Pengantar Machine Learning Workflow
- Get link
- X
- Other Apps
Pengantar Machine Learning Workflow
Selamat datang kembali wahai para engineer masa depan!
Sungguh tidak terasa perjalanan Anda untuk menjadi seorang Machine Learning Engineer atau Data Scientist sudah makin dekat. Setelah resmi menamatkan modul sebelumnya, tentunya Anda sudah memahami pengertian machine learning, tipe-tipenya, contoh studi kasus hingga memecahkan permasalahan menggunakan machine learning. Namun, masih banyak sekali hal yang harus Anda taklukan, salah satunya adalah ketekunan.
"As long as we are persistence in our pursuit of our deepest destiny, we will continue to grow. We cannot choose the day or time when we will fully bloom. It happens in its own time."

— Denis Waitley, American motivational speaker and writer —
Walaupun sudah makin dekat, bukan berarti ini waktunya berpuas diri. Saat ini, Anda sudah memasuki babak kedua dalam mempelajari kelas machine learning untuk pemula. Nah, pada tahap ini, Anda akan mempelajari urutan dalam membangun machine learning dari dasar hingga menjadi sebuah model yang bisa digunakan.
Awali hari dengan ceria,
Machine Learning kita jelajahi bersama.
Data dan model jadi sahabat setia,
Membuka jalan, mengejar cita.
Setiap langkah, tantangan menanti,
Dengan tekad kuat, kita hadapi.
Belajar dan berusaha tiada henti,
Meraih mimpi, wujudkan ambisi.
Mari melangkah dengan percaya diri,
Di dunia ilmu, kita berkreasi.
Semangat membara, teruslah berlari,
Kita bisa, masa depan berseri!
Mari kita mulai petualangan ini dengan semangat yang menggebu dan tekad yang kokoh. Setiap tantangan adalah peluang untuk berkembang dan maju. Semangat!
[Story] Membuat Tujuan, Mengejar Impian!
Hari demi hari, Diana menjalani kehidupannya bersama Bilqis. Mereka tidak hanya sekadar teman kuliah, tetapi juga rekan dalam mengejar mimpi. Mulai dari mengikuti kegiatan perkuliahan, makan siang bersama hingga belajar di luar jam kuliah, mereka selalu bersama. Kebersamaan ini membuat Diana semakin bersemangat dan perlahan membentuk cara pandangnya sebagai mahasiswa yang ingin memahami banyak hal secara menyeluruh atau yang sering disebut sebagai generalis.

Namun, seiring berjalannya waktu, Diana dan Bilqis menyadari bahwa menjadi mahasiswa bukan hanya soal mengikuti arus. Mereka tidak puas sekadar mengejar nilai, tetapi benar-benar berusaha memahami setiap mata kuliah yang dipelajari. Salah satunya adalah Algoritma Pemrograman. Dari mata kuliah inilah mereka belajar memecahkan masalah secara sistematis dan terstruktur. Pengalaman tersebut membuka mata mereka bahwa sebelum menguasai banyak hal sekaligus, ada kalanya seseorang perlu mendalami satu bidang secara fokus, atau biasa disebut dengan spesialis.

Diana akhirnya mengingat kembali diskusi terakhir bersama Bilqis yang membicarakan terkait Python, analisis data dan machine learning. Dengan bekal dasar tersebut, ia akhirnya memutuskan untuk mempelajari machine learning dan ingin menjadi seorang machine learning engineer masa depan.

Setelah berdiskusi panjang lebar akhirnya mereka memutuskan bekerja sama untuk menjadi seorang Machine Learning Engineer dan Data Scientist di masa depan. Namun, mereka sadar bahwa saat ini bekal ilmu yang dimiliki hanya sebatas dasar machine learning tanpa ada hal lainnya.
Mata kuliah Algoritma Pemrograman kembali mengingatkan Diana bahwa memahami langkah-langkah adalah kunci dalam mengembangkan sesuatu. Dengan semangat baru, mereka mulai merencanakan langkah-langkah konkret untuk menguasai machine learning.

Tentunya dengan bekal pengetahuan dari perkuliahan akhirnya mereka melakukan riset terkait langkah-langkah yang harus dipelajari untuk membangun machine learning dari dasar hingga bisa digunakan.
Sampai di sini mungkin Anda juga ikut penasaran dan bertanya-tanya, “Dari mana kita harus memulai belajar machine learning?” Tenang kawan, pada modul ini, kita akan menemani Diana dan Bilqis untuk menemukan jalan menuju predikat Machine Learning Engineer. Eitss, bukan hanya Diana dan Bilqis, modul ini juga akan menuntun Anda ke masa depan yang lebih terarah. Oleh karena itu, kencangkan sabuk pengaman, jangan sampai ketinggalan oleh Diana dan Bilqis ya, semangat!
Pendahuluan Machine Learning Workflow
Tahukah Anda bahwa setiap manusia ketika bepergian akan menyiapkan sebuah rute, baik itu dalam bentuk peta konvensional ataupun peta digital. Di lain sisi, jika kita sudah hafal atau dalam kata lain sudah menguasai rutenya, kita malah bisa memberikan informasi kepada orang lain juga, ‘kan?

Lalu, apa sebenarnya fungsi peta? Dalam konteks perjalanan, peta memiliki makna yang sangat penting dan simbolis. Sebagai panduan dan alat navigasi, peta memberikan arah yang jelas dan membantu kita merencanakan rute terbaik, serta dapat membantu untuk mencapai tujuan dengan efisien dan aman.
Sama halnya dengan perjalanan Anda dalam membangun sebuah project machine learning yang membutuhkan arah yang jelas sehingga dapat membantu merancang model terbaik. Nah, biasanya untuk membangun model machine learning, kita memerlukan alur kerja yang biasa disebut machine learning workflow.
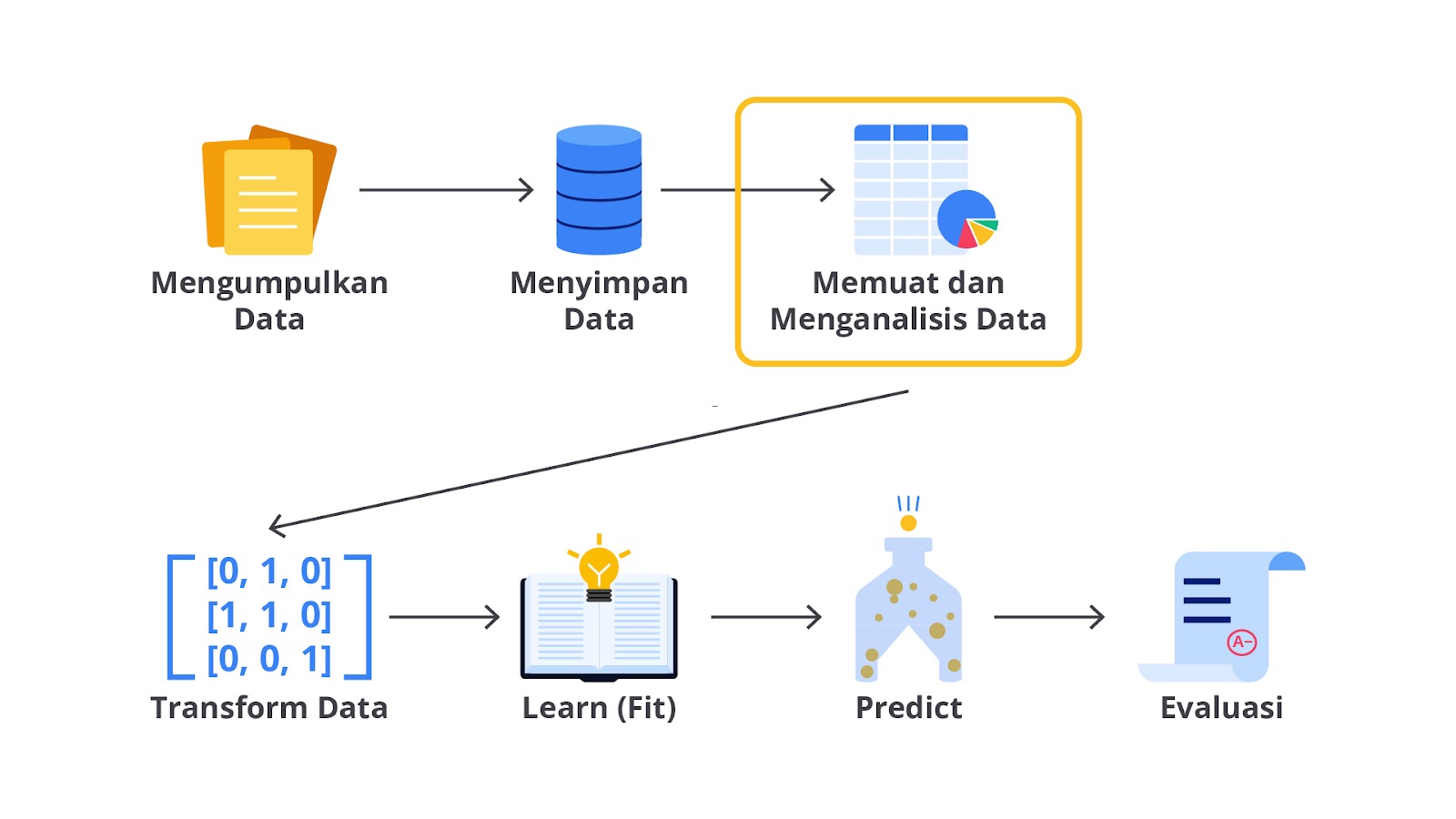
Machine learning workflow berisikan tahapan-tahapan yang perlu dilalui sebelum project tersebut bisa diimplementasikan di tahap produksi. Aurélien Géron dalam bukunya "Hands-On Machine Learning with Scikit-Learn & TensorFlow" [4] menjelaskan alur kerja machine learning sebagai serangkaian langkah sistematis yang dimulai dari definisi masalah hingga penerapan model yang jika kita rangkum akan menghasilkan diagram seperti berikut.
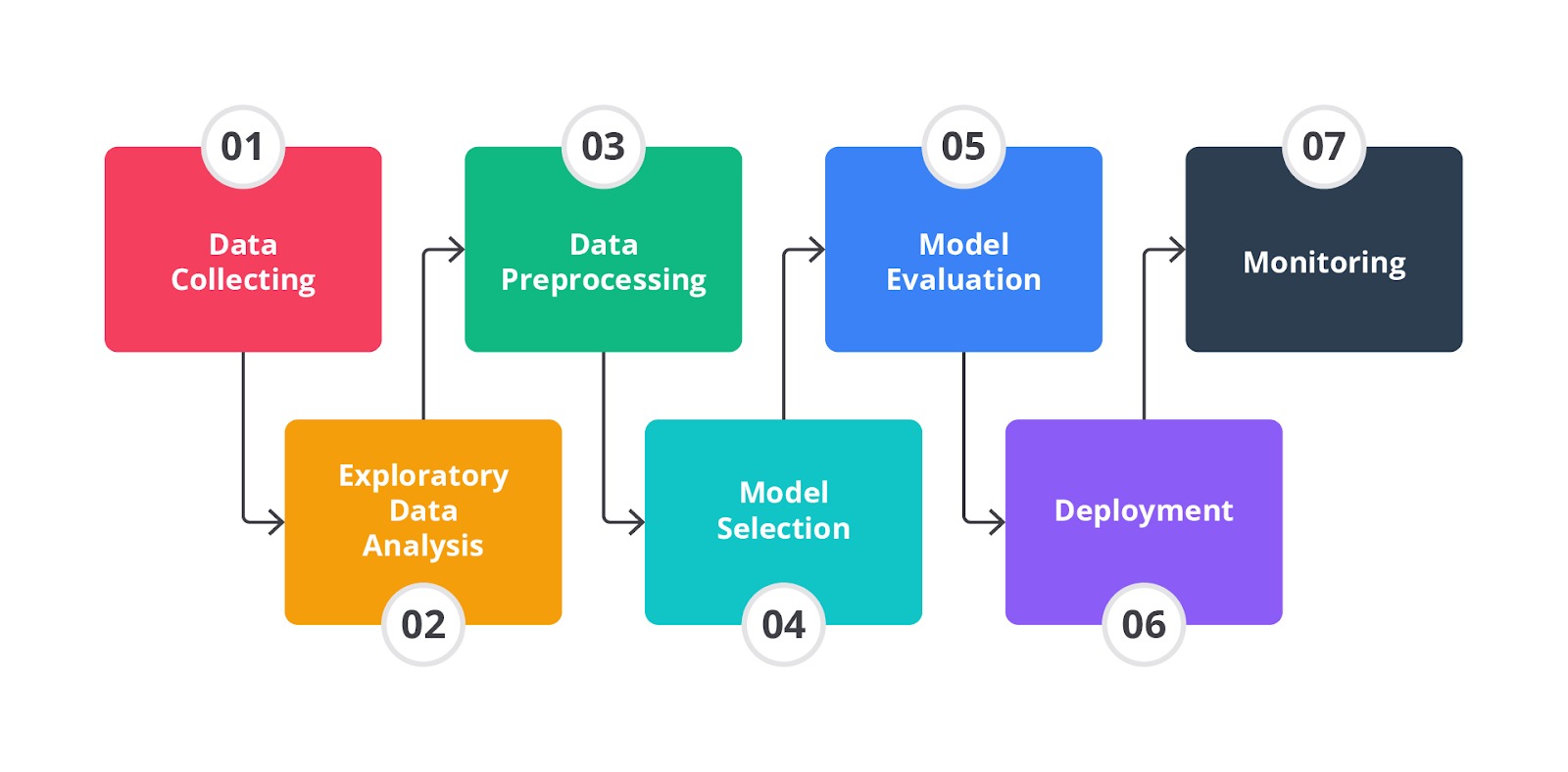
Alur kerja machine learning menurut buku tersebut melibatkan serangkaian langkah yang sistematis dan iteratif. Setiap langkah membutuhkan evaluasi dan penyesuaian untuk memastikan model yang dihasilkan dapat memberikan hasil yang akurat dan andal dalam lingkungan produksi. Buku ini juga menekankan pentingnya pemahaman mendalam terhadap data dan masalah yang dihadapi serta penggunaan alat dan teknik yang tepat untuk mencapai tujuan machine learning.
Seperti yang Anda lihat pada diagram di atas, tentunya tahapannya tidak sedikit, ‘kan? Tenang saja, sebagai bekal dasar, Anda akan mempelajari semuanya benar-benar dari nol dengan tujuan bisa memperkaya pengetahuan dasar sehingga akan mempermudah pengerjaan proyek Anda kelak.
Tanpa berlama-lama lagi, mari kita bahas diagram di atas secara saksama.
Proses Pengumpulan Data
Langkah pertama dalam alur kerja machine learning adalah memahami masalah yang ingin diselesaikan dan tujuan bisnis yang ingin dicapai. Setelah masalah dipahami, langkah berikutnya adalah mengumpulkan data yang relevan dari berbagai sumber, seperti basis data, API, atau data publik.
Saat ini banyak sekali data yang bisa kita akses kapan pun dan di mana pun, bahkan beberapa data penting dijual secara cuma-cuma. Dari sumber-sumber tersebut, Anda dapat memilih, mengunduh, dan menggunakan dataset yang sesuai dengan kebutuhan Anda kapan saja. Proses ini relatif mudah tetapi tantangannya adalah memilih dataset yang tepat untuk model Anda.
Jika Anda adalah seorang Machine Learning Engineer pada sebuah perusahaan yang bertugas untuk membangun model machine learning untuk keperluan internal, tentu proses pengumpulan datanya tidak semudah Anda mengunduh dataset yang sudah tersedia. Anda perlu mengumpulkan dan mengekstrak sendiri data dari berbagai sumber misalnya database, file, data sensor, dan sumber lainnya.
Salah satu cara untuk mendapatkan data yang tidak dimiliki perusahaan adalah dengan cara scraping. Scraping atau lebih tepatnya web scraping adalah proses otomatis untuk mengumpulkan data atau informasi dari situs web. Proses ini melibatkan penggunaan skrip atau perangkat lunak untuk mengekstrak data yang diinginkan dari halaman web tertentu, yang kemudian dapat diolah atau dianalisis lebih lanjut. Web scraping dapat dilakukan dengan berbagai cara, mulai dari menggunakan alat-alat sederhana hingga membangun skrip atau program yang kompleks.
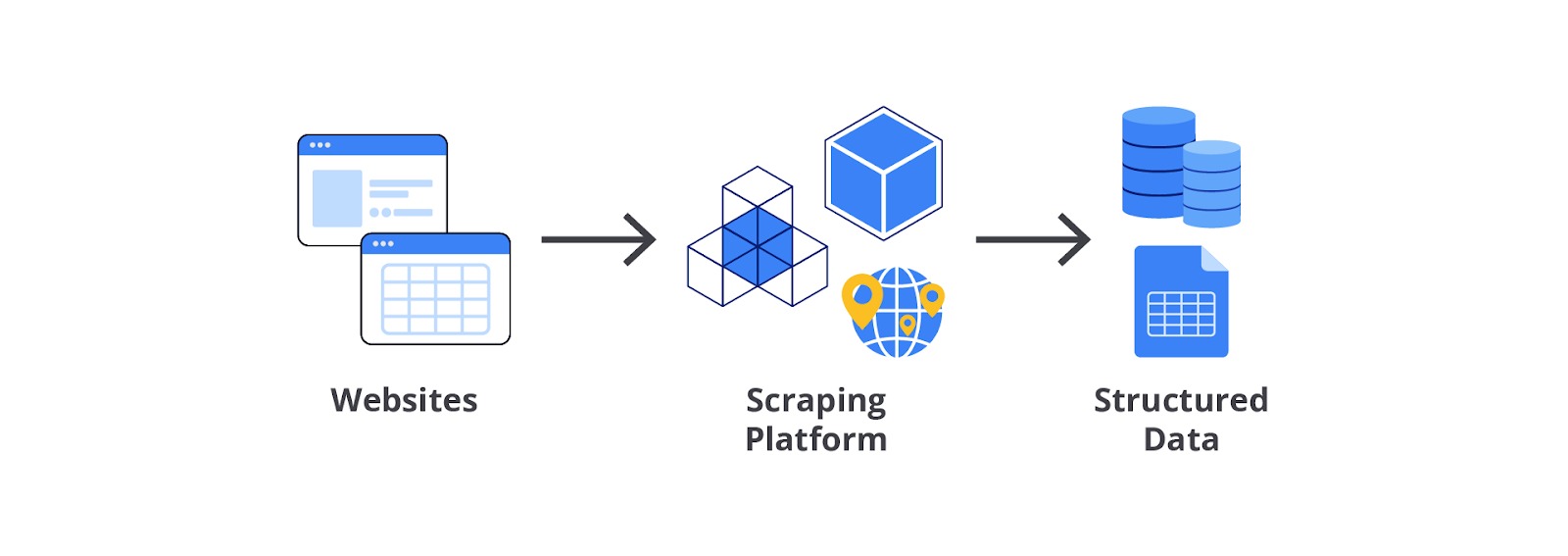
Proses scraping bisa memakan waktu yang cukup lama karena Anda perlu menentukan data yang sesuai dan mengolah semuanya dari nol. Namun, tenang saja pada modul ini, kita tidak akan melakukan hal tersebut. Jika Anda penasaran dengan teknik tersebut, silakan lanjutkan petualangan ini sampai kelas berikutnya ya.
Sebagai informasi pada tahap ini Anda juga perlu berurusan dengan berbagai jenis tipe data dari mulai structured data (seperti excel file atau database SQL), sampai unstructured data (seperti text file, email, video, audio, gambar, data sensor, dan lainnya). By the way, menurut Gartner lebih dari 80% data perusahaan adalah unstructured data.
Exploratory Data Analysis
Setelah data terkumpul, kita perlu memahami struktur dan karakteristik data. Ini termasuk melakukan analisis deskriptif dan visualisasi data untuk menemukan pola atau anomali tertentu.
Tahapan tersebut disebut exploratory data analysis atau EDA yang bertujuan sebagai analisis awal terhadap data dan melihat bagaimana kualitas data untuk meminimalkan potensi kesalahan di kemudian hari. Pada proses ini dilakukan investigasi awal pada data untuk memahami data, menemukan pola, anomali, menguji hipotesis, memahami distribusi, frekuensi, hubungan antara variabel, dan memeriksa asumsi dengan teknik statistik dan representasi grafik.
Pada umumnya, EDA dilakukan dengan dua cara, yaitu univariate analysis, dan multivariate analysis. Univariate analysis adalah analisis deskriptif yang memeriksa pola dengan satu variabel pada modelnya. Multivariate analysis merupakan analisis deskriptif yang memeriksa pola dalam data multidimensi dengan mempertimbangkan lebih dari dua variabel. Jika terdapat dua variabel yang akan dianalisis, ia disebut bivariate analysis.
Karena multivariate analysis mempertimbangkan lebih banyak variabel, ia dapat memeriksa fenomena yang lebih kompleks dan menemukan pola data yang mewakili dunia nyata dengan lebih akurat.
“Bentar-bentar, lalu apa maksud dan tujuan dari ketiga cara analisis di atas?”
Pertanyaan yang menarik, mari kita jabarkan sekali lagi terkait ketiga cara analisis tersebut.
- Univariate Analysis
Seperti penjelasan di atas, univariate adalah analisis yang melibatkan hanya satu variabel dalam satu waktu tertentu. Tujuan dari analisis univariate ini untuk memahami distribusi, central tendency (contoh: mean, median) dan penyebaran data (contoh: varians, standar deviasi) dari satu variabel. Contoh eksplorasi yang dapat dilakukan berupa histogram, box plot, bar plot, dan lain sebagainya.
- Bivariate Analysis
Seperti namanya bivariate analisis melibatkan dua variabel pada satu waktu tertentu untuk memahami hubungan atau asosiasi antar variabel yang digunakan. Analisis ini bertujuan untuk mengeksplorasi adanya hubungan antara dua variabel, apakah salah satunya memengaruhi yang lain, atau bagaimana kedua variabel tersebut berinteraksi. Biasanya analisis ini menggunakan visualisasi scatter plot, crosstab, box plot, dan lain sebagainya.
- Multivariate Analysis
Last but not least, multivariate analisis akan melibatkan lebih dari dua variabel pada satu waktu tertentu. Ini bisa mencakup tiga atau lebih variabel sekaligus yang tidak bisa dijelaskan dengan analisis univariate ataupun bivariate. Cara ini akan membantu dalam mengidentifikasi pola tersembunyi atau interaksi antara variabel yang mungkin akan memengaruhi hasil. Cara ini bisa divisualkan dengan menggunakan pair plot, heatmap, principal component analysis, dan lain sebagainya.
Dari penjelasan tersebut akan memberikan garis besar bahwa EDA merupakan langkah penting dalam proses pembangunan machine learning karena dapat memastikan bahwa setiap langkah berikutnya dalam alur kerja data didasarkan pada pemahaman yang kuat tentang data itu sendiri.
Data Preprocessing
Data preprocessing adalah langkah penting dalam alur kerja machine learning yang bertujuan untuk mempersiapkan data mentah agar dapat digunakan secara efektif oleh model machine learning.
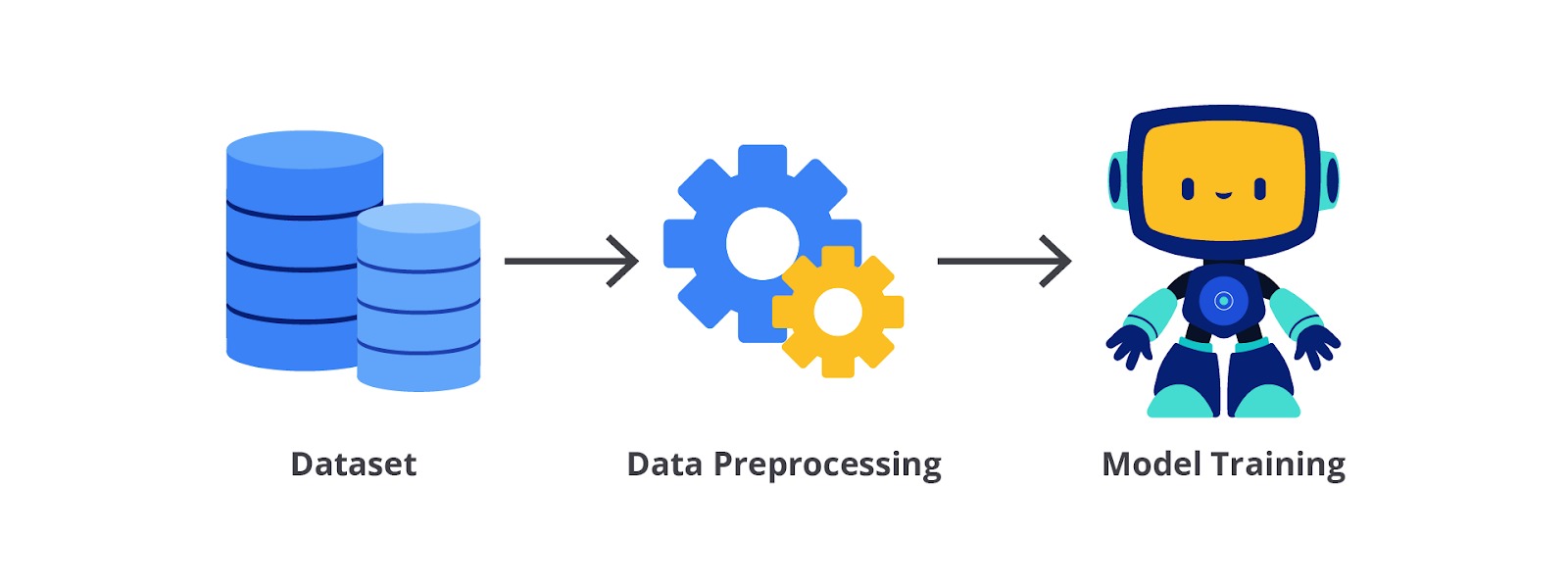
Proses ini mencakup serangkaian teknik dan transformasi untuk memastikan data yang digunakan berkualitas tinggi, konsisten, dan relevan dengan tujuan analisis atau pemodelan. Dengan kata lain, proses ini mengubah dan mentransformasi fitur-fitur data ke dalam bentuk yang mudah diinterpretasikan dan diproses oleh algoritma machine learning.
Beberapa hal yang bisa dilakukan dalam proses data cleaning seperti berikut.
- Mengidentifikasi dan Menangani Data yang Hilang
Data yang hilang atau missing value adalah masalah umum dalam dataset yang harus ditangani. Beberapa cara penanganannya dengan cara menghapus data yang hilang atau melakukan imputasi data. Imputasi adalah mengganti data yang hilang dengan nilai lain (contoh: mean, median, modus dan lain sebagainya).
- Mengidentifikasi dan Menangani Outliers
Outlier adalah data yang jauh berbeda dari mayoritas data lainnya. Outlier dapat memengaruhi performa model, terutama pada algoritma yang sensitif seperti regresi linear. Beberapa cara menanganinya dengan cara menghapus outlier, melakukan transformasi data, atau mengubah nilai menjadi lebih dekat ke distribusi normal.
Di lain sisi, kita juga terkadang perlu melakukan transformasi data, hal ini diperlukan untuk memastikan data sesuai dengan format atau skala yang dapat digunakan oleh model machine learning. Berikut beberapa cara untuk melakukan transformasi data.
- Normalisasi (Normalization)
Mengubah skala data sehingga berada dalam rentang tertentu, biasanya antara 0 dan 1.
- Standardisasi (Standardization)
Mengubah data sehingga memiliki distribusi dengan mean 0 dan standar deviasi 1. Ini sering digunakan ketika data memiliki distribusi Gaussian.
- Transformasi Log atau Sqrt
Menggunakan transformasi logaritmik atau akar kuadrat untuk mengurangi skewness data.
- Encoding Variabel Kategorikal (Categorical Encoding)
For your information, model machine learning itu hanya dapat bekerja dengan data numerik sehingga variabel kategorikal harus diubah menjadi bentuk numerik. Beberapa cara yang bisa Anda lakukan untuk menyelesaikan permasalahan tersebut antara lain- Label Encoding: mengubah kategori menjadi label numerik. Ini cocok untuk variabel dengan hubungan ordinal.
- One-Hot Encoding: mengubah setiap kategori menjadi kolom biner terpisah (0 atau 1). Ini digunakan ketika tidak ada hubungan ordinal di antara kategori.
- Ordinal Encoding: mengubah kategori ke dalam bentuk label numerik berdasarkan urutan atau tingkatan.
- Feature Scaling
Ketika data memiliki fitur dengan skala yang berbeda-beda, fitur dengan skala lebih besar bisa mendominasi algoritma machine learning tertentu seperti K-Nearest Neighbors atau Support Vector Machines. Untuk itulah fitur scaling diperlukan karena dapat mengatasi permasalahan tersebut. Berikut beberapa cara untuk melakukan feature scaling.- Min-Max Scaling: mengubah fitur ke dalam rentang antara nilai minimum dan maksimum yang diinginkan.
- Standardization: skala fitur ke dalam distribusi Gaussian dengan mean 0 dan standar deviasi 1.
Tidak lupa pula, proses train-test split juga merupakan bagian dari data preprocessing. Ini merupakan langkah terakhir dalam preprocessing dengan membagi data menjadi set pelatihan (training set), set pengujian (test set), dan kadang-kadang set validasi (validation set). Hal tersebut memastikan bahwa model dievaluasi pada data yang tidak pernah dilihat sebelumnya untuk mengukur kinerja yang sebenarnya.
Kesimpulannya, data preprocessing adalah proses kompleks dan kritis yang memastikan data siap untuk dimodelkan. Tahap ini mencakup pembersihan, transformasi, encoding, scaling, feature engineering, dan pengurangan dimensi. Tujuannya adalah untuk memastikan bahwa data yang diberikan ke model machine learning berkualitas tinggi, terstruktur dengan baik, dan siap untuk dianalisis sehingga model dapat menghasilkan prediksi yang akurat dan andal.
Disclaimer Proses data preprocessing bisa sangat dinamis dan tidak ada kontrak untuk melakukan semua tahapannya, bahkan suatu saat Anda bisa saja melakukan preprocessing lainnya yang tidak disebutkan di atas. Semuanya tergantung dengan kasus dan karakteristik data yang Anda hadapi. |
Model Selection
Model selection adalah langkah penting dalam alur kerja machine learning yang melibatkan pemilihan algoritma terbaik untuk memecahkan masalah spesifik berdasarkan data yang tersedia. Pemilihan model yang tepat dapat secara signifikan memengaruhi kinerja akhir dari solusi machine learning.
K. P. Murphy dalam bukunya yang berjudul Machine Learning: a Probabilistic Perspective [16] menuliskan kalimat berikut.
“when we have a variety of models of different complexity (e.g., linear or logistic regression models with different degree polynomials, or KNN classifiers with different values of K), how should we pick the right one?”
Singkatnya, pertanyaannya adalah tentang cara memilih model terbaik di antara beberapa kandidat yang kompleksitasnya berbeda, agar performanya bagus.
Berangkat dari pertanyaan tersebut, menentukan model yang sesuai dengan data merupakan tahapan yang penting dalam machine learning workflow.
Selain itu, Jie Ding, et al dalam tulisannya “Model Selection Techniques -An Overview” [17] menyatakan bahwa tidak ada model yang cocok secara universal untuk data dan tujuan apa pun. Pilihan model atau metode yang tidak tepat dapat menyebabkan kesimpulan yang menyesatkan atau performa prediksi yang mengecewakan. Sebagai contoh, saat memiliki kasus klasifikasi biner, kita perlu mempertimbangkan model terbaik untuk data kita, apakah logistic regression atau SVM classifier.
Langkah pertama dalam model selection adalah memahami jenis masalah yang ingin diselesaikan. Masalah machine learning biasanya dapat dibagi menjadi beberapa kategori utama seperti berikut.
- Masalah Klasifikasi dengan tujuan untuk mengkategorikan input ke dalam kelas tertentu. Misalnya, spam vs non-spam.
- Masalah Regresi dengan tujuan untuk memprediksi nilai kontinu. Misalnya, harga rumah berdasarkan fitur-fitur tertentu.
- Masalah Clustering dengan tujuan untuk mengelompokkan data ke dalam grup yang tidak diketahui sebelumnya.
- Masalah Dimensionality Reduction dengan tujuan untuk mengurangi jumlah fitur dalam dataset tanpa kehilangan informasi penting.
- Masalah Time Series dengan tujuan untuk memprediksi nilai masa depan berdasarkan data historis.
Setelah menentukan kategori utama yang cocok untuk permasalahan yang ingin diselesaikan, Anda perlu melakukan eksplorasi algoritma untuk kategori yang sudah ditentukan.
Pada tahap ini, Anda perlu melakukan pengujian awal atau baseline model dengan tujuan untuk menguji beberapa algoritma secara cepat sehingga mendapatkan gambaran awal tentang kinerja mereka pada dataset. Hal ini bisa dilakukan dengan menggunakan default hyperparameters tanpa penyesuaian khusus. Hasil baseline ini membantu dalam mengevaluasi seberapa kompleks atau sederhana model yang diperlukan.
Setelah menentukan algoritma yang cocok untuk data yang ada, langkah berikutnya adalah menyesuaikan hyperparameter untuk mengoptimalkan kinerja model. Hyperparameter adalah parameter yang ditentukan sebelum proses pelatihan dan tidak dipelajari dari data. Contoh hyperparameter termasuk jumlah tree dalam Random Forest, nilai C dalam SVM, atau learning rate dalam Gradient Boosting. Proses menemukan performa terbaik model dengan pengaturan hyperparameter yang berbeda ini juga disebut model selection.
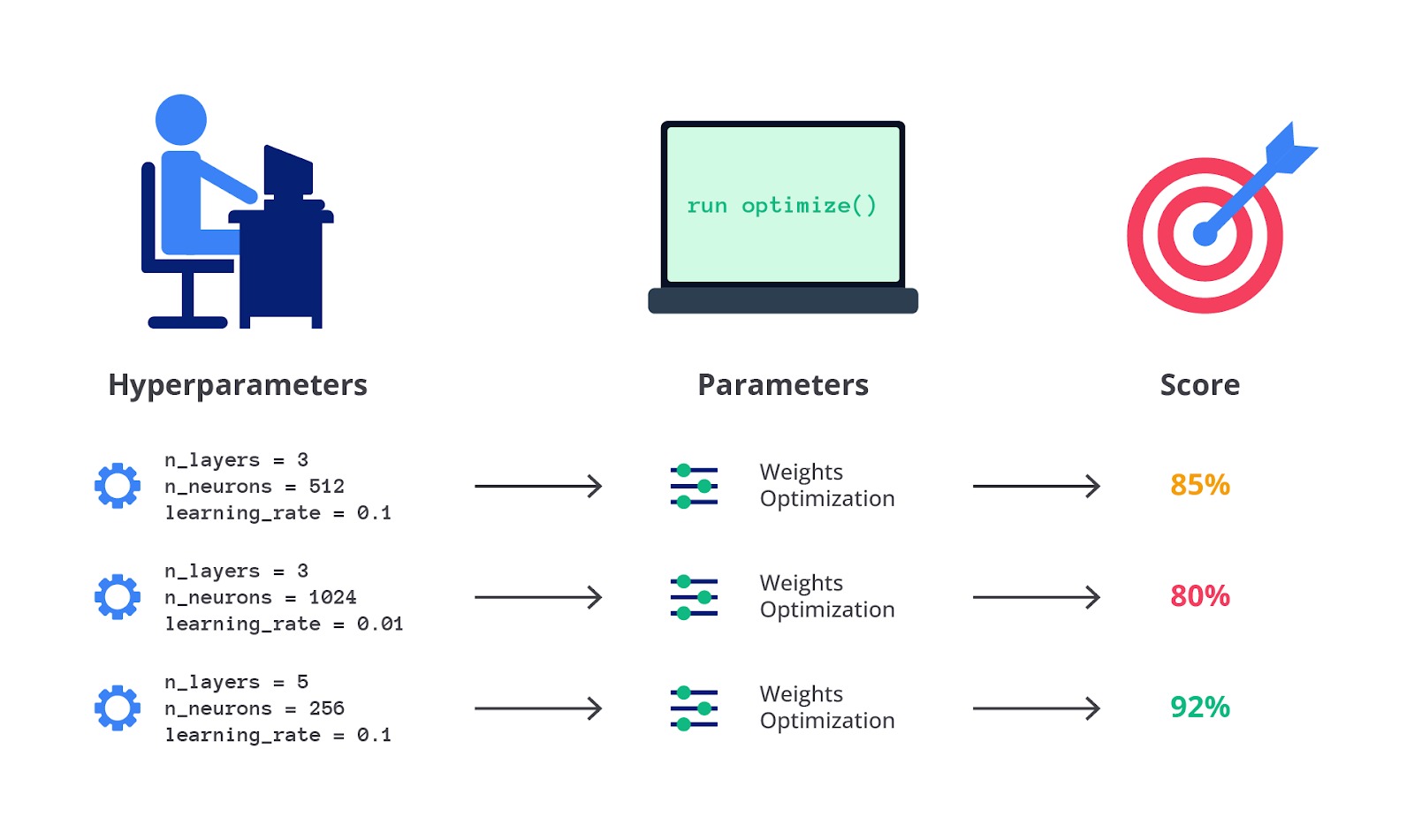
Dengan demikian, dalam konteks machine learning, model selection bisa berarti dua hal, yaitu pemilihan learning method atau algoritma machine learning dan pemilihan hyperparameter terbaik untuk metode machine learning yang dipilih.
Model Evaluation
Setelah mengotak-atik model Anda dengan hyperparameter yang berbeda, akhirnya Anda mendapatkan model yang kinerjanya cukup baik. Langkah selanjutnya adalah mengevaluasi model akhir pada data uji. Sederhananya, langkah evaluasi model dapat dijabarkan sebagai berikut.
- Memprediksi label pada data uji.
- Menghitung jumlah prediksi yang salah (error) kemudian membandingkannya dengan data label yang kita miliki.
- Dari data perbandingan ini, kita dapat menghitung akurasi atau performa model.
Beberapa metrik evaluasi yang umum digunakan tergantung pada jenis masalah yang dihadapi, contohnya seperti berikut.
- Akurasi: persentase prediksi yang benar dari total prediksi (digunakan untuk klasifikasi).
- Precision dan Recall: digunakan untuk masalah klasifikasi, terutama ketika data tidak seimbang.
- F1-Score: kombinasi precision dan recall yang lebih detail.
- Mean Squared Error (MSE) atau Mean Absolute Error (MAE): digunakan untuk regresi untuk mengukur seberapa jauh prediksi dari nilai sebenarnya.
- ROC-AUC Score: digunakan untuk mengevaluasi kinerja klasifikasi pada berbagai threshold.
- Dan lain sebagainya.
Pada prinsipnya proses model evaluation adalah menilai kinerja model ML pada data baru, yaitu data yang belum pernah “dilihat” oleh model sebelumnya.
Evaluasi model bertujuan untuk membuat estimasi generalisasi error (kesalahan) dari model yang dipilih, yaitu seberapa baik kinerja model tersebut pada data baru. Idealnya, model machine learning yang baik adalah model yang tidak hanya bekerja dengan baik pada data training, tetapi juga pada data baru.
Oleh karena itu, sebelum mengirimkan model ke tahap produksi, Anda harus cukup yakin bahwa performa model akan tetap baik dan tidak menurun saat dihadapkan dengan data baru. Psstt, sedikit spoiler jangan biarkan model Anda overfitting atau underfitting, ya!
Deployment
Pada umumnya, Anda akan sangat sibuk dan menghabiskan waktu hingga tahap evaluation, tetapi usaha itu akan menjadi sia-sia karena model yang dibangun tidak bisa digunakan oleh khalayak ramai (end-user). Tentunya itu akan sangat merugikan, ‘kan?

Model deployment adalah salah satu langkah terpenting dalam alur kerja machine learning. Model yang telah dilatih dan diuji diterapkan ke dalam lingkungan produksi sehingga dapat digunakan oleh pengguna akhir atau sistem untuk membuat prediksi pada data baru.
Proses ini tidak hanya mencakup memindahkan model dari fase pengembangan ke fase produksi, tetapi juga memastikan bahwa model berjalan dengan andal, cepat, dan aman dalam skala besar.
Lalu bagaimana cara melakukan deployment model tersebut? Caranya adalah dengan menyimpan model yang telah dilatih dari tahap preprocessing hingga pipeline prediksi. Kemudian, deploy model tersebut ke tahap produksi untuk membuat prediksi dengan memanggil kode predict()-nya. Sederhananya Geron [4] memberikan contoh ilustrasi model deployment seperti tampak dalam gambar berikut.
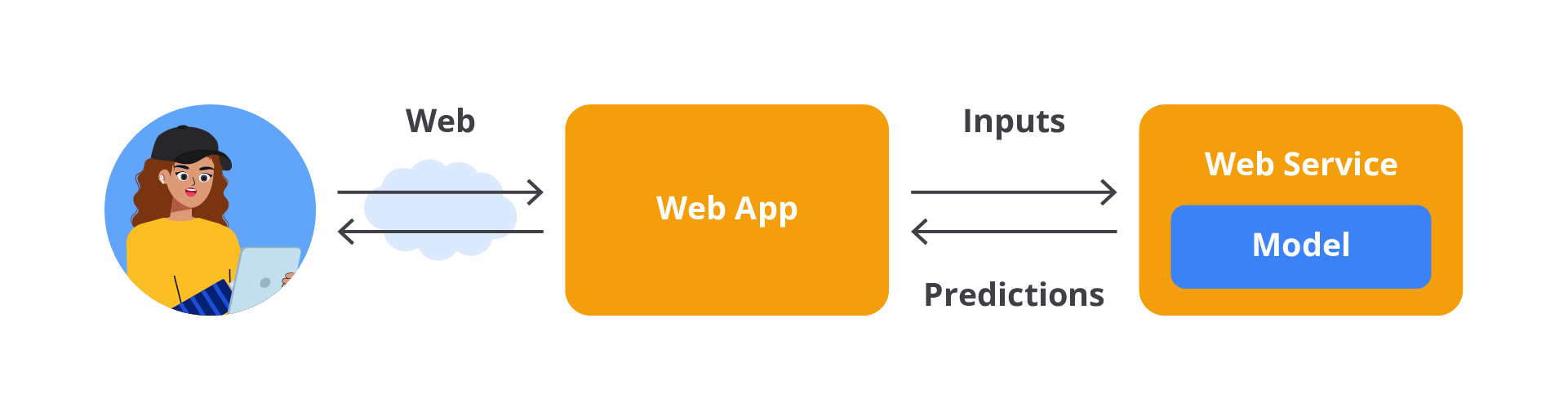
Bayangkan Anda sedang menggunakan sebuah situs web untuk memprediksi harga rumah. Di situs tersebut, Anda akan melihat sebuah formulir yang bisa memasukkan beberapa informasi, seperti lokasi rumah, luas rumah, jumlah kamar tidur, dan fasilitas lainnya. Setelah Anda memasukkan semua data yang diperlukan, Anda akan mengeklik tombol yang bertuliskan "Prediksi Harga".
Ketika Anda mengeklik tombol tersebut, berikut adalah proses yang terjadi di belakang layar.
- Saat Anda mengeklik tombol "Prediksi Harga", semua informasi yang telah Anda masukkan (misalnya, lokasi, ukuran rumah, dan jumlah kamar tidur) dikemas menjadi sebuah paket data yang disebut "input". Input ini kemudian dikirim dari browser Anda ke server yang menjalankan aplikasi web.
- Setelah server menerima input dari Anda, server tersebut akan mengarahkan data ini ke aplikasi web yang menjalankan model prediksi harga rumah. Aplikasi web ini telah dilengkapi dengan model machine learning, yaitu model regresi yang sebelumnya telah dilatih menggunakan data tentang harga rumah.
- Di dalam aplikasi web, data yang Anda kirimkan akan diproses oleh kode program yang ada. Kode program ini akan memanggil sebuah fungsi khusus yang disebut predict(). Fungsi predict() ini bekerja dengan memasukkan data yang Anda berikan ke dalam model regresi. Model ini kemudian akan menganalisis data tersebut—misalnya, mempertimbangkan lokasi rumah, ukuran, dan jumlah kamar tidur—untuk memperkirakan harga rumah yang sesuai berdasarkan pola-pola yang telah dipelajari sebelumnya.
- Setelah model menghasilkan prediksi harga, hasil tersebut akan dikirim kembali oleh server ke browser Anda. Dalam hitungan detik, Anda akan melihat hasil prediksi harga rumah yang muncul di layar situs web, berdasarkan data yang Anda masukkan.
Dengan demikian, proses ini memungkinkan Anda untuk mendapatkan estimasi harga rumah hanya dengan beberapa klik, dan semua pekerjaan berat dilakukan oleh model machine learning yang berjalan di server di belakang layar.
Monitoring
Ketika sebuah model machine learning sudah diterapkan dalam produksi dan digunakan oleh pengguna, pekerjaan belum selesai. Model ini masih perlu terus dipantau untuk memastikan bahwa ia tetap berfungsi dengan baik dan memberikan hasil yang akurat.
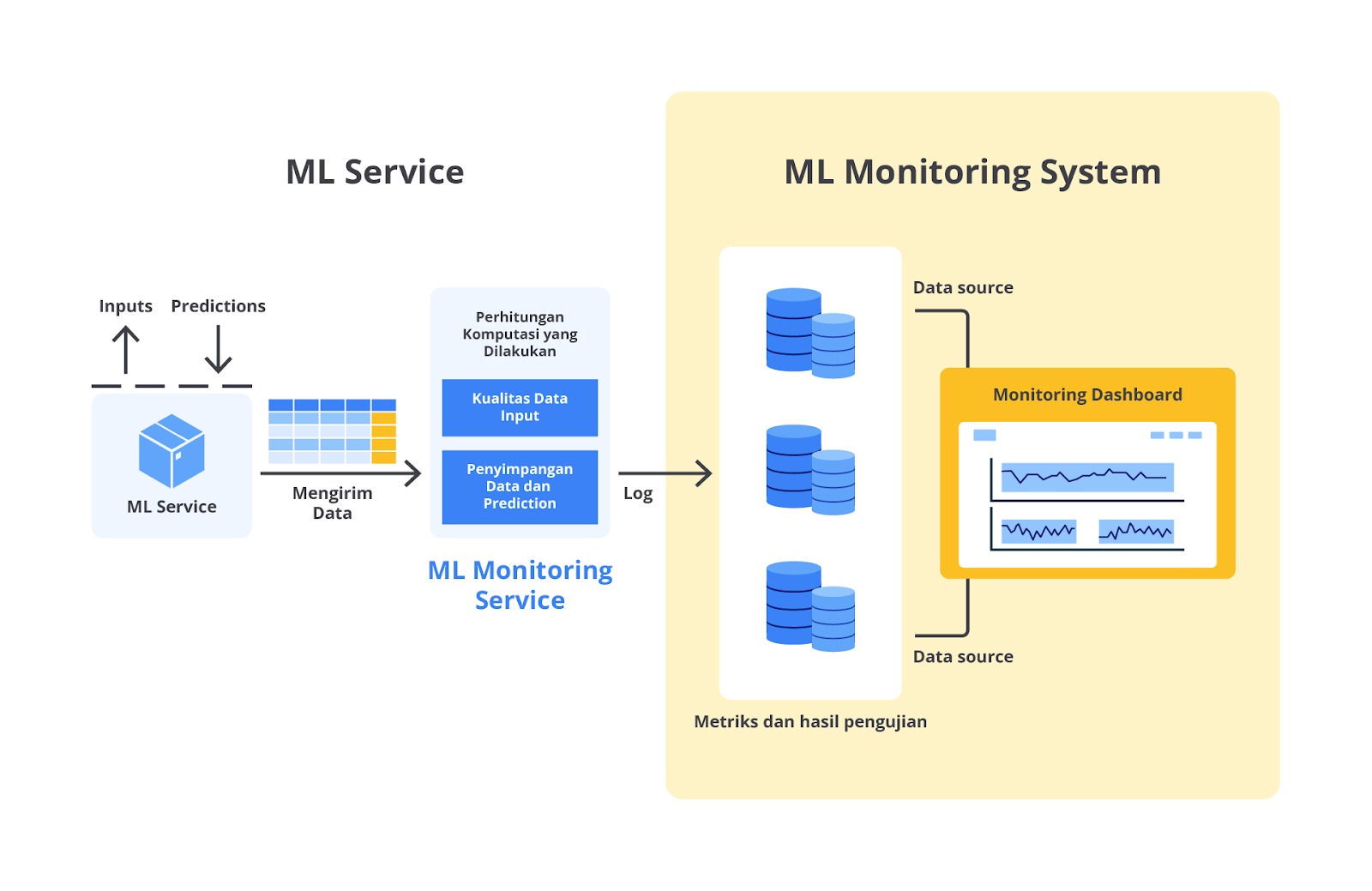
Hal ini sangat penting karena data yang dihadapi oleh model dalam tahap produksi bisa berbeda dari data yang digunakan saat model dilatih. Jika model bertemu dengan data yang tidak dikenali atau berbeda dari pola yang telah dipelajari, performanya bisa menurun seiring berjalannya waktu.
Contoh kasus misalnya jika Anda memiliki model machine learning yang digunakan dalam sistem rekomendasi produk di sebuah situs e-commerce. Model ini bertugas merekomendasikan produk kepada pengguna berdasarkan perilaku belanja mereka sebelumnya.
Untuk memastikan model ini bekerja dengan baik, Anda bisa memantau performanya dengan menghitung banyaknya produk rekomendasi yang benar-benar terjual setiap hari. Jika angka ini turun (dibandingkan dengan produk yang tidak direkomendasikan), kemungkinan model kita perlu dilatih ulang menggunakan data-data baru.
Jika Anda bekerja dalam lingkungan di mana data selalu berubah—seperti dalam e-commerce, media sosial, atau layanan streaming—melakukan update dataset dan melatih ulang model secara manual bisa menjadi pekerjaan yang berat dan tidak efisien.
Oleh karena itu, Anda mungkin perlu membangun sistem yang dapat melakukan pembaruan dataset dan pelatihan ulang model secara otomatis. Sistem ini bisa dijadwalkan untuk memproses data baru setiap minggu atau bulan, melatih model dengan data tersebut, dan kemudian menerapkan model yang telah diperbarui ke dalam produksi.
Dengan begitu, model Anda akan selalu up-to-date dan siap untuk memberikan hasil yang relevan meskipun lingkungan data di sekitar terus berubah. Sistem otomatis ini tidak hanya meningkatkan efisiensi, tetapi juga memastikan bahwa kualitas model tetap terjaga sepanjang waktu tanpa perlu intervensi manual yang sering.
Apakah sudah mulai terbayangkan portofolio yang akan Anda bangun di kemudian hari? Relaks saja tidak usah terburu-buru karena semua orang memiliki start yang berbeda-beda, tetapi bukan berarti Anda bisa berleha-leha, ya.
Machine learning adalah petualangan seru yang melibatkan banyak proses dan infrastruktur untuk membangun model yang hebat. Memahami algoritma itu penting, tetapi menguasai keseluruhan proses pembangunan machine learning hingga model siap digunakan di dunia nyata merupakan hal yang membuat Anda jadi master sejati!
Nantinya di kelas Belajar Fundamental Deep Learning, Anda akan diajak lebih jauh untuk belajar cara men-deploy model machine learning Anda ke tahap produksi. Jadi, siap-siap saja untuk melangkah lebih jauh! Terus semangat belajarnya, ya. Ciao!
Pengenalan Tools dan Library Populer pada Python untuk Machine Learning dan Data Science
Setelah memahami alur pengembangan machine learning, tentunya kurang afdal jika tidak mempelajari tools atau library yang sering digunakan ketika membangun model machine learning.
Library pada Python adalah kumpulan modul yang berisi kode-kode fungsional yang telah ditulis sebelumnya dan dapat digunakan kembali untuk menyelesaikan berbagai tugas. Modul ini bisa mencakup fungsi, kelas, dan variabel yang dapat diimpor ke dalam program Python Anda untuk mempermudah pengembangan perangkat lunak.
Library akan sangat membantu Anda untuk menyelesaikan tugas-tugas dengan lebih efisien dan efektif dengan menyediakan fungsi-fungsi siap pakai yang bisa langsung digunakan tanpa perlu menulis ulang kode dari awal.
Ngomong-ngomong, Python telah menjadi bahasa yang sangat populer di kalangan data scientist dan praktisi machine learning karena ekosistemnya yang kaya akan library dan alat yang memudahkan proses analisis data, visualisasi, serta pengembangan model machine learning.
Python adalah kombinasi antara general-purpose programming language yang powerful dan domain-specific scripting language yang mudah digunakan. Lalu, mengapa Python sangat populer? Salah satu alasan yang menarik adalah beberapa perusahaan teknologi raksasa seperti Google dan Facebook memilih Python sebagai bahasa utama untuk framework machine learning mereka, yaitu TensorFlow dan PyTorch.
Python memiliki keunggulan luar biasa yang membuatnya sangat menarik bagi siapa saja yang ingin terjun ke dunia machine learning atau data science. Salah satu keunggulannya adalah Python sangat mudah dipelajari, bahkan untuk mereka yang tidak memiliki latar belakang IT. Dengan sintaks yang sederhana dan intuitif, Python menjadi jembatan yang memudahkan siapa saja untuk memulai perjalanan mereka dalam dunia teknologi.
Tidak hanya itu, Python juga menawarkan fleksibilitas luar biasa melalui dua mode utama: script mode dan interactive mode. Keduanya memberikan cara yang berbeda untuk menulis dan menjalankan kode, tergantung pada kebutuhan Anda.
Apa itu script mode dan interactive mode?
Mari kita mulai dengan script mode. Bayangkan Anda sedang menulis sebuah cerita panjang—mode ini adalah tempat Anda bisa menuangkan ide-ide kompleks dan mendalam ke dalam sebuah file teks (biasanya dengan ekstensi .py).
Setelah selesai, Anda dapat menjalankan kode tersebut melalui compiler atau interpreter dan melihat keseluruhan hasilnya. Mode script ini sangat disukai oleh para ahli yang sudah berpengalaman dalam pemrograman Python karena memungkinkan mereka untuk menulis dan mengatur kode yang lebih kompleks dan terstruktur.
Di sisi lain, ada interactive mode, pendekatan ini seperti bermain dengan alat musik—Anda bisa langsung mencoba berbagai nada dan ritme, melihat hasilnya dengan lebih cepat atau instant. Di mode ini, Anda bisa menulis satu baris kode, mengeksekusinya, dan langsung melihat hasilnya.
Ini adalah cara yang sangat menyenangkan dan efisien untuk bereksperimen dan belajar, terutama bagi pemula yang sedang mengeksplorasi berbagai sintaks dan fitur Python. Mode interaktif ini memungkinkan Anda untuk mendapatkan umpan balik langsung yang sangat membantu dalam memahami cara kerja Python dengan lebih cepat dan efektif.
Dengan kemudahan belajar dan fleksibilitas dalam penulisan kode, Python benar-benar menjadi bahasa pemrograman yang penuh potensi dan menyenangkan untuk dipelajari, baik bagi pemula maupun profesional.
Untuk menunjang kemudahan Python, berikut adalah beberapa tools dan library yang paling populer dan sering digunakan dalam dunia machine learning dan data science.
Tools untuk Pemrograman Python
Bersiaplah karena pada sub-modul ini kita akan menjelajahi dunia luar biasa dari tools interaktif yang sering digunakan dalam pemrograman Python! Kelas ini akan mengenalkan Anda pada tiga tools yang sering kali menjadi senjata andalan para ahli data science dan machine learning. Tools ini tidak hanya memudahkan Anda menulis dan menjalankan kode, tetapi juga memberi Anda kekuatan untuk mengatur alur kerja dengan cara yang efisien dan menyenangkan.
Ketiga tools ini adalah web-based interactive development environments yang lebih dikenal dengan sebutan Notebook. Notebook menawarkan antarmuka yang fleksibel dan user-friendly, memungkinkan Anda untuk langsung menulis kode, mengeksekusinya, dan melihat hasilnya dalam satu platform yang terpadu. Anda juga bisa membuat konfigurasi, mengatur workflow, dan mengelola proyek data science Anda dengan cara yang lebih intuitif.
Apa saja tools hebat yang akan kita bahas? Ayo, kita mulai petualangan kita sekarang dan temukan bagaimana Notebook bisa menjadi katalisator untuk kemajuan Anda di dunia data science dan machine learning!
Jupyter Notebook
Jupyter Notebook adalah perangkat lunak gratis, open-source, dan layanan web yang mendukung berbagai bahasa pemrograman, termasuk Python.

Jupyter Notebook memberi Anda kekuatan untuk menulis kode, menjalankannya, dan langsung melihat hasilnya dalam satu platform yang intuitif. Instalasi Jupyter Notebook sangat mudah dan bisa dilakukan dengan beberapa cara. Silakan kunjungi panduan resmi Jupyter Notebook untuk detail lebih lanjut. Jika Anda tidak sabar untuk langsung mulai, gunakan Jupyter Notebook langsung di browser Anda dengan mengunjungi https://jupyter.org/try, lalu pilih Jupyter Notebook. Selamat bersenang-senang dengan mengeksplorasi potensi tak terbatas dengan Jupyter Notebook, enjoy!
Google Colaboratory
Selanjutnya, mari kita kenalan dengan Google Colaboratory, atau yang sering disebut Colab—alat revolusioner yang memungkinkan Anda menulis dan menjalankan kode Python langsung melalui browser.

Colab adalah salah satu sahabat terbaik Anda dalam dunia machine learning dan analisis data, terutama jika Anda baru mulai mengeksplorasi bidang ini. Tidak perlu repot menginstal apa pun, cukup buka browser dan kunjungi https://colab.research.google.com/notebooks/ untuk langsung mulai petualangan bersama Colab.
IBM Watson Studio
IBM Watson Studio merupakan salah satu layanan dari IBM yang banyak digunakan oleh analis dan ilmuwan data. Anda juga dapat menjalankan kode secara online pada layanan seperti IBM Watson Studio tanpa perlu menginstal perangkat lunak apa pun pada komputer. Sebelum menggunakan IBM Watson Studio, buatlah akun IBM Cloud terlebih dahulu. Akun IBM Cloud dapat dipakai untuk mengakses IBM Watson Studio, IBM Watson Machine Learning, dan IBM Cloud.

Lakukan beberapa hal berikut untuk mengakses IBM Watson Studio.
- Buatlah akun pada IBM Cloud dengan mengunjungi tautan ini kemudian lakukan registrasi menggunakan email Anda.
- Selanjutnya, setelah akun Anda jadi, login ke IBM Cloud dengan mengunjungi tautan https://cloud.ibm.com/login. Isi kolom IBMid dengan email yang telah Anda daftarkan di tahap sebelumnya.
- Setelah login ke akun IBMCloud, ketiklah Object Storage pada search bar. Pada laman Object Storage, pilih Lite pada bagian Plan. Perhatikan bahwa satu akun hanya dapat memiliki 1 Object Storage bertipe Lite. Jika Anda telah membuat object storage bertipe Lite sebelumnya, Anda harus menghapus dahulu object storage tersebut untuk bisa membuat object storage lite baru.
- Langkah berikutnya adalah login ke IBM Watson Studio menggunakan akun IBM Cloud Anda melalui tautan berikut.
- Terakhir, buatlah Project di lBM Watson Studio dan tambahkan Asset baru (Jupyter Notebook Editor) dalam project Anda.
Sampai pada tahap ini, Diana dan Bilqis sudah memiliki senjata yang cukup lengkap untuk memulai ke jenjang yang lebih serius. Tentunya Anda juga perlu menentukan tools yang paling cocok dengan preferensi sehingga dapat memaksimalkan pengalaman Anda ketika membangun model machine learning.
Library Populer untuk Machine Learning dan Data Science
Python telah menjadi bahasa pilihan bagi banyak data scientist dan engineer karena kekayaan ekosistem library yang dimilikinya. Library ini mempermudah berbagai aspek dalam data science dan machine learning, mulai dari manipulasi data, visualisasi, hingga pengembangan model machine learning. Dalam materi ini, kita akan membahas beberapa library Python yang paling populer dan sering digunakan dalam bidang ini.
NumPy
NumPy adalah library dasar untuk komputasi numerik di Python. Library ini menyediakan dukungan untuk array multidimensi dan berbagai fungsi matematika yang cepat dan efisien.

NumPy sangat terkenal sebagai library untuk memproses larik atau array. Fungsi-fungsi kompleks di baliknya membuat Numpy sangat tangguh dalam memproses larik multidimensi dan matriks berukuran besar. Library ML seperti TensorFlow juga menggunakan Numpy untuk memproses tensor atau sebuah larik N dimensi.
Fungsi utama NumPy bertugas untuk melakukan operasi vektor dan matriks, aljabar linear, transformasi fourier, dan fungsi matematika lainnya. Berikut contoh penggunaan NumPy.
- import numpy as np
- array = np.array([1, 2, 3, 4])
- print(array.mean()) # Output: 2.5
Pandas
Pandas adalah library yang digunakan untuk manipulasi dan analisis data, terutama data yang terstruktur dalam bentuk tabel. Dengan Pandas, Anda dapat dengan mudah melakukan operasi filtering, agregasi, dan manipulasi data lainnya.

Pandas menjadi salah satu library favorit untuk analisis dan manipulasi data. Kenapa keduanya penting? Sebelum masuk ke tahap pengembangan model, data perlu diproses dan dibersihkan. Proses ini bahkan merupakan proses yang paling banyak memakan waktu dalam pengembangan proyek machine learning. Library pandas membuat pemrosesan dan pembersihan data menjadi lebih mudah. Berikut contoh penggunaan Pandas.
- import pandas as pd
- df = pd.read_csv('data.csv')# Masukkan alamat penyimpanan file Anda
- print(df.head()) # Menampilkan 5 baris pertama dari dataset
Matplotlib
Matplotlib adalah sebuah library untuk membuat plot atau visualisasi data dalam 2 dimensi. Matplotlib mampu menghasilkan grafik dengan kualitas tinggi. Matplotlib dapat dipakai untuk membuat plot seperti histogram, scatter plot, grafik batang, pie chart, hanya dengan beberapa baris kode. Library ini sangat ramah pengguna.
Bahkan Seaborn dibangun di atas Matplotlib dan menawarkan antarmuka yang lebih ramah pengguna serta visualisasi statistik yang lebih canggih. Fungsi utama Matplotlib adalah membuat grafik dasar seperti bar plot, scatter plot, dan histogram (Matplotlib) dan membuat visualisasi statistik seperti heatmap, box plot, dan violin plot (Seaborn). Berikut adalah contoh penggunaan Matplotlib.
- import matplotlib.pyplot as plt
- import seaborn as sns
- sns.set(style="darkgrid")
- sns.histplot(data=df, x="column1") #Pastikan Anda sudah mengimport dataframe
- plt.show()
Scikit Learn
Scikit-Learn adalah library machine learning yang menyediakan berbagai algoritma pembelajaran mesin serta alat untuk preprocessing data, evaluasi model, dan tuning hyperparameter.

Scikit Learn merupakan salah satu library machine learning yang sangat populer. Scikit Learn menyediakan banyak pilihan algoritma machine learning yang dapat langsung dipakai, seperti klasifikasi, regresi, clustering, dimensionality reduction, dan pemrosesan data. Selain itu Scikit Learn juga dapat dipakai untuk analisis data.
Nah, pada kelas ini kita akan sering bermain-main dengan Scikit Learn baik itu untuk menangani klasifikasi, regresi hingga klastering. Menarik, ‘kan? Sebelum kita bermain, alangkah baiknya mengetahui fungsi utama dari alat yang akan digunakan.
Fungsi utama Scikit Learn adalah.
- Implementasi algoritma machine learning seperti klasifikasi, regresi, dan clustering.
- Pipeline untuk mengotomatisasi alur kerja machine learning.
- Alat evaluasi model seperti cross-validation dan metrik performa.
TensorFlow

TensorFlow adalah framework open source untuk machine learning yang dikembangkan dan digunakan oleh Google. TensorFlow memudahkan pembuatan model ML bagi pemula maupun ahli. Ia dapat dipakai untuk deep learning, computer vision, pemrosesan bahasa alami (Natural Language Processing), serta reinforcement learning.
PyTorch

Dikembangkan oleh Facebook, PyTorch adalah library yang dapat dipakai untuk masalah ML, computer vision, hingga pemrosesan bahasa alami. Bersaing dengan TensorFlow khususnya sebagai framework machine learning, PyTorch lebih populer di kalangan akademisi dibanding TensorFlow. Namun, dalam industri, TensorFlow lebih populer karena skalabilitasnya lebih baik dibanding PyTorch.
Keras

Keras adalah library deep learning yang luar biasa. Salah satu faktor yang membuat Keras sangat populer adalah penggunaannya yang minimalis dan simpel dalam mengembangkan deep learning. Keras dibangun di atas TensorFlow yang menjadikan Keras sebagai API dengan level lebih tinggi (Higher level API) dari TensorFlow sehingga antarmukanya lebih mudah dari TensorFlow. Keras sangat cocok untuk mengembangkan model deep learning dengan waktu yang lebih singkat atau untuk pembuatan prototipe.
NLTK dan SpaCy
NLTK (Natural Language Toolkit) dan SpaCy adalah library untuk Natural Language Processing (NLP). NLTK lebih banyak digunakan dalam riset dan pendidikan, sedangkan SpaCy lebih fokus pada kecepatan dan produksi.
Fungsinya NLTK dan SpaCy adalah sebagai berikut.
- Melakukan pemrosesan teks seperti tokenisasi, stemming, dan lemmatization.
- Ekstraksi entitas bernama, parsing sintaksis, dan analisis teks.
- Pipeline NLP yang lengkap untuk aplikasi seperti analisis sentimen dan chatbot.
Berikut adalah contoh penggunaan NLTK.
- import nltk
- sentence = """At eight o'clock on Thursday morning
- ... Arthur didn't feel very good."""
- tokens = nltk.word_tokenize(sentence)
- tokens
- # ['At', 'eight', "o'clock", 'on', 'Thursday', 'morning', 'Arthur', 'did', "n't", 'feel', 'very', 'good', '.']
- tagged = nltk.pos_tag(tokens)
- tagged[0:6]
- # [('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'), ('on', 'IN'), ('Thursday', 'NNP'), ('morning', 'NN')]
SciPy

SciPy adalah library yang menyediakan berbagai algoritma dan fungsi untuk komputasi ilmiah dan teknik. SciPy sering digunakan bersama NumPy untuk operasi yang lebih kompleks. Fungsi utama dari library ini untuk melakukan optimisasi, integrasi, dan pemecahan persamaan diferensial serta pengolahan sinyal dan gambar, serta analisis statistik. Berikut adalah contoh penggunaan library SciPy.
- from scipy import optimize
- def f(x):
- return x**2 + 5*x + 6
- result = optimize.minimize(f, 0)
- print(result)
Nah, di atas adalah beberapa contoh library yang sering digunakan dalam pengembangan machine learning. Tentunya masih banyak sekali library lainnya yang bisa membantu Anda membangun model machine learning dengan optimal.
Dengan menguasai beberapa library tersebut, Diana dan Bilqis akan memiliki fondasi yang kuat dalam dunia machine learning dan data science. Perlu Anda catat bahwa setiap library memiliki keunggulan dan kegunaannya masing-masing, alat ini akan membantu Anda untuk melakukan berbagai tugas mulai dari manipulasi data hingga pengembangan model machine learning yang canggih.
Sebagai catatan, silakan pelajari dan eksplorasi lebih lanjut setiap library yang ada untuk memperdalam pemahaman Anda, ya. Sampai jumpa pada latihan modul berikutnya!
Data Collecting
Perjalanan Diana dan Bilqis sudah mencapai babak yang baru karena pada tahap ini mereka akan memulai tahapan nyata dalam pembangunan model machine learning. Pada materi sebelumnya mereka telah belajar tentang pengenalan machine learning dan proses pengembangan machine learning. Namun, semua hal itu tidak akan ada artinya jika tidak memulai terjun ke lapangan ‘kan?
Jangan khawatir kita akan menemani perjalanan mereka sedikit demi sedikit. Mari kita mulai dengan membayangkan Anda sedang membangun sebuah gedung pencakar langit yang megah. Sebelum mulai mendirikan bangunan, Anda tentu membutuhkan fondasi yang kuat.
Dalam machine learning, data collecting adalah fondasi tersebut. Tanpa data yang tepat dan berkualitas, model machine learning Anda tidak akan mampu berdiri kokoh, apalagi memberikan hasil yang andal.
“Data is the new oil. It’s valuable, but if unrefined it cannot really be used. It has to be changed into gas, plastic, chemicals, etc to create a valuable entity that drives profitable activity; so must data be broken down, analyzed for it to have value.”
— Clive Humby —
Kutipan di atas adalah kalimat terkenal tentang data yang pertama kali disampaikan oleh Clive Humby, seorang matematikawan asal Inggris pada tahun 2006. Kutipan tersebut menjadi sangat populer setelah The Economist memublikasikan laporan tahun 2017 yang berjudul The World’s most valuable resource is no longer oil, but data.

Perangkat cerdas dan internet telah membuat data menjadi berlimpah. Banjir arus data yang terjadi di era digital mengubah sifat persaingan. Perusahaan teknologi raksasa berlomba-lomba mengumpulkan banyak data untuk meningkatkan produknya, menarik lebih banyak pengguna, menghasilkan lebih banyak data, dan seterusnya.
Mereka menjangkau seluruh sektor ekonomi: Google bisa melihat apa yang ditelusuri dan dicari oleh orang-orang, Facebook bisa melihat apa yang mereka bagikan, dan Amazon mengetahui apa yang mereka beli. Mereka seolah memiliki “God’s eyes view” tentang aktivitas di pasar mereka sendiri dan sekitarnya.
Luar biasa, ya? Sekarang hampir semua perusahaan mengumpulkan data untuk sumber daya mereka.
Lantas apa itu data collecting atau pengumpulan data? Data collecting adalah langkah pertama dalam alur kerja machine learning di mana Anda mengumpulkan semua informasi yang dibutuhkan untuk melatih model. Data ini bisa datang dari berbagai sumber dan dalam berbagai bentuk—mulai dari data numerik, teks, gambar, hingga data kategori. Kualitas dan kuantitas data yang Anda kumpulkan akan sangat menentukan performa model machine learning yang Anda bangun.

Proses pengumpulan data adalah jantung dari proyek machine learning. Tanpa data yang cukup dan relevan, model Anda tidak akan bisa belajar dengan baik. Ibarat seorang murid yang mencoba memahami pelajaran baru, model machine learning juga membutuhkan banyak contoh (data) untuk bisa memahami pola dan membuat prediksi yang akurat. Hal ini sudah sangat sering dikumandangkan pada kutipan “Garbage In Garbage Out” yang secara singkat berarti data yang digunakan akan menghasilkan output yang serupa.

Berdasarkan penjelasan di atas, Diana masih memiliki sebuah pertanyaan “Mengapa data collecting sepenting itu, ya? Kan yang sulit pembuatan modelnya.” Pertanyaan tersebut merupakan hal umum yang sering terjadi ketika memulai belajar machine learning. Mari kita kupas tuntas beberapa alasan mengapa data collecting itu sangat penting.
- Menentukan Akurasi Model
Makin banyak data relevan yang dikumpulkan, makin baik model Anda dalam memahami pola dan membuat prediksi. Namun, kualitas data juga penting—data yang penuh dengan noise atau outlier bisa mengaburkan pola sebenarnya dan menurunkan akurasi model. - Mencegah Bias
Data yang tidak lengkap atau tidak seimbang bisa menyebabkan model bias terhadap kelompok tertentu. Dengan mengumpulkan data dari berbagai sumber dan memastikan representasi yang seimbang, Anda dapat mengurangi risiko bias dalam model Anda. - Mengakomodasi Variasi
Dunia nyata penuh dengan variasi, dan model machine learning perlu dilatih dengan data yang mencerminkan variasi ini. Dengan mengumpulkan data dari berbagai kondisi, Anda membantu model Anda untuk lebih adaptif dan mampu menangani situasi yang berbeda-beda.
Lantas, bagaimana cara mengumpulkan data? Pertama-tama mari kita mundur sedikit dengan menentukan sumber data yang bisa kita gunakan mulai dari data internal, data eksternal, data sintetis hingga data yang dihasilkan dari pengguna. Tentunya ini akan sangat membantu Anda menentukan cara pengumpulan data kelak. Mari kita bahas satu per satu.
- Data Internal
Banyak perusahaan memiliki data sendiri yang berasal dari operasional bisnis mereka, seperti data penjualan, data pelanggan, atau data log dari aplikasi. Data ini sangat berharga karena biasanya sudah terstruktur dan sesuai dengan kebutuhan bisnis. - Data Eksternal
Jika data internal tidak cukup, Anda bisa mencari data eksternal. Ini bisa berupa data publik dari pemerintah, data yang diambil dari internet (web scraping), atau data yang dibeli dari penyedia data. - Data Sintetis
Dalam beberapa kasus, data nyata mungkin sulit didapatkan. Di sini, data sintetis bisa digunakan. Ini adalah data yang dibuat secara artifisial berdasarkan karakteristik dari data nyata. - Data yang Dihasilkan dari Pengguna
Pengguna aplikasi atau platform Anda bisa menjadi sumber data yang sangat berharga. Data ini bisa berupa interaksi pengguna, ulasan produk, atau perilaku penelusuran.
Nah, sekarang Anda sudah mengetahui berbagai sumber data yang bisa digunakan. Selanjutnya, mari kita bahas tiga cara yang bisa kita lakukan untuk mengumpulkan data.
- Mengekstrak data (misal dari internet, riset, survei, dll).
Biasanya hal ini disebut dengan scraping website. Teknik ini akan melakukan ekstraksi data secara otomatis dari situs website dengan struktur yang dapat Anda sesuaikan. Tenang saja, kita akan mempelajari tahapan ini secara detail pada kelas berikutnya. - Mengumpulkan dan membuat dataset Anda sendiri dari nol.
Anda juga dapat membuat dataset sendiri mulai dari melakukan survei, membuat sebuah aplikasi yang dapat mengolah data, atau menggabungkan beberapa dataset dari data internal perusahaan tempat Anda bekerja. Tentunya dengan membuat dataset dari nol, Anda memiliki keleluasaan sepenuhnya atas informasi dan struktur yang ingin dicapai. - Menggunakan dataset yang telah ada.
Saat ini ada berbagai macam penyimpanan data yang dibagikan secara publik mulai dari lisensi yang dapat digunakan secara bebas hingga terdapat beberapa batasan khusus. Tentunya dengan menggunakan dataset yang sudah ada Anda akan menghemat banyak waktu karena akan melewati tahapan data collecting yang memakan waktu.
Setelah memiliki bekal terkait pengumpulan alangkah lebih baiknya Anda juga mempelajari langkah-langkah yang umum dilakukan untuk melakukan pengumpulan data. Berangkat dari pengetahuan yang sudah dipelajari pada materi ini, mari kita bahas langkah-langkah dalam proses pengumpulan data.
- Menentukan Kebutuhan Data.
Sebelum mengumpulkan data, Anda harus memperjelas objektif tentang apa yang ingin Anda prediksi atau analisis. Ini akan membantu Anda menentukan jenis data apa yang perlu dikumpulkan dan dalam jumlah berapa.
- Memilih Sumber Data.
Setelah mengetahui kebutuhan Anda, langkah selanjutnya adalah memilih sumber data yang sesuai. Apakah Anda akan menggunakan data internal, mengunduh data publik, atau melakukan survei sendiri?
- Mengumpulkan dan Menyimpan Data.
Setelah sumber data dipilih, Anda mulai mengumpulkan data. Ini bisa melalui API, survei, scraping web, atau impor data dari file. Pastikan data disimpan dengan baik dan aman, serta dalam format yang mudah diakses untuk analisis lebih lanjut.
- Validasi dan Pembersihan Data.
Data yang terkumpul mungkin mengandung kesalahan atau data yang hilang. Oleh karena itu, proses validasi dan pembersihan data penting untuk memastikan data yang Anda gunakan berkualitas tinggi.
Sampai pada tahap ini Anda sudah mengetahui secara utuh tahapan pengumpulan data, tetapi untuk mempermudah pemahaman mari kita bayangkan beberapa studi kasus.
Bayangkan Anda ingin membangun model machine learning untuk memprediksi harga rumah. Langkah pertama yang Anda lakukan adalah mengumpulkan data. Anda bisa mengumpulkan data dari beberapa sumber berikut.
- Website properti untuk mendapatkan informasi harga, lokasi, ukuran rumah, dan tahun bangunan.
- Data ekonomi dari pemerintah yang memberikan informasi mengenai tingkat bunga hipotek dan tren pasar properti.
- Data survei pelanggan untuk mendapatkan preferensi dan kebutuhan dari calon pembeli rumah.
Setelah data terkumpul, Anda membersihkannya, memastikan tidak ada data yang hilang, dan mulai menggunakannya untuk melatih model prediksi harga rumah. Dengan data yang tepat, model Anda akan mampu memberikan estimasi harga rumah yang akurat.
Akhirnya Diana dan Bilqis telah menguasai teori pengumpulan data, tetapi pengetahuan tersebut masih terasa “pincang”. Mengapa hal itu bisa terjadi? Ada sebuah kalimat intermezzo yang menarik untuk Anda pelajari.

Dari kutipan di atas, tentunya kita tidak mendapatkan pengalaman yang maksimal ketika mengetahui salah satunya saja. Untuk memenuhi kebutuhan tersebut, mari kita lakukan praktik pada proses pengumpulan data pada materi berikutnya.
Latihan: Mengumpulkan Data dari Sumber Terbuka
Sebelum memulai latihan ini, mari kita sejenak berhenti dan memastikan bahwa “modal” pengetahuan kita sudah benar-benar siap. Jika Anda merasa sudah memahami dasarnya, itu tentu kabar baik. Namun, tidak ada salahnya untuk melakukan sedikit recall terhadap materi sebelumnya agar pemahaman kita kembali segar dan berada di jalur yang sama.
Kesimpulan dari materi sebelumnya adalah teori terkait data collecting. Data collecting adalah fondasi yang akan menentukan seberapa sukses model machine learning Anda. Mengumpulkan data dari sumber yang relevan dalam jumlah yang cukup adalah kunci untuk membangun model yang kuat dan andal.
Jadi, pastikan Anda tidak terburu-buru dalam materi ini—luangkan waktu untuk mengumpulkan dan memahami data Anda karena ini adalah investasi terbaik yang bisa Anda lakukan untuk kesuksesan sebuah model.
Ngomong-ngomong investasi tentunya akan lebih baik jika kita juga menambahkan “modal” baru agar menghasilkan output yang lebih maksimal. Nah, pada materi ini, kita akan melakukan praktik pengumpulan data agar mendapatkan pengalaman yang lebih maksimal.
Untuk saat ini, kita akan menggunakan dataset yang sudah ada dari platform penyedia data. Di masa mendatang tentu Anda dapat mencoba mengekstrak atau mengumpulkan dataset sendiri ya.
Psstt, Anda tidak perlu menunggu lama lho karena pada kelas berikutnya Anda sudah bisa mengumpulkan dataset sendiri. Semangaatt~
Menentukan Sumber Dataset
Menemukan dataset yang tepat adalah salah satu langkah penting dalam proyek machine learning. Saat ini, tersedia banyak sumber data di internet yang dapat kita manfaatkan.
Mari kita bahas beberapa sumber yang perlu Anda ketahui sebagai seorang machine learning engineer atau data scientist.
UC Irvine Machine Learning Repository

UCI ML Repository adalah salah satu sumber daya paling populer di dunia untuk dataset yang digunakan dalam penelitian dan pengembangan machine learning. Repositori tersebut awalnya dibuat sebagai arsip ftp pada tahun 1987 oleh David Aha, seorang mahasiswa pascasarjana UC Irvine. Saat ini arsip ini dikelola oleh University of California, Irvine, repositori ini berisi berbagai dataset yang dapat digunakan oleh peneliti, akademisi, dan praktisi machine learning untuk mengembangkan, menguji, dan memvalidasi model mereka.
Repositori ini menawarkan dataset dari berbagai bidang yang memungkinkan eksplorasi dan penelitian dalam berbagai jenis masalah machine learning. Setiap dataset dilengkapi juga dengan deskripsi yang detail, termasuk atribut, ukuran, sumber, publikasi, dan lisensi terkait.
Salah satu keuntungan besar yang diberikan repositori ini adalah aksesnya. Semua dataset yang disediakan dapat diakses secara gratis, yang membuatnya menjadi sumber daya yang sangat berharga untuk penelitian akademis maupun pengembangan model komersial.
Kaggle Dataset

Kaggle adalah platform online yang menyediakan lingkungan bagi para data scientist, peneliti, dan penggemar machine learning untuk berkolaborasi, berkompetisi, dan mempelajari berbagai aspek data science. Didirikan pada tahun 2010 dan sekarang dimiliki oleh Google, Kaggle dikenal sebagai salah satu komunitas terbesar di dunia bagi para praktisi data science dan machine learning.
Sedikit berbeda dengan UCI Repository, Kaggle terkenal karena kompetisi data science-nya, di mana perusahaan atau organisasi memberikan masalah nyata yang perlu dipecahkan. Peserta bersaing untuk menghasilkan model machine learning terbaik dengan hadiah yang menarik.
Kelebihan lainnya yang dimiliki Kaggle adalah kernels/notebook yang sudah built-in. Kaggle menyediakan platform untuk menulis dan menjalankan kode Python dan R secara langsung di browser melalui Kaggle Notebooks (dahulu dikenal sebagai Kaggle Kernels). Ini memudahkan pengguna untuk bereksperimen dengan dataset tanpa harus mengunduh atau menginstal software tambahan.
Terakhir untuk memaksimalkan pengalaman pengguna Kaggle menyediakan dua buah fitur yang sangat berguna, yaitu Discussion and Courses dan Community and Collaboration.
Kaggle memiliki forum diskusi yang aktif. Di sana,pengguna bisa bertanya, berdiskusi, dan berbagi pengetahuan. Selain itu, Kaggle juga menyediakan kursus online gratis untuk mempelajari dasar-dasar data science dan machine learning. Di lain sisi, Kaggle adalah tempat para data scientist dari seluruh dunia berkumpul, belajar, dan berkolaborasi. Anda bisa mengikuti user lain, belajar dari notebook mereka, atau, bahkan bergabung dalam tim untuk mengerjakan kompetisi bersama.
Dengan berbagai kelebihannya, Kaggle saat ini sangat mendominasi pengguna yang sedang belajar machine learning atau data science. Oleh karena itu, jangan sampai ketinggalan, silakan membuat akun Kaggle agar dapat menikmati semua fiturnya. Silakan eksplorasi Kaggle secara mandiri dan bersiap untuk membuat model machine learning pada submission kelas ini.
Google Dataset Search Engine
Google Dataset Search Engine adalah alat pencarian yang dikembangkan oleh Google untuk membantu peneliti, data scientist, dan siapa saja yang membutuhkan data untuk menemukan dataset yang tersedia secara online. Dataset Search ini mirip dengan mesin pencari Google biasa, tetapi fokusnya adalah pada dataset yang disimpan pada berbagai platform, baik yang bersifat publik maupun dari organisasi atau institusi tertentu.
Kelebihan dari Dataset Search adalah dapat menyimpan metadata dari dataset yang dipublikasikan di web serta memungkinkan pengguna untuk menemukan dataset yang relevan berdasarkan kata kunci pencarian. Metadata yang diindeks mencakup informasi seperti judul dataset, deskripsi, penerbit, tanggal publikasi, dan lain-lain, yang memungkinkan pengguna untuk menilai relevansi dataset sebelum mengunduh atau mengaksesnya.
TensorFlow Dataset
Seperti yang telah dijelaskan pada materi sebelumnya, TensorFlow adalah framework open source untuk machine learning yang dikembangkan dan digunakan oleh Google. Selain menyediakan learning resources, tensorflow juga menyediakan data resources yang cukup lengkap di library-nya mulai dari audio data, images, text, video, dan lainnya yang tersimpan di TensorFlow Datasets.
TensorFlow Dataset (TFDS) adalah kumpulan koleksi dataset yang sudah diproses dan diformat khusus untuk digunakan dengan TensorFlow, sebuah framework open-source yang banyak digunakan untuk machine learning dan deep learning. TFDS menyediakan dataset yang siap digunakan untuk berbagai tugas seperti klasifikasi gambar, pemrosesan bahasa alami, dan lain-lain. Dataset yang disediakan oleh TFDS tersedia dalam berbagai ukuran dan kompleksitas, dan dapat diakses langsung di dalam TensorFlow tanpa perlu langkah preprocessing tambahan.
TFDS menyediakan dataset dalam format tf.data.Dataset, yang merupakan API TensorFlow untuk menangani input pipeline. Ini memudahkan pengguna untuk mengintegrasikan dataset ke dalam pipeline pelatihan model, termasuk pembagian dataset menjadi training, validation, dan test set. Simpan terlebih dahulu rasa penasaran karena Anda akan mempelajari TFDS secara lengkap pada kelas berikutnya, ya.
Jika Anda menggunakan TensorFlow sebagai framework utama pembangunan machine learning itu akan memberikan beberapa keuntungan yang sangat signifikan seperti preprocessing otomatis, terintegrasi dengan TensorFlow hingga augmentasi yang lebih mudah.
Sebagai informasi, dataset di TFDS sudah diatur dalam format yang siap digunakan, termasuk pembagian ke dalam training dan test set sehingga pengguna tidak perlu melakukan banyak preprocessing tambahan.
Selain itu, dataset yang diakses melalui TFDS disiapkan dalam format yang langsung kompatibel dengan TensorFlow, memudahkan pengguna untuk menggunakan dataset tersebut ke dalam model dengan lebih seamless.
Terakhir, TFDS mendukung augmentasi data yang memungkinkan pengguna untuk memperkaya dataset dengan variasi baru, seperti rotasi gambar, flipping, atau perubahan warna dengan lebih mudah menggunakan fungsi yang sudah disediakan.
US Government Data

US Government Data mengacu pada berbagai dataset yang disediakan oleh pemerintah Amerika Serikat untuk publik. Bagi Anda yang tertarik untuk mempelajari fenomena yang terjadi di Amerika Serikat, ini bisa menjadi pilihan yang sangat baik. Data ini mencakup berbagai sektor, seperti kesehatan, pendidikan, ekonomi, lingkungan, transportasi, dan banyak lagi.
Sumber data ini disediakan melalui berbagai lembaga pemerintah dan sering kali tersedia secara gratis untuk digunakan oleh siapa saja, termasuk peneliti, data scientist, jurnalis, pengembang aplikasi, dan masyarakat umum.
Portal utama untuk mengakses data ini adalah Data.gov, yang merupakan situs web resmi pemerintah AS untuk memublikasikan data yang dikelola oleh berbagai badan pemerintah. Data ini didukung oleh prinsip transparansi dan partisipasi publik, dengan tujuan mendorong inovasi, penelitian, dan kebijakan berbasis data.
Satu Data Indonesia

Tentunya tidak hanya Amerika saja yang mendorong inovasi, penelitian, dan kebijakan berbasis data. Indonesia juga tidak tinggal diam akan hal itu dengan dukungan penuh dari pemerintah berupa penyediaan data yang bisa diakses oleh semua orang sehingga dapat mengakselerasi perkembangan digital di Indonesia.
Pemerintah Indonesia melalui portal resmi Satu Data Indonesia menjalankan kebijakan tata kelola data pemerintah yang bertujuan untuk menciptakan data berkualitas, mudah diakses, dapat dibagi, dan digunakan oleh instansi pusat serta daerah.
Data dalam portal ini dapat diakses secara terbuka dan dikategorikan sebagai data publik sehingga tidak memuat rahasia negara, rahasia pribadi, atau hal lain sejenisnya sebagaimana diatur dalam Undang-undang nomor 14 Tahun 2008 tentang Keterbukaan Informasi Publik.
Open Data Pemerintah Jawa Barat

Sedikit mengerucut dan lebih spesifik, salah satu pemerintah level provinsi membangun sebuah portal yang berisikan data di wilayah Jawa Barat melalui Open Data Jabar.
Open Data Jabar adalah portal resmi data terbuka milik Pemerintah Provinsi Jawa Barat yang berisikan data-data dari Perangkat Daerah di lingkungan Pemerintah Provinsi Jawa Barat. Open Data Jawa Barat hadir untuk memenuhi kebutuhan data publik bagi masyarakat. Data disajikan dengan akurat, akuntabel, valid, mudah diakses dan berkelanjutan.
Menggunakan Dataset dari Sumber Terpilih
Setelah mengetahui berbagai macam sumber data tidak afdal rasanya jika tidak mengetahui cara mengakses sumber data tersebut.
Catatan
Untuk saat ini, kita akan menggunakan salah satu sumber data yang sudah ada dari platform penyedia data terkenal, yaitu Kaggle. Anda bisa melakukan eksplorasi secara mandiri untuk sumber data lainnya karena penggunaannya tidak jauh berbeda sehingga materi yang ada di sini masih sangat relevan.
Pada latihan ini, kita akan menggunakan Kaggle sebagai sumber open data dengan tema prediksi harga rumah. Setelah mengenal teori pengumpulan data, sekarang kita akan belajar mengumpulkan data dari sumber Kaggle.
Tahapan yang akan kita lalui adalah sebagai berikut.
- Menentukan kasus yang akan diselesaikan.
- Menentukan sumber data yang akan digunakan (pada kasus ini kita akan menggunakan Kaggle).
- Menggunakan dataset yang sudah ada dari open data.
Langkah pertama adalah mengidentifikasi dan mendefinisikan masalah yang ingin Anda selesaikan dengan machine learning. Misalnya, Anda bekerja di bidang real estate dan ingin membangun model machine learning untuk memprediksi harga rumah berdasarkan berbagai fitur, seperti lokasi, ukuran, jumlah kamar, dan lain-lain.
Setelah menentukan masalah, langkah selanjutnya adalah menentukan jenis data yang diperlukan untuk melatih model Anda. Sebagai contoh data yang Anda butuhkan adalah sebagai berikut.
- Fitur: lokasi (kode pos atau koordinat GPS), ukuran rumah (luas tanah dan bangunan), jumlah kamar tidur, jumlah kamar mandi, tahun dibangun, dll.
- Label (Target): harga jual rumah.
Berikutnya, Anda perlu mencari sumber data yang dapat menyediakan informasi yang dibutuhkan. Dalam contoh ini, Anda bisa mencari dataset yang sudah ada tentang harga rumah. Salah satu sumber yang terkenal dan dapat diandalkan adalah Kaggle.
Sekarang, Anda akan mencari dataset yang sesuai di Kaggle. Ikuti langkah-langkah berikut.
- Kunjungi situs Kaggle dengan membuka tautan berikut Kaggle.com.
- Cari dataset yang relevan dengan mengetikkan kata kunci seperti "house prices" atau "real estate data" di kotak pencarian pada halaman utama Kaggle.
- Pilih dataset yang sesuai. Misalnya, salah satu dataset populer adalah House Prices - Advanced Regression Techniques yang menyediakan data tentang harga rumah di beberapa daerah dengan berbagai fitur properti yang relevan.
- Terakhir, setelah memilih dataset yang dirasa sesuai dengan permasalahan yang akan diselesaikan, Anda bisa mengunduhnya dengan mengeklik tombol Download.
Setelah mengunduh dataset, pahami dan pastikan dataset tersebut sudah sesuai dengan kebutuhan Anda. Biasanya, dataset dari Kaggle sudah terstruktur dengan baik, tetapi Anda tetap harus memahami struktur data dan mempersiapkannya sebelum digunakan dalam model machine learning. Untuk mengetahui langkah selanjutnya, mari kita lanjutkan perjalanan yang menyenangkan ini pada materi berikutnya, yaitu tentang Data Loading.
Data Loading
Sampai pada tahap ini jangan biarkan data yang sudah dikumpulkan menjadi sia-sia. Agar data yang sudah siap diolah dapat digunakan, Diana perlu melakukan loading atau memuat dataset.
Loading dataset dalam konteks machine learning adalah proses mengimpor atau memasukkan data ke dalam lingkungan pemrograman atau sistem yang digunakan untuk pengembangan model machine learning. Dataset ini berfungsi sebagai input yang akan digunakan oleh model untuk belajar dan membuat prediksi.
Proses loading dataset biasanya mencakup pengambilan data dari sumber eksternal (seperti file CSV, database, API, atau sumber lain) lalu memuatnya ke dalam struktur data yang sesuai di dalam bahasa pemrograman atau framework yang digunakan. Dalam banyak kasus, bahasa pemrograman seperti Python menggunakan library Pandas untuk memuat dataset ke dalam format yang mudah disesuaikan, seperti DataFrame.
Ada beberapa hal yang perlu Anda ketahui terkait pentingnya data loading.
- Sebagai Langkah Awal: loading dataset adalah langkah pertama yang sangat penting dalam alur kerja machine learning. Tanpa data, Anda tidak bisa melatih atau menguji model.
- Memastikan Integritas Data: proses loading juga memberikan kesempatan untuk memverifikasi bahwa data dimuat dengan benar dan sesuai dengan harapan. Misalnya, memeriksa apakah semua kolom dimuat dengan tipe data yang benar dan apakah ada data yang hilang atau tidak.
- Verifikasi Kesiapan Data: dataset yang sudah di-load ke dalam struktur data yang sesuai akan memudahkan proses berikutnya, seperti eksplorasi, pembersihan data, transformasi, dan pelatihan model.
Pandas mendukung berbagai ekstensi file yang digunakan untuk menyimpan dan memanipulasi data. Dengan kemampuannya untuk membaca berbagai format, Pandas memberikan fleksibilitas luar biasa dalam menangani data dari berbagai sumber dan memudahkan proses analisis data di Python. Berikut adalah tipe file yang dapat di-load menggunakan Pandas.
CSV (Comma-Separated Values)
- Ekstensi: .csv
- Cara Load: pd.read_csv('file.csv')
- Deskripsi: CSV adalah format file yang sangat umum digunakan untuk menyimpan data tabular. Setiap baris dalam file CSV mewakili satu record, dan setiap nilai dalam baris dipisahkan oleh koma (atau delimiter lainnya seperti titik koma).
Excel Files
- Ekstensi: .xls, .xlsx
- Cara Load: pd.read_excel('file.xlsx')
- Deskripsi: Excel adalah format file yang sering digunakan untuk spreadsheet dan data tabular. Pandas dapat membaca berbagai sheet dalam file Excel dan mengonversinya menjadi DataFrame.
JSON (JavaScript Object Notation)
- Ekstensi: .json
- Cara Load: pd.read_json('file.json')
- Deskripsi: JSON adalah format file yang sering digunakan untuk menyimpan dan mentransfer data berbasis objek. Pandas dapat mengonversi JSON yang terstruktur dengan baik menjadi DataFrame.
HTML
- Ekstensi: .html
- Cara Load: pd.read_html('file.html')
- Deskripsi: Pandas dapat membaca tabel data yang ada di dalam file HTML dan mengonversinya menjadi DataFrame. Ini sering digunakan untuk scraping data dari web.
SQL Database
- Ekstensi: Tidak ada ekstensi khusus, data diambil dari database.
- Cara Load: pd.read_sql_query('SELECT * FROM table_name', connection)
- Deskripsi: Pandas dapat mengakses data yang disimpan dalam tabel SQL dan mengonversinya menjadi DataFrame, dengan koneksi ke database seperti SQLite, MySQL, PostgreSQL, dll.
Parquet
- Ekstensi: .parquet
- Cara Load: pd.read_parquet('file.parquet')
- Deskripsi: Parquet adalah format file yang sangat efisien untuk menyimpan data kolumnar yang sering digunakan dalam big data analytics. Pandas mendukung pembacaan dan penulisan file Parquet.
HDF5 (Hierarchical Data Format)
- Ekstensi: .h5, .hdf5
- Cara Load: pd.read_hdf('file.h5')
- Deskripsi: HDF5 adalah format file yang dirancang untuk menyimpan data besar dalam struktur yang terorganisir. Pandas dapat membaca dan menulis data ke file HDF5.
Feather
- Ekstensi: .feather
- Cara Load: pd.read_feather('file.feather')
- Deskripsi: Feather adalah format file yang dioptimalkan untuk penyimpanan data tabular yang sangat cepat dan efisien, baik dalam hal pembacaan maupun penulisan.
Stata
- Ekstensi: .dta
- Cara Load: pd.read_stata('file.dta')
- Deskripsi: Stata adalah software statistik, dan Pandas mendukung pembacaan file .dta yang digunakan oleh Stata.
SAS (Statistical Analysis System)
- Ekstensi: .sas7bdat
- Cara Load: pd.read_sas('file.sas7bdat')
- Deskripsi: SAS adalah software analisis data yang digunakan untuk statistik. Pandas mendukung pembacaan file SAS.
SPSS (Statistical Package for the Social Sciences)
- Ekstensi: .sav
- Cara Load: pd.read_spss('file.sav')
- Deskripsi: SPSS adalah software statistik yang sering digunakan dalam ilmu sosial. Pandas dapat membaca file .sav yang digunakan oleh SPSS.
Pickle
- Ekstensi: .pkl
- Cara Load: pd.read_pickle('file.pkl')
- Deskripsi: Pickle adalah format serialisasi Python yang digunakan untuk menyimpan objek Python ke dalam file. Pandas dapat memuat objek DataFrame yang disimpan dalam format Pickle.
ORC (Optimized Row Columnar)
- Ekstensi: .orc
- Cara Load: pd.read_orc('file.orc')
- Deskripsi: ORC adalah format file yang dirancang untuk penyimpanan data kolumnar yang digunakan dalam Hadoop. Pandas mendukung pembacaan file ORC.
SQL Lite
- Ekstensi: .db atau .sqlite
- Cara Load: pd.read_sql_table('table_name', connection)
- Deskripsi: SQLite adalah database yang ringan dan file-based. Selain itu, Pandas juga dapat membaca tabel dari database SQLite langsung ke dalam DataFrame.
LaTeX
- Ekstensi: .tex
- Cara Load: pd.read_stata('file.tex')
- Deskripsi: Pandas bisa membaca dan menulis tabel LaTeX yang sering digunakan dalam dokumen akademik untuk pemformatan tabel.
Clipboard
- Ekstensi: Tidak ada ekstensi, data diambil dari clipboard.
- Cara Load: pd.read_clipboard()
- Deskripsi: Pandas dapat membaca data langsung dari clipboard (misalnya, hasil copy-paste dari spreadsheet) yang memudahkan pengambilan data cepat untuk analisis.
Selain tipe-tipe data di atas, ada berbagai macam file yang bisa diolah menggunakan Pandas. Anda bisa membaca lebih lengkapnya pada Pandas Documentation, ya. Ngomong-ngomong pada kelas ini kita akan sering menggunakan data csv dan excel, jadi silakan kuasai kedua tipe tersebut ya.
Latihan: Data Loading
Masih ingatkah tentang data yang telah Anda unduh sebelumnya pada materi Data Collecting terkait housing price? Jika Anda telisik lebih dalam pada file zip (sebuah file ekstensi) terdapat beberapa file seperti data_description.txt, sample_submission.csv, test.csv dan train.csv. Seluruh file yang akan kita gunakan bertipe CSV (Comma Separated Value(s)) sehingga Anda dapat menggunakan Pandas seperti berikut.

Jika kita konversi pada studi kasus yang akan diselesaikan, kode yang dibuat akan seperti berikut.
- import pandas as pd
- test = pd.read_csv("/content/test.csv")
- test.head()

- train = pd.read_csv("/content/train.csv")
- train.head()

Setelah dataset dimuat, langkah berikutnya biasanya adalah pembersihan data (data cleaning), eksplorasi data (data exploration), dan preprocessing sebelum akhirnya Anda melanjutkan ke tahap pelatihan model. Sampai pada tahap ini, Anda akan memastikan bahwa dataset sudah sesuai dengan format dan struktur yang dibutuhkan oleh algoritma machine learning yang akan digunakan.
Catatan
Walaupun terlihat sangat sederhana dan mudah loading dataset adalah langkah pertama dan esensial dalam proses machine learning. Proses ini melibatkan pengambilan data dari sumber eksternal dan memuatnya ke dalam lingkungan kerja untuk dianalisis lebih lanjut. Dengan dataset yang sudah dimuat, Anda bisa memulai proses eksplorasi, pembersihan, dan pelatihan model machine learning, yang semuanya bergantung pada kualitas dan kesiapan data yang Anda miliki.
Data Cleaning dan Transformation
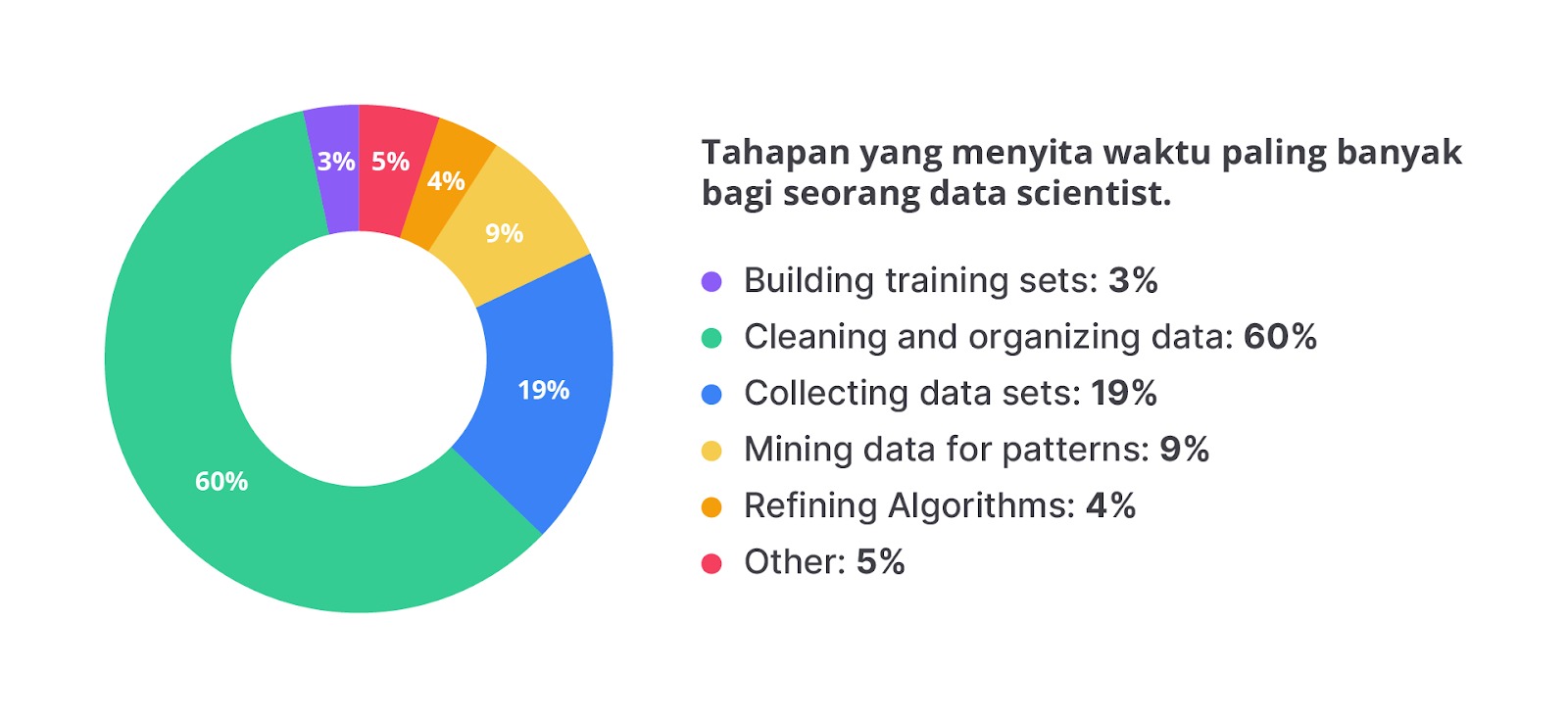
Anda mungkin berpikir pekerjaan data scientist atau machine learning engineer adalah membuat algoritma, mengeksplor data, membuat analisis, dan prediksi. Padahal faktanya, seseorang yang bekerja di bidang data menghabiskan sebagian besar waktunya untuk melakukan proses data cleaning. Hasil penelitian CrowdFlower dalam 2016 Data Science Report menyatakan bahwa 3 dari 5 data scientist yang disurvei menggunakan sebagian besar waktunya untuk membersihkan dan mengatur data.
Data Cleaning atau pembersihan data adalah proses penting dalam alur kerja machine learning yang bertujuan untuk meningkatkan kualitas dataset sebelum digunakan untuk pelatihan model. Dalam konteks machine learning, data cleaning mencakup serangkaian langkah yang dirancang untuk mendeteksi, memperbaiki, atau menghapus data yang tidak valid, tidak lengkap, tidak akurat, atau tidak relevan. Silakan simak gambar berikut dan perhatikan secara saksama.
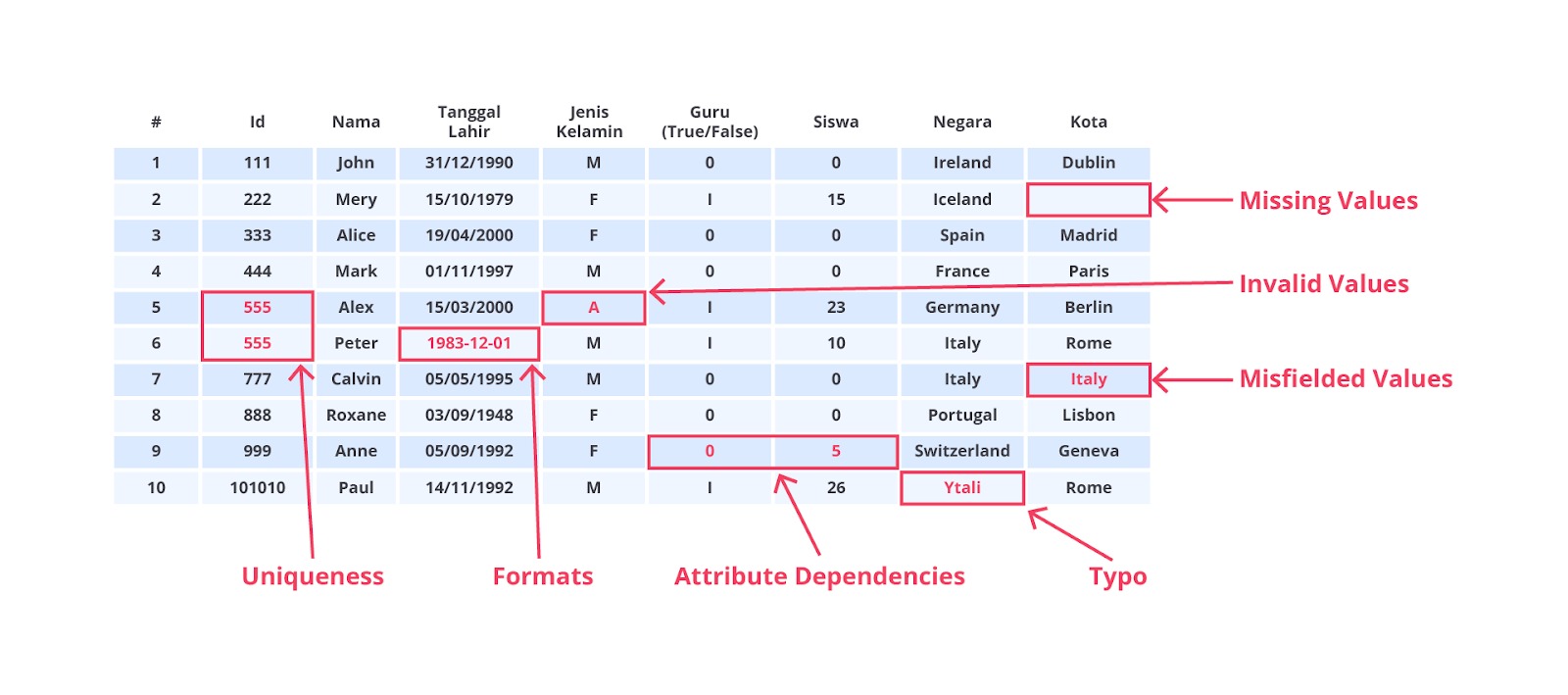
Dari gambar di atas mungkin tebersit dipikiran Anda sebuah pertanyaan “mengapa data cleaning begitu penting sehingga sebagian besar waktu digunakan untuk menyelesaikan proses ini?”
Data cleaning memiliki peran yang vital sebab proses ini meningkatkan kualitas data yang juga berpengaruh terhadap produktivitas kerja secara keseluruhan. Data yang tidak akurat bisa berpengaruh buruk terhadap akurasi dan performa model. Saat kita melakukan proses data cleaning, kita membuang data dan informasi yang tidak dibutuhkan sehingga kita akan mendapatkan data yang berkualitas.
Data yang akurat dan berkualitas akan berpengaruh positif terhadap proses pengambilan keputusan. Kita sudah familier mendengar ungkapan “Garbage In - Garbage Out?” Dalam konteks machine learning, jika input yang Anda masukkan itu buruk, sudah pasti hasil olah data pun akan buruk.
Secara umum, jika kita ringkas terdapat beberapa poin penting yang perlu diketahui ketika melakukan data cleaning.
- Meningkatkan Akurasi Model: data yang bersih dan berkualitas tinggi memungkinkan model untuk belajar pola yang sebenarnya dalam data, yang pada prosesnya akan meningkatkan akurasi dan kinerja model.
- Mencegah Overfitting: data yang tidak akurat atau penuh noise bisa menyebabkan model overfitting, di mana model belajar dari data yang salah dan tidak mampu membuat prediksi yang baik pada data baru.
- Meningkatkan Efisiensi: data yang bersih mempermudah proses analisis dan pemodelan, mengurangi kebutuhan untuk debugging atau penyesuaian model yang ekstensif di kemudian hari.
- Memastikan Keandalan: data yang tidak bersih dapat memperkenalkan bias atau kesalahan sistematis dalam model yang dapat menyesatkan dalam pengambilan keputusan berbasis data.
Sampai di sini tentu Anda sudah paham ‘kan mengapa data cleaning itu sangat penting? Oleh karena itu, data cleaning merupakan tahapan yang tidak boleh Anda lewatkan.
Berdasarkan data di atas, ada beberapa tahapan umum yang harus dilakukan dalam proses data cleaning.
- Mengidentifikasi dan Menangani Nilai yang Hilang (Missing Values)
Nilai yang hilang adalah salah satu masalah paling umum dalam data. Missing value terjadi ketika data dari sebuah record tidak lengkap. Missing value sangat memengaruhi performa model machine learning. Umumnya ada 2 (dua) opsi untuk mengatasi missing value, yaitu menghilangkan data missing value atau mengganti nilai yang hilang dengan nilai lain, seperti rata-rata dari kolom tersebut (mean) atau nilai yang paling sering muncul (modus), atau nilai tengah (median).
Jika terlalu banyak data yang hilang dalam suatu baris atau kolom, Anda mungkin memilih untuk menghapusnya. Namun, ini hanya disarankan jika data yang hilang tidak signifikan secara statistik. Di lain sisi, mengisi nilai yang hilang dengan nilai rata-rata, median, modus, atau menggunakan metode lebih canggih seperti K-Nearest Neighbors (KNN) atau regresi untuk memperkirakan nilai yang hilang menjadi pilihan yang baik ketika data yang hilang memiliki peran yang penting.
- Mengidentifikasi dan Menangani Outliers
Outliers adalah data yang secara signifikan berbeda dari mayoritas data lainnya. Mereka bisa disebabkan oleh kesalahan pengukuran atau fenomena yang sebenarnya terjadi. Jika outliers disebabkan oleh kesalahan atau tidak relevan, mereka dapat dihapus. Namun, jika outliers merupakan bagian dari distribusi normal, transformasi seperti log transformation dapat dilakukan untuk mengurangi dampaknya.
- Normalisasi dan Standardisasi Data
Data sering kali perlu dinormalisasi atau distandardisasi untuk memastikan bahwa fitur-fitur memiliki skala yang sama dan penting untuk algoritma tertentu seperti K-Nearest Neighbors atau Support Vector Machines.
- Menangani Duplikasi Data
Data yang memiliki duplikat akan memengaruhi model machine learning, apalagi jika data duplikat tersebut besar jumlahnya. Untuk itu, kita harus memastikan tidak ada data yang terduplikasi.
Duplikasi dalam data dapat terjadi karena berbagai alasan, seperti kesalahan input atau penggabungan dataset dari sumber yang berbeda. Data yang diduplikasi dapat menyebabkan model memberikan bobot berlebihan pada contoh yang sama sehingga dapat memengaruhi kinerjanya.
- Mengonversi Tipe Data dan Menangani Inkonsistensi Data
Data sering kali memiliki inkonsistensi, seperti ejaan yang berbeda untuk kategori yang sama atau format data yang tidak konsisten. Menangani inkonsistensi ini sangat penting untuk memastikan data yang bersih dan akurat.
Misalnya, sebuah variabel mungkin tidak memiliki format yang konsisten seperti penulisan tanggal 10-Okt-2020 versus 10/10/20. Format jam yang berbeda seperti 17.10 versus 5.10 pm. Penulisan uang seperti 17000 versus Rp17.000. Data dengan format berbeda tidak akan bisa diolah oleh model machine learning. Solusinya, format data harus disamakan dan dibuat konsisten terlebih dahulu.
Selain tipe data yang harus seragam, Anda perlu memastikan bahwa tipe data yang ada pada dataset sesuai dengan kebutuhan model machine learning. Terkadang, tipe data dalam dataset mungkin tidak sesuai dengan kebutuhan model. Misalnya, variabel kategorikal mungkin perlu dikonversi ke format numerik melalui teknik seperti one-hot encoding.
Terakhir, Anda perlu memastikan skala data pada setiap variabel yang ada. Sebagai contoh jika sebuah variabel memiliki jangka dari 1 sampai 100, pastikan tidak ada data yang lebih dari 100. Untuk data numerik, jika sebuah variabel merupakan bilangan positif, pastikan tidak ada bilangan negatif.
Intinya data cleaning adalah langkah vital yang berfungsi untuk memastikan bahwa data yang digunakan membangun model machine learning memiliki sifat akurat, relevan, dan bebas dari kesalahan yang bisa merusak kualitas model.
Dengan melakukan data cleaning secara hati-hati, Anda meningkatkan peluang untuk membangun model machine learning yang lebih baik, andal, dan mampu membuat prediksi yang akurat. Namun, perlu Anda catat bahwa proses cleaning data ini tidak bersifat wajib dilakukan semuanya. Tahapan tersebut perlu Anda cek secara mandiri karena bisa saja data yang digunakan sudah bersih karena mengambil dari pustaka open data dan sudah dibersihkan oleh author (pemilik) data.
Di waktu yang akan datang, mungkin Anda akan menemukan proses atau tahapan baru karena menghadapi karakteristik yang beragam. Oleh karena itu, kuasai fondasi atau dasar proses cleaning sehingga kelak Anda bisa menghadapi semua permasalahan yang ada.
Latihan: Data Cleaning dan Transformation
Pada latihan sebelumnya, Anda telah berhasil memuat data (data loading) train.csv dan test.csv. Namun, data tersebut masih perlu Anda lakukan pemeriksaan untuk mengetahui kualitas data yang digunakan.
Catatan
Proses data cleaning ini tidak perlu dilakukan semuanya karena tidak semua data memiliki karakteristik yang sama. Pada latihan ini, Anda akan melakukan cleaning terhadap train.csv, silakan lakukan secara mandiri untuk data test.csv, ya.
Mengidentifikasi Informasi Dataset
Kita akan melihat informasi dasar tentang dataset, seperti jumlah baris, kolom, tipe data, dan jumlah nilai yang hilang.
Pertama-tama, mari kita periksa tipe data dari masing-masing fitur yang ada di dataset. Tujuan dari pemeriksaan tipe data ini adalah untuk memastikan seluruh tipe data yang ada sudah sesuai dan tidak ada kekeliruan (contoh: data numerik terdeteksi str (string)). Sehingga, pada akhirnya Anda tidak akan mengalami kesulitan ketika melakukan preprocessing data karena tipe data yang ada sudah sesuai dan bisa melalui proses dengan lebih seamless.
- # Menampilkan ringkasan informasi dari dataset
- train.info()
Selanjutnya, Anda perlu melakukan analisis statistik deskriptif dari dataset yang digunakan. Tujuan analisis statistik deskriptif dalam proses data cleaning pada machine learning adalah untuk memahami karakteristik dasar dari data yang sedang diproses. Beberapa tujuan utama dari proses ini adalah sebagai berikut.
- Memahami Distribusi Data: statistik deskriptif ini akan membantu Anda dalam memahami bagaimana data terdistribusi, termasuk melihat nilai rata-rata (mean), median, modus, rentang (range), dan variabilitas (standard deviation). Ini penting untuk mengidentifikasi data yang mungkin tidak seimbang (imbalance) atau memiliki distribusi yang tidak normal.
- Mengidentifikasi Anomali dan Outlier: analisis deskriptif dapat membantu dalam mendeteksi nilai-nilai yang tidak wajar atau outlier yang bisa memengaruhi performa model. Masih ingatkan penjelasan tentang outlier pada materi sebelumnya? Jika Anda ragu, jangan sungkan untuk me-review ulang kembali materinya, ya.
- Menilai Kualitas Data: dengan analisis deskriptif, dapat diketahui apakah ada missing values, data duplikat, atau inkonsistensi dalam dataset. Ini penting untuk memastikan bahwa data bersih dan siap digunakan untuk model machine learning.
- Mempermudah Pemahaman Data: statistik deskriptif menyajikan informasi data dalam bentuk yang lebih sederhana, seperti tabel, grafik, dan summary statistics, yang memudahkan pemahaman atas kondisi data yang ada.
- Menentukan Transformasi Data yang Diperlukan: dari hasil analisis deskriptif, bisa ditentukan apakah diperlukan transformasi data, seperti normalisasi atau standardisasi, agar data lebih sesuai untuk algoritma machine learning yang akan digunakan.
Dengan melakukan analisis statistik deskriptif, kita bisa memastikan bahwa data yang digunakan untuk melatih model machine learning adalah data yang representatif, berkualitas tinggi, dan bebas dari masalah yang dapat memengaruhi hasil akhir. Berikut adalah contoh kode untuk melakukan analisis deskriptif.
- # Menampilkan statistik deskriptif dari dataset
- train.describe(include="all")
Terakhir Anda perlu melakukan pemeriksaan terhadap data yang hilang (missing value). Tujuannya untuk mencegah kesalahan ketika melakukan analisis, mencegah error pada model, dan meningkatkan performa model. Dengan melakukan pemeriksaan missing value, Anda dapat memastikan bahwa proses analisis data dan pelatihan model machine learning berjalan dengan baik sehingga hasil yang diperoleh lebih valid dan akurat. Berikut salah satu contoh kode untuk melakukan pemeriksaan missing value.
- # Memeriksa jumlah nilai yang hilang di setiap kolom
- missing_values = train.isnull().sum()
- missing_values[missing_values > 0]
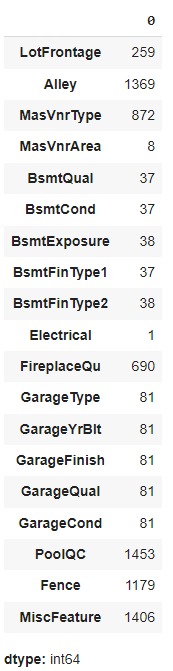
Mengatasi Missing Value
Perhatikan jumlah data yang hilang pada hasil kode sebelumnya, tentunya sangat banyak sekali data yang hilang ‘kan? Sebagai informasi jumlah data pada train.csv ini berjumlah 1460 baris sehingga jika salah satu fitur memiliki missing value lebih dari 1000, dapat kita asumsikan terlalu banyak data yang hilang. Lalu bagaimana solusinya?
Pertama-tama, mari kita pisahkan kolom yang memiliki missing value lebih dari 75% dan kurang dari 75%.
- less = missing_values[missing_values < 1000].index
- over = missing_values[missing_values >= 1000].index
Berdasarkan hasil dari langkah sebelumnya, kita akan memutuskan bagaimana menangani nilai yang hilang dengan dua cara.
- Mengisi Nilai yang Hilang: data di atas terdapat beberapa fitur yang memiliki missing value kurang dari 75% dari jumlah skala pada data. Namun, perlu Anda catat bahwa seluruh fitur tersebut memiliki tipe data yang berbeda. Sehingga penanganan missing value-nya pun perlu dibedakan.
Mari kita mulai dengan mengatasi missing value untuk tipe data numerik.Secara singkat kode di atas memiliki dua fungsi utama yaitu sebagai berikut.- # Contoh mengisi nilai yang hilang dengan median untuk kolom numerik
- numeric_features = train[less].select_dtypes(include=['number']).columns
- train[numeric_features] = train[numeric_features].fillna(train[numeric_features].median())
- Baris pertama memilih nama-nama kolom dari DataFrame train yang memiliki tipe data numerik dari subset kolom yang ditentukan oleh less.
- Baris kedua kemudian mengisi semua nilai yang hilang (NaN) pada kolom-kolom numerik tersebut dengan nilai median dari masing-masing kolom.
Secara keseluruhan, kode ini bertujuan untuk membersihkan data dengan memastikan bahwa semua kolom numerik dalam subset tertentu (train[less]) tidak memiliki missing value (NaN) dengan menggantinya menggunakan nilai median kolom masing-masing.
Selanjutnya, kita perlu menangani permasalahan yang serupa pada data yang bertipe object atau string. Sedikit berbeda dengan kasus data numerik, pada kasus ini kita tidak bisa menggunakan median, mean, atau fungsi agregasi lainnya. Biasanya ada dua cara yang sering dilakukan untuk mengatasi permasalahan missing value pada data kategori.
- Mengisi Missing Value dengan Modus (Nilai yang Paling Sering Muncul): pendekatan ini cukup umum karena nilai modus sering kali merupakan representasi yang baik untuk data yang hilang dalam konteks kategorikal.
- Mengisi dengan Kategori Baru (Misalnya "Unknown" atau "Missing"): ini adalah cara lain untuk menangani missing value dengan menandai data yang hilang sebagai kategori baru.
Pada contoh kasus ini, mari kita atasi dengan mengisi missing value dengan modus atau nilai yang paling sering muncul pada masing-masing fitur.
- # Contoh mengisi nilai yang hilang dengan mode untuk kolom kategori
- kategorical_features = train[less].select_dtypes(include=['object']).columns
- for column in kategorical_features:
- train[column] = train[column].fillna(train[column].mode()[0])
Kode di atas akan melakukan pengulangan pada setiap kolom yang berisi data kategori dalam DataFrame train. Selanjutnya, setiap kolom kategori akan melakukan proses pergantian untuk semua nilai yang hilang (NaN) dengan nilai modus dari kolom tersebut. Hasil akhirnya adalah semua kolom kategori dalam DataFrame train tidak lagi memiliki nilai yang hilang (NaN) karena semua NaN telah diisi dengan nilai modus dari kolom masing-masing.
- Menghapus Kolom dengan Banyak Nilai yang Hilang:jika ada kolom dengan terlalu banyak nilai yang hilang, kita bisa mempertimbangkan untuk menghapusnya (pada kasus ini kita mengambil batasan 75%). Untuk mengatasi kasus ini sangatlah mudah, pertama Anda perlu mengambil index atau nama kolom dari fitur yang memiliki missing value lebih dari batasan yang sudah ditentukan (Anda dapat lihat kode ketika memisahkan kolom di atas). Kemudian hal yang perlu dilakukan adalah menghapus kolom tersebut sesuai dengan nama fitur yang sudah ditentukan sebelumnyaJika Anda perhatikan kode di atas, ada sebuah perubahan nama DataFrame yang kita lakukan. Hal tersebut bertujuan supaya data asli tidak berubah dan dapat kita bandingkan sebelum dan sesudah proses mengisi missing value.
- # Menghapus kolom dengan terlalu banyak nilai yang hilang
- df = train.drop(columns=over)
Terakhir, lakukan pemeriksaan terhadap data yang sudah melewati tahapan verifikasi missing value dengan kode berikut.- missing_values = df.isnull().sum()
- missing_values[missing_values > 0]

Mengatasi Outliers
Seperti yang Anda ketahui bahwa outliers merupakan salah satu blocker dalam membangun model machine learning yang optimal. Hal ini bisa disebabkan oleh berbagai hal seperti kesalahan pengisian data, error yang terjadi ketika pengumpulan data, dan lain sebagainya.
Salah satu cara mengatasi outliers adalah dengan menggunakan metode IQR (Interquartile Range) adalah salah satu pendekatan yang efektif. IQR adalah rentang antara kuartil pertama (Q1) dan kuartil ketiga (Q3) dalam data. Nilai yang terletak di luar batas IQR dianggap sebagai outlier.
Mari kita periksa terlebih dahulu apakah dataset yang digunakan memiliki outlier atau tidak menggunakan kode berikut.
- import pandas as pd
- import seaborn as sns
- import matplotlib.pyplot as plt
- for feature in numeric_features:
- plt.figure(figsize=(10, 6))
- sns.boxplot(x=df[feature])
- plt.title(f'Box Plot of {feature}')
- plt.show()
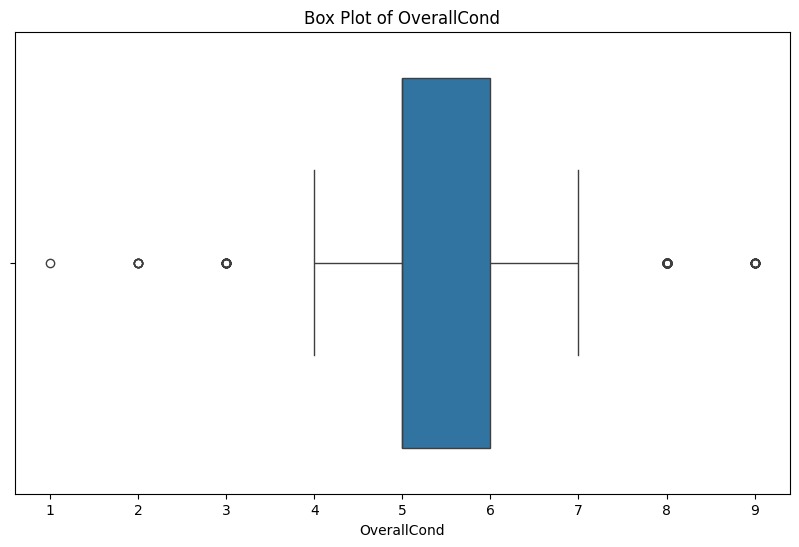
Catatan
Karena output dari kode di atas sangat banyak, kami hanya memperlihatkan salah satunya. Silakan ikuti latihan yang disediakan untuk melihat seluruh outputnya.
Perhatikan visualisasi data di atas, apakah Anda dapat menyimpulkan sesuatu? Yup, nilai yang berada di bawah batas bawah atau di atas batas atas dianggap sebagai outlier. Ada dua pilihan yang biasa dilakukan untuk mengatasi permasalahan ini.
- Anda dapat memilih untuk menghapus outlier.
- Menggantinya dengan nilai yang lebih moderat (seperti batas terdekat), atau menerapkan transformasi.
Nah, pada kasus ini, kita akan memilih untuk menghapus data outlier dengan asumsi bahwa outlier yang terjadi merupakan human error dan tidak ada pengaruh yang besar pada analisis deskriptif. Mari kita mulai pemeriksaan outlier menggunakan metode IQR.
Berikut adalah langkah-langkah umum untuk mendeteksi dan menangani outlier menggunakan metode IQR.
- Menghitung IQR, Q1, dan Q3
- Q1 (Quartile 1): Nilai di persentil ke-25 data.
- Q3 (Quartile 3): Nilai di persentil ke-75 data.
- IQR: Rentang antara Q3 dan Q1 (IQR = Q3 - Q1).
- Menentukan Batas Bawah dan Batas Atas
- Batas Bawah: Q1 - 1.5 * IQR
- Batas Atas: Q3 + 1.5 * IQR
Langkah di atas merupakan algoritma secara umum sehingga untuk memproses metode tersebut, Anda perlu mengonversi langkah-langkah yang ada pada bahasa pemrograman yang digunakan (pada kasus ini Python).
- # Contoh sederhana untuk mengidentifikasi outliers menggunakan IQR
- Q1 = df[numeric_features].quantile(0.25)
- Q3 = df[numeric_features].quantile(0.75)
- IQR = Q3 - Q1
Selanjutnya mari kita hapus outlier berdasarkan perhitungan di atas.
- # Filter dataframe untuk hanya menyimpan baris yang tidak mengandung outliers pada kolom numerik
- condition = ~((df[numeric_features] < (Q1 - 1.5 * IQR)) | (df[numeric_features] > (Q3 + 1.5 * IQR))).any(axis=1)
- df_filtered_numeric = df.loc[condition, numeric_features]
- # Menggabungkan kembali dengan kolom kategorikal
- categorical_features = df.select_dtypes(include=['object']).columns
- df = pd.concat([df_filtered_numeric, df.loc[condition, categorical_features]], axis=1)
Terakhir, mari kita bandingkan data yang telah melewati proses penanganan outliers dan sebelum melewati tahapan tersebut. Berikut adalah salah satu contoh visualisasi data yang telah melewati tahapan penanganan outliers.
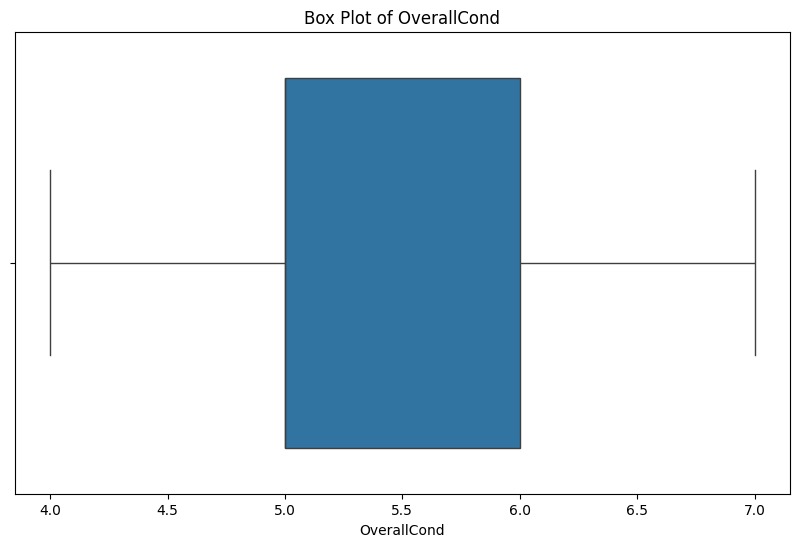
Apakah Anda melihat perbedaannya? Benar sekali! Setelah penanganan outliers menggunakan IQR, distribusi data menjadi lebih merata dan terpusat, dengan mean dan median yang mendekati satu sama lain. Di lain sisi, varians dan standar deviasi akan berkurang, lalu rentang data menyusut karena nilai yang berbeda telah diatasi.
Pro Tips Jika Anda tidak ingin menghapus outliers seperti contoh di atas, silakan gunakan metode agregasi seperti berikut.
atau
|
Normalisasi dan Standardisasi Data
Tahap selanjutnya dilakukan jika dataset memiliki fitur numerik dengan skala yang berbeda-beda, kita mungkin perlu melakukan normalisasi atau standardisasi. Normalisasi dan standardisasi adalah teknik preprocessing data yang digunakan untuk menyiapkan data sebelum analisis atau pemodelan. Keduanya bertujuan untuk membuat fitur memiliki skala yang seragam, tetapi mereka melakukannya dengan cara yang berbeda.
Sebuah pertanyaan klasik selalu muncul, “Bagaimana cara menentukan kapan harus menggunakan normalisasi atau standardisasi?”
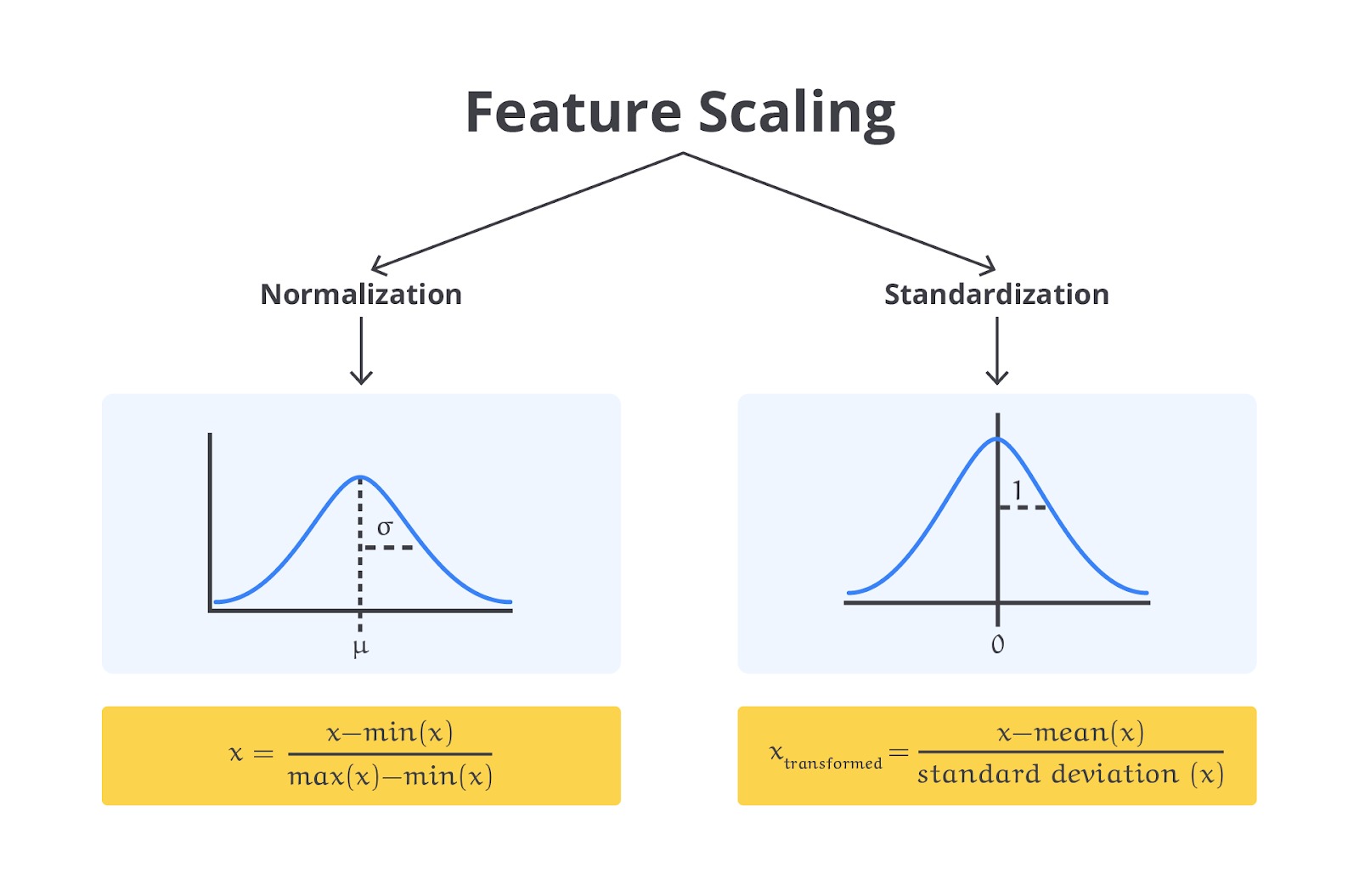
Berikut adalah panduan umum untuk menentukan kapan Anda harus menggunakan normalisasi atau standardisasi.
Normalisasi
Normalisasi (juga dikenal sebagai penskalaan min-max) bertugas untuk mengubah fitur sehingga nilainya berada dalam rentang tertentu, biasanya antara 0 dan 1.
Berikut poin-poin yang menjadi pertimbangan ketika akan melakukan normalisasi.
- Fitur dengan Skala Berbeda: ketika fitur memiliki skala yang sangat berbeda dan Anda ingin menyamakan rentangnya.
- Model Berbasis Jarak: jika Anda menggunakan algoritma yang bergantung pada jarak, seperti K-Nearest Neighbors (KNN) atau K-Means clustering, normalisasi dapat membantu karena model ini sensitif terhadap skala fitur.
- Data Tidak Terdistribusi Normal: jika data tidak terdistribusi normal dan Anda ingin mengubah data menjadi rentang yang lebih seragam.
Standardisasi
Standardisasi (juga dikenal sebagai penskalaan Z-score) bertugas untuk mengubah skala pada suatu fitur sehingga memiliki rata-rata 0 dan standar deviasi 1.
Berikut poin-poin yang menjadi pertimbangan ketika akan melakukan standardisasi.
- Data Berdistribusi Normal: ketika data mengikuti distribusi normal (atau mendekati normal) dan Anda ingin mempertahankan informasi tentang distribusi data.
- Model Berbasis Regresi: untuk algoritma yang memerlukan asumsi distribusi normal atau model linier seperti Regresi Linier, Standar, atau Logistic Regression.
- Data dengan Skala Berbeda: ketika fitur memiliki skala yang berbeda tetapi Anda ingin memastikan bahwa setiap fitur berkontribusi secara proporsional tanpa mengubah distribusi data secara signifikan.
Jika kita tarik benang merah perbedaan dari standardisasi dengan normalisasi hanya pada rentangnya.
- Normalisasi: mengubah data ke dalam rentang [0, 1]. Ideal untuk model berbasis jarak dan data yang tidak terdistribusi normal.
- Standardisasi: mengubah data sehingga rata-rata menjadi atau mendekati 0 dan standar deviasi menjadi 1. Hal ini membantu model yang memerlukan distribusi normal atau data dengan skala berbeda menjadi lebih ideal pada proses pelatihannya.
Dalam praktiknya di dunia nyata, pemilihan antara normalisasi dan standardisasi sering bergantung pada algoritma yang akan digunakan dan karakteristik data. Anda perlu mempertimbangkan distribusi data dan jenis model untuk menentukan teknik preprocessing yang paling sesuai.
Mari kita kembali ke studi kasus yang sedang kita hadapi. Kita akan melakukan standardisasi karena membutuhkan distribusi normal dan tidak membutuhkan skala 0-1. Perhatikan kode berikut.
- from sklearn.preprocessing import StandardScaler
- # Standardisasi fitur numerik
- scaler = StandardScaler()
- df[numeric_features] = scaler.fit_transform(df[numeric_features])
Untuk melakukan perbandingan antara data sebelum dan sesudah dilakukan standardisasi, Anda dapat menggunakan kode berikut.
- # Histogram Sebelum Standardisasi
- plt.figure(figsize=(12, 5))
- plt.subplot(1, 2, 1)
- sns.histplot(train[numeric_features[3]], kde=True)
- plt.title("Histogram Sebelum Standardisasi")
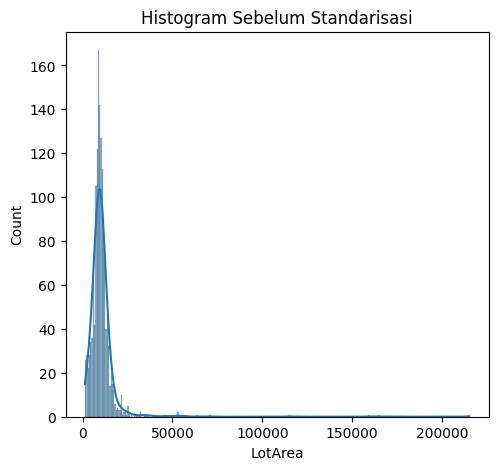
- # Histogram Setelah Standardisasi
- plt.subplot(1, 2, 2)
- sns.histplot(df[numeric_features[3]], kde=True)
- plt.title("Histogram Setelah Standardisasi")
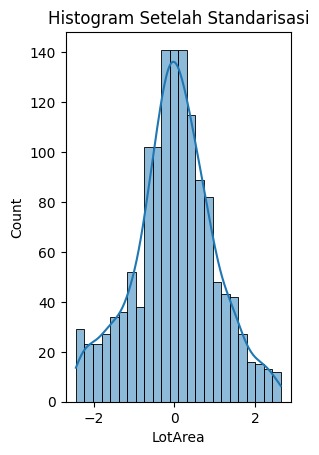
Perhatikan distribusi data pada kedua visualisasi di atas (sebelum dan sesudah standardisasi), terlihat sangat berbeda, ‘kan? Kesimpulannya, standardisasi ini akan meningkatkan kinerja model dengan menyamakan skala fitur, mempercepat konvergensi algoritma optimasi, dan mengurangi risiko overfitting.
Proses ini juga mempermudah interpretasi koefisien dalam model linier, memastikan konsistensi dalam perbandingan data, dan membantu deteksi outliers. Selain itu, standardisasi merupakan prasyarat bagi beberapa algoritma statistik dan machine learning, serta memungkinkan model lebih generalizable dan transferable antar dataset, menjadikannya langkah penting dalam preprocessing data.
Catatan
Jika Anda menjalankan proses di atas terhadap semua fitur proses tersebut akan memakan waktu yang cukup lama, Anda dapat melewati tahapan tersebut atau disarankan menggunakan GPU agar proses yang dilakukan bisa berjalan lebih cepat.Anda juga dapat menggunakan T4 GPU yang disediakan oleh Google Colab, ya.
Tenang saja, ini masih awal dari perjalanan yang lebih menegangkan. Pada materi berikutnya, Anda akan mempelajari kedua metode ini lebih detail.
Menangani Duplikasi Data
Bagaimana sampai di sini apakah Anda menikmati petualangan ini? Jika iya, mari kita lanjutkan agar Anda tidak “setengah matang” menjadi seorang machine learning engineer.
Pada tahap ini, Anda perlu melakukan pemeriksaan kepada data yang sudah melewati tahapan-tahapan sebelumnya. Proses tersebut dapat Anda lakukan dengan menggunakan kode berikut.
- # Mengidentifikasi baris duplikat
- duplicates = df.duplicated()
- print("Baris duplikat:")
- print(df[duplicates])

Kode yang berperan untuk melakukan tugas itu adalah duplicated(). Fungsi ini mengembalikan Series boolean yang menunjukkan apakah sebuah baris adalah duplikat atau tidak. Sayangnya seperti yang dapat Anda lihat di atas, kasus ini tidak terdapat satu pun data yang terindikasi duplikat. Oleh karena itu, kita dapat melewati tahapan ini dan melanjutkan ke tahapan berikutnya.
Namun, sayang rasanya jika kita melewati begitu saja tahapan ini. Mari kita bahas sedikit saja dengan catatan kita tidak akan melakukan proses ini pada studi kasus yang sedang dilakukan, ya.
Jika Anda menemukan data duplikat ketika menggunakan kode di atas proses penanganannya sangat sederhana, Anda hanya perlu menghapus data tersebut dengan kode berikut.
- # Menghapus baris duplikat
- df = df.drop_duplicates()
- print("DataFrame setelah menghapus duplikat:")
- print(df)
Jika Anda sadar, kita hanya perlu menggunakan fungsi drop_duplicates() untuk menghapus baris yang teridentifikasi sebagai duplikat dari seluruh DataFrame.
Mengonversi Tipe Data
Tahukah Anda bahwa model machine learning tidak bisa langsung menerima input kategorikal? Hal ini karena mereka bergantung pada operasi matematika yang memerlukan input numerik.
Sebagian besar algoritma machine learning didasarkan pada operasi matematika yang melibatkan perhitungan jarak, gradien, atau distribusi data. Misalnya, regresi linier menghitung persamaan garis menggunakan koefisien yang diterapkan pada fitur numerik. Jika data inputan berupa kategori (seperti "merah," "biru," "hijau"), tidak ada cara langsung untuk memasukkan nilai kategori tersebut ke dalam perhitungan matematika.
Di lain sisi, kategori seperti "merah," "biru," dan "hijau" tidak memiliki urutan atau nilai numerik inheren yang dapat dimengerti oleh model. Jika kategori diberi label numerik (misalnya, "merah" = 1, "biru" = 2, "hijau" = 3), model dapat salah menganggap bahwa ada hubungan matematis di antara kategori tersebut, seperti "biru" menjadi dua kali "merah" yang menghasilkan kesalahan persepsi sehingga mengakibatkan model tidak berjalan sesuai dengan harapan.
Banyak algoritma, terutama yang berbasis jarak (seperti KNN), memerlukan cara untuk mengukur jarak antar titik data. Oleh karena itu jika data bertipe kategori menyebabkan model tidak dapat mengukur jarak, misalnya, tidak ada jarak matematis yang berarti antara "merah" dan "biru."
Untuk mengatasi masalah ini, data kategorikal biasanya diubah menjadi bentuk numerik yang dapat dipahami oleh model yang biasa disebut encoding. Berikut beberapa contoh umum hal yang bisa kita lakukan untuk mengatasi permasalahan ini.
- One-Hot Encoding: mengubah setiap kategori menjadi kolom biner terpisah dengan nilai 0 atau 1 (bisa juga True atau False).

- Label Encoding: memberikan label numerik untuk setiap kategori, meskipun ini hanya cocok untuk data kategorikal ordinal.
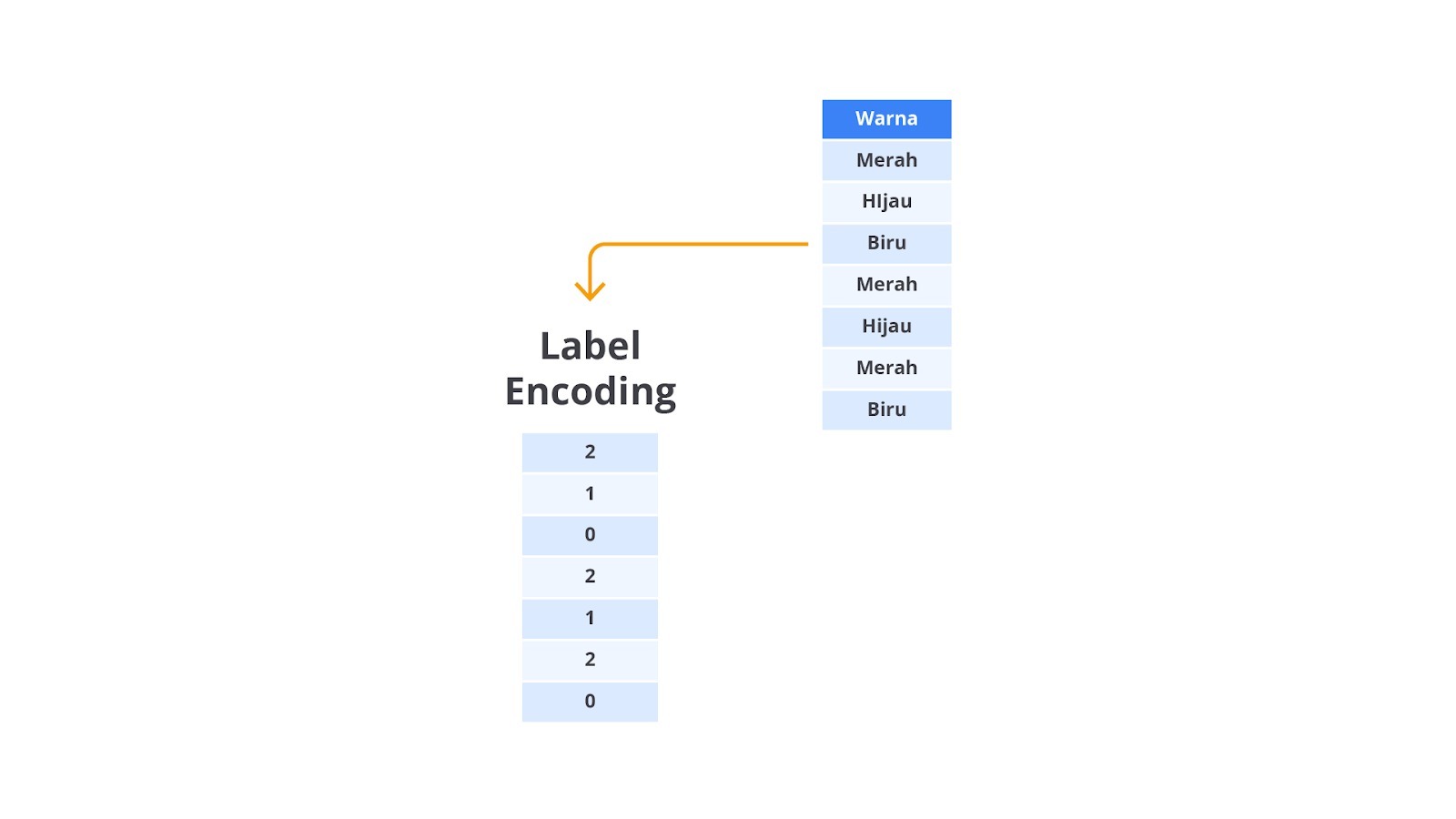
- Ordinal Encoding: mengonversi kategori yang memiliki urutan menjadi nilai numerik yang mencerminkan urutan tersebut.
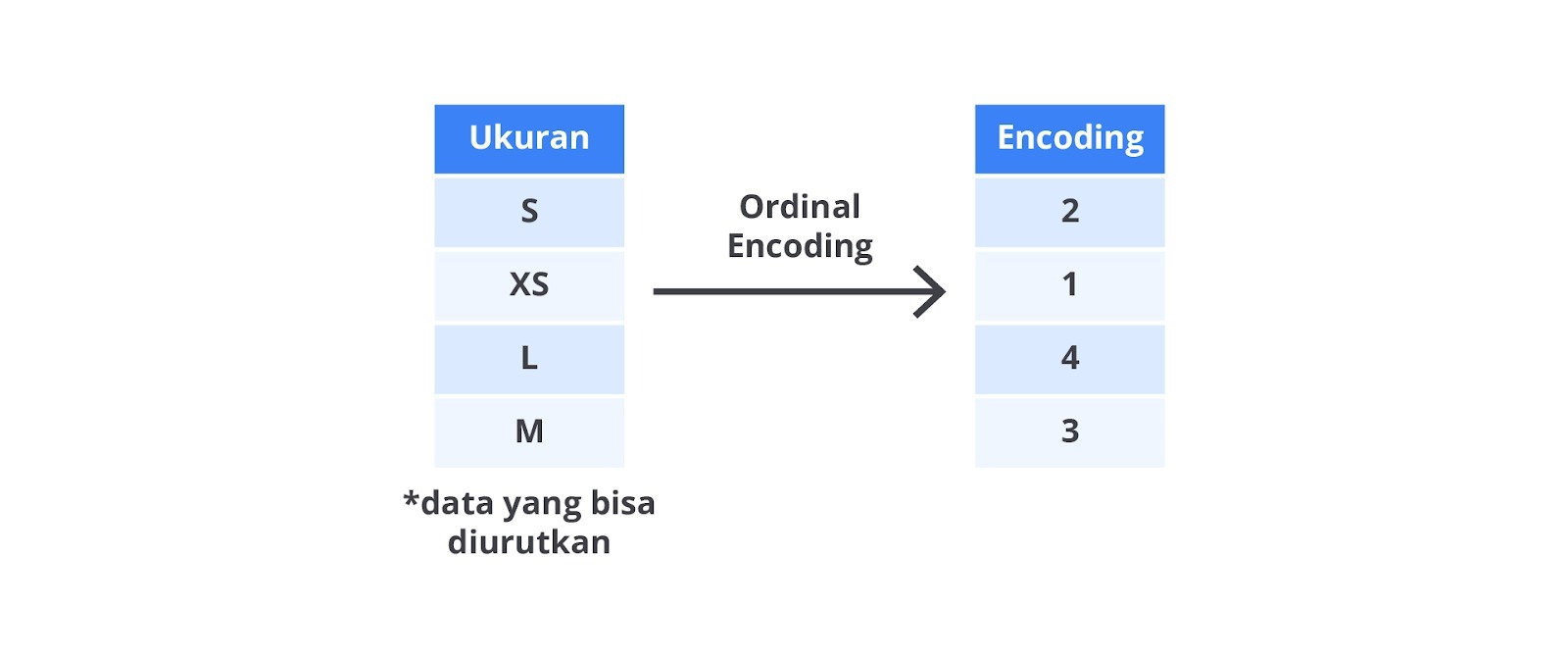
Sebelum kita melakukan encoding, silakan perhatikan data kategorikal yang ada pada dataset menggunakan kode berikut.
- category_features = df.select_dtypes(include=['object']).columns
- df[category_features]
Kita akan menggunakan metode one hot encoding dan label encoding karena data kategorikal yang ada pada dataset ini tidak memiliki urutan. Mari kita lakukan kedua pendekatan tersebut agar semakin terbayang perbedaannya.
One Hot Encoding
Penggunaan one hot encoding sangatlah mudah terutama ketika Anda telah memisahkan nama kolom untuk data kategorikal. Perhatikan kode berikut.
- df_one_hot = pd.get_dummies(df, columns=category_features)
- df_one_hot
Kode di atas akan mengubah seluruh data yang ada pada kolom category_features menjadi numerik dengan memisahkan kolom berdasarkan value yang ada. Kurang lebih hasil dari one hot encoding akan seperti berikut.
Perhatikan jumlah rows dan columns dari output di atas, tentunya sudah terlihat ‘kan perbedaannya? Jumlah kolom yang Anda miliki bertambah sangat banyak yang asalnya berjumlah 77 menjadi 216. Hal ini karena one hot encoding akan memecah suatu fitur menjadi fitur baru dengan struktur “namakolom_value”.
Label Encoding
Berbeda dengan one hot encoding, label encoding membutuhkan sebuah library lainnya untuk mempermudah proses pengerjaannya. Pada kasus ini, Anda akan menggunakan LabelEncoder dari sklearn sebagai senjata utama untuk melakukan encoding. Perhatikan kode berikut.
- from sklearn.preprocessing import LabelEncoder
- # Inisialisasi LabelEncoder
- label_encoder = LabelEncoder()
- df_lencoder = pd.DataFrame(df)
- for col in category_features:
- df_lencoder[col] = label_encoder.fit_transform(df[col])
- # Menampilkan hasil
- df_lencoder
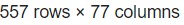
Dengan menggunakan LabelEncoder, jumlah kolom yang ada pada data tidak mengalami perubahan sama sekali. Hal ini karena LabelEncoder hanya mengubah value dari masing-masing fitur yang ia proses.
Sampai di sini Diana masih memiliki sebuah pertanyaan yang sangat membebani pikirannya, “Bagaimana cara menentukan encoder yang tepat untuk setiap kasus ya?” Dengan rasa penasaran tersebut Diana mencari Bilqis dan mengajaknya untuk riset bersama.
Sampai di sini, mari kita bahas bersama terkait kedua pendekatan tersebut. One hot encoding dan label encoding adalah dua teknik yang sering digunakan untuk mengubah data kategorikal menjadi format numerik yang dapat digunakan dalam algoritma machine learning. Keduanya memiliki kelebihan dan kekurangan tergantung pada konteks penggunaannya. Simak kelebihan dan kekurangan dari masing-masing encoder pada materi berikut.
Kelebihan:
- One-hot encoding tidak mengasumsikan adanya urutan atau hierarki di antara kategori, yang sangat cocok untuk data kategorikal nominal (misalnya, warna, jenis kelamin, dll.).
- Karena setiap kategori diubah menjadi kolom terpisah dengan nilai biner (0 atau 1), tidak ada risiko bahwa model akan memperlakukan satu kategori sebagai lebih besar atau lebih kecil daripada yang lain.
- Model yang sensitif terhadap skala numerik, seperti regresi linier, cenderung berfungsi lebih baik dengan one-hot encoding karena tidak ada hubungan numerik yang diciptakan antara kategori.
Kekurangan:
- One-hot encoding dapat menghasilkan DataFrame dengan dimensi yang sangat tinggi jika ada banyak kategori. Hal ini bisa menyebabkan masalah "curse of dimensionality," yang membuat model lebih lambat dan memerlukan lebih banyak memori.
- Hasil one-hot encoding sering kali menjadi sparse matrix, di mana sebagian besar nilainya adalah 0 atau False sehingga bisa memperlambat proses pelatihan.
- Untuk fitur yang memiliki ribuan kategori (misalnya, kode pos), one-hot encoding bisa menjadi tidak praktis karena akan menghasilkan ribuan kolom baru.
Pada akhirnya, pemilihan antara kedua metode ini tergantung pada sifat data kategorikal yang Anda miliki serta kebutuhan spesifik model yang akan Anda bangun.
Pada kasus ini, Diana dan Bilqis akan menggunakan LabelEncoder karena memiliki keterbatasan infrastruktur dan value yang ada bertipe ordinal sehingga sampai pada tahap ini data yang dimiliki Diana seperti berikut.
Sampai di sini, Diana dan Bilqis sudah mengetahui tahapan-tahapan umum untuk melakukan data cleaning dan transformation. Sebetulnya tahapan ini termasuk pada tahapan preprocessing data yang mencakup data cleaning, data transformation, dan data reduction. Namun, pada modul ini, kita hanya memahami dasarnya sebagai fondasi awal. Anda akan menemani perjalanan Diana dalam memperdalam tahapan ini pada modul feature engineering di akhir kelas, ya. Sampai jumpa di sana!
Bacaan Tambahan Tahapan pada data cleaning dan transformation sangatlah beragam tergantung pada kasus yang sedang dihadapi. Sebagai bekal tambahan, dosen Diana dan Bilqis yaitu Pak Fikri memberikan bacaan tambahan yaitu buku Data Preprocessing: Feature Engineering and Extracting Feature from Text. |
Exploratory dan Explanatory Data Analysis
Halo, calon praktisi data masa depan!
Setelah Anda melewati tahapan yang cukup menantang pada materi sebelumnya, sekarang kita sudah sampai di pertengahan materi kelas yang tak kalah serunya. Sejauh ini, kita sudah mempelajari berbagai konsep dasar dalam machine learning workflow beserta teknik yang sering digunakan dalam proses pembangunan machine learning.
Nah, sekarang kita akan lanjut ke tahap berikutnya yang tidak kalah penting, yaitu Exploratory Data Analysis (EDA). EDA merupakan tahap eksplorasi data yang telah dibersihkan guna memperoleh insight dan menjawab pertanyaan analisis. Pada prosesnya, kita akan sering menggunakan berbagai teknik dan parameter dalam descriptive statistics yang bertujuan untuk menemukan pola, hubungan, serta membangun intuisi terkait data yang diolah. Selain itu, tidak jarang kita juga menggunakan visualisasi data untuk menemukan pola dan memvalidasi parameter descriptive statistics yang diperoleh.
Menurut pandangan para praktisi data, EDA (Exploratory Data Analysis) adalah salah satu tahap yang paling sexy dalam proyek analisis data. Tahap ini memungkinkan para praktisi untuk mengeksplorasi dan bereksperimen dengan data guna menemukan pola, mendapatkan wawasan, menjawab berbagai tantangan bisnis serta menyusun kesimpulan berdasarkan hasil analisis yang diperoleh.
Sebagai calon engineer di masa depan, Anda pasti akan menikmati proses EDA ini karena tahapan ini tidak mungkin dilewati. Sebagai gambaran, dalam beberapa materi ke depan, kita akan membahas berbagai alat dan teknik yang dapat membantu Anda menjalankan proses EDA dengan efektif. Namun, sebelum masuk ke dalam topik tersebut, ada baiknya kita memahami perbedaan antara exploratory analysis dan explanatory analysis terlebih dahulu.
Exploratory Data Analysis (EDA) dan Explanatory Data Analysis (ExDA) adalah dua tahap yang penting dalam proses analisis data, namun memiliki tujuan dan pendekatan yang berbeda. Mari kita breakdown kedua tahap tersebut secara komprehensif mulai dari tujuan, metodologi, visualisasi data, audiens, contoh kasus hingga outputnya.
Tujuan
Exploratory Data Analysis (EDA):
- Tujuan utama dari EDA adalah untuk memahami struktur, karakteristik, dan pola dalam data. Pada tahap ini, Anda memiliki misi untuk menemukan insight atau informasi yang tersembunyi dalam data, mengidentifikasi anomali, serta memahami hubungan antar variabel.
- EDA bersifat eksploratif dan terbuka sehingga Anda tidak memiliki hipotesis yang pasti di awal prosesnya. Sebaliknya, Anda dapat menggunakan EDA untuk membangun hipotesis atau memahami lebih dalam data yang mereka miliki.
Explanatory Data Analysis (ExDA):
- ExDA di sisi lain memiliki tujuan utama untuk mengomunikasikan temuan atau insight yang sudah didapatkan kepada audiens yang lebih luas, seperti stakeholder, tim eksekutif, atau klien.
- Pada tahap ini, analisis data berfokus pada penyampaian informasi yang jelas, ringkas, dan meyakinkan, dengan dukungan visualisasi yang efektif dan narasi yang kuat.
Jika disimpulkan, explanatory analysis merupakan proses penyampaian temuan menarik dari proses exploratory analysis. Proses penyampaian ini tentunya harus diikuti dengan visualisasi data yang baik dan efektif.
Pendekatan dan Metodologi
Exploratory Data Analysis (EDA):
- EDA sering menggunakan berbagai teknik statistik deskriptif seperti mean, median, standar deviasi, dan distribusi frekuensi, serta visualisasi data seperti histogram, scatter plot, box plot, dan heatmap untuk mengeksplorasi data.
- Metodologi dalam EDA bersifat iteratif dan fleksibel. Seorang analis dapat mencoba berbagai pendekatan, mengubah parameter, atau menggunakan berbagai visualisasi hingga mendapatkan insight yang mendalam.
- EDA juga sering kali melibatkan proses pembersihan data sehingga data yang hilang, outlier, atau inkonsistensi diidentifikasi dan diperbaiki.
Explanatory Data Analysis (ExDA):
- ExDA menggunakan visualisasi dan narasi yang sangat fokus dan terarah sehingga setiap elemen dalam presentasi atau laporan ditujukan untuk mendukung argumen atau kesimpulan yang ingin disampaikan.
- Metodologi ExDA adalah terstruktur dan sistematis, biasanya dimulai dari pernyataan masalah atau hipotesis, kemudian mendukungnya dengan data yang telah dieksplorasi dan dianalisis, dan diakhiri dengan kesimpulan yang jelas.
- ExDA juga sering menggunakan storytelling sebagai alat untuk menyampaikan temuan, memastikan bahwa audiens dapat memahami dan terhubung dengan informasi yang disampaikan.
Visualisasi Data
Exploratory Data Analysis (EDA):
- Visualisasi dalam EDA bersifat eksploratif dan sering digunakan untuk membantu analis memahami data. Visualisasi dapat berupa berbagai jenis grafik yang menunjukkan hubungan antar variabel, distribusi data, atau pola yang tidak terduga.
- Karena sifatnya yang eksploratif, visualisasi dalam EDA tidak selalu rapi atau terstruktur, melainkan lebih banyak digunakan untuk mendukung pemahaman dan penggalian insight.
Explanatory Data Analysis (ExDA):
- Visualisasi dalam ExDA dirancang untuk menghasilkan komunikasi yang efektif. Grafik dan visual yang digunakan dalam ExDA harus jelas, sederhana, dan langsung ke poin utama yang ingin disampaikan.
- Contoh visualisasi yang sering digunakan dalam ExDA termasuk bar chart, line chart, atau pie chart yang sederhana, tetapi efektif, serta infografis yang dapat menyampaikan informasi dengan cara yang menarik dan mudah dipahami.
Audiens
Exploratory Data Analysis (EDA):
- Pengguna utama dari EDA adalah analis data, data scientist, atau researcher yang bekerja langsung dengan data untuk memahami dan mengembangkan hipotesis.
- EDA adalah proses internal, sering kali dilakukan oleh individu atau tim yang bertanggung jawab atas pengolahan dan analisis data.
Explanatory Data Analysis (ExDA):
- Audiens ExDA biasanya adalah stakeholder, pengambil keputusan, manajer, atau klien yang memerlukan informasi untuk membuat keputusan bisnis atau memahami hasil dari analisis yang dilakukan.
- ExDA adalah proses eksternal yang fokus pada komunikasi dan presentasi hasil analisis kepada pihak yang mungkin tidak memiliki latar belakang teknis yang mendalam.
Contoh Kasus
Exploratory Data Analysis (EDA):
- Misalnya, dalam sebuah proyek penelitian yang bertujuan untuk menemukan faktor-faktor yang memengaruhi penjualan produk, EDA akan digunakan untuk memahami bagaimana variabel-variabel seperti harga, lokasi, waktu promosi, dan lainnya berhubungan dengan penjualan. Pada tahap ini, analis bisa menemukan pola-pola tak terduga atau anomali dalam data.
Explanatory Data Analysis (ExDA):
- Setelah temuan signifikan diperoleh dari EDA, ExDA akan digunakan untuk menyusun laporan yang menjelaskan faktor-faktor yang memengaruhi penjualan kepada manajemen, dengan menggunakan grafik sederhana, tabel, dan narasi yang jelas sehingga manajemen dapat membuat keputusan yang tepat berdasarkan hasil analisis.
Output
Exploratory Data Analysis (EDA):
- Hasil dari EDA biasanya adalah insight, hipotesis baru, pemahaman yang lebih dalam tentang data, dan beberapa rekomendasi awal untuk analisis lebih lanjut.
Explanatory Data Analysis (ExDA):
- Output dari ExDA adalah laporan akhir, presentasi, atau dashboard yang berfungsi untuk menyampaikan hasil analisis dengan cara yang informatif dan mudah dipahami oleh audiens non-teknis.
Nah, sekarang Anda telah memahami perbedaan antara exploratory analysis dan explanatory analysis. Pada beberapa materi ke depan, kita akan mulai dengan membahas berbagai teknik dalam exploratory analysis dan explanatory analysis.
So, are you ready to explore? Ayo berangkat!
Latihan: Exploratory dan Explanatory Data Analysis
Masih ingatkah Anda dengan tahapan data cleaning dan transformation pada materi sebelumnya? Selamat jika Anda mengikuti dan mengerjakan latihan tersebut karena pada tahapan ini, kita akan melanjutkan hasil dari proses sebelumnya.
Sebenarnya, tahapan ini memiliki irisan yang cukup besar dengan latihan sebelumnya sehingga kita akan melewati beberapa tahapan yang sudah dilakukan pada materi data cleaning dan transformation.
Dengan kondisi seperti di atas, ada baiknya Anda melakukan pemeriksaan kembali terhadap DataFrame yang akan digunakan. Pada kasus ini, kita sepakat untuk menggunakan data yang telah melalui tahapan LabelEncoder. Jika Anda penasaran dengan One Hot Encoding, silakan berlatih secara mandiri dan temukan perbedaannya, ya.
- df_lencoder.head()
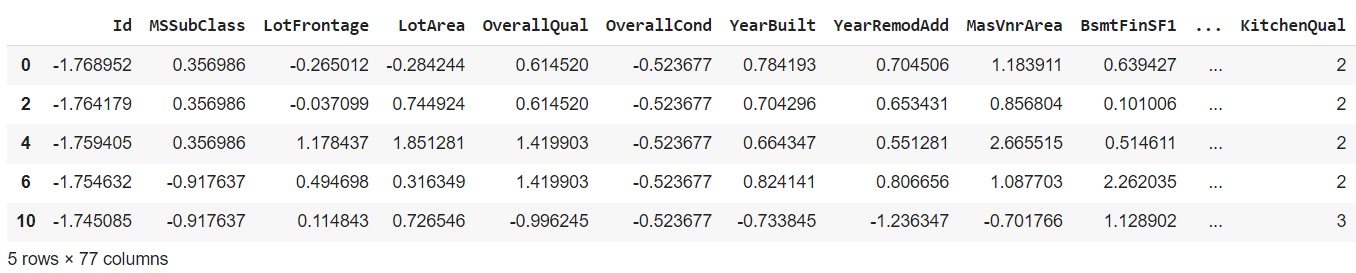
Karena pada tahapan data cleaning dan transformation Anda telah melakukan analisis deskriptif, pada tahapan ini kita memiliki asumsi bahwa data tersebut sudah bersih dan terdistribusi dengan baik. Bagaimana cara membuktikannya? Salah satu caranya adalah memeriksa kembali missing value pada dataset yang akan digunakan.
- # Menghitung jumlah dan persentase missing values di setiap kolom
- missing_values = df_lencoder.isnull().sum()
- missing_percentage = (missing_values / len(df_lencoder)) * 100
- missing_data = pd.DataFrame({
- 'Missing Values': missing_values,
- 'Percentage': missing_percentage
- }).sort_values(by='Missing Values', ascending=False)
- missing_data[missing_data['Missing Values'] > 0] # Menampilkan kolom dengan missing values
Seperti yang Anda lihat pada output di atas, tidak terdapat satu pun missing value karena kita sudah menangani permasalahan tersebut pada materi sebelumnya. Selanjutnya, lakukan analisis deskriptif menggunakan .describe() atau membuat histogram agar distribusi data lebih terlihat. Karena kita telah mempelajari fungsi .describe(), pada latihan ini akan menggunakan histogram untuk melihat sebaran data.
- # Menghitung jumlah variabel
- num_vars = df_lencoder.shape[1]
- # Menentukan jumlah baris dan kolom untuk grid subplot
- n_cols = 4 # Jumlah kolom yang diinginkan
- n_rows = -(-num_vars // n_cols) # Ceiling division untuk menentukan jumlah baris
- # Membuat subplot
- fig, axes = plt.subplots(n_rows, n_cols, figsize=(20, n_rows * 4))
- # Flatten axes array untuk memudahkan iterasi jika diperlukan
- axes = axes.flatten()
- # Plot setiap variabel
- for i, column in enumerate(df_lencoder.columns):
- df_lencoder[column].hist(ax=axes[i], bins=20, edgecolor='black')
- axes[i].set_title(column)
- axes[i].set_xlabel('Value')
- axes[i].set_ylabel('Frequency')
- # Menghapus subplot yang tidak terpakai (jika ada)
- for j in range(i + 1, len(axes)):
- fig.delaxes(axes[j])
- # Menyesuaikan layout agar lebih rapi
- plt.tight_layout()
- plt.show()
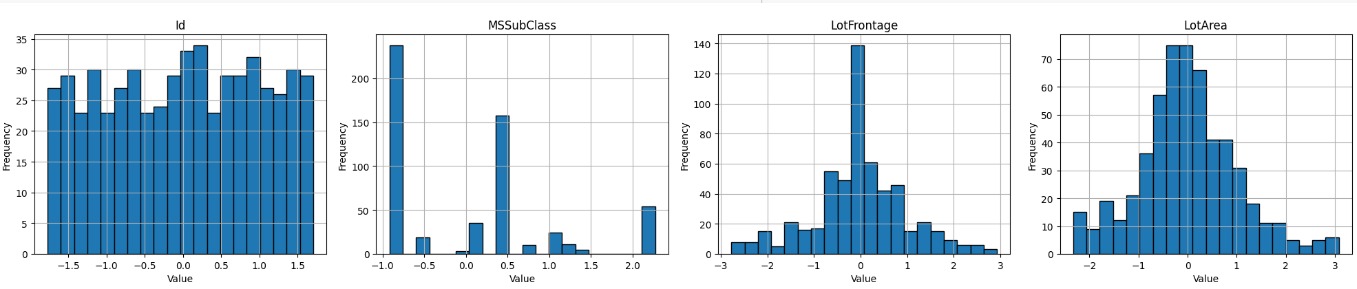
Silakan jalankan seluruh kode untuk melihat keseluruhan output dari kode di atas karena hasilnya cukup panjang untuk ditampilkan pada kelas. Jika Anda perhatikan pada seluruh output yang dihasilkan menunjukkan bahwa semua kolom sudah dinormalisasi atau distandardisasi. Hal tersebut ditunjukkan dari nilai rata-rata (mean) untuk hampir semua kolom adalah mendekati 0, dan standar deviasi (std) sekitar 1. Hal ini menunjukkan bahwa data telah diproses sehingga setiap fitur memiliki skala yang serupa untuk membantu proses analisis lebih lanjut.
Selanjutnya, mari kita visualisasikan distribusi beberapa kolom serta melihat korelasi antara variabel numerik.
- import matplotlib.pyplot as plt
- import seaborn as sns
- # Visualisasi distribusi data untuk beberapa kolom
- columns_to_plot = ['OverallQual', 'YearBuilt', 'LotArea', 'SaleType', 'SaleCondition']
- plt.figure(figsize=(15, 10))
- for i, column in enumerate(columns_to_plot, 1):
- plt.subplot(2, 3, i)
- sns.histplot(df_lencoder[column], kde=True, bins=30)
- plt.title(f'Distribution of {column}')
- plt.tight_layout()
- plt.show()
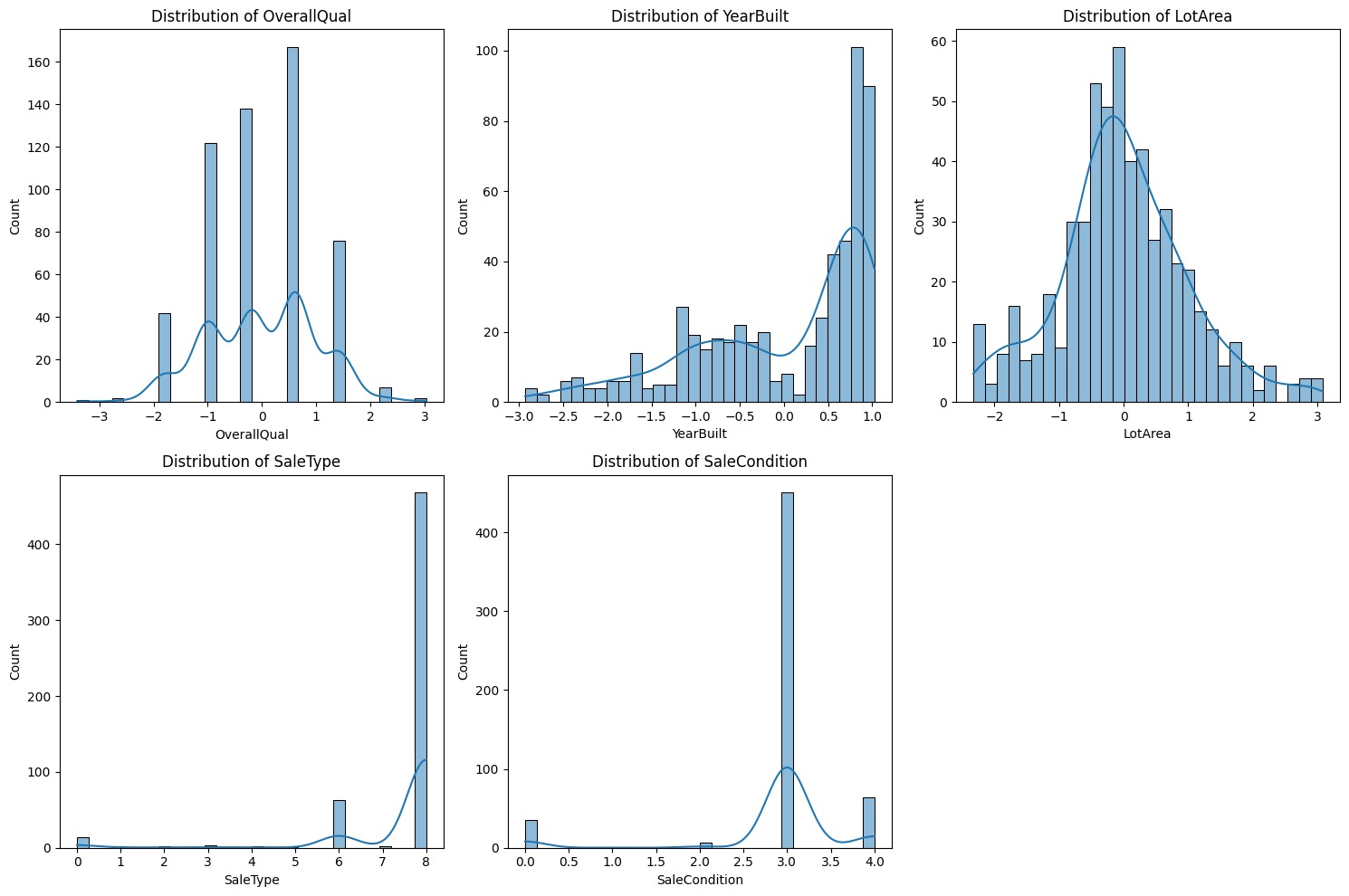
Seperti yang dapat Anda lihat dari hasil distribusi beberapa kolom yang menunjukkan variasi yang signifikan seperti berikut.
- OverallQual: sebagian besar data terkonsentrasi di sekitar nilai tengah dengan distribusi miring ke kanan.
- YearBuilt: distribusi cenderung normal dengan beberapa lonjakan pada tahun tertentu, menunjukkan periode pembangunan rumah yang lebih aktif.
- LotArea: distribusinya tidak simetris karena adanya beberapa outlier yang signifikan pada sisi kanan (lot area yang sangat besar).
- SaleType: kategori tertentu mendominasi distribusi, menunjukkan preferensi atau pola tertentu dalam tipe penjualan.
- SaleCondition: mirip dengan SaleType, beberapa kondisi penjualan lebih umum dibandingkan lainnya.
Untuk mengetahui kondisi kolom lainnya, silakan lakukan analisis secara mandiri supaya Anda dapat memahami dan memaksimalkan pengalaman belajar untuk melakukan eksplorasi data.
Berikutnya, kita perlu melakukan analisis korelasi dengan membuat matriks korelasi. Matriks korelasi menunjukkan beberapa hubungan penting antara variabel-variabel yang ada dalam dataset. Biasanya warna yang lebih terang atau lebih gelap mengindikasikan korelasi yang lebih kuat (positif atau negatif). Untuk melakukan analisis korelasi Anda dapat menggunakan kode berikut sebagai panduan awal.
- # Visualisasi korelasi antar variabel numerik
- plt.figure(figsize=(12, 10))
- correlation_matrix = df_lencoder.corr()
- sns.heatmap(correlation_matrix, annot=False, cmap='coolwarm', vmin=-1, vmax=1)
- plt.title('Correlation Matrix')
- plt.show()
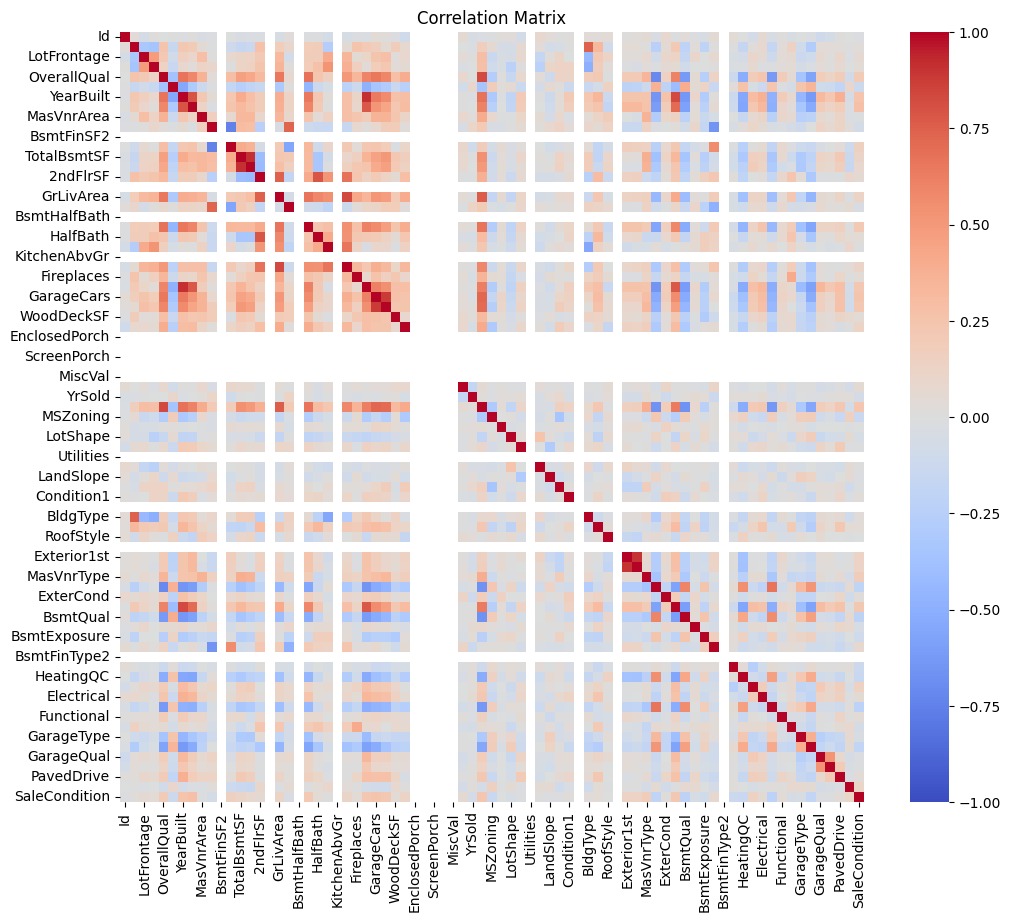
Beberapa poin penting yang bisa diambil dari analisis korelasi di atas antara lain sebagai berikut.
- Ada korelasi positif yang kuat antara variabel tertentu, seperti antara OverallQual dan SalePrice (kolom ini ada tetapi tidak tertulis karena banyaknya fitur) yang menunjukkan bahwa kualitas rumah mungkin berhubungan erat dengan harga jualnya.
- Korelasi negatif atau rendah juga terlihat pada beberapa pasangan variabel, menunjukkan hubungan yang lemah atau tidak ada antara variabel tersebut.
Silakan buat kesimpulan berdasarkan data matriks korelasi di atas dengan catatan sebagai berikut.
- Korelasi Positif: nilai korelasi positif menunjukkan bahwa saat satu variabel meningkat, variabel lain juga cenderung meningkat. Nilai korelasi +1 menunjukkan korelasi positif sempurna.
- Korelasi Negatif: nilai korelasi negatif menunjukkan bahwa saat satu variabel meningkat, variabel lain cenderung menurun. Nilai korelasi -1 menunjukkan korelasi negatif sempurna.
- Korelasi Nol: nilai korelasi 0 menunjukkan bahwa tidak ada hubungan linier antara dua variabel.
Dengan memahami korelasi antar variabel, Anda dapat memilih fitur yang akan dimasukkan ke dalam model machine learning dengan lebih baik serta memahami dinamika data secara lebih mendalam.
Pada tahapan ini, sebetulnya Anda bisa saja mengurangi fitur atau variabel yang tidak memiliki hubungan linier dengan variabel target (pada kasus ini SalePrice). Untuk mempermudah proses analisis tersebut, mari kita buat matriks korelasi hanya terhadap variabel atau fitur SalePrice saja sebagai variabel dependen pada studi kasus ini.
- # Menghitung korelasi antara variabel target dan semua variabel lainnya
- target_corr = df_lencoder.corr()['SalePrice']
- # (Opsional) Mengurutkan hasil korelasi berdasarkan korelasi
- target_corr_sorted = target_corr.abs().sort_values(ascending=False)
- plt.figure(figsize=(10, 6))
- target_corr_sorted.plot(kind='bar')
- plt.title(f'Correlation with SalePrice')
- plt.xlabel('Variables')
- plt.ylabel('Correlation Coefficient')
- plt.show()
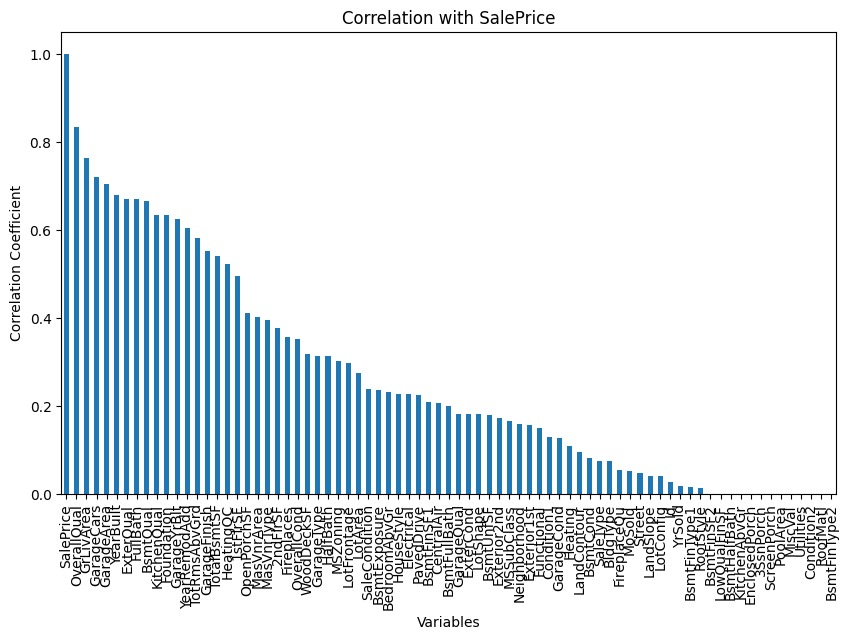
Berdasarkan matriks korelasi dari masing-masing kolom terhadap SalePrice di atas, Anda bisa menentukan threshold atau batasan korelasi untuk menentukan kolom mana saja yang akan dipilih. Tentunya pemilihan kolom tersebut akan menyebabkan perbedaan performa model sehingga Anda perlu melakukan eksplorasi untuk mendapatkan hasil yang terbaik. Dengan kata lain, jika tidak ingin mengurangi kolom karena alasan tertentu tentu Anda dapat menghiraukan tahapan ini.
Sampai di sini, menarik ‘kan? Karena tahapan exploratory data analysis ini merupakan tahapan yang sangat “bebas”. Anda dapat melakukan apa saja di sini tanpa ada guideline khusus yang wajib diikuti. Hal ini dapat memberikan developer kesempatan untuk melakukan eksplorasi “segila” mungkin untuk hasil yang maksimal.
Pro Tips Perlu Anda catat dalam konteks machine learning exploratory ini masih sangat luas untuk digali. Tentu saja dengan kebebasan itu, Anda juga perlu fondasi untuk melakukan analisis lainnya. Sayangnya pada materi ini tidak akan dibahas terlalu dalam karena kita menggunakan data yang sudah ada dari open data dan memiliki permasalahan yang pasti. Oleh karena itu, jika Anda masih penasaran terkait exploratory data analisis kami menyarankan untuk membaca salah satu buku berjudul “Exploratory Data Analysis with Python Cookbook” Di lain sisi, jika Anda ingin mempertajam kemampuan analisis data, silakan membaca kembali di kelas Belajar Analisis Data dengan Python karena kelas tersebut dibuat khusus untuk meningkatkan kemampuan analisis Anda. |
Berdasarkan hasil eksplorasi di atas, tentunya Anda dapat menyimpulkan beberapa hal. Santai saja tidak ada salah atau benar pada kondisi seperti ini. Silakan ambil waktu luang Anda untuk menyimpulkan proses analisis tersebut, ya.
Jika Anda sudah bisa menyimpulkan hasil dari eksplorasi tersebut, mari kita samakan dengan beberapa kesimpulan berikut.
- Hubungan antara Luas Ruang Tinggal dan Harga Jual
Analisis di atas menunjukkan hubungan positif yang kuat antara luas ruang tinggal (GrLivArea) dan harga jual (SalePrice). Properti dengan luas ruang tinggal yang lebih besar cenderung memiliki harga jual yang lebih tinggi. - Dampak Luas Garasi
Korelasi yang moderat antara luas garasi (GarageArea) dan harga jual menunjukkan bahwa properti dengan garasi yang lebih luas memungkinkan untuk dijual dengan harga lebih tinggi. - Outliers dan Distribusi
Outliers yang ditemukan dalam variabel seperti SalePrice dan GrLivArea dapat memberikan wawasan tentang properti-properti yang luar biasa dalam hal harga dan ukuran. Namun, mereka juga bisa menyesatkan analisis jika tidak ditangani dengan benar. Transformasi logaritmik membantu untuk mengatasi hal ini. - Pengaruh Signifikan dari Ukuran Properti
Pengembang properti atau investor harus mempertimbangkan ukuran ruang tinggal dan garasi sebagai faktor utama yang memengaruhi nilai jual. - Pengelolaan Outliers
Outliers yang ditemukan harus dianalisis lebih lanjut untuk memahami apakah mereka mencerminkan kondisi pasar yang unik atau kesalahan dalam data.
Kesimpulannya exploratory data analysis (EDA) dan explanatory data analysis (ExDA) adalah dua langkah penting dalam analisis data yang saling melengkapi. EDA bertujuan untuk memahami pola, anomali, dan struktur dalam data secara mendalam melalui visualisasi dan teknik statistik tanpa asumsi awal, sehingga membuka wawasan baru dan membantu membentuk hipotesis. Sebaliknya, ExDA fokus pada komunikasi temuan yang jelas dan meyakinkan, menggunakan visualisasi dan narasi yang efektif untuk menjelaskan dan mendukung argumen berdasarkan hasil analisis. Keduanya esensial untuk menghasilkan analisis yang valid dan dapat dimengerti oleh berbagai pemangku kepentingan (stakeholder).
Setelah memahami EDA dan ExDA, kini saatnya Anda melangkah ke tahap berikutnya, yaitu data splitting. Apakah Anda sudah siap? Yuk, kita pindah ke materi berikutnya!
Data Splitting
Heyoww calon engineer masa depan! Sebelum Anda melakukan pembangunan model (modelling) ada satu hal yang perlu dilakukan agar mempermudah proses pelatihan machine learning, yaitu data splitting.
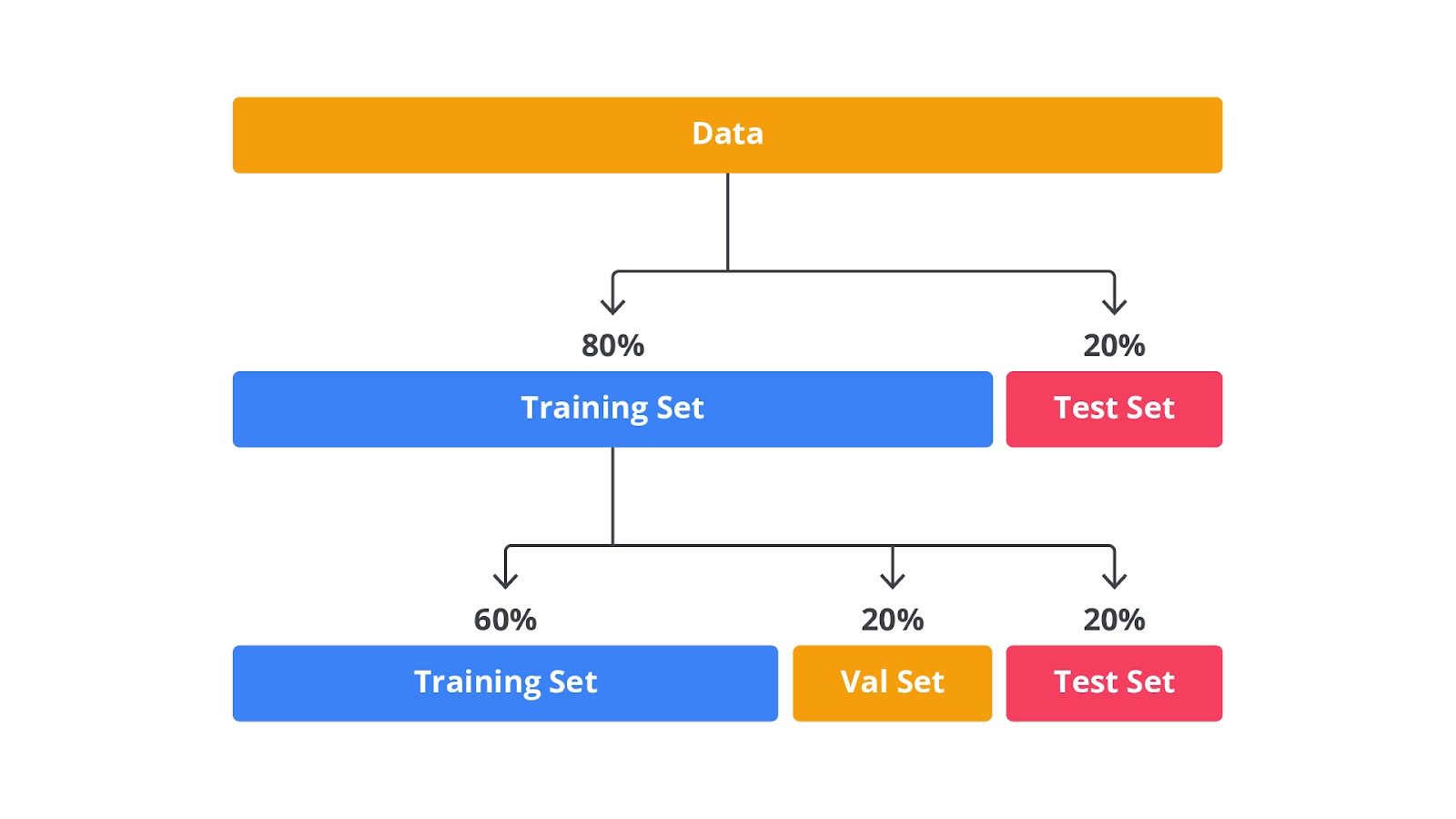
Data Splitting adalah proses membagi dataset menjadi beberapa subset yang terpisah untuk tujuan pelatihan, validasi, dan pengujian model machine learning. Proses ini merupakan langkah penting dalam pipeline machine learning karena membantu memastikan model yang dikembangkan mampu membuat prediksi yang baik tidak hanya pada data pelatihan, tetapi juga pada data baru yang belum pernah dilihat sebelumnya.
Lalu, mengapa data splitting itu penting? Walaupun terlihat sederhana, data splitting setidaknya memiliki peran untuk menghindari overfitting, menyediakan evaluasi yang akurat, dan memberikan validasi yang adil. Selain dari ketiga peran tersebut sebenarnya masih banyak hal yang membuat data splitting itu penting, tetapi pada kesempatan kali ini mari kita jabarkan terlebih dahulu ketiga peran tersebut sebagai dasar pengetahuan.
- Menghindari Overfitting:
Tanpa data splitting, model machine learning mungkin belajar terlalu banyak dari data pelatihan, termasuk noise dan outliers, sehingga kinerjanya menurun pada data baru. Data splitting membantu menguji generalisasi model pada data yang belum pernah dilihat oleh model pada proses pelatihan.
- Menyediakan Evaluasi yang Akurat:
Dengan memisahkan data untuk pelatihan, validasi, dan pengujian kita bisa mengevaluasi kinerja model secara lebih akurat. Proses ini dapat membantu dalam memilih model terbaik dan mengatur hyperparameter dengan lebih baik.
- Validasi yang Adil:
Data splitting memungkinkan kita untuk melakukan validasi model secara adil dengan menggunakan bagian dari data yang tidak dilibatkan dalam proses pelatihan untuk mengukur kinerja model.
Lantas apa saja bagian yang perlu kita tentukan ketika melakukan splitting? Setelah melakukan splitting Anda akan memiliki beberapa set data yang berisikan kolom yang sama. Sebetulnya proses splitting ini terbagi menjadi dua kubu yang sama besar yaitu kubu dua jenis (training dan testing) dan kubu tiga jenis (training, testing dan validation). Namun, Anda tidak perlu bingung karena sejatinya kedua kubu tersebut sama dan memiliki tujuan yang serupa.
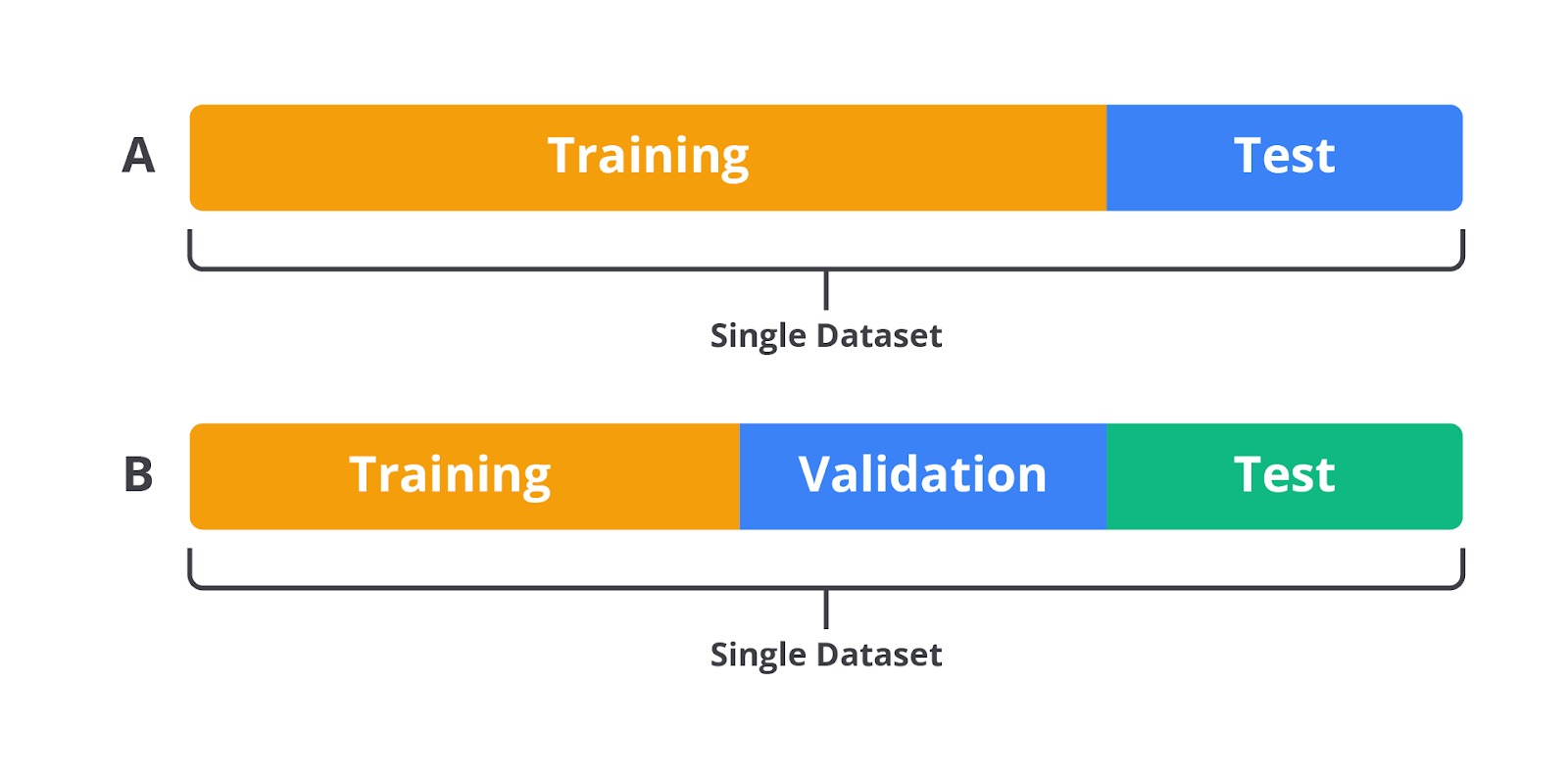
Jika Anda lebih condong ke salah satu kubu di atas, tenang saja kita tetap akan mempelajari hal yang sama mengenai jenis data setelah dilakukan splitting.
Training Set
- Deskripsi: subset data yang digunakan untuk melatih model. Model belajar pola dari data ini dan menyesuaikan parameternya.
- Persentase Umum: biasanya 60-80% dari total dataset.
Validation Set
- Deskripsi: subset data yang digunakan untuk melakukan validasi selama proses pelatihan. Ini digunakan untuk tuning hyperparameter dan memilih model terbaik. Model tidak melihat data ini selama pelatihan.
- Persentase Umum: biasanya 10-20% dari total dataset.
Test Set
- Deskripsi: subset data yang digunakan untuk melakukan pengujian akhir setelah model selesai dilatih dan di-tuning. Ini memberikan estimasi kinerja model pada data baru.
- Persentase Umum: biasanya 10-20% dari total dataset.
Rasio yang paling umum digunakan untuk data splitting adalah 70:30 atau 80:20, di mana 70-80% data digunakan untuk pelatihan (training) dan 20-30% sisanya digunakan untuk pengujian (testing). Alternatif lain yang sering digunakan adalah 60:20:20, di mana 60% data digunakan untuk pelatihan, 20% untuk validasi, dan 20% untuk pengujian.
Nerd Tips Tidak ada aturan baku yang berlaku untuk semua kasus dalam hal data splitting. Rasio seperti 70:30 atau 80:20 memang sering digunakan sebagai pedoman umum, tetapi pemilihan rasio yang tepat sebenarnya sangat kontekstual dan bergantung pada beberapa faktor seperti ukuran dataset, kompleksitas model, ketersediaan data label dan lain sebagainya. Yang terpenting Anda dapat memastikan bahwa data yang digunakan untuk pengujian cukup representatif untuk mengevaluasi kinerja model secara akurat. |
Terdapat beberapa teknik yang umum dilakukan pada tahap data splitting, perhatikan tabel berikut.
| Metode | Deskripsi | Kelebihan | Kekurangan |
|---|---|---|---|
Holdout Method | Metode dasar yang membaginya menjadi dua atau tiga bagian: training set, validation set, dan test set. Ini adalah metode yang paling sederhana dan umum digunakan. | Mudah diimplementasikan dan cepat. | Jika dataset kecil, pembagian data mungkin tidak mewakili distribusi data secara keseluruhan. |
K-Fold Cross Validation | Teknik yang membagi dataset menjadi k subset (folds). Model dilatih “k” kali setiap menggunakan satu fold sebagai test set dan k-1 fold lainnya sebagai training set. | Memberikan evaluasi yang lebih robust, mengurangi bias karena setiap data digunakan untuk pelatihan dan pengujian. | Lebih lambat karena model harus dilatih “k” kali. |
Stratified Splitting | Teknik splitting akan membagi data sedemikian rupa sehingga proporsi kelas dalam training, validation, dan test set tetap sama seperti di dataset asli. Ini sangat penting jika kondisi dataset tidak seimbang. | Menghindari bias dalam prediksi pada kelas minoritas. | Lebih kompleks daripada holdout biasa. |
Time Series Splitting | Untuk data time series, data harus dibagi berdasarkan waktu. Data yang lebih baru digunakan untuk pengujian, sementara data yang lebih lama digunakan untuk pelatihan. | Cocok untuk data time series yang membutuhkan urutan kronologis. | Tidak dapat digunakan untuk data non-time series. |
Setelah mengetahui teknik-teknik untuk melakukan splitting tentunya Anda sudah tidak sabar untuk melangkah lebih jauh ‘kan? Sabar dahulu karena untuk melangkah lebih jauh, Anda perlu mempertimbangkan beberapa hal seperti berikut untuk menghasilkan pembagian yang optimal.
- Imbalance Data: jika dataset memiliki distribusi kelas yang tidak seimbang, teknik seperti stratified splitting sangat penting untuk memastikan bahwa model tidak bias terhadap kelas mayoritas.
- Data Leakage: data leakage terjadi ketika informasi dari luar set pelatihan "bocor" ke dalam proses pelatihan sehingga kinerja model di test set tampak lebih baik daripada yang sebenarnya. Splitting yang benar membantu menghindari masalah ini.
- Randomness: randomness dalam proses splitting penting untuk memastikan bahwa pembagian data tidak bias. Namun, untuk eksperimen yang dapat direproduksi, sangat penting untuk menetapkan random_state yang tetap.
Dengan memahami dan menerapkan teknik data splitting secara benar, Anda dapat mengembangkan model machine learning yang lebih andal dan akurat.
Perdebatan Mana yang Lebih Dahulu?
Fun fact, sebuah pertanyaan tentang “Preprocessing dulu atau data splitting dulu ya?” sering kali muncul dalam berbagai platform. Lalu, apa jawabannya? Jawabannya tergantung pada jenis preprocessing yang dilakukan.
Ada beberapa jenis preprocessing yang sebaiknya dilakukan sebelum data splitting, terutama jika preprocessing tersebut memerlukan pengetahuan tentang keseluruhan dataset seperti berikut.
- Imputasi Missing Values: jika Anda memiliki missing values dalam dataset, biasanya Anda perlu mengisi nilai-nilai tersebut (misalnya, dengan rata-rata atau median) sebelum melakukan splitting. Ini karena Anda perlu mengisi missing value berdasarkan keseluruhan distribusi data, bukan hanya pada subset data tertentu.
- Encoding Kategorikal: jika Anda melakukan encoding pada variabel kategorikal (misalnya, one-hot encoding atau label encoding), sering kali lebih baik melakukannya sebelum splitting untuk memastikan bahwa encoding konsisten di seluruh dataset.
- Pembersihan Data Umum: pembersihan data yang melibatkan penghapusan outliers, menangani duplikasi, atau menyamakan format data juga sebaiknya dilakukan sebelum splitting. Ini memastikan bahwa data yang masuk ke proses splitting sudah dalam kondisi terbaiknya.
Namun, ada jenis preprocessing lain yang sebaiknya dilakukan setelah data splitting untuk menghindari data leakage (yaitu, informasi dari test set bocor ke dalam model pelatihan) seperti berikut.
- Standardisasi/Normalisasi: proses seperti standardisasi (mengubah data agar memiliki mean 0 dan standar deviasi 1) atau normalisasi (mengubah data agar berada dalam rentang tertentu) sebaiknya dilakukan setelah splitting. Ini karena Anda ingin memastikan bahwa test set benar-benar terpisah dari data pelatihan, dan standardisasi atau normalisasi dilakukan hanya berdasarkan data pelatihan.
- Feature Engineering: teknik seperti pembuatan fitur baru atau transformasi fitur (misalnya, log transform, polynomial features) sebaiknya dilakukan setelah data splitting untuk menghindari informasi dari test set yang memengaruhi model.
- Scaling dan PCA: teknik seperti scaling atau Principal Component Analysis (PCA) yang mengubah skala atau struktur data juga sebaiknya dilakukan setelah data splitting.
Dengan memahami urutan yang lebih baik untuk preprocessing dan data splitting, Anda dapat membangun model machine learning yang lebih andal, generalizable, dan bebas dari bias yang disebabkan oleh data leakage atau inkonsistensi dalam data.
Eitss, tetapi tetap saja tahapan ini masih menjadi perdebatan dan terbagi menjadi beberapa kubu. Yang perlu Anda pastikan adalah menjaga konsistensi, integritas data, dan mencegah data leakage. Selagi Anda mengikuti saran dan memperhatikan parameter tersebut, sebenarnya Anda dapat menyesuaikan urutan dari tahapan-tahapan yang ada.
Latihan: Data Splitting
Pada kesempatan kali ini Anda akan belajar membagi dataset menggunakan fungsi Train Test Split (holdout method) dari library SKLearn. Ke depannya Anda juga akan mempelajari metode lainnya yang sudah diberi tahu pada sub modul data splitting.
Untuk latihan membagi dataset ini terbilang sangat mudah. Tahapannya terdiri dari langkah-langkah sebagai berikut.
- Persiapkan dataset ke dalam Notebook.
- Impor library SKLearn.
- Buat variabel untuk menampung data training dan data testing.
- Panggil fungsi train_test_split().
Pada Google Colab, import library yang dibutuhkan.
- import sklearn
Selanjutnya, Anda harus memiliki data yang akan dibagi. Data ini bisa berupa DataFrame atau array yang berisi fitur (X) dan label/target (y). Pada kasus ini, kita sudah memiliki sebuah dataset yang disimpan pada variabel df_lencoder sehingga Anda hanya perlu memisahkan antara atribut dan label pada dataset tersebut.
- # Memisahkan fitur (X) dan target (y)
- X = df_lencoder.drop(columns=['SalePrice'])
- y = df_lencoder['SalePrice']
Untuk membagi dataset menjadi train set dan test set, kita bisa menggunakan fungsi train_test_split. Fungsi ini memerlukan beberapa parameter utama:
- X: kumpulan atribut atau fitur dari dataset, yaitu semua kolom kecuali kolom target (pada kasus ini SalePrice).
- y: target atau label yang akan kita prediksi merupakan kolom yang ingin kita pisahkan (pada kasus ini SalePrice).
- test_size: persentase dari data yang akan digunakan sebagai test set. Misalnya, ketika Anda menentukan test_size=0.2, 20% dari data akan menjadi test set, dan 80% sisanya akan menjadi train set.
- random_state: parameter yang memastikan pemisahan data yang konsisten setiap kali fungsi tersebut dijalankan. Parameter ini mengontrol pengacakan saat membagi dataset sehingga dengan menetapkan random_state hasil pembagian data (train set dan test set) akan selalu sama. Hal ini penting untuk memastikan eksperimen yang dapat direproduksi dan evaluasi model yang konsisten. Namun, parameter ini juga dapat memiliki kekurangan yaitu model tidak akan menerima inputan baru yang mungkin akan lebih baik dari sebelumnya.
Ketika Anda menjalankan train_test_split, fungsi ini akan mengembalikan empat bagian data seperti berikut.
- X_train: fitur untuk train set.
- X_test: fitur untuk test set.
- y_train: target untuk train set.
- y_test: target untuk test set.
Ini berarti setelah pemanggilan fungsi, Anda memiliki dua bagian data: satu untuk melatih model (train set) dan satu lagi untuk menguji model (test set).
Bagaimana apakah Anda sudah memahami fondasi data splitting? Bagus, karena seperti biasa teori tanpa implementasi hanyalah sebuah angan-angan. Oleh karena itu, mari kita melangkah sekali lagi untuk melihat contoh kode dari penjelasan di atas.
- from sklearn.model_selection import train_test_split
- # membagi dataset menjadi training dan testing
- x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
Pro Tips
|
Sangat mudah ‘kan? Tentunya dengan menggunakan metode holdout ini akan mempermudah eksplorasi yang Anda lakukan. Setelah splitting, Anda dapat menggunakan x_train dan y_train untuk melatih model, serta x_test dan y_test untuk menguji kinerjanya.
- # menghitung panjang/jumlah data
- print("Jumlah data: ",len(X))
- # menghitung panjang/jumlah data pada x_train
- print("Jumlah data latih: ",len(x_train))
- # menghitung panjang/jumlah data pada x_test
- print("Jumlah data test: ",len(x_test))

Sampai di sini data yang Anda miliki sudah siap dilatih pada tahapan pembangunan model yang cukup penting. Oleh karena itu, pastikan Anda sudah melakukan tahapan cleaning sampai splitting dengan benar, ya. Sampai jumpa pada bagian paling seru!
Pembangunan Model (Modelling)
Setelah data telah di-split menjadi training set dan test set, langkah berikutnya dalam machine learning workflow adalah data modeling. Data modeling adalah proses ketika Anda memilih, melatih, dan mengevaluasi model machine learning untuk memprediksi atau mengklasifikasikan data berdasarkan fitur/variabel yang tersedia.
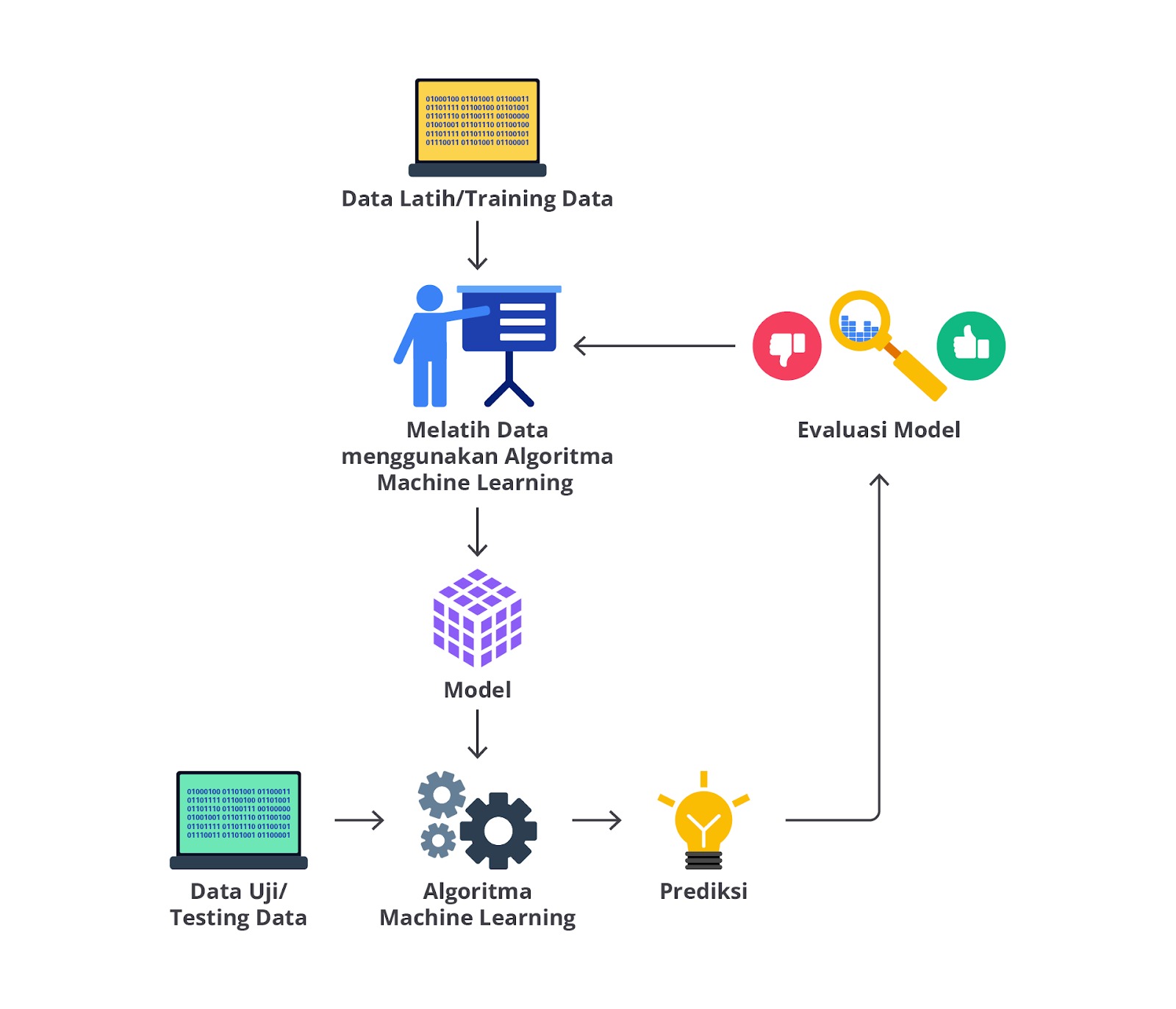
Pembangunan model ini memiliki beberapa tahapan mulai dari memilih model yang tepat, melatih model, evaluasi model, hyperparameter tuning, pengujian hingga interpretasi model. Namun, pada kelas pemula ini Anda akan mempelajari prosesnya hingga tahapan evaluasi model. Mengapa kita membatasi terlebih dahulu tahapannya? Karena sampai pada modul ini Anda diharapkan dapat mempertebal bekal awal hingga model dapat dibangun. Tahapan hyperparameter tuning, pengujian hingga interpretasi model akan Anda pelajari pada modul-modul berikutnya agar mendapatkan pengalaman belajar yang lebih maksimal.
Tanpa basa-basi lagi, mari kita bahas tahapan-tahapan di atas secara lebih dalam.
Memilih Model yang Tepat
Seperti yang sudah Anda pelajari pada materi submodul sebelumnya, memilih algoritma machine learning yang sesuai dengan masalah yang ingin diselesaikan sangatlah penting karena berhubungan dengan solusi yang ditawarkan.
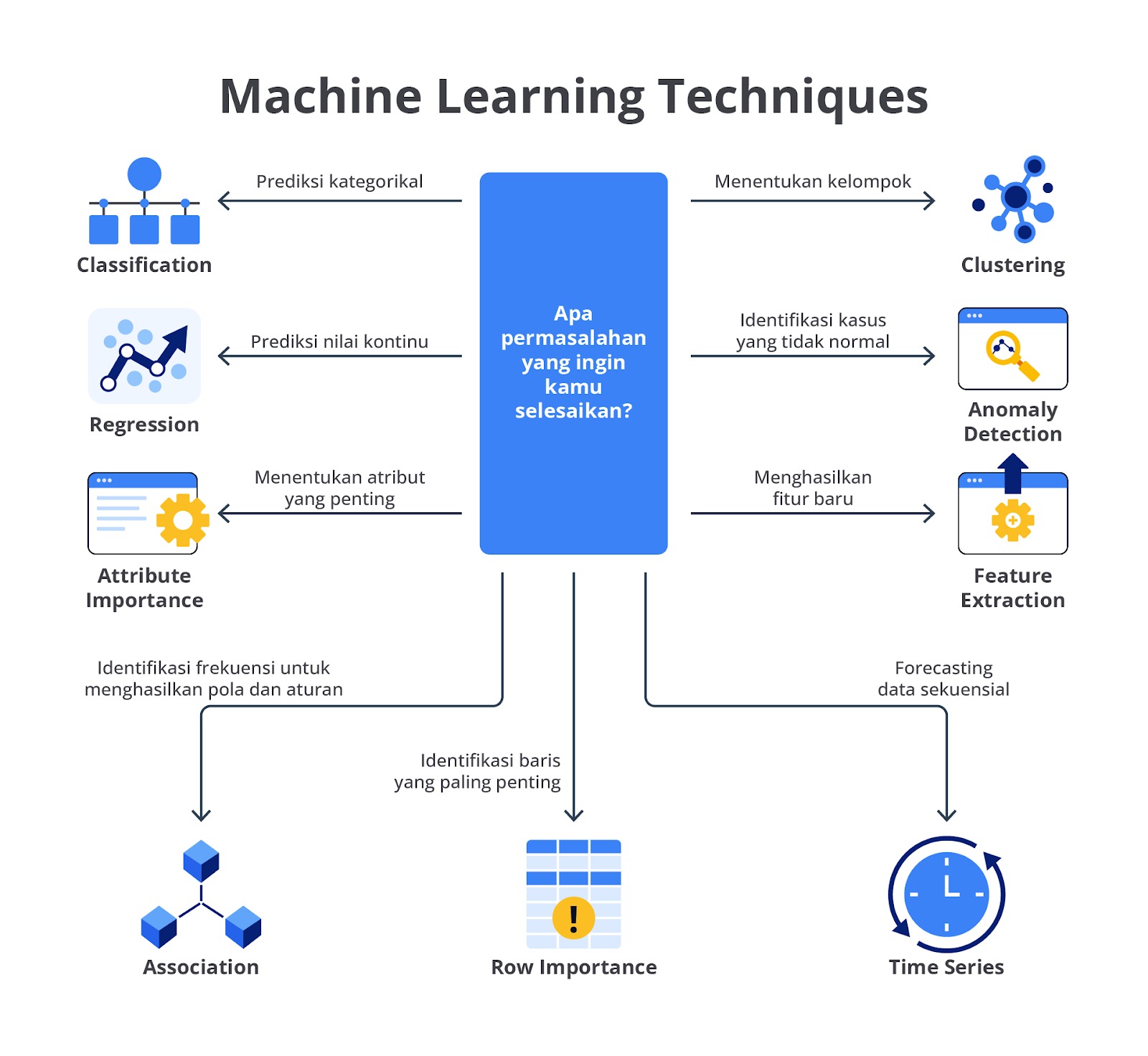
Anda perlu mengetahui secara garis besar masalah yang ingin diselesaikan beserta karakteristik data yang digunakan. Sedikit throwback ke materi sebelumnya, beberapa hal yang perlu Anda perhatikan seperti berikut.
- Regresi: jika target yang ingin diprediksi adalah data kontinu (misalnya, harga rumah), model regresi seperti Linear Regression, Ridge Regression, atau Random Forest Regressor dapat digunakan untuk menyelesaikan permasalahan tersebut.
- Klasifikasi: jika target adalah variabel kategori (misalnya, apakah email adalah spam atau bukan), model klasifikasi seperti Logistic Regression, Decision Trees, Random Forest, atau Support Vector Machines (SVM) mungkin lebih sesuai.
- Clustering: untuk mengelompokkan data ke dalam beberapa kategori atau cluster tanpa label yang jelas, Anda mungkin menggunakan model seperti K-Means atau DBSCAN.
Selain mempertimbangkan permasalahan yang sedang dihadapi, Anda juga dapat mempertimbangkan hal berikut untuk memilih algoritma lebih dalam.
- Jenis Data: apakah datanya numerik, kategorikal, atau campuran?
- Ukuran Dataset: apakah dataset kecil, sedang, atau besar? Model yang lebih kompleks mungkin memerlukan lebih banyak data.
- Linearitas: apakah hubungan antara fitur dan target bersifat linear atau non-linear?
Nah, karena pada contoh kasus yang sedang dihadapi memiliki data kontinu dengan tujuan memprediksi harga rumah maka kita akan menyelesaikan kasus regresi.
Melatih Model (Training)
Model akan "belajar" dari data training dengan menyesuaikan parameternya agar dapat memetakan input (fitur) ke output (target) dengan baik. Selama pelatihan, model akan menyesuaikan bobot atau koefisiennya untuk meminimalkan kesalahan antara prediksi dan nilai sebenarnya dalam training set.
Ada dua hal yang perlu Anda perhatikan pada tahapan ini, yaitu fitur dan target. Fitur adalah data input yang digunakan untuk melatih model, sedangkan target adalah data output yang menjadi referensi model untuk belajar.
Perlu Anda catat, pada latihan ini kita tidak akan melakukan hyperparameter tuning sehingga algoritma yang digunakan akan menghasilkan output berdasarkan konfigurasi dasarnya. Sebagai pemanasan, mari kita latih data yang sudah kita miliki dengan tiga algoritma yang berbeda.
- # Melatih model 1 dengan algoritma Least Angle Regression
- from sklearn import linear_model
- lars = linear_model.Lars(n_nonzero_coefs=1).fit(x_train, y_train)
- # Melatih model 2 dengan algoritma Linear Regression
- from sklearn.linear_model import LinearRegression
- LR = LinearRegression().fit(x_train, y_train)
- # Melatih model 3 dengan algoritma Gradient Boosting Regressor
- from sklearn.ensemble import GradientBoostingRegressor
- GBR = GradientBoostingRegressor(random_state=184)
- GBR.fit(x_train, y_train)
Evaluasi Model
Model yang telah dilatih perlu melalui tahapan evaluasi berdasarkan validation set untuk melihat seberapa baik ia mampu memprediksi output yang benar dari input yang belum pernah dilihat sebelumnya. Metrik umum untuk evaluasi adalah accuracy, precision, recall, F1-score (untuk klasifikasi), dan Mean Squared Error (MSE) atau R-squared (untuk regresi).
Karena contoh kasus yang sedang kita hadapi merupakan regresi, evaluasi yang akan akan kita gunakan adalah MAE, MSE, dan R2. Untuk melakukan evaluasi ini kita membutuhkan validation set (x_test). Validation test merupakan bagian dari data yang tidak digunakan untuk pelatihan tetapi digunakan untuk mengevaluasi model (unseen data). Mari kita lakukan evaluasi satu per satu.
- from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
- # Evaluasi pada model LARS
- pred_lars = lars.predict(x_test)
- mae_lars = mean_absolute_error(y_test, pred_lars)
- mse_lars = mean_squared_error(y_test, pred_lars)
- r2_lars = r2_score(y_test, pred_lars)
- # Membuat dictionary untuk menyimpan hasil evaluasi
- data = {
- 'MAE': [mae_lars],
- 'MSE': [mse_lars],
- 'R2': [r2_lars]
- }
- # Konversi dictionary menjadi DataFrame
- df_results = pd.DataFrame(data, index=['Lars'])
- df_results
- # Evaluasi pada model Linear Regression
- pred_LR = LR.predict(x_test)
- mae_LR = mean_absolute_error(y_test, pred_LR)
- mse_LR = mean_squared_error(y_test, pred_LR)
- r2_LR = r2_score(y_test, pred_LR)
- # Menambahkan hasil evaluasi LR ke DataFrame
- df_results.loc['Linear Regression'] = [mae_LR, mse_LR, r2_LR]
- df_results

- # Evaluasi pada model Gradient Boosting Regressor
- pred_GBR = GBR.predict(x_test)
- mae_GBR = mean_absolute_error(y_test, pred_GBR)
- mse_GBR = mean_squared_error(y_test, pred_GBR)
- r2_GBR = r2_score(y_test, pred_GBR)
- # Menambahkan hasil evaluasi GBR ke DataFrame
- df_results.loc['GradientBoostingRegressor'] = [mae_GBR, mse_GBR, r2_GBR]
- df_results
Sampai di sini, mudah ‘kan? Seperti yang dapat Anda lihat dari beberapa kode di atas memiliki struktur yang sama, yaitu .predict() dan beberapa metriks evaluasi seperti MAE, MSE, dan R2. Mari kita pelajari apa fungsi dari masing-masing function tersebut.
- .predict(): fungsi .predict() pada scikit-learn digunakan untuk membuat prediksi berdasarkan model yang telah dilatih. Setelah Anda melatih model dengan data pelatihan (menggunakan .fit() pada materi sebelumnya), Anda dapat menggunakan
.predict()untuk menghasilkan nilai prediksi pada data baru atau data testing. - mean_absolute_error: MAE mengukur rata-rata dari kesalahan absolut antara nilai prediksi dan nilai aktual. Ini adalah ukuran yang intuitif karena langsung menghitung seberapa jauh prediksi dari nilai sebenarnya tanpa memperhitungkan arah (positif atau negatif).
- mean_squared_error: MSE mengukur rata-rata dari kuadrat kesalahan antara nilai prediksi dan nilai aktual. Karena kesalahan dikuadratkan, MSE memberikan penalti (nilai error) yang lebih besar untuk kesalahan yang lebih besar, membuatnya lebih sensitif terhadap outlier.
- r2_score: R² adalah metrik statistik yang menunjukkan seberapa baik nilai prediksi mendekati nilai aktual. R² mengukur proporsi varians dari target yang dapat dijelaskan oleh fitur dalam model.
Nah, berdasarkan hasil evaluasi terhadap unseen data di atas, tentunya Anda sudah lebih yakin terhadap performa model yang telah dibangun. Lalu, manakah model yang Anda pilih berdasarkan latihan di atas? Jika memilih GradientBoostingRegressor berarti Anda sudah memahami arti dari masing-masing nilai evaluasi di atas. Selanjutnya mari kita selesaikan latihan machine learning workflow yang sangat panjang ini dengan menyimpan model agar dapat digunakan pada lingkungan produksi.
Menyimpan Model
Untuk menyimpan model GBR yang telah dilatih, Anda dapat menggunakan modul joblib atau pickle pada Python. Kedua modul ini memungkinkan Anda untuk menyimpan model ke dalam sebuah file sehingga bisa digunakan kembali di masa mendatang tanpa perlu melatih ulang model. Mari kita bahas kedua cara tersebut secara saksama.
- Joblib
Joblib adalah pilihan yang disarankan untuk menyimpan model scikit-learn karena lebih efisien dalam menyimpan objek model yang besar.- import joblib
- # Menyimpan model ke dalam file
- joblib.dump(GBR, 'gbr_model.joblib')
- Pickle
Pickle adalah modul standar Python yang dapat digunakan untuk menyimpan hampir semua objek Python termasuk model machine learning.- import pickle
- # Menyimpan model ke dalam file
- with open('gbr_model.pkl', 'wb') as file:
- pickle.dump(GBR, file)
Kapan menggunakan joblib vs pickle? joblib lebih efisien dan cepat ketika bekerja dengan objek besar seperti model machine learning, sedangkan pickle lebih umum dan dapat digunakan untuk menyimpan berbagai jenis objek Python, tetapi kurang efisien dibandingkan joblib untuk model besar.
Memilih antara joblib dan pickle tergantung pada preferensi Anda, tetapi untuk menyimpan model scikit-learn, joblib sering kali merupakan pilihan yang lebih baik.
Deployment dan Monitoring
Setelah model machine learning dilatih, diuji, dan dioptimalkan, langkah berikutnya adalah deployment (penerapan) dan monitoring (pemantauan) dari model tersebut. Hal ini menjadi penting dikarenakan tahapan ini satu-satunya cara agar model yang Anda bangun sebelumnya dapat dikonsumsi oleh masyarakat umum.
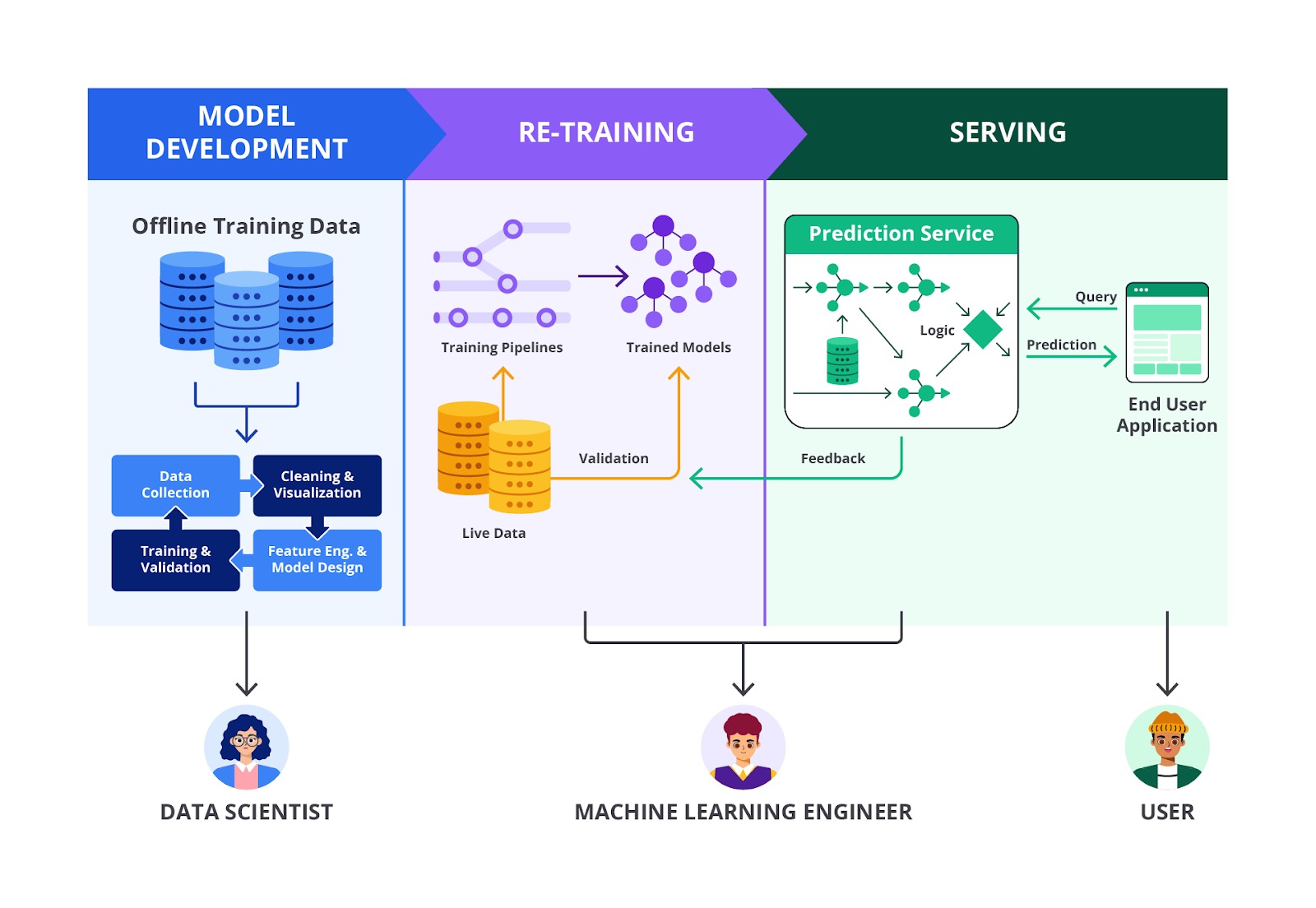
Deployment adalah proses pelatihan model dengan mengintegrasikannya ke dalam aplikasi atau sistem produksi, sehingga dapat digunakan oleh pengguna akhir (end user). Monitoring adalah proses untuk memastikan bahwa model bekerja dengan baik setelah deployment dan untuk mengidentifikasi jika ada degradasi kinerja atau masalah lain.
Pada latihan sebelumnya, kita memiliki sebuah model regresi yang disimpan menjadi dua ekstensi yang berbeda yaitu joblib dan pickle. Langkah pertama untuk melakukan deployment adalah memuat model yang sudah kita bangun.
- # Memuat model dari file joblib
- joblib_model = joblib.load('gbr_model.joblib')
- # Memuat model dari file pickle
- with open('gbr_model.pkl', 'rb') as file:
- pickle_model = pickle.load(file)
Setelah model dimuat, langkah berikutnya adalah mengintegrasikan model tersebut ke dalam aplikasi produksi. Ini bisa dilakukan dalam berbagai konteks, seperti web application, API, atau edge devices.
- Web Application: Anda dapat menggunakan framework seperti Flask atau Django untuk membuat API yang mengizinkan aplikasi web atau mobile untuk mengirim data ke model dan mendapatkan prediksi.
- Batch Processing: Model dapat digunakan untuk memproses data secara batch. Misalnya, dalam data pipeline yang berjalan secara terjadwal.
- Edge Deployment: Untuk model yang digunakan pada perangkat IoT atau perangkat edge lainnya, model bisa di-deploy langsung ke perangkat tersebut.
Pada contoh kasus modul ini, Anda akan berlatih untuk membuat sebuah API menggunakan Flask sehingga bisa digunakan oleh user melalui API.
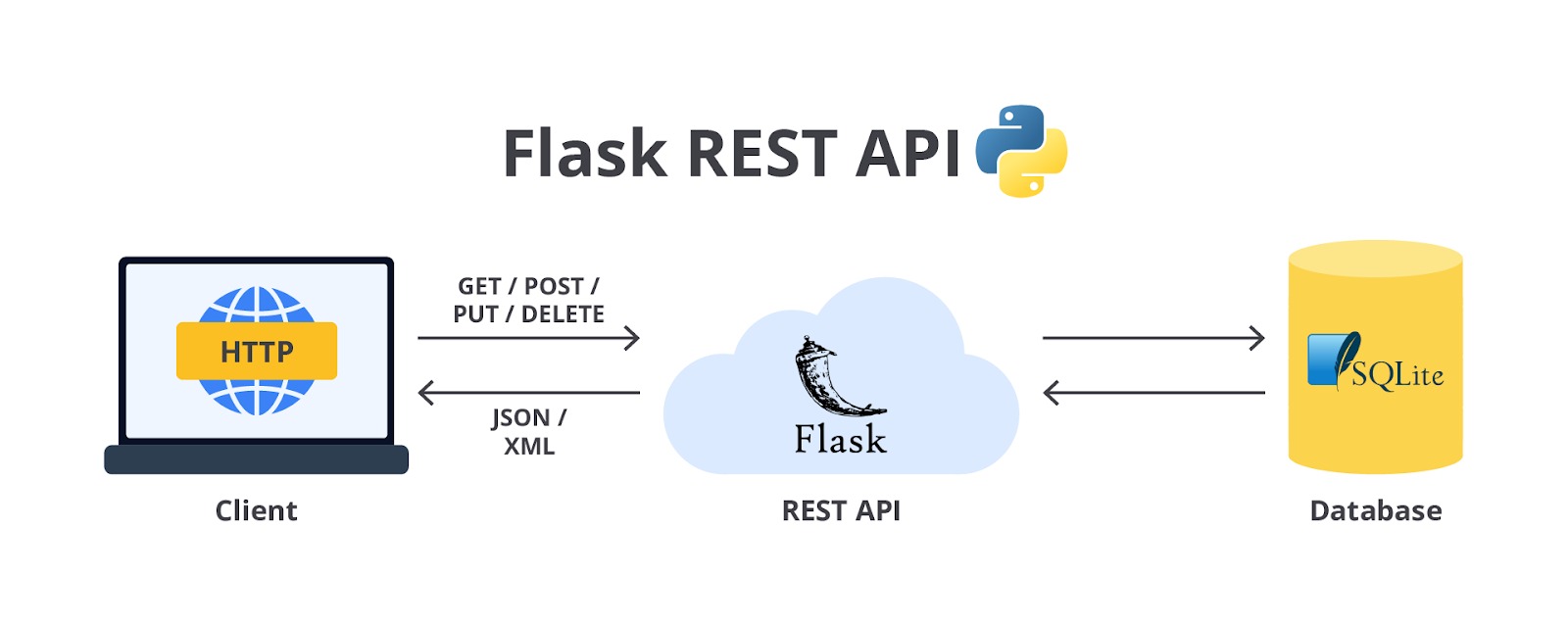
Hal pertama yang perlu Anda lakukan pada tahap ini adalah menginstal Flask dan Joblib. Sebagai catatan, pastikan Anda menggunakan versi Joblib dan Python yang sama ketika menyimpan model machine learning sebelumnya. Hal ini bertujuan untuk menghindari konflik dependencies yang sering terjadi pada Python.
Sebagai informasi, kami menggunakan scikit-learn versi 1.6.1 dan joblib versi 1.5.1. Disarankan untuk menggunakan versi yang sama untuk menghindari conflict/deprecated version.
Setelah semuanya sudah siap, sekarang Anda perlu membangun sebuah kode yang dapat menjadi jembatan antara model machine learning dan pengguna. Buatlah sebuah file Python dengan nama testing_deploy.py dan masukkan kode berikut.
- from flask import Flask, request, jsonify
- import joblib
- # Inisialisasi aplikasi Flask
- app = Flask(__name__)
- # Memuat model yang telah disimpan
- joblib_model = joblib.load('gbr_model.joblib') # Pastikan path file sesuai dengan penyimpanan Anda
- @app.route('/predict', methods=['POST'])
- def predict():
- data = request.json['data'] # Mengambil data dari request JSON
- prediction = joblib_model.predict(data) # Melakukan prediksi (harus dalam bentuk 2D array)
- return jsonify({'prediction': prediction.tolist()})
- if __name__ == '__main__':
- app.run(debug=True)
Dengan kode di atas, model Anda bisa digunakan untuk melayani permintaan prediksi melalui API HTTP POST. Seperti yang Anda ketahui, jumlah fitur/variabel pada model machine learning ini sangatlah banyak. Untuk mempermudah proses input data mari kita buat sebuah file json yang menampung seluruh variabel/fitur untuk memprediksi rumah dengan nama data.json.
- {
- "data": [[ 2.58814198e-02, -9.17637181e-01, 7.98581973e-01,
- 4.65818252e-03, -1.90862680e-01, -5.23676539e-01,
- 5.44502437e-01, 3.98055532e-01, -7.01765886e-01,
- 1.84842886e+00, 0.00000000e+00, -7.99528238e-01,
- 1.40061034e+00, 1.30453595e+00, -7.43485947e-01,
- 0.00000000e+00, 1.75076143e-01, 1.15778146e+00,
- 0.00000000e+00, 7.87362373e-01, -7.89877652e-01,
- 2.94736730e-01, 0.00000000e+00, -2.35844028e-01,
- -9.44263321e-01, 4.99353260e-01, 2.73711363e-01,
- 5.33168369e-01, 7.90365547e-01, -3.15583095e-01,
- 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
- 0.00000000e+00, 0.00000000e+00, 2.51894504e-01,
- -1.35256152e+00, 2.00000000e+00, 1.00000000e+00,
- 0.00000000e+00, 3.00000000e+00, 0.00000000e+00,
- 4.00000000e+00, 0.00000000e+00, 3.00000000e+00,
- 2.00000000e+00, 0.00000000e+00, 0.00000000e+00,
- 2.00000000e+00, 0.00000000e+00, 0.00000000e+00,
- 7.00000000e+00, 9.00000000e+00, 1.00000000e+00,
- 3.00000000e+00, 1.00000000e+00, 2.00000000e+00,
- 2.00000000e+00, 2.00000000e+00, 1.00000000e+00,
- 2.00000000e+00, 0.00000000e+00, 0.00000000e+00,
- 0.00000000e+00, 1.00000000e+00, 2.00000000e+00,
- 2.00000000e+00, 4.00000000e+00, 2.00000000e+00,
- 0.00000000e+00, 1.00000000e+00, 2.00000000e+00,
- 3.00000000e+00, 2.00000000e+00, 8.00000000e+00,
- 3.00000000e+00]]
- }
Tahapan terakhir untuk memastikan API Anda berjalan sedemikian rupa adalah melakukan pemeriksaan. Mari kita lakukan salah satu percobaan menggunakan curl tanpa menggunakan postman. Yang perlu Anda lakukan adalah membuka terminal dan memasukkan command berikut.
| curl -X POST http://127.0.0.1:5000/predict -H "Content-Type: application/json" -d @data.json |
Pastikan path atau direktori yang Anda buka pada terminal sudah sesuai dengan penyimpanan data.json, ya. Jika sudah output dari model machine learning tersebut kurang lebih akan seperti ini.

Setelah model di-deploy ke dalam produksi, monitoring menjadi sangat penting untuk memastikan bahwa model terus bekerja dengan baik dan tetap relevan seiring waktu. Walaupun pada tahapan ini kita masih melakukan deployment di local, materi tentang monitoring ini masih sangat relevan. Karena Anda akan mempelajari Machine Learning Operations di kelas-kelas berikutnya. Sampai pada kelas tersebut, silakan reviu kembali kelas ini sebagai bekal utama, ya.
Mungkin muncul sebuah pertanyaan, “Mengapa monitoring penting?” Model machine learning dapat mengalami penurunan kinerja dari waktu ke waktu karena perubahan dalam data yang masuk (concept drift) atau perubahan dalam distribusi data (data drift). Selain itu, monitoring membantu mendeteksi anomali atau bug yang mungkin muncul saat model digunakan di dunia nyata. Dan yang paling penting monitoring juga berperan untuk memastikan bahwa model mematuhi regulasi atau kebijakan internal terkait privasi, keamanan, atau fairness.
Biasanya model machine learning memiliki metrik dan alat untuk membantu monitoring. Berikut adalah metrik dan alat yang bisa digunakan ketika Anda memonitoring model machine learning di lingkungan produksi.
Metrik yang Dimonitor:
- Accuracy, Precision, Recall, F1-Score: digunakan untuk memantau kinerja model klasifikasi.
- Mean Squared Error (MSE), R-squared: digunakan untuk model regresi.
- Data Drift Metrics: memantau perubahan distribusi data input dibandingkan dengan data yang digunakan saat pelatihan.
- Model Latency: mengukur waktu yang diperlukan model untuk memberikan prediksi. Hal ini penting untuk aplikasi real-time.
Alat Monitoring:
- Prometheus/Grafana: digunakan untuk memantau metrik dan membuat dashboard custom.
- ELK Stack (Elasticsearch, Logstash, Kibana): digunakan untuk monitoring log dan menganalisis anomali.
- Sentry: digunakan untuk mendeteksi dan melaporkan error di aplikasi yang mengintegrasikan model.
- MLflow: alat khusus untuk tracking eksperimen dan monitoring model machine learning.
Sampai di sini Anda dapat memastikan bahwa model machine learning yang dibuat tidak hanya berguna pada saat dilatih, tetapi juga terus memberikan nilai saat digunakan di dunia nyata.
Sebagai penutup, Anda telah mencapai akhir babak dari materi ini yaitu Deployment dan Monitoring. Dengan pemahaman ini, Anda mampu memastikan model yang dibangun tidak hanya bekerja di lingkungan pengembangan, tetapi juga mampu bertahan dan beradaptasi dalam skenario dunia nyata.
Namun, perjalanan Anda belum selesai di sini. Di modul berikutnya, kita akan membahas lebih dalam tentang berbagai macam machine learning yang ada. Mulai dari supervised learning, unsupervised learning, hingga optimasi machine learning yang memiliki keunikan dan objektif masing-masing. Penasaran bagaimana algoritma-algoritma ini bekerja dan kapan waktu terbaik untuk menggunakannya? Jangan lewatkan pembahasan berikutnya yang akan membuka lebih banyak wawasan dan kemungkinan di dunia machine learning. Sampai jumpa!
[Story] Dimulai dari Nol ya, Dek.
Semua berawal dari ketidaktahuan Diana dan Bilqis dalam membangun project machine learning. Mereka hanya mengetahui setiap permasalahan pasti memiliki langkah-langkah yang harus diikuti. Di lain sisi, mereka juga hanya mengetahui bahasa pemrograman Python sebagai bekal utamanya. Dengan kata lain, mereka harus memulai pembelajarannya dari nol. Hal itu membuat mereka kebingungan harus mulai dari mana langkah yang tepat untuk mempelajari machine learning, ilmu yang sedang hype beberapa tahun belakangan ini hingga sekarang.

Setiap orang pasti perlu melangkah untuk mengawali masa depan yang lebih cerah. Jika Diana dan Bilqis hanya berdiam diri ketika kebingungan tentunya tidak akan menghasilkan apa-apa ‘kan? Namun, layaknya generasi Z pada umumnya, Diana dan Bilqis memiliki kecemasan yang cukup besar. Hal ini membuat mereka terkadang overthinking akan ketakutan di masa depan karena kebingungannya harus memulai dari mana untuk menggapai cita-citanya.

Setelah mereka stuck dan overthinking selama beberapa hari tanpa melakukan apa pun, akhirnya Diana menceritakan apa yang dialaminya kepada dosen favoritnya. Karena dosen ini memiliki pengalaman hidup yang lebih banyak, beliau menyarankan beberapa hal kepada Diana, salah satunya adalah berani untuk melangkah.

Tak perlu waktu lama setelah melakukan konsultasi dengan dosennya, akhirnya Diana pun tersadar bahwa ketakutan dan overthinking yang ia alami berasal dari pikirannya sendiri yang sering melihat konten TikTok tentang kesuksesan orang lain yang terlihat instan dan tanpa sadar menjadikan dirinya memiliki standar TikTok.
Setelah semua yang berlalu, akhirnya Diana kembali ke tujuan awalnya yaitu ingin menjadi seorang machine learning engineer atau data scientist di masa depan. Semangat Diana perlahan mulai menyala lagi. Bersamaan dengan itu, ternyata Bilqis sudah memulai lebih dahulu untuk mempelajari machine learning lebih dalam. Hingga suatu saat ketika mereka sedang belajar bersama Diana menemukan sebuah petikan yang sangat menempel di benaknya.
“Sukses tidak terwujud hanya karena sebuah langkah besar. Melainkan sekumpulan langkah kecil yang dilakukan secara konsisten.” — Dato DR. Andrew Ho, Founder Young Entrepreneurs Squad.
Diana sadar bahwa untuk mempelajari suatu hal, ia perlu tekun dan konsisten tanpa harus membuang-buang waktu dengan hal yang tidak berguna. Dari situ, Diana memiliki sebuah ide agar pembelajarannya menjadi lebih efisien dan terarah.

Hingga pada suatu hari Bilqis menemukan sebuah jurnal yang memberikan informasi dasar mengenai machine learning workflow mulai dari dasar hingga dapat digunakan oleh masyarakat umum. Bilqis sangat girang dan bahagia karena perjalanannya akhirnya menemukan sebuah “peta” yang memiliki ujung. Tanpa berlama-lama, ia memberi tahu Diana bahwa mereka dapat memulai pembelajarannya berdasarkan alur yang ada.
Diana yang mendengar informasi dari Bilqis masih roaming dan belum memahami sepenuhnya, ia merasa workflow tersebut sangat sederhana karena hanya memiliki tujuh buah tahapan. Setelah dijelaskan lebih detail oleh Bilqis, akhirnya mereka sepakat untuk memulai pembelajarannya berdasarkan workflow yang Bilqis temukan.
Hari demi hari mereka lalui bersama dengan penuh semangat, Diana dan Bilqis memulai pembelajaran dari nol, yaitu melakukan data collecting atau pengumpulan data. Untuk memulai tahapan tersebut, mereka perlu memikirkan sebuah rumusan masalah agar data yang dikumpulkan lebih terarah. Di tengah keheningan, mereka mengingat suatu permasalahan yang sedang dialami oleh orang tua Diana. Orang tua Diana ingin menjual sebuah rumah yang letaknya berada di tengah kota.
Diana ingin membantu orang tuanya, tetapi ia tidak memiliki pengetahuan terkait jual beli rumah. Berbekal dari pengetahuan dasar analisis data serta bantuan dari Bilqis, akhirnya mereka memutuskan untuk mencari tahu terlebih dahulu hal-hal yang memengaruhi harga jual sebuah rumah. Tak perlu waktu lama, akhirnya mereka menemukan beberapa komponen utama yang memengaruhi harga rumah, yaitu ukuran, jumlah kamar, lokasi, dan kondisi rumah.
Setelah mengetahui komponen utama penjualan rumah, akhirnya mereka berencana untuk mengumpulkan informasi tersebut melalui sebuah survei yang dibagikan secara online pada salah satu grup jual beli rumah di platform Facebook. Harapannya mereka dapat mengetahui harga rumah yang sudah terjual berdasarkan spesifikasi yang ada.
Tiga hari berselang setelah survei dilakukan, akhirnya mereka berhasil mengumpulkan 200 data penjualan rumah selama beberapa bulan terakhir. Rasa senang yang tak bisa tergambarkan muncul pada raut wajah mereka berdua karena dengan ini mereka bisa melanjutkan pembelajarannya ke tahap berikutnya.

Tahap kedua pada workflow yang mereka pelajari adalah data loading, mereka hanya perlu melakukan konversi dari data yang terkumpul agar dapat dibaca oleh bahasa pemrograman favoritnya yaitu Python. Pada tahap ini, mereka sama sekali tidak merasakan kesulitan karena semuanya dapat terselesaikan hanya dengan satu baris kode yang telah dipelajari pada materi analisis data ketika kuliah.
Permasalahan justru muncul pada tahapan ketiga dan keempat yaitu mereka harus memutar otak karena pada tahap pembersihan dan eksplorasi data, mereka dipaksa untuk menunjukkan kemampuan analisis dan pemecahan masalah. Diana yang memiliki kemampuan problem solving di atas rata-rata merasa tertantang dan menikmati detik demi detik di tahapan ini. Seperti mahasiswa pada umumnya, tak jarang beberapa kali Diana harus bergadang karena masih penasaran dengan permasalahan teknis yang sedang mereka hadapi.

Akhirnya mereka mencapai tiga tahapan akhir pada machine learning workflow, yaitu data splitting, modelling dan deployment. Tahapan ini memaksa mereka untuk membagi tugas, Diana bertugas mempelajari berbagai macam algoritma, sedangkan Bilqis bertugas melakukan eksplorasi terkait deployment dan monitoring.
Dengan skema belajar yang baru, mereka akhirnya bisa menyelesaikan permasalahan machine learning untuk memprediksi harga rumah dengan lebih cepat. Dengan pencapaiannya ini, mereka tidak sabar untuk melakukan uji coba kepada orang tua Diana.
Karena model machine learning ini sudah di-deploy oleh Bilqis, orang tua Diana tidak memerlukan usaha yang keras untuk menggunakannya. Orang tua Diana hanya perlu memasukkan spesifikasi rumah yang mereka miliki dan boom prediksi harga rumah muncul seketika!
Hufftt, perjalanan yang cukup panjang, ya? Hingga tahap ini, akhirnya Diana dan Bilqis sudah mengetahui alur pengembangan machine learning dan mengaplikasikannya pada salah satu keresahan Diana di kehidupan sehari-hari. Lalu, bagaimana dengan Anda? Apakah Anda juga sudah mulai tercerahkan dan ingin mulai mengimplementasikan hal tersebut? Kami tunggu jawabannya pada submission akhir, ya!
Berdasarkan perjalanan yang Diana dan Bilqis lalui di atas, kita mendapatkan sebuah insight yang cukup menarik yaitu mulailah hal yang ingin Anda capai karena dengan memulai, Anda baru bisa mengakhiri sesuatu.
Perjalanan Anda dalam memahami machine learning workflow baru saja dimulai. Dunia machine learning adalah lautan yang luas, penuh dengan keajaiban yang menunggu untuk ditemukan. Setiap tantangan yang Anda hadapi adalah kesempatan untuk tumbuh dan berkembang. Jangan takut untuk mencoba hal-hal baru dan keluar dari zona nyaman kalian. Sampai bertemu di modul berikutnya, di mana kita akan menyelami lebih dalam lagi ke dunia machine learning!
Rangkuman Machine Learning Workflow
Sebelum Anda melangkah, mari kita refresh seluruh materi yang ada pada modul ini sebagai bekal sebelum masuk ke modul berikutnya.
Pendahuluan Machine Learning Workflow
Alur kerja machine learning menurut buku tersebut melibatkan serangkaian langkah yang sistematis dan iteratif. Setiap langkah membutuhkan evaluasi dan penyesuaian untuk memastikan model yang dihasilkan dapat memberikan hasil yang akurat dan andal dalam lingkungan produksi. Buku ini juga menekankan pentingnya pemahaman mendalam terhadap data dan masalah yang dihadapi serta penggunaan alat dan teknik yang tepat untuk mencapai tujuan machine learning.
Proses Pengumpulan Data
Langkah pertama dalam alur kerja machine learning adalah memahami masalah yang ingin diselesaikan dan tujuan bisnis yang ingin dicapai. Setelah masalah dipahami, langkah berikutnya adalah mengumpulkan data yang relevan dari berbagai sumber, seperti basis data, API, atau data publik
Exploratory Data Analysis
Setelah data terkumpul, kita perlu memahami struktur dan karakteristik data. Ini termasuk melakukan analisis deskriptif dan visualisasi data untuk menemukan pola atau anomali tertentu.
Tahapan tersebut disebut exploratory data analysis atau EDA yang bertujuan sebagai analisis awal terhadap data dan melihat bagaimana kualitas data untuk meminimalkan potensi kesalahan di kemudian hari. Pada proses ini dilakukan investigasi awal pada data untuk memahami data, menemukan pola, anomali, menguji hipotesis, memahami distribusi, frekuensi, hubungan antara variabel, dan memeriksa asumsi dengan teknik statistik dan representasi grafik.
Pada umumnya, EDA dilakukan dengan dua cara, yaitu univariate analysis, dan multivariate analysis. Univariate analysis adalah analisis deskriptif yang memeriksa pola dengan satu variabel pada modelnya. Multivariate analysis merupakan analisis deskriptif yang memeriksa pola dalam data multidimensi dengan membertimbangkan dua atau lebih variabel. Jika terdapat dua variabel yang akan dianalisis, ia disebut bivariate analysis.
Data Preprocessing
Data preprocessing adalah langkah penting dalam alur kerja machine learning yang bertujuan untuk mempersiapkan data mentah agar dapat digunakan secara efektif oleh model machine learning.
Proses ini mencakup serangkaian teknik dan transformasi untuk memastikan data yang digunakan berkualitas tinggi, konsisten, dan relevan dengan tujuan analisis atau pemodelan. Dengan kata lain, proses ini mengubah dan mentransformasi fitur-fitur data ke dalam bentuk yang mudah diinterpretasikan dan diproses oleh algoritma machine learning.
Model Selection
Model selection adalah langkah penting dalam alur kerja machine learning yang melibatkan pemilihan algoritma terbaik untuk memecahkan masalah spesifik berdasarkan data yang tersedia. Pemilihan model yang tepat dapat secara signifikan memengaruhi kinerja akhir dari solusi machine learning.
Setelah menentukan kategori utama yang cocok untuk permasalahan yang ingin diselesaikan, Anda perlu melakukan eksplorasi algoritma untuk kategori yang sudah ditentukan.
Pada tahap ini, Anda perlu melakukan pengujian awal atau baseline model dengan tujuan untuk menguji beberapa algoritma secara cepat sehingga mendapatkan gambaran awal tentang kinerja mereka pada dataset. Hal ini bisa dilakukan dengan menggunakan default hyperparameters tanpa penyesuaian khusus. Hasil baseline ini membantu dalam mengevaluasi seberapa kompleks atau sederhana model yang diperlukan.
- Model Evaluation
Setelah mengotak-atik model Anda dengan hyperparameter yang berbeda, akhirnya Anda mendapatkan model yang kinerjanya cukup baik. Langkah selanjutnya adalah mengevaluasi model akhir pada data uji. - Deployment
Model deployment adalah salah satu langkah terpenting dalam alur kerja machine learning. Model yang telah dilatih dan diuji diterapkan ke dalam lingkungan produksi sehingga dapat digunakan oleh pengguna akhir atau sistem untuk membuat prediksi pada data baru.
Proses ini tidak hanya mencakup memindahkan model dari fase pengembangan ke fase produksi, tetapi juga memastikan bahwa model berjalan dengan andal, cepat, dan aman dalam skala besar. - Monitoring
Ketika sebuah model machine learning sudah diterapkan dalam produksi dan digunakan oleh pengguna, pekerjaan belum selesai. Model ini masih perlu terus dipantau untuk memastikan bahwa ia tetap berfungsi dengan baik dan memberikan hasil yang akurat.
Hal ini sangat penting karena data yang dihadapi oleh model dalam tahap produksi bisa berbeda dari data yang digunakan saat model dilatih. Jika model bertemu dengan data yang tidak dikenali atau berbeda dari pola yang telah dipelajari, performanya bisa menurun seiring berjalannya waktu.
Pengenalan Tools dan Library Populer pada Python untuk Machine Learning dan Data Science
Library pada Python adalah kumpulan modul yang berisi kode-kode fungsional yang telah ditulis sebelumnya dan dapat digunakan kembali untuk menyelesaikan berbagai tugas. Modul ini bisa mencakup fungsi, kelas, dan variabel yang dapat diimpor ke dalam program Python Anda untuk mempermudah pengembangan perangkat lunak.
Library akan sangat membantu Anda untuk menyelesaikan tugas-tugas dengan lebih efisien dan efektif dengan menyediakan fungsi-fungsi siap pakai yang bisa langsung digunakan tanpa perlu menulis ulang kode dari awal.
Tools untuk Pemrograman Python
Tools ini tidak hanya memudahkan Anda menulis dan menjalankan kode, tetapi juga memberi Anda kekuatan untuk mengatur alur kerja dengan cara yang efisien dan menyenangkan.
Ketiga tools ini adalah web-based interactive development environments yang lebih dikenal dengan sebutan Notebook. Notebook menawarkan antarmuka yang fleksibel dan user-friendly, memungkinkan Anda untuk langsung menulis kode, mengeksekusinya, dan melihat hasilnya dalam satu platform yang terpadu. Anda juga bisa membuat konfigurasi, mengatur workflow, dan mengelola proyek data science Anda dengan cara yang lebih intuitif.
- Jupyter Notebook
Jupyter Notebook adalah perangkat lunak gratis, open-source, dan layanan web yang mendukung berbagai bahasa pemrograman, termasuk Python. - Google Colaboratory
Selanjutnya, mari kita kenalan dengan Google Colaboratory, atau yang sering disebut Colab—alat revolusioner yang memungkinkan Anda menulis dan menjalankan kode Python langsung melalui browser. - IBM Watson Studio
IBM Watson Studio merupakan salah satu layanan dari IBM yang banyak digunakan oleh analis dan ilmuwan data. Anda juga dapat menjalankan kode secara online pada layanan seperti IBM Watson Studio tanpa perlu menginstal perangkat lunak apa pun pada komputer. Sebelum menggunakan IBM Watson Studio, buatlah akun IBM Cloud terlebih dahulu. Akun IBM Cloud dapat dipakai untuk mengakses IBM Watson Studio, IBM Watson Machine Learning, dan IBM Cloud.
Library Populer untuk Machine Learning dan Data Science
Python telah menjadi bahasa pilihan bagi banyak data scientist dan engineer karena kekayaan ekosistem library yang dimilikinya. Library ini mempermudah berbagai aspek dalam data science dan machine learning, mulai dari manipulasi data, visualisasi, hingga pengembangan model machine learning. Dalam materi ini, kita akan membahas beberapa library Python yang paling populer dan sering digunakan dalam bidang ini.
- NumPy
NumPy adalah library dasar untuk komputasi numerik di Python. Library ini menyediakan dukungan untuk array multidimensi dan berbagai fungsi matematika yang cepat dan efisien. - Pandas
Pandas adalah library yang digunakan untuk manipulasi dan analisis data, terutama data yang terstruktur dalam bentuk tabel. Dengan Pandas, Anda dapat dengan mudah melakukan operasi filtering, agregasi, dan manipulasi data lainnya. - Matplotlib
Matplotlib adalah sebuah library untuk membuat plot atau visualisasi data dalam 2 dimensi. Matplotlib mampu menghasilkan grafik dengan kualitas tinggi. Matplotlib dapat dipakai untuk membuat plot seperti histogram, scatter plot, grafik batang, pie chart, hanya dengan beberapa baris kode. Library ini sangat ramah pengguna. - Scikit Learn
Scikit-Learn adalah library machine learning yang menyediakan berbagai algoritma pembelajaran mesin serta alat untuk preprocessing data, evaluasi model, dan tuning hyperparameter. - TensorFlow
TensorFlow adalah framework open source untuk machine learning yang dikembangkan dan digunakan oleh Google. TensorFlow memudahkan pembuatan model ML bagi pemula maupun ahli. Ia dapat dipakai untuk deep learning, computer vision, pemrosesan bahasa alami (Natural Language Processing), serta reinforcement learning. - PyTorch
Dikembangkan oleh Facebook, PyTorch adalah library yang dapat dipakai untuk masalah ML, computer vision, hingga pemrosesan bahasa alami. Bersaing dengan TensorFlow khususnya sebagai framework machine learning, PyTorch lebih populer di kalangan akademisi dibanding TensorFlow. Namun, dalam industri, TensorFlow lebih populer karena skalabilitasnya lebih baik dibanding PyTorch. - Keras
Keras adalah library deep learning yang luar biasa. Salah satu faktor yang membuat Keras sangat populer adalah penggunaannya yang minimalis dan simpel dalam mengembangkan deep learning. Keras dibangun di atas TensorFlow yang menjadikan Keras sebagai API dengan level lebih tinggi (Higher level API) dari TensorFlow sehingga antarmukanya lebih mudah dari TensorFlow. Keras sangat cocok untuk mengembangkan model deep learning dengan waktu yang lebih singkat atau untuk pembuatan prototipe. - NLTK dan SpaCy
NLTK (Natural Language Toolkit) dan SpaCy adalah library untuk Natural Language Processing (NLP). NLTK lebih banyak digunakan dalam riset dan pendidikan, sedangkan SpaCy lebih fokus pada kecepatan dan produksi. - SciPy
SciPy adalah library yang menyediakan berbagai algoritma dan fungsi untuk komputasi ilmiah dan teknik. SciPy sering digunakan bersama NumPy untuk operasi yang lebih kompleks. Fungsi utama dari library ini untuk melakukan i optimisasi, integrasi, dan pemecahan persamaan diferensial serta pengolahan sinyal dan gambar, serta analisis statistik. Berikut adalah contoh penggunaan library SciPy.
Data Collecting
Dalam machine learning, data collecting adalah fondasi tersebut. Tanpa data yang tepat dan berkualitas, model machine learning Anda tidak akan mampu berdiri kokoh, apalagi memberikan hasil yang andal.
Data collecting adalah langkah pertama dalam alur kerja machine learning di mana Anda mengumpulkan semua informasi yang dibutuhkan untuk melatih model. Data ini bisa datang dari berbagai sumber dan dalam berbagai bentuk—mulai dari data numerik, teks, gambar, hingga data kategori. Kualitas dan kuantitas data yang Anda kumpulkan akan sangat menentukan performa model machine learning yang Anda bangun.
Data Loading
Loading dataset dalam konteks machine learning adalah proses mengimpor atau memasukkan data ke dalam lingkungan pemrograman atau sistem yang digunakan untuk pengembangan model machine learning. Dataset ini berfungsi sebagai input yang akan digunakan oleh model untuk belajar dan membuat prediksi.
Proses loading dataset biasanya mencakup pengambilan data dari sumber eksternal (seperti file CSV, database, API, atau sumber lain) lalu memuatnya ke dalam struktur data yang sesuai di dalam bahasa pemrograman atau framework yang digunakan. Dalam banyak kasus, bahasa pemrograman seperti Python menggunakan library Pandas untuk memuat dataset ke dalam format yang mudah disesuaikan, seperti DataFrame.
Data Cleaning dan Transformation
Data Cleaning atau pembersihan data adalah proses penting dalam alur kerja machine learning yang bertujuan untuk meningkatkan kualitas dataset sebelum digunakan untuk pelatihan model. Dalam konteks machine learning, data cleaning mencakup serangkaian langkah yang dirancang untuk mendeteksi, memperbaiki, atau menghapus data yang tidak valid, tidak lengkap, tidak akurat, atau tidak relevan. Silakan simak gambar berikut dan perhatikan secara saksama.
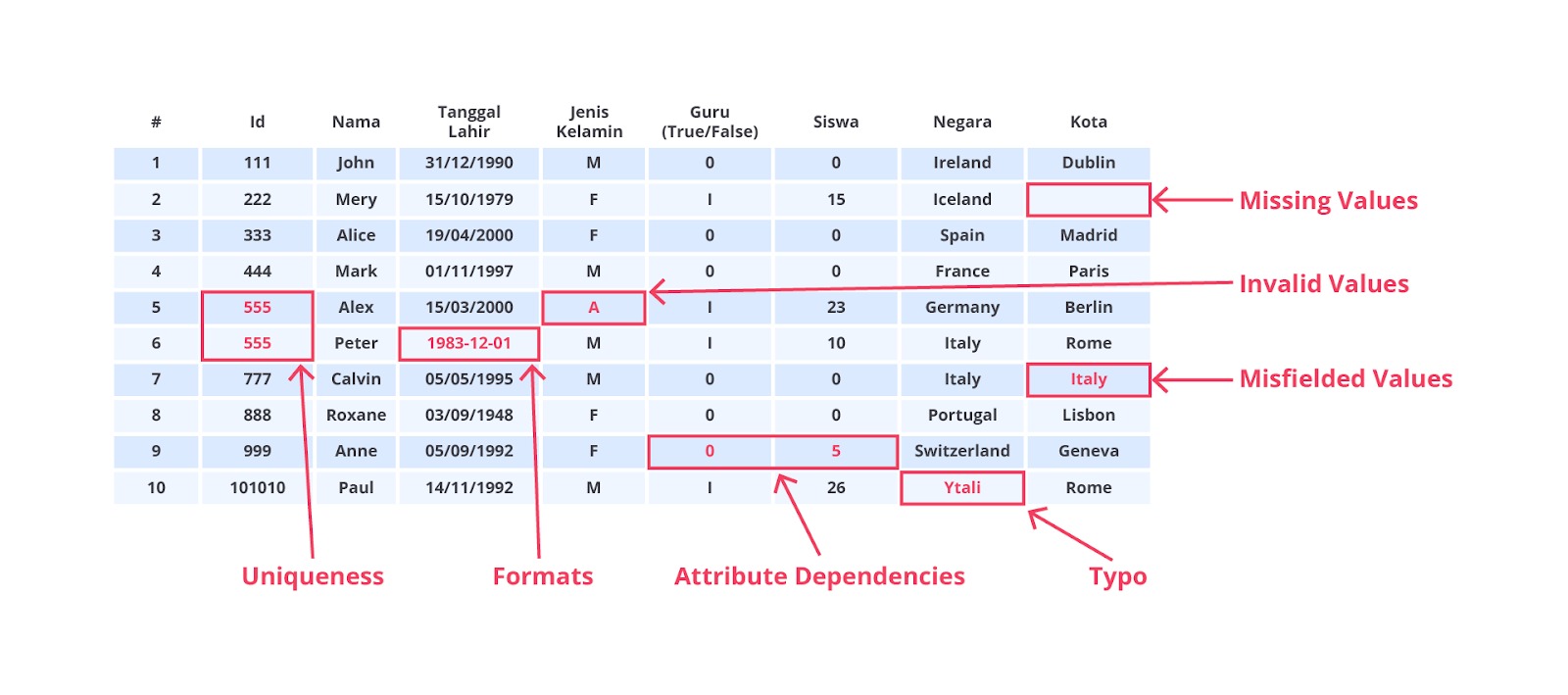
Exploratory dan Explanatory Data Analysis
EDA merupakan tahap eksplorasi data yang telah dibersihkan guna memperoleh insight dan menjawab pertanyaan analisis. Pada prosesnya, kita akan sering menggunakan berbagai teknik dan parameter dalam descriptive statistics yang bertujuan untuk menemukan pola, hubungan, serta membangun intuisi terkait data yang diolah. Selain itu, tidak jarang kita juga menggunakan visualisasi data untuk menemukan pola dan memvalidasi parameter descriptive statistics yang diperoleh.
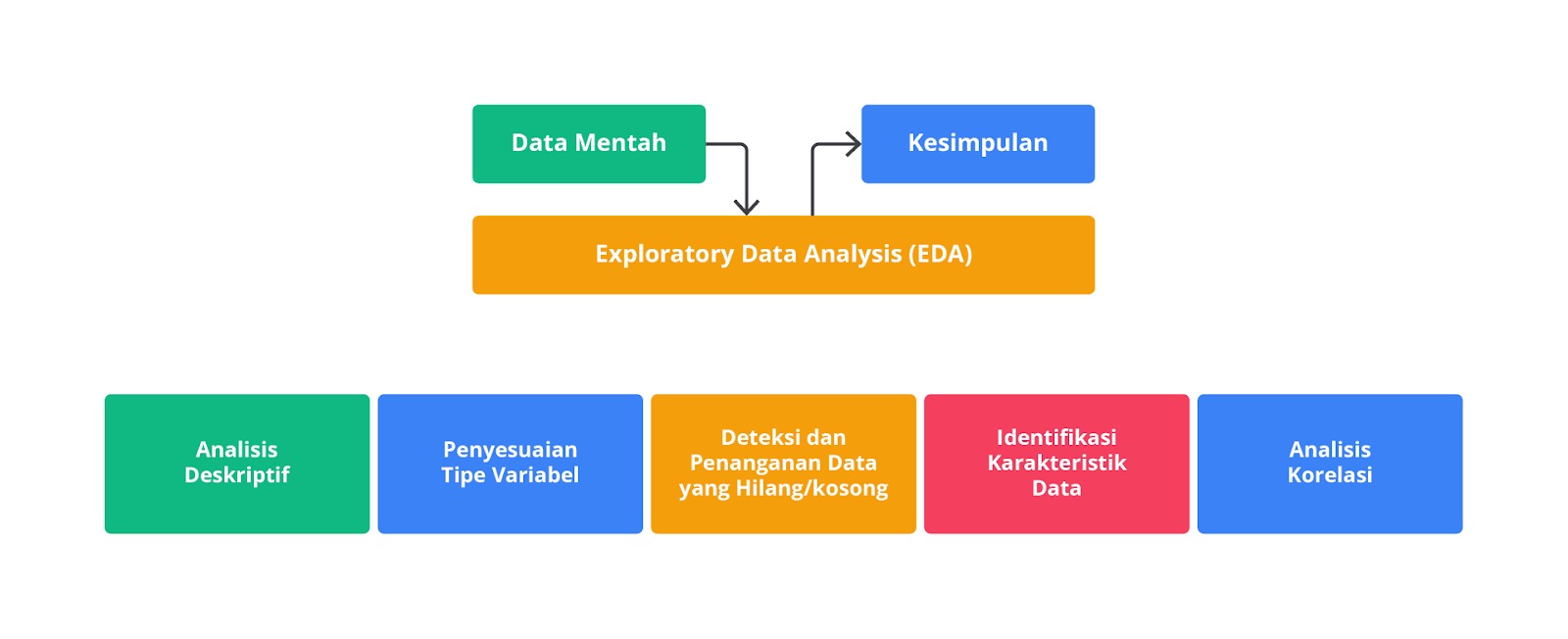
Menurut pandangan para praktisi data, EDA (Exploratory Data Analysis) adalah salah satu tahap yang paling sexy dalam proyek analisis data. Tahap ini memungkinkan para praktisi untuk mengeksplorasi dan bereksperimen dengan data guna menemukan pola, mendapatkan wawasan, menjawab berbagai tantangan bisnis serta menyusun kesimpulan berdasarkan hasil analisis yang diperoleh.
Exploratory Data Analysis (EDA) dan Explanatory Data Analysis (ExDA) adalah dua tahap yang penting dalam proses analisis data, namun memiliki tujuan dan pendekatan yang berbeda. Mari kita breakdown kedua tahap tersebut secara komprehensif mulai dari tujuan, metodologi, visualisasi data, audiens, contoh kasus hingga outputnya.
Exploratory Data Analysis (EDA):
- Tujuan utama dari EDA adalah untuk memahami struktur, karakteristik, dan pola dalam data. Pada tahap ini, Anda memiliki misi untuk menemukan insight atau informasi yang tersembunyi dalam data, mengidentifikasi anomali, serta memahami hubungan antar variabel.
- EDA bersifat eksploratif dan terbuka sehingga Anda tidak memiliki hipotesis yang pasti di awal prosesnya. Sebaliknya, Anda dapat menggunakan EDA untuk membangun hipotesis atau memahami lebih dalam data yang mereka miliki.
Explanatory Data Analysis (ExDA):
- ExDA di sisi lain memiliki tujuan utama untuk mengomunikasikan temuan atau insight yang sudah didapatkan kepada audiens yang lebih luas, seperti stakeholder, tim eksekutif, atau klien.
- Pada tahap ini, analisis data berfokus pada penyampaian informasi yang jelas, ringkas, dan meyakinkan, dengan dukungan visualisasi yang efektif dan narasi yang kuat.
Jika disimpulkan, explanatory analysis merupakan proses penyampaian temuan menarik dari proses exploratory analysis. Proses penyampaian ini tentunya harus diikuti dengan visualisasi data yang baik dan efektif.
Data Splitting
Data Splitting adalah proses membagi dataset menjadi beberapa subset yang terpisah untuk tujuan pelatihan, validasi, dan pengujian model machine learning. Proses ini merupakan langkah penting dalam pipeline machine learning karena membantu memastikan model yang dikembangkan mampu membuat prediksi yang baik tidak hanya pada data pelatihan, tetapi juga pada data baru yang belum pernah dilihat sebelumnya.
Deployment dan Monitoring
Setelah model machine learning dilatih, diuji, dan dioptimalkan, langkah berikutnya adalah deployment (penerapan) dan monitoring (pemantauan) dari model tersebut. Hal ini menjadi penting dikarenakan tahapan ini satu-satunya cara agar model yang Anda bangun sebelumnya dapat dikonsumsi oleh masyarakat umum.
Deployment adalah proses pelatihan model dengan mengintegrasikannya ke dalam aplikasi atau sistem produksi, sehingga dapat digunakan oleh pengguna akhir (end user). Monitoring adalah proses untuk memastikan bahwa model bekerja dengan baik setelah deployment dan untuk mengidentifikasi jika ada degradasi kinerja atau masalah lain.
Bersambung ke:
Pendahuluan Klasifikasi
- Get link
- X
- Other Apps



Comments
Post a Comment