Pengantar Supervised Learning - Regresi
- Get link
- X
- Other Apps
Pengantar Supervised Learning - Regresi
Hi, machine learning enthusiast!
Wah, kita bertemu lagi di Modul 4! Bagaimana perasaan Anda setelah menaklukkan Modul 3 tentang Supervised Learning - klasifikasi? Sudah siap untuk tantangan berikutnya, ‘kan?
Semoga Anda tidak kehilangan semangat karena perjalanan kita masih panjang dan yang pasti makin seru! Jika pada modul sebelumnya fokus pada klasifikasi, sekarang Anda akan melanjutkan dengan topik yang tak kalah menarik yaitu regresi.
Mungkin istilah ini sudah tidak asing lagi bagi Anda, tetapi kali ini kita akan mengupasnya lebih dalam, mulai dari konsep dasarnya hingga berbagai teknik yang digunakan dalam regresi.
Sebelum kita mulai, ada pantun nih buat menghangatkan suasana.
Jalan-jalan ke pasar senja,
Beli kerupuk sambil berjalan.
Yuk, kita belajar bersama,
Supaya pintar dan tidak ketinggalan jaman!
Dalam modul ini, kita akan menggali lebih dalam tentang regresi, salah satu teknik keren dalam supervised learning yang memungkinkan kita memprediksi nilai kontinu berdasarkan berbagai parameter. Jika klasifikasi itu ibarat kita mengelompokkan orang-orang berdasarkan warna baju, regresi ini seperti memprediksi umur berdasarkan karakteristik pengunjung. Seru, ‘kan?
Jadi, siapkan camilan favorit Anda, santai sejenak, dan mari kita pelajari cara kerja regresi, serta bagaimana penerapannya dalam berbagai kasus nyata. Ingat, sambil belajar, jangan lupa untuk tetap enjoy dan sesekali tersenyum. Kan, katanya, senyum itu ibadah.
Keep the spirit high and enjoy the journey!
[Story] Semakin Tahu, Semakin Merasa Bodoh
Pada cerita sebelumnya, Diana dan Bilqis telah berhasil membuat sebuah model klasifikasi yang dapat memprediksi seorang pelanggan akan pergi atau tetap bertahan dengan layanan di perusahaan XYZ. Sampai di titik ini, mereka merasa dapat menyelesaikan semua permasalahan supervised learning dengan sangat mudah. Hingga akhirnya mereka kembali ke co-working space favoritnya dan bersantai sejenak.

Suasana begitu menyenangkan ketika mereka berdua berhasil menguasai ilmu baru. Seperti remaja pada umumnya, mereka menghabiskan waktu untuk healing setelah mencapai sebuah achievement. Diana pada saat itu asyik menonton drakor favoritnya, sedangkan Bilqis menamatkan TikTok di gawai pribadinya.
Namun, semua berubah ketika Bilqis tidak sengaja melihat sebuah berita pada televisi di coworking space itu tentang bencana banjir yang melanda beberapa kota di Indonesia dengan volume air yang cukup besar.

Diana merasa iba terhadap masyarakat yang terdampak, tetapi pada saat itu, ia tidak bisa melakukan apa pun selain berdoa. Namun, rasa iba itu memunculkan sebuah keinginan agar Diana dapat membantu masyarakat walaupun dengan hal kecil.

Berbekal pengetahuan mengenai supervised learning dan klasifikasi yang ia miliki, akhirnya Diana berpikir seharusnya ia juga dapat memprediksi volume banjir karena memiliki karakteristik yang sama dengan klasifikasi. Diana menyadari betul bahwa banjir yang terjadi dapat disebabkan oleh beberapa faktor sehingga menimbulkan volume air yang cukup besar. Namun, setelah berpikir cukup lama, Diana menyadari bahwa prediksi yang ia hasilkan bukanlah sebuah kelompok melainkan angka atau nilai kontinu.

Momen tersebut mengubah keadaan Diana dan Bilqis yang tadinya sudah merasa “menguasai” machine learning menjadi terbalik, sehingga mereka merasa ilmunya masih di permukaan dan tidak ada apa-apanya. Diana juga menyadari bahwa dengan menguasai suatu materi bukanlah akhir perjalanan, melainkan awal dari pembelajaran yang tidak ada ujungnya.

Berawal dari berita yang tidak disengaja, akhirnya mereka memutuskan untuk menghentikan sesi berleha-leha yang sedari tadi dilakukan. Tanpa berlama-lama, Bilqis mulai mencari informasi terkait ide Diana yang ingin memprediksi nilai kontinu.
Diana menyadari satu hal, ternyata supervised learning yang ia pelajari sebelumnya bersama Bilqis memiliki dua cabang, yaitu klasifikasi dan regresi. Setelah menyelesaikan quest klasifikasi, akhirnya mereka memulai perjalanan untuk menuntaskan pembelajaran mengenai supervised learning.
Hai, calon engineer masa depan! Perjalanan Diana dan Bilqis sudah memasuki tahapan baru, tentunya Anda juga tidak ingin ketinggalan, ‘kan? Oleh karena itu, mari kita simak bersama-sama perjalanan mereka dalam mempelajari kasus regresi pada modul ini. Kencangkan sabuk pengaman karena kereta cepat angkat segera berangkat, Let’s goooo~
Pendahuluan Regresi dalam Konteks Machine Learning
Sebelumnya, Anda sudah sedikit mengenal konsep ini dari modul Machine Learning Workflow, tetapi sekarang kita akan memperdalam pemahaman tentang regresi secara lebih detail.
Regresi adalah salah satu teknik dalam machine learning yang memiliki kesamaan dengan klasifikasi. Namun, perbedaan utama antara keduanya terletak pada hasil prediksinya. Pada klasifikasi, model machine learning bertugas untuk memprediksi sebuah kelas atau kategori. Misalnya, apakah suatu email adalah spam atau bukan.
Sebaliknya, pada regresi model akan memprediksi sebuah nilai numerik yang bersifat kontinu, seperti memprediksi harga rumah berdasarkan berbagai faktor seperti luas tanah, jumlah kamar, dan lokasi.
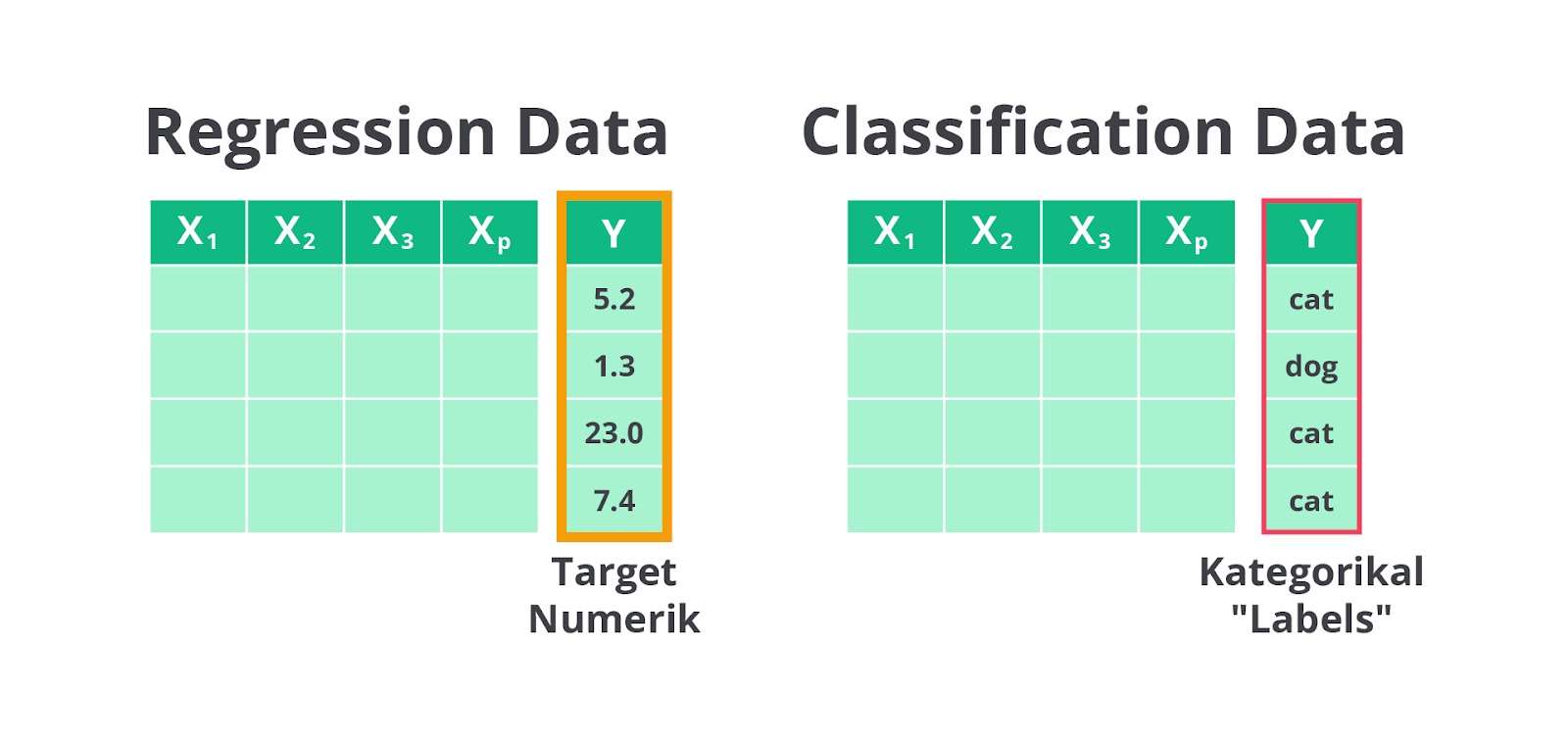
Bilangan kontinu yang diprediksi oleh model regresi adalah bilangan numerik yang tidak terbatas pada nilai-nilai diskrit. Sebagai contoh, dalam klasifikasi Anda mungkin memprediksi apakah seseorang lulus atau tidak lulus ujian (dua kelas atau kategori), sedangkan dalam regresi, Anda memprediksi nilai ujian seseorang dalam bentuk angka, misalnya 85,3.
Dengan kata lain, model klasifikasi berfungsi untuk memprediksi kelas atau kategori tertentu, sedangkan model regresi berfungsi untuk memprediksi suatu nilai berdasarkan atribut-atribut yang tersedia.
Untuk memperjelas, mari kita lihat contoh berikut.
| Lama Bekerja | Industri | Tingkat Pendidikan | Gaji |
|---|---|---|---|
6 tahun | Marketing | SMA | 8.000.000 |
12 tahun | IT | S1 | 16.000.000 |
8 tahun | Kesehatan | S2 | 20.000.000 |
5 tahun | IT | SMK | ? |
6 tahun | Marketing | S2 | 14.000.000 |
21 tahun | Perbankan | S3 | 35.000.000 |
3 tahun | IT | S1 | 10.000.000 |
Pada contoh data di atas, model regresi digunakan untuk memprediksi besaran gaji seseorang berdasarkan beberapa atribut seperti lama bekerja, jenis industri tempat bekerja, dan tingkat pendidikan yang dimiliki. Gaji merupakan contoh dari bilangan kontinu, yang berarti nilai gaji tersebut dapat bervariasi tanpa dibatasi oleh kategori tertentu.
Sebagai contoh pada data di atas terdapat satu kolom berisikan “?”. Kolom tersebut bisa saja bernilai Rp8.000.000, Rp14.000.000, atau bahkan Rp35.000.000, sesuai dengan berbagai faktor yang memengaruhinya. Tidak ada batasan pada nilai-nilai ini, sehingga gaji tidak dikelompokkan ke dalam kategori-kategori yang tetap.
Eitss, walaupun terlihat berbeda, tetapi ada hal yang sangat mirip dari kedua tipe supervised learning ini yaitu proses pembuatannya.
Proses Regresi: Langkah Demi Langkah
Proses regresi melibatkan beberapa tahapan penting yang perlu dipahami agar model yang dihasilkan dapat memberikan prediksi yang akurat. Berikut adalah langkah-langkah dalam proses regresi.
- Pengumpulan Data
- Pra-pemprosesan Data
- Pembagian Data
- Pemilihan Algoritma Regresi
- Pelatihan Model
- Evaluasi Model
- Deployment
Mungkin terlihat sederhana, ya? Langkah-langkah di atas merupakan implementasi dari modul yang telah kita pelajari sebelumnya, yaitu Machine Learning Workflow. Jika pada modul tersebut kita membahas secara umum penggunaannya pada salah satu studi kasus, sekarang sudah waktunya kita menyelam lebih dalam dengan cara mengadaptasi workflow tersebut pada studi kasus regresi.
Pengumpulan Data
Langkah awal dalam membangun model regresi adalah mengumpulkan data yang akan digunakan untuk melatih dan menguji model tersebut. Data ini harus relevan dengan permasalahan yang ingin dipecahkan. Selain itu, kualitas data harus bagus, yang berarti data harus lengkap, tepat, dan menggambarkan kondisi sebenarnya dari populasi yang lebih luas.
Bayangkan kita sedang membangun model regresi untuk memprediksi gaji seseorang. Data yang kita kumpulkan bisa mencakup berbagai informasi penting, seperti lama bekerja, jenis industri tempat mereka bekerja, dan tingkat pendidikan.
| Lama Bekerja (tahun) | Industri | Tingkat Pendidikan | Gaji (Rp) |
|---|---|---|---|
5 | Teknologi | S1 | 15.000.000 |
2 | Manufaktur | S2 | 12.000.000 |
10 | Keuangan | S1 | 20.000.000 |
3 | Teknologi | D3 | 10.000.000 |
8 | Kesehatan | S2 | 18.000.000 |
Setiap elemen data ini akan memainkan peran krusial dalam menentukan seberapa akurat prediksi gaji yang dihasilkan oleh model kita. Misalnya, jika kita hanya mengumpulkan data dari satu sektor industri atau hanya untuk individu dengan tingkat pendidikan tertentu, prediksi kita mungkin tidak mencerminkan gaji yang lebih beragam di seluruh industri dan tingkat pendidikan lainnya.
Pra-Pemrosesan Data
Data yang sudah dikumpulkan biasanya masih kotor dan belum siap untuk digunakan oleh model. Pra-pemrosesan data adalah proses untuk memastikan bahwa data tersebut dalam kondisi yang optimal untuk digunakan. Tahap ini bisa melibatkan pembersihan data dari nilai-nilai yang hilang, penghapusan duplikasi, serta penyesuaian format data agar sesuai dengan kebutuhan algoritma yang akan digunakan. Normalisasi atau standardisasi data juga sering dilakukan pada tahap ini.
Dalam contoh prediksi gaji karyawan, jika ada data yang hilang atau tidak lengkap, kita perlu menangani masalah tersebut. Misalnya, jika data tentang lama bekerja hilang untuk satu karyawan, kita bisa menggunakan rata-rata dari data yang ada untuk mengisinya. Setelah itu, misalnya kita juga ingin mengonversi kategori seperti "Industri" dan "Tingkat Pendidikan" menjadi kode numerik agar lebih mudah diproses oleh model.
Catatan:
Teknologi = 1, Manufaktur = 2, Keuangan = 3, dan Kesehatan = 4.
D3 = 2, S1 = 3, S2 = 4
Lama Bekerja (tahun) | Industri (kode) | Tingkat Pendidikan (kode) | Gaji (Rp) |
|---|---|---|---|
5 | 1 | 3 | 15.000.000 |
2 | 2 | 4 | 12.000.000 |
10 | 3 | 3 | 20.000.000 |
3 | 1 | 2 | 10.000.000 |
8 | 4 | 4 | 18.000.000 |
Pembagian Data
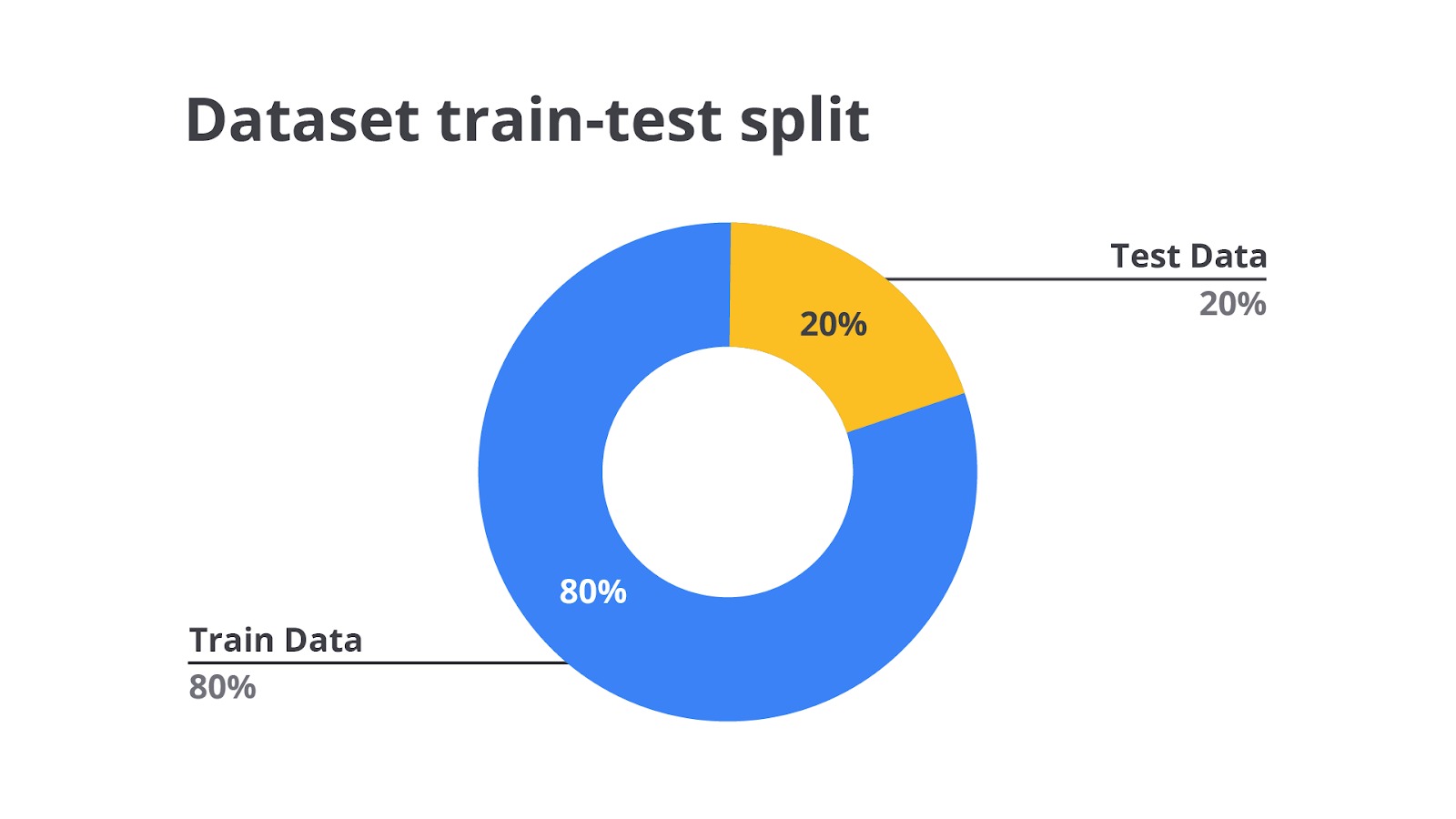
Setelah data diproses, langkah berikutnya adalah membaginya menjadi dua set, yaitu data pelatihan dan data pengujian (bisa juga tiga set dengan data evaluasi). Data pelatihan digunakan untuk membangun model, sedangkan data pengujian digunakan untuk mengevaluasi keakuratan model. Biasanya, sekitar 70-80% data dialokasikan untuk pelatihan, dan sisanya untuk pengujian. Namun, dalam kasus tertentu seperti dataset yang sangat besar pembagian ini perlu disesuaikan dengan kemampuan dan kebutuhan perusahaan.
Misalnya, dari 100 data karyawan, Anda dapat membagi 80 data untuk pelatihan dan 20 data untuk pengujian. Ini membantu memastikan bahwa model yang Anda bangun dapat memberikan prediksi yang akurat tidak hanya untuk data yang sudah dikenal, tetapi juga untuk data baru yang belum pernah dilihat oleh model.
Pemilihan Algoritma Regresi
Pemilihan algoritma regresi adalah langkah krusial dalam membangun model prediksi yang akurat. Algoritma yang tepat tidak hanya akan memberikan hasil yang baik pada data pelatihan, tetapi juga mampu melakukan generalisasi dengan baik pada data yang belum pernah dilihat sebelumnya. Memilih algoritma regresi yang tepat adalah proses yang melibatkan analisis mendalam terhadap karakteristik data yang Anda miliki serta tujuan prediksi yang ingin dicapai.
Berikut adalah langkah-langkah dan pertimbangan penting yang perlu Anda lakukan dalam pemilihan algoritma regresi tanpa langsung membahas jenis-jenis algoritmanya.
- Pahami Hubungan antara Variabel
Langkah pertama dalam memilih algoritma regresi adalah memahami hubungan antara variabel independen (fitur) dan variabel dependen (target). Apakah hubungan ini tampak linear, non-linear, atau mungkin kompleks dengan banyak interaksi? Anda dapat menggunakan visualisasi data seperti scatter plot atau pair plot untuk memeriksa pola hubungan ini.
- Pertimbangkan Dimensi Data
Dimensi data mengacu pada jumlah fitur (variabel independen) yang Anda miliki. Data dengan dimensi tinggi (banyak fitur) memerlukan algoritma yang dapat menangani kompleksitas ini, terutama jika ada risiko multikolinearitas yang berarti beberapa fitur saling berkorelasi kuat.
- Evaluasi Ukuran Dataset
Ukuran dataset, baik dari segi jumlah fitur maupun jumlah observasi (baris), sangat memengaruhi pemilihan algoritma. Beberapa algoritma mungkin bekerja lebih baik dengan data yang besar, sementara yang lain mungkin lebih efisien dengan dataset yang lebih kecil.
- Analisis Multikolinearitas
Multikolinearitas terjadi ketika beberapa variabel independen saling berkorelasi kuat sehingga bisa menyebabkan masalah dalam pemodelan jika menggunakan algoritma yang salah. Anda perlu mempertimbangkan algoritma yang dapat menangani atau mengurangi dampak dari multikolinearitas ini, seperti Ridge Regression, Lasso Regression, Elastic Net, dan lain sebagainya..
- Identifikasi Kebutuhan Seleksi Fitur
Jika Anda bekerja dengan dataset yang memiliki banyak fitur, tetapi hanya sebagian yang benar-benar penting untuk prediksi, Anda memerlukan algoritma yang dapat melakukan seleksi fitur secara otomatis. Ini akan membantu menyederhanakan model dan meningkatkan interpretabilitas.
- Periksa Distribusi Data
Memeriksa distribusi data, khususnya variabel dependen merupakan hal yang sangat penting. Jika distribusi data tidak normal atau memiliki outlier, Anda perlu memilih algoritma yang lebih robust terhadap outlier atau yang dapat memodelkan distribusi non-normal dengan baik.
- Evaluasi Risiko Overfitting
Overfitting terjadi ketika model terlalu kompleks dan sangat cocok dengan data pelatihan, tetapi performanya buruk pada data baru. Anda perlu mempertimbangkan apakah algoritma yang dipilih cenderung overfitting dan apakah ada teknik regularisasi yang bisa membantu mengurangi risiko ini.
- Pertimbangkan Interpretabilitas
Jika interpretabilitas model penting bagi Anda karena perlu menjelaskan hasil prediksi ke pemangku kepentingan secara non teknis, pemilihan model memiliki peran penting. Pada kasus-kasus tertentu, Anda mungkin ingin memilih algoritma yang menghasilkan model yang mudah dipahami dan diinterpretasikan.
- Kecepatan dan Efisiensi
Beberapa algoritma lebih cepat dan lebih efisien dalam hal waktu komputasi dan sumber daya. Jika Anda bekerja dengan dataset yang sangat besar atau perlu menjalankan model secara real-time, kecepatan, dan efisiensi algoritma menjadi faktor penting dalam pemilihan.
- Tentukan Tujuan Prediksi
Terakhir, pertimbangkan apa tujuan akhir dari prediksi Anda. Apakah Anda hanya perlu memprediksi nilai rata-rata atau ada kebutuhan untuk memahami distribusi yang lebih luas dari data? Apakah Anda ingin memprediksi nilai spesifik pada kuantil tertentu atau seluruh distribusi? Jawaban atas pertanyaan ini akan memandu Anda dalam memilih algoritma yang paling sesuai.
Dengan mengikuti langkah-langkah ini, Anda dapat membuat keputusan yang lebih tepat tentang algoritma regresi mana yang akan digunakan berdasarkan kebutuhan spesifik dan karakteristik dataset tanpa harus langsung terfokus pada jenis algoritma yang tersedia.
Jika data Anda menunjukkan hubungan linear antara variabel-variabel seperti lama bekerja, industri, dan tingkat pendidikan dengan gaji, regresi linear bisa menjadi pilihan yang tepat. Namun, jika hubungan tersebut tidak linear, Anda perlu mempertimbangkan penggunaan regresi polinomial atau algoritma lain yang lebih cocok. Apa sih regresi linear dan polinomial? Tenang saja, Anda akan mempelajari tentang jenis-jenis regresi tersebut di materi berikutnya.
Pelatihan Model
Setelah algoritma dipilih, saatnya melatih model menggunakan data pelatihan. Pada tahap ini, algoritma akan menganalisis data untuk menemukan pola yang dapat digunakan untuk memprediksi gaji berdasarkan variabel-variabel yang ada. Proses ini akan melibatkan penyesuaian parameter model untuk memaksimalkan akurasi prediksi.
Misalnya, model regresi linear akan belajar menghubungkan variabel-variabel seperti lama bekerja, jenis industri, dan tingkat pendidikan dengan gaji karyawan. Model akan membangun persamaan yang paling sesuai dengan data pelatihan untuk memprediksi gaji.
Evaluasi Model
Evaluasi model adalah langkah untuk mengukur seberapa baik model dapat memprediksi gaji berdasarkan data pengujian. Berbagai metrik seperti Mean Squared Error (MSE) dan R-squared digunakan untuk menilai performa model. Evaluasi ini penting untuk memastikan bahwa model tidak hanya baik pada data pelatihan, tetapi juga mampu melakukan generalisasi pada data baru.
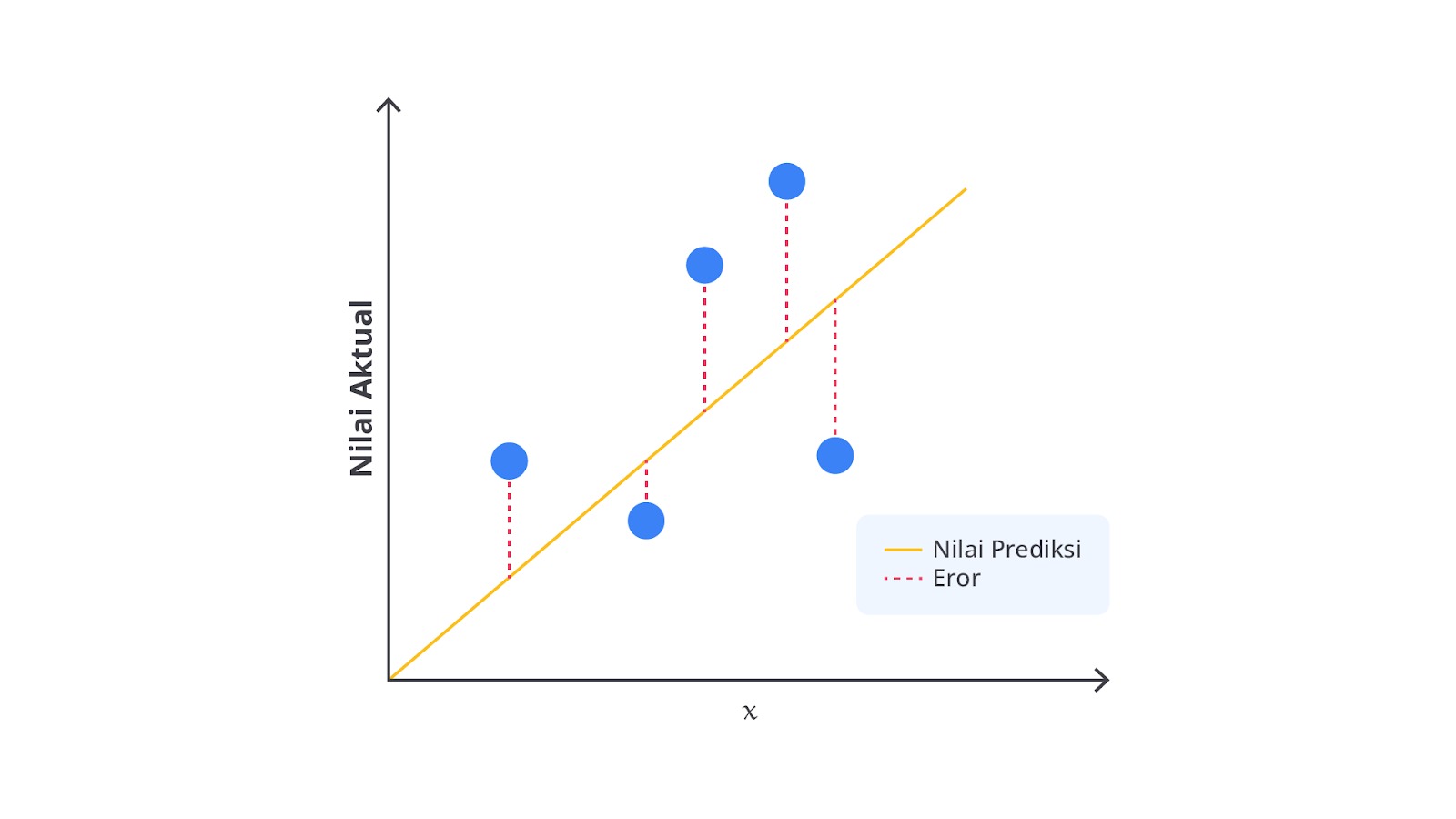
Jika model Anda memprediksi gaji karyawan dengan MSE yang rendah, ini berarti rata-rata kesalahan prediksinya kecil. Hal ini menunjukkan bahwa model bekerja dengan baik. Selain itu, nilai R-squared yang tinggi menandakan bahwa model dapat menjelaskan sebagian besar variasi dalam data gaji karyawan.
Misalkan kita memiliki lima data pengujian dengan nilai sebenarnya dan nilai prediksi sebagai berikut.
| ID Karyawan | Gaji Sebenarnya (Rp) | Gaji yang Diprediksi (Rp) |
|---|---|---|
1 | 15.000.000 | 14.500.000 |
2 | 12.000.000 | 12.500.000 |
3 | 20.000.000 | 19.000.000 |
4 | 10.000.000 | 11.000.000 |
5 | 18.000.000 | 17.500.000 |
Kita dapat menghitung MSE sebagai berikut.

Jadi, MSE dari contoh di atas adalah 550.000.000.000. Dari mana rumus tersebut didapatkan? Tenang, pada modul ini kita akan membahas lebih detail beberapa metriks yang biasa digunakan untuk melakukan evaluasi pada model regresi.
Deployment
Setelah model terbukti efektif, langkah terakhir adalah menerapkannya pada data baru untuk memprediksi gaji karyawan di masa depan. Model ini bisa digunakan oleh berbagai departemen. Misalnya, HR bisa menggunakannya untuk menetapkan gaji yang sesuai berdasarkan lama bekerja, industri, dan tingkat pendidikan karyawan. Dengan model ini, penentuan gaji dapat dilakukan dengan lebih efisien dan objektif, serta mengurangi bias dalam proses penentuan gaji.
Proses di atas merupakan penjelasan dari model deployment. Deployment adalah proses mengintegrasikan model machine learning yang telah dilatih dan diuji ke dalam lingkungan produksi sehingga dapat digunakan oleh aplikasi atau sistem yang membutuhkan prediksi secara real-time atau batch. Perhatikan gambar berikut secara saksama.
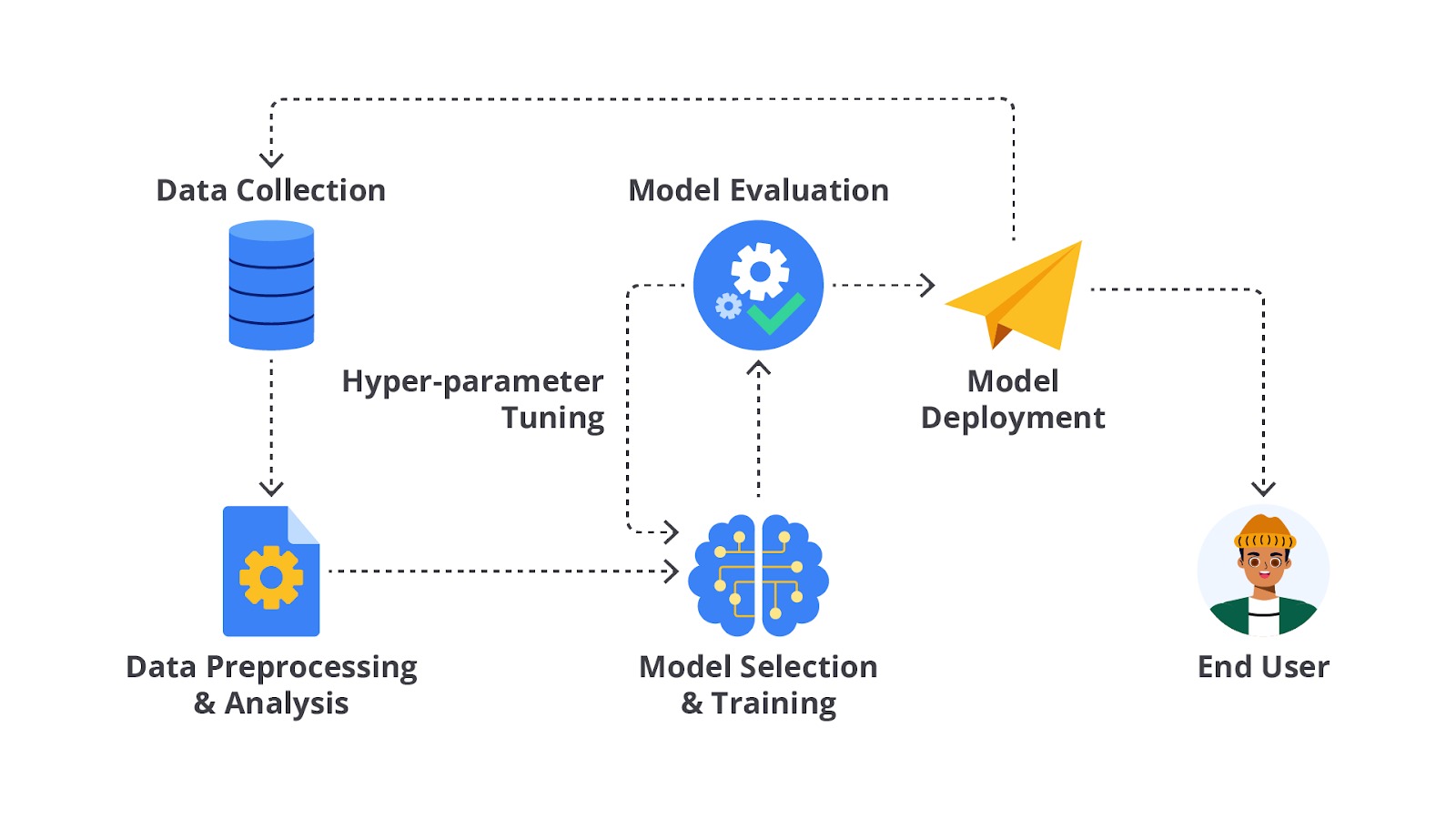
Tahapan model deployment merupakan hal yang paling penting dalam proses pembangunan machine learning, mengapa hal tersebut bisa terjadi? Sederhananya dengan melakukan model deployment, Anda bisa membuat sebuah “jembatan” dari kode yang dibangun dengan pengguna umum bahkan yang tidak memiliki latar belakang IT. Hal ini menjadi sangat penting karena tujuan akhir pembangunan model machine learning adalah dapat digunakan oleh pengguna dan menghasilkan revenue atau membantu proses bisnis bekerja.
Eitsss, setelah melakukan model deployment, bukan berarti tugas Anda sebagai machine learning engineer sudah selesai. Pada umumnya, tahapan deployment ini menjadi satu paket dengan model monitoring. Monitoring model adalah proses memantau kinerja model setelah deployment untuk memastikan model tetap memberikan hasil yang akurat dan relevan. Monitoring diperlukan karena model Machine Learning dapat mengalami penurunan kinerja seiring waktu akibat berbagai faktor, seperti perubahan dalam data input (data drift), perubahan pola pengguna, atau perubahan dalam lingkungan operasi.
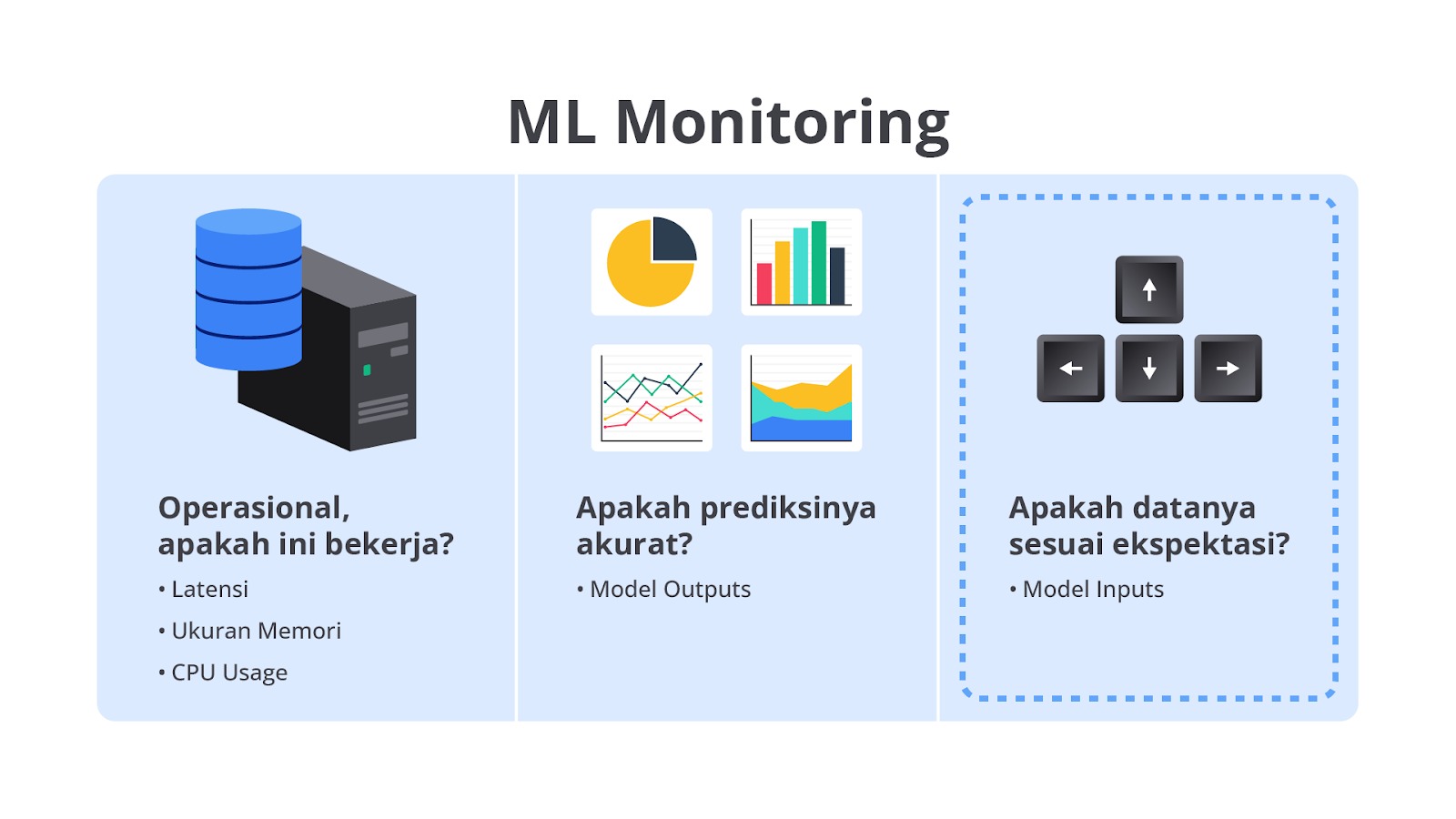
Kedua tahapan di atas adalah bagian integral dari siklus hidup model machine learning yang andal. Tanpa monitoring, kinerja model dapat menurun tanpa disadari sehingga dapat mengakibatkan keputusan bisnis yang salah atau pengalaman pengguna yang buruk.
Dengan deployment dan monitoring yang terstruktur dan cermat, developer dapat memastikan bahwa model machine learning mereka tidak hanya berhasil dibangun, tetapi juga terus memberikan nilai dalam lingkungan produksi.
Jenis-Jenis Regression
Seperti yang sudah Anda pelajari, regresi adalah salah satu teknik dalam statistik dan machine learning yang digunakan untuk memodelkan hubungan antara satu atau lebih variabel independen (input) dan variabel dependen (output).
Tujuan utama regresi adalah untuk memprediksi nilai dari variabel dependen berdasarkan nilai dari variabel independen. Namun, tahukah Anda bahwa setiap jenis regresi memiliki cara kerja dan kegunaan yang berbeda?
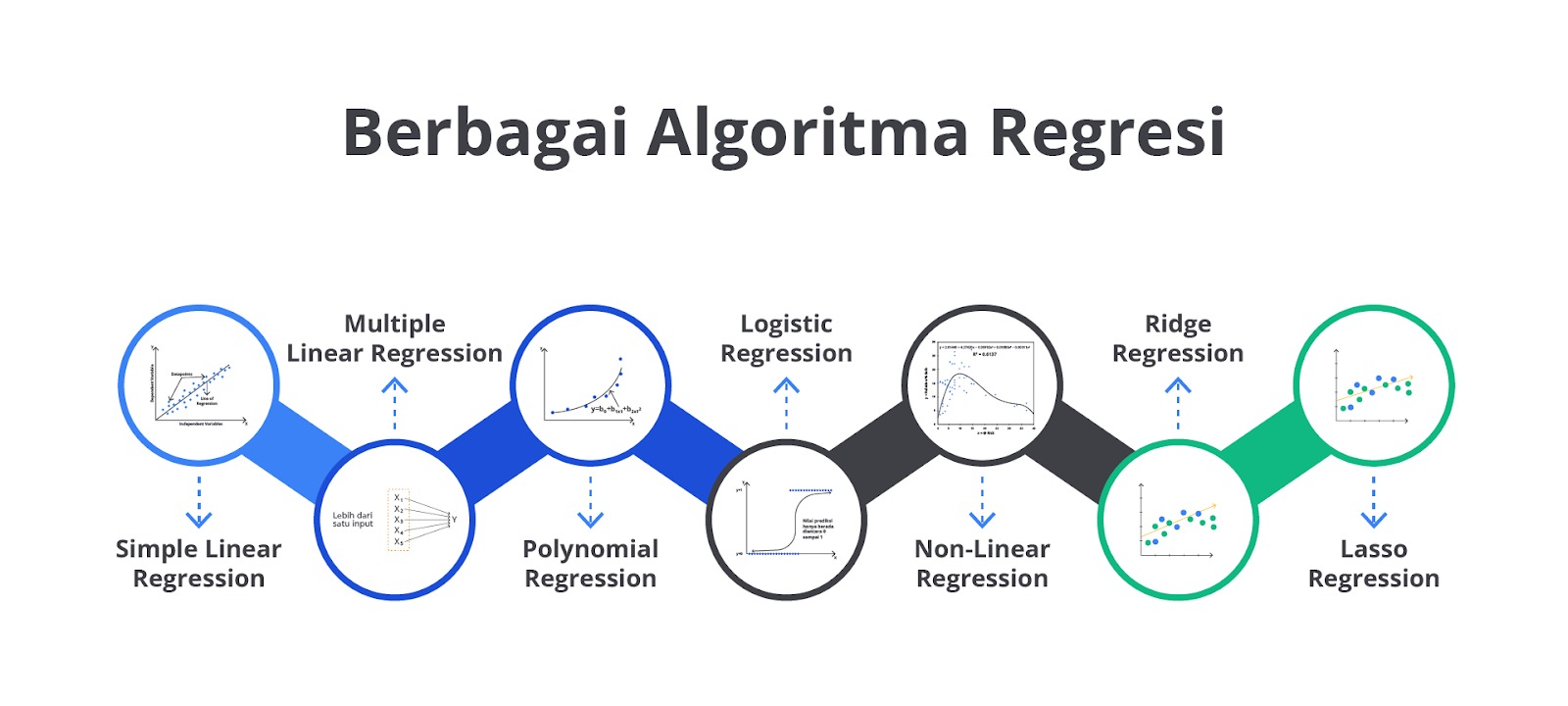
Mari kita bahas jenis-jenis regresi ini secara lebih detail dengan penjelasan yang mudah dipahami.
Linear Regression
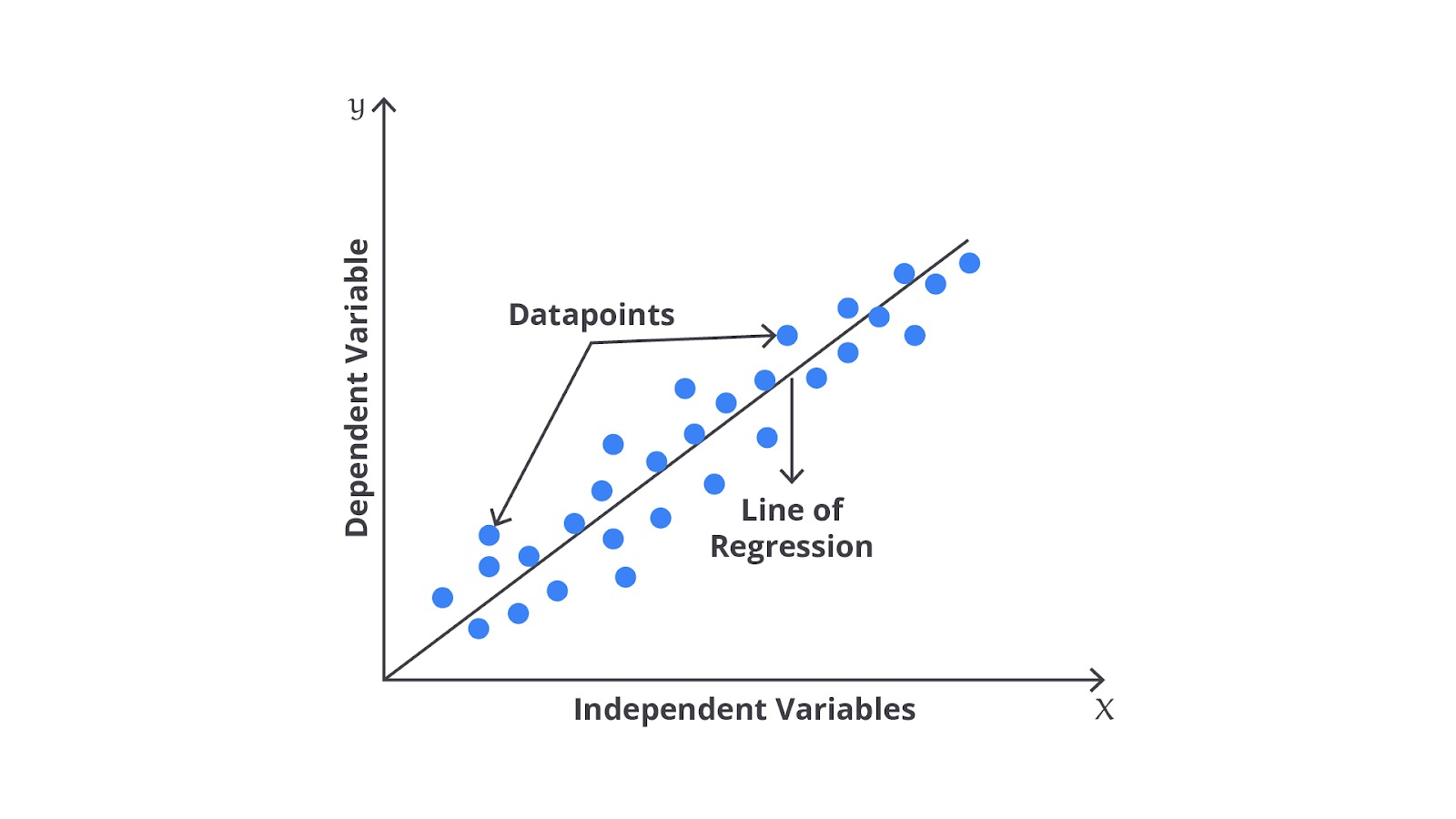
Linear regression (regresi linear) adalah jenis regresi yang paling sederhana, kita akan mencoba menemukan garis lurus terbaik yang menggambarkan hubungan antara variabel independen (X) dan variabel dependen (Y).
Misalnya, jika kita ingin memprediksi harga rumah berdasarkan ukuran rumah, kita bisa menggunakan regresi linear untuk menemukan garis yang paling cocok antara ukuran rumah (X) dan harga rumah (Y).
Misalkan kita punya data tentang ukuran rumah dan harga jualnya. Dengan regresi linear, kita bisa membuat persamaan garis seperti ini.
Harga Rumah = a + b* (Ukuran Rumah) dengan catatan a adalah intercept (titik yang memotong sumbu Y) dan b adalah kemiringan garis (seberapa banyak harga berubah dengan setiap unit perubahan ukuran rumah).
Metode ini memiliki beberapa kelebihan dan kekurangan seperti.
| Kelebihan | Kekurangan |
|---|---|
|
|
Mungkin tebersit sebuah pertanyaan di benak Anda, “Bagaimana cara mengetahui hubungan antara variabel? Apakah termasuk linear atau nonlinear?” Pertanyaan yang bagus. Mari kita bahas sekilas pada materi ini.
Salah satu cara paling mudah untuk mengetahui hubungan antar variabel adalah menggunakan visualisasi data seperti scatter plot. Dengan membuat scatter plot antara dua variabel, kita dapat langsung melihat pola hubungan mereka. Jika titik-titik data membentuk garis lurus (atau mendekati garis lurus), hubungan antara variabel tersebut adalah linear. Namun, jika titik-titik tersebut membentuk kurva atau pola yang melengkung, hubungan tersebut cenderung non-linear.
Contoh:
- Hubungan linear: titik-titik data cenderung membentuk garis lurus.
- Hubungan non-linear: titik-titik data membentuk pola melengkung atau berbentuk U.
Multiple Linear Regression
Multiple Linear Regression (Regresi Linear Berganda) adalah pengembangan dari regresi linear sederhana yang digunakan untuk memodelkan hubungan antara satu variabel dependen (terkadang disebut variabel respons atau target) dan dua atau lebih variabel independen (juga disebut prediktor atau fitur). Model ini memungkinkan kita untuk memahami bagaimana beberapa faktor memengaruhi hasil yang diinginkan secara simultan.
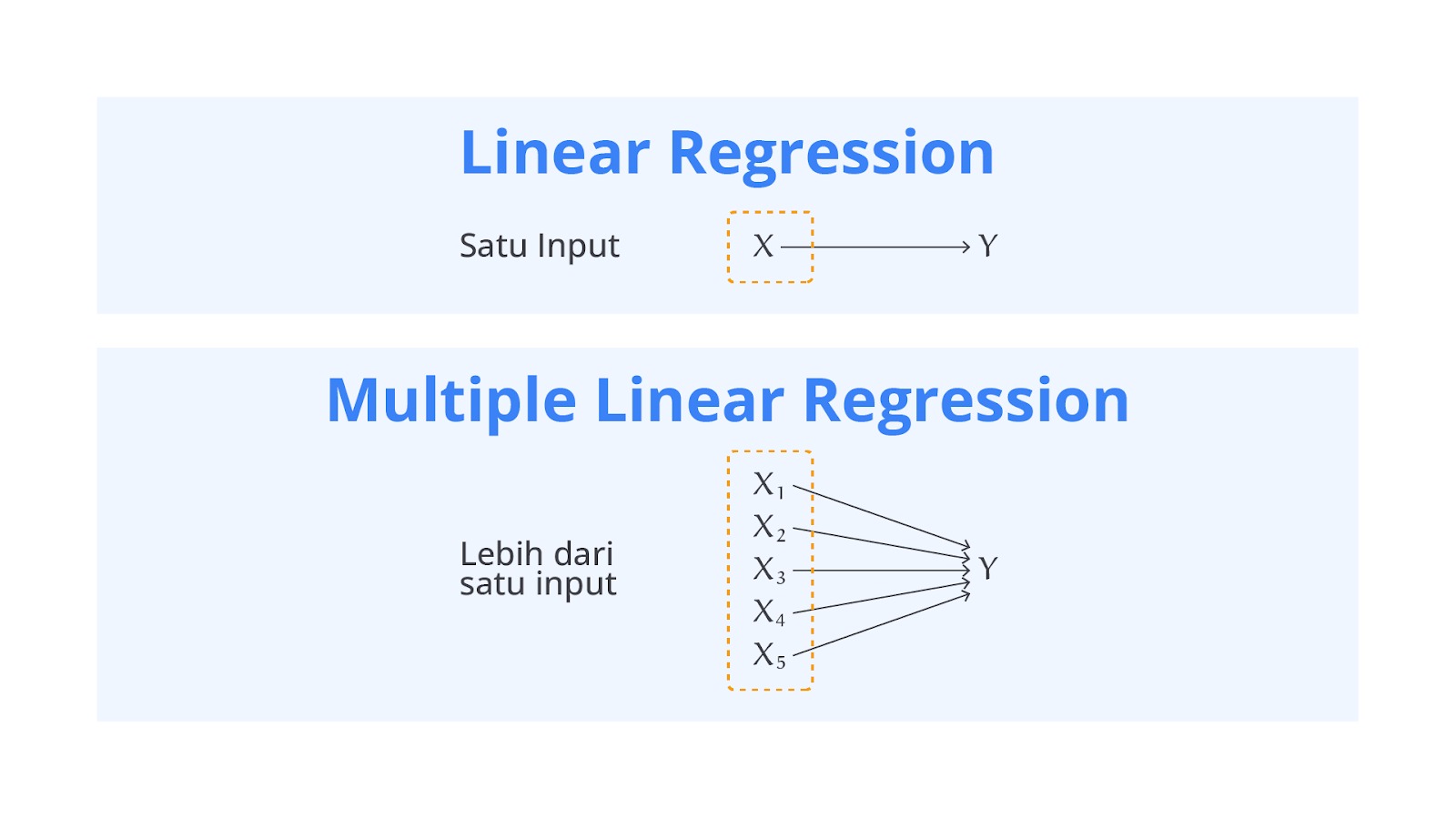
Persamaan umum untuk regresi linear berganda adalah seperti berikut.
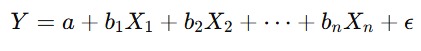
Rumus di atas dapat kita interpretasikan sebagai berikut.
- Y: variabel dependen (output yang ingin diprediksi).
- a: intercept atau konstanta, yaitu nilai Y saat semua X bernilai nol.
- b1, b2, ..., bn: koefisien regresi untuk setiap variabel independen X1,X2,...,Xn. Koefisien ini mengukur seberapa besar pengaruh masing-masing variabel independen terhadap variabel dependen.
- X1, X2, ..., Xn: variabel independen (input atau prediktor yang memengaruhi Y).
- ε: error term atau residu yang menangkap variasi dalam Y dan tidak bisa dijelaskan oleh variabel independen.
Misalkan, kita ingin memprediksi harga rumah berdasarkan beberapa variabel seperti ukuran rumah, jumlah kamar tidur, dan usia rumah. Model regresi linear berganda akan terlihat seperti ini:
Harga Rumah=a+b1(Ukuran Rumah)+b2(Jumlah Kamar Tidur)+b3(Usia Rumah)+ϵ
- Jika b1 positif, itu berarti semakin besar ukuran rumah, semakin tinggi harga rumah, dengan asumsi variabel lain tetap konstan.
- Jika b3 negatif, itu berarti semakin tua rumah, semakin rendah harga rumah, dengan asumsi variabel lain tetap konstan.
Dengan menggunakan multiple linear regression, kita bisa mendapatkan pemahaman yang lebih baik tentang bagaimana berbagai faktor memengaruhi variabel dependen, membantu dalam pengambilan keputusan, dan peramalan yang lebih akurat.
Polynomial Regression
Polynomial Regression (regresi polinomial) adalah bentuk lanjutan dari regresi linear yang digunakan untuk memodelkan hubungan antara variabel independen dan variabel dependen ketika hubungan tersebut tidak linear. Sebagai pengembangan dari regresi linear, metode regresi polinomial memungkinkan hubungan antara variabel untuk berbentuk kurva dengan derajat yang lebih tinggi daripada garis lurus seperti parabola atau kurva lainnya.
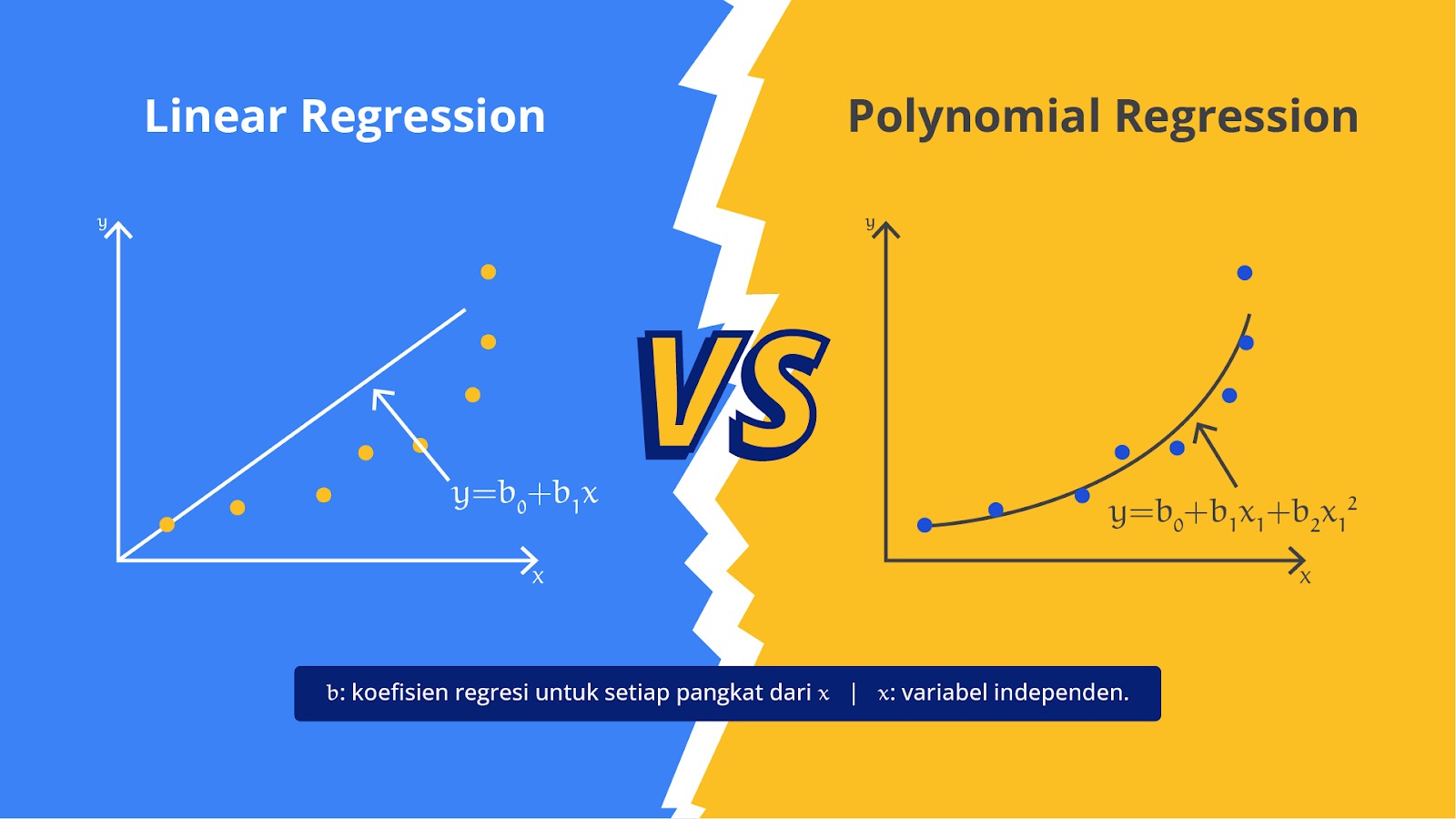
Dalam regresi polinomial Anda memodelkan hubungan antara variabel dependen Y dan satu atau lebih variabel independen X menggunakan polinomial dari derajat n. Persamaan umum untuk regresi polinomial adalah seperti di bawah ini.
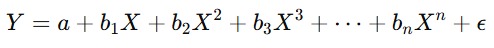
Rumus di atas dapat kita interpretasikan sebagai berikut.
- Y: variabel dependen yang ingin kita prediksi.
- a: intercept, yaitu nilai Y saat X memiliki nilai nol.
- b1, b2, ..., bn: koefisien regresi untuk setiap pangkat dari X. Koefisien ini menunjukkan kontribusi dari masing-masing pangkat X terhadap nilai prediksi Y.
- X: variabel independen.
- n: derajat dari polinomial.
- ε: error term atau residu yang menangkap variasi dalam Y dan tidak bisa dijelaskan oleh variabel independen.
Lalu, kapan Anda perlu menggunakan regresi polinomial? Ia digunakan ketika data menunjukkan hubungan non-linear antara variabel independen dan dependen. Jika kita mencoba menggunakan regresi linear pada data yang memiliki pola melengkung, model linear mungkin tidak memberikan hasil yang baik karena tidak dapat menangkap kompleksitas hubungan tersebut.
Misalnya, ketika hubungan antara variabel dependen dan independen berbentuk U atau terbalik (seperti kurva parabola). Selain itu Anda juga bisa menggunakan metode ini ketika data menunjukkan pola lebih kompleks yang melibatkan titik balik atau kurva ganda.
Logistic Regression
Logistic Regression (regresi logistik) adalah salah satu teknik pemodelan statistik yang digunakan untuk memprediksi hasil biner, yaitu hasil dengan dua kemungkinan, seperti "ya" atau "tidak," "sukses" atau "gagal," dan lain sebagainya. Berbeda dengan regresi linear yang digunakan untuk memprediksi nilai numerik, regresi logistik digunakan untuk memodelkan probabilitas bahwa suatu kejadian akan terjadi (hasil biner).
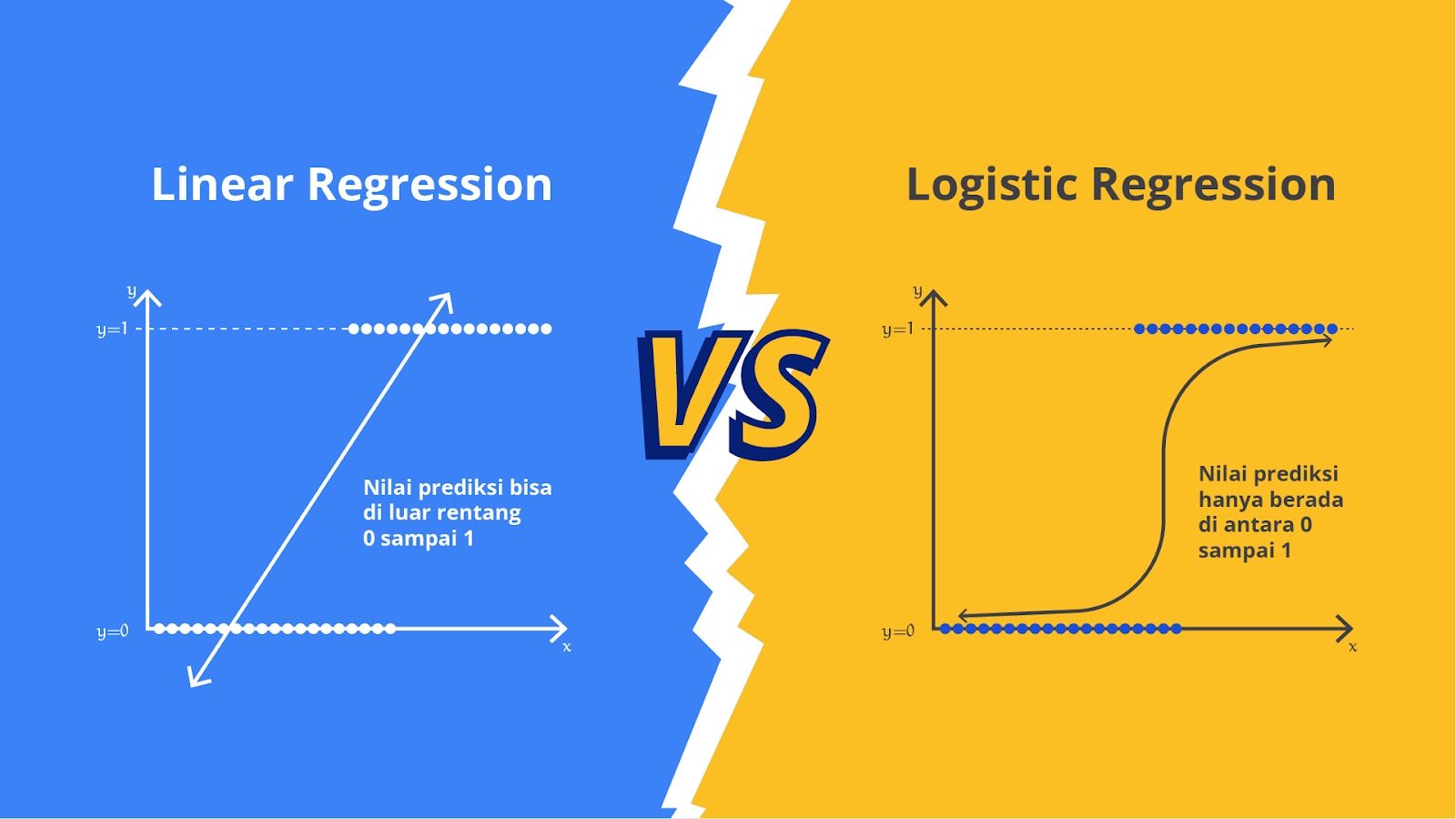
Fun fact-nya walaupun memiliki nama regresi, metode ini sering kali digunakan untuk masalah klasifikasi. Namun, tidak sepenuhnya akurat juga untuk menyebut regresi logistik sebagai klasifikasi karena regresi logistik adalah metode statistik yang memperkirakan probabilitas hasil biner, sedangkan klasifikasi adalah tugas memprediksi kategori atau kelas yang dimiliki oleh titik data baru berdasarkan sekumpulan fitur.
Meskipun regresi logistik dapat digunakan untuk tugas klasifikasi, tetapi pada intinya ia masih merupakan metode regresi dan terutama digunakan untuk memperkirakan probabilitas daripada membuat klasifikasi langsung.
Regresi logistik mengasumsikan bahwa hubungan antara variabel independen X dan variabel dependen Y dapat dimodelkan sebagai probabilitas yang dihasilkan dari fungsi logistik (sigmoid function). Fungsi ini mengubah input apa pun menjadi output antara 0 dan 1 yang dapat diinterpretasikan sebagai probabilitas. Persamaan dasar dari regresi logistik dapat dituliskan dengan rumus seperti berikut.
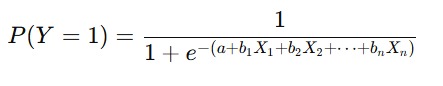
Rumus di atas dapat kita interpretasikan sebagai berikut.
- P(Y=1): probabilitas bahwa variabel dependen Y adalah 1 (kejadian yang diinginkan terjadi).
- a: intercept atau konstanta model.
- b1,b2,...,bn: koefisien regresi untuk setiap variabel independen.
- X1,X2,...,Xn: variabel independen yang memengaruhi hasil Y.
- e: basis dari logaritma natural (sekitar 2.718).
Pada intinya, logistik regresi ini merupakan salah satu algoritma yang sering digunakan untuk mengatasi permasalahan klasifikasi. So, jangan tertipu dengan namanya, ya!
Non-Linear Regression
Non-linear regression adalah bentuk regresi yang digunakan untuk memodelkan hubungan antara variabel independen dan variabel dependen ketika hubungan tersebut tidak dapat dijelaskan dengan garis lurus atau fungsi linear. Dalam non-linear regression, model yang digunakan bisa berbentuk lebih kompleks, seperti eksponensial, logaritmik, kuadrat, kubik, atau bentuk fungsi lainnya.
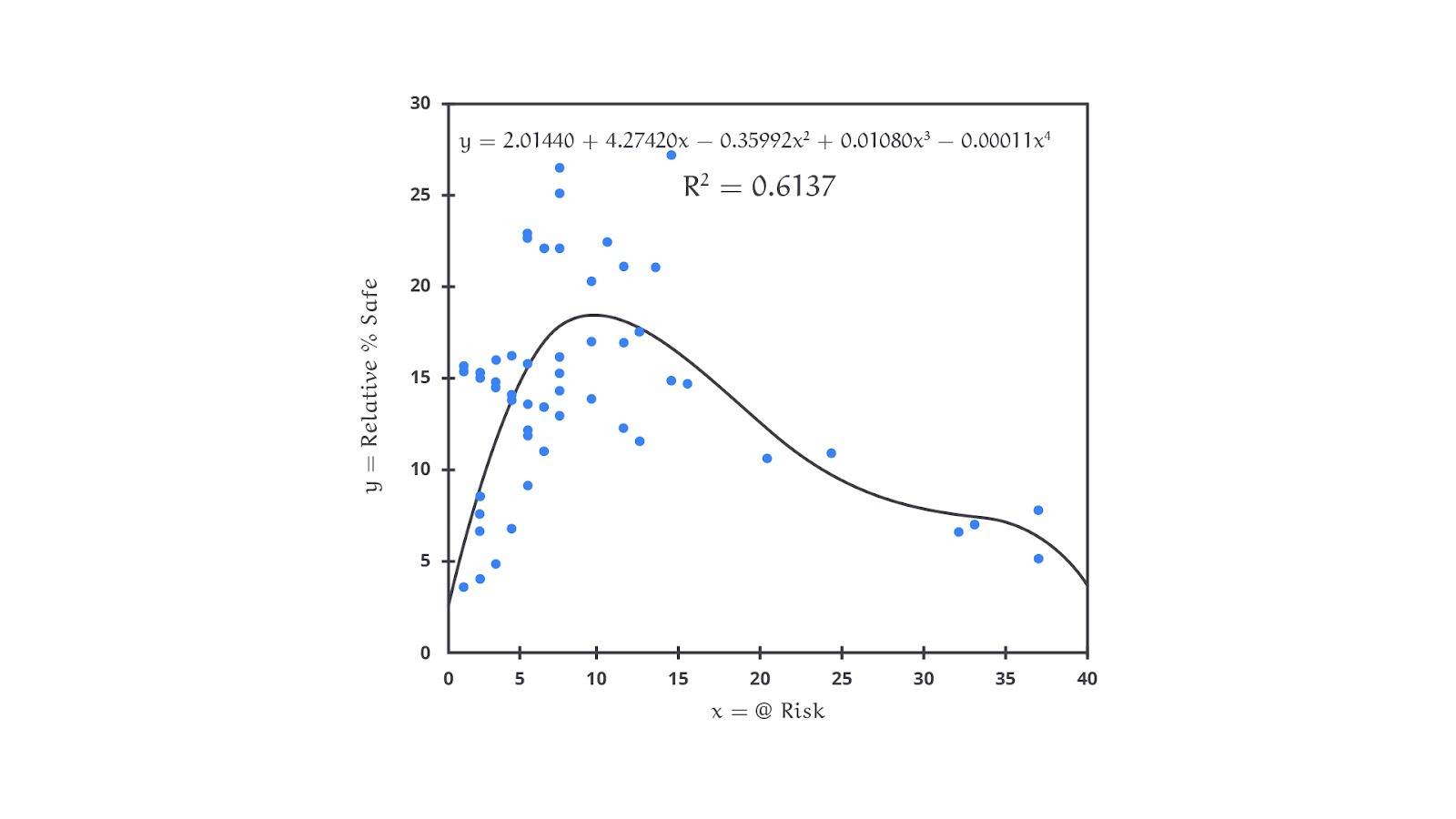
Berbeda dengan linear regression yang memiliki hubungan linear dalam bentuk Y=a+bX antara variabel independen X dan variabel dependen Y, non-linear regression memungkinkan untuk mencari hubungan yang lebih rumit dibandingkan hanya garis linear saja. Model non-linear bisa berupa hampir semua bentuk matematis seperti Y=f(X)+ϵ dengan ketentuan f(X) adalah fungsi non-linear dari variabel independen X, dan ϵ adalah error term atau residu.
Terdapat banyak sekali bentuk dari non-linear regression yang perlu Anda ketahui. Beberapa contohnya adalah eksponensial, logaritmik, power, polynomial (sudah kita bahas pada materi sebelumnya), kuadratik, dan lain sebagainya.

Berikut adalah beberapa contoh model non-linear yang sering digunakan.
- Model Eksponensial
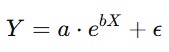
Dengan ketentuan a dan b adalah parameter yang harus diestimasi. Model ini sering digunakan dalam situasi dengan kondisi perubahan dari Y bersifat konstan. - Model Logaritmik
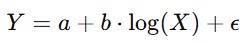
Model ini sering digunakan ketika perubahan Y melambat seiring dengan bertambahnya X. - Model Kuadrat (Quadratic Model)
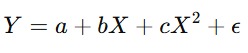
Model ini berguna ketika hubungan antara variabel memiliki titik balik. - Model Sigmoid (Logistik atau Gompertz)
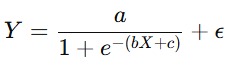
Model sigmoid sering digunakan dalam biologi, ekonomi, dan ilmu sosial untuk memodelkan pertumbuhan populasi, difusi inovasi, dan fenomena lain yang menunjukkan saturasi.
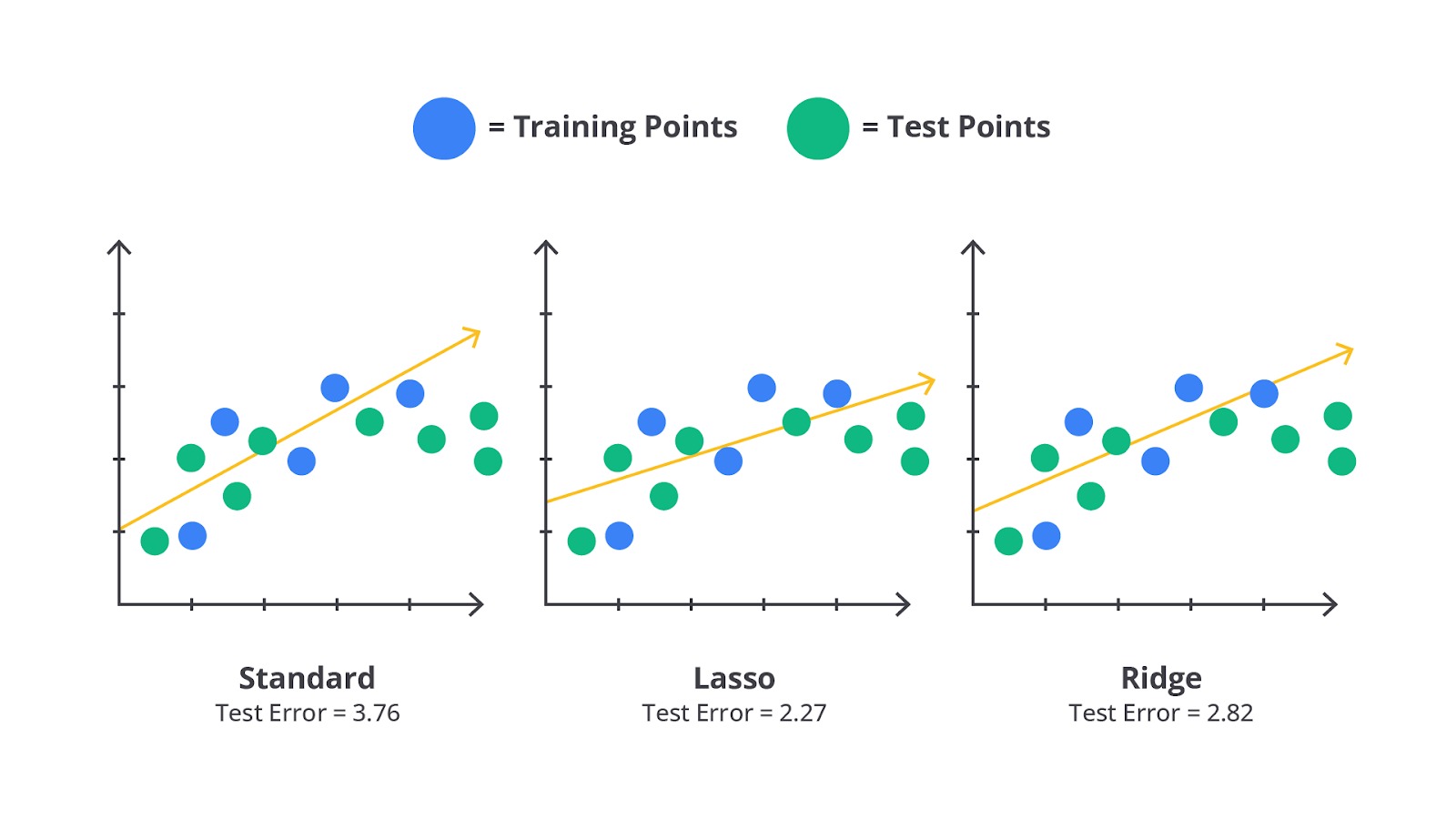
Ridge and Lasso Regression
Ridge Regression dan Lasso Regression adalah dua teknik regularisasi yang digunakan dalam regresi linear untuk mengatasi masalah multikolinearitas dan overfitting.
Refreshing Material Multikolinearitas adalah kondisi dua atau lebih variabel independen dalam model regresi sangat berkorelasi satu sama lain. Ini berarti bahwa salah satu variabel independen dapat diprediksi secara linear dari variabel independen lainnya dengan tingkat akurasi yang tinggi. Overfitting terjadi ketika model regresi terlalu kompleks dan terlalu fit terhadap data latih (training data) sehingga model tersebut menangkap "noise" atau fluktuasi acak dalam data selain pola yang sebenarnya. Akibatnya, model tidak bekerja dengan baik pada data baru atau data uji (test data). |
Meskipun kedua teknik ini bertujuan untuk menstabilkan model dan meningkatkan performa prediksi, mereka melakukannya dengan cara yang berbeda, terutama dalam hal bagaimana mereka menerapkan penalti pada koefisien regresi.
Ridge Regression
Ridge regression menambahkan penalti berupa jumlah kuadrat dari koefisien regresi ke dalam fungsi loss. Fungsi objektif yang diminimalkan dalam ridge regression dapat ditulis dengan rumus seperti berikut.
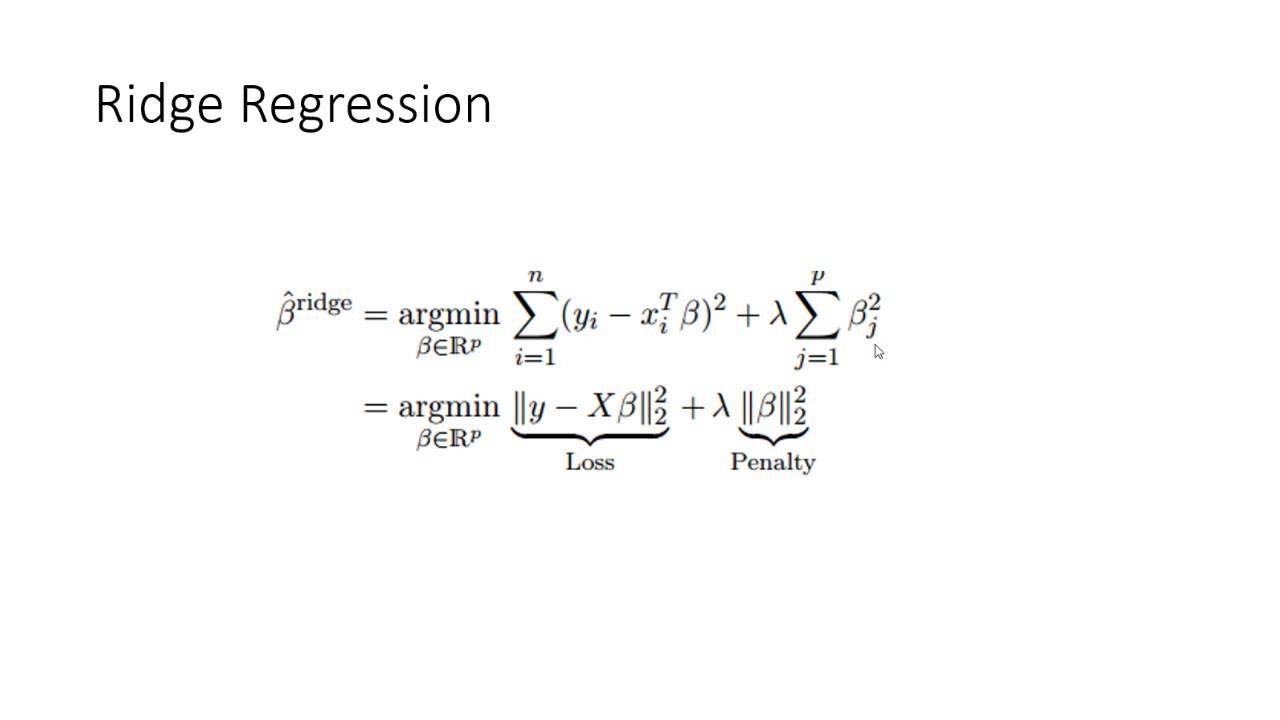
Penalti yang diterapkan membuat koefisien regresi menjadi lebih kecil (shrinkage), tetapi tidak pernah menyetel mereka menjadi nol. Ini berarti semua variabel tetap akan digunakan dalam pembangunan model, meskipun dengan koefisien yang lebih kecil. Karena tidak ada koefisien yang disetel menjadi nol, interpretasi model ridge regression lebih sederhana dalam hal mempertimbangkan kontribusi semua variabel. Namun, karena semua variabel tetap ada, interpretasi bisa menjadi sulit jika ada banyak variabel.
Lasso Regression
Lasso regression menambahkan penalti berupa jumlah absolut dari koefisien regresi ke dalam fungsi loss. Fungsi objektif yang diminimalkan dalam lasso regression dapat ditulis dengan rumus seperti berikut.
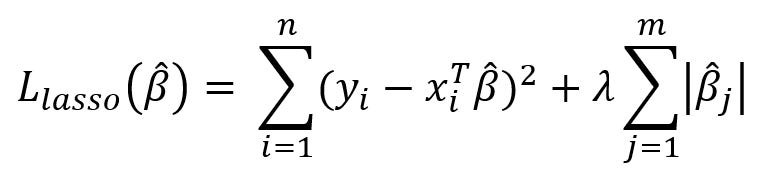
Penalti yang diterapkan tidak hanya mengecilkan koefisien, tetapi juga dapat menyetel beberapa koefisien menjadi nol. Ini berarti Lasso regression secara efektif dapat melakukan seleksi fitur, menghilangkan variabel yang dianggap tidak signifikan dan mempertahankan variabel yang memiliki peran signifikan.
Lalu, kapan waktu yang tepat untuk menggunakan ridge atau lasso regression?
Ridge regression lebih cocok digunakan ketika semua variabel diharapkan memiliki pengaruh yang kecil tetapi signifikan dan tidak ingin menghilangkan variabel dari model. Ini sangat berguna dalam situasi multikolinearitas tinggi dan kita ingin menjaga semua fitur dalam model dengan koefisien yang lebih stabil. Di lain sisi, lasso regression lebih cocok ketika kita memiliki banyak variabel, tetapi kita percaya bahwa hanya sebagian kecil dari mereka yang benar-benar signifikan. Lasso membantu menyederhanakan model dengan secara otomatis menghilangkan variabel yang tidak penting.
Di lain sisi, ketika memiliki kasus yang lebih kompleks, Anda dapat menggabungkan kedua metode regularisasi di atas dengan menggunakan metode Elastic Net. Elastic Net adalah teknik yang menggabungkan penalti dari Ridge dan Lasso (kombinasi L1 dan L2 regularization). Hal ini dapat memberikan fleksibilitas lebih ketika kita ingin mengontrol keduanya (jumlah fitur yang dipilih dan tingkat regularisasi).
Contoh Algoritma Regresi - Linear Regression
Linear Regression adalah salah satu teknik statistik yang paling sederhana dan banyak digunakan dalam analisis data untuk memodelkan hubungan antara satu variabel dependen (output) dan satu atau lebih variabel independen (input). Dalam bentuknya yang paling dasar, yaitu Simple Linear Regression, hanya ada satu variabel independen yang digunakan untuk memprediksi nilai variabel dependen. Jika ada lebih dari satu variabel independen, model tersebut disebut Multiple Linear Regression.
Linear regression bertujuan untuk menemukan garis lurus terbaik yang dapat menggambarkan hubungan antara variabel independen dan variabel dependen.
Parameter Utama dalam Linear Regression
- Intercept
- Intercept adalah nilai Y ketika semua variabel independen X1,X2,…,Xn bernilai nol. Sederhana, intercept adalah titik pada garis regresi yang memotong sumbu Y. Namun, interpretasi intercept bergantung pada apakah nilai X=0 masuk akal dalam konteks data tersebut atau tidak. Jika X=0 tidak relevan atau tidak mungkin, intercept mungkin tidak memiliki makna yang signifikan.
- Koefisien Regresi
- Koefisien regresi mewakili kemiringan atau slope garis regresi untuk masing-masing variabel independen. Ini menunjukkan perubahan yang diharapkan pada variabel dependen Y untuk setiap perubahan satu unit pada variabel independen Xi, dengan asumsi variabel lainnya tetap konstan.
- Interpretasi:
- Positif: jika koefisien bi positif, peningkatan Xi akan menyebabkan peningkatan juga pada Y.
- Negatif: jika koefisien bi negatif, peningkatan Xi akan menyebabkan penurunan pada Y.
- Besarnya Nilai: besarnya nilai bi menunjukkan seberapa kuat pengaruh variabel independen tersebut terhadap variabel dependen.
- Residual (ϵ)
- Residual adalah selisih antara nilai yang diamati (aktual) dan nilai yang diprediksi oleh model regresi. Ini menggambarkan error atau kesalahan dalam prediksi model. Residual digunakan untuk menilai seberapa baik model sesuai dengan data yang ada. Jika residualnya kecil dan tersebar acak, ini menunjukkan bahwa model cukup baik dalam memprediksi variabel dependen.
Dalam penerapannya, Anda perlu memperhatikan beberapa hal agar dapat memastikan penggunaan linear regression sudah tepat, berikut beberapa hal yang perlu diperhatikan.
- Linearitas: hubungan antara variabel independen dan dependen harus linear. Ini berarti perubahan Y harus proporsional terhadap perubahan X.
- Independensi Residual: residual harus independen satu sama lain. Tidak boleh ada pola atau korelasi yang jelas antara residual.
- Homoskedastisitas: varians residual harus konstan di seluruh rentang nilai variabel independen. Jika varians residual berubah (heteroskedastisitas), hasil model bisa menjadi bias.
- Normalitas Residual: residual harus mengikuti distribusi normal. Ini penting untuk validitas uji statistik seperti pengujian signifikansi koefisien.
- Tidak Ada Multikolinearitas: dalam multiple linear regression, variabel independen tidak boleh terlalu berkorelasi satu sama lain. Jika ada multikolinearitas yang tinggi, koefisien regresi bisa menjadi tidak stabil dan sulit diinterpretasikan.
Sebagai contoh mari kita kembali ke contoh persoalan jual beli rumah agar semakin terbayang studi kasus yang tepat untuk menggunakan linear regression. Pada kasus ini, data yang akan kita gunakan adalah luas rumah dan harga.
Luas Rumah (m2) | Harga (Juta Rupiah) |
|---|---|
50 | 100 |
75 | 165 |
100 | 180 |
125 | 224 |
Jika kita memplot luas rumah pada sumbu X dan harga pada sumbu Y, sebuah garis dari sudut kiri bawah grafik ke kanan atas mewakili hubungan antara X dan Y. Saat memplot titik-titik data ini pada scatter plot, kita mendapatkan grafik berikut.
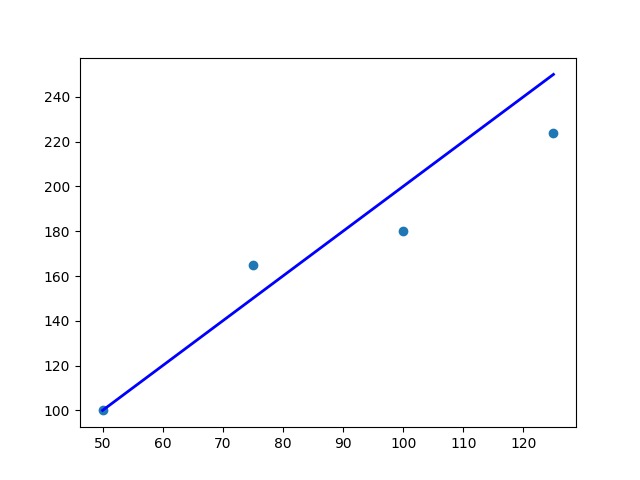
Dapat Anda lihat pada plot di atas, rasio luas rumah terhadap harga menunjukkan sebuah pola. Data di kiri bawah menunjukkan harga yang lebih murah dengan luas rumah yang lebih kecil, dan garis berlanjut ke sudut kanan atas grafik dengan artian luas rumah yang lebih besar menyebabkan harga rumah semakin mahal.
Model regresi mendefinisikan fungsi linear antara variabel X dan Y yang paling baik sehingga dapat menunjukkan hubungan antara keduanya. Hal ini diwakili oleh garis miring yang terlihat pada gambar di atas. Tujuannya adalah untuk menentukan 'garis regresi' optimal yang paling sesuai dengan semua titik data individu.
Setelah data sudah berhasil dikumpulkan dan memiliki karakteristik linear, selanjutnya model akan menghitung nilai error yang dihasilkan. Biasanya tahapan ini terjadi ketika Anda melakukan fitting atau melatih model berdasarkan data.
Model regresi linear biasanya dilatih menggunakan metode Ordinary Least Squares (OLS), yang bertujuan untuk meminimalkan jumlah kuadrat dari residuals (eror). Residual adalah perbedaan antara nilai yang diamati (aktual) dan nilai yang diprediksi oleh model. Dalam persamaan matematika, rumus OLS dapat dituliskan sebagai berikut.
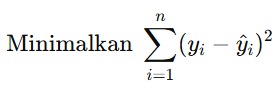
Rumus di atas dapat kita interpretasikan sebagai berikut.
- yi adalah nilai aktual dari variabel dependen untuk pengamatan ke-i.
- ŷ adalah nilai yang diprediksi oleh model untuk pengamatan ke-i.
- n adalah jumlah data.
Dalam proses pelatihan, OLS akan mencari nilai optimal untuk koefisien b1,b2,…,bn dan intercept yang meminimalkan error pada nilai prediksi. Ini dilakukan dengan mencari titik turunan pertama dari fungsi objektif (jumlah kuadrat error) terhadap masing-masing koefisien adalah nol yang merupakan minimum fungsi tersebut.
Setelah proses pelatihan selesai, model akan menghasilkan nilai koefisien regresi b1,b2,…,bn dan intercept. Koefisien ini menunjukkan seberapa besar dampak perubahan masing-masing variabel independen terhadap variabel dependen.
Dengan koefisien yang telah ditentukan, model dapat digunakan untuk membuat prediksi. Untuk setiap nilai baru dari X, model akan menghitung nilai Y yang diprediksi dengan memasukkan nilai X ke dalam persamaan regresi seperti berikut.
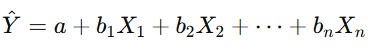
Hasil prediksi ini adalah nilai terbaik yang akan diprediksi oleh model berdasarkan hubungan linear yang dipelajari dari data latih.
Nah, sampai di sini mungkin terlihat mudah ya? Memang kok, teknik ini relatif sederhana, tetapi sangat berguna untuk memodelkan hubungan antara variabel.
Sederhananya, model ini bekerja hanya dengan menyesuaikan garis lurus yang menggambarkan hubungan antara variabel independen dan variabel dependen, lalu menggunakan metode seperti Ordinary Least Squares (OLS) untuk meminimalkan prediksi yang error.
Setelah model dilatih, koefisien regresi akan menunjukkan dampak dari variabel independen terhadap variabel dependen, dan model dapat digunakan untuk melakukan prediksi serta dievaluasi untuk validitas dan keandalannya.
Ini mungkin akan menjadi perjalanan yang cukup seru untuk Diana dan Bilqis karena di dalamnya terdapat banyak sekali rumus matematika yang menyenangkan. Namun, tentunya ini juga menjadi pengalaman yang penting untuk Anda karena sampai di sini pastinya sudah terbayang tentang penggunaan linear regression pada kehidupan sehari-hari.
Selanjutnya untuk memaksimalkan pengalaman belajar Anda mari kita bahas sedikit lebih dalam teknik regression lainnya pada materi berikutnya, yaitu polynomial regression. Cuss~
Contoh Algoritma Regresi - Polynomial Regression
Halo, kembali lagi pada materi regression yang membuat gairah belajar Anda menggebu-gebu karena banyak sekali perhitungan dan persamaan matematika. Tentunya sampai, di sini Anda sudah memahami betul cara menangani permasalahan linear, tetapi bagaimana jika Anda dihadapkan dengan data yang tidak memiliki hubungan linear? Nah, jika data yang Anda miliki tidak bersifat linear, regresi polinomial merupakan solusi terbaik yang bisa digunakan.
Regresi linear bekerja dengan mengasumsikan hubungan antara variabel independen X dan variabel dependen Y bersifat linear. Hubungan tersebut dapat direpresentasikan dengan garis lurus pada visualisasi scatter plot. Hal itu akan menjadi sebuah masalah ketika data yang Anda miliki menunjukkan pola non-linear sehingga mengakibatkan linear regression tidak dapat menangkap pola tersebut dengan baik.
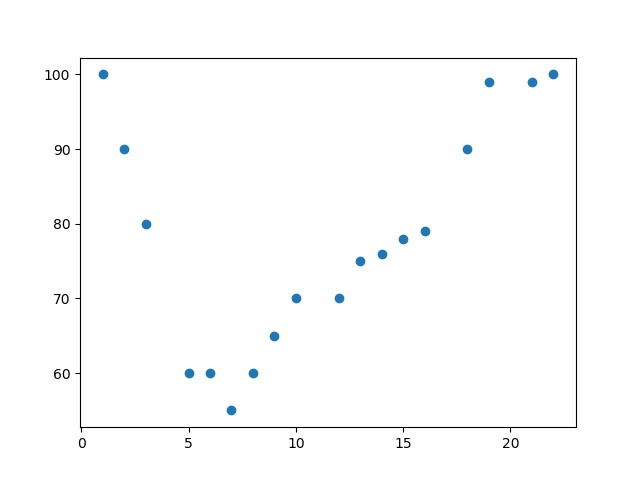
Regresi polinomial adalah bentuk lanjutan dari regresi linear yang digunakan untuk memodelkan hubungan antara variabel independen dan variabel dependen ketika hubungan tersebut tidak dapat dijelaskan dengan garis lurus, tetapi dengan kurva polinomial. Regresi polinomial memungkinkan hubungan antara variabel independen dan dependen untuk berbentuk lebih kompleks, seperti parabola, kurva kubik, atau bentuk polinomial lainnya.
Metode ini akan memperluas konsep regresi linear yang memungkinkan hubungan non-linear antara variabel independen X dan variabel dependen Y dengan menambahkan pangkat atau derajat X. Sehingga, persamaan matematikanya dapat ditulis seperti berikut.
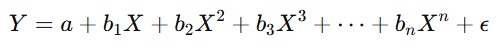
Seperti yang dapat Anda lihat pada persamaan di atas terdapat sebuah perbedaan yaitu nilai X2,X3,…,Xn. Nilai tersebut adalah variabel independen yang telah ditransformasikan menjadi bentuk polinomial.
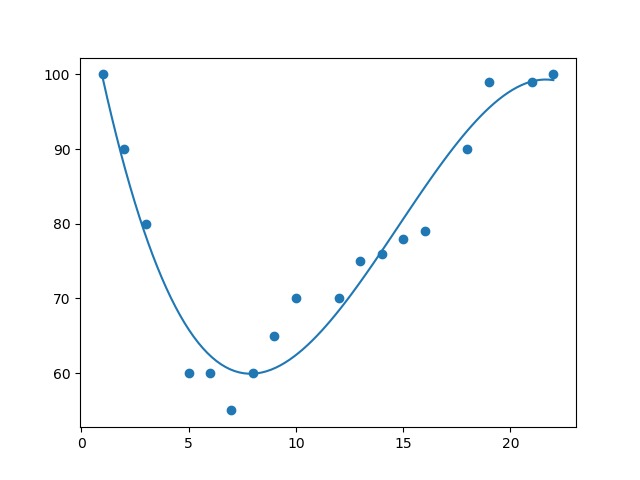
Pada metode ini, Anda juga perlu menentukan jumlah derajat polinomial (n) yang akan digunakan. Memilih derajat n yang tepat adalah langkah penting dalam regresi polinomial. Derajat n akan menentukan kompleksitas model sebagai berikut.
- Derajat rendah (n=1 atau 2): model sederhana yang mungkin tidak cukup untuk menangkap pola kompleks dalam data.
- Derajat tinggi (n ≥ 3): model yang lebih kompleks, mampu menangkap pola yang lebih rumit tetapi dengan risiko overfitting.
Tentunya hukum trade-off tetap berlaku pada proses pemilihan jumlah derajat polinomial yang Anda tentukan. Ada dua hal yang cukup penting ketika Anda menentukan jumlah derajat n, yaitu bias dan varians.
Model dengan derajat rendah mungkin memiliki bias tinggi karena tidak cukup fleksibel untuk menangkap hubungan non-linear. Sedangkan model dengan derajat tinggi mungkin memiliki varians tinggi, yang berarti model sangat sesuai dengan data latih tetapi tidak generalizable terhadap data baru yang dapat menyebabkan overfitting.
Setelah memilih derajat polinomial, variabel independen X akan diubah menjadi bentuk polinomial. Misalnya, jika X adalah luas rumah, dan kita memilih derajat n=3, kita akan memiliki variabel X (luas rumah), X2 (kuadrat dari luas rumah), dan X3 (kubik dari luas rumah).
Karena metode ini merupakan bentuk lanjutan dari linear regression, ada hal yang masih sama yaitu proses pelatihannya. Setelah variabel diubah menjadi bentuk polinomial, model regresi akan dilatih menggunakan metode OLS juga. Tujuannya adalah untuk menemukan koefisien b1,b2,…,bn yang akan meminimalkan jumlah kuadrat dari error (residual) antara nilai yang diprediksi oleh model dan nilai aktual. Bentuk persamaannya akan berubah sedikit (jika dibandingkan dengan regresi linear) menjadi seperti berikut.
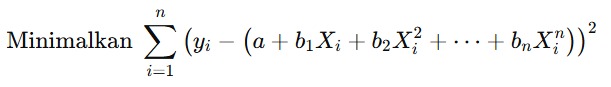
Fungsi OLS akan menentukan nilai optimal dari koefisien a, b1, b2, ..., bn yang meminimalkan nilai error.
Dengan persamaan matematika yang lebih kompleks jika dibandingkan dengan linear regression, bukan berarti semua permasalahan regresi ini dapat diselesaikan oleh polynomial regression. Ada beberapa kekurangan yang perlu diperhatikan ketika Anda memilih untuk menggunakan regresi polinomial.
- Overfitting: semakin tinggi derajat polinomial, semakin besar risiko model menjadi overfit, terutama jika jumlah data yang tersedia terbatas.
- Interpretasi yang Sulit: koefisien pada regresi polinomial tidak se-intuitif regresi linear, terutama untuk polinomial dengan derajat tinggi.
- Ekstrapolasi yang Berbahaya: prediksi di luar rentang data (ekstrapolasi) bisa sangat tidak akurat dengan regresi polinomial, terutama pada derajat tinggi.
Di balik kekurangan pasti ada kelebihan ‘kan? Itu juga berlaku pada konteks machine learning. Berikut beberapa kelebihan dari regresi polinomial ketika permasalahan Anda tidak memiliki karakteristik linear.
- Fleksibilitas Tinggi: mampu menangkap hubungan non-linear antara variabel independen dan dependen.
- Lebih Akurat untuk Hubungan Non-linear: memberikan pelatihan yang lebih baik pada data yang memiliki pola non-linear dibandingkan regresi linear sederhana.
Sampai di sini, Anda sudah memiliki bekal yang cukup untuk mengatasi permasalahan regresi baik itu pada data linear hingga nonlinear. Namun, jangan cepat berpuas diri karena pada modul selanjutnya, kita akan mempelajari beberapa algoritma yang sering digunakan untuk menangani kasus regresi. Penasaran apa bedanya dan bagaimana proses perhitungan masing-masing algoritma regresi? Yuk, kita melangkah bersama agar bisa grow together, sampai jumpa!
Contoh Algoritma Regresi - Decision Tree Regression
Decision Tree Regression adalah salah satu metode dalam machine learning yang digunakan untuk memprediksi nilai kontinu dari variabel dependen berdasarkan variabel independen. Berbeda dengan regresi linear atau polinomial yang berusaha menemukan hubungan matematis linear atau non-linear antara variabel, decision tree regression memprediksi nilai dengan cara mempartisi data ke dalam sub kelompok yang lebih homogen melalui serangkaian keputusan berbasis aturan.
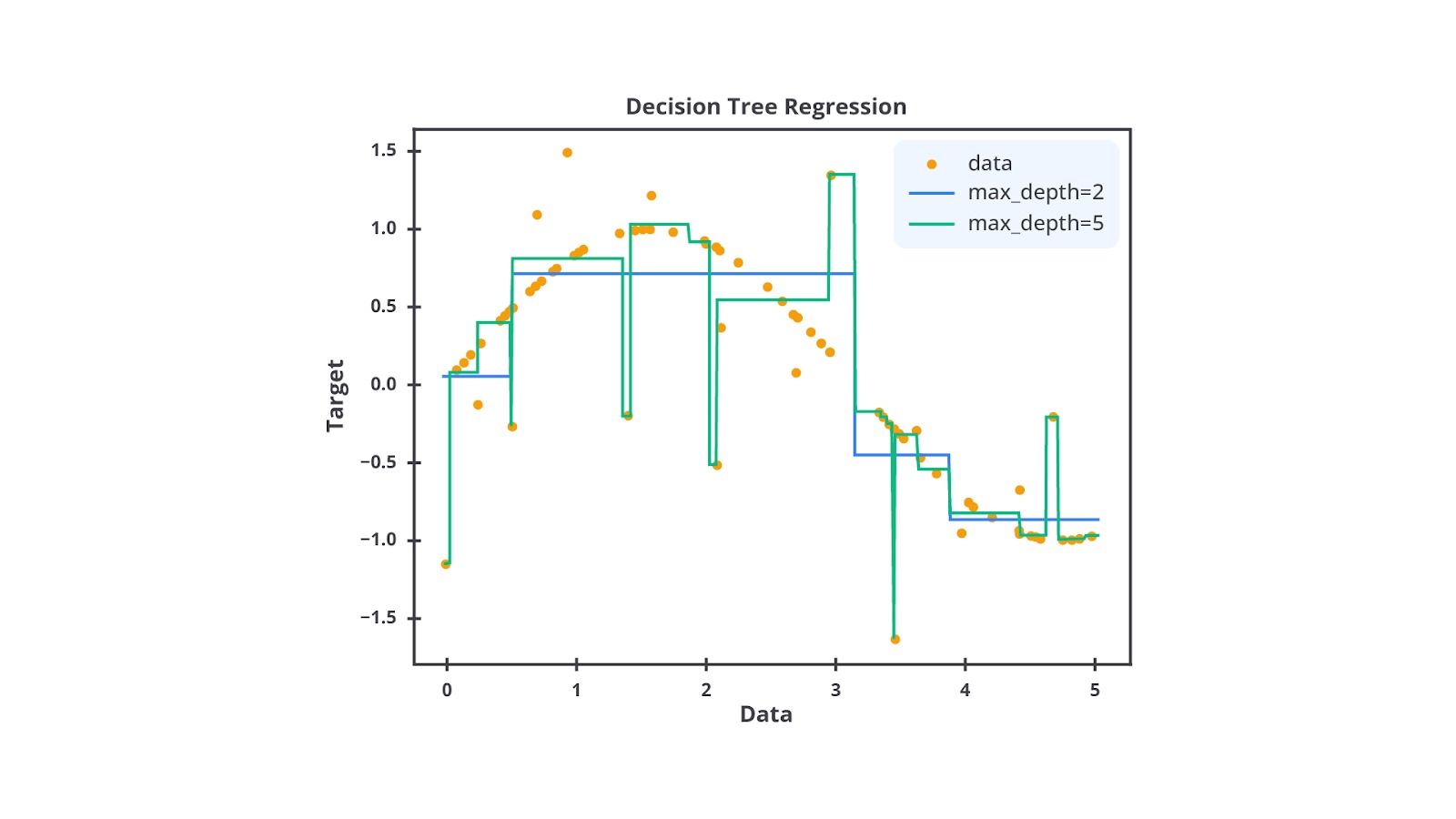
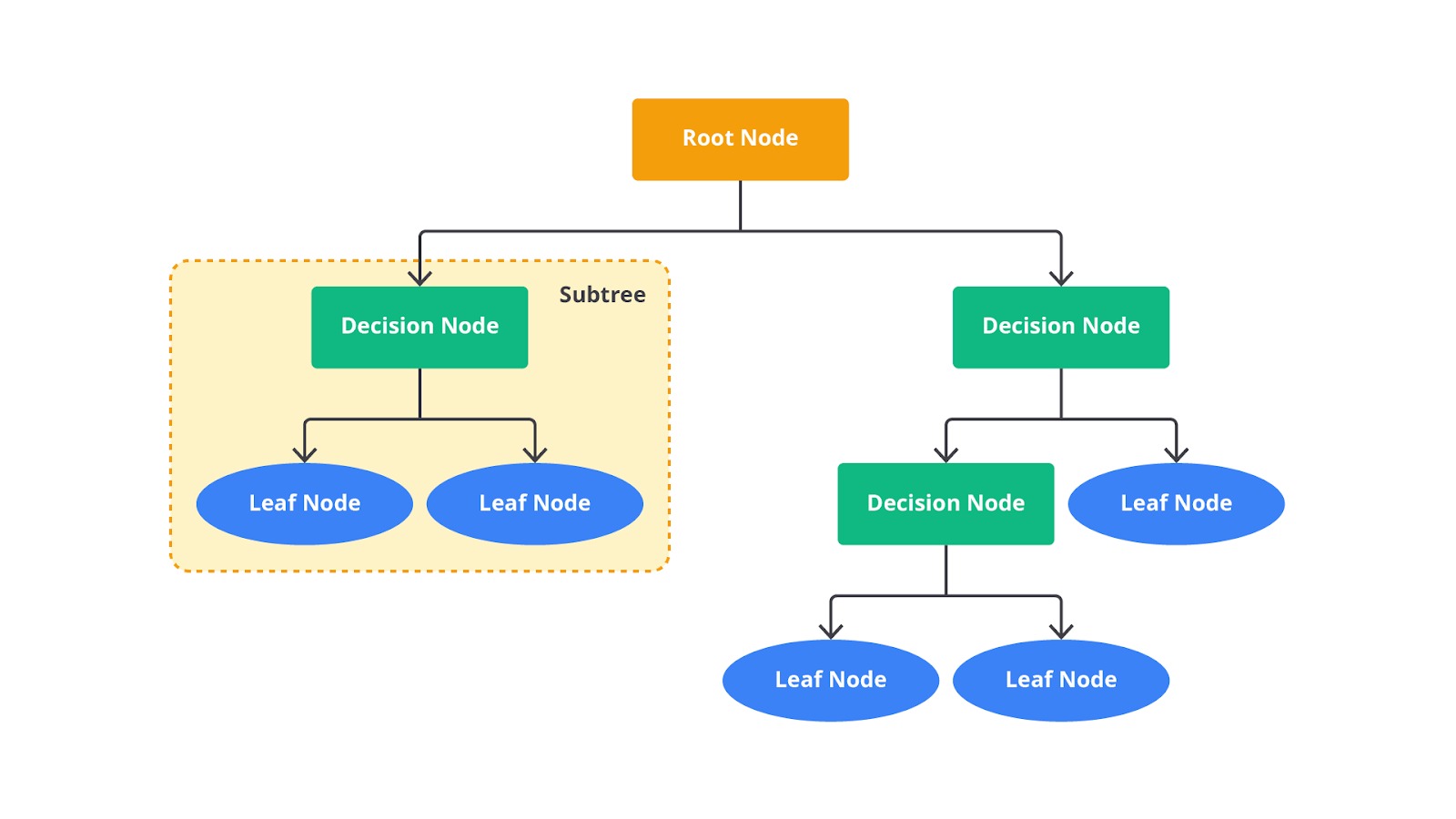
Metode ini menggunakan struktur pohon (tree structure) untuk memecah atau membagi dataset menjadi subset yang lebih kecil dan lebih kecil lagi secara rekursif. Struktur pohon yang dibangun akan memiliki tiga buah komponen yaitu root node , decision nodes, dan leaf nodes. Ketiga komponen tersebut memiliki perannya masing-masing, mari kita bahas satu per satu.
- Root Node: node awal yang mencakup seluruh dataset.
- Decision Nodes: titik percabangan yang membagi dataset berdasarkan kondisi tertentu pada variabel independen.
- Leaf Nodes: node terminal yang menunjukkan hasil prediksi, yaitu nilai yang diprediksi untuk observasi dalam kelompok tersebut.
Setiap cabang dalam pohon mewakili keputusan berdasarkan kondisi yang diterapkan pada satu atau lebih fitur dan setiap leaf nodes memberikan prediksi yang merupakan rata-rata dari nilai target untuk observasi di dalam node tersebut.
Proses yang dilakukan pada metode ini sangatlah mudah, mari kita asumsikan data yang Anda gunakan sudah melewati tahapan data preprocessing dan siap digunakan sehingga kita akan memulai dari perhitungan decision node hingga menjadi leaf node.
Setiap langkah pembagian node pada decision tree akan memilih fitur (variabel independen) yang paling efektif dalam membagi dataset menjadi subset yang lebih homogen. Efektivitas fitur dalam pembagian dinilai menggunakan metrik tertentu, seperti Mean Squared Error (MSE) atau Variance Reduction.
Lalu, bagaimana cara menentukan node pada decision tree? Split yang dipilih merupakan fitur yang memiliki nilai MSE terkecil dalam subset yang dihasilkan. Sebaliknya dengan variance reduction, metode ini memilih pengurangan varians terbesar untuk dijadikan node.
Setelah node terbaik dipilih dan dataset dibagi, proses yang sama diterapkan pada setiap subset yang dihasilkan. Hal ini terus menerus dilakukan secara rekursif hingga kondisi tertentu terpenuhi, seperti mencapai kedalaman maksimum pohon, jumlah minimum sampel dalam node, atau MSE di bawah ambang batas tertentu.
Setelah pohon selesai “dibangun” dan memiliki pola tertentu akhirnya Anda dapat melakukan prediksi. Prediksi untuk setiap data baru dibuat dengan "menjatuhkan" observasi tersebut melalui pohon, mengikuti keputusan di setiap node hingga mencapai leaf node. Nilai yang diprediksi adalah rata-rata dari nilai target untuk semua observasi yang jatuh ke leaf node tersebut.
Pada proses pelatihannya algoritma ini memiliki beberapa hyperparameter penting yang bisa Anda atur sehingga mendapatkan hasil yang maksimal. Berikut adalah beberapa hyperparameter yang dapat mengontrol perilaku dan kinerja model decision tree regression:
- Max Depth: batasan pada kedalaman maksimum pohon. Membatasi kedalaman dapat mencegah overfitting. Artinya, pohon akan menjadi terlalu kompleks dan overfit terhadap data latih.
- Min Samples Split: jumlah minimum sampel yang dibutuhkan untuk membuat split pada node internal. Ini mencegah overfitting yang disebabkan oleh pembagian node yang terlalu kecil.
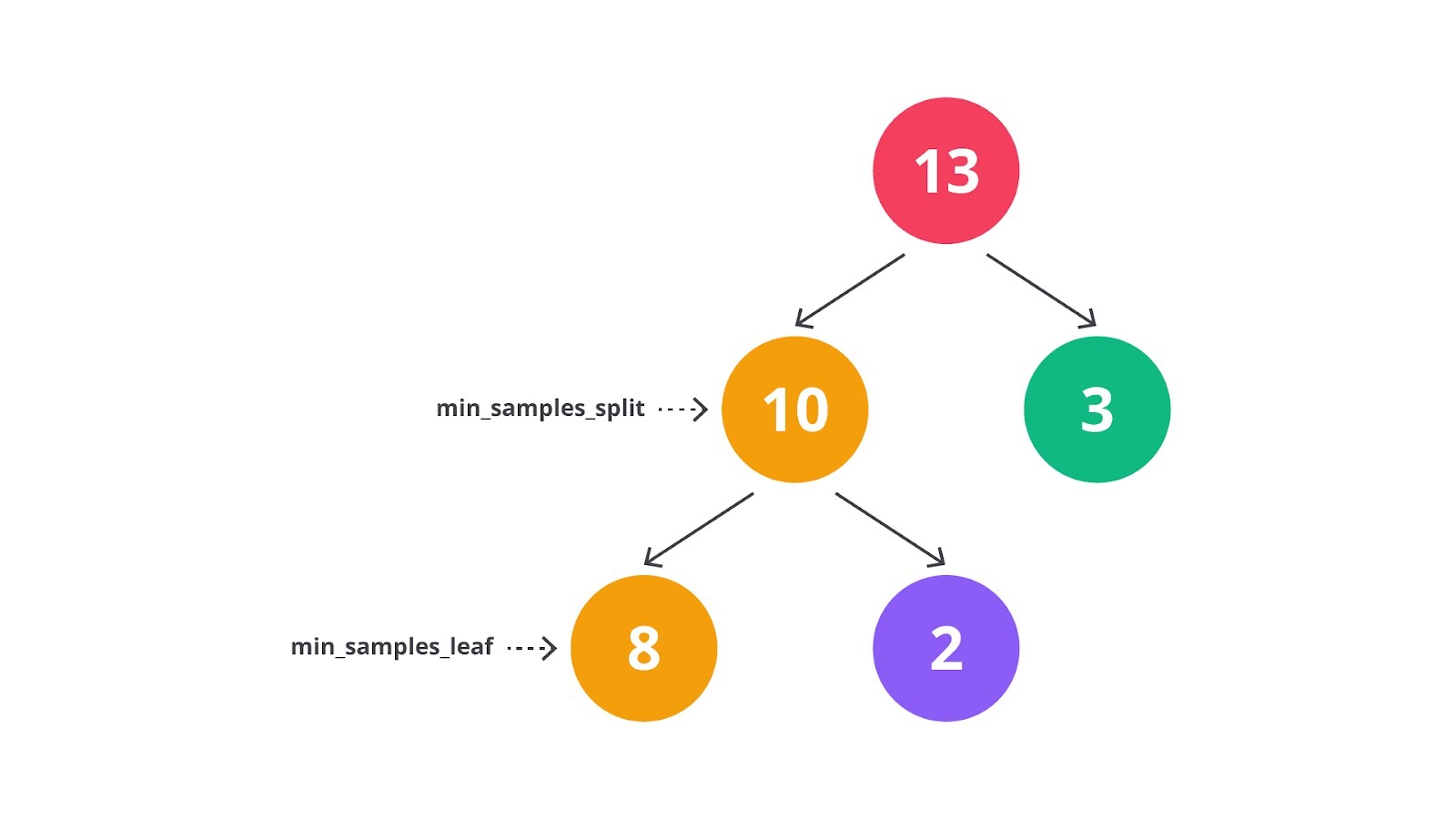
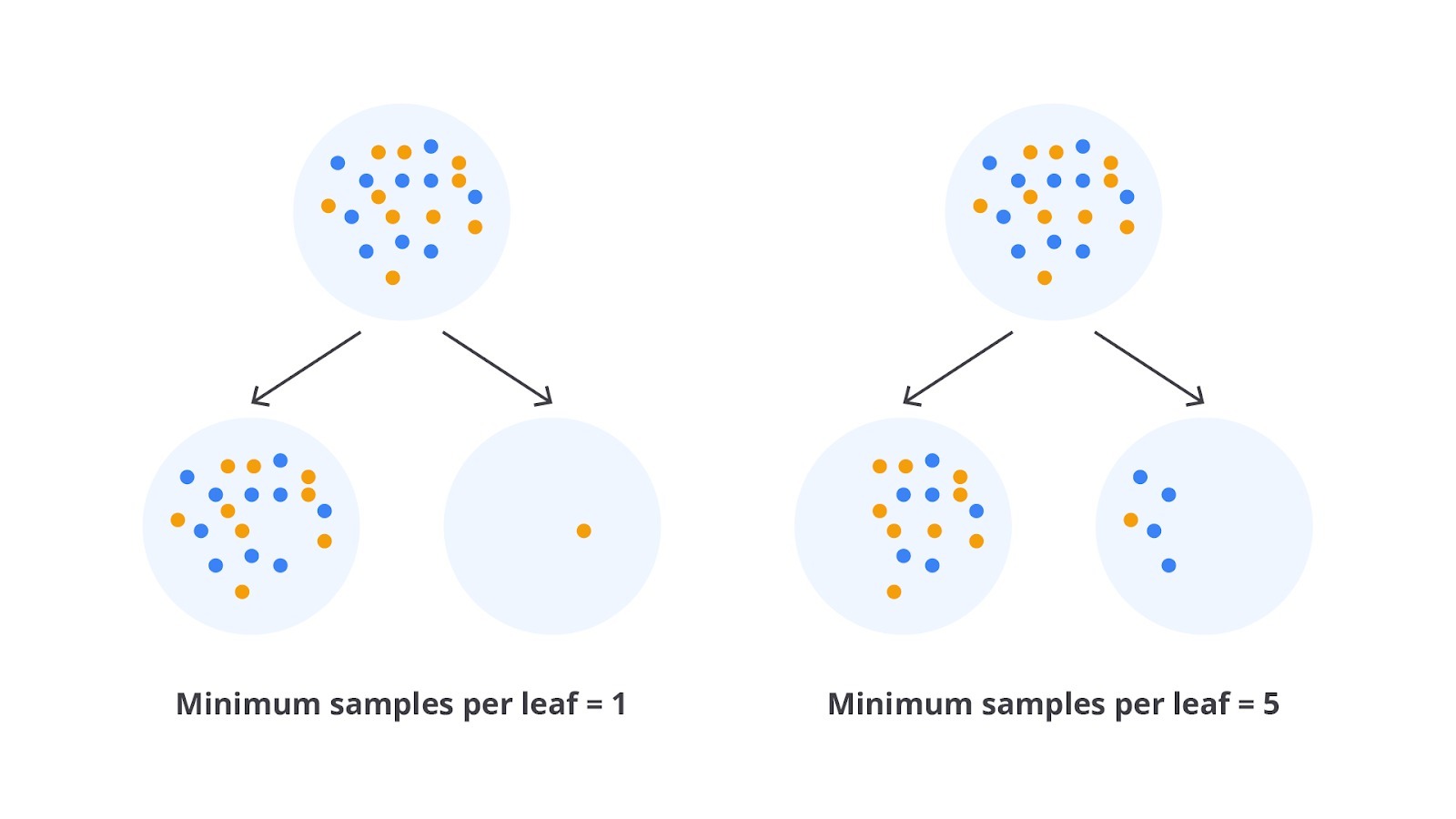
- Min Samples Leaf: jumlah minimum sampel yang dibutuhkan untuk membentuk leaf node. Ini mencegah pembentukan leaf node yang sangat kecil.
- Max Features: jumlah maksimum fitur yang dipertimbangkan untuk split di setiap node.
Di balik kesederhanaan decision tree regression ada banyak kelebihan yang ia miliki mulai dari interpretasi yang mudah dipahami, tidak membutuhkan prasyarat distribusi hingga dapat menangani berbagai macam fitur. Mari kita bahas satu per satu.
- Sederhana dan Mudah Diinterpretasikan: struktur pohon memiliki sifat yang intuitif dan mudah diinterpretasikan. Setiap keputusan dalam pohon dapat dilihat sebagai aturan sederhana yang menjelaskan proses pengolahan prediksi.
- Non-Linear Relationships: decision tree regression secara alami menangkap hubungan non-linear antara variabel independen dan dependen tanpa memerlukan transformasi fitur.
- Tidak Membutuhkan Prasyarat Distribusi: tidak seperti model regresi linear, decision tree regression tidak mengasumsikan hubungan linear atau distribusi tertentu pada data.
- Dapat Menangani Fitur Kategorikal dan Numerik: decision tree regression dapat bekerja dengan baik bersama fitur kategorikal dan numerik, serta mampu menangani data yang hilang dengan baik.
Sama seperti manusia, decision tree tidaklah sempurna. Dari berbagai kelebihannya, metode ini memiliki beberapa kekurangan yang mungkin menjadi pertimbangan bagi Anda. Mari kita bahas secara saksama.
- Overfitting: metode ini cenderung overfit jika tidak diatur dengan benar. Misalnya, tanpa batasan pada kedalaman maksimum atau jumlah sampel minimum. Overfitting menyebabkan model yang sangat sesuai dengan data latih, tetapi memiliki kinerja yang buruk pada data uji.
- Sensitif terhadap Perubahan Data: metode ini sangat sensitif terhadap perubahan kecil dalam data. Perubahan kecil dalam data bisa menghasilkan pohon yang sangat berbeda.
- Weak Learner: meskipun mudah diinterpretasikan, decision tree regression mungkin tidak sekuat model lain seperti ensemble methods (Random Forests dan Gradient Boosting). Namun, pohon tunggal seperti ini sering kali digunakan sebagai komponen dasar dari model ensemble yang lebih kompleks. Jadi, tidak ada salahnya untuk mempelajari dari dasar ‘kan?
Kekurangan yang dimiliki oleh metode ini sebenarnya masih bisa diminimalisasi kembali dengan menggunakan teknik pruning atau ensemble methods. Pruning adalah salah satu cara untuk menghindari overfitting adalah dengan “memangkas” pohon setelah proses pelatihan selesai. Pruning menghapus node yang tidak memberikan banyak informasi, berdasarkan kriteria tertentu seperti MSE. Namun, Ensemble Methods menggabungkan banyak pohon keputusan yang dilatih dan dikombinasikan untuk meningkatkan akurasi prediksi dan mengurangi overfitting.
Contoh Algoritma Regresi - Support Vector Regression (SVR)
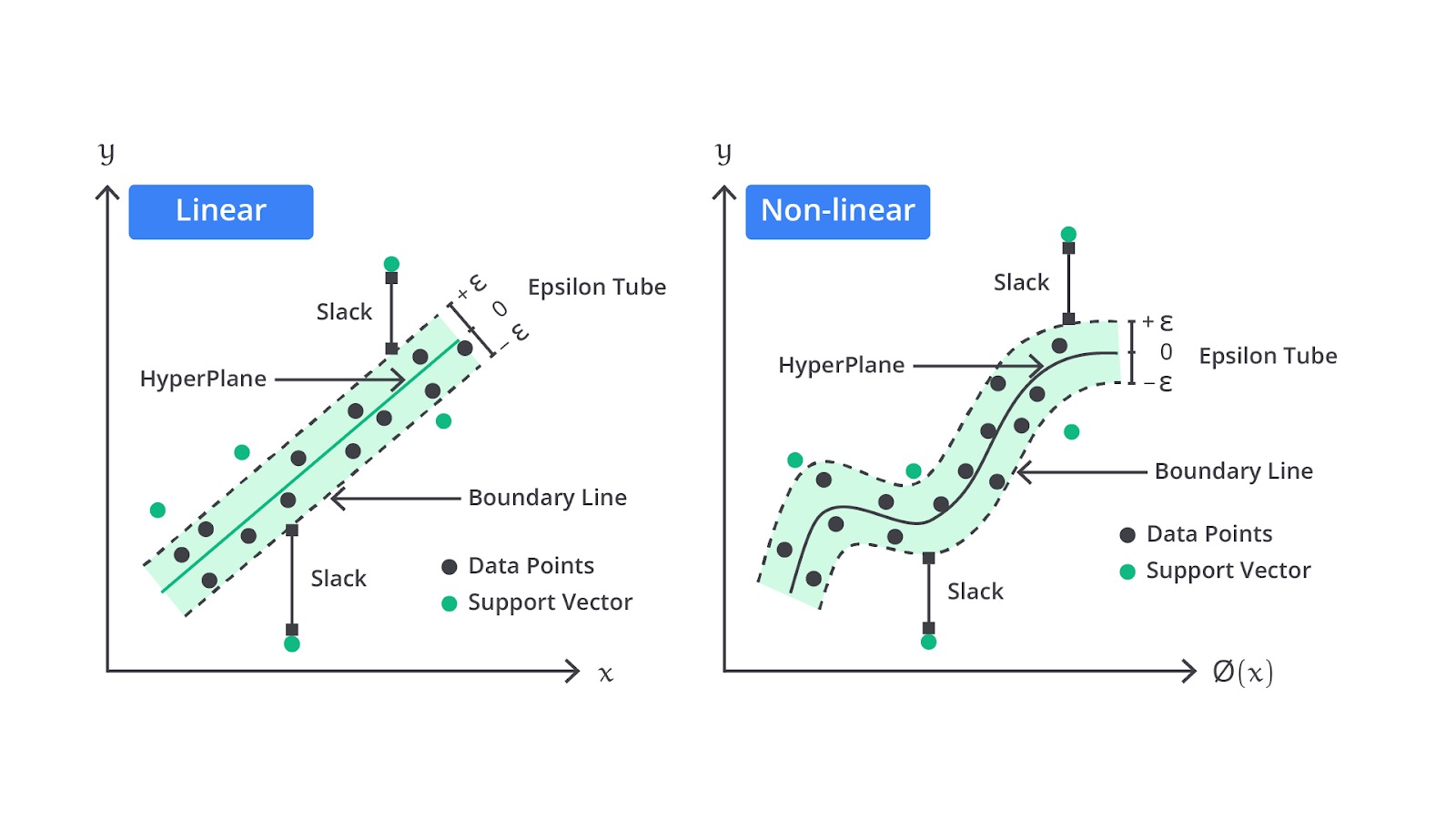
Support Vector Regression (SVR) adalah varian dari Support Vector Machines (SVM) yang digunakan untuk tugas regresi. Berbeda dengan regresi linear yang bertujuan meminimalkan prediksi error secara langsung, SVR mencari hyperplane terbaik yang memaksimalkan margin antara data dengan nilai prediksi dalam sebuah batasan error tertentu yang disebut epsilon-insensitive loss.
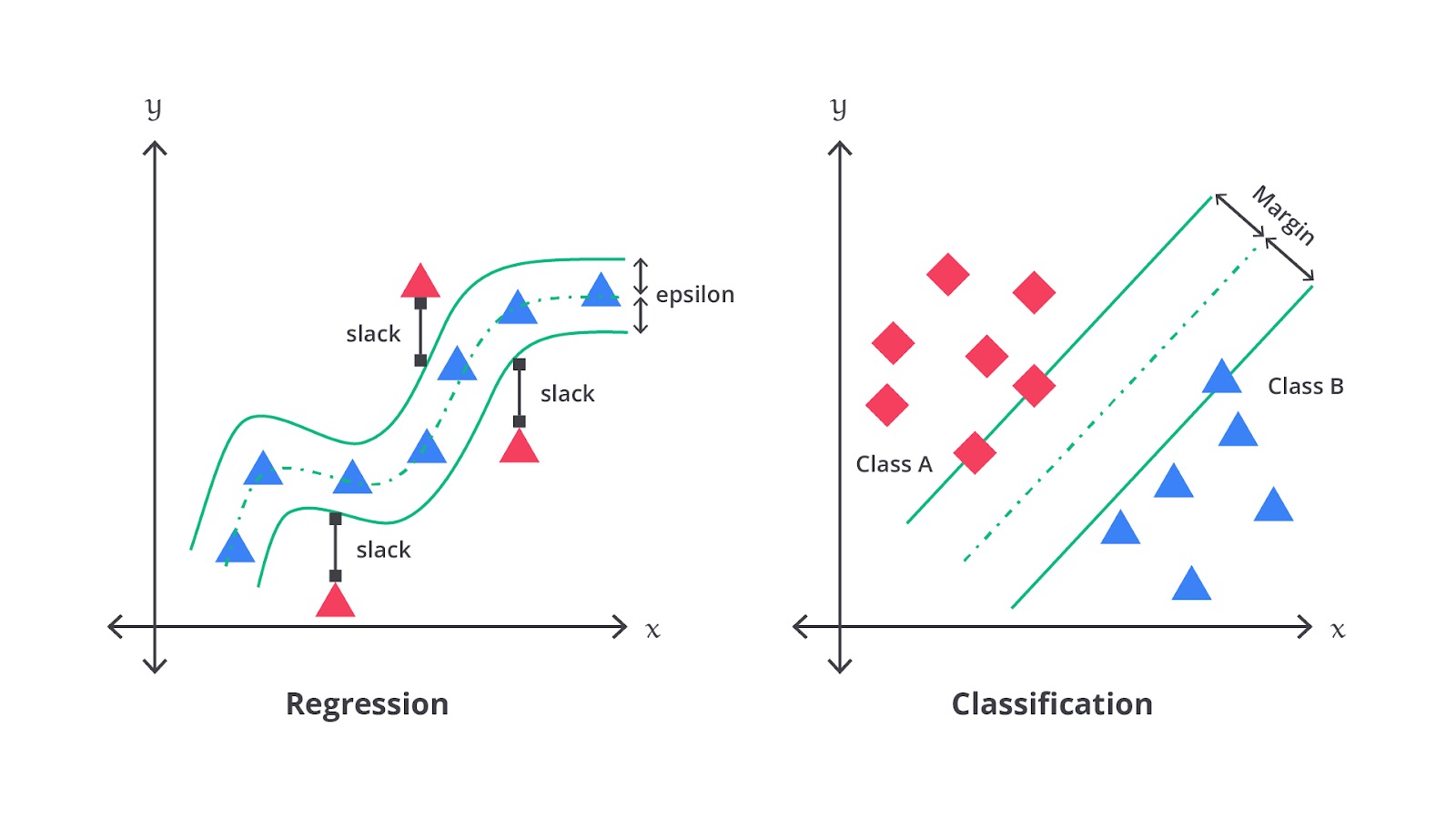
Jika Anda lihat pada gambar di atas sekilas terlihat mirip ‘kan? Walaupun SVR bekerja dengan cara yang mirip dengan SVM untuk klasifikasi tetapi terdapat sebuah perbedaan, alih-alih mencari garis pemisah (hyperplane) antara dua kelas, SVR mencoba menemukan garis atau hyperplane yang memprediksi nilai output dengan margin error yang diizinkan. Dalam SVR, hanya titik-titik data di luar margin error yang berkontribusi dalam menentukan hyperplane atau disebut dengan support vectors.
Dalam konteks SVR, hyperplane adalah fungsi linear yang memprediksi nilai target (variabel dependen) berdasarkan variabel input (variabel independen). Persamaan hyperplane dalam ruang dimensi tinggi dinyatakan sebagai berikut.
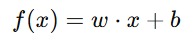
Rumus di atas dapat kita interpretasikan sebagai berikut.
- w adalah vektor bobot.
- x adalah vektor fitur input.
- b adalah bias atau intercept.
SVR secara umum dapat digunakan dalam dua konteks utama yaitu Linear SVR dan Nonlinear SVR, tetapi memiliki varian yang dikenal sebagai Epsilon-Support Vector Regression (ε-SVR). Masing-masing memiliki karakteristik dan penerapan yang berbeda sesuai dengan sifat data dan kebutuhan pemodelan. Penasaran dengan perbedaanya? Yuk, kita bahas bersama-sama.
Linear SVR
Linear SVR adalah bentuk dasar dari Support Vector Regression yang digunakan ketika hubungan antara variabel independen (fitur) dan variabel dependen (target) bersifat linear. Artinya, SVR akan mencari hyperplane linear yang paling sesuai dengan data, di mana prediksi output (target) adalah fungsi linear dari input.
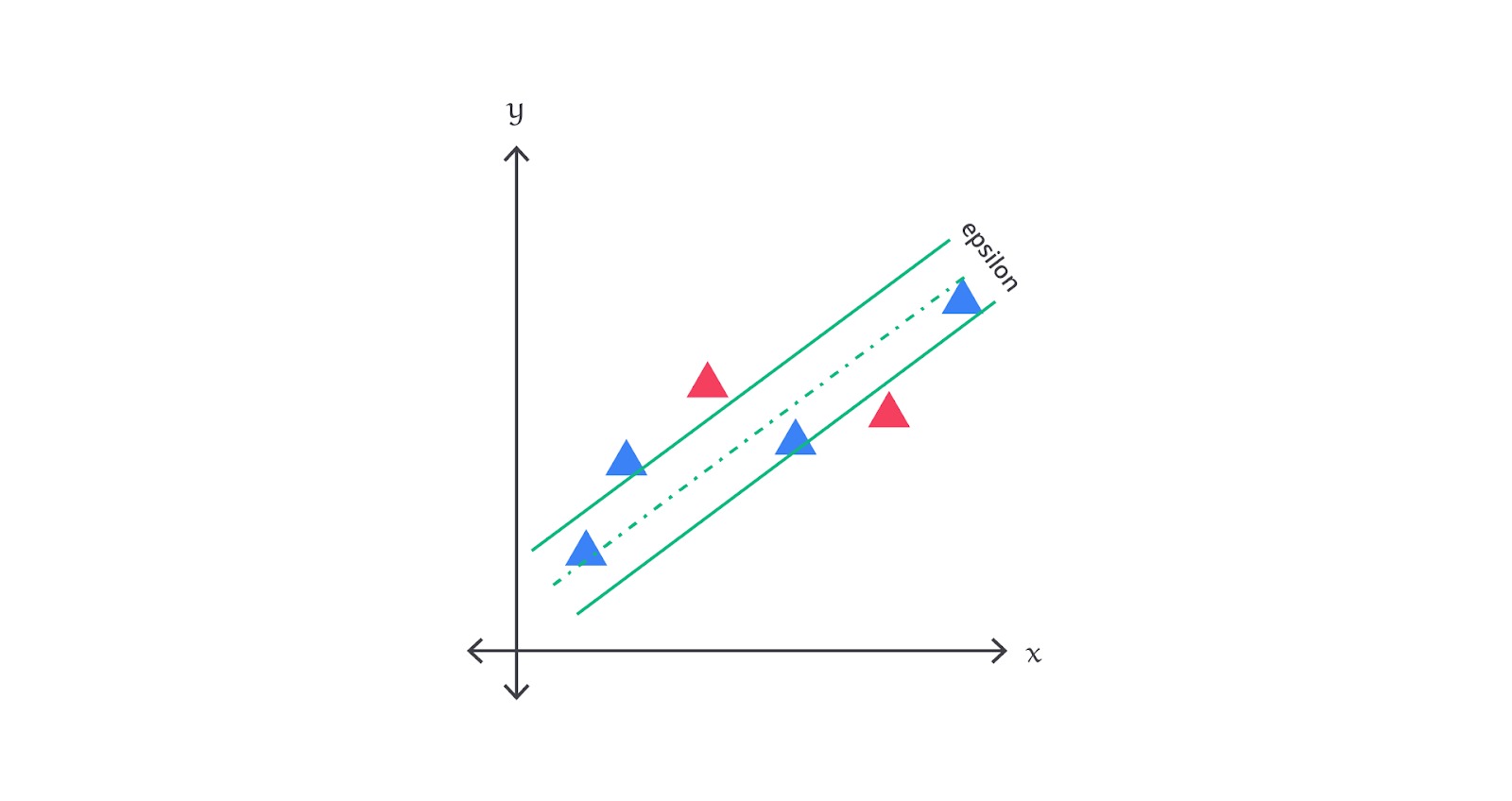
Cara kerja linear SVR kurang lebih seperti berikut.
- Hyperplane: dalam Linear SVR, model mencari hyperplane linear dalam ruang fitur yang dapat memprediksi output dengan margin error yang minimum. Persamaannya seperti berikut.
Rumus di atas dapat kita interpretasikan sebagai berikut.- w adalah vektor bobot yang menunjukkan arah dan orientasi hyperplane.
- x adalah vektor input (fitur).
- b adalah bias atau intercept.
- Margin (ϵ): linear SVR memperkenalkan margin ϵ, yang menentukan batas toleransi error. Data yang berada di dalam margin tidak dikenakan penalti, sementara data yang berada di luar margin dianggap sebagai eror.
- Loss Function: model dioptimalkan dengan meminimalkan fungsi loss yang mencakup margin error (ϵ) dan regularisasi (C) untuk mengontrol kompleksitas model. Hanya data yang berada di luar margin (ϵ) yang berkontribusi terhadap fungsi loss.
Nonlinear SVR
Nonlinear SVR digunakan ketika hubungan antara variabel independen dan dependen bersifat non-linear. Dalam kasus ini, SVR menggunakan kernel trick untuk memetakan data ke ruang dimensi lebih tinggi sehingga hubungan linear dapat ditemukan meskipun hubungan tersebut mungkin memiliki sifat non-linear dalam ruang asli.
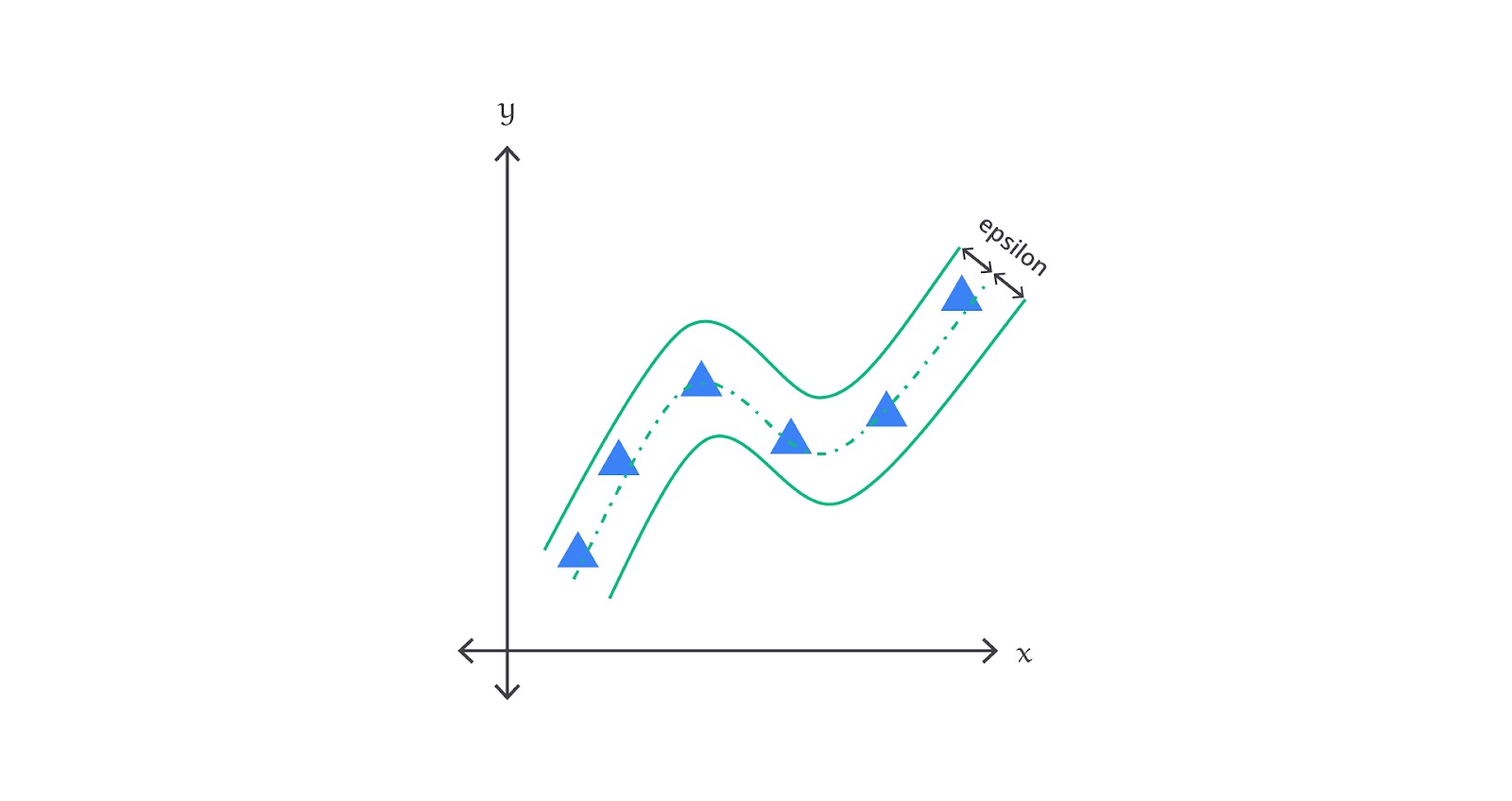
Cara Kerja Nonlinear SVR kurang lebih seperti berikut.
- Kernel Trick: nonlinear SVR menggunakan fungsi kernel untuk memetakan data dari ruang asli ke ruang dimensi yang lebih tinggi. Fungsi kernel memungkinkan SVR untuk menemukan hyperplane linear dalam ruang dimensi tinggi ini tanpa perlu secara eksplisit melakukan transformasi.
Beberapa kernel yang umum digunakan dalam Nonlinear SVR adalah:- Polynomial Kernel: memetakan data ke ruang polinomial yang lebih tinggi dan menangkap hubungan non-linear dengan kurva polinomial.
- Radial Basis Function (RBF) Kernel: kernel Gaussian yang populer karena memetakan data ke ruang dimensi sangat tinggi untuk menangkap hubungan non-linear yang kompleks.
- Support Vectors: hanya titik data yang berada di luar margin ϵ (epsilon) dalam ruang dimensi tinggi yang memengaruhi posisi hyperplane sehingga menjadikannya support vectors.
- Loss Function: sama seperti Linear SVR, tetapi dengan pemetaan kernel yang memungkinkan model menangkap hubungan non-linear.
Epsilon-Support Vector Regression (ε-SVR)
Epsilon-Support Vector Regression (ε-SVR) adalah varian dari SVR yang menekankan penggunaan margin error ϵ dalam fungsi loss. Semua bentuk SVR, baik linear maupun non-linear, bisa dianggap sebagai bentuk ϵ-SVR jika mereka menggunakan margin ϵ untuk menentukan toleransi error.
Tenang dahulu, sampai di sini kita hanya akan membahas konsep kerja epsilon secara singkat.
- Epsilon Margin (ϵ): parameter ϵ menentukan lebar margin di sekitar hyperplane atau kurva prediksi, sehingga prediksi tidak dikenakan penalti jika error berada dalam margin ini. Jika prediksi berada di luar margin ϵ nilai tersebut akan dikenakan penalti dan nilai error dihitung.
- Slack Variables (ξ): untuk data yang berada di luar margin ϵ, slack variables (ξ) digunakan untuk mengukur sejauh mana prediksi berada di luar margin ini. Slack variables memungkinkan beberapa eror berada di luar margin dengan penalti yang dikendalikan oleh parameter C.
- Objective Function: fungsi objektif dalam ε-SVR adalah untuk meminimalkan kombinasi dari error yang berada di luar margin ϵ dan regularisasi terhadap kompleksitas model. Ini memberikan kontrol yang baik atas trade-off antara error pada data latih dan generalisasi model.
Sampai di sini, materi yang perlu Anda ketahui cukup sampai konsep dasar. Jika Anda penasaran dengan perhitungan lebih dalamnya, kami tunggu di kelas Belajar Fundamental Deep Learning, ya!
Eiitss jangan beranjak terlebih dahulu, sebagai materi tambahan untuk Anda yang penasaran dengan materi SVR mari kita tutup dengan kelebihan dan kekurangan dari SVR ini.
Kelebihan:
- Kemampuan Menangani Hubungan Non-Linear: dengan kernel trick, SVR dapat menangkap hubungan non-linear antara fitur dan target.
- Fleksibilitas dengan Parameter: parameter ϵ dan C memberikan fleksibilitas dalam mengontrol error dan kompleksitas model.
- Robust terhadap Outliers: dengan memilih ϵ yang sesuai, SVR dapat menjadi robust terhadap outliers karena hanya eror di luar margin yang dihitung.
Kekurangan:
- Komputasi yang Mahal: SVR, terutama dengan kernel non-linear bisa menjadi sangat mahal secara komputasi, terutama untuk dataset besar.
- Pemilihan Parameter yang Sulit: memilih parameter yang tepat untuk ϵ, C, dan kernel bisa menjadi sulit dan memerlukan tuning yang ekstensif.
- Kurangnya Interpretasi: model SVR, terutama dengan kernel non-linear, kurang intuitif dan lebih sulit diinterpretasikan dibandingkan dengan model regresi linear sederhana.
Bagaimana, mudah ‘kan materinya? Baguslah kalau begitu karena pada materi berikutnya, kita akan mempelajari salah satu bentuk regresi yang lebih seru yaitu neural network regression.
Dari namanya saja sudah menandakan banyak petualangan yang menunggu, tanpa berlama-lama mari kita berangkat!
Contoh Algoritma Regresi - Neural Network Regression
Neural Network Regression adalah salah satu teknik lanjutan machine learning yang digunakan untuk memodelkan dan memprediksi nilai kontinu dari variabel dependen (target) berdasarkan variabel independen (fitur). Neural Network (NN) menggunakan struktur jaringan yang terinspirasi oleh otak manusia yang berarti neuron buatan akan dihubungkan dalam berbagai lapisan untuk memproses dan mengubah input menjadi output.
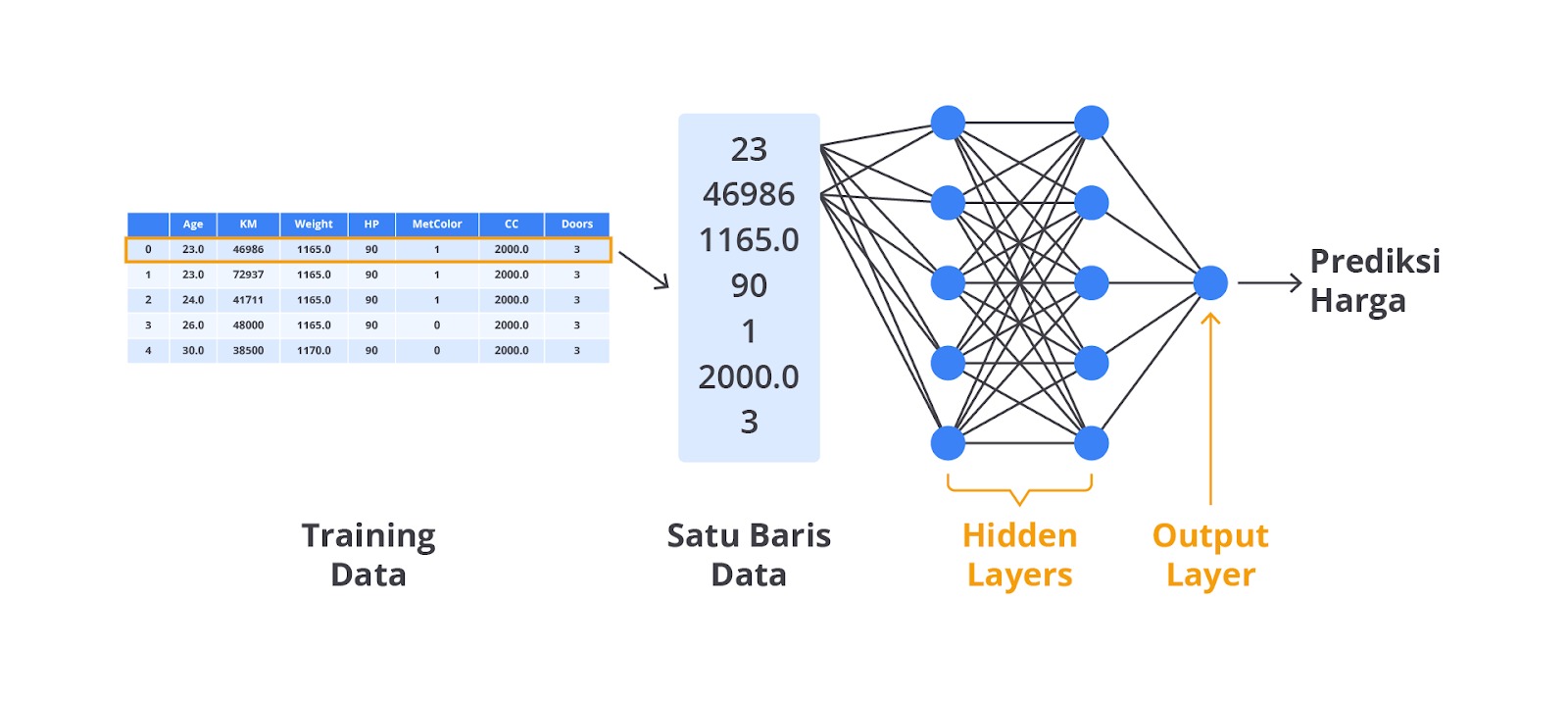
| To be honest, materi ini seharusnya terdapat di materi deep learning. Namun, sebagai calon praktisi machine learning setidaknya Anda mengetahui materi selanjutnya yang akan dipelajari. Pada materi ini, kita tidak akan terlalu jauh bermain-main dengan neural network karena sejatinya materi ini akan Anda pelajari dengan sangat detail dan komprehensif pada kelas Belajar Fundamental Deep Learning. Anggap saja materi ini sebagai sneek peek ya teman-teman! |
Pada dasarnya, Neural Network Regression berfungsi dengan cara yang mirip dengan model regresi tradisional tetapi dengan pendekatan yang jauh lebih fleksibel dan kuat. Neural network dapat menangkap hubungan yang sangat kompleks antara input dan output, termasuk hubungan non-linear yang sulit diidentifikasi oleh model regresi sederhana seperti linear regression.
Dengan keandalan metode ini, untuk menangkap hubungan antara input dan output dari sebuah kasus regresi tentu saja tidak lepas dari arsitektur dasarnya yang sangat powerfull. By default satu buah neuron akan memiliki arsitektur yang meliputi input, bias, weight, activation function, dan output.
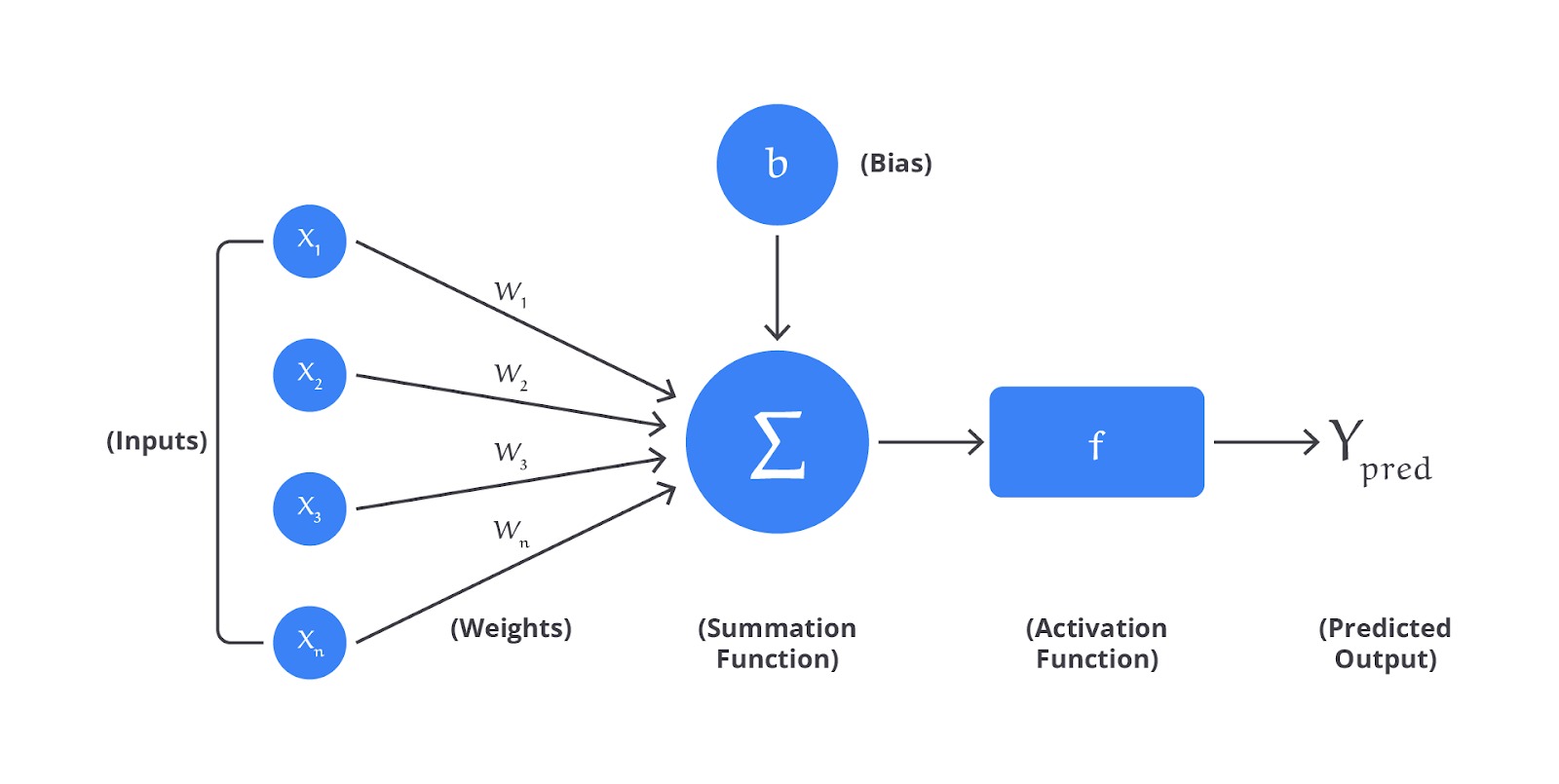
“Hah, apa artinya semua istilah itu?” Mari kita bahas sedikit pada materi ini.
- Neuron: unit dasar dari neural network adalah neuron buatan, yang juga disebut sebagai node atau unit. Setiap neuron menerima satu atau lebih input, memproses input tersebut, dan menghasilkan output yang diteruskan ke neuron berikutnya.
- Lapisan (Layers):satu arsitektur neural network setidaknya terdiri dari tiga jenis lapisan yaitu input layer, hidden layer, dan output layer. Ketiganya memiliki peran yang berbeda-beda, berikut penjelasan singkat dari masing-masing layer.
- Input Layer: lapisan pertama yang menerima input dari data. Setiap neuron dalam lapisan ini mewakili satu fitur dari data input.
- Hidden Layers: lapisan-lapisan di antara input dan output yang memproses input menggunakan bobot dan fungsi aktivasi. Neural network bisa memiliki satu atau lebih hidden layers, dan semakin banyak hidden layers yang dimiliki, semakin dalam jaringan tersebut.
- Output Layer: lapisan terakhir yang menghasilkan output dari network yang dibangun, dalam kasus regresi output ini adalah nilai kontinu yang diprediksi.
- Bobot (Weights): setiap koneksi antara neuron memiliki bobot, yang menentukan seberapa besar pengaruh input tertentu terhadap output neuron. Bobot ini diubah selama pelatihan untuk meminimalkan error prediksi.
- Bias: bias adalah nilai tambahan yang membantu model menangkap pola yang lebih kompleks. Bias ditambahkan ke input neuron sebelum melewati fungsi aktivasi.
- Fungsi Aktivasi (Activation Function): fungsi aktivasi mengubah input ke neuron menjadi output non-linear. Beberapa fungsi aktivasi yang umum digunakan dalam neural network regression termasuk ReLU (Rectified Linear Unit), Sigmoid, dan Tanh.
Penjelasan di atas merupakan bekal Anda untuk memperdalam materi tentang deep learning pada kelas berikutnya. Sampai di sini, bekal materi di atas akan menjadi sangat berarti ketika Anda memulai kelas berikutnya. Agar tetap semangat melanjutkan kelas berikutnya, mari kita bahas kelebihan neural network regression ini sebagai pemantik rasa penasaran.
Neural network atau bagian dari deep learning ini memiliki kelebihan yang sangat menguntungkan, dalam konteks regresi neural network dapat menangkap hubungan non-linear yang kompleks antara input dan output. Di lain sisi, neural network dapat digunakan untuk berbagai jenis data dan masalah, termasuk data yang besar dan beragam (bahkan unstructured data loh). Dan salah satu kelebihan yang dapat di highlight adalah kemampuan generalisasi.
Bagaikan pisau bermata dua, tentunya tidak semua permasalahan yang diselesaikan oleh neural network akan memberikan hasil yang lebih baik karena selain performa Anda juga perlu memperhatikan parameter lainnya seperti harga, waktu, dan kesulitan.
Neural network terutama deep learning, memerlukan komputasi yang intensif dan waktu pelatihan yang lama hal ini menjadi penting ketika Anda bekerja di sebuah perusahaan startup. Dengan harga dan waktu yang cukup besar neural network juga rentan terhadap overfitting jika tidak diatur dengan baik, terutama dengan jumlah parameter yang besar. Dan yang terakhir, neural network sering dianggap sebagai "black box" karena sulit untuk diinterpretasikan dibandingkan dengan model yang lebih sederhana seperti linear regression.
Dengan beragam kelebihan dan kekurangan dari neural network regression tentunya Anda sudah dapat menentukan metode yang tepat untuk menyelesaikan permasalahan yang akan dihadapi. Oiya, sebagai catatan walaupun neural network ini merupakan metode yang powerfull dan dapat menyelesaikan permasalahan yang lebih kompleks bukan berarti metode ini menjadi solusi all in one ya. Karena selain performa, ada beberapa hal yang nantinya akan menjadi pertimbangan Anda dalam membangun model machine learning, seperti waktu, biaya, dan usaha.
Ngomong-ngomong all in one method, pernahkah Anda mendengar kutipan seperti "kita tidak perlu menggunakan palu besar untuk memukul paku kecil" atau "jangan gunakan meriam untuk membunuh lalat"? Gagasan tersebut memiliki arti bahwa kita tidak perlu menggunakan alat yang terlalu kuat atau kompleks untuk menyelesaikan masalah yang sederhana.
Kutipan-kutipan semacam itu mengandung pesan bahwa penggunaan sesuatu yang lebih sederhana dan lebih sesuai dengan konteks dapat sama efektifnya, atau bahkan lebih efisien, daripada menggunakan solusi yang berlebihan atau berdaya terlalu besar.
Yup, permasalahan di atas juga sangat relevan pada konteks machine learning. Karena at the end of the day, Anda ditugaskan untuk menyelesaikan masalah dengan efisien, baik itu dalam segi kemampuan (performa), biaya, usaha, bahkan hingga maintenance.
Dengan perkembangan AI yang sangat pesat hingga saat ini, deep learning tentunya dapat menyelesaikan permasalahan dengan lebih baik. Bahkan dengan hadirnya Generative AI, permasalahan regresi, klasifikasi, sentimen analisis dan lain sebagainya dapat diselesaikan dengan model yang sama. Apa itu Generative AI dan mengapa sangat powerful? Tenang-tenang, kita juga akan mempelajari materi tersebut di kelas selanjutnya ya.

Walaupun Generative AI memiliki berbagai macam kemampuan, tetapi hal itu bukanlah pilihan yang bijak ketika Anda hanya ingin melakukan klasifikasi atau regresi sederhana. “You don't need a sledgehammer to crack a nut.” Yang berarti dengan model machine learning sederhana Anda dapat menyelesaikan permasalahan tersebut dengan lebih tepat, murah, fleksibel, dan tidak mubazir sumber daya.
Huftt, bagaimana perjalanan yang Anda lalui sangat menyenangkan ‘kan? Pada materi ini, Anda bertemu dengan istilah baru seperti deep learning dan generative AI. Tentunya kita belum membahas keduanya dengan sangat detail karena ini merupakan awal perjalanan Anda.
Setelah mempelajari berbagai metode regresi tentunya Anda sudah bisa menentukan metode yang paling cocok untuk permasalahan Anda kelak. Namun, sebenarnya di luar materi kelas ini, masih terdapat banyak sekali metode atau algoritma baik itu untuk klasifikasi atau regresi. Dengan perkembangan yang sangat cepat, kami menyarankan Anda tetap melakukan eksplorasi secara mandiri. Karena sebaik-baiknya materi, akan jauh lebih baik jika itu didorong dari diri kita sendiri.
Pada materi berikutnya, kita akan mempelajari teknik evaluasi pada permasalahan regresi. Hal ini akan membantu untuk mengetahui performa model yang dibangun sehingga nantinya Anda dapat menentukan metode mana yang akan digunakan untuk menyelesaikan permasalahan yang ada.
Evaluasi Model Regresi
Evaluasi model regresi adalah langkah penting dalam proses membangun model prediksi. Dengan evaluasi yang baik, kita bisa mengetahui seberapa akurat model dalam memprediksi data yang belum pernah dilihat. Untuk membantu siswa pemula memahami proses ini, kami akan menjelaskan konsep dasar, metrik evaluasi utama, dan cara menginterpretasinya.
Setelah membangun model, penting untuk mengevaluasi seberapa baik model tersebut bekerja. Evaluasi ini membantu kita untuk memahami seberapa akurat prediksi model, mengetahui jika model terlalu rumit atau terlalu sederhana, dan memastikan bahwa model tidak hanya baik pada data latihan tetapi juga pada data baru.
Mari kita membahas evaluasi model regresi dengan lebih detail menggunakan contoh perhitungan pada kasus jual beli rumah. Dalam kasus ini, kita akan menggunakan fitur luas rumah (dalam meter persegi) untuk memprediksi harga rumah (dalam juta Rupiah).
Misalkan kita memiliki data berikut.
Luas Rumah (m²) | Harga Rumah (asli) (juta Rupiah) |
|---|---|
50 | 100 |
60 | 150 |
70 | 200 |
80 | 250 |
90 | 300 |
Kita ingin membangun model regresi sederhana yang memprediksi harga rumah berdasarkan luas rumah. Katakanlah setelah melatih model, kita mendapatkan persamaan regresi sebagai berikut.
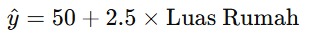
Kita akan menghitung prediksi harga rumah untuk masing-masing luas rumah yang ada di dataset sehingga jika divisualisasikan hasilnya akan seperti berikut.
Luas Rumah (m²) | Harga Rumah (asli) (juta Rupiah) | Harga Prediksi (juta Rupiah) | Selisih (juta Rupiah) |
|---|---|---|---|
50 | 100 | ŷ = 50 + 2.5 × 50 = 175 | -75 |
60 | 150 | ŷ = 50 + 2.5 × 60 = 200 | -50 |
70 | 200 | ŷ = 50 + 2.5 × 70 = 225 | -25 |
80 | 250 | ŷ = 50 + 2.5 × 80 = 250 | 0 |
90 | 300 | ŷ = 50 + 2.5 × 90 = 275 | 25 |
Jika Anda perhatikan kolom selisih pada tabel di atas, kita sudah menemukan nilai selisih hanya dengan mengurangi harga prediksi dengan harga asli, mudah sekali ‘kan? Menghitung selisih antara nilai aktual dan prediksi memang merupakan langkah dasar dalam evaluasi model regresi, tetapi ada beberapa alasan mengapa kita tidak cukup hanya menghitung selisih tersebut secara langsung tanpa menggunakan metrik lain.
Jika hanya menghitung selisih antara nilai aktual dan nilai prediksi, kita akan mendapatkan serangkaian nilai selisih (residual) dengan nilai positif atau negatif. Selisih ini bisa membantu kita melihat performa model overestimate (terlalu tinggi) atau underestimate (terlalu rendah), tetapi mereka tidak memberikan gambaran yang jelas tentang performa keseluruhan model.
Perhatikan data terakhir pada tabel di atas yang memiliki nilai selisih -25, nilai selisih ini bisa saling membingungkan ketika kita menghitung rata-rata dan memberi kesan bahwa tidak ada kesalahan. Namun, jelas bahwa model tidak akurat dalam kedua prediksi tersebut karena terdapat selisih positif dan negatif.
Solusi dari permasalahan di atas kita dapat menggunakan perhitungan metriks yang lebih andal. Beberapa contoh nya dengan menggunakan nilai absolut seperti pada MAE atau kuadrat dari selisih seperti pada MSE kita memastikan bahwa semua kesalahan diperhitungkan secara positif sehingga kesalahan besar tidak terabaikan.
Tahukah Anda walaupun regresi dan klasifikasi memiliki induk yang sama yaitu supervised learning, tetapi mereka memiliki metriks evaluasi yang berbeda.
Hayoo, apakah Anda masih ingat dengan metriks evaluasi pada kasus klasifikasi di modul sebelumnya atau sedikit lupa karena terlalu asyik dengan materi di modul ini? Tenang, mari kita lihat perbedaannya melalui diagram berikut.
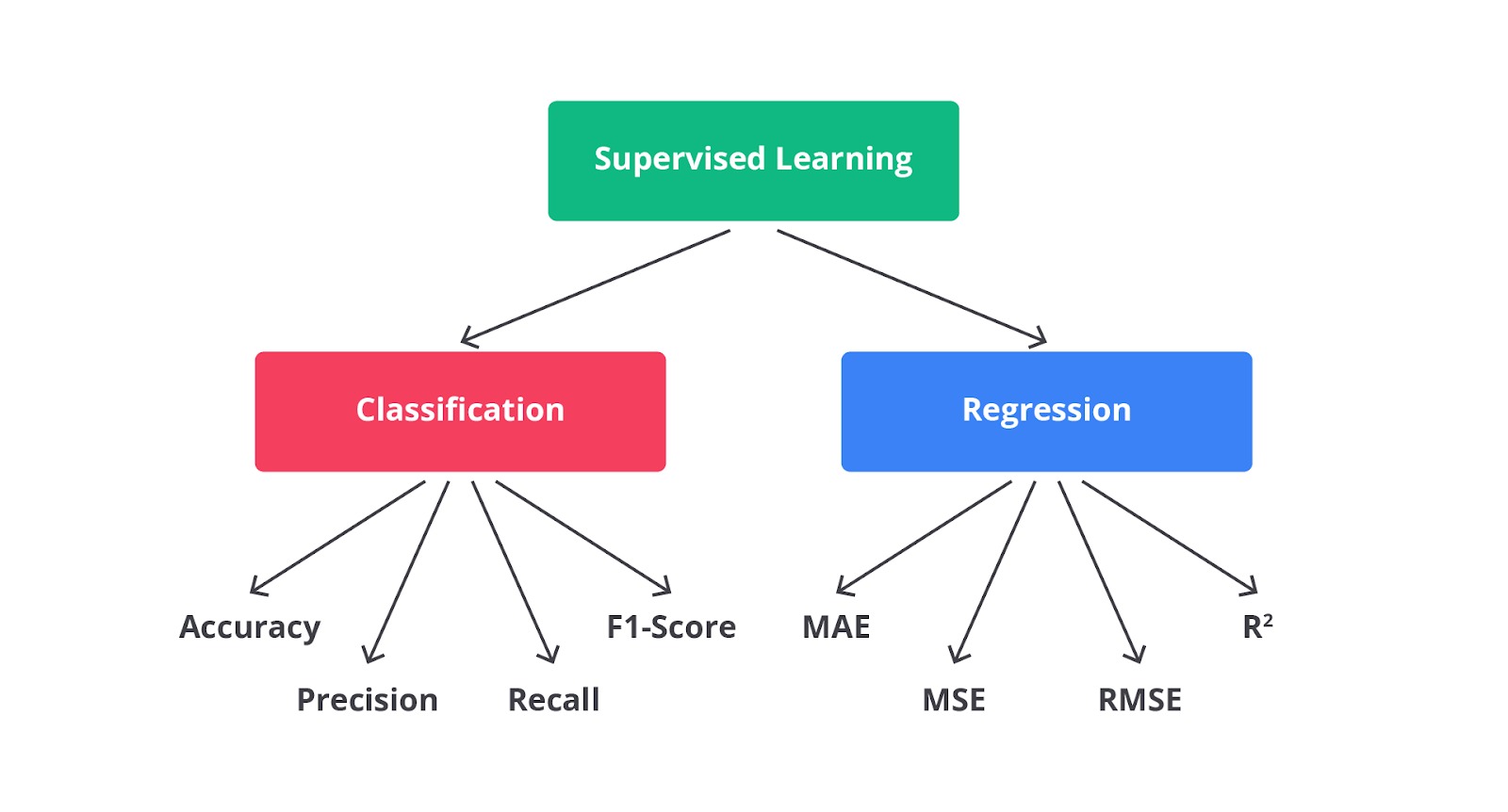
Serupa tapi tak sama, begitulah kira-kira yang bisa kita pelajari bersama untuk klasifikasi dan regresi. Kesamaan dari keduanya adalah harus memiliki fitur atau variabel target sebagai jawabannya, tetapi memiliki output yang sangat berbeda.
Setelah Anda memahami proses evaluasi pada kasus klasifikasi, sekarang saatnya kita melangkah sedikit lebih jauh untuk mencoba memahami proses evaluasi pada kasus regresi.
Secara umum ada empat dasar metriks evaluasi yang biasa digunakan dalam kasus regresi yaitu MAE, MSE, RMSE, dan R2. Namun, di luar metriks tersebut ada banyak metriks lainnya baik itu turunan dari keempat metode yang sudah disebutkan atau perhitungan yang lainnya.
Pada penjelasan ini, kita akan mempelajari metrics dasar terlebih dahulu hingga Anda memahami sepenuhnya dasar dari proses evaluasi regresi.
Mean Absolute Error (MAE)
MAE adalah rata-rata dari kesalahan dengan nilai absolut antara nilai sebenarnya dan nilai prediksi.
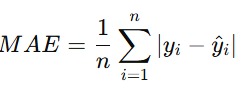
Mari kita hitung untuk setiap titik data yang ada pada tabel perhitungan yang sudah kita buat di awal materi ini.
| Luas Rumah (m2) | Harga Rumah (asli) (juta Rupiah) | Harga Prediksi (juta Rupiah) | Selisih MAE |
|---|---|---|---|
50 | 100 | ŷ = 50 + 2.5 × 50 = 175 | ∣100 − 175∣ = 75 |
60 | 150 | ŷ = 50 + 2.5 × 60 = 200 | ∣150 − 200∣ = 50 |
70 | 200 | ŷ = 50 + 2.5 × 70 = 225 | ∣200 − 225∣ = 25 |
80 | 250 | ŷ = 50 + 2.5 × 80 = 250 | ∣250 − 250∣ = 0 |
90 | 300 | ŷ = 50 + 2.5 × 90 = 275 | ∣300 − 275∣ = 25 |
Terlihat jelas ‘kan perbedaannya dengan selisih awal tanpa menggunakan metode apa pun? Hasil akhirnya akan membuat model lebih bagus karena dengan menggunakan MAE Anda akan mendapatkan nilai error seperti berikut.
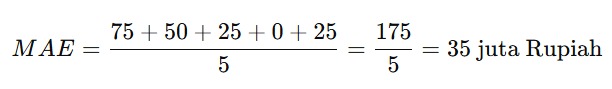
Mean Squared Error (MSE)
MSE adalah nilai rata-rata dari kuadrat kesalahan antara nilai sebenarnya dan nilai prediksi. MSE dapat digambarkan dengan rumus matematika seperti berikut.
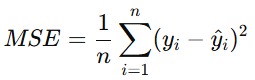
Mari kita hitung untuk setiap titik data yang ada pada tabel perhitungan yang sudah kita buat di awal materi ini.
| Luas Rumah (m2) | Harga Rumah (asli) (juta Rupiah) | Harga Prediksi (juta Rupiah) | Selisih MSE |
|---|---|---|---|
50 | 100 | ŷ = 50 + 2.5 × 50 = 175 | (100−175)2 = (-75)2 = 5625 |
60 | 150 | ŷ = 50 + 2.5 × 60 = 200 | (150 − 200)2 = (-50)2 = 2500 |
70 | 200 | ŷ = 50 + 2.5 × 70 = 225 | (200 − 225)2 = (-25)2 = 625 |
80 | 250 | ŷ = 50 + 2.5 × 80 = 250 | (250 − 250)2 = 02 = 0 |
90 | 300 | ŷ = 50 + 2.5 × 90 = 275 | (300 − 275)2 = 252 = 625 |
Dengan perhitungan di atas, Anda akan mendapatkan nilai MSE seperti berikut.
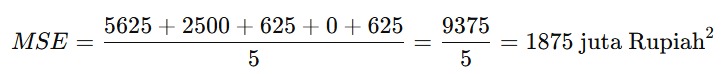
Root Mean Squared Error (RMSE)
RMSE adalah akar kuadrat dari MSE. Ini mengembalikan kesalahan ke dalam satuan yang sama dengan data sehingga lebih mudah diinterpretasikan. Karena Anda sudah melakukan perhitungan MSE, pada kesempatan kali ini, kita hanya perlu melanjutkannya sehingga hasilnya akan menjadi seperti berikut.
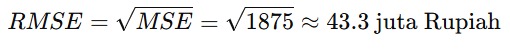
R-squared (R²)
R-squared juga dikenal sebagai coefficient of determination adalah salah satu metrik yang digunakan untuk mengevaluasi seberapa baik model regresi linear menjelaskan variasi dalam data. R-squared memberikan ukuran proporsi variasi dalam variabel dependen (output) yang dapat dijelaskan oleh variabel independen (input) dalam model.
R-squared dihitung dengan menggunakan perbandingan antara variasi total dalam data dan variasi yang dapat dijelaskan oleh model regresi. Secara matematis, R-squared dapat ditulis sebagai berikut.
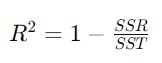
Rumus di atas dapat kita interpretasikan sebagai berikut.
- SSR (Sum of Squared Residuals) adalah jumlah kuadrat dari selisih antara nilai observasi dengan nilai prediksi model. Ini adalah kesalahan yang dibuat oleh model.
- SST (Total Sum of Squares) adalah jumlah kuadrat dari selisih antara nilai observasi dengan rata-rata nilai observasi. Ini mengukur variasi total dalam data.
Sehingga, jika kita jabarkan rumus matematis untuk R2 dapat ditulis sebagai berikut.
Langkah pertama yang perlu Anda lakukan adalah menghitung ȳ yang merupakan rata-rata dari harga rumah aktual.
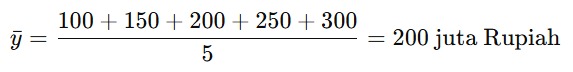
Lalu, kita hitung jumlah kuadrat total untuk nilai SST dengan rumus nilai aktual dikurangi nilai ȳ.
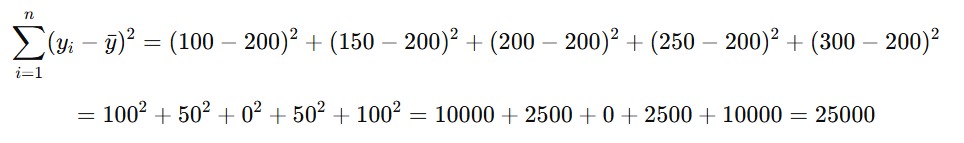
Sehingga, nilai SST pada kasus ini adalah 25000. Lalu, bagaimana dengan nilai SSR? Nilai SSR didapat dari nilai aktual dikurangi nilai prediksi lalu dikuadratkan. Sehingga, jika kita hitung berdasarkan tabel di atas akan menghasilkan perhitungan seperti berikut.
Nah setelah kedua parameter terpenuhi Anda bisa langsung menghitung nilai R2 dengan memasukkan nilai SSR dan SST yang sudah dihitung sehingga hasil akhirnya akan mendapatkan nilai R2 seperti berikut.
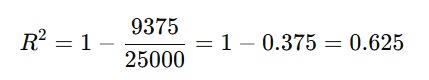
Sampai di sini, mungkin Anda masih meraba-raba interpretasi dari masing-masing evaluasi ‘kan? Sini kita jelaskan sekali lagi agar Anda bisa memahaminya dengan lebih baik.
- MAE = 35 juta Rupiah berarti rata-rata prediksi kita meleset sebesar 35 juta Rupiah dari harga sebenarnya.
- MSE = 1875 juta Rupiah² ini menunjukkan bahwa ada beberapa prediksi yang cukup jauh dari nilai sebenarnya.
- RMSE ≈ 43.3 juta Rupiah yang berarti kesalahan prediksi rata-rata sekitar 43.3 juta Rupiah.
- R² = 0.625 yaitu ketika model kita mampu menjelaskan 62.5% variabilitas harga rumah berdasarkan luas rumah. Ini berarti ada variabel lain selain luas rumah yang mungkin memengaruhi harga, dan model kita tidak menangkap semua variasi tersebut.
Dengan contoh di atas, kita dapat melihat bahwa evaluasi model regresi memberikan wawasan penting tentang bagaimana model kita bekerja. MAE dan RMSE menunjukkan seberapa besar kesalahan rata-rata, sedangkan R² menunjukkan seberapa baik model kita menjelaskan hubungan antara variabel independen dan dependen. Dengan memahami dan menggunakan metrik-metrik ini, kita bisa mengevaluasi dan memperbaiki model prediksi kita sehingga lebih akurat.
Kita telah sampai di penghujung materi modul regresi, jangan terburu-buru untuk menyelesaikan kelas ini. Karena objektif sesungguhnya adalah menguasai materi yang ada, bukan hanya sekadar lulus dan menghilang.
Nikmatilah masa-masa belajar di kelas pemula ini. Anda dapat mengulas kembali dan memahami materi dengan lebih baik. Jika ada pertanyaan, silakan berkunjung ke forum diskusi, ya.
Latihan Studi Kasus Regresi
Kita berjumpa pada bagian paling menyenangkan pada setiap modul yang ada, yaitu Latihan.
“Theory without practice is empty; Practice without theory is blind: The inherent inseparability of doctrine and skills” —Harold Anthony Lloyd, Professor of Law at Wake Forest.
Untuk memenuhi kebutuhan ilmu machine learning tentunya teori saja tidaklah cukup. Ngomong-ngomong, apakah Anda menyadari sesuatu pada latihan modul dua mengenai machine learning workflow?
Wow ternyata Anda menyadari nya, ya. Benar, latihan yang disediakan pada modul dua merupakan permasalahan regresi yang mana studi kasus tersebut kita bahas lebih detail pada modul ini.
Karena pada kasus sebelumnya sudah membahas permasalahan terkait prediksi harga rumah, kita perlu mengganti studi kasus untuk latihan kali ini agar Anda mendapatkan pengalaman belajar yang lebih baik.
Data yang Anda gunakan pada proyek kali ini adalah Flood Predictions dataset yang diunduh dari repository Kaggle. Unduh dataset tersebut pada tautan berikut: Flood Predictions (tautan alternatif).
Untuk tahap latihan, Anda hanya akan menggunakan dataset ini sehingga tidak perlu menambahkan data lain atau melakukan penggabungan dataset lagi. Selain itu, dataset ini juga cukup bersih sehingga tidak terlalu banyak memerlukan proses data cleaning.
Dataset ini memiliki 815.044 baris data banjir dengan berbagai karakteristik. Karakteristik yang dimaksud di sini adalah fitur seperti MoonsoonIntensity, TopographyDrainage, RiverManagement, dan lain sebagainya.
Data ini memiliki 22 fitur, dengan 20 fitur di antaranya adalah fitur yang akan Anda gunakan dalam menemukan pola pada data, sedangkan FloodProbability merupakan fitur target.
Saat membangun model machine learning, Anda bebas menggunakan tools favorit seperti Google Colaboratory, Jupyter Notebook, atau Python Anaconda. Jika lebih nyaman menggunakan Python IDE (Integrated Development Environment), Anda bisa memilih PyCharm atau Visual Studio. Tak hanya itu, Anda juga bisa memanfaatkan notebook dari platform cloud, seperti IBM Watson Studio, Kaggle Kernel, atau Google Colab.
Agar setiap tahapan kode lebih mudah diikuti, proyek ini akan menggunakan Google Colaboratory. Bagaimana dengan Anda? Sudahkah Anda menentukan tools pilihan untuk proyek ini?
Jika sudah siap, mari kita mulai proses pembangunan model kita melalui beberapa langkah seperti pada modul dua.
Data Loading
Agar dataset lebih mudah dipahami, langkah pertama yang perlu kita lakukan adalah memuat datanya. Jangan lupa untuk mengimpor library pandas agar kita bisa membaca file data.
Pada contoh kasus ini kita akan mengimpor data dari secara manual ke Google Colab. Kondisi ini terjadi ketika dataset ada di komputer lokal, Anda bisa mengunggahnya langsung ke file storage di Google Colab. Jika menggunakan tools lain atau menyimpan data di Google Drive, pastikan untuk menyesuaikan path data yang sesuai.
Langkah pertama, impor library yang diperlukan. Anda bisa melakukannya di awal, atau membaginya ke dalam sel kode sesuai kebutuhan.
- import pandas as pd
- df_train = pd.read_csv("/content/train.csv")
- df_train
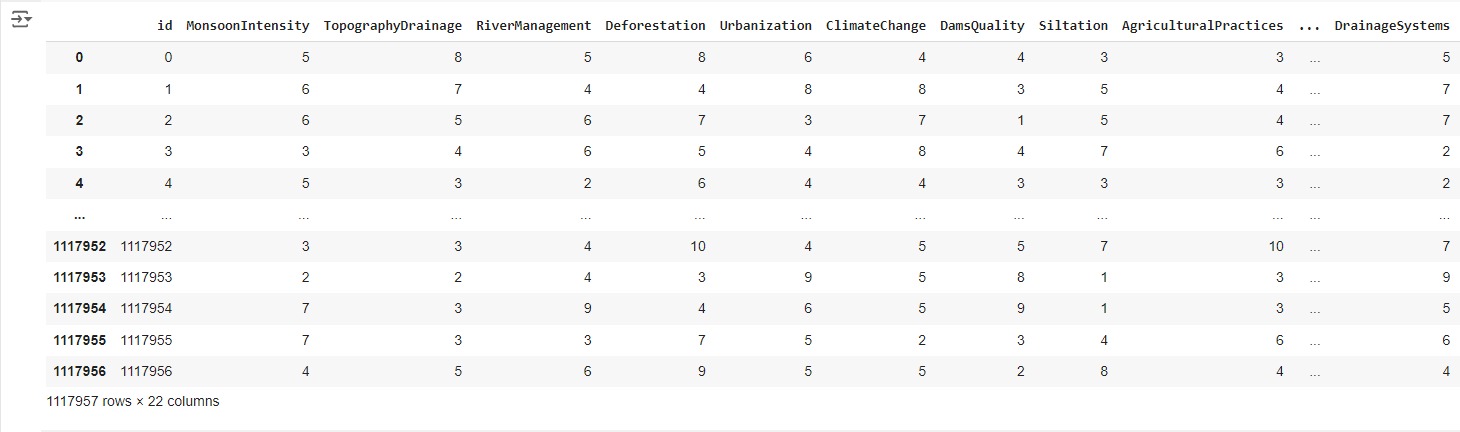
Dapat Anda lihat pada output kode di atas bahwa data yang kita miliki memiliki 1.117.957 baris dengan 22 kolom. Wow, jumlah data yang banyak ‘kan? Dengan jumlah yang sangat banyak ini bukan berarti materi ini ingin mempersulit Anda untuk belajar, tetapi justru sebaliknya. Materi ini ingin memberikan sedikit gambaran terkait jumlah data dan komputasi yang kelak akan Anda lakukan setiap hari di kantor impian!
Sebetulnya, Anda juga dapat memuat data test dengan menggunakan kode berikut.
- df_test = pd.read_csv("/content/test.csv")
- df_test
Jika Anda perhatikan data testing di atas tidaklah memiliki label atau target, hal ini bertujuan agar Anda dapat melakukan testing ketika model sudah berada di tahap produksi agar tidak terjadi error.
Hal ini menjadi wajar dalam situasi tertentu. Setelah model diuji dan dievaluasi, data testing tanpa label digunakan untuk membuat prediksi pada data baru yang belum diketahui. Data ini biasanya berasal dari dunia nyata sehingga model digunakan untuk membuat prediksi atau keputusan. Dalam kasus ini, memang tidak ada label karena data tersebut belum memiliki hasil aktual yang bisa dibandingkan.
Data Cleaning dan Transformation
Kita akan melihat informasi dasar tentang dataset, seperti jumlah baris, kolom, tipe data, dan jumlah nilai yang hilang.
Pertama-tama, mari kita periksa tipe data dari masing-masing fitur yang ada di dataset. Tujuan dari pemeriksaan tipe data ini adalah untuk memastikan seluruh tipe data yang ada sudah sesuai dan tidak ada kekeliruan (contoh: data numerik terdeteksi str (string)). Sehingga, pada akhirnya Anda tidak akan mengalami kesulitan ketika melakukan preprocessing data karena tipe data yang ada sudah sesuai dan bisa melalui proses dengan lebih seamless.
- # Menampilkan ringkasan informasi dari dataset
- df_train.info()
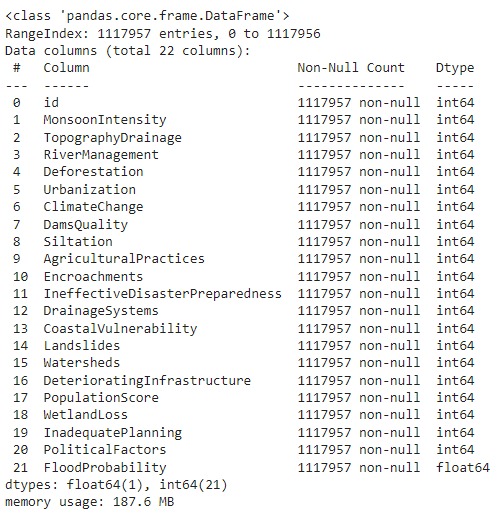
Selanjutnya, Anda perlu melakukan analisis statistik deskriptif dari dataset yang digunakan. Tujuan analisis statistik deskriptif dalam proses data cleaning pada machine learning adalah untuk memahami karakteristik dasar dari data yang sedang diproses.
Dengan melakukan analisis statistik deskriptif, kita bisa memastikan bahwa data yang digunakan untuk melatih model machine learning adalah data yang representatif, berkualitas tinggi, dan bebas dari masalah yang dapat memengaruhi hasil akhir. Berikut adalah contoh kode untuk melakukan analisis deskriptif.
- # Menampilkan statistik deskriptif dari dataset
- df_train.describe(include="all")
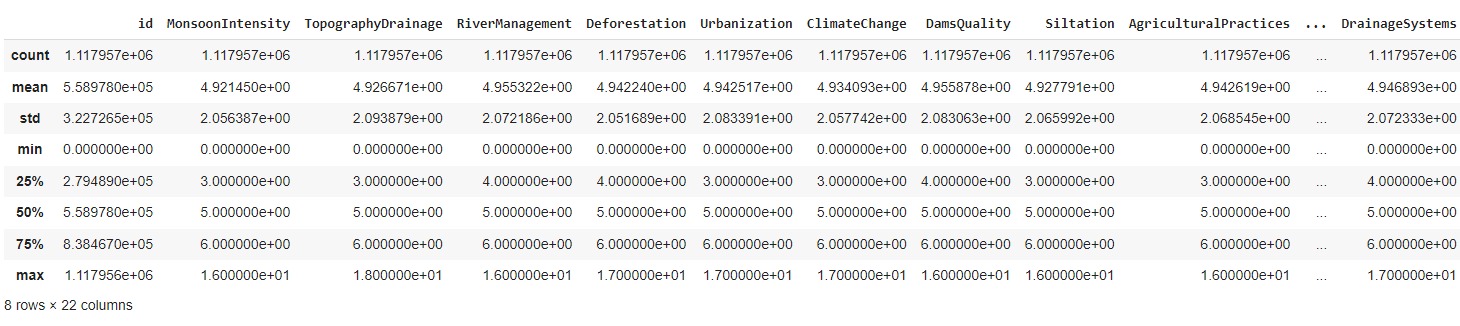
Terakhir, Anda perlu melakukan pemeriksaan terhadap data yang hilang (missing value). Tujuannya untuk mencegah kesalahan ketika melakukan analisis, mencegah error pada model, dan meningkatkan performa model. Dengan melakukan pemeriksaan missing value, Anda dapat memastikan bahwa proses analisis data dan pelatihan model machine learning berjalan dengan baik, sehingga hasil yang diperoleh lebih valid dan akurat. Berikut salah satu contoh kode untuk melakukan pemeriksaan missing value.
- missing_values = df_train.isnull().sum()
- missing_values[missing_values > 0]
Seperti yang sudah diimbau pada awal materi ini, data yang Anda gunakan sudah tergolong bersih dan tidak memiliki missing value sehingga proses pembersihan data terlihat sangat mudah. Agar tantangannya semakin terasa, mari kita berpindah ke tahap berikutnya, yaitu menangani outliers.
Seperti yang Anda ketahui bahwa outliers merupakan salah satu blocker dalam membangun model machine learning yang optimal. Hal ini bisa disebabkan oleh berbagai hal seperti kesalahan pengisian data, error yang terjadi ketika pengumpulan data, dan lain sebagainya.
Salah satu metode yang efektif untuk mengatasi outlier adalah Interquartile Range (IQR). Metode IQR mengukur sebaran data berdasarkan rentang antara kuartil pertama (Q1) dan kuartil ketiga (Q3). Nilai yang berada di bawah batas bawah (Q1 − 1,5 × IQR) atau di atas batas atas (Q3 + 1,5 × IQR) akan dianggap sebagai outlier.
Mari kita periksa terlebih dahulu apakah dataset yang digunakan memiliki outlier atau tidak menggunakan kode berikut.
- import pandas as pd
- import seaborn as sns
- import matplotlib.pyplot as plt
- for feature in df_train.columns:
- plt.figure(figsize=(10, 6))
- sns.boxplot(x=df_train[feature])
- plt.title(f'Box Plot of {feature}')
- plt.show()
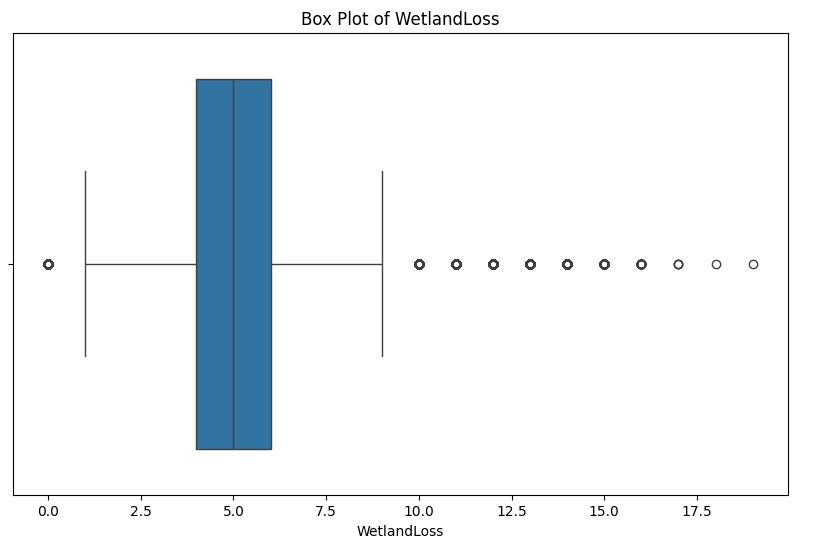
Perhatikan visualisasi data di atas, apakah Anda dapat menyimpulkan sesuatu? Yup, nilai yang berada di bawah batas minimum atau di atas batas maksimum dianggap sebagai outlier. Ada dua pilihan yang biasa dilakukan untuk mengatasi permasalahan ini.
- Anda dapat memilih untuk menghapus outlier.
- Menggantinya dengan nilai yang lebih moderat (seperti batas terdekat), atau menerapkan transformasi.
Nah, pada kasus ini, kita akan memilih untuk menghapus data outlier dengan asumsi bahwa outlier yang terjadi merupakan human error dan tidak ada pengaruh yang besar pada analisis deskriptif. Mari kita mulai pemeriksaan outlier menggunakan metode IQR dengan menggunakan kode berikut.
- # Contoh sederhana untuk mengidentifikasi outliers menggunakan IQR
- Q1 = df_train.quantile(0.25)
- Q3 = df_train.quantile(0.75)
- IQR = Q3 - Q1
- # Filter dataframe untuk hanya menyimpan baris yang tidak mengandung outliers pada kolom numerik
- condition = ~((df_train < (Q1 - 1.5 * IQR)) | (df_train > (Q3 + 1.5 * IQR))).any(axis=1)
- df = df_train.loc[condition, df_train.columns]
Apakah Anda melihat perbedaannya? Benar sekali! Setelah penanganan outliers menggunakan IQR, distribusi data menjadi lebih merata dan terpusat, dengan mean dan median yang mendekati satu sama lain. Di lain sisi, varians dan standar deviasi akan berkurang, lalu rentang data menyusut karena nilai yang berbeda telah diatasi.
Jika Anda perhatikan, ketika melakukan analisis deskriptif di awal ada beberapa hal yang menarik seperti distribusi data yang berbeda, standar deviasi yang masih besar, hingga rentang data yang berbeda-beda. Nah, untuk mengatasi permasalahan tersebut, mari kita lakukan standardisasi pada data agar dapat mengoptimalkan proses pelatihannya kelak.
Berhubung seluruh tipe data yang ada pada dataset ini numerikal maka Anda tidak perlu melakukan transformasi atau pengubahan tipe data. Sehingga, pada tahapan standardisasi, kita bisa langsung memanggil library andalan, yaitu StandardScaler.
- from sklearn.preprocessing import StandardScaler
- # Memastikan hanya data dengan tipe numerikal yang akan diproses
- numeric_features = df.select_dtypes(include=['number']).columns
- numeric_features
- # Standardisasi fitur numerik
- scaler = StandardScaler()
- df[numeric_features] = scaler.fit_transform(df[numeric_features])
Dengan menggunakan kode di atas, Anda dapat mengubah distribusi data sehingga lebih baik dengan nilai standar deviasi kurang lebih mendekati satu. Perhatikan perbedaannya dari gambar berikut.
Standardisasi penting untuk memastikan bahwa semua fitur dalam dataset memiliki skala yang sama sehingga mempermudah model untuk belajar dengan lebih baik dan memberikan hasil yang lebih akurat serta stabil.
Selanjutnya, Anda perlu memastikan bahwa data yang digunakan sudah bersih dengan mengecek duplikasi data.
- # Mengidentifikasi baris duplikat
- duplicates = df.duplicated()
- print("Baris duplikat:")
- print(df[duplicates])

Seperti yang sudah dijelaskan pada awal materi ini, data yang Anda gunakan sudah tergolong bersih sehingga data ini tidak memiliki duplikasi atau nilai kosong.
Beralih ke tahap berikutnya, yaitu exploratory dan explanatory data. Pada tahap ini, Anda perlu meningkatkan kemampuan critical thinking agar dapat menggali informasi sedalam-dalamnya sehingga dapat memperoleh insight yang bermanfaat. Mari kita mulai dengan melihat karakteristik data yang sudah diolah sebelumnya.
- df.describe(include='all')
Data yang Anda miliki sudah memiliki distribusi yang cukup baik, hal tersebut dibuktikan dengan standar deviasi yang mendekati satu dan rentang nilai yang sama. Mari visualisasikan agar bentuknya terlihat lebih jelas.
- # Menghitung jumlah variabel
- num_vars = df.shape[1]
- # Menentukan jumlah baris dan kolom untuk grid subplot
- n_cols = 4 # Jumlah kolom yang diinginkan
- n_rows = -(-num_vars // n_cols) # Ceiling division untuk menentukan jumlah baris
- # Membuat subplot
- fig, axes = plt.subplots(n_rows, n_cols, figsize=(20, n_rows * 4))
- # Flatten axes array untuk memudahkan iterasi jika diperlukan
- axes = axes.flatten()
- # Plot setiap variabel
- for i, column in enumerate(df.drop(columns=["id"]).columns):
- df[column].hist(ax=axes[i], bins=20, edgecolor='black')
- axes[i].set_title(column)
- axes[i].set_xlabel('Value')
- axes[i].set_ylabel('Frequency')
- # Menghapus subplot yang tidak terpakai (jika ada)
- for j in range(i + 1, len(axes)):
- fig.delaxes(axes[j])
- # Menyesuaikan layout agar lebih rapi
- plt.tight_layout()
- plt.show()
Standardisasi yang Anda lakukan dapat membantu mengurangi efek bias atau skewness dari data yang tidak merata distribusinya. Dengan menempatkan fitur-fitur dalam skala yang sama, model machine learning lebih mudah untuk menemukan pola yang relevan seperti gambar di atas. Selain itu, ketika variabel-variabel berada pada skala yang berbeda secara signifikan, model machine learning mungkin menjadi tidak stabil dan memberikan hasil yang buruk. Standardisasi mengurangi risiko ini dengan membuat semua variabel berada dalam rentang yang konsisten.
Karena distribusi data yang Anda miliki sudah cukup baik, selanjutnya kita perlu memilih fitur yang memiliki hubungan dengan fitur target atau pada kasus ini adalah FloodProbability.
- # Menghitung korelasi antara variabel target dan semua variabel lainnya
- target_corr = df.corr()['FloodProbability']
- # (Opsional) Mengurutkan hasil korelasi berdasarkan kekuatan korelasi
- target_corr_sorted = target_corr.abs().sort_values(ascending=False)
- plt.figure(figsize=(10, 6))
- target_corr_sorted.plot(kind='bar')
- plt.title(f'Correlation with Flood Probability')
- plt.xlabel('Variables')
- plt.ylabel('Correlation Coefficient')
- plt.show()
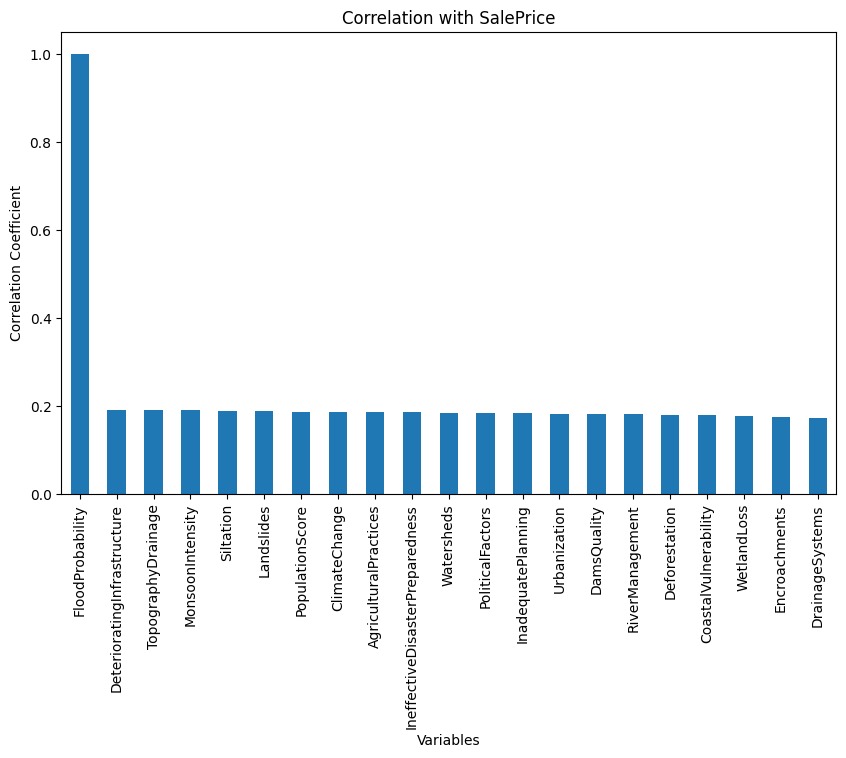
Sekali lagi, data yang kita gunakan pada kasus ini memang sudah dibuat sedemikian rupa sehingga fitur-fitur yang ada memang memiliki hubungan yang sama dengan fitur target. Lalu, apa artinya? Dengan adanya hubungan antara semua fitur dengan target, Anda tidak perlu menghilangkan fitur sehingga dataset ini siap untuk memasuki tahap selanjutnya, yaitu splitting.
Data splitting adalah langkah penting dalam workflow machine learning untuk memastikan bahwa model yang dibangun dapat digeneralisasikan dengan baik pada data yang belum pernah dilihat. Ini dapat menghindari bias evaluasi dan mengoptimalkan model dengan benar, dan memberikan estimasi kinerja yang lebih akurat. Mari kita split data menggunakan kode berikut.
- import sklearn
- from sklearn import datasets
- # Memisahkan fitur (X) dan target (y)
- X = df.drop(columns=['FloodProbability'])
- y = df['FloodProbability']
- from sklearn.model_selection import train_test_split
- # membagi dataset menjadi training dan testing
- x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
- # menghitung panjang/jumlah data
- print("Jumlah data: ",len(X))
- # menghitung panjang/jumlah data pada x_train
- print("Jumlah data latih: ",len(x_train))
- # menghitung panjang/jumlah data pada x_test
- print("Jumlah data test: ",len(x_test))

Dari sini kita bisa melihat bahwa dari jumlah data yang digunakan dapat dibagi menjadi dua subset yang berbeda dengan proporsi yang sudah ditentukan. Pada kasus ini kita akan menggunakan 676.708 data latih dan 169.178 data testing.
Dengan begitu data splitting memungkinkan kita untuk mengevaluasi kinerja model secara objektif. Dengan memisahkan data pelatihan dan pengujian, Anda bisa melihat seberapa baik model bekerja pada data yang belum pernah dilihat yang menyimulasikan kondisi dunia nyata. Ini membantu menghindari overfitting sehingga model dapat bekerja dengan sangat baik pada data pelatihan tetapi buruk pada data baru.
Selain itu, dengan membagi data menjadi bagian-bagian yang lebih kecil seperti set pelatihan dan set validasi memungkinkan Anda untuk menyetel hyperparameter model. Set validasi membantu dalam mengoptimalkan model tanpa memengaruhi data pengujian, yang sebaiknya hanya digunakan sekali untuk evaluasi akhir.
Setelah proses data splitting dilakukan langkah berikutnya dalam workflow machine learning adalah modelling. Proses ini melibatkan pelatihan model menggunakan set pelatihan yang telah kita siapkan, dan kemudian mengevaluasi kinerjanya dengan data pengujian atau validasi.
Setelah data terbagi, Anda dapat melatih model menggunakan training set. Model akan belajar dari fitur-fitur yang ada dalam data ini dan mencoba memetakan hubungan antara fitur dan target. Mari kita lakukan modelling atau pelatihan model menggunakan tiga algoritma yang berbeda.
- LARS
Gunakan kode berikut untuk menerapkan LARS.Setelah model dilatih Anda dapat menguji kinerja model pada data validasi. Proses ini penting agar model tidak hanya optimal pada data pelatihan, tetapi juga bekerja dengan baik pada data baru.- from sklearn import linear_model
- lars = linear_model.Lars(n_nonzero_coefs=1).fit(x_train, y_train)
- pred_lars = lars.predict(x_test)
- from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
- mae_lars = mean_absolute_error(y_test, pred_lars)
- mse_lars = mean_squared_error(y_test, pred_lars)
- r2_lars = r2_score(y_test, pred_lars)
- print(f"MAE: {mae_lars}")
- print(f"MSE: {mse_lars}")
- print(f"R²: {r2_lars}")
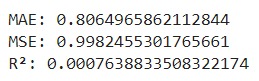
Bagaimana apakah Anda sudah puas dengan performa model yang dibangun? Jika belum mari kita bandingkan dengan algoritma lainnya.
Nah, agar Anda dapat membandingkan ketiga model yang akan dibangun, mari kita buat sebuah DataFrame seperti berikut.- # Membuat dictionary untuk menyimpan hasil evaluasi
- data = {
- 'MAE': [mae_lars],
- 'MSE': [mse_lars],
- 'R2': [r2_lars]
- }
- # Konversi dictionary menjadi DataFrame
- df_results = pd.DataFrame(data, index=['Lars'])
- df_results
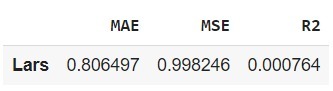
Selanjutnya, lakukanlah hal yang sama terhadap algoritma lainnya.
- Linear Regression
Gunakan kode berikut untuk menerapkan Linear Regression.- from sklearn.linear_model import LinearRegression
- LR = LinearRegression().fit(x_train, y_train)
- pred_LR = LR.predict(x_test)
- mae_LR = mean_absolute_error(y_test, pred_LR)
- mse_LR = mean_squared_error(y_test, pred_LR)
- r2_LR = r2_score(y_test, pred_LR)
- print(f"MAE: {mae_LR}")
- print(f"MSE: {mse_LR}")
- print(f"R²: {r2_LR}")

Dari sini sudah terlihat jelas perbedaan performa yang dihasilkan, tetapi untuk membuktikan ini yang terbaik mari kita bandingkan dengan salah satu algoritma lainnya.- df_results.loc['Linear Regression'] = [mae_LR, mse_LR, r2_LR]
- df_results
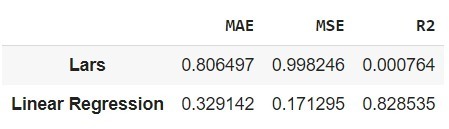
- GradientBoostingRegressor
Gunakan kode berikut untuk menerapkan GradientBoostingRegressor.- from sklearn.ensemble import GradientBoostingRegressor
- GBR = GradientBoostingRegressor(random_state=184)
- GBR.fit(x_train, y_train)
- pred_GBR = GBR.predict(x_test)
- mae_GBR = mean_absolute_error(y_test, pred_GBR)
- mse_GBR = mean_squared_error(y_test, pred_GBR)
- r2_GBR = r2_score(y_test, pred_GBR)
- print(f"MAE: {mae_GBR}")
- print(f"MSE: {mse_GBR}")
- print(f"R²: {r2_GBR}")

Dari sini, Anda sudah membandingkan beberapa algoritma. Langkah terakhir Anda perlu membandingkan ketiga model dan memilih model dengan performa terbaik.- df_results.loc['GradientBoostingRegressor'] = [mae_GBR, mse_GBR, r2_GBR]
- df_results
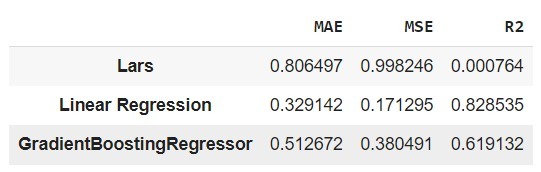
Seperti yang dapat Anda lihat pada hasil di atas, algoritma Linear Regression memiliki nilai evaluasi yang lebih baik jika dibandingkan dengan GradientBoostingRegressor. Mengapa hal itu bisa terjadi? Ada beberapa alasan mengapa algoritma Linear Regression dapat bekerja lebih baik daripada GradientBoostingRegressor dalam beberapa kasus meskipun Gradient Boosting adalah algoritma ensemble yang lebih kompleks.
Salah satu alasannya adalah data yang Anda gunakan memiliki hubungan sederhana antara fitur dan target atau bisa disebut linearitas.
Jika hubungan antara fitur dan target bersifat linear atau hampir linear, Linear Regression mungkin akan bekerja lebih baik. Linear Regression didesain untuk menangani hubungan linear secara optimal dan tidak membutuhkan model yang kompleks untuk menemukan pola tersebut. Sebaliknya, GradientBoostingRegressor adalah model non-linear yang mencoba menangkap pola yang lebih rumit. Jika hubungan antara variabel sangat sederhana dan linear, model ini akan terlalu kompleks (overfitting) dan memberikan hasil yang lebih buruk.
Pada dasarnya, pemilihan algoritma yang tepat sangat bergantung pada karakteristik dataset dan masalah yang sedang dihadapi. Meskipun GradientBoostingRegressor secara teori lebih kuat dan fleksibel, tetapi dalam kasus tertentu Linear Regression bisa menjadi pilihan yang lebih tepat karena kesederhanaan dan kemampuan generalisasi yang lebih baik pada dataset sederhana. So, jangan asal memilih algoritma karena ingin terlihat lebih keren, ya!
Anda telah menempuh perjalanan yang luar biasa dalam memahami regresi pada modul ini. Dimulai dari mengenal dasar-dasar Linear Regression hingga menyelami model-model yang lebih kompleks seperti GradientBoostingRegressor, Anda telah membuka pintu menuju salah satu fondasi paling penting dalam dunia machine learning dan analisis data. Tidak hanya sekadar memahami teori, tetapi Anda juga sudah belajar bagaimana menerapkannya dalam kode, melihat hasilnya, dan mengevaluasi kinerja model.
Satu hal yang pasti: belajar machine learning, khususnya regresi adalah sebuah petualangan yang tak pernah berakhir. Anda tidak hanya belajar pengetahuan baru, tetapi juga cara berpikir yang baru—cara berpikir yang memungkinkan Anda untuk mengubah data menjadi wawasan yang berarti. Itulah yang menjadikan perjalanan ini begitu mengasyikkan dan bermanfaat.
Tetaplah penasaran. Tantang diri Anda dengan proyek baru. Jangan takut untuk membuat kesalahan—itulah bagian dari proses belajar yang sesungguhnya. Setiap percobaan dan latihan membawa Anda lebih dekat kepada keahlian dan pemahaman yang lebih mendalam.
Selamat melanjutkan perjalanan di dunia data dan machine learning! Setiap langkah kecil yang Anda ambil akan membuka pintu menuju peluang yang lebih besar di masa depan. Semoga semangat belajar Anda tetap manyala dan terus tumbuh seiring bertambahnya pengetahuan dan pengalaman, ya!
Selamat berlatih dan berkreasi. Kami tunggu di modul berikutnya!
Rangkuman Supervised Learning - Regresi
Pendahuluan Regresi dalam Konteks Machine Learning
Regresi adalah salah satu teknik dalam machine learning yang memiliki kesamaan dengan klasifikasi. Namun, perbedaan utama antara keduanya terletak pada hasil prediksinya. Pada klasifikasi, model machine learning bertugas untuk memprediksi sebuah kelas atau kategori. Misalnya, apakah suatu email adalah spam atau bukan.
Sebaliknya, pada regresi model akan memprediksi sebuah nilai numerik yang bersifat kontinu, seperti memprediksi harga rumah berdasarkan berbagai faktor seperti luas tanah, jumlah kamar, dan lokasi.
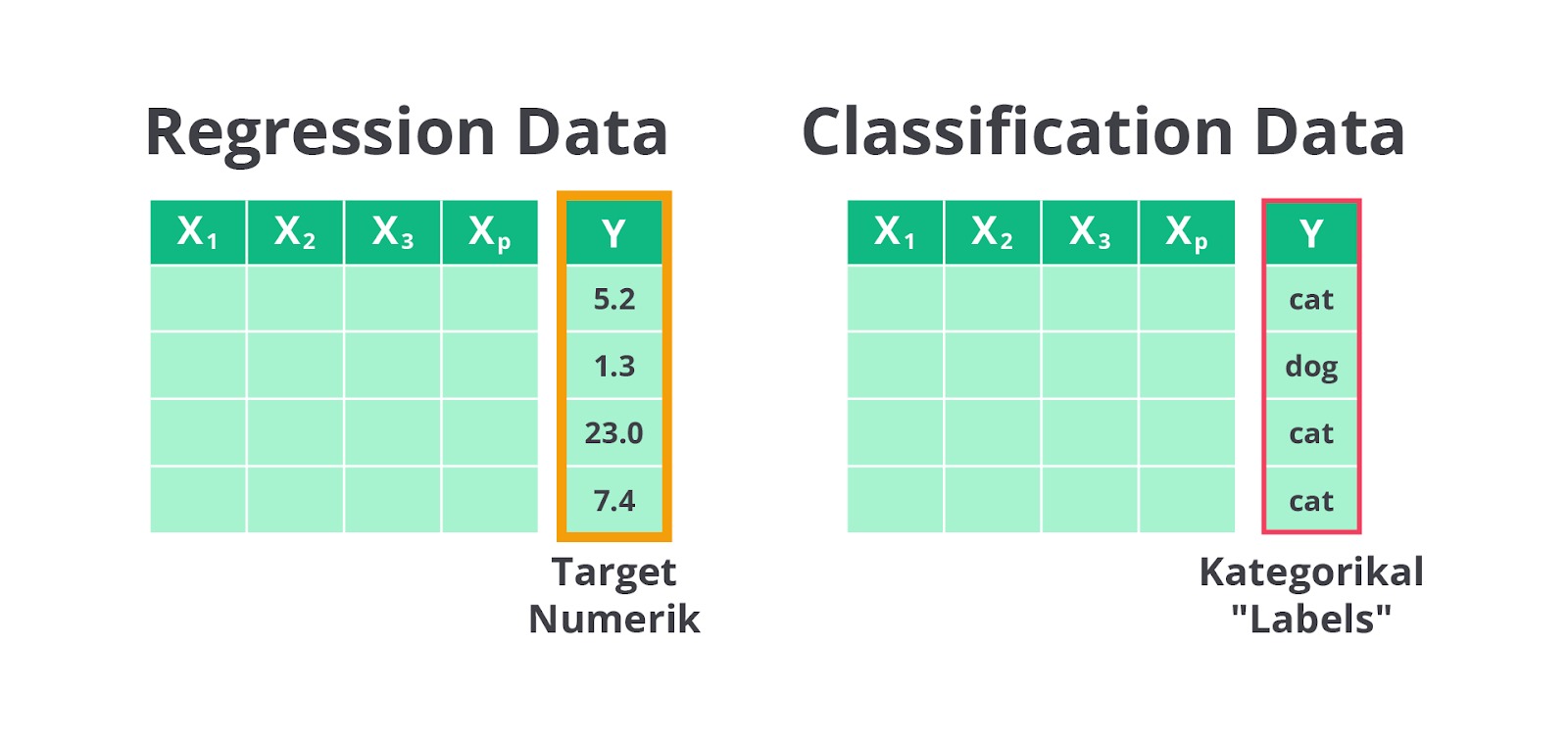
Bilangan kontinu yang diprediksi oleh model regresi adalah bilangan numerik yang tidak terbatas pada nilai-nilai diskrit. Sebagai contoh, dalam klasifikasi Anda mungkin memprediksi apakah seseorang lulus atau tidak lulus ujian (dua kelas atau kategori), sedangkan dalam regresi, Anda memprediksi nilai ujian seseorang dalam bentuk angka, misalnya 85,3.
Jenis-Jenis Regression
Seperti yang sudah Anda pelajari, regresi adalah salah satu teknik dalam statistik dan machine learning yang digunakan untuk memodelkan hubungan antara satu atau lebih variabel independen (input) dan variabel dependen (output).
Tujuan utama regresi adalah untuk memprediksi nilai dari variabel dependen berdasarkan nilai dari variabel independen. Namun, tahukah Anda bahwa setiap jenis regresi memiliki cara kerja dan kegunaan yang berbeda?
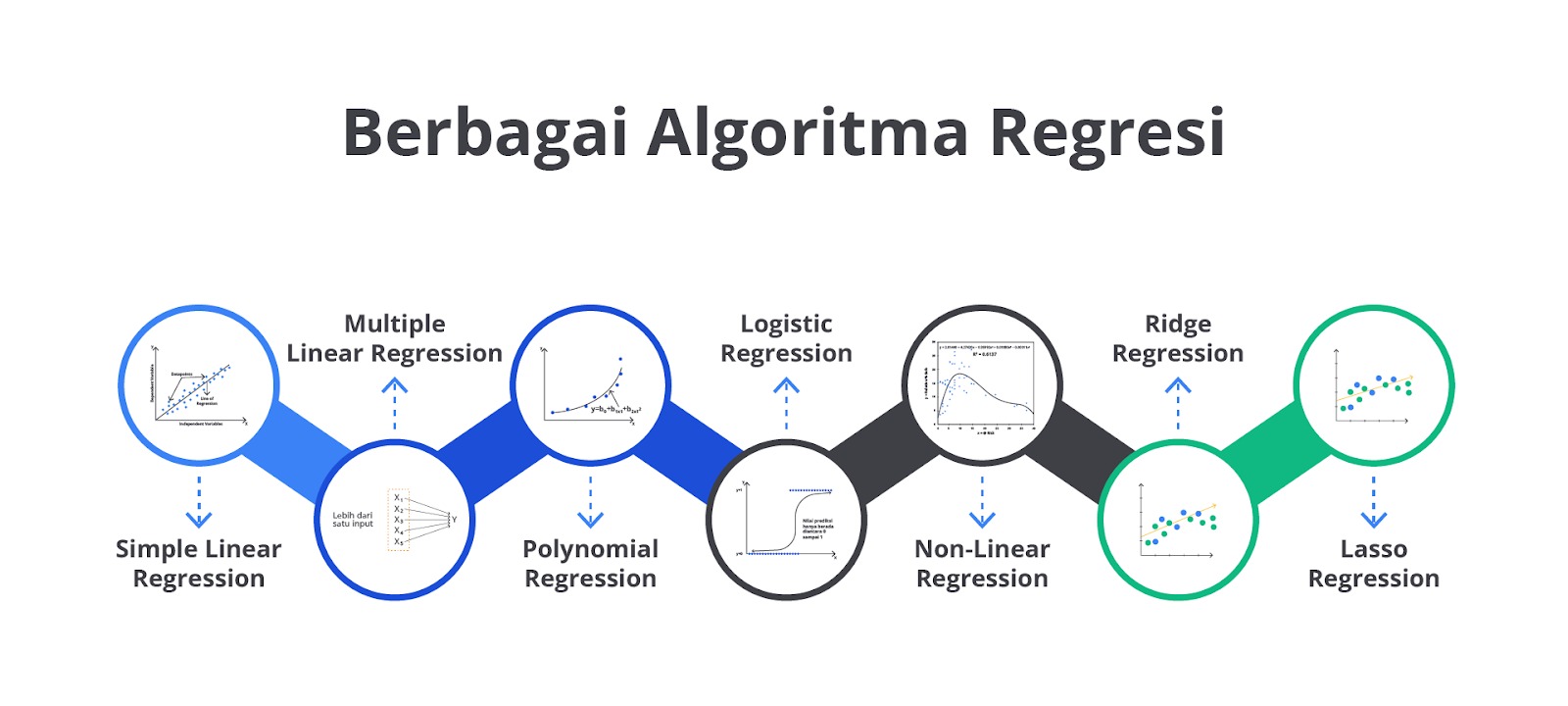
Linear Regression
Linear regression (regresi linear) adalah jenis regresi yang paling sederhana, kita akan mencoba menemukan garis lurus terbaik yang menggambarkan hubungan antara variabel independen (X) dan variabel dependen (Y).
Misalnya, jika kita ingin memprediksi harga rumah berdasarkan ukuran rumah, kita bisa menggunakan regresi linear untuk menemukan garis yang paling cocok antara ukuran rumah (X) dan harga rumah (Y).
Multiple Linear Regression
Multiple Linear Regression (Regresi Linear Berganda) adalah pengembangan dari regresi linear sederhana yang digunakan untuk memodelkan hubungan antara satu variabel dependen (terkadang disebut variabel respons atau target) dan dua atau lebih variabel independen (juga disebut prediktor atau fitur). Model ini memungkinkan kita untuk memahami bagaimana beberapa faktor memengaruhi hasil yang diinginkan secara simultan.
Polynomial Regression
Polynomial Regression (regresi polinomial) adalah bentuk lanjutan dari regresi linear yang digunakan untuk memodelkan hubungan antara variabel independen dan variabel dependen ketika hubungan tersebut tidak linear. Sebagai pengembangan dari regresi linear, metode regresi polinomial memungkinkan hubungan antara variabel untuk berbentuk kurva dengan derajat yang lebih tinggi daripada garis lurus seperti parabola atau kurva lainnya.
Logistic Regression
Logistic Regression (regresi logistik) adalah salah satu teknik pemodelan statistik yang digunakan untuk memprediksi hasil biner, yaitu hasil dengan dua kemungkinan, seperti "ya" atau "tidak," "sukses" atau "gagal," dan lain sebagainya. Berbeda dengan regresi linear yang digunakan untuk memprediksi nilai numerik, regresi logistik digunakan untuk memodelkan probabilitas bahwa suatu kejadian akan terjadi (hasil biner).
Non-Linear Regression
Non-linear regression adalah bentuk regresi yang digunakan untuk memodelkan hubungan antara variabel independen dan variabel dependen ketika hubungan tersebut tidak dapat dijelaskan dengan garis lurus atau fungsi linear. Dalam non-linear regression, model yang digunakan bisa berbentuk lebih kompleks, seperti eksponensial, logaritmik, kuadrat, kubik, atau bentuk fungsi lainnya.
Ridge and Lasso Regression
Ridge Regression dan Lasso Regression adalah dua teknik regularisasi yang digunakan dalam regresi linear untuk mengatasi masalah multikolinearitas dan overfitting.
- Ridge Regression
Ridge regression menambahkan penalti berupa jumlah kuadrat dari koefisien regresi ke dalam fungsi loss. Fungsi objektif yang diminimalkan dalam ridge regression dapat ditulis dengan rumus seperti berikut. - Lasso Regression
Lasso regression menambahkan penalti berupa jumlah absolut dari koefisien regresi ke dalam fungsi loss. Fungsi objektif yang diminimalkan dalam lasso regression dapat ditulis dengan rumus seperti berikut.
Evaluasi Model Regresi
Evaluasi model regresi adalah langkah penting dalam proses membangun model prediksi. Dengan evaluasi yang baik, kita bisa mengetahui seberapa akurat model dalam memprediksi data yang belum pernah dilihat. Untuk membantu siswa pemula memahami proses ini, kami akan menjelaskan konsep dasar, metrik evaluasi utama, dan cara menginterpretasinya.
Setelah membangun model, penting untuk mengevaluasi seberapa baik model tersebut bekerja. Evaluasi ini membantu kita untuk memahami seberapa akurat prediksi model, mengetahui jika model terlalu rumit atau terlalu sederhana, dan memastikan bahwa model tidak hanya baik pada data latihan tetapi juga pada data baru.
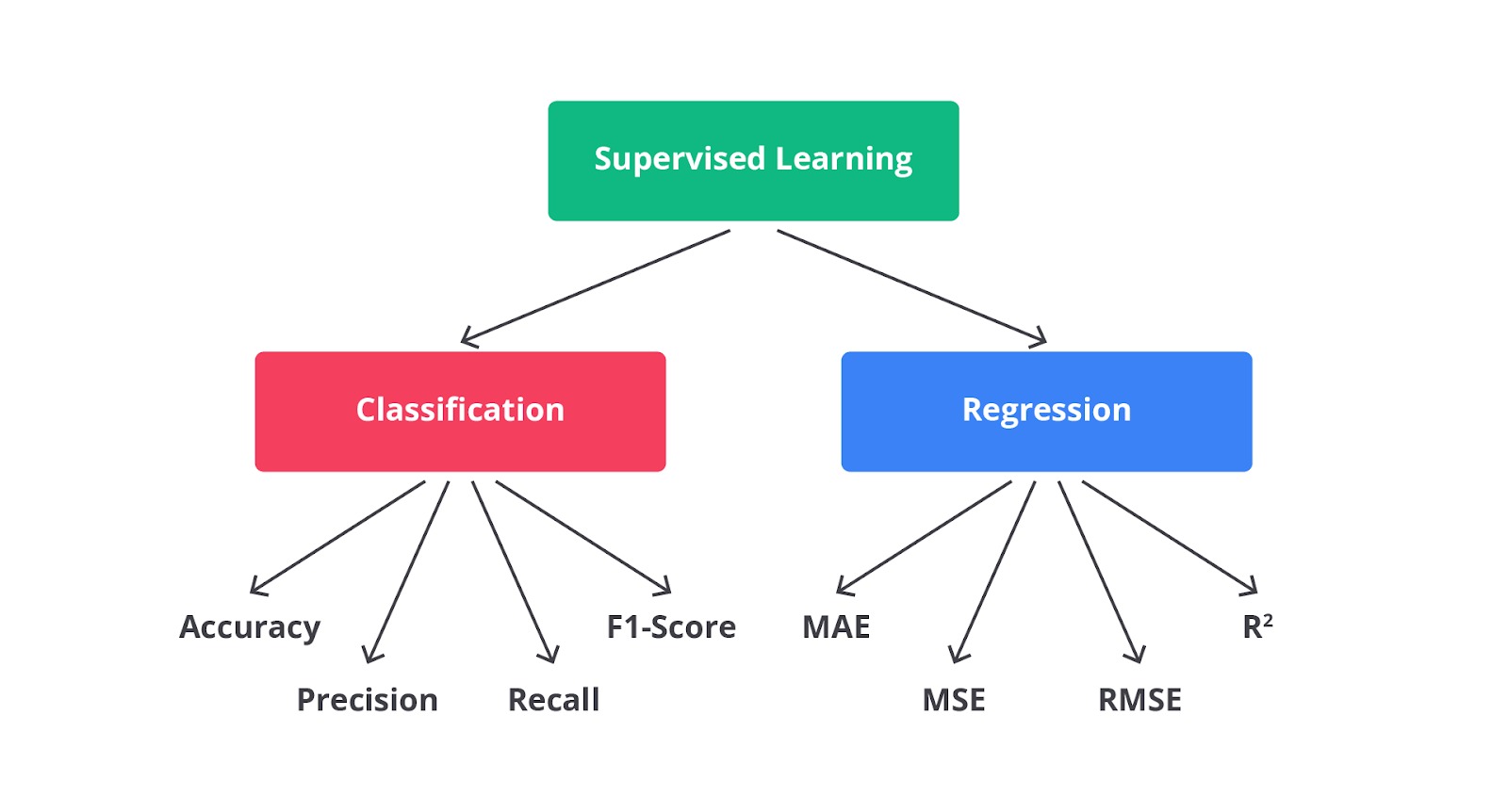
Mean Absolute Error (MAE)
MAE adalah rata-rata dari kesalahan dengan nilai absolut antara nilai sebenarnya dan nilai prediksi.
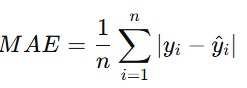
Mean Squared Error (MSE)
MSE adalah nilai rata-rata dari kuadrat kesalahan antara nilai sebenarnya dan nilai prediksi. MSE dapat digambarkan dengan rumus matematika seperti berikut.
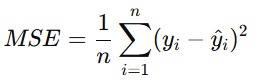
Root Mean Squared Error (RMSE)
RMSE adalah akar kuadrat dari MSE. Ini mengembalikan kesalahan ke dalam satuan yang sama dengan data sehingga lebih mudah diinterpretasikan.
R-squared (R²)
R-squared juga dikenal sebagai coefficient of determination adalah salah satu metrik yang digunakan untuk mengevaluasi seberapa baik model regresi linear menjelaskan variasi dalam data. R-squared memberikan ukuran proporsi variasi dalam variabel dependen (output) yang dapat dijelaskan oleh variabel independen (input) dalam model.
R-squared dihitung dengan menggunakan perbandingan antara variasi total dalam data dan variasi yang dapat dijelaskan oleh model regresi. Secara matematis, R-squared dapat ditulis sebagai berikut.
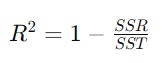
Bersambung ke:
Pendahuluan Clustering
- Get link
- X
- Other Apps



Comments
Post a Comment