda membuat model untuk memprediksi harga makanan di pasar, model good fit akan mempertimbangkan faktor-faktor penting, seperti ukuran, kualitas, dan lokasi, tanpa berlebihan dalam menghafal harga spesifik pada data latih. Saat dihadapkan pada data baru, model mampu membuat prediksi dengan tepat karena memahami pola umum yang relevan dari data tersebut.
Penyebab Overfitting dan Underfitting
Ketika Anda berusaha mengembangkan model machine learning secara akurat serta efektif, memahami penyebab di balik masalah overfitting dan underfitting adalah hal yang sangat penting. Keduanya adalah tantangan umum yang dapat memengaruhi kualitas prediksi model.

Melalui penjelasan berikut, Anda akan menggali lebih dalam mengenai berbagai penyebab dari kedua masalah ini serta pengaruhnya pada kinerja model. Memahami penyebab-penyebab ini tentunya akan membantu Anda dalam mengidentifikasi dan memperbaiki masalah sehingga dapat membangun model yang lebih baik serta andal. Berikut adalah beberapa di antaranya.
- Kompleksitas Model yang Terlalu Tinggi
Overfitting sering kali terjadi ketika model machine learning memiliki terlalu banyak parameter atau fitur. Model yang terlalu kompleks mampu menangkap bahkan detail terkecil dan noise dalam data latih.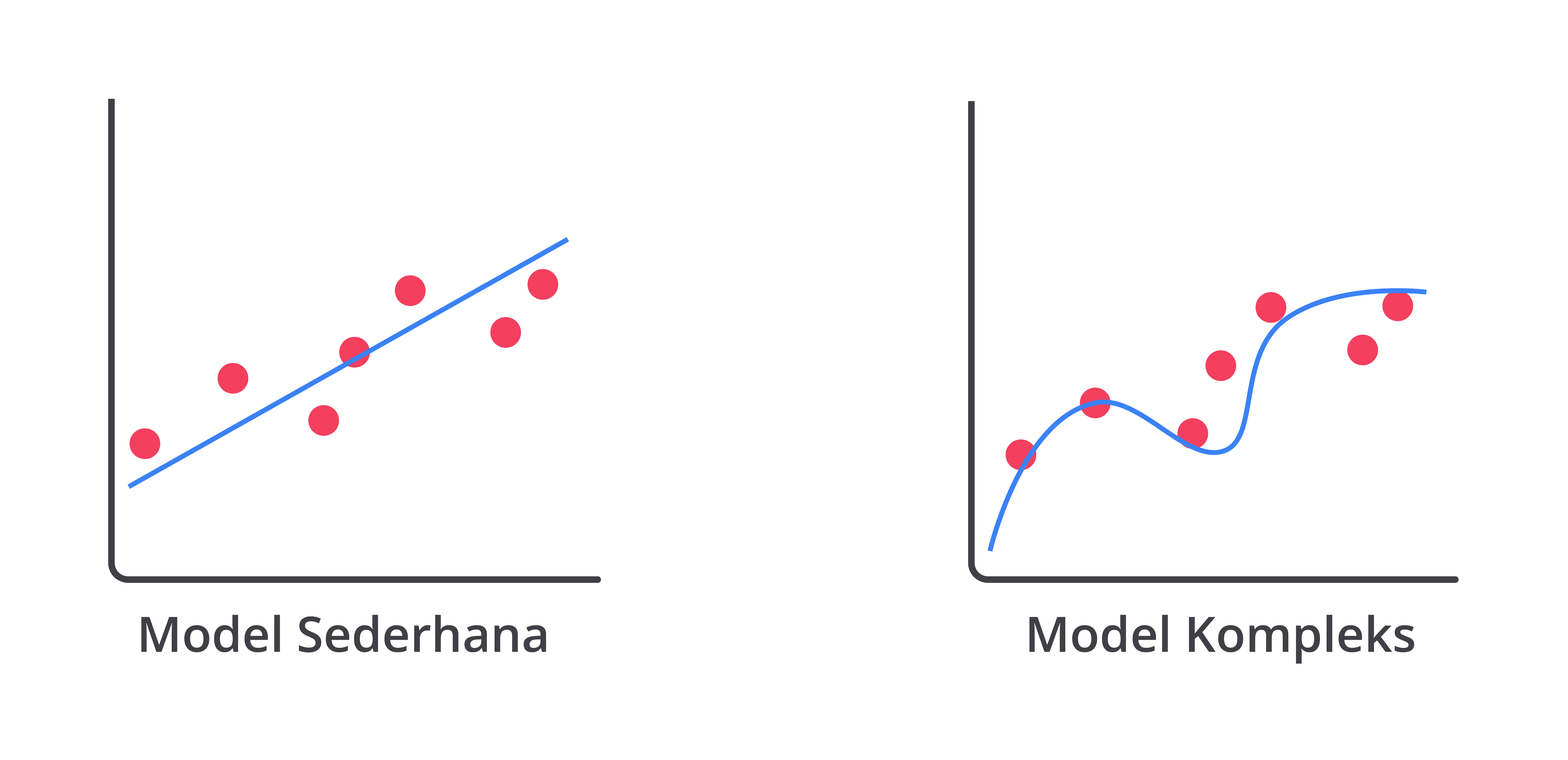 Misalnya, jika Anda menggunakan model yang sangat kompleks, seperti regresi polinomial dengan nilai degree tinggi untuk data yang sebenarnya hanya butuh model sederhana, seperti regresi linear, model tersebut bisa menjadi terlalu spesifik terhadap data latih. Artinya, model akan terlalu fokus pada detail-detail kecil dan kesalahan yang tidak penting. Hasilnya, meskipun model bekerja dengan baik pada data latih, ia tidak dapat memberikan prediksi yang akurat untuk data baru.
Misalnya, jika Anda menggunakan model yang sangat kompleks, seperti regresi polinomial dengan nilai degree tinggi untuk data yang sebenarnya hanya butuh model sederhana, seperti regresi linear, model tersebut bisa menjadi terlalu spesifik terhadap data latih. Artinya, model akan terlalu fokus pada detail-detail kecil dan kesalahan yang tidak penting. Hasilnya, meskipun model bekerja dengan baik pada data latih, ia tidak dapat memberikan prediksi yang akurat untuk data baru. - Data Latih yang Terbatas
 Jika kompleksitas model sangat besar dibandingkan dengan jumlah ketersediaan data latih, model tersebut mungkin akan terlalu menyesuaikan diri dengan data yang ada. Ini bisa menyebabkan model menangkap noise dan detail yang tidak penting. Model yang terlalu "fit" dengan data latih mungkin tidak dapat generalisasi secara baik pada data baru yang berbeda.
Jika kompleksitas model sangat besar dibandingkan dengan jumlah ketersediaan data latih, model tersebut mungkin akan terlalu menyesuaikan diri dengan data yang ada. Ini bisa menyebabkan model menangkap noise dan detail yang tidak penting. Model yang terlalu "fit" dengan data latih mungkin tidak dapat generalisasi secara baik pada data baru yang berbeda. - Pelatihan yang Terlalu Lama
 Pelatihan model yang terlalu lama dapat menyebabkan overfitting karena model terus-menerus menyesuaikan parameter untuk meminimalkan kesalahan pada data latih. Seiring berjalannya waktu, model dapat mulai mempelajari pola-pola spesifik yang tidak relevan dan tidak ada dalam data uji sehingga mengurangi kemampuannya untuk menggeneralisasi.
Pelatihan model yang terlalu lama dapat menyebabkan overfitting karena model terus-menerus menyesuaikan parameter untuk meminimalkan kesalahan pada data latih. Seiring berjalannya waktu, model dapat mulai mempelajari pola-pola spesifik yang tidak relevan dan tidak ada dalam data uji sehingga mengurangi kemampuannya untuk menggeneralisasi. - Fitur yang Tidak Relevan
Penggunaan fitur yang banyak dan tidak relevan juga dapat menyebabkan overfitting. Fitur yang tidak penting dapat membuat model terlalu kompleks dan cenderung fokus pada pola-pola tidak signifikan atau acak dalam data latih.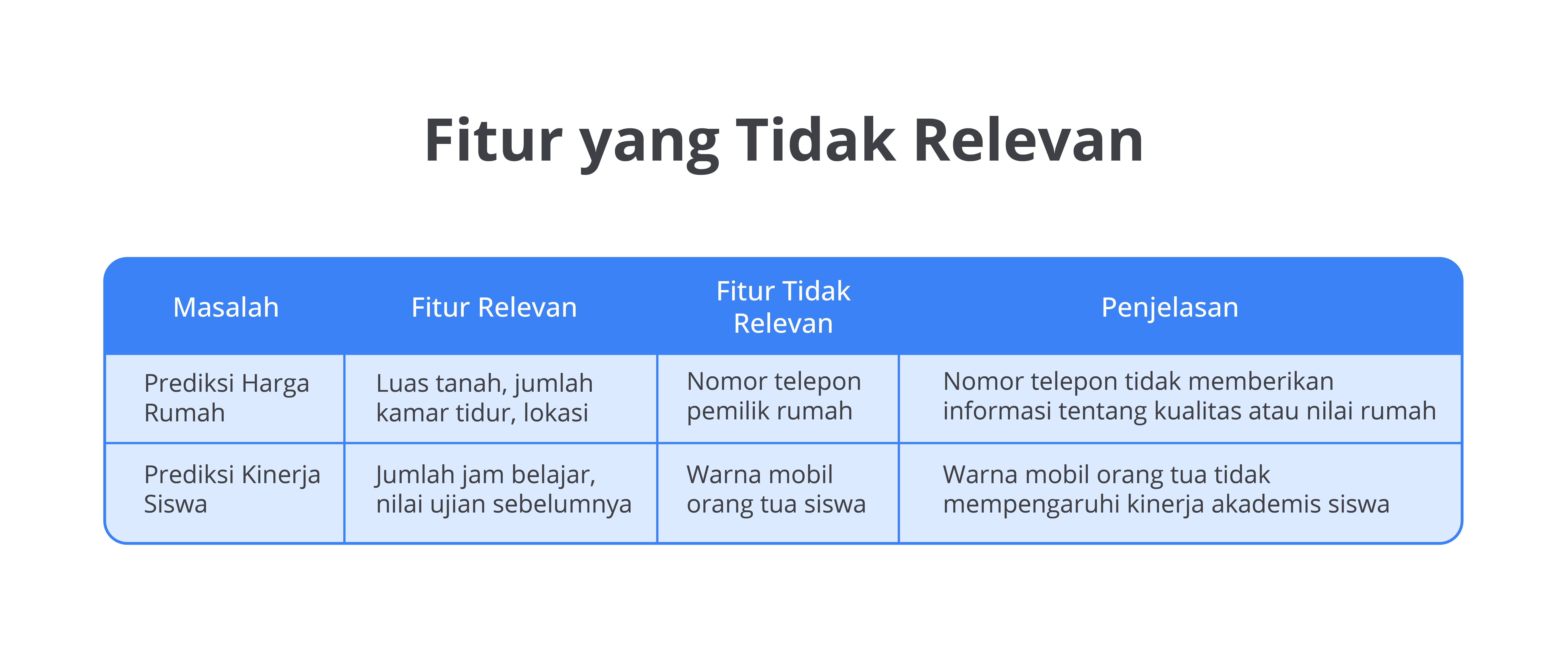 Misalnya, bayangkan kamu membuat model untuk memprediksi hasil ujian dengan memasukkan banyak fitur, seperti waktu tidur, waktu belajar, dan jenis makanan. Jika model terlalu kompleks dengan banyak fitur tambahan yang tidak benar-benar berhubungan dengan hasil ujian, model mungkin hanya "mempelajari" pola-pola acak dari data latih, yang tidak akan berlaku pada data baru.
Misalnya, bayangkan kamu membuat model untuk memprediksi hasil ujian dengan memasukkan banyak fitur, seperti waktu tidur, waktu belajar, dan jenis makanan. Jika model terlalu kompleks dengan banyak fitur tambahan yang tidak benar-benar berhubungan dengan hasil ujian, model mungkin hanya "mempelajari" pola-pola acak dari data latih, yang tidak akan berlaku pada data baru.
Metode Deteksi Overfitting dan Underfitting
Memahami serta mengatasi overfitting dan underfitting adalah kunci untuk membangun model machine learning yang efektif serta akurat. Overfitting dan underfitting masing-masing mengindikasikan masalah dengan cara model beradaptasi terhadap data serta masing-masing memerlukan pendekatan yang berbeda untuk deteksi dan perbaikan. Metode deteksi ini membantu kita mengevaluasi cara model bekerja pada data latih dan data uji serta cara model dapat disesuaikan untuk mencapai performa yang optimal.
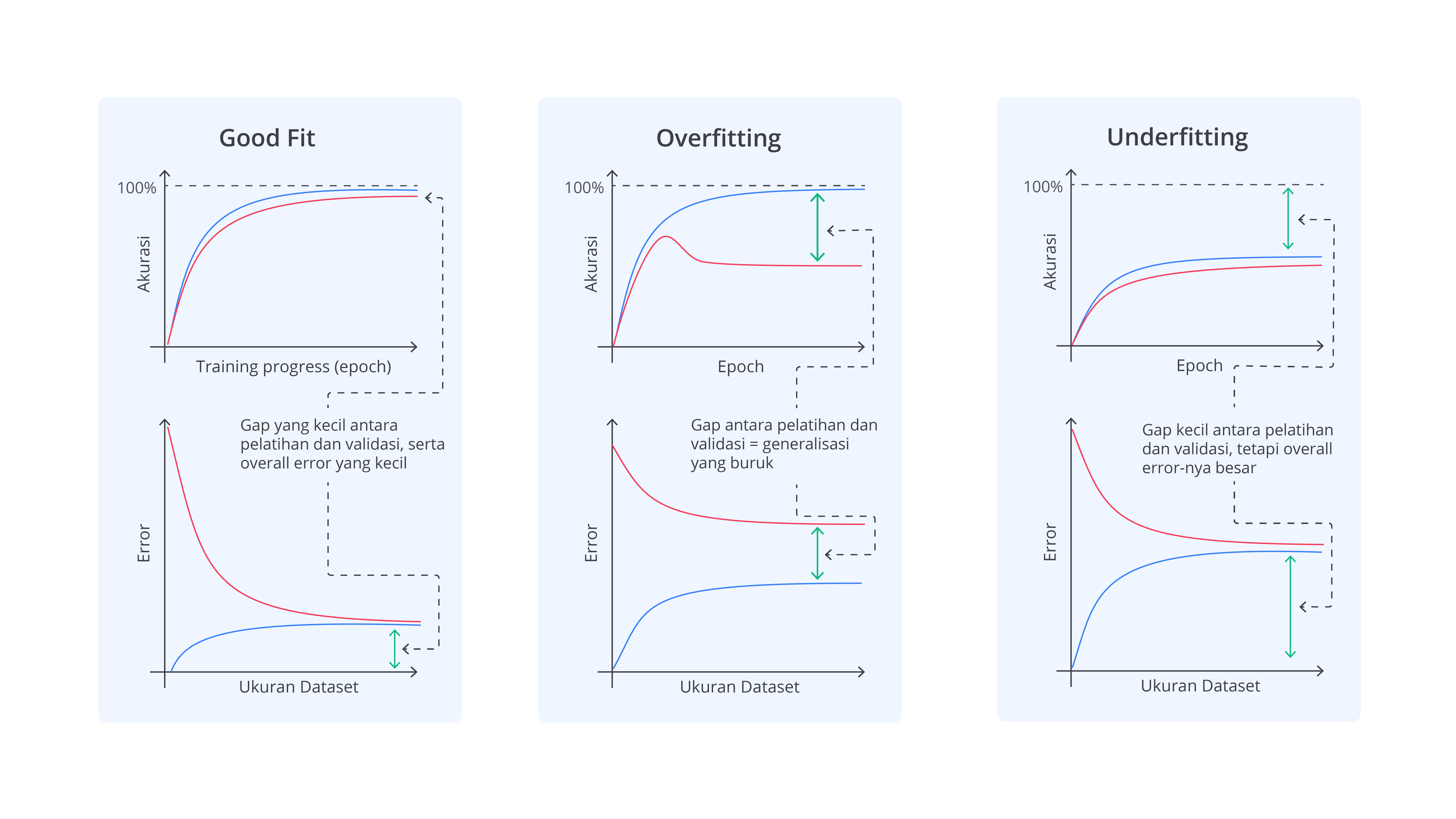
Metode Deteksi Overfitting
Dalam pengembangan model machine learning, deteksi overfitting adalah langkah krusial untuk memastikan bahwa model yang dibangun tidak hanya berfungsi baik pada data latih, tetapi juga dapat menggeneralisasi dengan baik dalam data yang belum pernah dilihat sebelumnya. Untuk mendeteksi dan mengatasi masalah ini, berbagai metode dapat diterapkan. Berikut adalah di antaranya.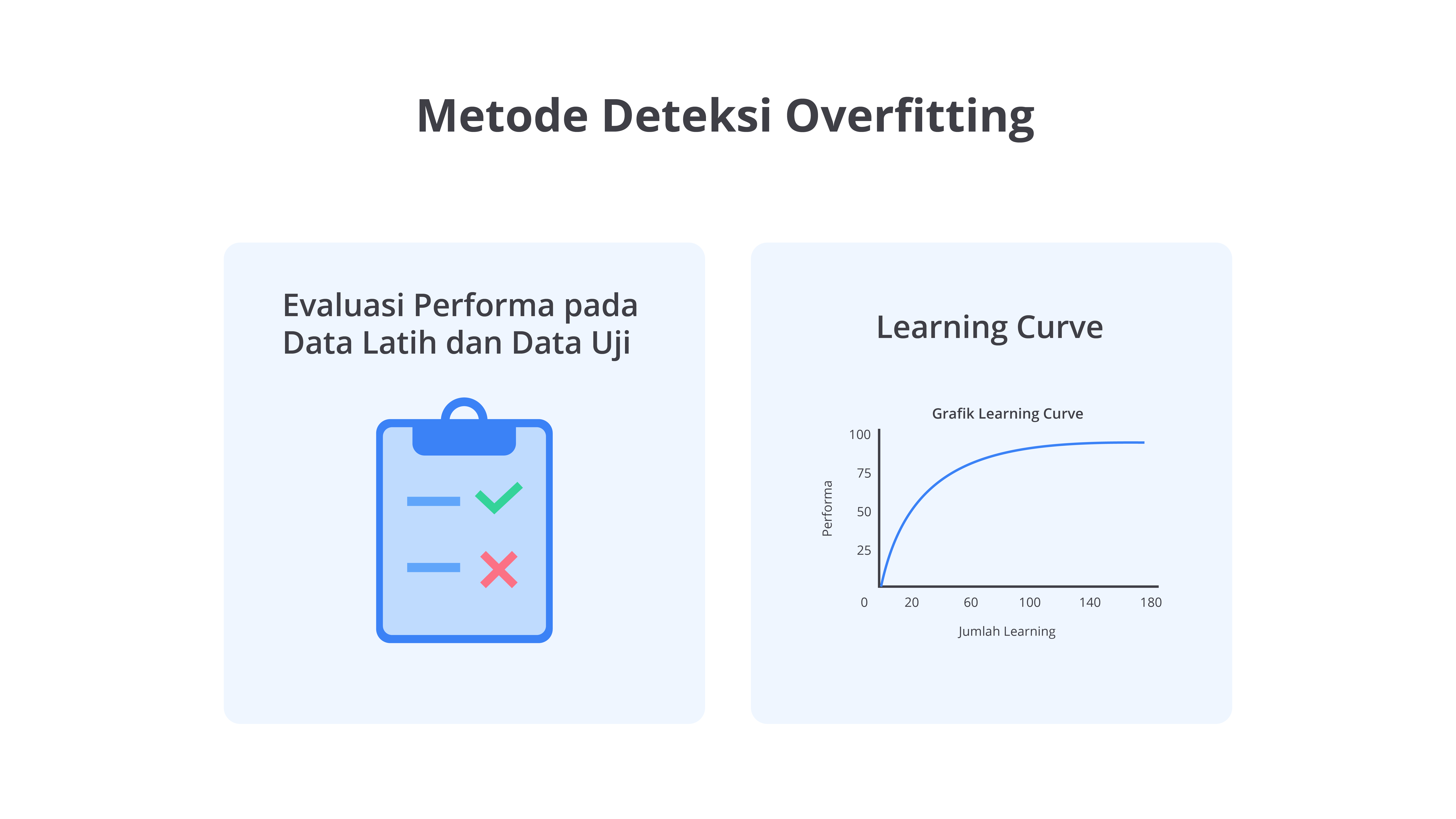
Evaluasi Performa pada Data Latih dan Data Uji
Untuk mendeteksi overfitting, Anda perlu membandingkan performa model pada data latih dan data uji. Jika model menunjukkan kinerja yang sangat baik pada data latih, tetapi performanya menurun secara signifikan dalam data uji, ini menandakan bahwa model terlalu terlatih pada data latih dan gagal menggeneralisasi pola dalam data yang belum pernah dilihat. Perbedaan besar antara akurasi pada data latih dan data uji menunjukkan bahwa model telah "mengingat" data latih dengan terlalu detail.
Learning Curve
Learning curve menunjukkan proses perubahan ataupun kesalahan model seiring dengan jumlah data pelatihan. Jika model menunjukkan kesalahan pelatihan yang sangat rendah, tetapi kesalahan validasi tetap tinggi atau meningkat, ini dapat menandakan overfitting. Kurva ini membantu memvisualisasikan bahwa model terlalu kompleks dan memerlukan penyederhanaan.
Metode Deteksi Underfitting
Setelah membahas metode deteksi overfitting, sekarang bagaimana dengan lawan mainnya, yaitu underfitting? Pada dasarnya metode yang digunakan tidak jauh berbeda dengan yang ada di overfitting sebelumnya, hanya saja kali ini ada tambahan satu opsi metode deteksi. Mari kita bahas satu per satu.

Evaluasi Performa pada Data Latih dan Data Uji
Sama seperti overfitting, untuk mendeteksi underfitting, perhatikan jika model menunjukkan performa yang buruk, baik pada data latih maupun data uji. Model yang terlalu sederhana akan tidak mampu menangkap pola kompleks dalam data sehingga menyebabkan kesalahan yang tinggi pada kedua set data. Ini menunjukkan bahwa model perlu diperbaiki untuk menangkap informasi yang lebih mendalam.
Learning Curve
Learning curve juga berguna untuk mendeteksi underfitting. Jika kurva pembelajaran menunjukkan kesalahan tinggi pada data latih dan data uji yang tidak menurun meskipun jumlah data pelatihan meningkat, ini menandakan bahwa model mungkin terlalu sederhana untuk menangkap pola dalam data. Kurva ini membantu menentukan jika model perlu lebih kompleks.
Pemeriksaan Kompleksitas Model
Tinjau kompleksitas model dengan memeriksa jenis model yang digunakan dan jumlah fitur tersedia. Model yang terlalu sederhana mungkin tidak dapat menangkap hubungan rumit dalam data. Misalnya, menggunakan regresi linear pada data dengan hubungan non-linear dapat mengakibatkan underfitting. Menyederhanakan model atau menambahkan fitur baru bisa membantu.
Dengan menggunakan metode deteksi ini, Anda dapat memastikan bahwa model machine learning tidak hanya berfungsi baik pada data latih, tetapi juga dapat menggeneralisasi dengan baik dalam data yang belum pernah dilihat sebelumnya sehingga meningkatkan akurasi dan efektivitas model secara keseluruhan.
Teknik Mengatasi Overfitting dan Underfitting
Untuk memastikan bahwa model machine learning dapat bekerja secara optimal tanpa terjebak dalam masalah overfitting atau underfitting, beberapa teknik penting dapat diterapkan. Mengatasi overfitting dan underfitting adalah langkah krusial dalam proses pembangunan model yang efektif. Berikut adalah beberapa di antaranya.
Mengatasi Overfitting
Dalam bagian ini, kita akan menjelajahi beberapa metode efektif untuk mengatasi overfitting, termasuk early stopping, regularization, pruning, dropout, dan data augmentation. Teknik-teknik ini dirancang untuk membuat model lebih robust dan mampu beradaptasi dengan berbagai jenis data sehingga menghasilkan prediksi yang lebih akurat serta dapat diandalkan.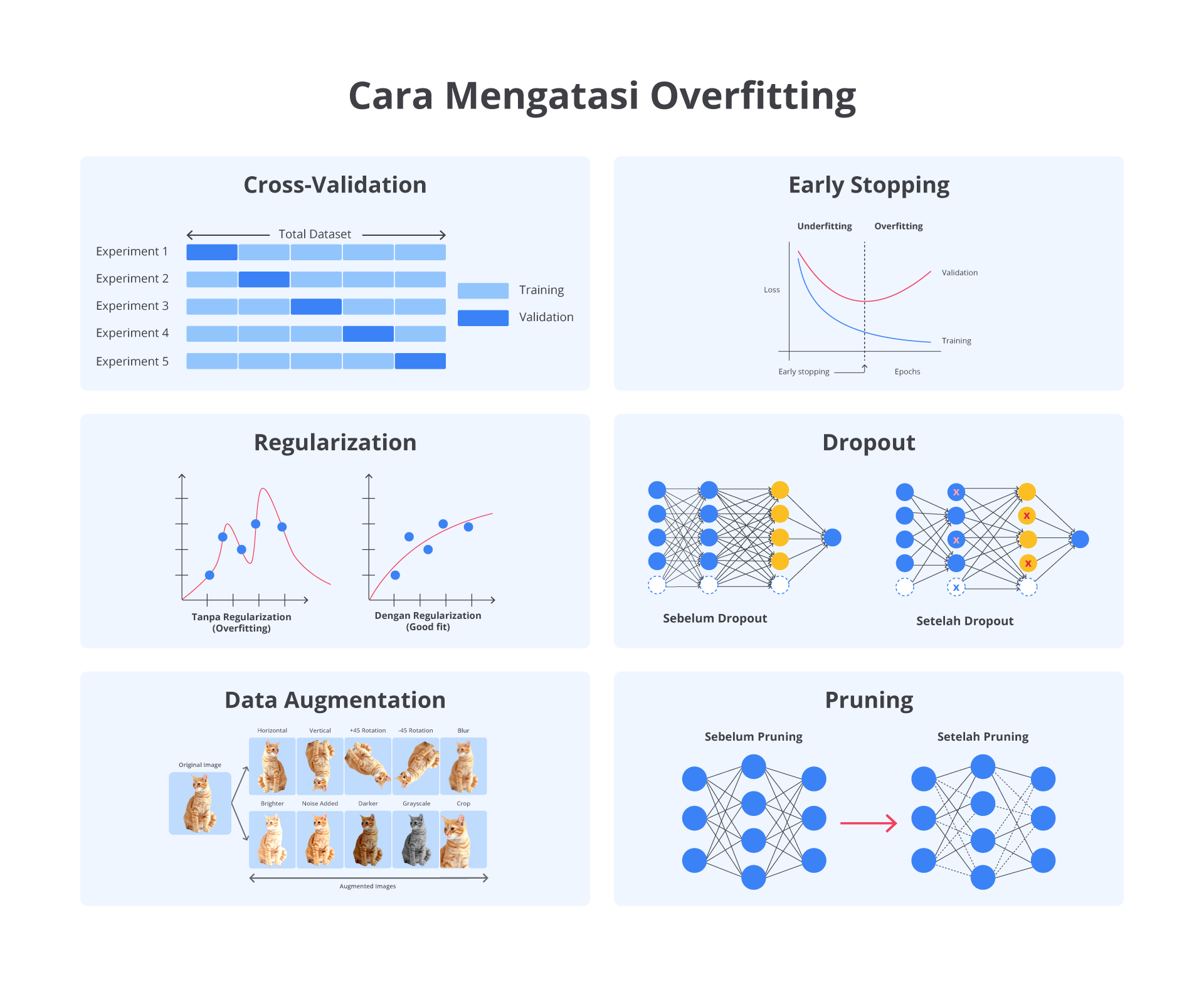
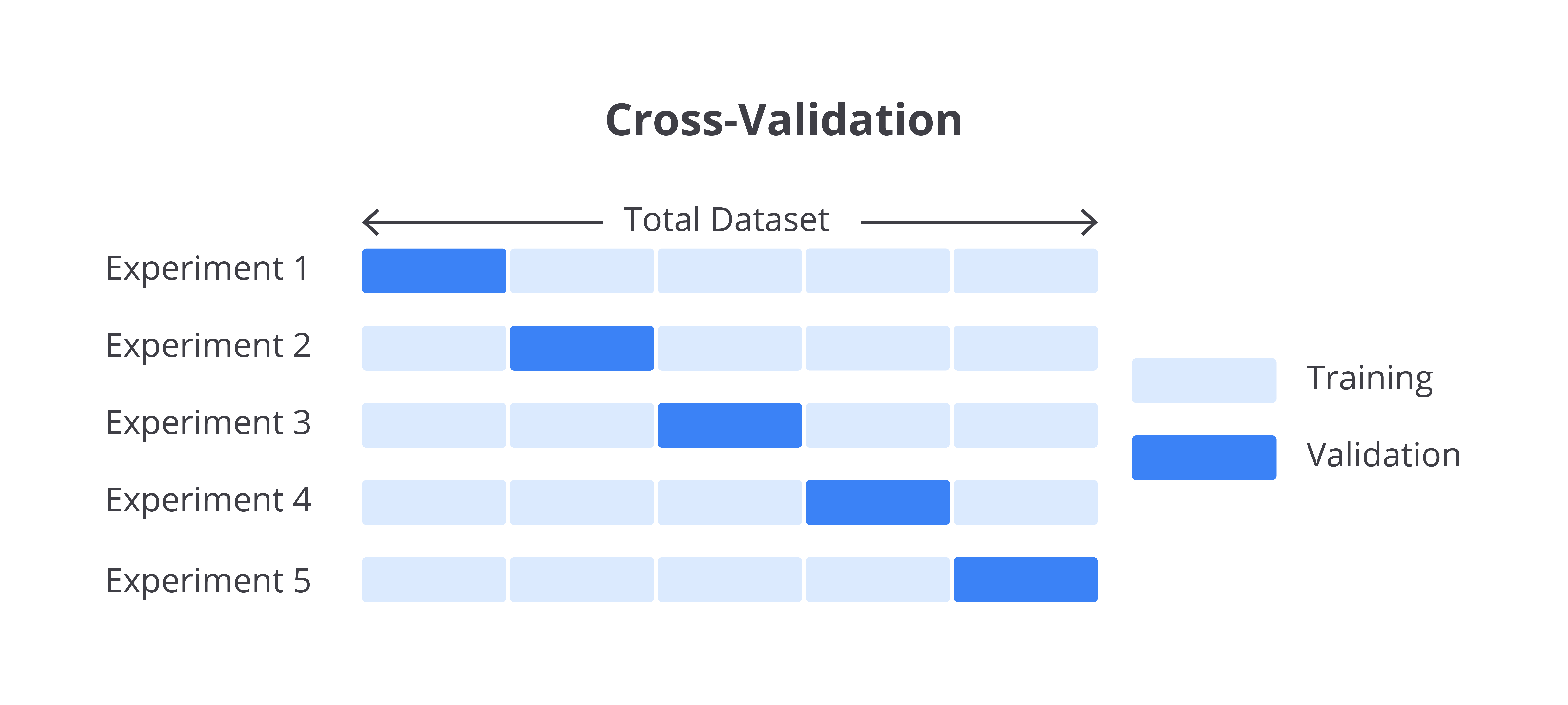
Cross-Validation
Teknik ini membagi data menjadi beberapa subset yang dikenal sebagai fold. Model dilatih dalam beberapa subset serta diuji pada subset yang tersisa dan proses ini diulang beberapa kali. Jika performa model sangat bervariasi antara fold, ini menunjukkan bahwa model mengalami overfitting pada subset data tertentu dan tidak dapat menggeneralisasi dengan baik. Cross-validation membantu memastikan bahwa model dinilai secara lebih konsisten di seluruh data.
Early Stopping
Early stopping adalah teknik yang digunakan dalam melatih model machine learning untuk mencegah overfitting. Overfitting terjadi ketika model belajar terlalu banyak dari data latih sampai-sampai tidak bisa bekerja dengan baik pada data baru.
Cara kerjanya cukup sederhana, yaitu ketika kita melatih model, data dibagi menjadi dua bagian, yaitu data training (data latih) dan data validation (data validasi). Model dilatih menggunakan data latih, sementara kita memantau kinerjanya menggunakan data validasi.
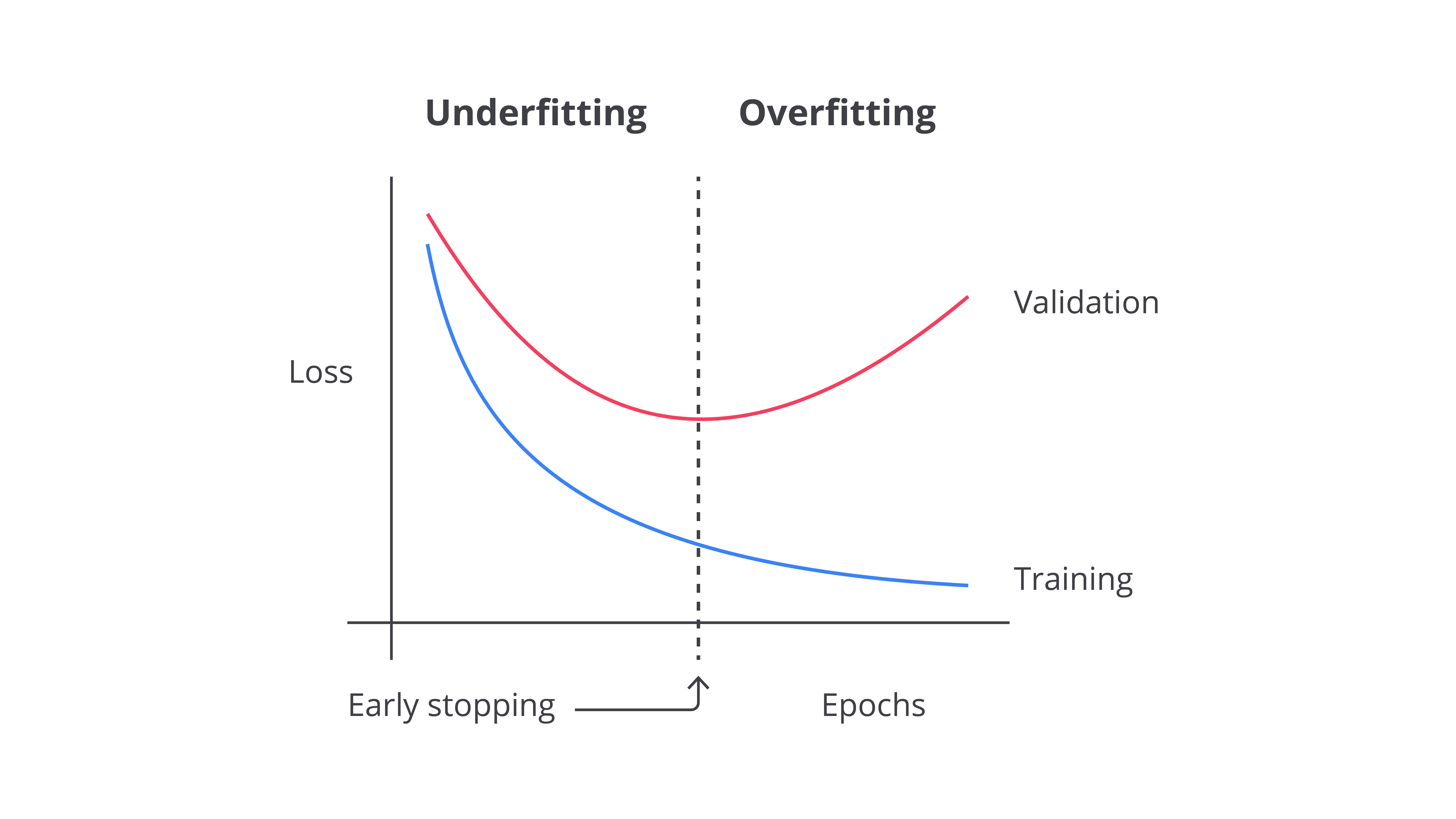 Jika performa model pada data validasi mulai memburuk (meskipun performanya dalam data latihan terus membaik), itu adalah tanda bahwa model mulai overfitting. Early stopping menghentikan pelatihan yang saat ini terjadi sehingga model tidak berlatih terlalu lama dan bisa bekerja lebih baik saat dihadapkan pada data baru.
Jika performa model pada data validasi mulai memburuk (meskipun performanya dalam data latihan terus membaik), itu adalah tanda bahwa model mulai overfitting. Early stopping menghentikan pelatihan yang saat ini terjadi sehingga model tidak berlatih terlalu lama dan bisa bekerja lebih baik saat dihadapkan pada data baru.
Intinya, early stopping memastikan kita berhenti melatih model pada saat yang tepat sebelum performa model turun karena belajar terlalu berlebihan.
Regularization
Regularization adalah teknik yang digunakan dalam machine learning untuk mengurangi kompleksitas model dan mencegah overfitting dengan menambahkan penalti pada ukuran koefisien model.
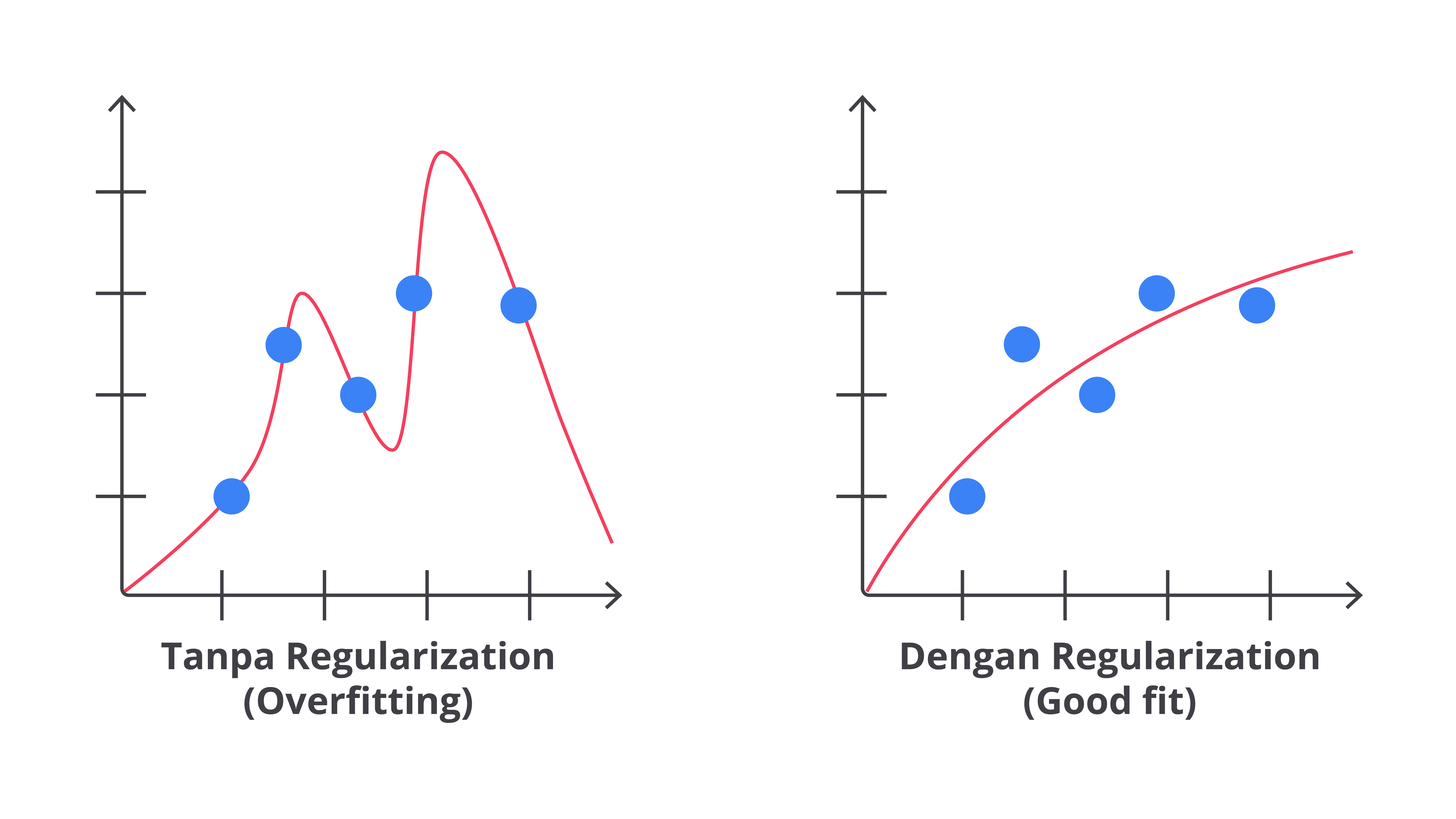
Tujuan utama dari regularisasi adalah menjaga model agar tetap sederhana dan menghindari penyesuaian yang berlebihan terhadap data pelatihan. Ini dilakukan dengan menambahkan suatu bentuk penalti terhadap ukuran atau kompleksitas model dalam fungsi biaya yang digunakan selama pelatihan. Berikut adalah penjelasan lebih rinci tentang teknik regularisasi yang umum digunakan.
Jenis-Jenis Regularization
Dalam regularization, ada tiga teknik yang umum digunakan. Teknik-teknik ini meliputi L1 Regularization (Lasso), L2 Regularization (Ridge), dan Elastic Net. Masing-masing teknik ini menawarkan cara berbeda untuk mengontrol kompleksitas model dan meningkatkan kemampuannya dalam menggeneralisasi pada data baru. Berikut adalah penjelasan mendetail tentang masing-masing teknik tersebut.
- L1 Regularization (Lasso)
L1 Regularization, atau Lasso, adalah cara untuk menyederhanakan model dengan mengurangi koefisien fitur yang kurang penting hingga menjadi nol. Ini artinya, fitur-fitur yang tidak relevan akan diabaikan oleh model.
Teknik ini membantu memilih fitur yang paling penting saja. Misalnya, jika Anda membangun model untuk memprediksi harga rumah serta memiliki banyak fitur, seperti ukuran rumah, lokasi, dan jumlah kamar, L1 regularisasi akan membantu memilih hanya fitur-fitur yang benar-benar berpengaruh pada harga rumah serta mengabaikan fitur yang tidak penting. - L2 Regularization (Ridge)
L2 Regularization, atau Ridge, menambahkan penalti untuk koefisien fitur yang terlalu besar. Dalam arti lain, teknik ini membuat model lebih sederhana dengan mengurangi ukuran koefisien, tetapi tidak menghilangkan fitur sama sekali.
L2 Regularization memastikan bahwa semua fitur berkontribusi pada model, tetapi tidak ada yang mendominasi terlalu banyak. Misalnya, dalam model harga rumah, L2 akan membantu memastikan bahwa tidak ada satu fitur yang terlalu berpengaruh dan menyebabkan model menjadi terlalu rumit. - Elastic Net
Elastic Net adalah campuran dari L1 dan L2 Regularization. Ia tidak hanya memilih fitur penting, seperti L1, tetapi juga mencegah fitur menjadi terlalu dominan, seperti L2.
Mengapa ini berguna? Kadang-kadang, banyak fitur yang saling berhubungan dalam penggunaan data. Misalnya, dalam model untuk memprediksi harga rumah, ada fitur-fitur yang terkait erat, seperti ukuran rumah dan jumlah kamar.
Jika kita hanya menggunakan L1, fitur-fitur ini bisa saling bertentangan dan menyebabkan model menjadi tidak stabil. Dengan Elastic Net, kita bisa memilih fitur paling penting tanpa kehilangan informasi dari fitur yang saling berhubungan serta memastikan model tetap stabil dan efektif.
Dropout
Dropout adalah penggunaan teknik untuk mencegah model neural network terlalu menyesuaikan diri dengan data latih, yang dikenal sebagai overfitting. Selama proses pelatihan, beberapa neuron dalam jaringan "dibuang" atau dinonaktifkan secara acak. Ini berarti neuron-neuron tidak berfungsi dalam perhitungan untuk sementara waktu.
Melalui cara ini, model tidak bergantung pada neuron tertentu dan harus belajar untuk bekerja dengan berbagai neuron yang tersedia. Hasilnya, model menjadi lebih fleksibel dan mampu mengenali pola yang lebih umum, bukan hanya detail spesifik dari data latih.
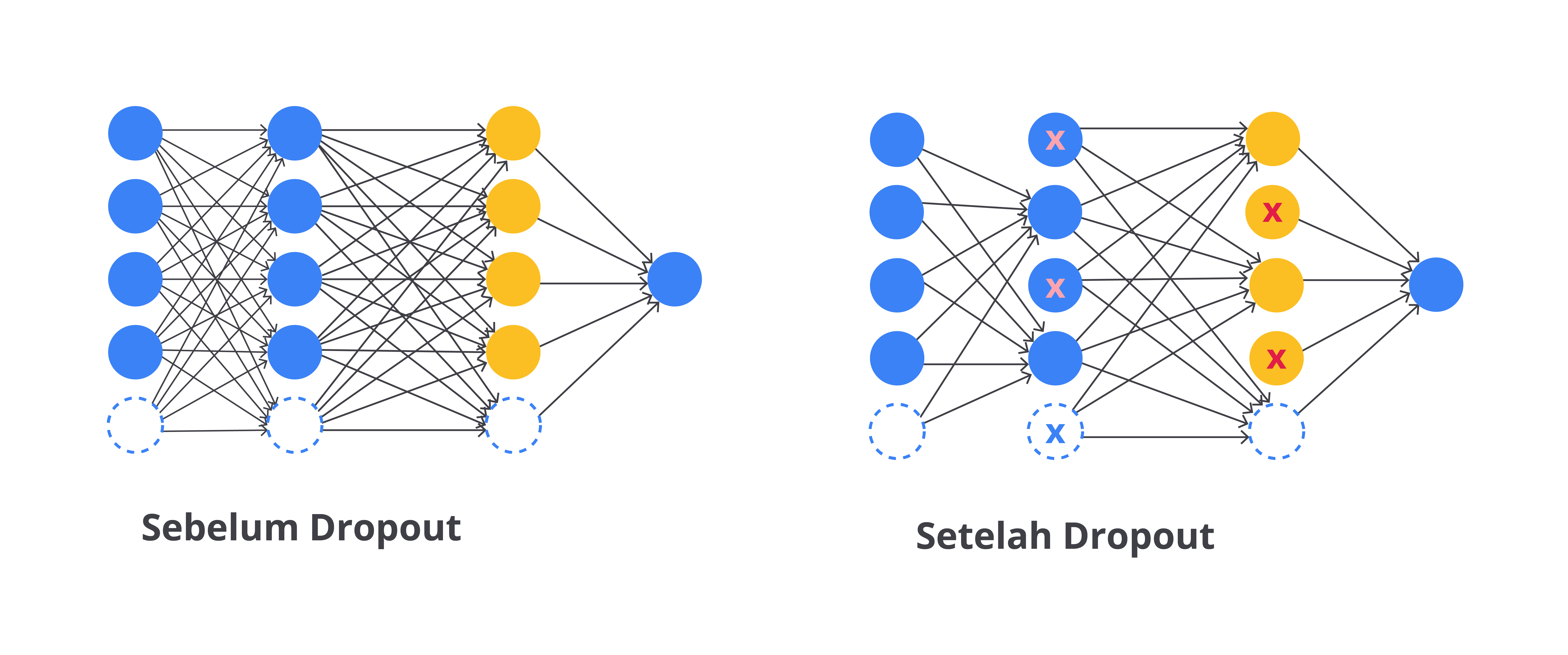
Ketika model siap digunakan untuk membuat prediksi, semua neuron akan diaktifkan kembali dan memungkinkan model menggunakan semua informasi yang dipelajari untuk membuat keputusan lebih akurat. Dropout membantu model belajar dengan lebih baik dan lebih tahan terhadap data baru yang mungkin berbeda dari data latih.
Data Augmentation
Data augmentation adalah teknik penting yang digunakan untuk meningkatkan jumlah dan variasi data pelatihan tanpa harus mengumpulkan data baru. Dengan membuat modifikasi atau variasi pada data yang sudah ada, teknik ini membantu model machine learning menjadi lebih tangguh dan mampu menangani berbagai situasi berbeda di dunia nyata.
Tentunya ini sangat berguna, terutama ketika data latih terbatas. Sebab, model yang dilatih pada data beragam cenderung memiliki kemampuan generalisasi lebih baik dan tidak mudah terjebak dalam overfitting.
Keuntungan utama dari data augmentation adalah model menjadi lebih robust dan adaptif terhadap variasi data.
Ini membuat model lebih baik dalam menangani data baru yang mungkin berbeda dari data latih, mengurangi risiko overfitting, dan memperbaiki performa model secara keseluruhan. Data augmentation juga mengurangi kebutuhan pengumpulan data baru yang bisa menjadi proses mahal dan memakan waktu.
Pruning
Pruning adalah teknik yang umumnya diterapkan pada pohon keputusan untuk menyederhanakan model dengan mengurangi kompleksitasnya. Tujuannya adalah meningkatkan kemampuan model dalam menggeneralisasi data baru dengan menghilangkan cabang-cabang pohon yang tidak memberikan kontribusi signifikan terhadap hasil akhir.
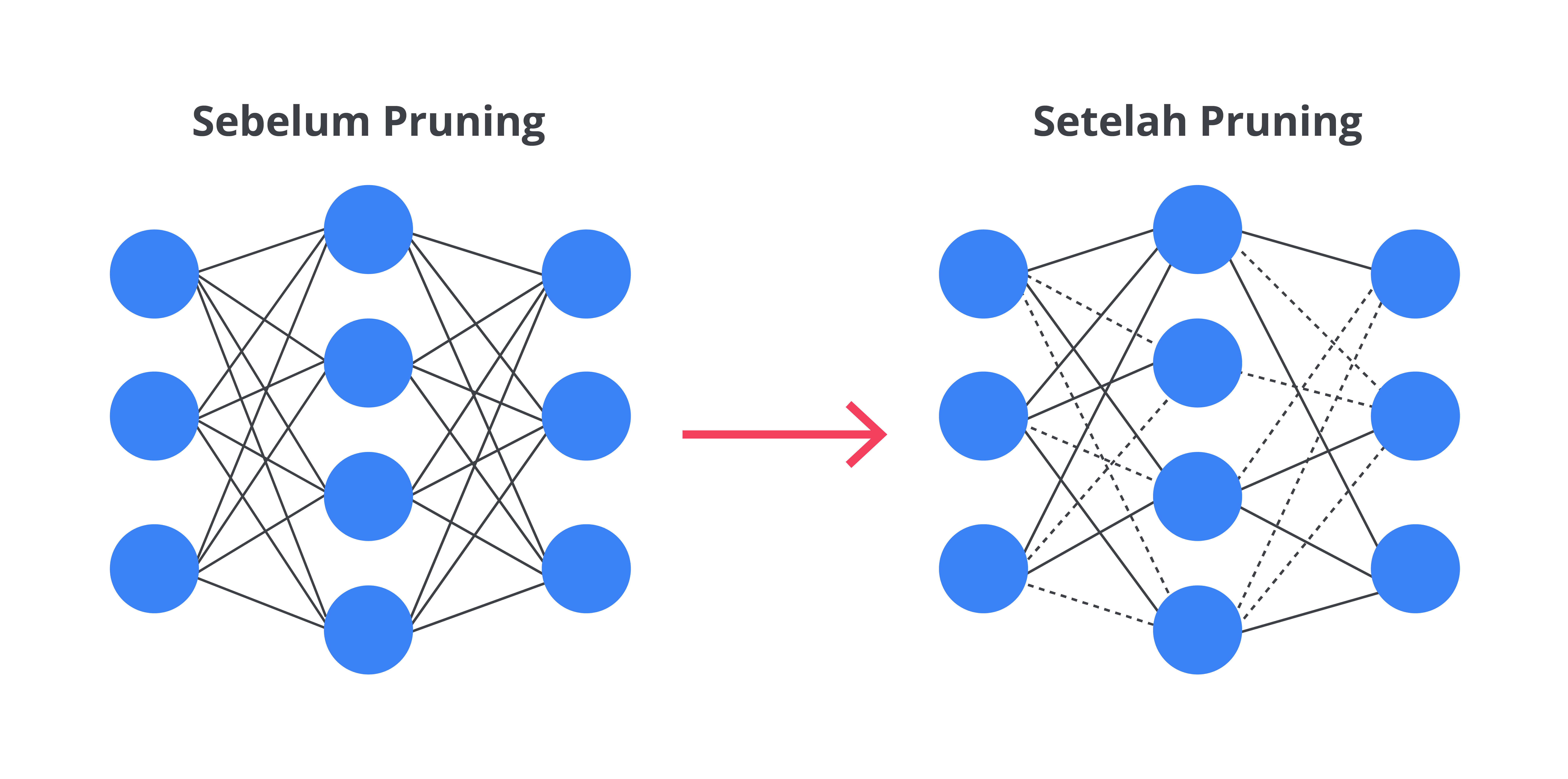
- Pre-Pruning: Dalam proses ini, kita menghentikan penambahan cabang baru ke pohon keputusan saat masa pelatihan. Misalnya, jika penambahan cabang baru tidak memberikan manfaat yang cukup atau kesalahan pada pohon tidak berkurang secara signifikan, kita akan menghentikan pembentukan cabang tersebut. Ini mencegah pohon tumbuh terlalu besar dan rumit. Dengan cara ini, kita membantu model agar tidak terlalu spesifik pada data latih sehingga mengurangi risiko overfitting.
- Post-Pruning: Setelah pohon keputusan selesai dibentuk, kita melakukan pemangkasan untuk menghapus cabang-cabang yang tidak banyak membantu dalam membuat keputusan. Caranya adalah memeriksa seberapa baik setiap cabang berkontribusi pada akurasi model. Cabang yang memberikan kontribusi kecil akan dihapus untuk menyederhanakan model.
Penerapan masing-masing metodenya akan kita bahas nanti dalam bagian Latihan, jadi jangan khawatir! Tetap semangat membaca materi ini, ya! Anda pasti bisa memahaminya dengan baik. Fighting!
Mengatasi Underfitting
Model yang mengalami underfitting akan memiliki akurasi rendah karena tidak mampu mempelajari hubungan penting antar fitur sehingga hasil prediksi kurang tepat. Oleh karena itu, penting untuk memahami cara-cara mengatasi underfitting agar model bisa memberikan hasil yang lebih akurat dan dapat diandalkan. Berikut adalah beberapa di antaranya.
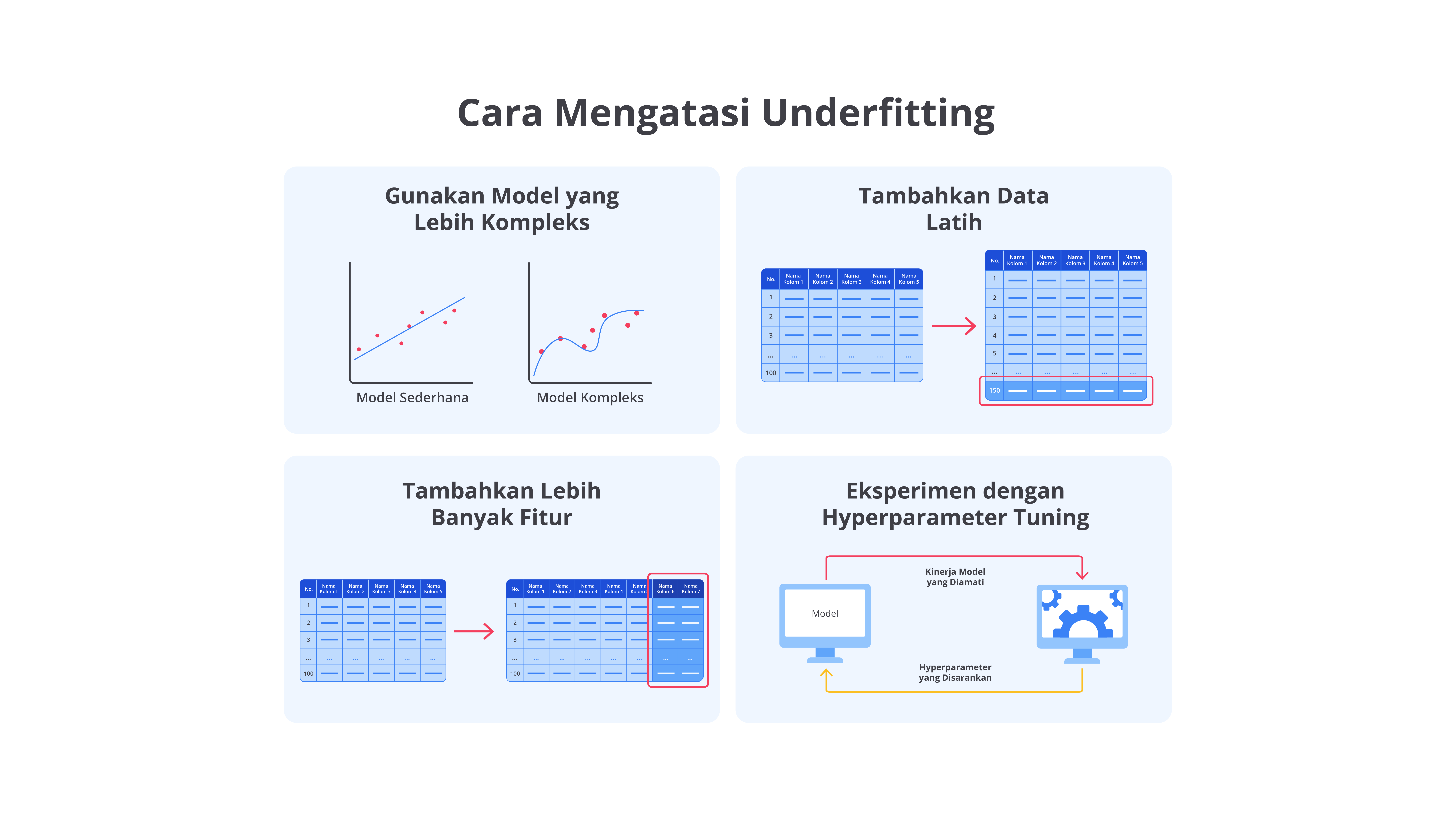
Gunakan Model yang Lebih Kompleks
Salah satu cara utama untuk mengatasi underfitting adalah menggunakan model yang lebih kompleks. Model sederhana, seperti regresi linear sering kali tidak cukup untuk menangkap hubungan yang kompleks antara fitur dan target dalam data Anda.
Misalnya, jika data Anda menunjukkan pola non-linear yang tidak dapat dijelaskan dengan baik oleh regresi linear, model yang lebih canggih dapat memberikan harapan lebih baik. Pertimbangkan untuk beralih ke model yang lebih kompleks, seperti decision trees, random forests, atau neural networks.
Decision Trees, dengan kemampuannya membagi data ke dalam berbagai cabang keputusan, sangat efektif untuk menangani interaksi fitur yang kompleks. Random Forests, yang merupakan ensemble dari banyak Decision Trees, lebih robust dalam menangkap variasi data dan menangani kompleksitas. Sementara itu, neural networks, dengan arsitektur yang memiliki banyak layer dan neuron, mampu menangkap pola yang sangat rumit serta abstrak dalam data.
Namun, penting untuk diingat bahwa menambah kompleksitas model tidak boleh dilakukan secara sembarangan. Terlalu banyak layer atau neuron pada neural networks atau terlalu dalamnya Decision Trees bisa menyebabkan overfitting, terutama jika tidak diimbangi dengan jumlah data yang cukup.
Jadi, meskipun menggunakan model yang lebih kompleks dapat membantu mengatasi underfitting, pastikan Anda mempertimbangkan keseimbangan antara kompleksitas model dan kualitas serta kuantitas data.
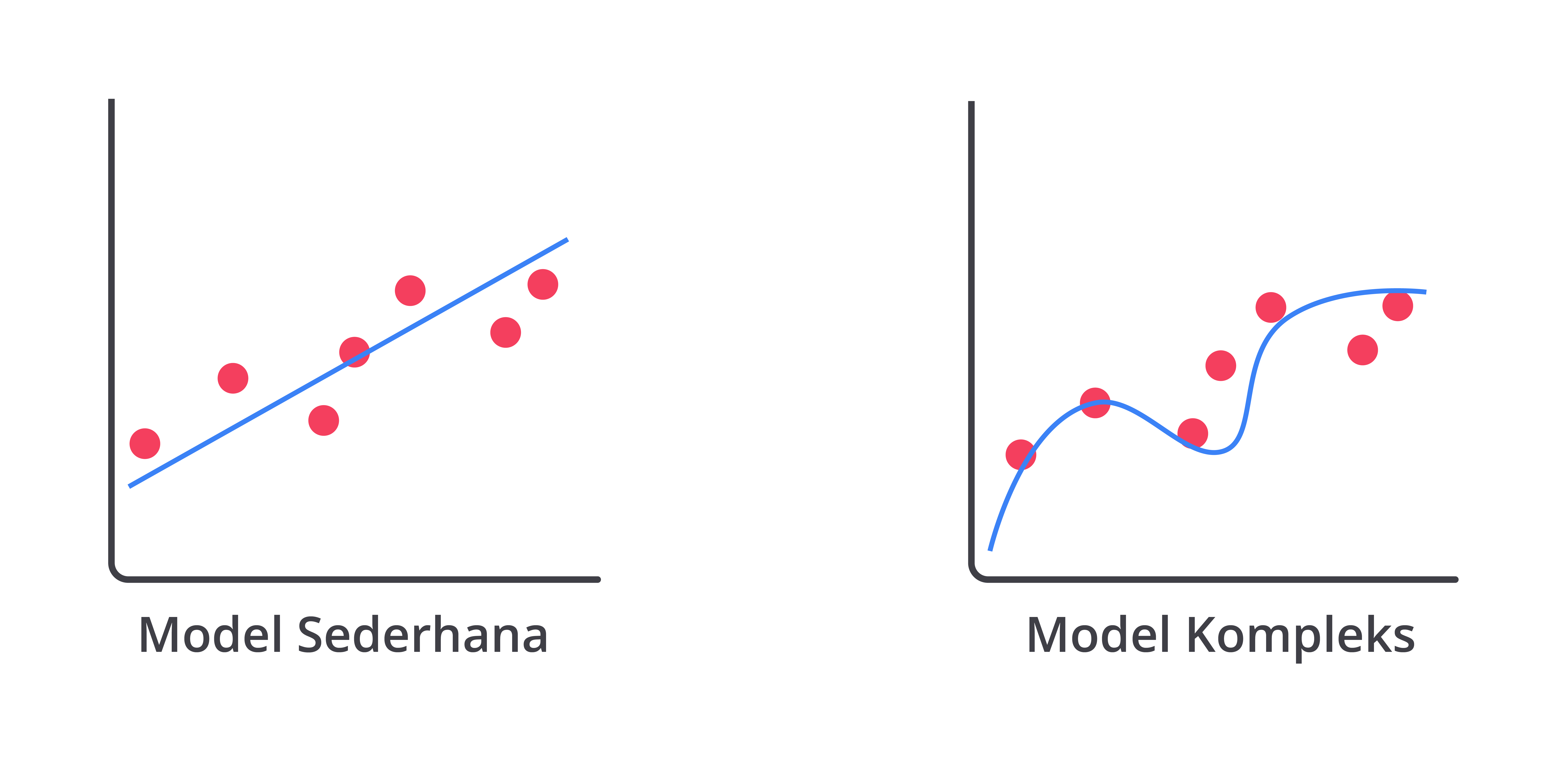
Tambahkan Data Latih
Menambahkan data latih adalah langkah penting untuk mengatasi underfitting dan ini dapat memberikan manfaat besar dalam meningkatkan kinerja model Anda. Jika model Anda mengalami underfitting, artinya ia tidak dapat menangkap pola atau hubungan yang relevan dalam data dengan baik. Salah satu cara untuk memperbaiki masalah ini adalah memberikan model lebih banyak data untuk dipelajari.
Ketika Anda menambahkan data latih, model memiliki kesempatan lebih besar untuk belajar dari berbagai variasi dan contoh dalam data. Ini memungkinkan model untuk menangkap pola lebih kompleks dan hubungan lebih detail yang mungkin terlewatkan ketika hanya memiliki data terbatas.
Menambahkan data latih untuk mengatasi underfitting bisa diibaratkan seperti seorang koki yang sedang belajar memasak hidangan baru. Bayangkan Anda adalah koki pemula yang hanya punya sedikit bahan dan instruksi sangat dasar. Dengan bahan terbatas, Anda hanya bisa membuat versi sangat sederhana dari hidangan tersebut, dan rasanya mungkin tidak memuaskan karena tidak punya cukup informasi tentang berbagai teknik atau bahan tambahan yang bisa membuat hidangan lebih lezat.

Sekarang, jika diberikan lebih banyak bahan dan kesempatan untuk berlatih dengan lebih banyak variasi resep, Anda akan lebih memahami cara mengombinasikan bahan, menyesuaikan rasa, serta mengenal lebih banyak teknik memasak. Setiap kali memasak dengan bahan berbeda, Anda mendapatkan lebih banyak wawasan tentang cara membuat hidangan yang lebih baik.
Hal ini serupa dengan menambahkan lebih banyak data latih ke model machine learning. Model Anda (seperti koki yang berlatih) dapat mempelajari lebih banyak pola serta hubungan dalam data yang akhirnya membantu model menjadi lebih akurat dan fleksibel.
Menambahkan data latih juga dapat membantu dalam mengurangi bias model dan meningkatkan kemampuannya untuk generalisasi. Dengan lebih banyak data, model tidak hanya belajar dari contoh tertentu, tetapi juga memahami tren umum dalam data. Jika menambahkan data latih tidak memungkinkan karena keterbatasan sumber daya atau waktu, Anda juga dapat menggunakan teknik augmentasi data, seperti rotasi atau flipping gambar untuk menciptakan variasi tambahan dari data yang sudah ada.
Penting untuk memastikan bahwa data yang Anda tambahkan relevan dan berkualitas tinggi. Data yang tidak relevan atau memiliki kualitas buruk dapat memperburuk masalah dan menyebabkan model belajar dari informasi tidak berguna. Jadi, pastikan Anda memeriksa dan memproses data tambahan dengan cermat sebelum digunakan untuk melatih model.
Tambahkan Lebih Banyak Fitur
Menambahkan lebih banyak fitur adalah strategi efektif lainnya untuk mengatasi underfitting. Dalam konteks ini, fitur adalah variabel atau atribut yang digunakan oleh model machine learning untuk membuat prediksi. Semakin relevan serta informatif fitur yang Anda sediakan, semakin baik model dalam memahami dan memprediksi hasil. Jika model Anda mengalami underfitting, bisa jadi fitur tidak cukup memberikan informasi yang diperlukan.
Analogi sederhananya, menambahkan lebih banyak fitur bisa disamakan dengan memberi lebih banyak petunjuk kepada seseorang yang sedang mencoba memecahkan teka-teki. Bayangkan Anda sedang mencoba menebak lokasi harta karun hanya berdasarkan satu petunjuk: "lokasinya dekat dengan pohon". Informasi ini sangat terbatas dan mungkin tidak cukup membantu.
Namun, jika diberikan petunjuk tambahan, seperti "di dekat sungai" dan "terdapat batu besar di sekitar", Anda bisa mendapatkan gambaran yang lebih jelas dan lebih akurat tentang letak harta karun tersebut berada. Pada kasus machine learning, fitur tambahan berperan sebagai petunjuk tambahan untuk membantu model dalam menangkap hubungan yang lebih kompleks pada data.
Cara menambahkan fitur bisa dilakukan melalui teknik feature engineering, yaitu Anda menciptakan fitur baru dari fitur yang sudah ada. Namun, perlu diperhatikan bahwa menambah terlalu banyak fitur tanpa pemilihan yang tepat dapat menyebabkan model menjadi terlalu rumit dan sulit diinterpretasikan. Jika fitur yang tidak relevan ditambahkan, hal ini bisa mengganggu model dan malah menyebabkan overfitting, artinya model belajar terlalu spesifik dalam data latih serta tidak bisa digeneralisasi dengan baik pada data baru.
Eksperimen dengan Hyperparameter Tuning
Eksperimen dengan hyperparameter tuning adalah langkah penting dalam mengoptimalkan model machine learning untuk mengatasi underfitting. Setiap model memiliki hyperparameter sebagai parameter eksternal yang tidak diatur langsung oleh data, seperti jumlah pohon dalam Random Forest atau jumlah neuron pada neural networks.
Jika hyperparameter tidak diatur dengan baik, model bisa menjadi terlalu sederhana (underfitting) atau terlalu rumit (overfitting). Oleh karena itu, menyesuaikan hyperparameter dengan tepat bisa meningkatkan kinerja model secara signifikan.
Disclaimer dulu, ya, hal ini akan kita bahas lebih dalam pada Modul 8. Di sana kita akan menjelajahi berbagai teknik hyperparameter tuning yang efektif. Kita juga akan membahas cara memilih nilai yang optimal untuk mencapai keseimbangan antara underfitting dan overfitting. Dengan begitu, kita dapat memastikan model berfungsi dengan baik dan memberikan hasil yang maksimal.
Ibaratnya, melakukan hyperparameter tuning seperti menyetel alat musik gitar. Jika senar gitar terlalu longgar, suara yang dihasilkan akan terlalu rendah, tetapi jika terlalu kencang, suaranya akan terlalu tinggi.
Demikian juga, jika hyperparameter seperti learning rate terlalu kecil, model akan belajar sangat lambat dan tidak akan menemukan pola yang kompleks dalam data; ini bisa menyebabkan underfitting. Sebaliknya, jika terlalu besar, model mungkin akan "melompat-lompat" melewatkan pola penting, bahkan bisa berujung pada overfitting.
Sebagai contoh, dalam neural networks, Anda bereksperimen dengan ukuran batch, jumlah epoch, dan learning rate untuk menemukan kombinasi yang memberikan hasil terbaik pada data validasi. Dalam SVM (Support Vector Machine), Anda mencoba berbagai nilai untuk C (regularization) dan gamma untuk mencapai performa optimal. Eksperimen dengan hyperparameter tuning bukan hanya soal meningkatkan akurasi, tetapi juga tentang membuat model lebih robust dan dapat digeneralisasi secara baik ke data baru.
Praktik: Studi Kasus Overfitting dan Underfitting
Setelah mendalami berbagai teori mengenai overfitting dan underfitting, rasanya belum lengkap jika kita tidak menerjemahkan teori-teori tersebut ke dalam implementasi kode. Namun, sebelum kita melanjutkan ke tahap praktik ini, izinkan kami mengucapkan selamat dan terima kasih kepada Anda. Kami menghargai upaya dan ketekunan Anda dalam mempelajari machine learning hingga modul 7.
Tentu saja, perjalanan ini tidaklah mudah. Namun, seperti yang dikatakan oleh Nelson Mandela, "It always seems impossible until it's done." Ketekunan dan tekad Anda yang kuat telah mengubah tantangan menjadi pencapaian nyata.
Sekarang, saatnya untuk membawa pemahaman Anda tentang overfitting dan underfitting ke dalam praktik dengan coding. Dengan keterampilan yang telah dikuasai, Anda siap untuk menghadapi tantangan berikutnya dalam dunia machine learning. Teruslah maju karena setiap langkah yang diambil mendekatkan Anda pada kemampuan lebih mendalam dan solusi yang lebih inovatif! Break a leg, ya!
Tanpa menunggu lama, mari kita mulai!
Import Library
Pertama, kita mengimpor pustaka-pustaka yang diperlukan untuk menjalankan analisis data dan pemodelan machine learning. Dalam kode ini, kita menggunakan kode berikut.
- import numpy as np
- import pandas as pd
- from sklearn.datasets import fetch_california_housing
- from sklearn.model_selection import train_test_split, cross_val_score, learning_curve
- from sklearn.preprocessing import StandardScaler
- from sklearn.tree import DecisionTreeRegressor
- from sklearn.metrics import mean_squared_error
- import matplotlib.pyplot as plt
Pada tahapan awal, kita mengimpor pustaka-pustaka penting untuk analisis data serta pemodelan machine learning, termasuk numpy dan pandas dalam manipulasi data, serta sklearn untuk akses dataset dan alat pemodelan. Dataset fetch_california_housing digunakan untuk mendapatkan data harga rumah yang kemudian dibagi menjadi set pelatihan dan pengujian.
Data dinormalisasi menggunakan StandardScaler untuk memastikan fitur memiliki skala yang seragam. Model regresi Decision Tree (DecisionTreeRegressor) dilatih pada data pelatihan dan kinerjanya dievaluasi dengan mean_squared_error. Akhirnya, hasil analisis divisualisasikan menggunakan matplotlib.pyplot untuk memberikan gambaran yang jelas tentang performa model.
Memuat Dataset untuk Kasus Overfitting
Selanjutnya, kita memuat dataset California Housing menggunakan fetch_california_housing() dari pustaka sklearn. Data ini disimpan dalam variabel X sebagai DataFrame untuk fitur-fitur dan y sebagai Series untuk target harga rumah. Selanjutnya, data dinormalisasi menggunakan StandardScaler untuk memastikan semua fitur memiliki skala yang seragam sehingga memudahkan proses pelatihan model.
Dataset kemudian dibagi menjadi dua bagian, yaitu data latih serta data uji dengan rasio 70% untuk pelatihan dan 30% untuk pengujian menggunakan train_test_split. Ini penting untuk mengevaluasi kinerja model pada data yang belum pernah dilihat sebelumnya.
- # Load dataset California Housing
- data = fetch_california_housing()
- X = pd.DataFrame(data.data, columns=data.feature_names)
- y = pd.Series(data.target)
- # Normalisasi data
- scaler = StandardScaler()
- X_scaled = scaler.fit_transform(X)
- # Membagi dataset menjadi data latih dan data uji
- X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
Model DecisionTreeRegressor diinisialisasi dengan parameter max_depth=50 untuk membatasi kedalaman pohon keputusan, yang sering kali digunakan untuk mengatasi overfitting. Model ini kemudian dilatih pada data latih menggunakan metode fit(). Setelah pelatihan, model digunakan untuk membuat prediksi pada data latih serta data uji, menghasilkan y_train_pred dan y_test_pred yang akan digunakan untuk evaluasi lebih lanjut dari kinerja model.
- # Inisialisasi model Decision Tree Regressor
- model = DecisionTreeRegressor(max_depth=50, random_state=42)
- # Melatih model dengan data latih
- model.fit(X_train, y_train)
- # Membuat prediksi untuk data latih dan data uji
- y_train_pred = model.predict(X_train)
- y_test_pred = model.predict(X_test)
Mendeteksi Overfitting
Untuk mendeteksi overfitting, kita perlu membandingkan performa model pada data latih dan data uji. Overfitting terjadi ketika model bekerja sangat baik pada data latih, tetapi menunjukkan kinerja yang buruk pada data uji karena model terlalu menyesuaikan diri dengan data latih.
1. Evaluasi Performa pada Data Latih dan Data Uji
Pertama, kita menghitung Mean Squared Error (MSE) untuk data latih dan data uji. MSE adalah metrik yang mengukur rata-rata kuadrat perbedaan antara nilai prediksi dan nilai sebenarnya. Semakin rendah nilai MSE, semakin baik performa model dalam memprediksi data.
- # Menghitung Mean Squared Error (MSE) untuk data latih dan data uji
- train_mse = mean_squared_error(y_train, y_train_pred)
- test_mse = mean_squared_error(y_test, y_test_pred)
- # Menampilkan hasil MSE
- print(f'Training MSE: {train_mse}')
- print(f'Test MSE: {test_mse}')
Dalam kode ini, mean_squared_error digunakan dalam menghitung MSE untuk prediksi pada data latih (y_train_pred) dan data uji (y_test_pred). Hasilnya kemudian ditampilkan untuk memberikan gambaran tentang performa model pada kedua set data.
- Training MSE: MSE pada data latih menunjukkan seberapa baik model memprediksi data yang telah dilihat selama pelatihan. Nilai MSE yang sangat rendah pada data latih dapat menunjukkan bahwa model terlalu menyesuaikan diri dengan data tersebut.
- Test MSE: MSE pada data uji menunjukkan seberapa baik model memprediksi data baru yang belum pernah dilihat sebelumnya. Jika MSE dalam data uji jauh lebih tinggi dibandingkan dengan pada data latih, ini adalah indikator overfitting.
Dengan membandingkan MSE pada data latih dan data uji, kita dapat mengidentifikasi model mengalami overfitting atau tidak. Model yang baik seharusnya memiliki nilai MSE relatif seimbang antara data latih dan data uji. Jika terjadi perbedaan yang signifikan, mungkin perlu mempertimbangkan untuk menyederhanakan model atau melakukan teknik regularisasi untuk mengurangi overfitting.
Hasilnya sebagai berikut.
Training MSE: 9.904697258622977e-32 Test MSE: 0.5265256772490148 |
Hasil evaluasi model menunjukkan bahwa Training MSE sebesar 9.90e-32 mengindikasikan performa yang sangat baik pada data latih dengan kesalahan prediksi hampir mendekati nol. Namun, Test MSE sebesar 0.5265 yang lebih tinggi menunjukkan bahwa model tidak dapat memprediksi data uji dengan akurat.
Perbedaan signifikan antara kedua nilai MSE ini mengindikasikan bahwa model mengalami overfitting, yaitu ketika model terlalu menyesuaikan diri dengan data latih sehingga gagal dalam generalisasi pada data baru.
2. Learning Curve
Cara yang lain untuk mengidentifikasi overfitting adalah menampilkan learning curve. Kode ini menggunakan fungsi learning_curve dari pustaka sklearn.model_selection untuk menghitung learning curve.
Fungsi ini memproses model DecisionTreeRegressor pada berbagai ukuran set pelatihan dan menghitung skor MSE menggunakan cross-validation (dengan cv=5 yang berarti 5-fold cross-validation). Parameter scoring='neg_mean_squared_error' digunakan untuk mengevaluasi model berdasarkan MSE dan n_jobs=-1 memungkinkan perhitungan paralel untuk mempercepat proses pelatihan.
- from sklearn.model_selection import learning_curve
- import matplotlib.pyplot as plt
- # Menghitung learning curve
- train_sizes, train_scores, test_scores = learning_curve(model, X_train, y_train, cv=5, scoring='neg_mean_squared_error', n_jobs=-1)
- # Menghitung rata-rata dan standar deviasi
- train_mean = -np.mean(train_scores, axis=1)
- test_mean = -np.mean(test_scores, axis=1)
- # Plot learning curve
- plt.plot(train_sizes, train_mean, 'o-', color="blue", label="Training error")
- plt.plot(train_sizes, test_mean, 'o-', color="green", label="Cross-validation error")
- plt.title("Learning Curve")
- plt.xlabel("Training Set Size")
- plt.ylabel("MSE")
- plt.legend()
- plt.show()
Learning curve membantu kita memahami jika model sedang mengalami overfitting atau underfitting. Jika kesalahan pelatihan sangat rendah, tetapi kesalahan validasi silang tetap tinggi atau tidak menurun seiring bertambahnya data pelatihan, ini mengindikasikan overfitting.
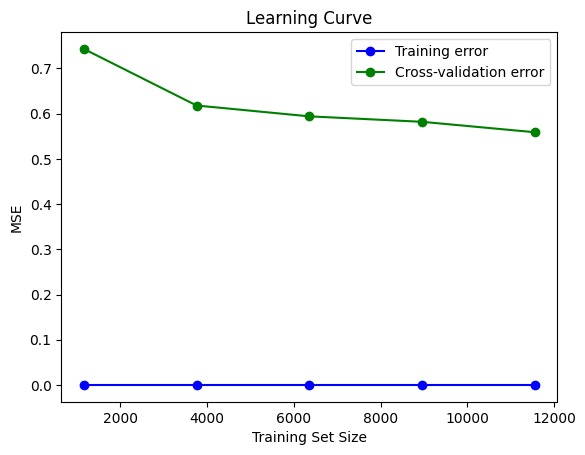
Pada gambar di atas, dapat kita lihat bahwa learning curve menunjukkan jarak yang sangat jauh antara training error dan cross-validation error, hal ini memberikan indikasi jelas bahwa terjadi overfitting.
Setelah mengidentifikasi bahwa model mengalami overfitting, langkah selanjutnya adalah mencari solusi untuk memperbaiki masalah tersebut dan meningkatkan kemampuan model dalam memprediksi data baru. Apa saja cara yang bisa dilakukan? Simak terus, ya, materinya!
Mengatasi Overfitting
Mengatasi overfitting adalah langkah penting untuk memastikan model machine learning Anda dapat bekerja dengan baik tidak hanya pada data latih, tetapi juga dalam data baru. Overfitting terjadi ketika model terlalu menyesuaikan diri dengan data latih sehingga menghasilkan performa yang sangat baik pada data tersebut, tetapi buruk dalam data uji.
Dengan kata lain, model terlalu kompleks dan menangkap noise atau detail yang tidak relevan dalam data latih. Untuk menangani overfitting, kita dapat menggunakan berbagai teknik untuk menyederhanakan model dan meningkatkan kemampuannya dalam generalisasi.
Di bawah ini, kita akan membahas beberapa metode yang dapat diterapkan untuk mengatasi masalah tersebut serta membuat model Anda lebih robust dan efektif!
1. Cross-Validation
Salah satu cara efektif untuk mengatasi overfitting adalah penggunaan cross-validation. Teknik ini membantu menilai seberapa baik model dapat menggeneralisasi data baru dengan membagi data pelatihan menjadi beberapa subset dan melatih serta menguji model secara bergantian pada subset yang berbeda. Ini memberikan gambaran yang lebih komprehensif tentang kinerja model dan mengurangi risiko overfitting.
Berikut adalah implementasi cross-validation menggunakan 5-fold cross-validation dengan model yang telah dilatih.
- from sklearn.model_selection import cross_val_score
- # Menggunakan cross-validation dengan 5 fold
- cross_val_scores = cross_val_score(model, X_train, y_train, cv=5, scoring='neg_mean_squared_error')
- # Menampilkan hasil cross-validation
- print(f'Cross-Validation MSE: {-cross_val_scores.mean()}')
cross_val_score mengevaluasi model menggunakan metode cross-validation dengan membagi data menjadi 5 bagian. Pada setiap langkah, model dilatih dengan 4 bagian data dan diuji dengan 1 bagian sisanya. Proses ini dilakukan sebanyak 5 kali sehingga setiap bagian data berkesempatan menjadi data uji.
Parameter scoring='neg_mean_squared_error' digunakan untuk menghitung Mean Squared Error (MSE) model dan hasilnya dibalik agar menjadi positif. MSE dari setiap percobaan kemudian dirata-ratakan untuk memberikan gambaran kinerja model secara keseluruhan.
Setelah menggunakan cross-validation, hasil Cross-Validation MSE sebesar 0.556 didapatkan. Sebelumnya, model menunjukkan hasil Training MSE yang sangat kecil, yaitu 9.90 × 10⁻³² dan Test MSE sebesar 0.526. Hasil ini menunjukkan bahwa sebelum cross-validation, model mengalami overfitting karena performanya hampir sempurna pada data latih (training), tetapi tidak begitu baik dalam data uji (test).
Dengan cross-validation, performa model diuji lebih menyeluruh dan lebih adil karena data dibagi menjadi beberapa bagian untuk diuji secara bergantian. Hasil Cross-Validation MSE yang lebih mendekati Test MSE (0.556 vs. 0.526) menunjukkan bahwa model lebih konsisten dan mampu menghindari overfitting. Ini berarti model kini lebih baik dalam memprediksi data baru dan lebih stabil ketika diuji dengan data yang berbeda.
Meskipun hasil Cross-Validation MSE sudah lebih stabil, kita masih melihat adanya perbedaan cukup besar dengan Training MSE yang sangat kecil. Ini menunjukkan bahwa model kita masih belum optimal dan mungkin masih mengalami overfitting.
Oleh karena itu, mari kita coba metode lain untuk memperbaiki model!
2. Regularization (Max Depth, Min Samples Split, Min Samples Leaf)
Dalam langkah ini, kita mencoba cara lain, yaitu melakukan regularization atau regularisasi pada model Decision Tree untuk mengatasi overfitting. Regularisasi dilakukan dengan mengurangi kedalaman pohon keputusan (max_depth) menjadi 5. Ini bertujuan agar model tidak terlalu rumit dan lebih mampu menggeneralisasi data baru.
- # Membuat model Decision Tree dengan kedalaman yang lebih kecil
- model_reg = DecisionTreeRegressor(max_depth=5, random_state=42)
- model_reg.fit(X_train, y_train)
- # Evaluasi pada data latih dan uji
- y_train_pred_reg = model_reg.predict(X_train)
- y_test_pred_reg = model_reg.predict(X_test)
- # Hitung MSE
- train_mse_reg = mean_squared_error(y_train, y_train_pred_reg)
- test_mse_reg = mean_squared_error(y_test, y_test_pred_reg)
- print(f'Training MSE (After Regularization): {train_mse_reg}')
- print(f'Test MSE (After Regularization): {test_mse_reg}')
Sebelumnya, model Decision Tree tanpa regularisasi memberikan hasil sebagai berikut.
- Training MSE: 9.90 × 10⁻³² (hampir nol)
- Test MSE: 0.5265
Ini menunjukkan bahwa model sangat cocok (overfitting) pada data latih dengan kesalahan yang sangat kecil, tetapi kesalahan dalam data uji cukup tinggi. Perbedaan yang besar ini menunjukkan bahwa model terlalu rumit dan tidak mampu menggeneralisasi dengan baik saat berhadapan dengan data baru.
Setelah menerapkan regularisasi pada model Decision Tree, hasil sebagai berikut didapatkan.
- Training MSE (Setelah Regularisasi): 0.4928
- Test MSE (Setelah Regularisasi): 0.5211
Hasil ini menunjukkan peningkatan dibandingkan sebelumnya, yaitu perbedaan antara Training MSE dan Test MSE menjadi lebih kecil. Ini berarti model telah menjadi lebih seimbang dan tidak lagi terlalu fokus pada data latih (overfitting) karena performa dalam data uji sekarang lebih mendekati performa pada data latih. Regularisasi berhasil membuat model lebih mampu memprediksi data baru dengan lebih akurat.
3. Pruning (Pruning Manual pada Kedalaman Pohon)
Cara ketiga, kita mencoba metode pruning untuk mengatasi overfitting pada Decision Tree. Teknik yang digunakan adalah Cost Complexity Pruning dengan parameter ccp_alpha. Ini memungkinkan kita memangkas cabang-cabang pohon yang kurang penting. Semakin besar nilai ccp_alpha, semakin banyak pemangkasan dilakukan.
- # Menggunakan ccp_alpha untuk pruning (Cost Complexity Pruning)
- path = model.cost_complexity_pruning_path(X_train, y_train)
- ccp_alphas = path.ccp_alphas
- # Melatih model dengan pruning
- model_pruned = DecisionTreeRegressor(random_state=42, ccp_alpha=ccp_alphas[-2])
- model_pruned.fit(X_train, y_train)
- # Membuat prediksi
- y_train_pred_pruned = model_pruned.predict(X_train)
- y_test_pred_pruned = model_pruned.predict(X_test)
- # Menghitung MSE
- train_mse_pruned = mean_squared_error(y_train, y_train_pred_pruned)
- test_mse_pruned = mean_squared_error(y_test, y_test_pred_pruned)
- print(f'Pruned Model Training MSE: {train_mse_pruned}')
- print(f'Pruned Model Test MSE: {test_mse_pruned}')
Pada model Decision Tree tanpa regularisasi, hasilnya berikut.
- Training MSE: 9.90 × 10⁻³² (hampir nol)
- Test MSE: 0.5265
Hasil ini menunjukkan adanya overfitting yang sangat jelas. MSE pada data latih hampir nol, artinya model sangat sesuai dengan data latih (overfitted), tetapi performanya dalam data uji tidak begitu baik dengan MSE sebesar 0.5265. Ini menunjukkan bahwa model tidak dapat melakukan generalisasi secara baik terhadap data baru karena terlalu rumit dan terlalu pas dengan data latih.
Setelah melakukan pruning pada model Decision Tree, hasil yang diperoleh sebagai berikut.
- Pruned Model Training MSE: 0.9189
- Pruned Model Test MSE: 0.9194
Hasil ini menunjukkan bahwa setelah diterapkan pruning, kesalahan pada data latih dan data uji menjadi hampir sama. Ini adalah tanda bahwa model telah berhasil mengurangi overfitting karena perbedaan antara MSE pada data latih dan data uji sudah sangat kecil. Meskipun nilai MSE pada data latih meningkat dibandingkan model sebelumnya, kemampuan model untuk melakukan generalisasi dalam data baru menjadi lebih baik dan lebih stabil.
4. Data Augmentation
Cara keempat yang bisa dicoba adalah augmentasi data. Data augmentation adalah penggunaan teknik untuk meningkatkan kualitas dan kemampuan model dengan membuat variasi tambahan dari data yang sudah ada.
Dalam contoh ini, kita melakukan augmentasi dengan menambahkan sedikit noise atau gangguan pada data latih. Noise ini adalah gangguan acak yang tidak signifikan, tetapi cukup untuk memberikan variasi pada data latih kita.
- # Menambahkan sedikit noise ke data sebagai augmentasi
- X_train_aug = X_train + np.random.normal(0, 0.1, X_train.shape)
- # Melatih ulang model dengan augmented data
- model_aug = DecisionTreeRegressor(max_depth=10, random_state=42)
- model_aug.fit(X_train_aug, y_train)
- # Membuat prediksi
- y_train_pred_aug = model_aug.predict(X_train_aug)
- y_test_pred_aug = model_aug.predict(X_test)
- # Menghitung MSE
- train_mse_aug = mean_squared_error(y_train, y_train_pred_aug)
- test_mse_aug = mean_squared_error(y_test, y_test_pred_aug)
- print(f'Augmented Data Training MSE: {train_mse_aug}')
- print(f'Augmented Data Test MSE: {test_mse_aug}')
Setelah menerapkan data augmentation dengan menambahkan noise pada data latih, hasil yang diperoleh sebagai berikut.
- Augmented Data Training MSE: 0.3193
- Augmented Data Test MSE: 0.5219
Sebelumnya, model tanpa augmentasi menunjukkan sebagai berikut.
- Training MSE: 9.90 × 10⁻³² (hampir nol)
- Test MSE: 0.5265
Dari hasil tersebut, kita dapat melihat perubahan signifikan setelah data augmentation. Sebelumnya, Training MSE sangat rendah, mendekati nol, menunjukkan overfitting yang besar. Dengan menerapkan data augmentation, Training MSE naik menjadi 0.3193.
Ini menunjukkan bahwa model sekarang lebih general dan tidak terlalu pas dengan data latih. Test MSE tetap hampir sama pada 0.5219, yang menunjukkan performa model dalam data uji tidak banyak berubah.
Secara keseluruhan, data augmentation membantu mengurangi overfitting dengan membuat model lebih adaptif terhadap variasi dalam data latih meskipun hasil pada data uji tetap stabil.
5. Dropout
Cara selanjutnya yang bisa Anda pilih adalah dropout.
Dropout adalah teknik regulasi yang digunakan untuk mencegah overfitting dalam model machine learning, khususnya neural networks. Teknik ini bekerja dengan "menghilangkan" beberapa neuron secara acak selama pelatihan sehingga model tidak terlalu bergantung pada neuron tertentu dan belajar untuk membuat keputusan berdasarkan fitur yang lebih robust.
Namun, untuk masalah yang kita hadapi, yaitu model Decision Tree, kita tidak dapat menerapkan dropout secara langsung. Sebagai gantinya, kita menggunakan pendekatan lain yang mirip, yaitu Random Forest. Random Forest adalah ensemble method yang menggunakan banyak pohon keputusan untuk meningkatkan kinerja model dan mengurangi overfitting.
- from sklearn.ensemble import RandomForestRegressor
- # Inisialisasi Random Forests dengan n_estimators (jumlah pohon)
- model_rf = RandomForestRegressor(n_estimators=100, max_depth=10, random_state=42)
- # Melatih model
- model_rf.fit(X_train, y_train)
- # Membuat prediksi
- y_train_pred_rf = model_rf.predict(X_train)
- y_test_pred_rf = model_rf.predict(X_test)
- # Menghitung MSE
- train_mse_rf = mean_squared_error(y_train, y_train_pred_rf)
- test_mse_rf = mean_squared_error(y_test, y_test_pred_rf)
- print(f'Random Forest Training MSE: {train_mse_rf}')
- print(f'Random Forest Test MSE: {test_mse_rf}')
Hasil dari penerapan Random Forest sebagai berikut.
- Training MSE: 0.1694
- Test MSE: 0.2945
Sebelumnya, model Decision Tree menunjukkan Training MSE yang sangat kecil, yaitu 9.90 × 10⁻³² dan Test MSE sebesar 0.5265; ini mengindikasikan adanya overfitting. Dengan menerapkan Random Forest, hasil MSE pada data latih adalah 0.1694 dan data uji adalah 0.2945.
Meskipun MSE dalam data latih sedikit meningkat dibandingkan dengan model awal, MSE pada data uji menunjukkan penurunan yang signifikan. Ini menandakan bahwa model Random Forest lebih baik dalam mengatasi overfitting dan memberikan hasil yang lebih stabil saat diterapkan pada data baru.
6. Early Stopping
Terakhir, metode early stopping sering digunakan dalam neural networks untuk menghentikan pelatihan lebih awal jika model tidak menunjukkan perbaikan pada data validasi. Ini membantu menghindari overfitting dengan menghentikan proses pelatihan ketika model tidak lagi membaik.
Namun, early stopping juga bisa diterapkan pada model lain, seperti Decision Trees meskipun tidak langsung tersedia sebagai fitur. Untuk Decision Trees, kita bisa mengimplementasikannya secara manual dengan memantau kinerja model pada data validasi dan menghentikan pelatihan jika performa tidak meningkat.
Selain itu, karena dalam kelas ini kita fokus pada machine learning dan bukan deep learning, kita akan mengeksplorasi cara-cara lain untuk menangani masalah overfitting dan meningkatkan performa model, seperti regularization, cross-validation, serta teknik lain yang relevan dengan machine learning.
Jika Anda ingin menerapkan early stopping secara manual pada Decision Trees atau model regresi lain, ini bisa dilakukan dalam konteks teknik pembelajaran iteratif, seperti Gradient Boosting. Dalam gradient boosting, early stopping dapat diatur dengan memantau kinerja model secara terus-menerus dan menghentikan pelatihan jika tidak ada perbaikan setelah beberapa iterasi.
Anda tidak perlu menerapkan semua metode ini sekaligus dalam setiap kasus. Sebaiknya pilih metode paling sesuai dengan studi kasus dan model yang dibangun. Masing-masing metode, seperti regularization, cross-validation, data augmentation, atau teknik lainnya, memiliki kegunaan dan efek yang berbeda.
Jadi, penting untuk menilai cara yang paling efektif untuk meningkatkan kinerja model Anda dalam konteks tertentu. Pilihan yang tepat akan membantu Anda mencapai hasil optimal tanpa memperumit proses atau membuat model menjadi terlalu rumit, ya.
Rangkuman Hasil Mengatasi Overfitting
Berikut adalah rangkuman penerapan metode untuk mengatasi overfitting pada model Decision Tree serta hasil yang diperoleh dari masing-masing metode.
1. Cross-Validation
Mengukur seberapa baik model dapat menggeneralisasi ke data baru dengan membagi data menjadi beberapa subset untuk pelatihan dan pengujian bergantian.
- Implementasi: Menggunakan 5-fold cross-validation.
- Hasil:
- Cross-Validation MSE: 0.556
- Perbandingan: Sebelumnya, Training MSE = 9.90 × 10⁻³² dan Test MSE = 0.526.
Cross-validation menunjukkan performa model yang lebih konsisten, tetapi masih ada perbedaan signifikan antara Training MSE dan Test MSE. Ini menunjukkan potensi overfitting.
2. Regularization (Max Depth, Min Samples Split, Min Samples Leaf)
Tujuan: Mengurangi kompleksitas model untuk menghindari overfitting dengan mengatur parameter, seperti max_depth.
- Implementasi: Model dengan
max_depth=5. - Hasil:
- Training MSE (Setelah Regularisasi): 0.4928
- Test MSE (Setelah Regularisasi): 0.5211
- Perbandingan: Sebelumnya, Training MSE = 9.90 × 10⁻³² dan Test MSE = 0.5265.
Regularisasi mengurangi perbedaan antara Training MSE dan Test MSE. Ini membuat model lebih seimbang dan mampu generalisasi lebih baik.
3. Pruning (Cost Complexity Pruning)
Tujuan: Memangkas cabang pohon keputusan yang kurang penting untuk mengurangi overfitting.
- Implementasi: Menggunakan Cost Complexity Pruning dengan ccp_alpha.
- Hasil:
- Pruned Model Training MSE: 0.9189
- Pruned Model Test MSE: 0.9194
- Perbandingan: Sebelumnya, Training MSE = 9.90 × 10⁻³² dan Test MSE = 0.5265.
Pruning mengurangi overfitting dengan menyeimbangkan MSE antara data latih dan data uji meskipun nilai MSE meningkat, model lebih stabil.
4. Data Augmentation
Tujuan: Meningkatkan variasi data latih dengan menambahkan noise untuk membantu model generalisasi.
- Implementasi: Menambahkan noise ke data latih.
- Hasil:
- Augmented Data Training MSE: 0.3193
- Augmented Data Test MSE: 0.5219
- Perbandingan: Sebelumnya, Training MSE = 9.90 × 10⁻³² dan Test MSE = 0.5265.
Data augmentation mengurangi overfitting dengan meningkatkan Training MSE, tetapi Test MSE tetap stabil.
5. Random Forest
Tujuan: Mengurangi overfitting dengan menggunakan ensemble metode (Random Forest) yang menggabungkan banyak pohon keputusan.
- Implementasi: Menggunakan Random Forest dengan 100 pohon.
- Hasil:
- Random Forest Training MSE: 0.1694
- Random Forest Test MSE: 0.2945
- Perbandingan: Sebelumnya, Training MSE = 9.90 × 10⁻³² dan Test MSE = 0.5265.
Random Forest menunjukkan penurunan signifikan dalam MSE pada data uji. Ini menandakan kemampuan model dalam mengatasi overfitting dengan hasil yang lebih stabil.
6. Early Stopping
Tujuan: Menghentikan pelatihan lebih awal untuk menghindari overfitting. Ini sering diterapkan dalam neural networks dan tidak langsung tersedia untuk Decision Trees, tetapi bisa diadaptasi dalam konteks teknik pembelajaran iteratif, seperti Gradient Boosting.
- Implementasi: Tidak diterapkan langsung pada Decision Trees, tetapi relevan untuk teknik lain, seperti Gradient Boosting.
Setelah menerapkan berbagai metode untuk mengatasi overfitting, model Decision Tree menunjukkan peningkatan performa dengan MSE yang lebih rendah serta seimbang antara data latih dan data uji. Metode seperti regularisasi, pruning, data augmentation, dan Random Forest berhasil mengurangi overfitting serta meningkatkan stabilitas model.
Cross-validation juga memberikan gambaran yang lebih menyeluruh tentang kinerja model. Masing-masing metode memiliki keunikan tersendiri dan pemilihan metode yang tepat tergantung pada studi kasus serta kebutuhan spesifik model.
Memuat Dataset untuk Kasus Underfitting
Untuk memahami fenomena underfitting, kita mulai dari memuat dataset dan menerapkan model yang sangat sederhana. Pertama, kita menggunakan dataset Breast Cancer dari sklearn yang berisi informasi tentang fitur-fitur sampel kanker payudara serta label yang menunjukkan bahwa sampel tersebut jinak atau ganas. Dataset ini kemudian diubah menjadi format DataFrame dan Series untuk mempermudah analisis lebih lanjut.
Selanjutnya, kita membagi dataset menjadi dua subset: data latih (70%) dan data uji (30%). Tujuan dari pembagian ini adalah melatih model pada satu subset dan mengujinya dalam subset berbeda sehingga kita bisa mengevaluasi performa model pada data yang belum pernah dilihat sebelumnya.
- import numpy as np
- import pandas as pd
- from sklearn.datasets import load_breast_cancer
- from sklearn.model_selection import train_test_split, learning_curve
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.metrics import accuracy_score
- import matplotlib.pyplot as plt
- # 1. Load dataset (Breast Cancer Dataset)
- data = load_breast_cancer()
- X = pd.DataFrame(data.data, columns=data.feature_names)
- y = pd.Series(data.target)
- # Membagi dataset menjadi data latih dan data uji
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Kita kemudian menerapkan model Decision Tree dengan kedalaman maksimum (max_depth) yang sangat rendah, yaitu 1. Model dengan kedalaman ini cenderung terlalu sederhana dan tidak mampu menangkap pola kompleks dalam data, yang sering kali menyebabkan underfitting. Model ini dilatih dengan data latih, kemudian digunakan untuk membuat prediksi pada data latih dan data uji.

- # 2. Model Underfitting (Decision Tree dengan max_depth rendah)
- model_underfit = DecisionTreeClassifier(max_depth=1, random_state=42)
- model_underfit.fit(X_train, y_train)
Terakhir, setelah model dilatih, kita menghasilkan prediksi, baik untuk data latih maupun data uji. Hasil prediksi ini akan digunakan untuk mengevaluasi kinerja model dan mengidentifikasi jika model mengalami underfitting yang ditandai dengan performa buruk pada kedua set data.
- # Prediksi
- y_train_pred_underfit = model_underfit.predict(X_train)
- y_test_pred_underfit = model_underfit.predict(X_test)
Mendeteksi Underfitting
Untuk mendeteksi underfitting, kita perlu membandingkan performa model pada data latih dan data uji. Underfitting terjadi ketika model gagal menangkap pola mendalam pada data sehingga menunjukkan kinerja yang buruk dalam kedua data latih dan data uji. Ini biasanya terjadi ketika model terlalu sederhana untuk pemecahan masalah sehingga tidak mampu belajar dengan baik dari data yang tersedia.
1. Evaluasi Performa pada Data Latih dan Data Uji
Langkah pertama dalam mendeteksi underfitting adalah mengevaluasi performa model pada data latih dan data uji. Dalam hal ini, kita menggunakan akurasi sebagai metrik untuk menilai seberapa baik model saat mengklasifikasikan data.
Untuk model underfitting, kita menghitung akurasi pada data latih dan data uji dengan kode berikut.
- # Evaluasi performa pada data latih dan uji
- train_acc_underfit = accuracy_score(y_train, y_train_pred_underfit)
- test_acc_underfit = accuracy_score(y_test, y_test_pred_underfit)
- print(f"Underfit Model Training Accuracy: {train_acc_underfit}")
- print(f"Underfit Model Test Accuracy: {test_acc_underfit}")
Hasil yang diperoleh adalah berikut.
- Underfit Model Training Accuracy: 0.9246
- Underfit Model Test Accuracy: 0.8947
Dari hasil ini, kita dapat melihat bahwa meskipun model memiliki akurasi yang cukup baik pada data latih (92.46%), akurasinya sedikit menurun dalam data uji (89.47%). Perbedaan ini menunjukkan bahwa model tidak terlalu menyesuaikan diri dengan data latih, tetapi juga tidak menangkap pola yang cukup baik untuk memprediksi data uji dengan akurasi lebih tinggi. Ini adalah indikasi bahwa model mengalami underfitting.
2. Learning Curve
Learning curve adalah alat yang berguna untuk menganalisis bahwa model Anda berperforma baik dengan berbagai ukuran data latih. Dengan learning curve, Anda bisa melihat model mengalami underfitting atau overfitting.
Dalam kasus underfitting, Anda bisa menggunakan learning curve untuk memeriksa performa model pada berbagai ukuran data latih. Berikut adalah langkah-langkah dan kode yang digunakan.
- # Learning Curve untuk memeriksa performa pada berbagai ukuran data latih
- train_sizes, train_scores, test_scores = learning_curve(model_underfit, X_train, y_train, cv=5, scoring='accuracy', train_sizes=np.linspace(0.1, 1.0, 10))
- train_scores_mean = np.mean(train_scores, axis=1)
- test_scores_mean = np.mean(test_scores, axis=1)
- # Plot Learning Curve
- plt.figure()
- plt.plot(train_sizes, train_scores_mean, label='Training score')
- plt.plot(train_sizes, test_scores_mean, label='Validation score')
- plt.ylabel('Accuracy')
- plt.xlabel('Training Set Size')
- plt.title('Learning Curve (Underfitting)')
- plt.legend()
- plt.grid(True)
- plt.show()
Pada learning curve ini, Anda dapat melihat grafik yang menunjukkan perubahan akurasi model seiring dengan penambahan ukuran data latih. Pada grafik ini, ada penjelasan sebagai berikut.
- Training score adalah akurasi model pada data latih.
- Validation score adalah akurasi model pada data validasi (data uji).
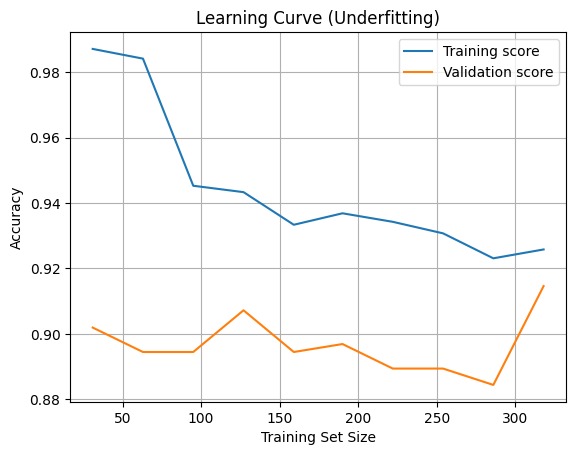
Jika learning curve menunjukkan bahwa baik skor pelatihan maupun skor validasi tidak meningkat secara signifikan dengan bertambahnya ukuran data, ini mengindikasikan bahwa model mungkin tidak cukup kompleks untuk menangkap pola dalam data. Ini merupakan tanda underfitting. Grafik ini membantu Anda memahami bahwa model mungkin terlalu sederhana dan menunjukkan perlunya model yang lebih kompleks untuk meningkatkan performa.
3. Pemeriksaan Kompleksitas Model
Jika learning curve menunjukkan bahwa baik training score maupun validation score tidak meningkat secara signifikan dengan bertambahnya ukuran data, ini adalah tanda bahwa model Anda tidak cukup kompleks untuk menangkap pola-pola dalam data. Ini adalah indikasi dari underfitting bahwa model terlalu sederhana. Grafik ini membantu Anda melihat bahwa model mungkin perlu ditingkatkan agar lebih mampu menangani kompleksitas data dan meningkatkan performanya.
- # Membandingkan dengan model yang lebih kompleks (e.g., max_depth=5)
- model_complex = DecisionTreeClassifier(max_depth=5, random_state=42)
- model_complex.fit(X_train, y_train)
- y_train_pred_complex = model_complex.predict(X_train)
- y_test_pred_complex = model_complex.predict(X_test)
- train_acc_complex = accuracy_score(y_train, y_train_pred_complex)
- test_acc_complex = accuracy_score(y_test, y_test_pred_complex)
- print(f"Complex Model Training Accuracy: {train_acc_complex}")
- print(f"Complex Model Test Accuracy: {test_acc_complex}")
Dengan menggunakan model yang lebih kompleks, yakni dengan max_depth=5, perubahan signifikan dalam hasil terlihat sebagai berikut.
- Akurasi Model Kompleks pada Data Latih: 0.995
- Akurasi Model Kompleks pada Data Uji: 0.953
Model sederhana yang mengalami underfitting sebelumnya hanya mencapai akurasi pelatihan sekitar 0.925 dan akurasi uji sekitar 0.895. Model yang lebih kompleks ini hampir mencapai akurasi sempurna pada data latih dan tetap sangat bagus dalam data uji.
Perbedaan besar ini menunjukkan bahwa model yang lebih kompleks dapat menangkap pola data dengan lebih baik dan memperbaiki masalah underfitting pada model yang lebih sederhana. Dengan demikian, jika model Anda terasa terlalu sederhana, pertimbangkan untuk mencoba model yang lebih kompleks guna meningkatkan performa, ya!
Mengatasi Underfitting
Mengatasi underfitting adalah kunci untuk meningkatkan performa model yang tidak cukup menangkap pola dalam data. Ini sering terlihat dari hasil akurasi yang rendah, baik pada data latih maupun data uji. Underfitting terjadi ketika model terlalu sederhana untuk memodelkan hubungan yang kompleks dalam data sehingga menghasilkan prediksi kurang akurat.
Dalam mengatasi underfitting, tujuan kita adalah menyempurnakan model sehingga dapat menangkap pola-pola yang ada dengan lebih baik. Berbagai teknik dapat digunakan untuk meningkatkan kapasitas model dan performanya.
Di bawah ini, kita akan menjelaskan beberapa metode yang bisa diterapkan untuk mengatasi underfitting dan meningkatkan kemampuan model dalam memprediksi data secara lebih efektif.
1. Gunakan Model yang Lebih Kompleks
Ketika Anda menghadapi masalah underfitting, salah satu langkah pertama yang bisa dicoba adalah menggunakan model lebih kompleks. Underfitting terjadi ketika model terlalu sederhana dan tidak dapat menangkap pola dalam data sehingga hasil prediksinya kurang optimal, baik pada data latih maupun data uji.
Sebelumnya, hasil akurasi model underfitting adalah berikut.
- Akurasi Training Underfitting: 0.9246
- Akurasi Test Underfitting: 0.8947
Untuk mengatasi masalah ini, Anda bisa meningkatkan kompleksitas model. Dalam contoh ini, kita menggunakan model DecisionTreeClassifier dengan parameter max_depth yang lebih besar, yaitu 10. Ini memberikan kapasitas yang lebih besar pada model dan memungkinkan model untuk menangkap lebih banyak pola dalam data.
Berikut adalah kode untuk melatih dan mengevaluasi model yang lebih kompleks.
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.metrics import accuracy_score
- # Menggunakan model yang lebih kompleks dengan max_depth lebih besar
- complex_model = DecisionTreeClassifier(max_depth=10, random_state=42)
- complex_model.fit(X_train, y_train)
- # Prediksi pada data latih dan uji
- y_train_pred_complex = complex_model.predict(X_train)
- y_test_pred_complex = complex_model.predict(X_test)
- # Evaluasi performa
- train_acc_complex = accuracy_score(y_train, y_train_pred_complex)
- test_acc_complex = accuracy_score(y_test, y_test_pred_complex)
- print(f"Training Accuracy (Complex Model): {train_acc_complex}")
- print(f"Test Accuracy (Complex Model): {test_acc_complex}")
Hasil setelah menerapkan model yang lebih kompleks adalah berikut.
- Training Accuracy (Complex Model): 1.0
- Test Accuracy (Complex Model): 0.9415204678362573
- Training Accuracy: 1.0
- Test Accuracy: 0.9415
Dengan menggunakan model yang lebih kompleks, Anda akan melihat peningkatan signifikan dalam akurasi, baik pada data latih maupun data uji. Ini menunjukkan bahwa model sekarang lebih mampu menangkap pola data dan mengatasi masalah underfitting yang sebelumnya ada.
2. Tambahkan Lebih Banyak Fitur (Feature Engineering dengan PCA)
Metode kedua untuk mengatasi underfitting adalah menambahkan lebih banyak fitur ke dalam model melalui teknik feature engineering. Salah satu cara untuk melakukannya adalah menggunakan principal component analysis (PCA).
PCA adalah teknik untuk mereduksi dimensi data sambil mempertahankan informasi yang paling penting. Dengan menghasilkan fitur baru dari data asli, PCA dapat membantu model dalam memahami pola yang lebih kompleks.
Sebelumnya, hasil akurasi model underfitting sebagai berikut.
- Akurasi Training Underfitting: 0.9246
- Akurasi Test Underfitting: 0.8947
Dalam mencoba pendekatan ini, pertama-tama kita normalisasi data dengan StandardScaler, kemudian menerapkan PCA untuk menghasilkan fitur baru dari data yang telah dinormalisasi. Setelah itu, kita melatih model DecisionTreeClassifier yang sama dengan parameter max_depth 10 menggunakan fitur hasil PCA.
Berikut adalah langkah-langkah dan kode untuk menerapkan PCA.
- from sklearn.decomposition import PCA
- from sklearn.preprocessing import StandardScaler
- # Normalisasi data
- scaler = StandardScaler()
- X_scaled = scaler.fit_transform(X)
- # PCA untuk mengurangi dimensi atau menghasilkan fitur baru
- pca = PCA(n_components=5) # Menghasilkan fitur baru dari data asli
- X_pca = pca.fit_transform(X_scaled)
- # Membagi data menjadi data latih dan data uji
- X_train_pca, X_test_pca, y_train_pca, y_test_pca = train_test_split(X_pca, y, test_size=0.3, random_state=42)
- # Model dengan fitur hasil PCA
- complex_model_pca = DecisionTreeClassifier(max_depth=10, random_state=42)
- complex_model_pca.fit(X_train_pca, y_train_pca)
- # Prediksi pada data latih dan uji
- y_train_pred_pca = complex_model_pca.predict(X_train_pca)
- y_test_pred_pca = complex_model_pca.predict(X_test_pca)
- # Evaluasi performa
- train_acc_pca = accuracy_score(y_train_pca, y_train_pred_pca)
- test_acc_pca = accuracy_score(y_test_pca, y_test_pred_pca)
- print(f"Training Accuracy (PCA): {train_acc_pca}")
- print(f"Test Accuracy (PCA): {test_acc_pca}")
Hasil yang diperoleh setelah menggunakan fitur hasil PCA sebagai berikut.
Training Accuracy (PCA): 1.0 Test Accuracy (PCA): 0.9415204678362573 |
- Training Accuracy (PCA): 1.0
- Test Accuracy (PCA): 0.9415
Dengan menerapkan PCA serta menambahkan fitur baru, kita bisa melihat bahwa akurasi model pada data latih dan data uji meningkat secara signifikan. Ini menunjukkan bahwa model sekarang lebih mampu menangkap pola-pola kompleks dalam data sehingga mengurangi masalah underfitting yang ada sebelumnya.
3. Hyperparameter Tuning Menggunakan GridSearchCV
Langkah ketiga untuk mengatasi underfitting adalah melakukan hyperparameter tuning pada model. Hyperparameter tuning adalah proses mencari kombinasi terbaik dari parameter model untuk meningkatkan kinerja model. Salah satu alat yang berguna untuk tugas ini adalah GridSearchCV. Ini memungkinkan kita mengeksplorasi berbagai kombinasi hyperparameter secara sistematis.
Sebelumnya, hasil akurasi model underfitting adalah berikut.
- Akurasi Training Underfitting: 0.9246
- Akurasi Test Underfitting: 0.8947
Dengan GridSearchCV, kita dapat mencari parameter terbaik untuk model DecisionTreeClassifier. Kita menentukan grid pencarian untuk hyperparameter, seperti max_depth,` min_samples_split`, dan min_samples_leaf. Proses ini melibatkan evaluasi berbagai kombinasi parameter menggunakan teknik cross-validation untuk menemukan konfigurasi yang optimal.
Berikut adalah kode untuk melakukan hyperparameter tuning.
- from sklearn.model_selection import GridSearchCV
- # Grid Search untuk hyperparameter tuning
- param_grid = {
- 'max_depth': [5, 10, 15],
- 'min_samples_split': [2, 5, 10],
- 'min_samples_leaf': [1, 2, 4]
- }
- grid_search = GridSearchCV(estimator=DecisionTreeClassifier(random_state=42),
- param_grid=param_grid, cv=5, scoring='accuracy')
- # Melakukan pencarian hyperparameter terbaik
- grid_search.fit(X_train, y_train)
- # Hyperparameter terbaik
- best_params = grid_search.best_params_
- best_model = grid_search.best_estimator_
- # Prediksi dengan model terbaik
- y_train_pred_best = best_model.predict(X_train)
- y_test_pred_best = best_model.predict(X_test)
- # Evaluasi performa
- train_acc_best = accuracy_score(y_train, y_train_pred_best)
- test_acc_best = accuracy_score(y_test, y_test_pred_best)
- print(f"Training Accuracy (Best Model): {train_acc_best}")
- print(f"Test Accuracy (Best Model): {test_acc_best}")
- print(f"Best Params: {best_params}")
Hasil yang diperoleh setelah hyperparameter tuning adalah berikut.
Training Accuracy (Best Model): 0.9949748743718593 Test Accuracy (Best Model): 0.9532163742690059 Best Params: {'max_depth': 5, 'min_samples_leaf': 1, 'min_samples_split': 2} |
- Training Accuracy (Best Model): 0.9950
- Test Accuracy (Best Model): 0.9532
- Best Params: {'max_depth': 5, 'min_samples_leaf': 1, 'min_samples_split': 2}
Dengan melakukan hyperparameter tuning, kita bisa melihat peningkatan signifikan dalam akurasi model pada data latih dan data uji. Ini menunjukkan bahwa model kini lebih sesuai dengan data dan dapat menangani pola yang lebih kompleks serta mengatasi masalah underfitting sebelumnya.
4. Perbaiki Preprocessing Data
Langkah keempat dalam mengatasi underfitting adalah memperbaiki preprocessing data. Preprocessing yang baik sangat penting karena dapat memengaruhi kinerja model secara signifikan. Salah satu teknik penting adalah normalisasi data. Ini memastikan bahwa fitur memiliki skala yang sama sehingga model dapat belajar dengan lebih efektif.
Sebelumnya, hasil akurasi model underfitting adalah berikut.
- Akurasi Training Underfitting: 0.9246
- Akurasi Test Underfitting: 0.8947
Untuk meningkatkan performa model, kita melakukan normalisasi ulang pada data. Anda bisa menggunakan StandardScaler untuk menstandardisasi fitur sehingga memiliki rata-rata 0 dan standar deviasi 1. Setelah itu, kita membagi data menjadi data latih dan data uji, kemudian melatih model DecisionTreeClassifier dengan parameter max_depth yang lebih besar.
Berikut adalah kode untuk preprocessing ulang dan evaluasi model.
- # Melakukan normalisasi ulang dengan scaler
- scaler = StandardScaler()
- X_scaled_new = scaler.fit_transform(X)
- # Membagi ulang data latih dan uji
- X_train_scaled, X_test_scaled, y_train_scaled, y_test_scaled = train_test_split(X_scaled_new, y, test_size=0.3, random_state=42)
- # Model setelah preprocessing data lebih baik
- model_after_scaling = DecisionTreeClassifier(max_depth=10, random_state=42)
- model_after_scaling.fit(X_train_scaled, y_train_scaled)
- # Prediksi
- y_train_pred_scaled = model_after_scaling.predict(X_train_scaled)
- y_test_pred_scaled = model_after_scaling.predict(X_test_scaled)
- # Evaluasi performa
- train_acc_scaled = accuracy_score(y_train_scaled, y_train_pred_scaled)
- test_acc_scaled = accuracy_score(y_test_scaled, y_test_pred_scaled)
- print(f"Training Accuracy (After Scaling): {train_acc_scaled}")
- print(f"Test Accuracy (After Scaling): {test_acc_scaled}")
Hasil yang diperoleh setelah perbaikan preprocessing adalah berikut.
Training Accuracy (After Scaling): 1.0 Test Accuracy (After Scaling): 0.9415204678362573 |
- Training Accuracy (After Scaling): 1.0
- Test Accuracy (After Scaling): 0.9415
Dengan perbaikan preprocessing data, kita melihat bahwa akurasi model pada data latih tetap tinggi dan akurasi dalam data uji juga meningkat. Ini menunjukkan bahwa preprocessing yang lebih baik membantu model untuk belajar lebih efektif dan memberikan performa lebih baik serta mengatasi masalah underfitting sebelumnya.
5. Tambahkan Data Latih
Langkah kelima untuk mengatasi underfitting adalah menambahkan lebih banyak data latih. Dengan meningkatkan jumlah data latih, model memiliki lebih banyak informasi untuk belajar dan dapat meningkatkan kemampuannya dalam mengenali pola yang lebih kompleks.
Sebelumnya, hasil akurasi model underfitting adalah berikut.
- Akurasi Training Underfitting: 0.9246
- Akurasi Test Underfitting: 0.8947
Untuk memperbaiki performa model, kita dapat memperbesar ukuran data latih. Kita membagi ulang data dengan meningkatkan proporsi data latih dan mengurangi ukuran data uji. Kemudian, kita melatih model DecisionTreeClassifier dengan parameter max_depth lebih besar menggunakan data latih yang lebih besar.
Berikut adalah kode untuk menambah data latih dan evaluasi model.
- # Membagi ulang data dengan lebih banyak data latih (menambah ukuran training set)
- X_train_more_data, X_test_less_data, y_train_more_data, y_test_less_data = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
- # Model dengan lebih banyak data latih
- model_more_data = DecisionTreeClassifier(max_depth=10, random_state=42)
- model_more_data.fit(X_train_more_data, y_train_more_data)
- # Prediksi
- y_train_pred_more_data = model_more_data.predict(X_train_more_data)
- y_test_pred_more_data = model_more_data.predict(X_test_less_data)
- # Evaluasi performa
- train_acc_more_data = accuracy_score(y_train_more_data, y_train_pred_more_data)
- test_acc_more_data = accuracy_score(y_test_less_data, y_test_pred_more_data)
- print(f"Training Accuracy (More Data): {train_acc_more_data}")
- print(f"Test Accuracy (More Data): {test_acc_more_data}")
Hasil yang diperoleh setelah menambahkan data latih adalah berikut.
Training Accuracy (More Data): 1.0 Test Accuracy (More Data): 0.9473684210526315 |
- Training Accuracy (More Data): 1.0
- Test Accuracy (More Data): 0.9474
Dengan menambah ukuran data latih, akurasi model dalam data latih tetap tinggi dan akurasi pada data uji juga mengalami peningkatan. Ini menunjukkan bahwa dengan data latih yang lebih banyak, model dapat menangkap pola lebih kompleks dan memberikan performa lebih baik. Ini membantu mengatasi masalah underfitting yang ada sebelumnya.
Rangkuman Hasil Mengatasi Underfitting
Setelah mengidentifikasi dan mengatasi masalah underfitting pada model DecisionTreeClassifier, berikut adalah hasil dari berbagai metode yang diterapkan.
1. Model yang Lebih Kompleks
- Akurasi Training: 1.0
- Akurasi Test: 0.9415
Melalui penggunaan model dengan max_depth yang lebih besar, akurasi pada data latih mencapai 100%, dan akurasi dalam data uji juga meningkat signifikan. Ini menunjukkan bahwa model yang lebih kompleks dapat lebih baik menangkap pola dalam data.
2. Feature Engineering dengan PCA
- Akurasi Training (PCA): 1.0
- Akurasi Test (PCA): 0.9415
Dengan menerapkan principal component analysis (PCA) untuk mengurangi dimensi data, model yang lebih kompleks berhasil mencapai akurasi 100% pada data latih dan 94.15% dalam data uji. Ini menunjukkan bahwa teknik tersebut juga efektif dalam mengatasi underfitting.
3. Hyperparameter Tuning Menggunakan GridSearchCV
- Akurasi Training (Best Model): 0.9950
- Akurasi Test (Best Model): 0.9532
- Parameter Terbaik:
max_depth=5, min_samples_split=2, min_samples_leaf=1
Melalui hyperparameter tuning menggunakan GridSearchCV, model yang dihasilkan menunjukkan akurasi sangat baik pada data uji dengan nilai tertinggi di antara metode lainnya. Ini menegaskan pentingnya pencarian parameter terbaik untuk meningkatkan performa model.
4. Perbaiki Preprocessing Data
- Akurasi Training (After Scaling): 1.0
- Akurasi Test (After Scaling): 0.9415
Setelah melakukan normalisasi ulang pada data, akurasi dalam data latih tetap sempurna, sementara akurasi pada data uji juga meningkat. Ini menandakan bahwa preprocessing yang baik dapat memperbaiki performa model.
5. Tambahkan Data Latih
- Akurasi Training (More Data): 1.0
- Akurasi Test (More Data): 0.9474
Dengan meningkatkan ukuran data latih, model mencapai akurasi 100% pada data latih dan meningkat dalam data uji menjadi 94.74%. Ini menunjukkan bahwa penambahan data latih dapat memperbaiki performa model secara signifikan.
Setelah menerapkan berbagai metode untuk mengatasi underfitting, kita berhasil memperbaiki performa model secara signifikan pada data uji. Penggunaan metode termasuk menggunakan model yang lebih kompleks, feature engineering dengan PCA, hyperparameter tuning, preprocessing data lebih baik, dan menambah ukuran data latih. Semua metode ini berkontribusi pada peningkatan akurasi dan mengurangi masalah underfitting yang sebelumnya terjadi.
[Story] Katakan Tidak pada Salah Prediksi!
Beberapa minggu setelah mereka duduk di kantin dengan kebab serta burger, Diana dan Bilqis kembali berkumpul di tempat favorit mereka—kantin—kali ini dengan semangat baru. Mereka baru saja menyelesaikan modul tentang overfitting dan underfitting, kemudian ingin berbagi pengalaman.
Diana membuka laptopnya sambil tersenyum lebar, “Kamu tau enggak, Cis, setelah belajar tentang overfitting dan underfitting, kita jadi paham banget kenapa model kita dulu selalu ngaco!”
Bilqis menyeruput kopi sambil melirik penasaran, “Serius, Na? Jadi, apa yang bikin kita salah paham kemarin?”
“Jadi gini,” Diana mulai menjelaskan dengan penuh semangat. “Kemarin kan kita sempet bingung kenapa model churn kita selalu salah prediksi. Ternyata masalahnya adalah kita enggak ngecek overfitting dan underfitting dengan benar.”
“Bisa jelasin lagi enggak, kayak yang kemarin di kantin?” tanya Bilqis.
Diana mengangguk, “Jadi, overfitting itu kayak kamu belajar semua jawaban ujian dengan detail, sampe akhirnya pas ujian bener-bener bingung kalo ada soal yang beda dari latihan. Model kita kemarin kayak gitu—terlalu fokus sama data latih, jadi enggak bisa generalisasi dengan baik.”

Diana : “Kamu tau nggak, Cis, setelah belajar tentang overfitting dan underfitting, kita jadi paham banget kenapa model kita dulu selalu ngaco!”
Bilqis: “Serius, Na? Jadi, apa yang bikin kita salah paham kemarin?”
Diana: “Model kita overfitting”
“Ah, ngerti deh!” Bilqis menjawab. “Jadi, cara ngeceknya gimana, Na?”
“Makanya, kita nyoba visualisasi learning curves,” kata Diana. “Kita lihat grafiknya. Kalau kurva error data latih terus menurun, tapi error data validasi naik, itu tanda overfitting. Kalau errornya tinggi di semua data, berarti underfitting.”
Bilqis terlihat lebih paham, “Oh, jadi kalo grafiknya aneh-aneh gitu, kita tahu harus ngapain!”
“Yup, bener!” Diana menjelaskan. “Misalnya di kasus prediksi harga rumah, kita belajar kalau model yang terlalu sederhana gak bisa menangkap kompleksitas data, jadi kita tambahin fitur lebih banyak biar modelnya gak underfit.”
Bilqis memutar otak, “Jadi, di proyek gambar kita juga gitu? Kita tambahin dropout supaya modelnya gak terlalu hafal data latih, kan?”
“Exactly!” Diana mengangguk. “Dan kita juga belajar regularization buat ngurangin kompleksitas model. Jadi modelnya lebih fleksibel dan bisa bekerja dengan baik di data baru.”
Bilqis menyeringai, “Jadi sekarang kita punya senjata rahasia buat ngatasin overfitting dan underfitting, ya?”
“Bener banget!” Diana menjawab dengan antusias. “Kita udah coba semua ini di berbagai proyek. Kayak di proyek churn, harga rumah, sama gambar—semua hasilnya jauh lebih baik setelah kita terapin teknik-teknik ini.”
Bilqis terlihat puas, “Wah, enak banget, deh! Sekarang kita gak cuma ngerti teori, tapi juga udah bisa praktek.”
Diana tersenyum bangga, “Iya, dan kita bisa terus ngejalanin teknik-teknik ini di proyek-proyek kita berikutnya. Jadi, enggak bakal ada lagi model yang salah prediksi terus.”
Mereka berdua menyeruput kopi dan menikmati momen kemenangan kecil ini. Dengan pengetahuan baru mereka tentang overfitting serta underfitting, Diana dan Bilqis siap menghadapi berbagai tantangan di depan. Mereka yakin bisa menangani berbagai masalah dengan lebih percaya diri.
“Cheers buat ilmu baru kita!” Bilqis mengangkat gelas.
“Cheers!” Diana membalas dengan semangat.
Dengan penuh percaya diri, mereka melanjutkan hari mereka, siap untuk menghadapi proyek-proyek baru dan memastikan model tetap dalam performa terbaik.
Rangkuman Overfitting dan Underfitting
Hi machine learning enthusiast! Selamat Anda telah menyelesaikan modul tujuh ini dengan semangat yang luar biasa!
Modul ini berfokus pada dua tantangan utama dalam machine learning, yaitu overfitting dan underfitting. Keduanya memengaruhi kemampuan model untuk membuat prediksi secara akurat pada data yang belum pernah dilihat sebelumnya. Pemahaman serta penanganannya sangat penting untuk mengembangkan model yang efektif.
Overfitting terjadi ketika model terlalu kompleks sehingga mampu mempelajari data latih dengan sangat baik, termasuk noise atau fluktuasi acak. Model seperti ini akan memiliki performa tinggi pada data latih, tetapi cenderung memiliki kinerja buruk pada data baru. Sebaliknya, underfitting terjadi ketika model terlalu sederhana untuk menangkap pola mendalam dari data sehingga tidak dapat memberikan prediksi yang baik pada data latih maupun data baru. Ini biasanya disebabkan oleh model yang tidak cukup kompleks atau fitur tidak memadai.
Modul ini mengajarkan Anda cara menyeimbangkan kompleksitas model dengan kualitas data untuk mencapai good fit—keadaan ideal saat model memiliki generalisasi yang baik tanpa overfitting atau underfitting. Dengan menerapkan teknik-teknik ini secara bijaksana, Anda dapat mengembangkan model machine learning yang lebih robust dan dapat diandalkan. Ini memastikan performa baik tidak hanya pada data latih, tetapi juga pada data baru yang dihadapi dalam aplikasi nyata.
Ingatlah bahwa keseimbangan adalah kunci. Teruslah bereksperimen dan belajar karena setiap dataset serta masalah dapat memerlukan pendekatan yang berbeda. Selamat mencoba, semoga model-model Anda semakin tajam dan andal, ya!
Berikut adalah rangkuman dari Modul 7: Overfitting dan Underfitting.
Dalam machine learning, tujuan utama adalah membangun model yang dapat menggeneralisasi dengan baik dari data latih untuk membuat prediksi akurat pada data baru. Keseimbangan antara belajar pola penting dan menghindari pemahaman berlebihan adalah kunci serta masalah umum yang muncul adalah overfitting dan underfitting.
Overfitting
- Definisi: Ini terjadi ketika model belajar terlalu banyak dari data latih, termasuk detail dan noise yang tidak relevan.
- Gejala: Model menunjukkan performa sangat baik pada data latih, tetapi buruk dalam data uji.
- Analogi: Ini seperti menghafal setiap soal dari buku latihan tanpa memahami konsep sehingga kesulitan menghadapi variasi soal ujian.
- Contoh: Model prediksi harga rumah yang menghafal harga spesifik dari data latih termasuk outlier sehingga kesulitan dengan data baru.
Underfitting
- Definisi: Ini terjadi ketika model terlalu sederhana dan tidak mampu menangkap pola signifikan dalam data.
- Gejala: Model memiliki performa buruk, baik pada data latih maupun data uji.
- Analogi: Ini seperti hanya membaca ringkasan buku sebelum ujian sehingga kesulitan menjawab soal yang memerlukan pemahaman mendalam.
- Contoh: Model linear sederhana untuk memprediksi harga rumah dengan hanya mempertimbangkan satu fitur, seperti luas rumah, tanpa memperhitungkan faktor lain yang kompleks.
Good Fit
- Definisi: Kondisi ideal ketika model dapat menangkap pola signifikan tanpa terlalu terikat pada detail yang tidak relevan atau terlalu sederhana.
- Gejala: Model memberikan prediksi yang akurat pada data latih dan data uji.
- Analogi: Ini seperti mempersiapkan ujian dengan memahami buku secara menyeluruh dan berbagai jenis soal sehingga mampu menjawab dengan baik.
- Contoh: Model prediksi harga rumah yang memahami hubungan kompleks antara berbagai fitur, seperti lokasi, ukuran, dan kondisi.
Penyebab Overfitting dan Underfitting
- Kompleksitas Model yang Terlalu Tinggi: Model dengan terlalu banyak parameter atau fitur dapat menangkap noise dan menyebabkan overfitting.
- Data Latih yang Terbatas: Model terlalu menyesuaikan dengan data latih yang sedikit dan mengakibatkan overfitting.
- Pelatihan yang Terlalu Lama: Model yang dilatih terlalu lama dapat mulai mempelajari pola tidak relevan.
- Fitur yang Tidak Relevan: Penggunaan fitur yang tidak penting membuat model terlalu kompleks dan cenderung overfit.
Memahami dan mengatasi penyebab ini adalah kunci untuk mengembangkan model yang efektif serta dapat diandalkan.
Metode Deteksi Overfitting
- Evaluasi Performa pada Data Latih dan Data Uji
- Jika model berperforma sangat baik pada data latih, tetapi buruk dalam data uji, ini menunjukkan overfitting. Model mungkin "mengingat" data latih secara berlebihan dan gagal menggeneralisasi.
- Learning Curve
- Learning curve yang menunjukkan kesalahan rendah pada data latih, tetapi tinggi dalam data uji dapat menandakan overfitting. Kurva ini memvisualisasikan bahwa model terlalu kompleks.
Metode Deteksi Underfitting
- Evaluasi Performa pada Data Latih dan Data Uji
- Model menunjukkan performa buruk, baik pada data latih maupun data uji yang mengalami underfitting. Model mungkin terlalu sederhana untuk menangkap pola kompleks dalam data.
- Learning Curve
- Learning curve dengan kesalahan tinggi pada kedua set data yang tidak menurun menunjukkan underfitting. Ini menandakan model mungkin terlalu sederhana.
- Pemeriksaan Kompleksitas Model
- Evaluasi jenis model dan jumlah fitur. Model sederhana tidak dapat menangkap hubungan rumit sehingga perlu penyesuaian untuk meningkatkan kompleksitas model.
Teknik Mengatasi Overfitting
- Cross-Validation
- Membagi data menjadi beberapa subset untuk memastikan model tidak overfitting pada subset tertentu dan dapat menggeneralisasi dengan baik.
- Early Stopping
- Menghentikan pelatihan saat model mulai overfit pada data validasi meskipun performa dalam data latih masih meningkat.
- Regularization
- L1 Regularization (Lasso): Menyederhanakan model dengan mengurangi koefisien fitur yang kurang penting menjadi nol.
- L2 Regularization (Ridge): Mengurangi ukuran koefisien fitur yang besar tanpa menghilangkan fitur sama sekali.
- Elastic Net: Kombinasi L1 dan L2 untuk memilih fitur penting tanpa kehilangan informasi dari fitur terkait.
- Dropout
- Menghilangkan neuron secara acak selama pelatihan untuk mencegah model terlalu bergantung pada neuron tertentu.
- Data Augmentation
- Meningkatkan variasi data latih untuk membantu model lebih robust terhadap berbagai situasi.
- Pruning
- Menyederhanakan pohon keputusan dengan menghilangkan cabang yang tidak signifikan untuk mengurangi kompleksitas dan risiko overfitting.
Teknik Mengatasi Underfitting
- Gunakan Model yang Lebih Kompleks
- Beralih ke model lebih kompleks, seperti Decision Trees, Random Forests, atau neural networks untuk menangkap hubungan yang lebih rumit dalam data.
- Tambahkan Data Latih
- Menambah jumlah data latih untuk memberikan model lebih banyak variasi dan contoh untuk belajar serta membantu model dalam menangkap pola yang lebih kompleks.
- Perbaiki Preprocessing Data
- Memastikan data telah diproses dengan baik untuk menangkap informasi yang relevan.
- Tambahkan Lebih Banyak Fitur
- Menambahkan fitur baru atau melakukan feature engineering untuk memberikan model informasi lebih banyak dan relevan.
- Eksperimen dengan Hyperparameter Tuning
- Mengatur parameter model untuk menemukan konfigurasi optimal yang dapat meningkatkan kinerja model.
Dengan mengidentifikasi dan mengatasi overfitting serta underfitting menggunakan teknik-teknik ini, Anda dapat membangun model machine learning secara lebih akurat dan efektif. Ini dapat menggeneralisasi dengan baik pada data yang belum pernah dilihat sebelumnya.
Bersambung ke:
Pengantar Hyperparameter Tuning
- Get link
- X
- Other Apps



Comments
Post a Comment