Rangkuman Kelas
- Get link
- X
- Other Apps
Rangkuman Kelas
Rangkuman Berkenalan dengan Artificial Intelligence (AI)
Kita sudah berada di penghujung materi pertama. Sampai sini Anda sudah memiliki pengetahuan mendasar mengenai Artificial Intelligence. Mari kita rangkum secara saksama.
Penerapan AI dalam Dunia Nyata
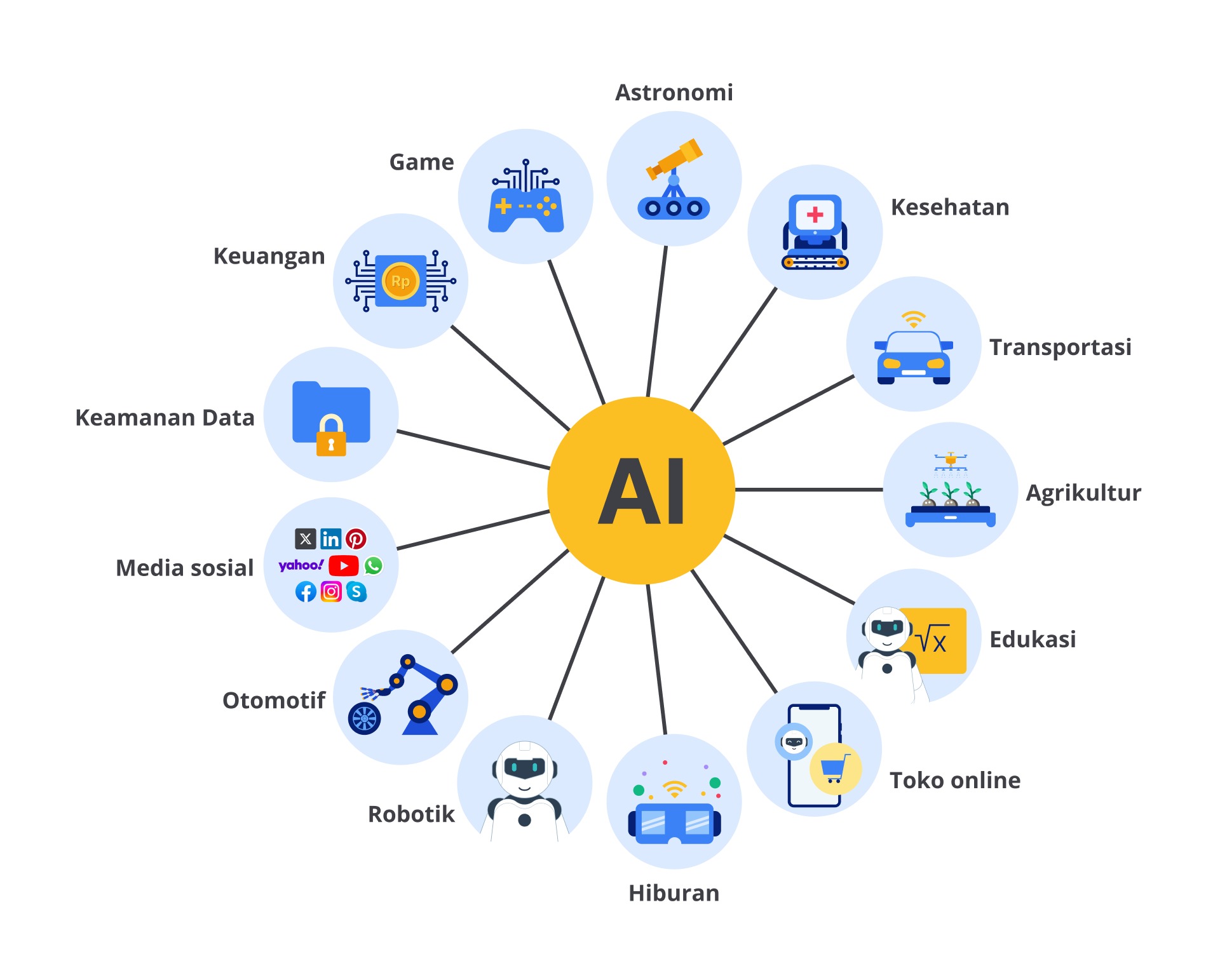
Selain dalam kehidupan sehari-hari, penerapan AI juga sudah menyebar ke seluruh bidang industri. Seperti yang Anda lihat pada gambar di atas, penerapan AI sudah ada pada seluruh bidang pekerjaan. Namun, pada kesempatan ini, kita akan membahas dua contoh saja yang sering ditemui. Tanpa berlama-lama, mari kita uraikan beberapa contoh penerapan AI pada dunia nyata di bawah ini.
Smart Speaker

Smart Speaker merupakan salah satu alat yang dapat diaktifkan menggunakan suara penggunanya. Alat ini dapat merespon perintah verbal yang kita ucapkan. Contohnya, jika kita mengucapkan “berikan contoh pantun lucu”, smart speaker akan langsung memberikan pantun lucu sesuai permintaan kita.
Pertanyaannya bagaimana caranya membuat perangkat yang memiliki dapat memahami perintah verbal dan memberikan respons pada kita? Pada contoh kasus ini, terdapat beberapa langkah hingga smart speaker dapat merespon perintah yang kita berikan. Mari kita uraikan langkah-langkahnya bersama.
- Pertama, kita harus memberikan kata pemicu yang telah ditentukan oleh algoritma alat ini. Seperti contohnya pada Google kata pemicunya yaitu “Ok, Google!” Lalu, setelah perangkat mendeteksi kata pemicu, ia akan mengembalikan nilai True atau False yang nantinya akan dilanjutkan pada langkah berikutnya.
- Setelah perangkat memberikan status True, ia akan melakukan pengenalan suara untuk mendeteksi perintah yang diberikan. Misalnya, perintah yang dapat diberikan adalah “berikan contoh pantun lucu”. Setelah perintah diterima, perangkat akan melakukan pemetaan audio menjadi sebuah teks.
- Langkah ketiga merupakan langkah paling kompleks. Pada tahap ini perangkat harus mencari tahu maksud sebenarnya dari perintah yang diberikan oleh pengguna. Hal tersebut akan diolah oleh algoritma yang telah dibangun sebelumnya hingga mendapatkan maksud dari perintah yang diberikan.
- Terakhir adalah proses eksekusi dari apa yang diminta oleh pengguna kepada smart speaker. Pada kasus ini, perintah akan dieksekusi dengan mengembalikan audio yang berisi pantun lucu.
Self-driving car
Berbicara tentang penerapan AI, hal yang paling menarik pada era ini adalah Self-driving Car, salah satu perusahaan yang memiliki teknologi tersebut ialah Tesla. Beberapa dari kalian mungkin penasaran tentang “bagaimana sih cara kerja dari teknologi self-driving car?” Untuk menjawab rasa penasaran tersebut. Simak uraiannya di bawah ini.
Mari kita awali dari proses sebuah mobil dapat memahami berbagai macam perintah, mulai dari langkah utama untuk mendapatkan input hingga dapat mengemudikan dirinya sendiri secara otomatis. Mobil ini akan menerima input dari berbagai sensor, seperti gambar yang ada di sekitarnya dan radar sensor laser. Perhatikan gambar berikut untuk mengetahui detailnya.
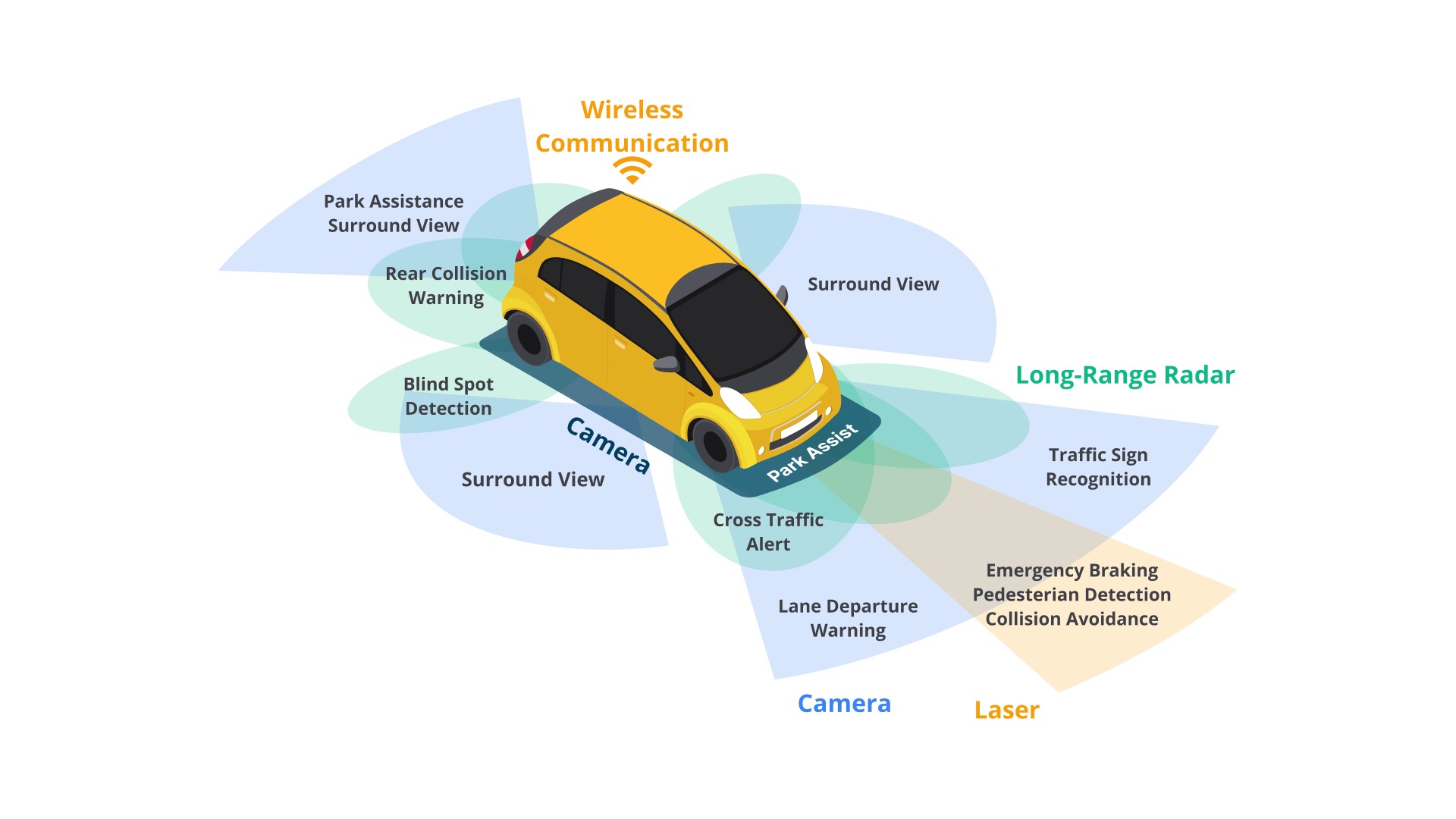
Dengan input tersebut mobil ini dapat mendeteksi mobil lain serta pejalan kaki. Pendeteksian ini dapat dilakukan dengan melakukan pemetaan sehingga dapat mengirimkan input dan memberikan informasi posisi mobil dan pejalan kaki lainnya. Setelah mengetahui lokasi dari objek lainnya, informasi tersebut akan digunakan untuk perancangan gerakan pada perangkat lunak yang dibangun sehingga dapat membuat keputusan dan menghindari tabrakan.
Pengenalan AI
Sadar atau tidak, AI bukanlah sebuah teknologi yang baru ditemukan. Ada banyak sekali perdebatan terkait kapan AI pertama kali dibahas. Namun, mari kita mulai dengan perkembangan AI pada tahun 1950 sebelum konferensi pertama tentang AI dilaksanakan.

AI pertama kali dikembangkan pada tahun 1950 oleh John McCarthy, Marvin Minsky, dan para ilmuwan lainnya di Massachusetts Institute of Technology (MIT) yang membentuk kelompok penelitian untuk mempelajari AI. Mereka menciptakan program-program komputer yang dapat meniru kemampuan manusia, seperti pemrosesan bahasa alami dan permainan catur. Hingga muncul satu statement dari salah satu peneliti bernama Turing yang menyebutkan “jika manusia mampu menyelesaikan masalah dan membuat keputusan berdasarkan informasi dan tatanan yang tersedia, mengapa mesin tidak bisa melakukan hal yang sama?”.
Hal tersebut membuat para peneliti semakin bersemangat dan yakin bahwa AI merupakan ilmu yang patut untuk dikembangkan. Lalu, pada tahun 1956 dibuatlah sebuah konferensi AI Darthmouth Summer Research Project on Artificial Intelligence (DSRPAI) yang menjadi tonggak awal perkembangan AI sebagai bidang ilmu yang mandiri. Pada konferensi ini, para ilmuwan sepakat untuk memusatkan perhatian mereka pada pembangunan program-program komputer yang mampu "mempelajari" dan "berpikir" seperti manusia.
Definisi Artificial Intelligence adalah sebuah teknologi yang memberikan kemampuan untuk berpikir dan belajar dengan komputer. Dengan demikian penerapan AI dapat membantu memecahkan masalah dengan cara yang cerdas menggunakan algoritma. Dengan menggunakan cara yang cerdas tersebut kita tidak perlu lagi melakukan hal yang berulang-ulang dan dapat menghindari kesalahan pengguna.
Namun, apakah kalian penasaran bagaimana untuk mendefinisikan “cara yang cerdas” dan apa yang dimaksud “cara yang cerdas”? Mungkin banyak dari kalian yang bertanya-tanya terkait kalimat sebelumnya. “Cara yang cerdas” ini dapat didefinisikan dengan melakukan pendekatan komputasi untuk meniru kecerdasan manusia yang dipengaruhi oleh data.
Dengan kata lain, Artificial Intelligence ini merupakan teknologi yang menggunakan komputer untuk menyelesaikan tugas secara otomatis dengan sedikit campur tangan manusia atau bahkan tanpa campur tangan manusia sama sekali. Keren, bukan?
Taksonomi AI
Berangkat dari materi sebelumnya, pengertian AI sangatlah luas dan banyak sekali kelompok keilmuan di dalamnya. Oleh karena itu, mari kita jelajahi bersama kelompok ilmu atau bisa disebut taksonomi AI secara runut.
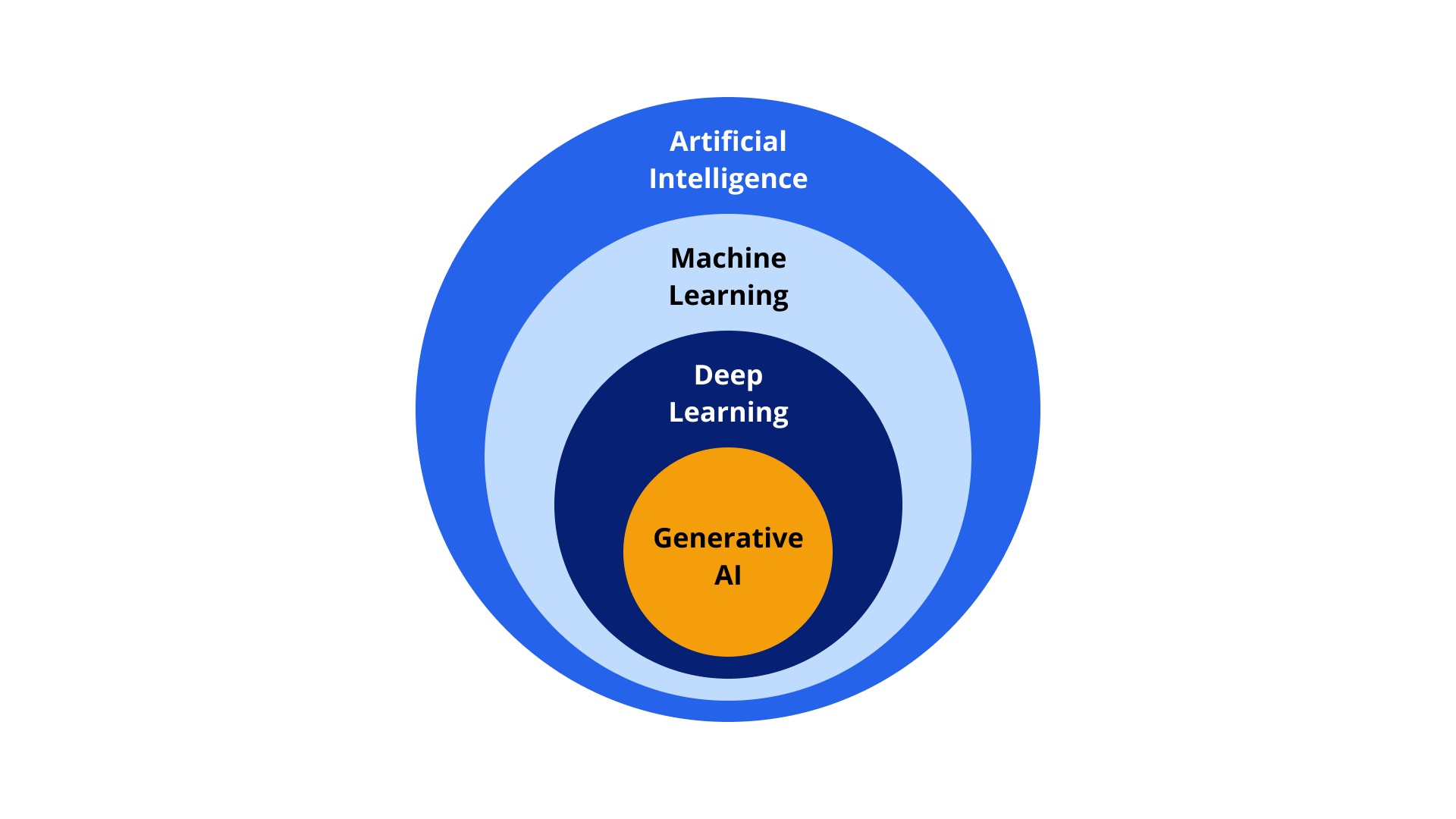
Artificial Intelligence (AI)
Seperti yang telah kita bahas sebelumnya pada pengenalan AI mengenai sejarah hingga pengertiannya, lalu bagaimana Anda mendefinisikan AI? Yap, AI adalah teknologi yang menerapkan peniruan perilaku manusia terhadap komputer supaya dapat mempelajari dan melakukan tugas tanpa perlu bantuan eksplisit tentang output yang diharapkan. Nah, dengan penjelasan tersebut, AI memungkinkan komputer untuk belajar dari pengalaman, mengidentifikasi pola, membuat keputusan, dan menyelesaikan tugas-tugas kompleks dengan cepat dan efisien.
Machine Learning (ML)
Machine learning (ML) merupakan salah satu bagian dari kelompok keilmuan AI yang secara otomatis dapat belajar dan berkembang berdasarkan pengalamannya. Machine learning adalah sebuah teknologi yang menggunakan metode statistika untuk membuat komputer dapat mempelajari pola pada data tanpa perlu diprogram secara eksplisit. ML bergantung pada algoritma yang digunakan untuk menganalisis data dalam jumlah yang besar, belajar dari pengetahuan berdasarkan data, dan memberikan keputusan berdasarkan pengalaman yang dipelajarinya dengan tepat.
Machine Learning menggunakan sebuah algoritma untuk melakukan pelatihan dan meningkatkan performa dari waktu ke waktu setiap kali pelatihan dilakukan. Nah, setelah melewati proses tersebut, kita akan mendapatkan sebuah output dari proses pembelajaran mesin tersebut. Output akhir dari pengembangan Machine Learning ini sendiri merupakan sebuah model yang dapat melakukan tugas berdasarkan data pelatihan yang diberikan. Semakin banyak data yang digunakan, semakin baik pula modelnya.
Deep Learning
Deep Learning merupakan bagian dari Machine Learning. Namun, perlu kamu ketahui bahwa terdapat perbedaan mendasar antara Machine Learning dengan Deep Learning. Deep Learning merupakan pembelajaran mesin yang didasari oleh saraf tiruan, proses yang lebih kompleks dari pada Machine Learning karena pada tahapan ini proses pembelajarannya terdiri dari beberapa bagian mulai dari input, hidden layer, dan output.
Generative AI
Kita telah sampai pada bagian terakhir dari kelompok AI yang ada pada kelas ini, Generative AI merupakan bagian lebih dalam dari Deep Learning. Pembelajaran ini dapat menghasilkan berbagai konten baru berdasarkan input yang diberikan oleh pengguna.
Biasanya model yang dibangun oleh Generative AI dapat menghasilkan mulai dari bahasa, kode, suara, hingga gambar. Salah satu contoh implementasi Generative AI adalah DALL-E. DALL-E sendiri merupakan Generative AI yang dapat menciptakan gambar dari deskriptif tekstual. Misalnya, contoh deskripsinya adalah “pantai dengan langit yang biru”. Setelah mengetikkan deskripsi tersebut, DALL-E akan menampilkan hasil gambar seperti berikut.

AI Workflow
Setelah kita mengetahui contoh penerapan AI pada materi sebelumnya, lantas bagaimana tahapan pengembangan AI secara umum? Mari kita mulai perjalanan yang menyenangkan ini bersama-sama.
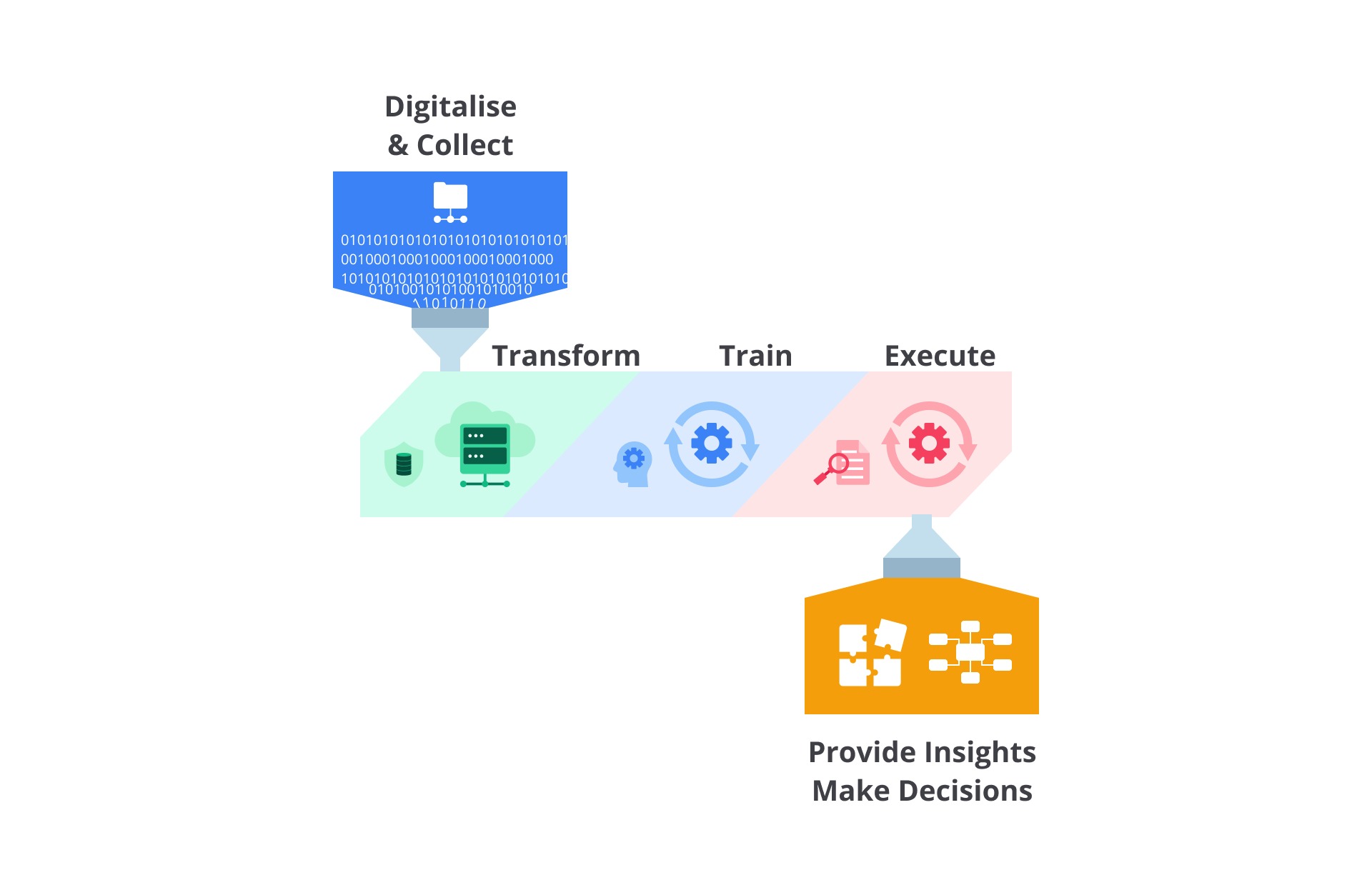
Pada tahap ini, Anda akan memahami gambaran umum pada pengembangan AI, tanpa berlama-lama yuk kita mulai membahas tahapan yang ada pada proses pengembangan AI.
- Digitalise & Collect
Digitalise & collect merupakan tahapan pengumpulan dan penyimpanan data yang akan digunakan pada proses pembangunan AI. Perlu kalian pahami, digitalise di sini berarti kita perlu melakukan perubahan data agar dapat disimpan pada penyimpanan komputer.
Jika anda ingin membuat AI dengan permasalahan pribadi, proses pengumpulan data tidak semudah ketika mengunduh dataset yang sudah jadi. Anda perlu mengumpulkan dan mengekstrak sendiri data dari berbagai sumber, seperti database, file, data sensor, dan sumber lainnya.
Faktanya, tahapan ini merupakan kunci untuk menentukan tugas yang akan dilakukan oleh AI berdasarkan data yang telah dikumpulkan. Dengan pengumpulan data yang benar, ia akan menghasilkan AI yang sesuai dengan harapan pengembang nantinya. - Transform
Transform di sini bisa diartikan sebagai proses perubahan. Pada tahapan ini, data yang telah dikumpulkan akan diproses secara berulang mulai dari persiapan data, mengubah data menjadi format yang dibutuhkan, hingga mengevaluasi data dengan mengidentifikasi data yang tidak dibutuhkan. - Train
Setelah melewati tahapan yang paling memakan waktu sebelumnya (Digitalise & Collect; dan Transform), kita telah mendapatkan data yang telah terorganisasi. Selanjutnya, pada tahap train, kita akan menentukan algoritma yang cocok untuk pengembangan AI ini.
Namun, perlu kami tegaskan pada salah satu buku yang diusung oleh Jie Ding, dkk yang berjudul “Model Selection Techniques -An Overview” menyatakan bahwa tidak ada algoritma yang cocok secara universal untuk data dan tujuan apa pun. Oleh karena itu, kita harus menentukan algoritma yang cocok dengan data yang kita miliki sehingga dapat menghasilkan AI dengan performa optimal. - Execute
Hingga tahapan ini, Anda telah memiliki model AI yang telah dibangun.Setelah dieksekusi, model AI yang telah dilatih dan disempurnakan dapat digunakan untuk melakukan tugas manusia. Selama fase ini, keakuratan model juga dievaluasi secara terus-menerus. Proses eksekusi dianalisis ulang untuk memastikan bahwa sistem memenuhi harapan dan memberikan umpan balik untuk perbaikan. - Provide Insights Make Decisions
Ketika model AI sudah dapat melakukan tugasnya, sekarang kita harus melakukan ekstraksi dari pengetahuan yang dimilikinya. Proses ini membantu pengambilan keputusan serta meningkatkan pemahaman kita dalam pengembangan AI selanjutnya.
Jika ingin membangun model AI yang datanya terus berubah, Anda perlu memperbarui dataset dan melatih ulang model Anda secara reguler. Selain itu, Anda juga perlu membuat sistem yang dapat membuat proses update ini berjalan secara otomatis.
Rangkuman Data untuk AI
Kita sudah berada di penghujung materi Data untuk AI. Sampai sini, Anda telah memiliki pemahaman mendasar mengenai data untuk AI. Mari kita rangkum secara saksama.
Pengenalan Data
Apa Itu Data
Data merupakan fondasi penting dalam pengembangan AI. Kualitas dan jumlah data yang baik dapat memengaruhi hasil pengembangan AI menjadi lebih baik. Setelah mengetahui bahwa data memiliki peran penting dalam proses pengembangan AI mari kita gali sedikit lebih dalam tentang data. Mungkin pertanyaan pertama yang terbesit di benak Anda saat ini, “Apa sih data itu?” Yuk, kita bahas satu per satu.
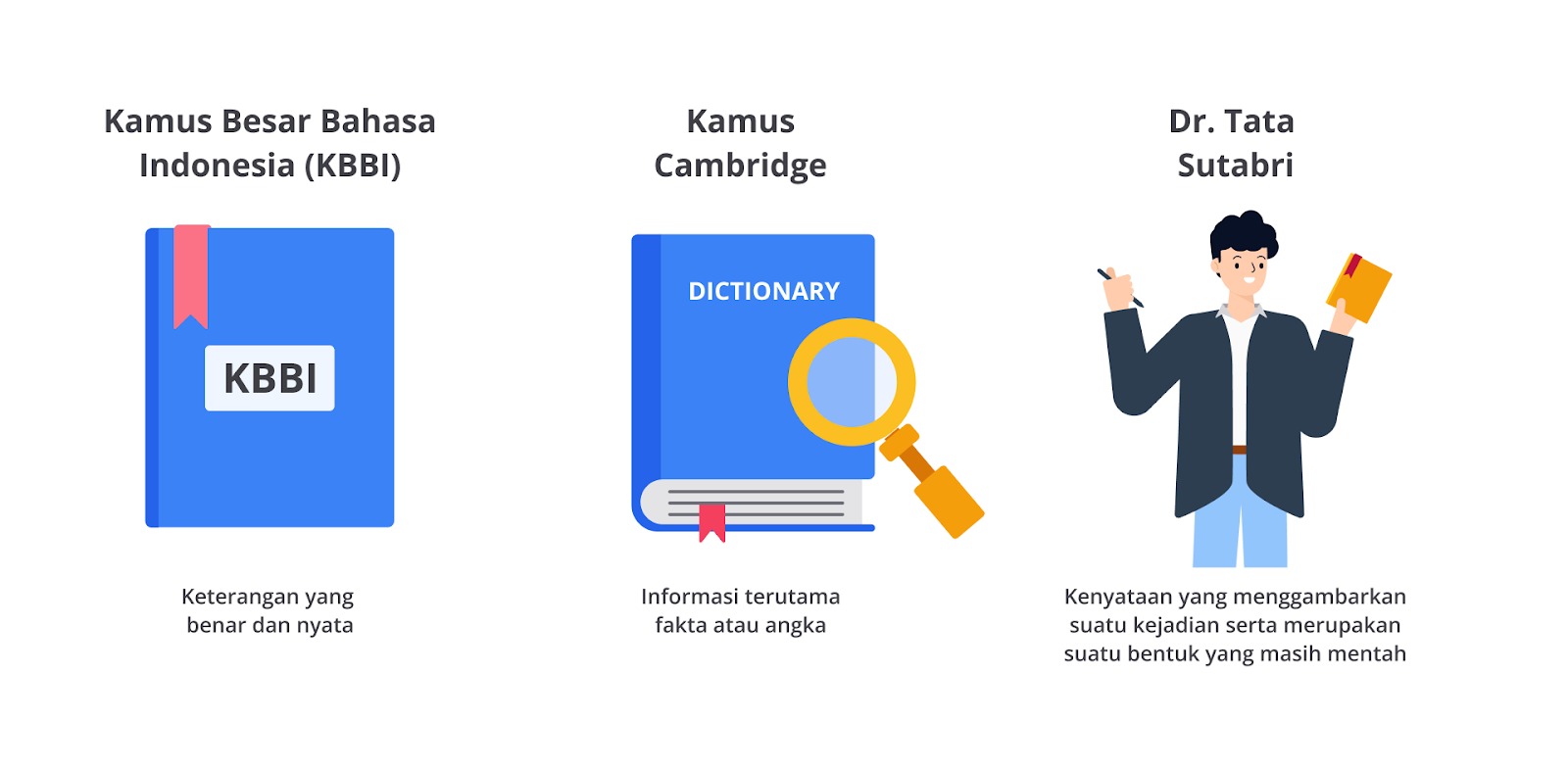
Menurut Kamus Besar Bahasa Indonesia, data merupakan keterangan yang benar dan nyata; keterangan atau bahan nyata yang dapat dijadikan dasar kajian; informasi dalam bentuk yang dapat diproses oleh komputer, seperti representasi digital dari teks, angka, gambar grafis, atau suara.
Menurut Kamus Cambridge, data adalah informasi, terutama fakta atau angka, dikumpulkan untuk diperiksa dan dipertimbangkan, serta digunakan untuk membantu pengambilan keputusan atau informasi dalam bentuk elektronik yang dapat disimpan dan digunakan oleh komputer.
Terakhir, menurut ahli, yaitu Tata Sutabri, dalam buku Konsep Sistem Informasi, data adalah kenyataan untuk menggambarkan suatu kejadian serta suatu bentuk yang masih mentah dan belum dapat bercerita banyak sehingga perlu diolah lebih lanjut melalui suatu model untuk menghasilkan informasi.
Data, Dataset, dan Basis Data
Pemahaman yang baik tentang perbedaan antara data, dataset, dan basis data memungkinkan Anda mengelola dan memanfaatkan informasi dengan lebih efisien, membuat keputusan yang lebih tepat, dan menghindari kebingungan atau kesalahan yang mungkin terjadi dalam konteks pengembangan AI.
Data adalah fakta, nyata, dan informasi yang tersimpan di dalamnya dapat berbentuk teks, angka, gambar, suara, dan banyak bentuk lainnya. Data dalam konteks dataset dan basis data mengacu pada kumpulan informasi yang relevan serta dikumpulkan, disimpan, dan dikelola untuk tujuan tertentu. Dengan kata lain data merupakan entri tunggal atau informasi individual. Perhatikan gambar berikut.
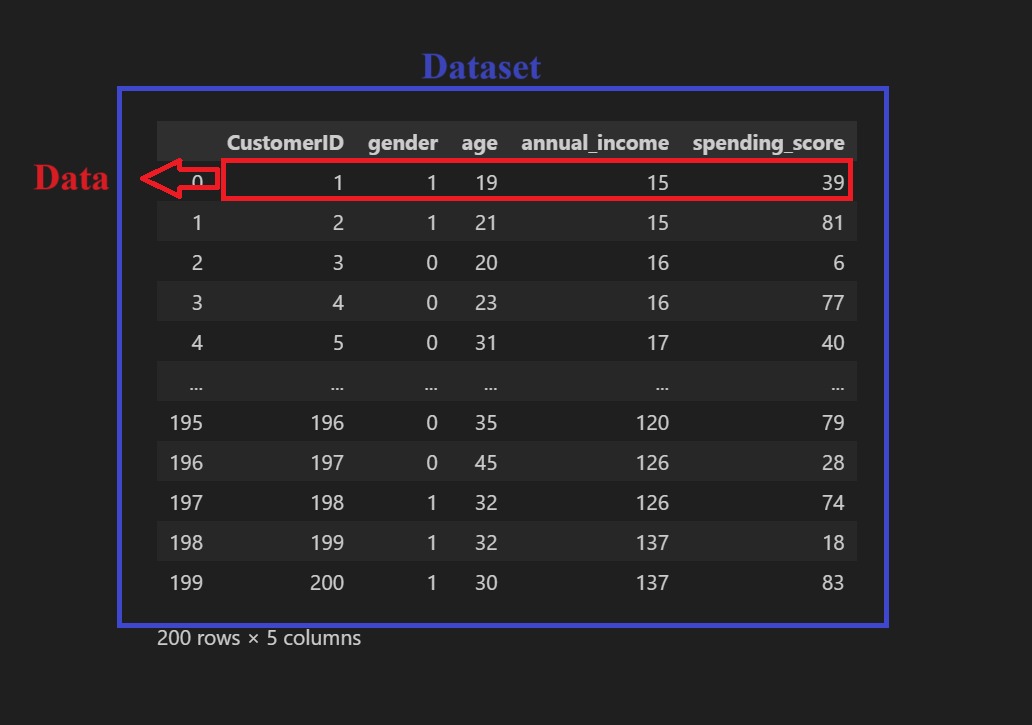
Setelah melihat gambar di atas, dapatkah Anda mengamati perbedaan antara data dan dataset? Yup! Dataset adalah kumpulan data yang disusun secara terstruktur. Dataset dapat digunakan untuk tujuan tertentu, seperti pembangunan machine learning, analisis statistik, dan visualisasi data. Lalu pada contoh di atas, yang mana data? Seperti yang telah dibahas sebelumnya, data merupakan entri tunggal. Pada kasus di atas, data mencakup satu baris dari dataset yang ada dan dapat disebut sebagai data pelanggan.
Selain data dan dataset, Anda juga perlu mengetahui tentang basis data karena keduanya memiliki hubungan yang erat. Mari kita mulai menyelam sedikit lebih dalam agar dapat mengetahui perbedaan di antara keduanya!
Basis Data merupakan kumpulan data yang diatur dan disimpan secara terorganisir sehingga dapat diambil dan diakses dengan mudah. Selain itu, ia juga dapat menyimpan berbagai macam tipe data, termasuk teks, nomor, gambar, dan tipe data lainnya. Lalu, apa perbedaannya dengan dataset? Basis data memiliki banyak kumpulan data dan dapat digunakan untuk aplikasi yang berbeda, sedangkan dataset merupakan bagian dari data yang diambil dari basis data.
Agar Anda dapat lebih memahami perbedaan antara dataset dan basis data, yuk telisik bersama gambar di bawah ini.
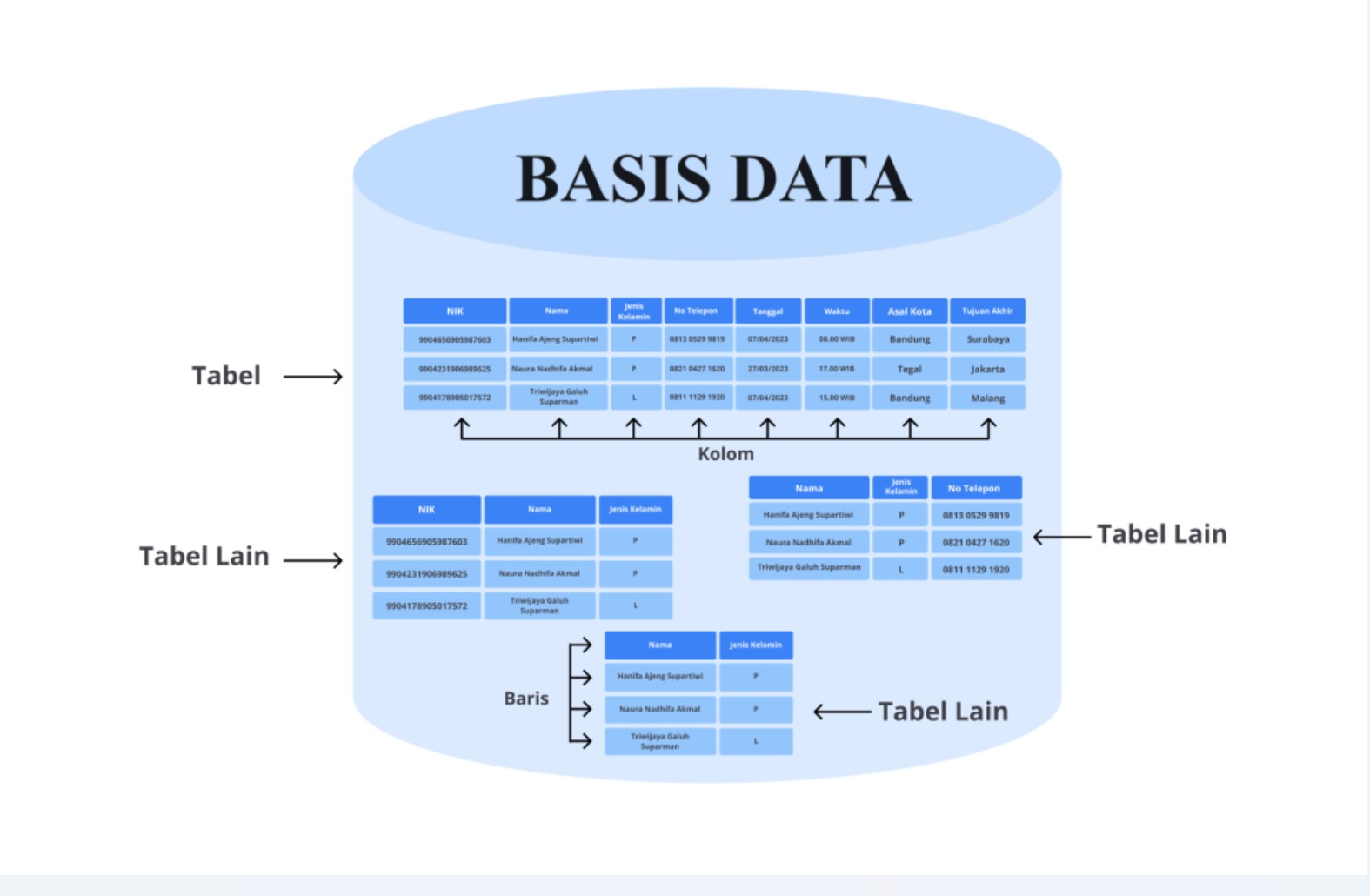
Gambar tabung di atas merupakan representasi dari sebuah basis data dan tabel yang di dalamnya memiliki struktur basis data yang diatur dengan kolom dan baris. Namun, berdasarkan gambar di atas, apakah Anda dapat menentukan manakah yang termasuk dataset? Benar, Jika tabel yang ada dalam basis data dibungkus dengan menggunakan format tertentu dan dibuat menjadi satu buah tabel maka ia dapat disebut dataset.
Tipe-Tipe Data
Seperti halnya manusia yang memiliki tipenya tersendiri, pengembangan AI juga memerlukan data yang sesuai dengan “tipe”-nya agar dapat mengerjakan tugasnya dengan baik. Oleh karena itu, pada modul ini, kita akan bersama-sama mengetahui berbagai macam tipe data mulai dari data terstruktur hingga data tidak terstruktur.
Data Terstruktur
Data terstruktur merupakan jenis data yang memiliki format dan tata letak yang tetap atau teratur. Artinya, data ini diatur dalam suatu pola atau struktur yang konsisten sehingga mudah dibaca, diproses, dan dianalisis oleh komputer atau manusia. Jenis data terstruktur umumnya memiliki definisi yang jelas seperti kolom dalam tabel atau bidang dalam dokumen teks. Data ini memiliki 2 turunan, yaitu data kuantitatif dan data kategorikal.
Data Kuantitatif
Data kuantitatif adalah jenis data yang dapat diukur atau diungkapkan dalam bentuk angka. Data ini digunakan untuk mengukur atau menggambarkan jumlah, besaran, atau atribut-atribut yang dapat diukur secara numerik. Perhatikan contoh data kuantitatif berikut.

Pada modul ini, kita akan menyelam lebih dalam karena data kuantitatif akan terbagi menjadi dua bagian, yaitu data kontinu dan diskrit. Mari kita kupas tuntas hingga ke akarnya!
Data Kontinu
Data kontinu dapat direpresentasikan dalam berbagai nilai numerik, seperti bilangan desimal, bulat, dan lain-lain. Beberapa contoh tipe data kontinu yang umum adalah tinggi, berat, waktu, suhu, usia, dan lain-lain.

Mari kita analogikan bahwa Anda memiliki sebuah toko kelontong dan ingin menentukan data kontinu pada kasus yang Anda miliki. Sebelum Anda membuka toko, ada baiknya jika mengetahui suhu yang terjadi di toko agar Anda dapat memutuskan ingin menyalakan AC pada waktu yang tepat sehingga pengunjung merasa nyaman. Sehingga Anda akan mencatat data sebagai berikut.
| Waktu | Suhu (Celcius) |
|---|---|
10.00 | 24 |
10.15 | 24.5 |
10.30 | 24.75 |
… | … |
Dari data tersebut, Anda dapat menentukan waktu penggunaan AC yang tepat supaya pengunjung merasa nyaman. Misalnya, ketika suhu sudah lebih dari 28C, AC harus dinyalakan.
Data Diskrit
Data diskrit merupakan data numerik yang hanya bisa direpresentasikan dengan bilangan bulat dan tidak dapat dibagi ke dalam unit yang lebih kecil. Perhatikan tabel berikut.
| Produk | Stok |
|---|---|
Kopi Brazil | 12 |
Susu THT | 15 |
Snack Cheetos | 7 |
Beras | 5 |
Tabel tersebut menunjukan stok produk yang sudah mulai habis pada hari itu. Karena stok produk merupakan sebuah objek tunggal, ia tidak dapat dibagi ke dalam unit yang lebih kecil. Oleh karena itu, stok produk termasuk ke dalam data diskrit.
Data Kategorikal
Data kategorikal mengacu pada bentuk informasi yang dapat disimpan dan diidentifikasi berdasarkan nama atau labelnya. Data kategorikal merupakan data yang dapat dikelompokkan dan terbagi berdasarkan karakteristik atau ciri khasnya masing-masing. Dari data kategorikal, ada dua pembagian, yaitu ordinal dan nominal.
Data Ordinal
Data ordinal adalah jenis pengelompokan data yang memiliki urutan atau harus disusun secara berurutan dengan mekanisme peringkat. Perhatikan data rating yang ada pada gambar berikut.
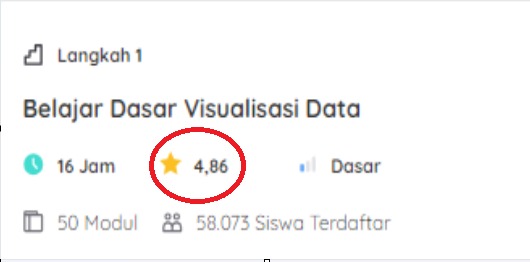
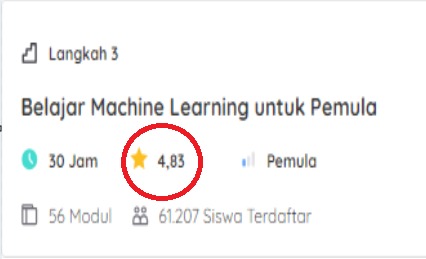
Gambar di atas menunjukkan bahwa terdapat dua kelas yang memiliki rating 4,86 dan 4,83. Dari kedua kelas tersebut, manakah menurut Anda yang lebih baik? Dari angka tersebut, pasti Anda langsung bisa mengetahui kelas manakah yang memiliki rating tertinggi. Nah informasi tersebut merupakan contoh dari data ordinal bahwa jenis data ini dapat diurutkan berdasarkan peringkat.
Data Nominal
Berkebalikan dengan data ordinal, data nominal adalah jenis pengelompokan data yang tidak memiliki keterkaitan dengan data lainnya dan tidak memiliki arti khusus. Jadi, data ini dapat dibedakan tanpa harus mengurutkan atau dibandingkan dengan data lainnya. Perhatikan gambar di bawah ini.

Seperti yang tertera pada gambar di atas, Anda dapat mengetahui bahwa jenis kelamin terbagi menjadi 2, yaitu perempuan dan laki-laki. Pada dasarnya jenis kelamin tersebut tidak memiliki keterkaitan, tetapi dapat diklasifikasikan menjadi jenis kelamin. Seperti halnya pengertian dari data nominal, data ini tidak dapat dibandingkan atau diurutkan.
Data Tidak Terstruktur
Data tidak terstruktur adalah jenis data yang tidak memiliki format atau struktur yang jelas. Data ini cenderung bervariasi bentuknya dan sulit untuk diorganisasi dalam kategori atau kolom tertentu. Data tidak terstruktur seringkali memiliki sifat lebih bebas, tidak terbatas, dan lebih kompleks dibandingkan dengan data terstruktur. Berikut merupakan contoh dari data tidak terstruktur.
Kriteria data untuk AI
Kenapa kita harus mempelajari ini? Karena ada salah satu pepatah yang mengatakan “garbage in, garbage out” atau GIGO yang artinya bahwa output suatu sistem komputer tidak akan lebih baik dibandingkan inputnya. Maksudnya apa sih? Jika Anda penasaran dengan kalimat tersebut, berarti Anda berada di jalur yang benar. Yuk, kita pelajari bersama-sama detail dari GIGO!
Garbage in, Garbage out (GIGO)
Garbage in, garbage out yang dalam bahasa Indonesia memiliki arti sampah masuk, sampah keluar. Apakah Anda memahami arti kata “sampah” di sini? Mari kita samakan sudut pandang kita terkait kata tersebut supaya tidak terjadi salah paham.
Sampah di sini berarti data yang buruk, tidak wajar, tidak relevan, dan keliru sehingga nantinya akan menghasilkan AI yang tidak sesuai dengan harapan pengembang.
Perhatikan gambar berikut.
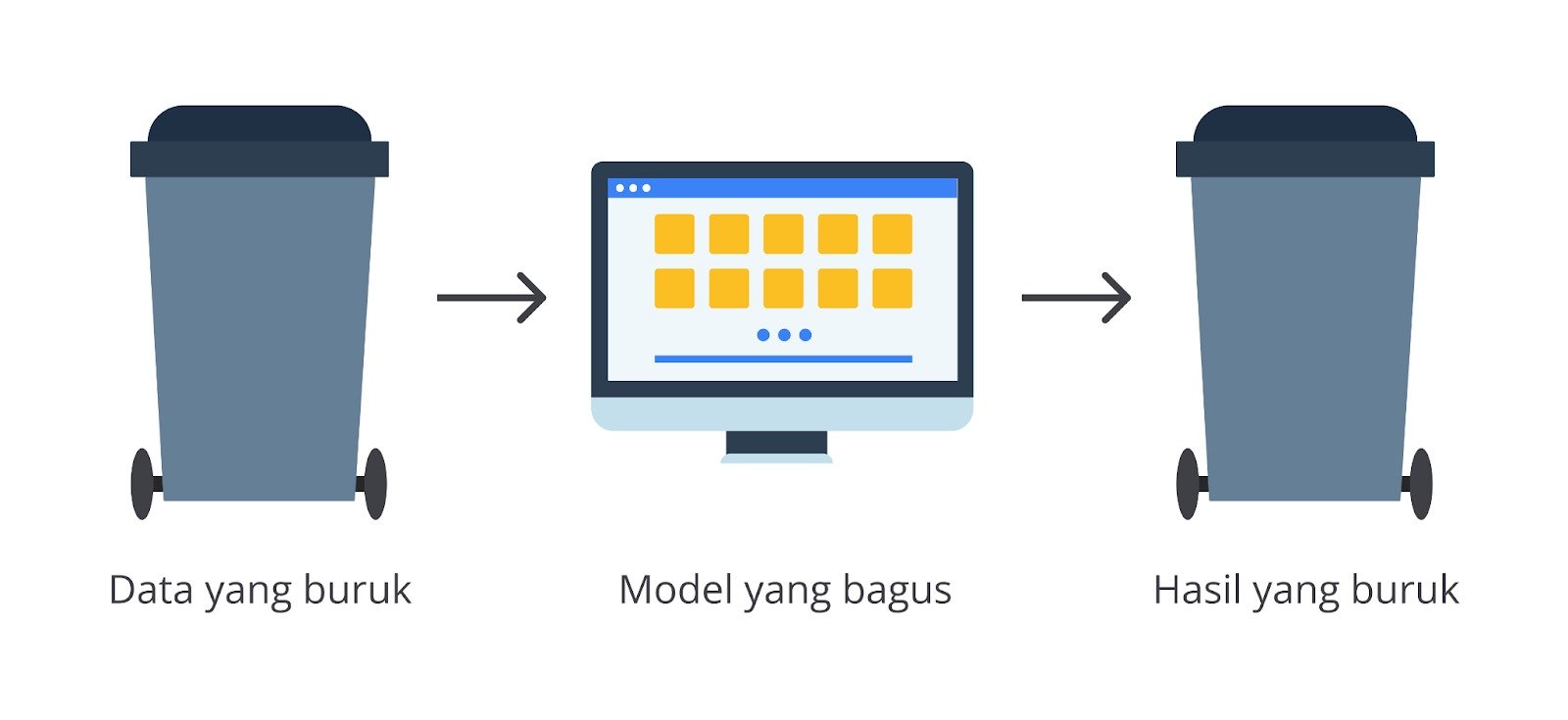
Dari gambar di atas kita bisa mendapatkan kesimpulan bahwa keluaran dari AI yang kita bangun sangat bergantung pada data masukkan yang diterima. Jika kita memiliki data masukkan yang buruk, besar kemungkinan AI yang dihasilkan tidak sesuai harapan.
Sedari tadi, kita telah membahas kualitas data dengan menyebut “data yang buruk”. Namun, hingga saat ini kita belum membahas apa saja masalah yang ada pada data sehingga sebuah data dapat memiliki kualitas yang buruk.
Masalah dalam Data
Sebelum kita memasuki permasalahan pada data, alangkah baiknya kita mengetahui terlebih dahulu mengapa bisa terjadi permasalahan dalam data. Permasalahan yang terjadi pada data biasanya disebabkan oleh kesalahan ketika pengumpulan atau pencatatan data. Data yang diperoleh dengan cara yang salah atau bahkan diambil dari sumber yang tidak dapat dipercaya juga bisa disebut sebagai data sampah.
Dari hal tersebut muncullah permasalahan umum pada data. Permasalahan umum yang sering terjadi terdapat pada kualitas data di antaranya, seperti data yang tidak relevan (incorrect), data berbeda dengan yang lain (outlier), data duplikat, data kosong, data yang tidak benar, dan masih banyak lagi. Pada kesempatan ini, kita akan membahas beberapa permasalahan umum yang terjadi dan bagaimana cara menanganinya.
Dari beberapa permasalahan di atas, setidaknya kita akan sering menemui data kosong. Kita dapat menanganinya dengan beberapa cara, seperti menghapus data yang kosong tersebut atau mengisi data kosong dengan nilai rata-rata atau median jika datanya berupa numerik.
Infrastruktur Data di Industri
Tujuan dari infrastruktur data adalah untuk menyediakan pengelolaan data yang baik, memproses data, dan menganalisis data yang ada. Jika kalian penasaran dengan tujuan infrastruktur data tersebut, mari kita jabarkan satu per satu tujuan dari infrastruktur data di industri.
- Manajemen data
Dengan menggunakan infrastruktur data yang baik maka tempat penyimpanan data akan terpusat. Hal ini akan membuat data dalam sebuah organisasi menjadi lebih aman dan mudah untuk dikelola. - Pemrosesan data
Infrastruktur data menyediakan daya komputasi dan sumber daya yang dibutuhkan untuk memproses dan menganalisis data dengan jumlah besar. Hal ini memungkinkan organisasi untuk melakukan analisis dan membuat pemodelan yang kompleks sehingga dapat membantu untuk mendapatkan informasi dan keputusan yang tepat berdasarkan data. - Integrasi data
Seperti yang sudah dijelaskan sebelumnya, dengan menggunakan infrastruktur data yang baik, kita dapat mengintegrasikan data dari berbagai sumber. - Keamanan data
Infrastruktur data menyediakan fitur dan protokol keamanan untuk melindungi data sensitif dari akses yang tidak sah, pencurian, atau penyalahgunaan. Hal ini memastikan kepatuhan terhadap peraturan dan praktik terbaik untuk keamanan dan privasi data.
Rangkuman Pengantar Machine Learning
Kita sudah berada di penghujung materi pengantar machine learning. Sampai sini, Anda memiliki pemahaman mendasar mengenai dasar machine learning, tipe-tipe machine learning, machine learning workflow, model maintenance, machine learning di industri, dan batasan machine learning. Mari kita rangkum secara saksama.
Pengenalan Machine Learning
Seperti yang sudah dijelaskan pada materi taksonomi AI, secara singkat machine learning (ML) merupakan salah satu cabang dari AI. Machine learning menggunakan algoritma untuk menganalisis data dalam jumlah yang besar, belajar dari pengetahuan yang ada pada data, dan akhirnya akan memberikan keputusan berdasarkan pengalaman yang dimilikinya.
Dalam satu dekade terakhir, machine learning menjelma sebagai bidang yang berkembang sangat pesat dan terus dikembangkan para ilmuwan seluruh dunia. Inilah inti dari berbagai macam produk berteknologi tinggi terkini. Perannya sangat signifikan dalam disrupsi industri 4.0 yang sarat dengan transformasi digital.
Traditional Programming vs Machine Learning
Agar kita memiliki perspektif yang sama terhadap machine learning, mari kita mundur sejenak dan mulai dengan mendefinisikan apa itu machine learning. Jika Anda melakukan pencarian di mesin pencari (search engine) seperti google, bing, DuckDuckGo dan lain sebagainya, Anda akan mendapatkan definisi yang beragam tentang machine learning. Hal ini tidak jadi masalah karena secara umum definisi tersebut memiliki kesamaan. Pada modul ini, kita akan membahas definisi machine learning yang disampaikan oleh Arthur Samuel.
Arthur Samuel merupakan seorang ilmuwan komputer yang memelopori kecerdasan buatan pada tahun 1959. Dia merupakan orang pertama yang memopulerkan term “machine learning”. Menurutnya, machine learning adalah suatu cabang ilmu yang memberi komputer kemampuan untuk belajar tanpa diprogram secara eksplisit. Bagaimana maksudnya?
Mari kita mundur sejenak ke masa sebelum machine learning ditemukan. Seperti dikemukakan oleh Moroney[2], prinsip atau paradigma pemrograman sejak permulaan era komputasi direpresentasikan dalam diagram berikut.
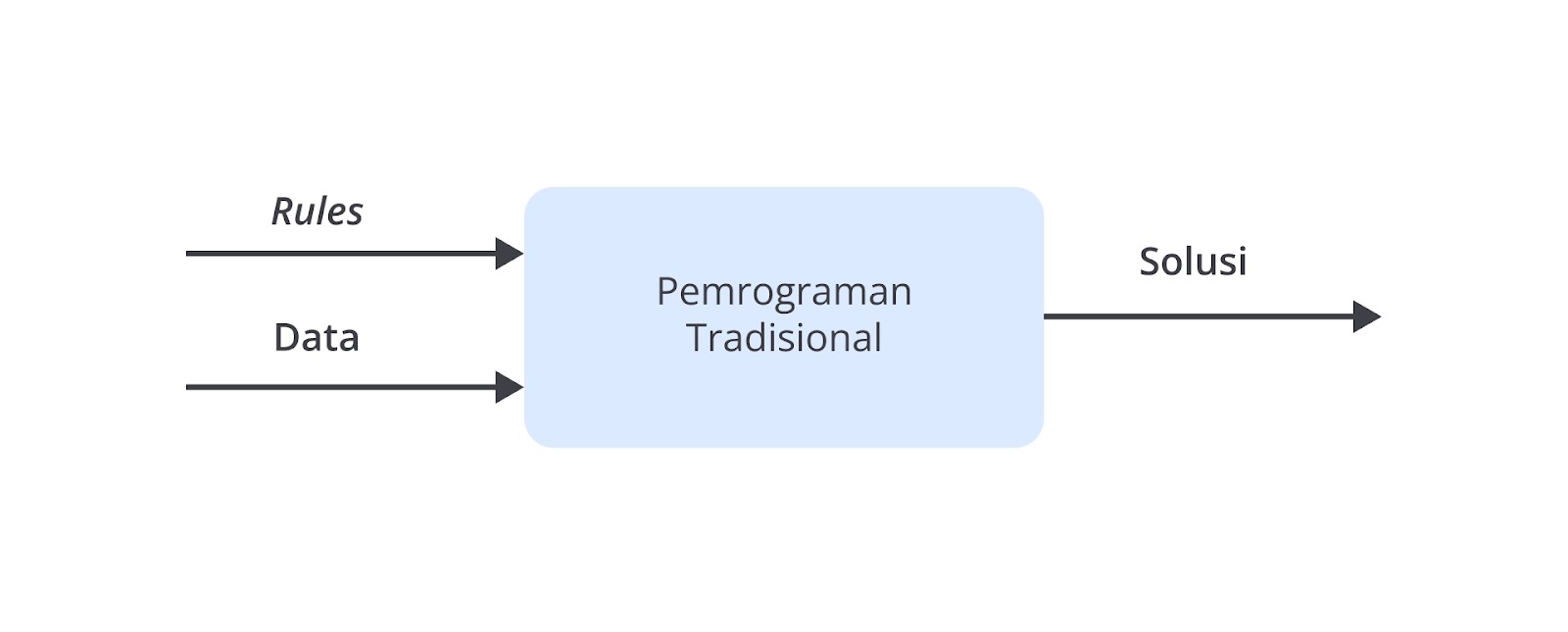
Pada pemrograman tradisional aturan dan data merupakan sebuah input bagi komputer. Secara eksplisit, aturan diekspresikan dalam bahasa pemrograman. Tambahan masukan berupa data kemudian akan menghasilkan solusi sebagai keluaran. Paradigma pemrograman seperti pada diagram di atas sering disebut sebagai pemrograman tradisional.
Pemrograman tradisional memiliki keterbatasan karena ia rigid dengan sekumpulan aturan “if” dan “else” untuk memproses data atau menyesuaikan dengan masukan. Sebagai contoh, kita ingin membuat sebuah program untuk melakukan klasifikasi pelanggan. Kita bisa menggunakan parameter “umur” sebagai data untuk membedakan kategori satu dengan lainnya.
Perhatikan contoh penggunaan if berikut.
- if umur <= 17:
- kategori = “Bukan prioritas”
- else:
- kategori = “Prioritas”
Pada contoh di atas, kita membuat algoritma program tradisional menggunakan python sebagai bahasa pemrogramannya. Tujuannya untuk melakukan klasifikasi jika umur kurang dari atau sama dengan 17 maka termasuk kategori bukan prioritas. Lalu, bagaimana jika ada penambahan parameter seperti “pendapatan”? Kondisinya akan berubah menjadi seperti berikut.
- if umur <= 17:
- if pendapatan <= 3000000:
- kategori = “Bukan prioritas”
- else:
- Kategori = “Prioritas”
- else:
- kategori = “Prioritas”
Mudah, bukan? Kita hanya perlu memberikan aturan dan data agar menghasilkan jawaban yang diinginkan. Namun, bayangkan jika kita ingin membuat klasifikasi pelanggan tersebut menjadi lebih detail. Bayangkan kita memiliki parameter sebagai berikut.
Parameter | Bukan Prioritas | Prioritas |
Pengeluaran | 0-1500000 | >1500000 |
Member | Bukan | Ya |
Jarak Rumah | >20 KM | <= 20 KM |
Pekerjaan | Tidak Bekerja | Bekerja |
Jumlah beli produk | < 10 | >= 10 |
Berdasarkan tabel di atas, tentu kita harus membuat kondisi if lebih banyak lagi. Bayangkan lebih jauh lagi jika kita memiliki sekitar 100 kondisi if else dengan berbagai parameter untuk menentukan segmentasi pelanggan. Tentu kondisi tersebut akan membuat programmer kewalahan.

Dengan kondisi yang sangat banyak, kita akan menemui masalah. Hal ini membuat kita menyadari bahwa pemrograman tradisional memiliki keterbatasan dalam menyelesaikan masalah. Perhatikan salah satu contoh jika kita memiliki banyak kondisi if else.
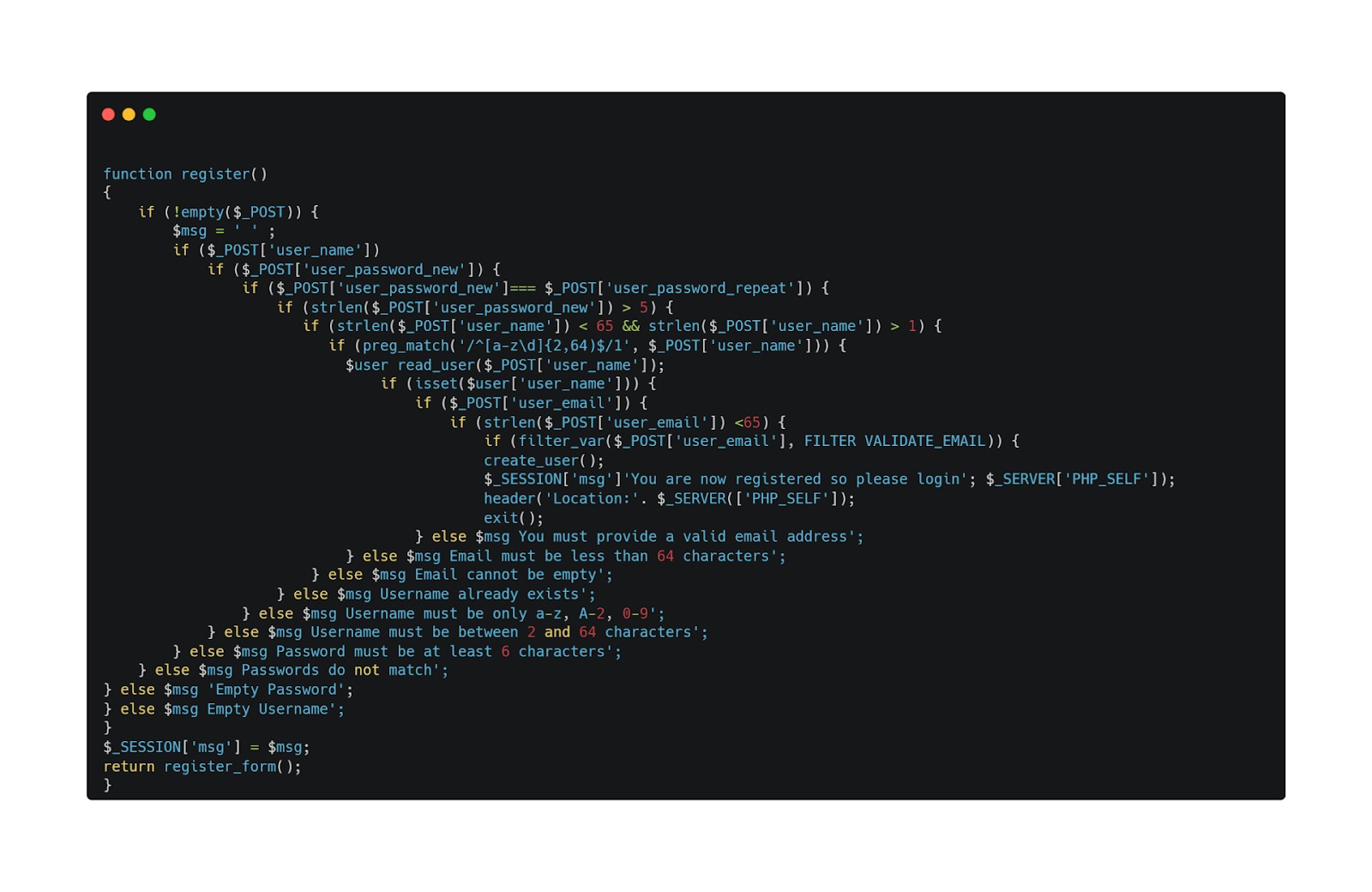
Pada pemrograman tradisional kita merepresentasikan masalah menjadi aturan dalam bahasa pemrograman. Kini ketika hal itu tidak lagi memungkinkan, kita perlu mengubah alur berpikir kita dengan cara yang berbeda. Paradigma baru pemrograman dengan machine learning adalah kita memiliki banyak sekali data dan label bagi data tersebut. Kita juga telah mengetahui keterkaitan antara data dengan label sebagai suatu solusi. Paradigma machine learning dapat direpresentasikan dalam diagram berikut.
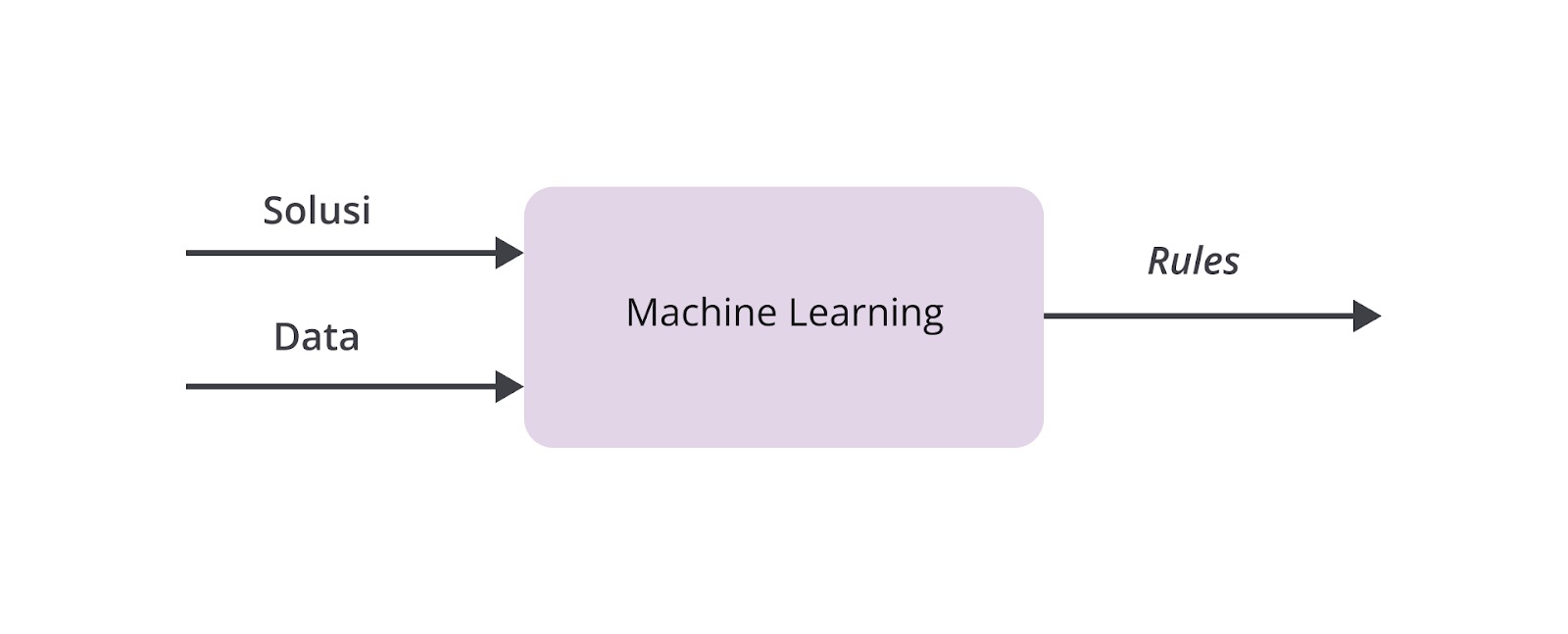
Ketika perusahaan memiliki banyak sekali data dan mengharuskan kita untuk mempelajari data tersebut tentu akan memakan waktu yang cukup lama atau bahkan jika data tersebut berisikan hal yang tabu bagi kita tentu akan membuat pusing tujuh keliling. Dengan menggunakan machine learning kita tidak perlu lagi mempelajari keseluruhan data dan membuat aturan secara ekspilisit. Dengan menggunakan machine learning kita hanya perlu menentukan algoritma sehingga machine learning dapat menentukan aturannya sendiri. Bagaimana caranya?
Algoritma machine learning dapat mencari pola tertentu dari sekumpulan data. Ia menentukan karakteristik data sehingga dapat menyimpulkan sebuah aturan. Perhatikan tanda panah di sebelah kanan diagram paradigma machine learning di atas. Paradigma machine learning menghasilkan aturan atau rules sebagai keluarannya.
Selanjutnya, aturan ini dapat digunakan untuk melakukan identifikasi dan prediksi bagi data baru yang relevan dengan model machine learning yang kita miliki. Dengan menerapkan machine learning, kita tidak perlu lagi menuliskan seluruh kondisi yang kompleks tersebut. Sangat efisien dan menarik, ‘kan?

Tipe-Tipe Machine Learning
Machine learning dibagi menjadi beberapa kategori. Pada modul ini, kita akan mempelajari tiga kategori yang paling sering digunakan, yaitu supervised learning, unsupervised learning, dan reinforcement learning.
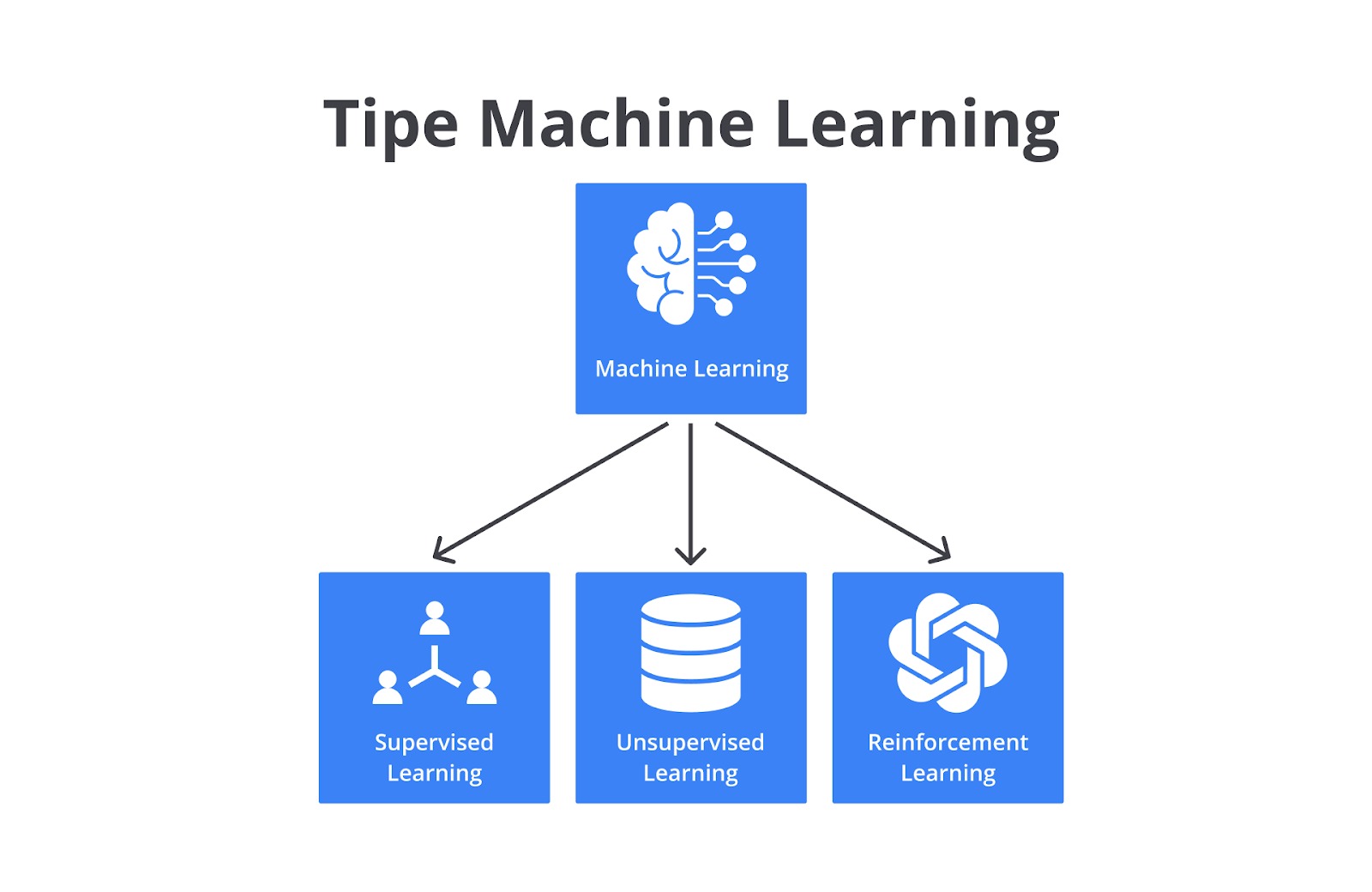
Supervised learning dan unsupervised learning adalah dua kategori yang mungkin familier bagi Anda. Namun, pertanyaannya adalah berdasarkan apakah pembagian kategori tersebut? Benar, pembagian kategori tersebut berdasarkan karakteristik data dan jenis supervisi yang didapatkan oleh program selama pelatihan. Apa maksudnya dan apa bedanya dengan reinforcement learning? Simak pembahasan berikut, ya.
Supervised Learning
Supervised learning adalah kategori machine learning yang dalam proses pembelajarannya menggunakan data yang memiliki label atau jawaban. Ketika data dimasukkan ke dalam model machine learning, model akan melakukan perhitungan komputasi terhadap input yang diberikan berdasarkan algoritma yang digunakan. Proses perhitungan komputasi tersebut akan dilakukan secara berulang kali hingga model dapat mengenali karakteristik masing-masing input dan dapat memberikan prediksi label atau jawaban yang sesuai dengan data yang diberikan (data aktual).
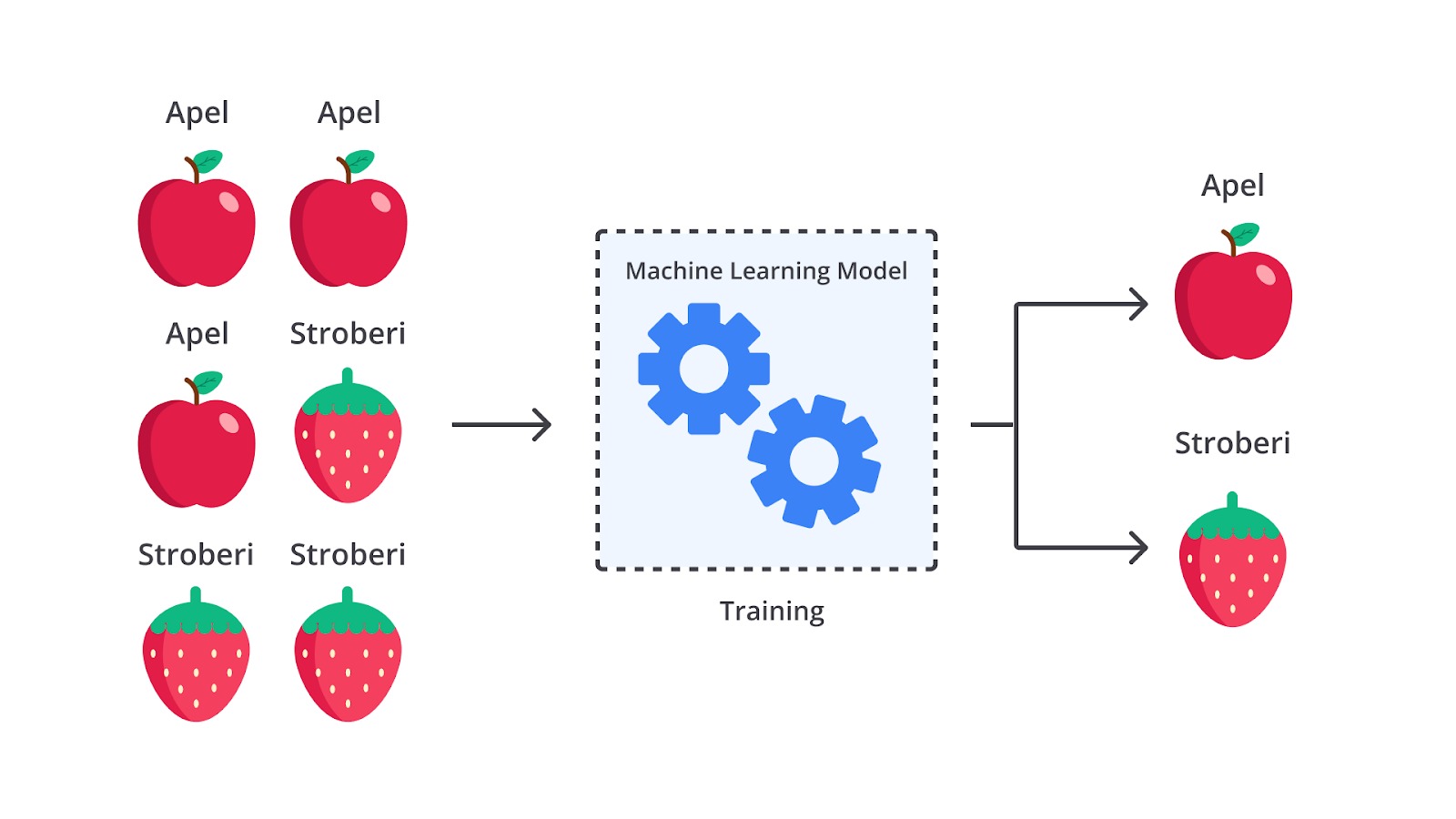
Perhatikan gambar di atas, bayangkan Anda memiliki kumpulan data buah-buahan yang terdiri dari apel dan stroberi beserta labelnya. Anda menginginkan model machine learning dapat mempelajari karakteristik kedua buah tersebut berdasarkan data dan label yang sudah ada. Kemudian, setelah model machine learning mempelajari karakteristik dari kedua buah tersebut, Anda mendapatkan sebuah model yang dapat melakukan klasifikasi terhadap buah apel dan stroberi. Akhirnya, saat Anda memberikan gambar dengan karakteristik serupa dengan apel maka model machine learning dapat mengenali gambar tersebut sebagai buah apel.
Cerita di atas merupakan salah satu contoh penerapan dari supervised learning. Menarik, bukan? Lebih lanjut Andrew Ng, seorang ilmuwan AI dari Stanford University menyatakan gagasan mengenai supervised learning. Menurutnya, supervised learning merupakan tipe machine learning yang hingga saat ini paling banyak digunakan pada berbagai bidang di industri.
Supervised learning digunakan pada berbagai bidang dikarenakan penggunaannya yang jelas, dengan data beserta jawaban atau label yang sudah dimiliki maka memungkinkan model machine learning mengerjakan tugas yang sudah ditentukan.
Selain itu, supervised learning mudah dipahami dan performa akurasinya pun mudah diukur untuk dievaluasi. Supervised learning dapat membantu permasalahan yang sangat beragam. Dua buah pilar pada supervised learning yaitu classification dan regression merupakan contoh metode yang paling sering digunakan. Seperti kisah sebelumnya, model tersebut dapat menjalankan tugas untuk melakukan klasifikasi pada data buah yang baru. Selain contoh yang telah disebutkan, supervised learning dapat mengerjakan tugas seperti mengklasifikasikan spam pada pesan, memprediksi harga rumah, dan lain sebagainya.
Unsupervised Learning
Berbeda dengan supervised learning, pada unsupervised learning data yang digunakan pada proses pembelajarannya tidak memiliki jawaban atau label. Sehingga, unsupervised learning melakukan proses belajar sendiri untuk melabeli atau mengelompokkan data.
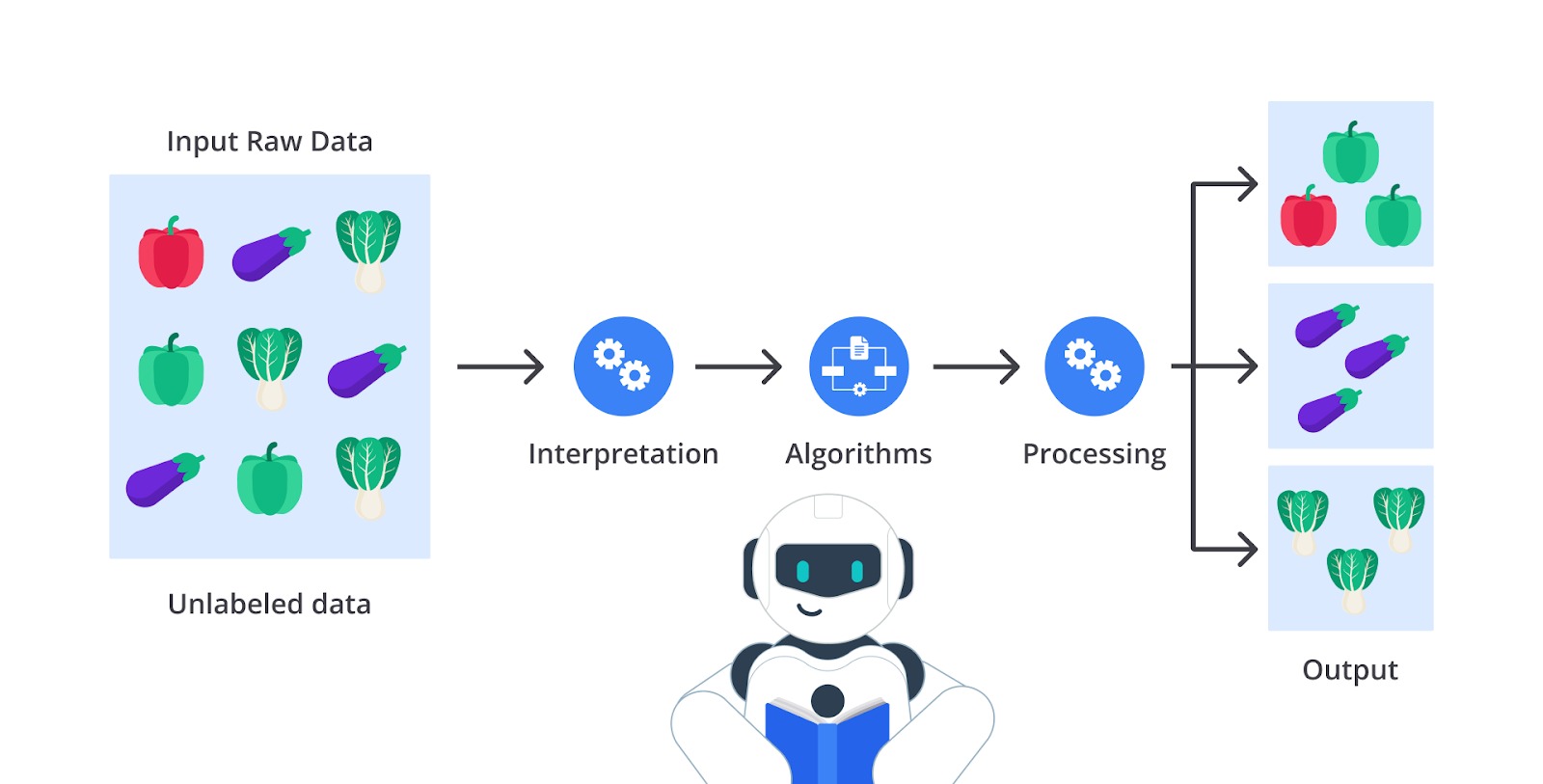
Perhatikan gambar di atas secara saksama, Anda mungkin sudah dapat menduga bahwa dataset yang digunakan tidak memiliki label bahkan masih berupa sayuran yang tercampur. Betul, kemampuan metode ini dapat menemukan kesamaan dan perbedaan pada dataset sehingga membuatnya ideal untuk analisis data eksplorasi, strategi penjualan silang, segmentasi pelanggan, dan pengenalan gambar dan pola seperti contoh di atas.
Mungkin rasa ingin tahu mengenai bagaimana unsupervised learning dapat mengeksplorasi data secara mandiri tumbuh di benak Anda. Unsupervised learning akan melakukan proses interpretasi yaitu menemukan sebuah pola berdasarkan karakteristik dataset yang ada, tahapan ini dibantu oleh algoritma yang dapat melakukan perhitungan komputasi untuk membantu menemukan pola atau struktur yang ada di dalamnya.
Akhirnya, model unsupervised learning dapat melakukan processing sehingga dapat mengelompokkan dataset dari yang semula masih tercampur menjadi beberapa kelompok dengan karakteristik yang serupa.
Dengan kata lain, berdasarkan cerita di atas unsupervised learning dapat dilihat sebagai robot/mesin yang berusaha belajar menjawab pertanyaan secara mandiri tanpa ada jawaban yang disediakan manusia.
Reinforcement Learning
Reinforcement learning adalah teknik yang mempelajari bagaimana membuat keputusan terbaik secara berurutan untuk memaksimalkan ukuran sukses kehidupan nyata. Entitas pembuat keputusan atau yang biasa disebut agent belajar melalui proses trial dan error. Bagaimana maksudnya? Perhatikan gambar berikut.
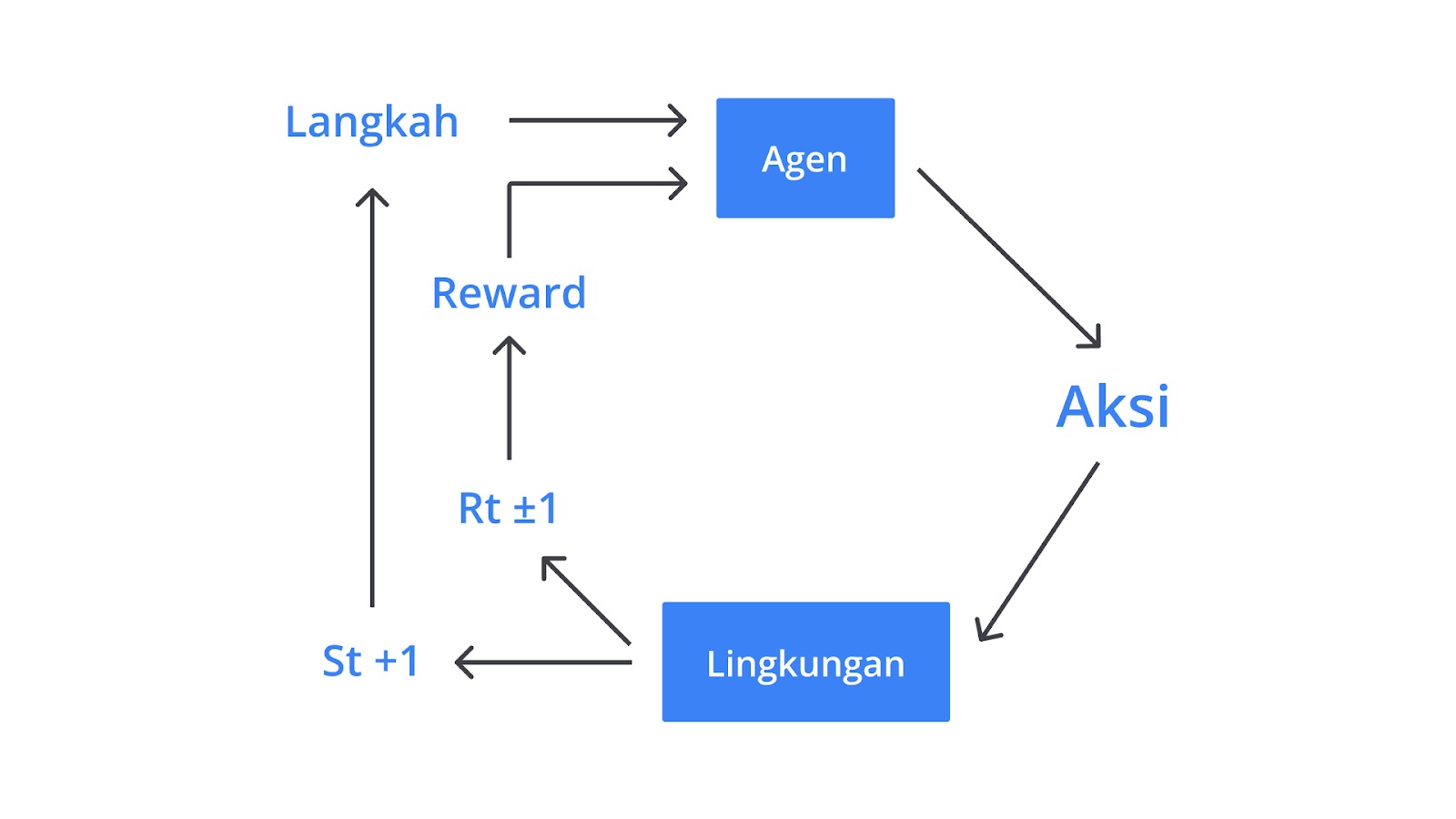
Gambar di atas merupakan cara kerja reinforcement learning. Pada Reinforcement Learning sebuah perangkat lunak yang disebut agent membuat pengamatan terhadap lingkungan dan melakukan aksi-aksi yang sesuai dari pengamatan yang dilakukan.
Tujuan dari agent adalah untuk melakukan tindakan sehingga menghasilkan keputusan terbaik, secara berurutan, untuk memaksimalkan ukuran sukses kehidupan nyata. Dengan kata lain, agent memiliki tujuan untuk melakukan tindakan yang menghasilkan reward/hadiah. Reward akan diberikan jika agent berhasil melakukan tindakan yang telah ditentukan oleh developer.
Tujuan dari agent adalah untuk melakukan tindakan-tindakan yang terus menambah reward/hadiah. Analoginya seperti teorema hadiah dan hukuman. Kita sebagai manusia cenderung melakukan hal yang membuat kita senang (hadiah) dan menghindari kegiatan yang membuat kita menderita (hukuman). Demikian halnya dengan agen pada RL yang berusaha untuk mendapatkan banyak hadiah dan meminimalisasi hukuman.
Agar kalian dapat memahami konsep reinforcement learning lebih jelas, mari kita simak ilustrasi cerita berikut.
Kai merupakan seorang mahasiswa yang belum memiliki informasi terkait peraturan yang ada di kampusnya dan ia berperan sebagai agent pada kasus kali ini. Kai ingin mempelajari peraturan kelas sebagai lingkungan barunya. Kelas tersebut memiliki peraturan untuk tidak menggunakan handphone ketika jam pelajaran berlangsung. Dengan adanya peraturan tersebut, Kai harus belajar untuk menaati peraturan tersebut sehingga ia harus belajar fokus di kelas dan tidak boleh menggunakan handphone.
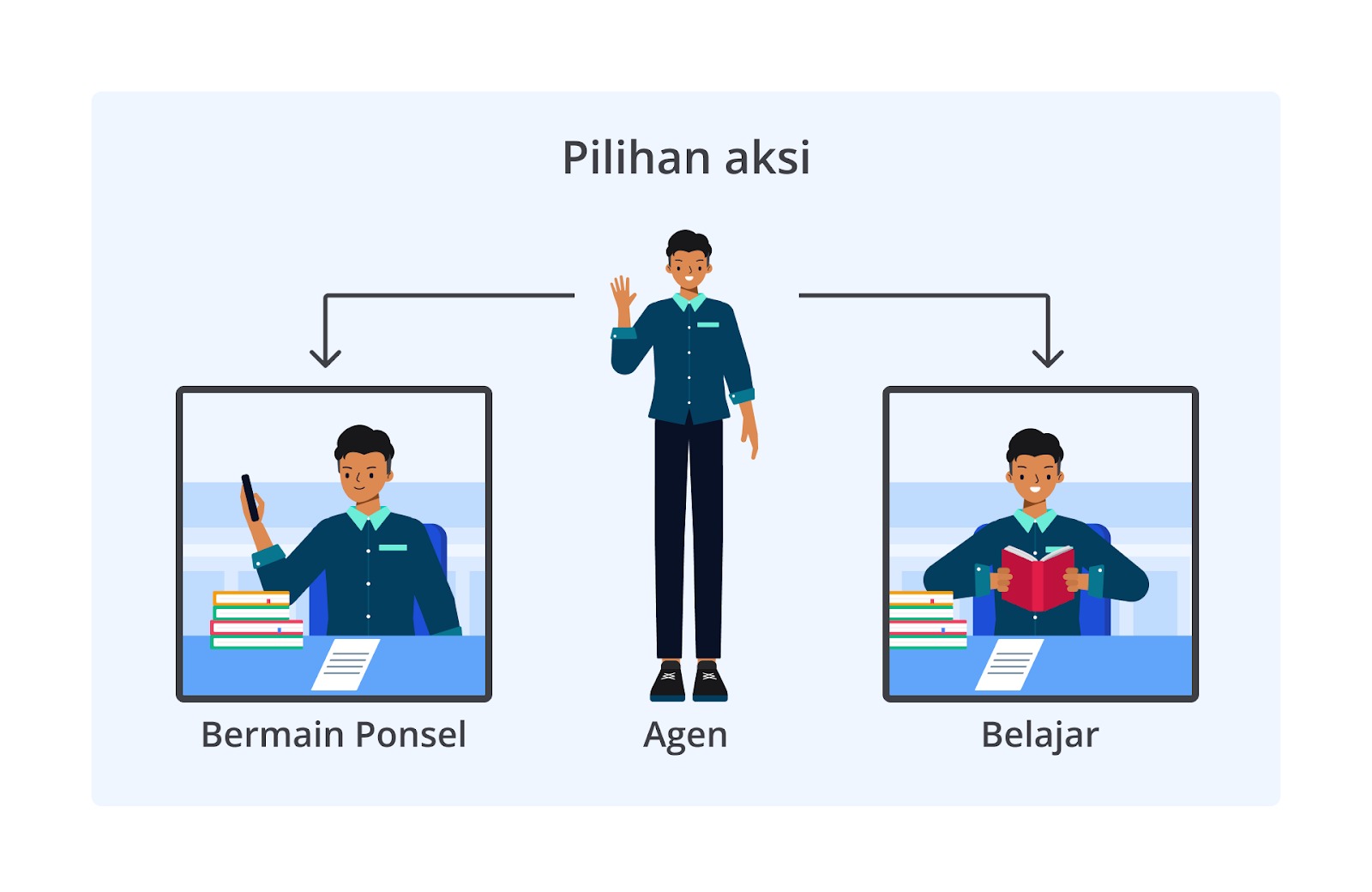
Karena Kai belum mengetahui apa yang harus dilakukannya di kelas, ia harus membuat policy di awal secara acak. Policy adalah panduan untuk agent melakukan aksi yang sesuai dengan lingkungannya. Nah, berdasarkan policy yang dibuat, agent akan melakukan aksi sesuai dengan policy tersebut. Setelah aksi dikerjakan, agent akan mendapatkan hadiah atau penalti.
Pada aksi pertama, agent memilih menggunakan handphone sehingga mendapatkan penalti yaitu pengurangan poin.

Karena Kai mendapatkan penalti, ia sebagai agent akan mengingatnya dan tentu menghindari penalti tersebut di masa depan. Setelah mendapat penalti, agent akan memperbarui policy-nya hingga ia bisa mendapatkan hadiah/poin sebanyak-banyaknya.
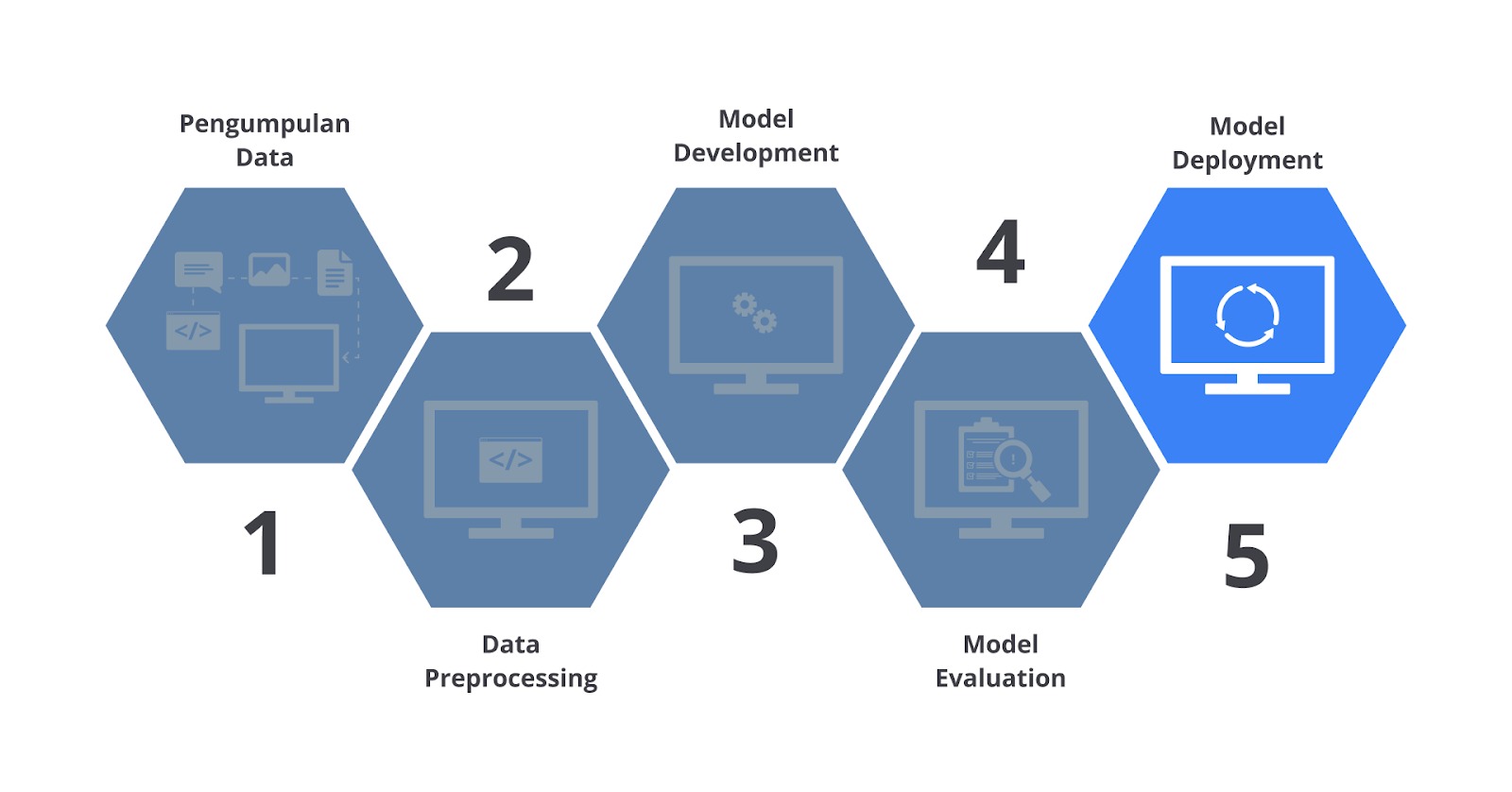
Machine Learning Workflow
Pada modul ini kita akan membahas beberapa tahapan machine learning workflow mulai dari pengumpulan data, data preprocessing, model development, model evaluation hingga model deployment.
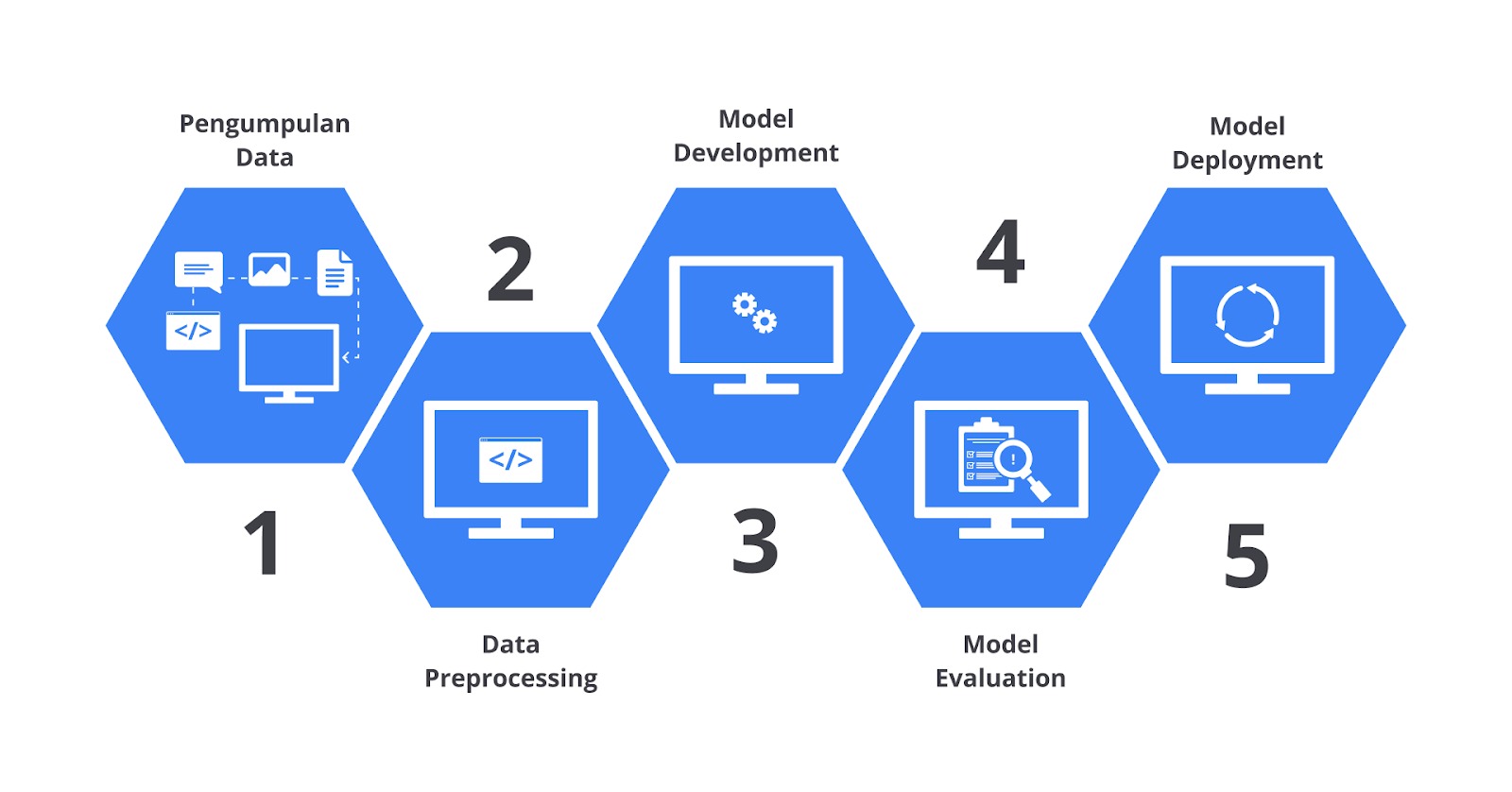
Machine learning workflow memiliki tahapan iteratif yang berarti prosesnya bisa berulang sesuai dengan kebutuhan. Anda dapat mengevaluasi ulang proses yang Anda jalankan dan kembali ke langkah sebelumnya ketika dibutuhkan. Machine learning worfklow umumnya memiliki lima tahapan yang berkesinambungan. Mari kita uraikan bersama tahapan umum pada proses pembuatan machine learning bersama-sama.
- Pengumpulan Data
Proses pengumpulan data dapat dilakukan dengan mengambil dataset dari sumber yang sudah disediakan, seperti dari kaggle, zenodo, UCI, dan lain sebagainya. Dari sumber-sumber tersebut, Anda dapat memilih, mengunduh, dan menggunakan dataset yang sesuai dengan kebutuhan Anda. Proses ini relatif mudah. Tantangannya adalah memilih dataset yang tepat untuk model Anda.
Namun, jika Anda adalah seorang Machine Learning Engineer pada sebuah perusahaan yang bertugas untuk membangun model ML untuk keperluan perusahaan, tentu proses pengumpulan datanya tidak semudah mengunduh dataset yang sudah jadi. Anda perlu mengumpulkan dan mengekstrak sendiri data dari berbagai sumber, seperti dari database, file, data sensor, dan sumber lainnya.
Pada tahap ini, Anda juga perlu berurusan dengan berbagai jenis tipe data mulai dari structured data (seperti excel file atau database SQL), hingga unstructured data (seperti text file, email, video, audio, gambar, data sensor, dan lainnya). Seorang analis yang bekerja pada sebuah perusahaan yang melakukan riset dan penasehatan global menyatakan bahwa lebih dari 80% data yang digunakan saat ini adalah unstructured data.
Namun, pada tahap ini dataset yang Anda miliki masih mentah. Agar dapat digunakan dengan maksimal pada pembangunan machine learning, dataset harus dikelola sedemikian rupa sesuai dengan tujuan pembangunan model machine learning. Tahapan tersebut disebut preprocessing data. - Data Preprocessing
Data preprocessing adalah tahapan pengolahan data lebih lanjut sehingga menjadi lebih siap dalam pengembangan model machine learning. Dengan kata lain, proses ini mengubah fitur-fitur data ke dalam bentuk yang mudah diinterpretasikan dan diproses oleh algoritma machine learning. Data preprocessing memiliki beberapa bagian, yaitu data cleaning, data transformation, dan data integration. Beberapa hal yang bisa dilakukan dalam proses data cleaning antara lain- penanganan missing value,
- data yang tidak konsisten,
- duplikasi data,
- ketidakseimbangan data,
- dan lain sebagainya.
Selain itu, ada juga beberapa hal yang bisa dilakukan untuk proses transformasi data seperti
- scaling atau merubah skala data agar sesuai dengan skala tertentu,
- standarisasi,
- normalisasi,
- mengonversi data menjadi variabel kategori,
- dan sebagainya.
Lalu, bagaimana dengan data integration? Berikut beberapa hal yang bisa dilakukan pada tahap data integration.
- Menggabungkan dataset.
- Menghilangkan fitur yang duplikat.
- Menyamakan format; dan lain sebagainya.
- Model Development
Setelah kita memiliki data yang sudah siap digunakan, mari kita mulai proses model development. Pada konteks machine learning, model development bisa berarti dua hal: pemilihan learning method atau algoritma ML; dan pemilihan hyperparameter terbaik untuk metode machine learning yang dipilih.
Ada seorang peneliti bernama K.P Murphy menuliskan sebuah kalimat,
“When we have a variety of models of different complexity (e.g., linear or logistic regression models with different degree polynomials, or KNN classifiers with different values of K), how should we pick the right one?”[17].
Berangkat dari pertanyaan tersebut, menentukan model yang sesuai dengan data yang kita miliki merupakan tahapan yang penting dalam machine learning workflow.
Jie Ding, et al dalam tulisannya “Model Selection Techniques -An Overview” [5] menyatakan bahwa tidak ada model yang cocok secara universal untuk data dan tujuan apa pun. Pilihan model atau metode yang tidak tepat dapat menyebabkan kesimpulan yang menyesatkan atau performa prediksi yang mengecewakan. Sebagai contoh, saat memiliki kasus klasifikasi biner, kita perlu mempertimbangkan model terbaik untuk data kita, apakah logistic regression atau SVM classifier.
Setelah kita menentukan metode yang cocok untuk data yang ada, kita perlu mengubah hyperparameter untuk mendapatkan performa terbaik dari model. Hyperparameter di sini merupakan variabel yang digunakan untuk mengontrol proses pelatihan model, contohnya seperti epochs, optimizer, dan lain sebagainya.
Dengan mengubah nilai hyperparameter saat kita menjalankan algoritma ML akan memberikan hasil atau performa model yang berbeda. Proses menemukan performa terbaik model dengan pengaturan hyperparameter yang berbeda ini juga disebut model development. - Model Evaluation
Setelah mengutak-atik model dengan hyperparameter yang berbeda, akhirnya Anda mendapatkan model yang kinerjanya cukup baik. Langkah selanjutnya adalah mengevaluasi model akhir pada data uji. Sederhananya, langkah evaluasi model dapat dijabarkan sebagai berikut.- Memprediksi label pada data uji.
- Menghitung jumlah dari hasil prediksi berdasarkan data uji. Pada tahap ini menghitung keseluruhan kondisi yang ada, seperti jumlah dari kondisi prediksi yang memiliki status benar ataupun salah.
- Membandingkan hasil prediksi dengan data label yang kita miliki. Dari data perbandingan ini, kita dapat menghitung akurasi atau performa model.
Pada prinsipnya proses model evaluation adalah menilai kinerja model ML pada data baru, yaitu data yang belum pernah “dilihat” oleh model sebelumnya. Evaluasi model bertujuan untuk membuat estimasi generalisasi error dari model yang dipilih, yaitu seberapa baik kinerja model tersebut pada data baru.
Idealnya, model machine learning yang baik adalah model yang tidak hanya bekerja dengan baik pada data training, tetapi juga pada data baru. Oleh karena itu, sebelum mengirimkan model ke tahap produksi, Anda harus cukup yakin bahwa performa model akan tetap baik dan tidak menurun saat dihadapkan dengan data baru.
- Model Deployment
Bonjour! Sampai sini kita telah belajar mulai dari pengumpulan data, data preprocessing, model development, hingga model evaluation. Bagaimana perjalanan Anda, menyenangkan, bukan? Selamat, kita telah sampai pada tahapan terakhir machine learning workflow yaitu model deployment.
Setelah model dievaluasi, model siap untuk dipakai pada tahap produksi yang biasanya disebut model deployment. Caranya adalah dengan menyimpan model yang telah dilatih dari tahap preprocessing hingga pipeline prediksi. Selanjutnya, jangan lupa untuk membawa seluruh tahapan pada data preprocessing untuk digunakan pada tahapan prediksi. Simpan seluruh tahapan yang dilakukan pada data preprocessing pada sebuah fungsi bernama predict yang berguna untuk memproses data baru. Kemudian deploy model tersebut ke sebuah platform seperti web, mobile, IoT dan lain sebagainya. Last but not least, kita dapat membuat prediksi dengan memanggil fungsi predict() yang sebelumnya telah dibuat. Terdengar sangat mudah, bukan?
Agar penjelasan di atas lebih terbayang mari kita simak gambar berikut. Geron [6] memberikan contoh ilustrasi model deployment seperti tampak dalam gambar berikut.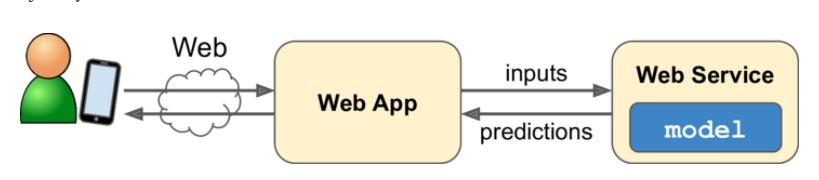
Untuk lebih memahami gambar di atas mari kita analogikan dengan sebuah studi kasus regresi. Sebuah model regresi untuk menentukan harga rumah akan digunakan dalam situs web. Pengguna akan mengetik beberapa data tentang lokasi yang diinginkan dan mengeklik tombol “Prediksi Harga”. Proses ini akan mengirimkan query yang berisi data ke server, kemudian meneruskannya ke aplikasi web Anda. Terakhir, kode akan memanggil fungsi predict() untuk memberikan hasil prediksi pada Anda.
Bagaimana semakin dalam makin seru, ‘kan?
Dalam pengembangannya, machine learning melibatkan cukup banyak proses dan infrastruktur untuk membangun modelnya. Memahami algoritma machine learning memang penting, tetapi memahami keseluruhan proses machine learning hingga ke tahap produksi juga tak kalah pentingnya.
Model Maintenance
Umumnya sebuah model yang di-deploy kinerjanya akan turun seiring waktu. Penurunan tersebut terjadi karena model akan terus menemui lebih banyak data baru seiring waktu sehingga menyebabkan akurasi model menurun.
Misalnya, sebuah model untuk memprediksi harga rumah yang dikembangkan dengan data pada tahun 2010. Model yang dilatih pada data dalam tahun tersebut akan menghasilkan prediksi yang buruk untuk data tahun 2020. Hal tersebut akan diketahui ketika kita melakukan evaluasi terhadap yang sudah di-deploy sehingga kita harus melakukan optimasi pada model tersebut.
Sebagai contoh dalam kehidupan sesungguhnya, bayangkan kita memiliki sebuah model machine learning yang dapat memprediksi harga sebuah rumah berdasarkan beberapa fitur seperti jumlah kamar, luas tanah dan lain sebagainya. Model machine learning ini dilatih dengan data penjualan pada tahun 2010 dan telah melakukan prediksi dengan baik selama satu tahun kedepan. Namun, seiring berjalannya waktu model ini mengalami penurunan performa sehingga akan menghasilkan prediksi yang buruk pada tahun-tahun berikutnya. Penurunan performa ini dapat diakibatkan oleh banyak faktor, seperti kebiasaan pelanggan, inflasi, atau faktor alami seperti bencana alam. Penurunan performa akan diketahui ketika kita melakukan evaluasi sehingga kita harus melakukan optimasi pada model tersebut.
Untuk mengatasi masalah ini, ada 2 teknik dasar dalam menjaga agar model selalu bisa belajar dengan data-data baru. Dua teknik tersebut yaitu manual retraining dan continuous learning.
Manual Retraining
Teknik pertama adalah melakukan ulang proses pelatihan model dari awal sehingga data-data baru yang ditemui di tahap produksi akan digabung dengan data lama. Selanjutnya, model dilatih ulang dari awal menggunakan data lama dan data baru.
Salah satu kekurangan dari proses ini adalah dari sisi waktu dan efektivitas. Proses ini membutuhkan effort yang lebih untuk dilakukan mulai dari pengumpulan data, data preprocessing, penggabungan data lama dengan data baru, hingga proses training. Bayangkan ketika kita harus melatih ulang model dalam jangka waktu mingguan atau bahkan harian, tentunya proses tersebut akan memakan waktu yang lama, bukan?
Proses manual retraining ini memang membutuhkan waktu yang lama dan effort yang lebih banyak. Namun, manual retraining memungkinan kita menemukan model-model baru atau atribut-atribut baru yang menghasilkan performa lebih baik di masa kini bahkan di masa yang akan datang.
Continuous Learning
Teknik kedua untuk menjaga model kita up-to-date adalah continuous learning yang menggunakan sistem terotomasi dalam pelatihan ulang model. Berikut alur dari continuous learning.
- Menyimpan data-data baru yang ditemui pada tahap produksi. Contohnya, ketika sistem mendapatkan harga emas naik, data harga tersebut akan disimpan di database.
- Ketika data-data baru yang dikumpulkan cukup, lakukan pengujian akurasi dari model terhadap data baru.
- Jika akurasi model menurun seiring waktu, gunakan data baru, atau kombinasi data lama dan baru untuk melatih dan men-deploy ulang model.
Sesuai namanya, 3 proses di atas dapat terotomasi sehingga kita tidak perlu melakukannya secara manual.
Dengan merawat dan melakukan pembaruan pada model yang telah di-deploy, ini membuat tugas yang dilakukan oleh machine learning tetap konsisten dan tepat sesuai dengan kondisi dan situasi di lapangan.
Machine Learning di Industri
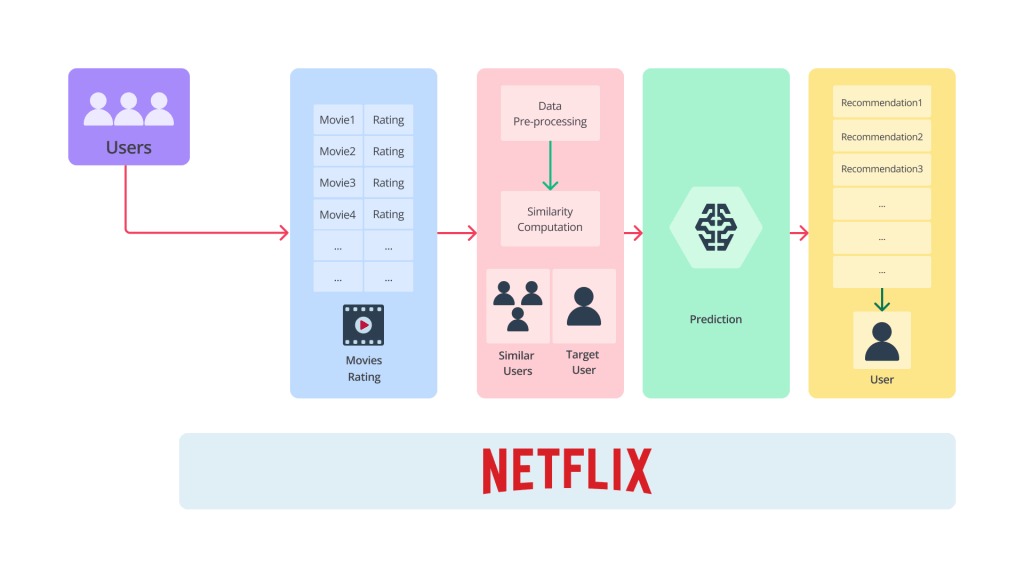
Pada era digital saat ini, banyak sekali perusahaan yang menerapkan machine learning untuk membantu menyelesaikan pekerjaannya. Salah satu contoh penerapan AI adalah sistem rekomendasi yang dikembangkan oleh Netflix. Netflix adalah layanan streaming berbasis langganan yang memungkinkan pengguna menonton acara TV dan film di perangkat yang terhubung ke Internet.
Netflix menggunakan machine learning untuk merekomendasikan film kepada pengguna mereka melalui sistem rekomendasi yang mereka bangun. Sistem ini berperan penting dalam meningkatkan pengalaman pengguna dengan menyediakan rekomendasi yang disesuaikan dengan preferensi masing-masing pengguna. Berikut adalah gambaran dari sistem rekomendasi yang dikembangkan Netflix.
Rekomendasi sistem yang dibangun oleh Netflix berjalan sesuai dengan tugasnya, hal ini dibuktikan oleh meningkatnya waktu streaming setelah menerapkan rekomendasi sistem tersebut. Menurut Todd Yellin sebagai wakil presiden dari divisi product mengatakan bahwa lebih dari 80% pengikut memercayai dan mengikuti hasil rekomendasi yang diberikan oleh sistem rekomendasi Netflix. Di sisi lain, Netflix percaya bahwa mereka dapat kehilangan hingga 1 miliar dollar setiap tahunnya jika tidak menggunakan sistem rekomendasi tersebut.
Hal tersebut menjadi sangat masuk akal dikarenakan setiap kali pengguna menggunakan Netflix, rekomendasi sistem tersebut akan memberikan bantuan untuk mencari film kepada pengguna dengan usaha yang ringan. Sebagai pengguna, kita tidak perlu lagi melakukan scrolling dengan waktu yang lama, berdasarkan perhitungan yang dilakukan oleh Netflix mereka menyatakan bahwa butuh waktu kurang lebih 90 detik untuk mendapatkan perhatian pengguna untuk memilih film. Hal tersebut yang membuat pengguna terus berlangganan dan Netflix dapat menghindari kerugian karena dampak dari ditinggalkan oleh pelanggan.
Apakah Anda penasaran ingin mengetahui cara rekomendasi Netflix ini bekerja? Mari kita gali sedikit lebih dalam agar lebih memahami salah satu penerapan machine learning yang sudah ada di industri saat ini.
Netflix menggunakan beberapa data yang diambil dari masing-masing pengguna sehingga dapat memperbesar kemungkinan pengguna tersebut menonton film karena sesuai dengan karakteristiknya. Faktor yang diambil dan digunakan pada sistem rekomendasi Netflix yaitu
- Rating yang diberikan,
- Riwayat pencarian atau menonton,
- Kesamaan dengan pengguna yang lainnya,
- Informasi terkait film yang ditonton,
- Jumlah waktu menonton dalam sehari,
- Gawai yang digunakan,
- Waktu regional ketika pengguna menonton (siang/sore/malam).
Setelah data yang dibutuhkan untuk menghasilkan rekomendasi dikumpulkan, selanjutnya data tersebut akan digunakan untuk menjadi input yang akan diproses oleh algoritma. Hasil dari proses itulah yang nantinya akan digunakan oleh Netflix. Lalu, muncul di benak kita semua “bagaimana Netflix mengolah data tersebut serta algoritma apa yang digunakannya?” Mari kita cari tahu bersama algoritma apa yang digunakan Netflix sehingga dapat menghasilkan output yang sangat baik sebelumnya.
Pada tulisannya, Netflix menyebutkan bahwa mereka menggunakan beberapa macam algoritma untuk menghasilkan rekomendasi sistem, tetapi tidak menjelaskan arsitekturnya secara detail. Beberapa algoritma yang digunakan Netflix, antara lain personalised video ranking (PVR), top-N Video ranker, trending now ranker, continue watching ranker, dan video-video similarity ranker. Jika Anda ingin mengetahui lebih detail dari masing-masing algoritma tersebut, pelajari di sini, ya.
Setelah algoritma menjalankan tugasnya, Netflix akan memberikan hasil rekomendasinya (output) berupa urutan film yang cocok dengan karakteristik penggunanya. Netflix memberikan hasil rekomendasinya dengan sistem peringkat berbasis dua tingkat yaitu pada kolom (rekomendasi terbaik dari kiri) dan baris (rekomendasi terbaik dari atas).
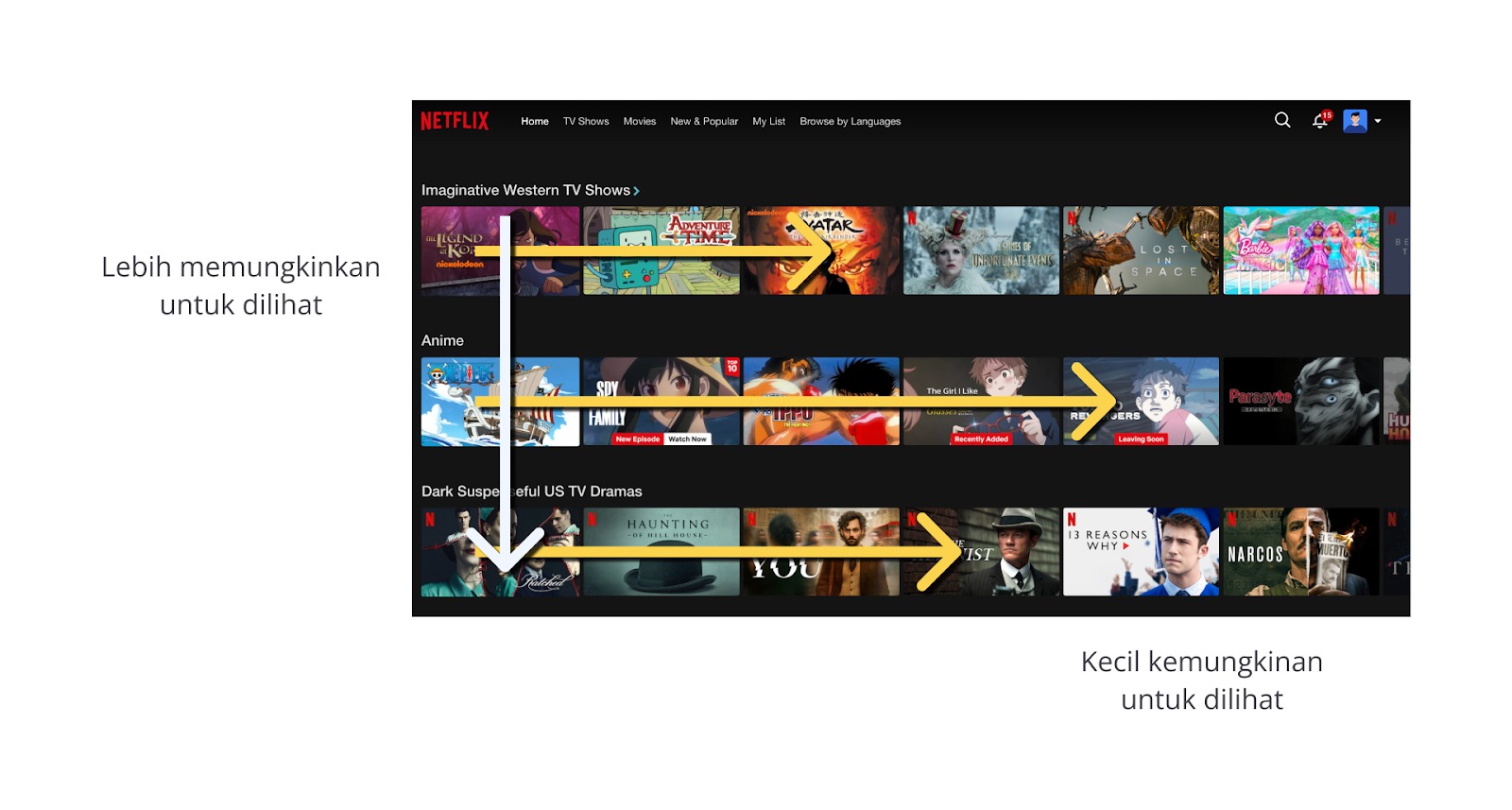
Mengapa Netflix menggunakan baris dan kolom pada hasil rekomendasinya? Hal tersebut dijelaskan bahwa ada keuntungan dari dua buah sudut pandang yang berbeda yaitu pengguna dan perusahaan. Sebagai pengguna, itu membuat rekomendasi yang disajikan lebih koheren karena memiliki hubungan yang erat pada baris atau kolom yang sama. Selain itu, sebagai perusahaan akan mudah mendapatkan feedback ketika pengguna terindikasi tidak menyukai urutannya dengan cara melakukan scroll dan mengabaikan rekomendasinya.
Berdasarkan sudut pandang perusahaan tersebut, Netflix melakukan model maintenance berdasarkan feedback dari pengguna agar dapat memberikan rekomendasi yang relevan setiap waktunya. Netflix akan melakukan pelatihan ulang model untuk meningkatkan akurasi dari prediksi yang diberikan berdasarkan film yang paling sering ditonton oleh pengguna.
Pengenalan Deep Learning
Deep learning adalah bagian dari bidang keilmuan AI yang mengajarkan komputer untuk memproses data yang terinspirasi dari cara kerja otak manusia. Model deep learning dapat mengerjakan tugas yang lebih kompleks dari machine learning. Dengan kompleksitas yang cukup tinggi, model deep learning dapat mengenali gambar, teks, suara, dan data lainnya.
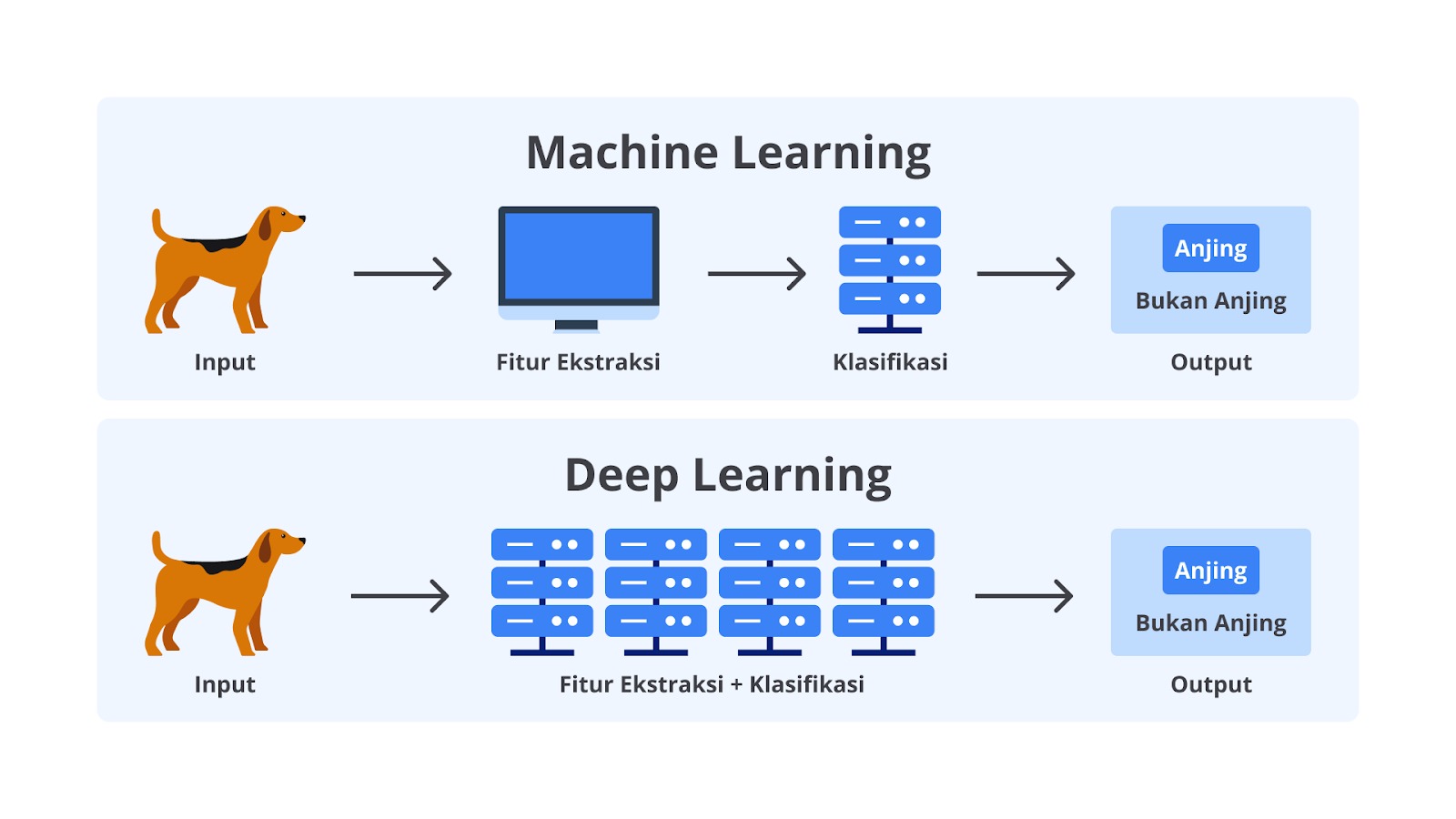
Anda pasti masih ingat pada modul Data untuk AI, kita mempelajari data tidak terstruktur berupa gambar, suara, dan bentuk lainnya. Nah, dengan menggunakan deep learning kita dapat membuat sebuah sistem AI yang dapat mengotomatiskan tugas-tugas yang biasanya membutuhkan kecerdasan manusia seperti mendeskripsikan gambar atau mengubah file suara ke dalam teks secara langsung seperti gambar di atas.
Lalu, mengapa deep learning ini menjadi bagian yang penting dari pengenalan AI? Seperti yang telah disinggung sebelumnya, deep learning merupakan model yang dapat melatih komputer untuk berpikir layaknya manusia sehingga dapat menggantikan tugas yang selama ini kita lakukan secara manual.
Deep learning terdiri dari 3 atau lebih lapisan atau biasa disebut layers. Ia berperan sebagai pengganti otak manusia sebagai jaringan saraf yang memungkinkan model mempelajari data yang sangat besar.
Lantas, apa itu jaringan saraf manusia yang ada pada layers tersebut? Pertanyaan tersebut akan segera terjawab karena kita akan mempelajari dan mengenali jaringan saraf atau artificial neural network yang berperan dalam pembangunan deep learning
Mengenal Artificial Neural Network
ANN merupakan salah satu model ML yang multiguna, powerful, dan memiliki skalabilitas tinggi. Dengan kelebihan tersebut, ANN sangat ideal untuk dipakai dalam menangani masalah ML yang sangat kompleks, mulai dari mengklasifikasi miliaran gambar, mengenali ratusan bahasa dunia, merekomendasikan video ke ratusan juta pengguna, sampai belajar mengalahkan juara dunia permainan papan GO.
Namun, tahukah Anda apa itu ANN? Artificial Neural Network (ANN) atau Jaringan Saraf Tiruan adalah sebuah model machine learning yang terinspirasi dari neuron/saraf yang terdapat pada otak manusia.
Sebelum mengenali jaringan saraf manusia pada komputer, sebaiknya kita mempelajari sedikit terkait saraf biologis (neuron) dalam otak manusia sesungguhnya.
National Institute of Neurological Disorders and Stroke[7] dalam tulisannya yang berjudul “Brain Basics: The Life and Death of a Neuron” menyatakan bahwa neuron atau saraf adalah pembawa pesan/informasi. Mereka menggunakan impuls listrik dan sinyal kimiawi untuk mengirimkan informasi antara area otak yang berbeda, serta antara otak dan seluruh sistem saraf.
Sebuah saraf terdiri dari 3 (tiga) bagian utama, yaitu akson, dendrit, dan badan sel yang di dalamnya terdapat nukleus. Nukleus berisi materi genetik dan bertugas mengontrol seluruh aktivitas sel. Akson adalah cabang yang terlihat seperti ekor yang panjang. Ia bertugas untuk mengirimkan pesan dari sel. Panjang akson berkisar antara beberapa kali lebih panjang dari badan sel, bahkan hingga 10 ribu kali lebih panjang dari badan sel; sedangkan dendrit adalah cabang-cabang pendek yang terlihat seperti cabang pohon yang tugasnya menerima pesan untuk sel.
Setiap ujung akson dari sebuah neuron terhubung dengan dendrit dari neuron lainnya. Neuron berkomunikasi satu sama lain dengan mengirimkan senyawa kimia yang disebut neurotransmitter. Ia melintasi ruang kecil (synapse) antara akson dan dendrit neuron yang berdekatan. Ketika sebuah neuron mendapatkan rangsangan, neuron tersebut akan mengirim sinyal ke neuron lainnya. Seperti ketika kita tidak sengaja menyentuh panci yang panas, saraf di tangan kita mengirim sinyal ke saraf lain sampai ke otak dan kita merespon dengan cepat. Pengiriman sinyal antar neuron terjadi sangat cepat dengan kisaran beberapa milidetik saja.
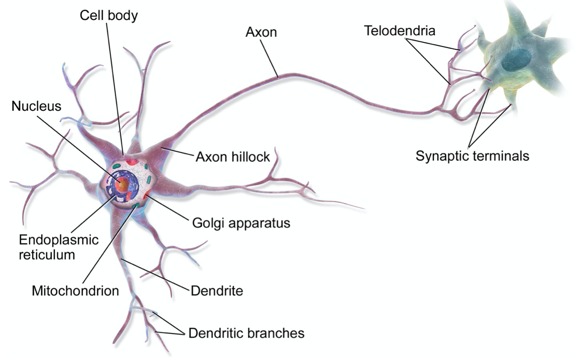
Cara kerja dari sebuah neuron terlihat sangat sederhana. Namun, neuron-neuron tersebut terorganisir dalam sebuah jaringan berisi miliaran neuron. Setiap neuron terhubung dengan beberapa ribu neuron lainnya. Dengan jumlah yang luar biasa besar tersebut, banyak pekerjaan kompleks yang dapat diselesaikan.
Nah, kita akan mempelajari neuron tersebut sebagai acuan untuk membuat sebuah jaringan saraf tiruan dalam komputer. Jaringan saraf tiruan ini memiliki komponen dasar bernama perceptron. Frank Rosenblatt dari Cornell Aeronautical Library adalah ilmuwan yang pertama kali menemukan perceptron pada tahun 1957 [8]. Perceptron pada jaringan saraf tiruan terinspirasi dari neuron pada jaringan saraf di otak manusia. Pada jaringan saraf tiruan, perceptron dan neuron merujuk pada hal yang sama.
Lantas bagaimana perceptron bekerja pada jaringan saraf tiruan?
Sebuah perceptron menerima masukan berupa bilangan numerik. Perceptron kemudian memproses masukan tersebut untuk menghasilkan sebuah keluaran. Agar lebih memahami cara kerja perceptron, kita akan menggunakan diagram di bawah.
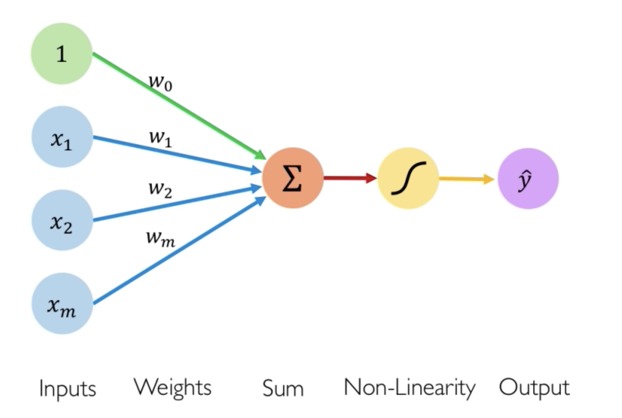
Berikut adalah proses yang menjelaskan bagaimana perceptron bekerja.
- Input menerima masukan berupa angka-angka.
- Setiap input memiliki bobot masing-masing. Bobot adalah parameter yang akan dipelajari oleh sebuah perceptron dan menunjukkan kekuatan node tertentu.
- Selanjutnya adalah tahap penjumlahan input. Pada tahap ini, setiap input akan dikalikan dengan bobotnya masing masing, lalu hasilnya akan ditambahkan dengan bias yang merupakan sebuah konstanta atau angka. Nilai bias memungkinkan Anda untuk mengubah kurva fungsi aktivasi ke atas atau ke bawah sehingga bisa lebih fleksibel dalam meminimalisasi eror. Penjelasan lebih lanjut tentang bias dapat Anda pelajari pada tautan berikut.
Hasil penjumlahan pada tahap ini biasanya disebut weighted sum.
- Berikutnya, aplikasikan weighted sum pada fungsi aktivasi atau disebut juga Non-Linearity Function. Fungsi aktivasi digunakan untuk memetakan nilai yang dihasilkan menjadi nilai yang diperlukan, misalnya antara (0, 1) atau (-1, 1). Fungsi ini memungkinkan perceptron dapat menyesuaikan pola untuk data yang non linier. Penjelasan lebih lanjut tentang fungsi aktivasi akan diulas pada paragraf di bawah.
- Setelah semua langkah di atas terlewati, akhirnya kita memperoleh output berupa hasil perhitungan sebuah perceptron dalam bentuk bilangan numerik.
Setelah mengetahui cara kerja perceptron, kita akan membahas tentang hidden layer. Sebuah hidden layer adalah dense layer yang berada di antara input layer dan output layer. Perhatikan ilustrasi berikut yang menunjukkan jaringan saraf di sebelah kiri memiliki 1 hidden layer, sedangkan jaringan saraf di sebelah kanan memiliki 4 buah hidden layer.
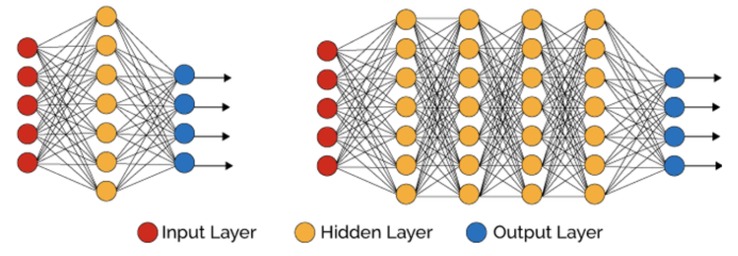
Dalam sebuah jaringan saraf tiruan, input layer dan output layer harus selalu ada, tetapi untuk hidden layer bisa ada beberapa atau tidak sama sekali. Hidden layer dan output layer sama-sama merupakan sebuah layer yang memiliki beberapa perceptron, sedangkan input layer adalah sebuah layer yang hanya menampung angka-angka.
Hidden layer diberikan nama hidden karena sifatnya yang tersembunyi. Pada sebuah sistem jaringan saraf, input dan output layer merupakan lapisan yang dapat kita amati, sementara hidden layer, tidak.
Pada sebuah jaringan saraf tiruan, semakin banyak jumlah hidden layer dalam sistem, semakin lama jaringan saraf tersebut memproduksi hasil, tetapi juga semakin kompleks masalah yang dapat diselesaikan.
Gambaran Penerapan Deep Learning di Industri
Deep learning sebagai bagian dari keilmuan machine learning sudah diimplementasikan pada berbagai bidang industri saat ini. Jika Anda ingat kembali pada materi data untuk AI disebutkan bahwa data tidak terstruktur dapat digunakan untuk membangun sebuah sistem berbasis AI. Untuk mengolahnya, kita dapat menggunakan model deep learning untuk mempelajari data tersebut sehingga dapat melakukan tugas berdasarkan data dan permasalahan yang dialami oleh developer.
Sebelum era deep learning, pendekatan yang dilakukan untuk tugas klasifikasi gambar melibatkan tim expert (ahli) yang menjelaskan bagaimana karakteristik atau fitur hewan tertentu. Misal, seekor burung memiliki sayap, bentuk paruh, dan bentuk kaki tertentu.
Kemudian, kita merancang filter pemrosesan gambar agar sesuai dengan kriteria ini. Misalnya, fitur edge detection untuk mengidentifikasi bentuk paruh burung dan mencocokkan fitur morfologi untuk melihat apakah hewan tersebut cocok dengan bentuk yang kita harapkan. Beberapa teknik pemrosesan gambar lain juga dibutuhkan dalam proses ini. Selanjutnya, berdasarkan beberapa kriteria, kita akan mendapatkan skor untuk menilai apakah gambar tersebut adalah seekor burung.
Sebuah proses yang panjang, bukan? Kita juga melakukan hal yang sama saat merancang dan menerapkan serangkaian aturan berbeda untuk hewan-hewan lainnya. Bayangkan usaha yang harus dilakukan untuk dapat menyelesaikan satu tugas klasifikasi. Tentunya sangat menantang, ‘kan?
Dengan mempelajari konsep deep learning ini akan mempermudah Anda untuk membangun sebuah sistem berbasis AI. Agar lebih paham terkait pengembangannya, mari kita simak contoh penerapan deep learning yang akan dibahas di bawah ini, mulai dari pengolahan citra, text, hingga audio.
Pengolahan Citra/Custom Vision
Mari kita awali dengan sebuah cerita. Bayangkan Anda sedang duduk di tepi pantai, menikmati senja dan mengamati segala hal yang terjadi di lingkungan sekitar. Di hadapan Anda, laut membentang, ombak berkejaran, sekelompok camar terbang rendah, sesekali mematuk ikan kecil yang muncul ke permukaan. Jauh di ufuk sana, matahari perlahan tenggelam, meninggalkan rona merah keemasan.
Saat Anda berada di sana dan menyaksikan itu semua, sesungguhnya ada dua sistem dalam tubuh yang sedang bekerja, yaitu mata dan sistem kognitif dalam tubuh. Mata berfungsi sebagai sensor yang menciptakan representasi pemandangan, sedangkan sistem kognitif yang akan memahami apa yang dilihat oleh mata.

Mata manusia dapat melihat pemandangan di sekelilingnya sekaligus mampu melakukan penyesuaian secara dinamis. Saat fokus pada daerah dengan tingkat kecerahan yang bervariasi, mata bisa mengimbangi. Selain itu, mata mampu mencakup sudut pandang yang lebih luas dan fokus pada objek dengan berbagai jarak secara bergantian. Kemampuan mata kita luar biasa, bukan?
Kemudian sistem kognitif memproses semua informasi yang dilihat oleh mata dan merepresentasikan ke dalam berbagai bentuk, warna, kecerahan, detil, dan keindahan. Inilah yang disebut sebagai “vision” atau sistem penglihatan manusia. Kemampuan penglihatan manusia (human vision capabilities) ini kemudian ditiru oleh komputer atau mesin sehingga lahirlah bidang computer vision.
Bagaimana caranya semua itu bisa dilakukan? Computer vision bekerja dengan membangun metode untuk pembentukan gambar (meniru sistem sensorik manusia) dan persepsi mesin (meniru sistem kognitif manusia). Sistem sensorik manusia ditiru dengan melibatkan sistem sensor, seperti kamera, pengaturan desain, dan penempatannya; sedangkan pendekatan modern untuk meniru sistem kognitif manusia terdiri dari metode machine learning yang digunakan untuk mengekstrak informasi dari gambar,
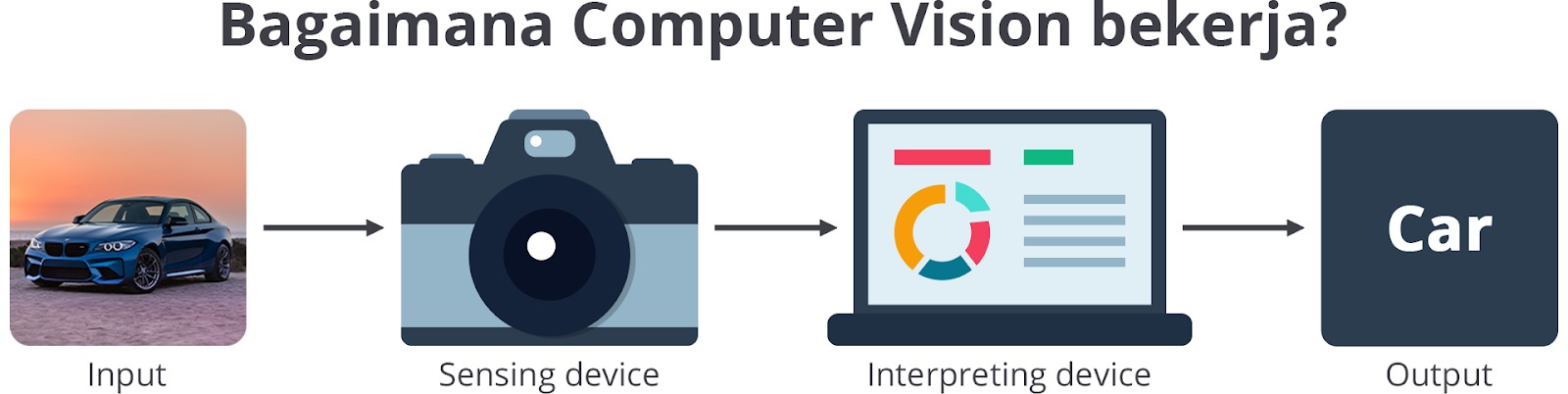
Jadi, computer vision merupakan bidang yang memungkinkan komputer atau sistem memperoleh informasi dari gambar digital, video, dan input visual lainnya. Bagi manusia dengan sistem penglihatan yang normal, tentu mudah untuk dapat langsung menginterpretasikan objek yang dilihatnya. Sayangnya, hal tersebut akan sulit dilakukan oleh mesin. Mesin membutuhkan sistem pemrosesan paralel yang mumpuni untuk memproses data dalam jumlah besar dan sistem kontrol yang kompleks untuk menyelesaikan permasalahan. Hal ini menjadikan computer vision sebagai salah satu bidang yang rumit sekaligus menantang.
Jika Anda mempelajari computer vision satu dekade ke belakang, metode yang digunakan untuk mengekstrak informasi dari objek digital tidaklah melibatkan machine learning. Pada masa itu, beberapa metode yang digunakan antara lain tentang denoising, edge detection, texture detection, dan morphological operation (shape-based). Kemajuan di bidang AI dan machine learning telah mengubah cara ini. Sebagai contoh, klasifikasi gambar sekarang bisa diselesaikan dengan pendekatan deep learning, yaitu teknik Convolutional Neural Network.
Pendekatan deep learning mengajarkan komputer untuk mengenali suatu objek dalam gambar dengan memberikan banyak data gambar beserta labelnya (solusi yang benar). Misalnya, pada permasalahan klasifikasi hewan, kita akan menunjukkan kepada komputer banyak gambar hewan seperti burung, kelinci, kucing, dan sebagainya. Dengan data pelatihan seperti itu, komputer belajar cara mengklasifikasikan gambar yang belum pernah ditemui sebelumnya.
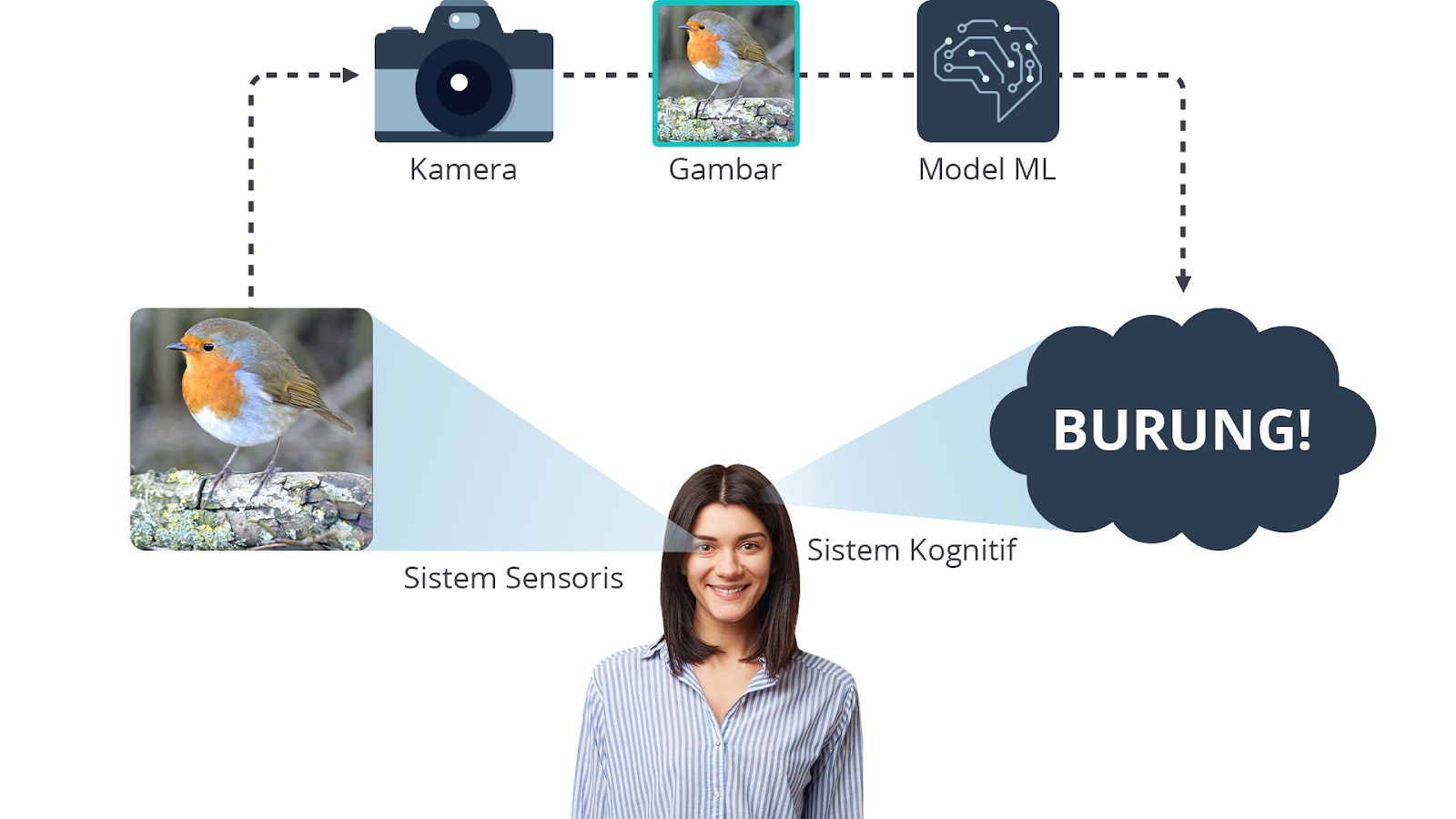
Dengan cara di atas, proses pengenalan dan klasifikasi gambar tentu jadi lebih mudah dan cepat.
Anda mungkin bertanya-tanya, apa contoh penerapan computer vision di industri saat ini? Contohnya ada banyak sekali, tetapi pada modul ini kita akan membahas salah satu contoh penerapannya di bidang kesehatan.
Kemajuan computer vision di bidang kesehatan memungkinkan para tenaga medis menggunakan data citra medis (medical imaging data) untuk membantu memberikan diagnosis, pengobatan, dan prediksi penyakit. Dengan computer vision, tenaga medis dapat menafsirkan citra sinar-X, CT scan, MRI, dan citra mikroskopis secara lebih akurat. Meskipun computer vision tidak akan sepenuhnya menggantikan tenaga kesehatan, ia cukup berperan dalam melengkapi diagnosis untuk pasien.
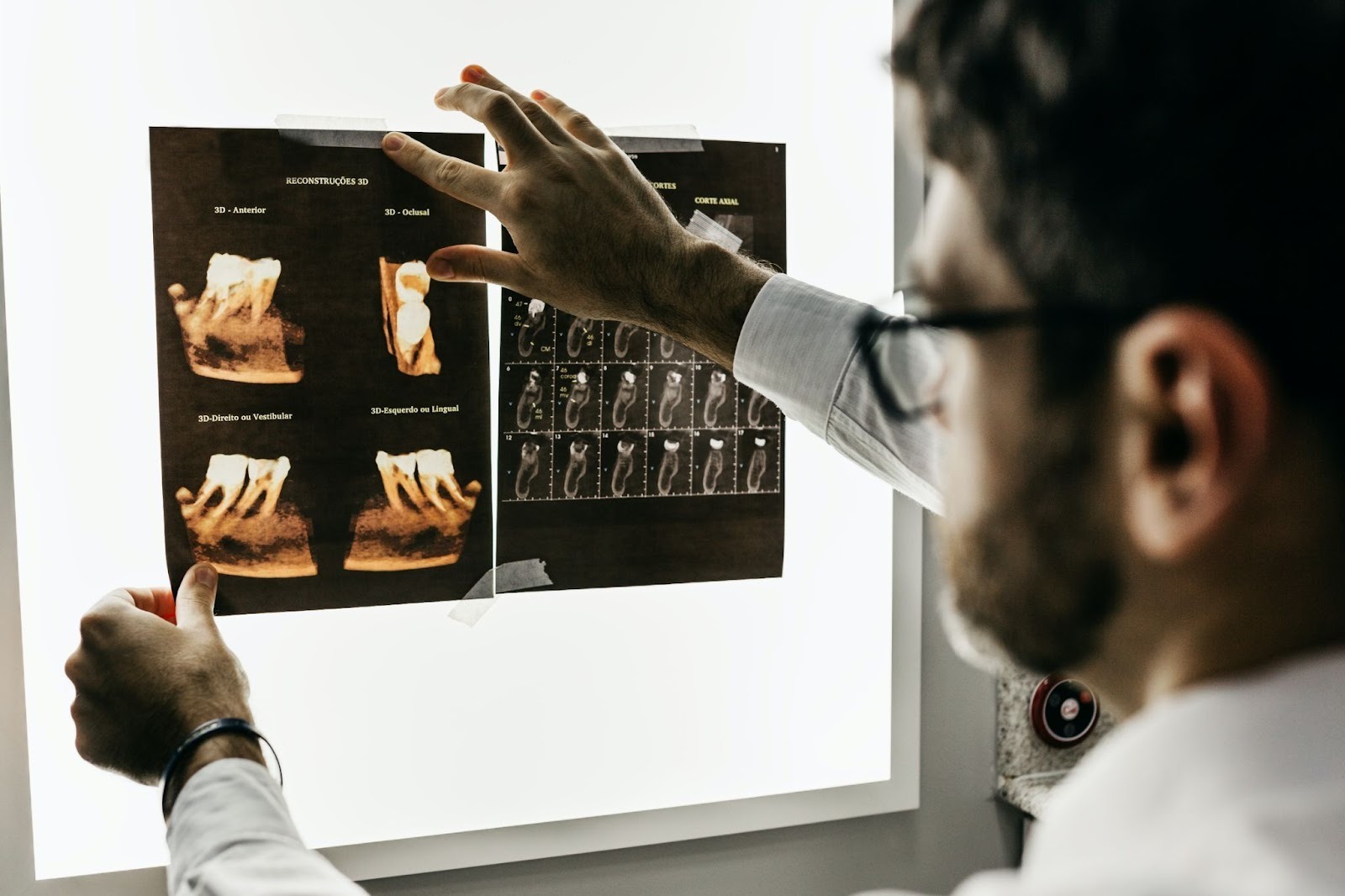
Penerapan computer vision dalam pencitraan medis juga menghasilkan solusi untuk memprediksi dan menganalisis gejala gangguan pada gigi, neurologis dan neuropathy, memantau kehilangan darah untuk mengoptimalkan transfusi, mendeteksi COVID-19, dan lain sebagainya. COVID-Net dengan teknik deep neural network menunjukkan akurasi 90% dalam mendiagnosis COVID-19 berdasarkan gambar rontgen dada.
Selain itu, sebuah perusahaan bernama Gauss Surgical memproduksi alat untuk memonitor darah secara real-time. Monitor dilengkapi dengan aplikasi sederhana dengan teknik computer vision berbasis cloud. Alat ini bertujuan untuk memprediksi banyaknya darah yang hilang selama operasi, memaksimalkan proses transfusi darah, dan mendeteksi potensi pendarahan secara lebih akurat. Teknologi ini diperkirakan dapat menghemat sekitar 10 miliar dollar setiap tahunnya.
Pengolahan Text
Bayangkan Anda terbangun di pagi hari. Dengan mata masih setengah terpejam, Anda mengaktifkan perangkat cerdas di sisi tempat tidur kemudian bertanya kepadanya.
Anda: “Jam berapa sekarang?”
Asisten digital: “Sekarang pukul enam pagi”
Tidak seperti biasanya, pagi ini Anda merasa sangat kedinginan. Kemudian, sambil menarik selimut, Anda bertanya lagi.
Anda : “Berapa suhu saat ini?”
Asisten digital : “Sekarang, suhu di Bandung 14 derajat celcius”
Dengan suhu sedingin ini, rasanya enggan untuk beranjak dari tempat tidur. Melanjutkan tidur sambil meringkuk di dalam selimut yang hangat sepertinya ide bagus. Namun, Anda kemudian ingat ada janji temu klien hari ini tapi entah jam berapa. Anda lantas bertanya lagi.
Anda: “Apa saja jadwalku hari ini?”
Asisten digital menjawab dengan membacakan seluruh jadwal pada kalender digital Anda hari itu, termasuk jadwal meeting dengan klien pada pukul 7 pagi. Artinya, Anda tidak bisa lanjut rebahan dan harus segera bangkit dari tempat tidur untuk bersiap.

Anda mungkin familier dan pernah menggunakan asisten digital. Bahkan, sebagian dari Anda mungkin telah lama menggunakannya dalam kehidupan sehari-hari. Tentu saja, bahasa yang Anda gunakan saat berkomunikasi dengan asisten digital bukanlah bahasa pemrograman formal seperti Python atau C, melainkan bahasa alami seperti yang Anda gunakan sehari-hari untuk berkomunikasi dengan sesama manusia.
Permasalahannya, komputer hanya dapat memproses data dalam biner. Lalu, bagaimana kita membuat mesin memahami bahasa alami tersebut? Di sinilah bidang Natural Language Processing (Pemrosesan Bahasa Alami) berperan. NLP merupakan subbidang dari Artificial Intelligence (AI) untuk memproses, menganalisis, memahami, dan menghasilkan bahasa manusia. NLP termasuk bidang keilmuan AI karena pemrosesan bahasa dianggap sebagai bagian dari kecerdasan manusia. Penggunaan bahasa merupakan keterampilan paling menonjol yang membedakan manusia dengan makhluk lainnya.
NLP mencakup berbagai algoritma, metode, dan pemecahan masalah yang menggunakan teks sebagai input. NLP menghasilkan beberapa informasi sebagai output, seperti label, representasi semantik, dan sebagainya. Teknik NLP digunakan di setiap aplikasi cerdas yang melibatkan bahasa alami. Ia merupakan komponen penting dalam berbagai aplikasi perangkat lunak yang kita gunakan dalam kehidupan sehari-hari.
Besarnya peluang pengembangan NLP ini berdampak pada semakin banyaknya perusahaan menerapkan NLP dalam produk maupun bisnisnya. Hal ini berpengaruh pada permintaan akan pakar atau tenaga ahli di bidang NLP. Tentu ini peluang bagus bagi Anda yang tertarik untuk mendalami NLP. Semangat!
Nah, berbicara tentang penerapan NLP, kita bisa menemukan penerapan NLP pada banyak bidang. Sebagai contoh, bidang e-commerce, pendidikan, keuangan, hiburan, perawatan kesehatan, layanan pelanggan, dan marketing.
Pada bidang marketing, salah satu aplikasi NLP yang telah dibahas di materi sebelumnya adalah analisis sentimen untuk social media monitoring. Selain yang telah disebutkan tadi, NLP memiliki peran signifikan pada berbagai produk dan layanan. Salah satu contoh penerapan yang paling populer pada aplikasi NLP adalah mesin pencari.
Siapa yang tidak mengenal mesin pencari? Tempat kita mencari dan bertanya mengenai berbagai hal di internet. Mesin pencari modern seperti Google dan Bing seolah telah menjadi bagian tak terpisahkan dalam kehidupan daring umat manusia. Nah, di balik kecanggihan mesin pencari, ada peran penting NLP dalam berbagai tahap pengembangannya.
Salah satu contohnya adalah pada tahap analisis kueri (query analysis). Analisis kueri mengidentifikasi intensi pengguna saat mengetikkan kata kunci pada mesin pencari kemudian memberikan informasi yang relevan. Misalnya, jika kita mengetik nama seorang tokoh terkenal pada mesin pencari, akan muncul berbagai informasi penting yang relevan dengan tokoh tersebut. Selain itu juga muncul beberapa berita mengenai tokoh tersebut.
Selain itu, mesin pencari juga memiliki fungsi koreksi dan rekomendasi kueri. Fungsi ini biasanya muncul saat kita mengetikkan ejaan yang salah dalam mesin pencari. Ketika hal tersebut terjadi, mesin menunjukkan koreksi dengan label seperti “menampilkan hasil untuk (ejaan yang dikoreksi)” atau “telusuri (ejaan salah yang kita ketik)”. Fungsi ini tentu memudahkan proses pencarian dan mengoptimalkan pengalaman pengguna.
Sampai di sini, Anda telah memahami beberapa contoh penerapan dari deep learning, mulai dari data yang berupa citra hingga proses pengolahan bahasa alami. Dengan uraian tersebut, diharapkan Anda dapat memahami cara kerja deep learning dan dapat memiliki ide untuk membuat deep learning berdasarkan permasalahan yang ada di sekitar.
Ekstensi Model
Setelah Anda membuat sebuah model machine learning, tentu perlu melakukan export model tersebut menjadi ekstensi tertentu agar dapat digunakan pada platform yang diinginkan. Permasalahan yang muncul saat ini adalah tidak ada ekstensi yang cocok dengan berbagai platform, katakanlah Anda ingin men-deploy model yang Anda buat di web atau mobile device. Anda perlu membuat model machine learning dengan bentuk atau ekstensi tertentu agar bisa di-consume oleh platform tersebut.
Untuk menyelesaikan tersebut teachable machine menyediakan beberapa ekstensi seperti TensorFlow.js dan TensorFlow Lite sebagai pilihan export model machine learning. Pertanyaannya, apa perbedaan dari masing-masing ekstensi yang disediakan oleh teachable machine? Bagaimana cara kita menentukan ekstensi yang cocok untuk proyek yang sedang dibangun?
TensorFlow.js
TensorFlow.js memungkinkan kita untuk membangun aplikasi machine learning pada Web Browser. Ia adalah sebuah framework yang kompatibel dengan TensorFlow API. TensorFlow.js menggunakan model yang telah dibuat dengan mengubah format model menjadi JSON file.
Pada level atas TensorFlow.js API, kita akan dihadapkan dengan Layers API. Jika familier dengan penggunaan layer-layer pada Keras, kita dapat lebih mudah untuk menggunakan Layers API.
Di bawah layers API, ada Core API yang menangani model dari TensorFlow. Core API juga mengimplementasikan operasi graf pada level lebih kompleks, seperti deklarasi tensor (data input), operasi pada tensor, memori, eksekusi fungsi, dan lain-lain.
Selain itu CORE API bekerja dengan browser dan menggunakan WebGL untuk menggunakan resource yang mendukung proses training atau pengambilan hasil prediksi (inference). Pada Node.js, kita bisa membuat aplikasi server-side dan menggunakan resource yang tersedia, seperti CPU, GPU, atau TPU.
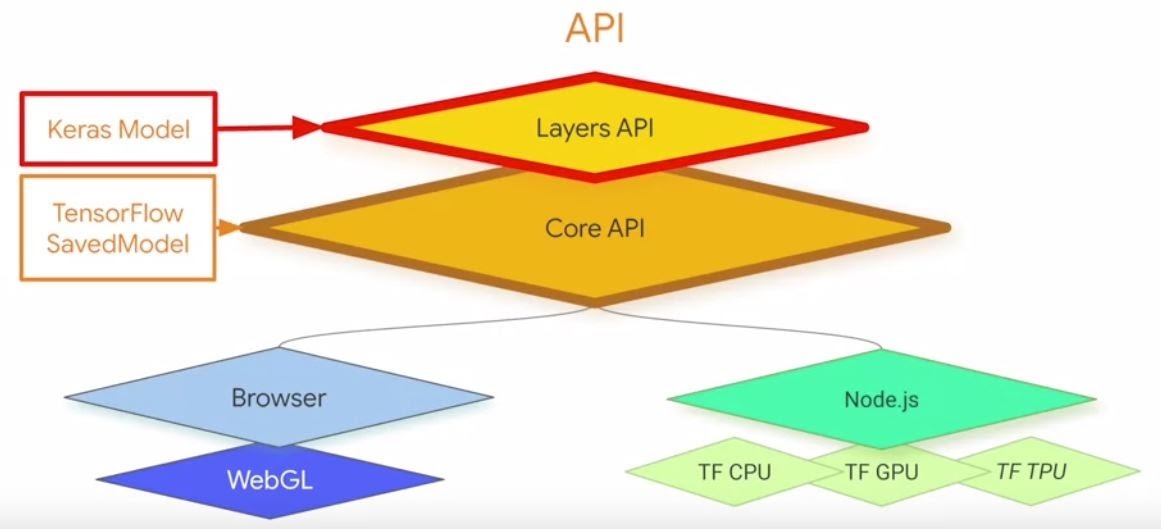
Terdapat beberapa keuntungan menggunakan TensorFlow.js seperti memudahkan kita dalam melakukan integrasi dengan teknologi web seperti user interface karena TensorFlow.js dapat ditulis dalam bahasa script. Selain itu, TensorFlow.js memudahkan kita pada beberapa utilitas yang dapat kita import seperti document object model (DOM) canvas yang memungkinkan kita mendapat data langsung dari input user di internet.
Jika ada kelebihan, pasti ada kekurangan. TensorFlow.js juga memiliki kekurangan, salah satunya yaitu penggunaan web browser sebagai platform machine learning menyebabkan permasalahan performa. Web browser biasanya merupakan aplikasi dengan single proses dan tidak bekerja intens dengan CPU. Namun, modern web browser sudah menyediakan API yang bisa memanfaatkan lokal hardware akselerator dengan menggunakan WebGL atau WebGPU. Dengan adanya API tersebut, TensorFlow.js dapat memberikan performa yang sama baiknya walaupun menggunakan browser.
Web browser merupakan platform yang cocok untuk men-deploy model dengan ekstensi TensorFlow.js. Selanjutnya, mari kita pelajari proses deployment model machine learning pada perangkat mobile dan IoT.
TensorFlow Lite
Sebelumnya Anda telah mempelajari proses deployment menggunakan TensorFlow.js yang cocok diimplementasikan pada web browser. Pada bagian ini, kita akan berkenalan dengan TensorFlow Lite. TensorFlow Lite (TF-Lite) merupakan sebuah framework yang dapat menjalankan model TensorFlow pada perangkat mobile dan IoT.
Machine learning pada perangkat mobile dapat memudahkan manusia dalam menyelesaikan tugas sehari-hari. Selain itu, implementasi model machine learning pada perangkat mobile menggunakan TF-Lite juga memiliki beberapa keuntungan seperti berikut.
- Penggunaan TF-Lite tidak memerlukan server sehingga perangkat tidak harus terhubung ke internet untuk melakukan prediksi dan mampu menjaga privasi pengguna.
- Memiliki Latency dan ukuran binary yang kecil sehingga dapat mengurangi konsumsi daya ketika melakukan prediksi.
Dengan adanya machine learning pada perangkat mobile, kita dapat melakukan beragam aktivitas dengan lebih mudah dan efisien. Agar semakin paham, mari kita bahas beberapa contoh penggunaan machine learning pada perangkat mobile.
- Traveloka OCR merupakan salah satu contoh penerapan machine learning yang dapat mengenali identitas seseorang berdasarkan foto KTPnya. Fitur ini dapat membantu kita dalam mengisi identitas pada platform Traveloka agar mempercepat proses pengisian data dan menghindari kesalahan manusia pada proses pengisian secara manual.
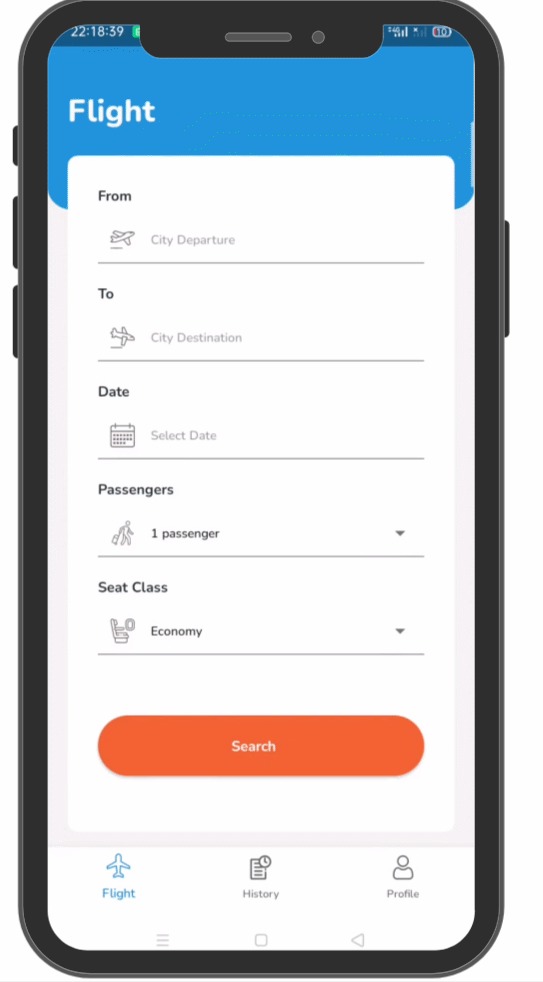
- Google Translate Instant Camera Translation yang dapat menerjemahkan teks bahasa asing dengan foto. Fitur ini dapat membantu turis mancanegara dalam memahami bahasa asing ketika berlibur tanpa bantuan penerjemah sehingga mereka tidak perlu khawatir ketika berlibur ke negara asing.

Sebelum menjalankan model TensorFlow pada perangkat mobile, kita perlu memahami arsitektur TF-Lite terlebih dahulu. Berikut merupakan ilustrasi sederhana arsitektur TF-Lite.
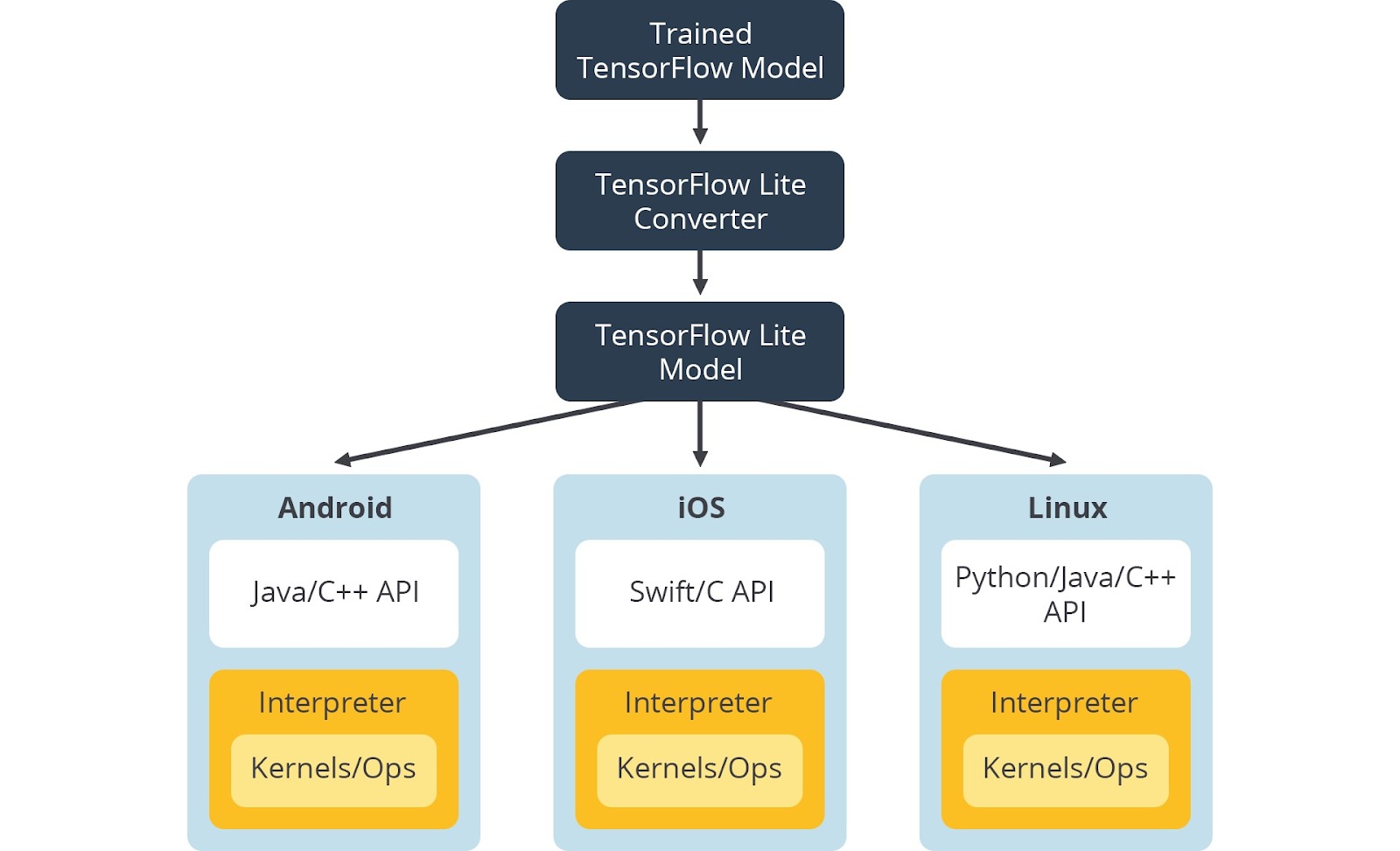
Setelah melatih model menggunakan teachable machine, Anda bisa memilih export model dengan pilihan “TensorFlow Lite”. Sekadar informasi, TF-Lite juga dilengkapi dengan API untuk berbagai macam bahasa pemrograman, seperti C, C++, Swift, Java, dan Python. Menarik, ‘kan?
Proses di Balik Deep Learning
Pembelajaran yang Dilakukan Komputer
Di balik proses pembelajaran yang dilakukan oleh komputer terdapat banyak sekali perhitungan matematis yang terjadi. Mari kita bahas satu per satu mulai dari input layer, hidden layer, hingga output layer.
Kita akan menggunakan studi kasus klasifikasi gambar fashion menggunakan MNIST dataset untuk mempelajari cara kerja dari setiap layer. Dataset tersebut memiliki 10 buah kelas yang terdiri dari baju, sepatu, tas, dan sebagainya.

Jika tidak menggunakan teachable machine, kita harus menggunakan TensorFlow untuk membuat model machine learning tersebut. Kita dapat menggunakan Keras dengan kode sebagai berikut.
- mnist = tf.keras.datasets.fashion_mnist
- (x_train, y_train),(x_test, y_test) = mnist.load_data()
- X_train, x_test = x_train / 255.0, x_test / 255.0
- model = tf.keras.models.Sequential([
- tf.keras.layers.Flatten(input_shape=(28, 28)),
- tf.keras.layers.Dense(512, activation=tf.nn.relu),
- tf.keras.layers.Dense(10, activation=tf.nn.softmax)
- ])
- model.compile(optimizer=tf.optimizers.Adam()),
- loss=’sparse_categorical_crossentropy’,
- metrics=[‘accuracy’])
- model.fit(x_train, y_train, epochs=10)
Mari kita bahas kode di atas satu per satu. Hal yang paling pertama adalah kita perlu mempersiapkan data kemudian membaginya menjadi data latih dan data uji. Data fashion MNIST bisa kita dapatkan dengan mudah dari library datasets yang disediakan Keras.
- Mnist = tf.keras.datasets.fashion_mnist
- (x_train, y_train),(x_test, y_test) = mnist.load_data()
- X_train, x_test = x_train / 255.0, x_test / 255.0
Dalam klasifikasi gambar, setiap piksel pada gambar memiliki nilai dari 0 sampai 255. Kita perlu melakukan normalisasi dengan membagi setiap pixel pada gambar dengan 255. Dengan nilai yang telah dinormalisasi, jaringan saraf dapat belajar dengan lebih baik.
- X_train, x_test = x_train / 255.0, x_test / 255.0
Pada langkah berikutnya, kita mendefinisikan arsitektur dari jaringan saraf yang akan kita latih.
- model = tf.keras.models.Sequential([
- tf.keras.layers.Flatten(input_shape=(28, 28)),
- tf.keras.layers.Dense(512, activation=tf.nn.relu),
- tf.keras.layers.Dense(10, activation=tf.nn.softmax)
- ])
Seperti yang Anda lihat pada kode di atas, ketiga layer tersebut terdiri dari input layer, hidden layer, dan output layer. Apa arti dari masing-masing layer tersebut? Mari kita bedah semuanya agar Anda dapat lebih memahami proses pembelajaran yang terjadi pada machine learning.
Untuk membuat sebuah model di Keras, kita bisa memanggil fungsi tf.keras.models.Sequential([...]) dan menampungnya pada sebuah variabel. Model sequential pada Keras adalah tumpukan layer-layer yang melakukan proses perhitungan sehingga mendapatkan output yang sesuai dengan tugasnya.
Berikut definisi dari 3 layer utama pada model sequential.
- Input layer
Layer yang memiliki parameter ‘input_shape’. Input_shape sendiri adalah resolusi dari gambar-gambar pada data latih. Dalam hal ini sebuah gambar MNIST memiliki resolusi 28x28 pixel sehingga input shape-nya adalah (28, 28). Sebuah layer Flatten pada Keras akan berfungsi untuk meratakan input. Meratakan di sini artinya mengubah gambar yang merupakan matriks 2 dimensi menjadi array 1 dimensi. Pada kasus kita sebuah gambar MNIST yang merupakan matriks 28x 28 elemen akan diubah menjadi larik/array satu dimensi sebesar 784 elemen. - Hidden layer
Dense layer pada Keras merupakan layer yang dapat dipakai sebagai hidden layer dan output layer pada sebuah MLP. Parameter unit merupakan jumlah perceptron pada sebuah layer. Kita dapat menggunakan fungsi aktivasi relu (rectified linear unit) atau fungsi aktivasi lain untuk hidden layer kita. - Output layer
Ia didefinisikan dengan membuat sebuah Dense layer. Jumlah unit menyesuaikan dengan jumlah label pada dataset. Untuk fungsi aktivasi pada layer output, gunakan fungsi aktivasi Sigmoid ketika hanya terdapat 2 kelas/label pada dataset. Untuk dataset yang memiliki 3 kelas atau lebih, gunakan fungsi aktivasi Softmax. Fungsi aktivasi softmax akan memilih kelas mana yang memiliki probabilitas tertinggi. Untuk data fashion MNIST kita akan menggunakan fungsi aktivasi softmax karena terdapat 10 kelas.
Agar Anda lebih memahami proses terjadinya pembelajaran machine learning, perhatikan gambar di bawah ini.
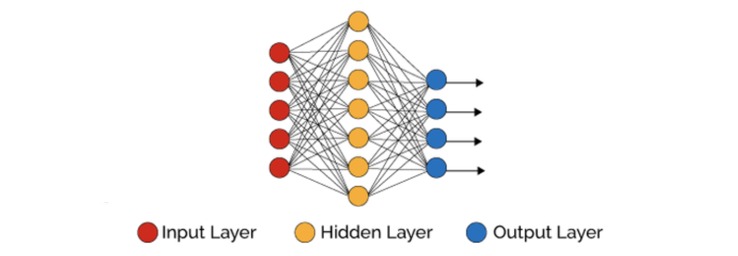
Gambar di atas menunjukkan jumlah layer yang direpresentasikan oleh neuron. Jika kalian ingat, proses pembelajaran di atas sama halnya dengan perceptron yang telah kita bahas pada modul ini. Setiap neuron yang terhubung mewakili perhitungan dari sebuah perceptron. Proses pembelajaran ini terdiri dari 5 komponen, yaitu bobot atau weights (Wi) dan bias (W0), penjumlahan atau sum (∑), fungsi aktivasi atau non linearity function (⎰), dan output (y).
Fungsi matematis dari proses pembelajaran ini dapat kita lihat di bawah ini.
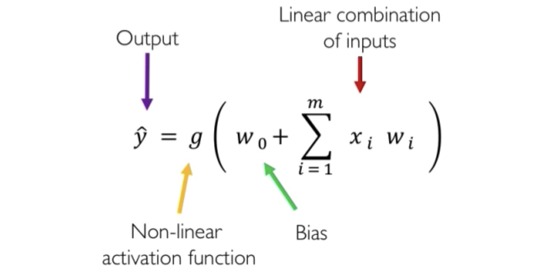
Rumus tersebut merupakan notasi matematis yang menjelaskan proses yang kita bahas sebelumnya. Berikut merupakan keterangan dari rumus di atas:
- ŷ = output/keluaran
- w0 = bias
- w1 = weight/bobot
- x1 = input
- g = fungsi aktivasi
Sehingga dari rumus di atas dapat disimpulkan bahwa output/keluaran (ŷ) merupakan hasil perhitungan dari bias (w0) ditambah dengan total dari input (x1) dikalikan dengan bobot (w1). Kemudian, nilai akhir dari perhitungan tersebut dikalikan dengan fungsi aktivasi (g) sehingga mendapatkan sebuah nilai output/keluaran
Fungsi aktivasi (g) pada perceptron bertugas untuk membuat jaringan saraf mampu menyesuaikan pola pada data non linier. Seperti yang sudah pernah dibahas sebelumnya, mayoritas data yang terdapat di dunia nyata adalah data non linier seperti di bawah ini.
Tanpa fungsi aktivasi, jaringan saraf hanya bisa mengenali pola linier seperti garis pada regresi linier. Hasilnya bisa Anda lihat melalui gambar berikut.
Fungsi aktivasi (g) itulah yang memungkinkan jaringan saraf dapat mengenali pola non-linier tanpa memperhatikan kompleksitas atau sebaran data yang ada. Sehingga dengan penggunaan fungsi aktivasi (g) menghasilkan batasan sebaran data sebagai berikut.
Setelah membuat arsitektur machine learning, model kita belum bisa melakukan apa pun. Agar model bisa belajar, kita perlu memanggil fungsi compile pada model dan menspesifikasikan optimizer dan loss function. Dua hal ini memiliki peran yang sangat penting ketika kita membangun model machine learning. Loss function berfungsi untuk menghitung perbedaan antara output prediksi dengan output sesungguhnya, sedangkan optimizer berfungsi untuk menyesuaikan nilai parameter sehingga dapat meminimalisir kesalahan pada saat pembelajaran dilakukan.
Salah satu optimizer yang biasa digunakan adalah Adam. Selanjutnya untuk loss function kita dapat menggunakan sparse categorical entropy pada kasus klasifikasi 3 kelas atau lebih. Untuk masalah 2 kelas, loss function yang lebih tepat adalah binary cross entropy. Parameter metrics berfungsi untuk menampilkan metrik yang dipilih pada proses pelatihan model.
- model.compile(optimizer=tf.optimizers.Adam()),
- loss=’sparse_categorical_crossentropy’,
- metrics=[‘accuracy’])
Setelah membuat arsitektur MLP dan menentukan optimizer serta loss functionnya, kita dapat melatih model kita pada data training. Parameter epoch merupakan jumlah berapa kali sebuah model melakukan propagasi balik.
- model.fit(x_train, y_train, epochs=10)
Begitulah cara kita membuat sebuah model deep learning dengan tanpa bantuan teachable machine. Tentu sangat menyenangkan, bukan? Namun, Anda tidak perlu risau melihat proses pembuatan machine learning tersebut karena sejatinya tugas tersebut akan dikelola oleh machine learning engineer.
Perangkat Keras yang Digunakan
Anda telah mempelajari banyak hal terkait pembangunan AI hingga deep learning, tetapi tahukah Anda bagaimana model yang kita buat dapat melakukan tugasnya seperti mengklasifikasikan kelompok umur, atau memprediksi sebuah gambar? Komputer memerlukan perangkat keras untuk menjalankan model machine learning karena tugas-tugas yang dilakukan olehnya seringkali melakukan komputasi yang berat dan memerlukan operasi matematika yang intensif.
Ada beberapa perangkat keras yang dapat mendukung komputer untuk menjalankan model machine learning beberapa contohnya seperti Central Processing Unit (CPU), Graphical Processing Unit (GPU), dan Tensor Processing Unit (TPU).

Mari kita bahas apa perbedaannya dan kelebihan dari masing-masing perangkat keras tersebut. Materi ini dibuat agar Anda dapat menentukan perangkat keras yang cocok untuk menjalankan model machine learning yang telah dibuat sebelumnya.
Saat kami menyebutkan beberapa contoh perangkat keras yang dapat membantu menjalankan model machine learning, mungkin Anda akan bertanya “bagaimana cara menentukan perangkat keras yang cocok untuk model yang telah dibuat?” Pertanyaan yang bagus!
Sebetulnya, jika menjalankan machine learning pada komputer lokal dan memiliki perangkat keras yang mendukung, Anda tidak perlu memikirkan hal ini karena GPU akan secara otomatis melakukan segala komputasinya. Namun, permasalahan muncul ketika Anda akan menjalankan model machine learning pada mesin yang terbatas atau ketika Anda akan menyimpan model pada sebuah layanan cloud computing.
Mengapa ketika kita menyimpan model machine learning pada layanan cloud computing harus memperhatikan perangkat keras yang digunakan? Hal ini disebabkan mayoritas layanan tersebut memiliki batasan spesifikasi sehingga mempengaruhi biaya yang kita keluarkan untuk menjalankan model machine learning.
Mari kita kembali ke pertanyaan utama kita, “Bagaimana cara menentukan perangkat keras yang cocok untuk model yang telah dibuat?” Jika Anda membuat machine learning yang memerlukan pelatihan model yang sangat intensif secara komputasi seperti pelatihan jaringan saraf tiruan yang besar, GPU atau TPU bisa menjadi pilihan yang lebih baik daripada CPU. Namun, ketika Anda memiliki model machine learning yang lebih sederhana tanpa melibatkan jaringan saraf seperti klasifikasi menggunakan decision tree, k-means clustering, dan lain sebagainya, Anda dapat menggunakan CPU.
Sampai di sini, bagaimana menurut Anda mengenai pembangunan machine learning ini? Proses pengembangan machine learning tidak sebatas membuat model saja karena kita harus mempelajari hingga model tersebut dapat mengerjakan tugasnya. Berita baiknya, Anda sudah mempelajari semua itu, sekaligus mengetahui perangkat keras yang dapat digunakan.
Bersambung ke:
- Get link
- X
- Other Apps



Comments
Post a Comment