Pengantar Hyperparameter Tuning
- Get link
- X
- Other Apps
Pengantar Hyperparameter Tuning
Hi champs!
Akhirnya Anda mencapai modul terakhir pada kelas Belajar Machine Learning untuk Pemula. Setelah melewati berbagai macam rintangan yang ada, tentunya sekarang Anda sudah memiliki banyak sekali pengalaman membangun model machine learning mulai dari klasifikasi, regresi, clustering, hingga optimasi fitur melalui feature engineering.
Modul ini merupakan checkpoint terakhir sebelum Anda resmi menamatkan kelas Machine Learning Pemula. Untuk menyelesaikan submission dengan sempurna, tentunya Anda perlu melakukan hyperparameter tuning agar mencapai performa yang dapat diandalkan.
Seperti yang Anda tahu, pada modul ini akan membahas salah satu bagian paling krusial dalam pengembangan model, yaitu optimasi hyperparameter. Tahapan ini merupakan langkah akhir dalam menyempurnakan model machine learning Anda.
Bayangkan setiap pilihan hyperparameter ini seperti menyusun potongan puzzle yang tersisa. Setelah semua kerja keras sebelumnya, tahapan ini adalah momen di mana semuanya akan terhubung dan menghasilkan model yang sempurna.
So, siapkan energi penuh karena modul ini adalah langkah terakhir dari perjalanan Anda sejauh ini. Anda akan menikmati hasilnya setelah menyelesaikan suatu permasalahan sampai akhir. Saatnya memberikan yang terbaik dan akhiri perjalanan dengan penuh keyakinan dan semangat.
Selamat menikmati modul terakhir ini dan bersiaplah mendapatkan model terbaik!
[Story] Tugas Akhir Kuliah
Setelah mengarungi perjalanan yang cukup panjang dan membuat berbagai model machine learning, Diana dan Bilqis akhirnya mencapai akhir masa ujian yang berada di akhir semester. Tugas akhir menjadi salah satu momok yang menakutkan bagi mahasiswa karena biasanya mereka akan diberi sebuah tugas dengan skala yang cukup besar.
Hingga hari ujian untuk mata kuliah machine learning tiba, dosennya memberikan tugas akhir yang cukup menantang, yaitu membangun model prediksi harga rumah menggunakan dataset besar dan menerapkan hyperparameter tuning untuk meningkatkan performa model.
Diana merasa bersemangat sekaligus sedikit gugup. Untungnya, ia memiliki sahabat baik, Bilqis, yang juga merupakan mahasiswa jurusan yang sama dan keduanya sering belajar bersama.
Diana bertemu Bilqis di perpustakaan kampus dengan laptop dan sebuah buku tebal di tangannya. Ia mulai menjelaskan tugas yang harus ia selesaikan.

Bilqis, yang sudah lebih dulu mempelajari topik ini, tersenyum dan menjelaskan sedikit informasi kepada Diana.

Dimulai dari pertanyaan tersebut akhirnya Bilqis menjelaskan dengan sangat detail ilmu yang ia miliki.

Diana memutuskan untuk memulai dengan Random Forest, sebuah model yang populer untuk masalah regresi. Mereka membuka laptop dan mulai bekerja dengan dataset California Housing dari Scikit-learn.
Setelah model pertama mereka berjalan, Diana melihat hasilnya. “Wow! Model kita sudah bisa memprediksi harga rumah dengan akurasi 0.75, tapi ini masih model dasar, kan? Bagaimana caranya kita bisa membuatnya lebih baik?”
Bilqis tersenyum lebar. “Sekarang saatnya kita mencoba Grid Search. Ini metode yang sederhana, tapi bisa lama. Dengan Grid Search, kita mencoba semua kombinasi hyperparameter yang memungkinkan, seperti mencicipi semua variasi suhu oven dan waktu memanggang untuk menemukan yang terbaik.”
Setelah beberapa saat, Grid Search selesai, dan mereka menemukan bahwa akurasi model meningkat menjadi 0.78. Namun, Diana merasa waktu komputasinya cukup lama.
“Ini sudah lebih baik, tapi Grid Search mencoba setiap kombinasi yang mungkin terjadi. Kira-kira ada cara yang lebih cepat nggak ya?” ujar Diana.
“Ada cara yang lebih cepat, namanya Random Search. Alih-alih mencoba semua kombinasi, kita memilih beberapa kombinasi secara acak. Ini lebih hemat waktu, tapi tetap bisa memberikan hasil yang bagus,” jawab Bilqis sambil mengangguk.
Setelah hasil keluar, akurasinya sedikit menurun menjadi 0.77, tetapi waktu komputasinya jauh lebih cepat.
“Random Search memang lebih cepat,” kata Diana, “Tapi bagaimana kalau ada metode lain yang lebih baik dalam mencari hyperparameter terbaik tanpa harus mencoba semua kombinasi? Dan kalau bisa juga lebih efisien daripada grid search”
Sambil tersenyum bangga, Bilqis berkata, “Dugaanmu benar Na! Itu namanya Bayesian Optimization. Ini metode yang lebih cerdas karena memprediksi hasil percobaan berikutnya berdasarkan hasil sebelumnya.”
Setelah Bayesian Optimization selesai, akurasi model meningkat menjadi 0.80 dengan waktu komputasi yang efisien.
Setelah mencoba ketiga metode, Diana merasa lebih percaya diri. "Jadi Cis, Grid Search memberi kita hasil yang baik tapi lambat, Random Search lebih cepat tapi kurang akurat, dan Bayesian Optimization cerdas dan seimbang," ujar Diana.
Bilqis tersenyum puas. "Benar! Kini kamu paham bahwa tidak ada satu metode yang cocok untuk semua situasi. Terkadang kita butuh hasil cepat, terkadang kita ingin mencoba semuanya, atau kita bisa memilih metode cerdas seperti Bayesian Optimization."

Diana mengangguk, penuh dengan semangat baru. Mereka berdua menutup laptop masing-masing dan keluar dari perpustakaan dengan penuh rasa percaya diri untuk menghadapi tugas akhir pada mata kuliah machine learning.
Diana dan Bilqis akhirnya menyelesaikan mata kuliah machine learning dengan nilai sempurna dan menjadi murid terbaik pada mata kuliah tersebut. Tentunya Anda juga tidak mau kalah ‘kan?
Selagi masih ada waktu, Anda juga perlu mengejar kesuksesan seperti mereka berdua. Dengan menyelesaikan modul ini, Anda juga semakin dekat dengan kesuksesan yang sudah direncanakan. Oleh karena itu, mari kita selesaikan tugas akhir ini dengan sangat gemilang. Semangat!
Pendahuluan Hyperparameter Tuning
Hai hai hai!
Selamat datang kembali di kelas Machine Learning untuk Pemula, terima kasih telah berjuang sejauh ini dan memberanikan diri untuk terus melangkah. Jangan lupa untuk mengapresiasi diri sendiri, ya. Namun, jangan berlebihan juga karena masih banyak ilmu yang perlu kita cari.

Seperti yang sudah Anda pelajari pada modul Overfitting dan Underfitting, hyperparameter tuning merupakan langkah yang sangat penting untuk menghasilkan model machine learning yang andal.
Ngomong-ngomong, apakah Anda masih ingat apa itu hyperparameter tuning pada modul Overfitting dan Underfitting? Yup, ingatan Anda sangat baik. Hyperparameter tuning adalah proses dalam machine learning untuk mengoptimalkan kinerja model berdasarkan suatu nilai tertentu. For your information, pada machine learning terdapat dua jenis parameter yaitu parameter model dan hyperparameter. Apa sih bedanya? Sini, mari kita jelaskan secara saksama.
| Fitur | Parameter | Hyperparameter |
|---|---|---|
Definisi | Nilai yang dipelajari oleh model selama pelatihan. | Ditentukan oleh pengguna untuk mengontrol proses pembelajaran model. |
Tujuan | Memengaruhi performa pada model secara langsung. | Mengontrol proses pembelajaran dan struktur model. |
Kapan Diatur | Dipelajari selama proses pelatihan model. | Ditentukan sebelum pelatihan dimulai. |
Metode Tuning | Dipelajari dari data menggunakan algoritma optimasi. | Disetel manual atau melalui metode seperti grid search, random search, atau Bayesian optimization. |
Pengaruh pada Model | Memengaruhi hasil/output model secara langsung. | Memengaruhi kecepatan dan kualitas pembelajaran. |
Ketergantungan pada Dataset | Bergantung pada dataset yang digunakan untuk pelatihan. | Independen dari dataset, ditentukan sebelum pelatihan dimulai. |
Contoh | Koefisien dalam regresi linear, bobot dalam jaringan saraf, dan lain sebagainya. | Learning rate, jumlah layer, batch size, test_size, dan lain sebagainya. |
Kesimpulannya, parameter model adalah nilai yang dipelajari oleh model selama proses pelatihan, seperti bobot (weight) dalam jaringan saraf tiruan. Di lain sisi, hyperparameter merupakan nilai yang tidak dipelajari selama pelatihan, tetapi dapat ditentukan sebelum pelatihan model dimulai.

Jika Anda memperhatikan gambar di atas, terdapat banyak sekali hyperparameter yang dapat diatur. Beberapa contoh penerapan hyperparameter adalah jumlah pohon dalam algoritma Random Forest, learning rate dalam gradient boosting, atau jumlah neuron dalam hidden layer pada jaringan saraf tiruan.
Sebenarnya apa sih fungsi dari hyperparameter ini secara nyata? Berikut salah satu contoh dari penerapan learning rate yang dapat memengaruhi performa model.
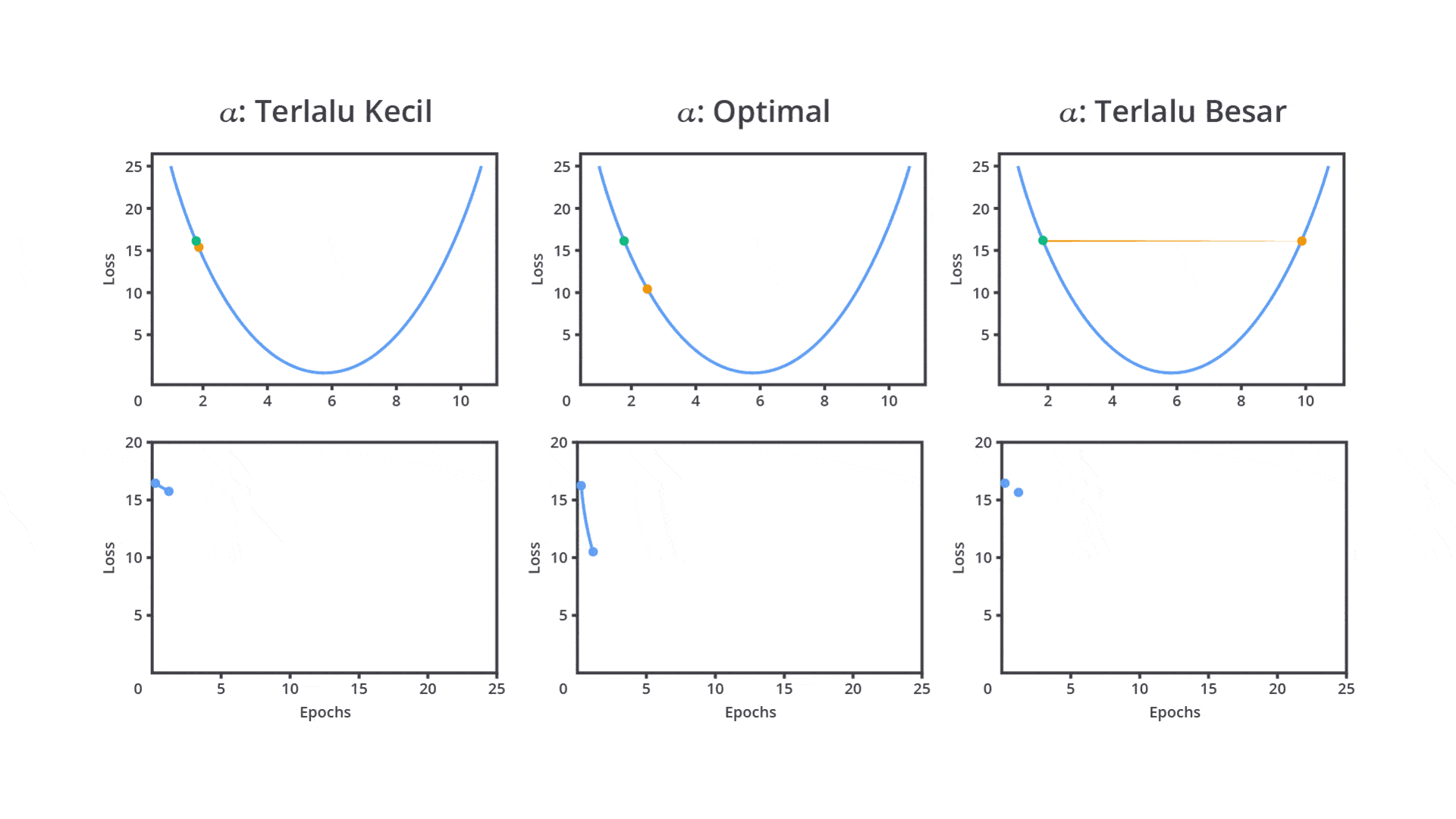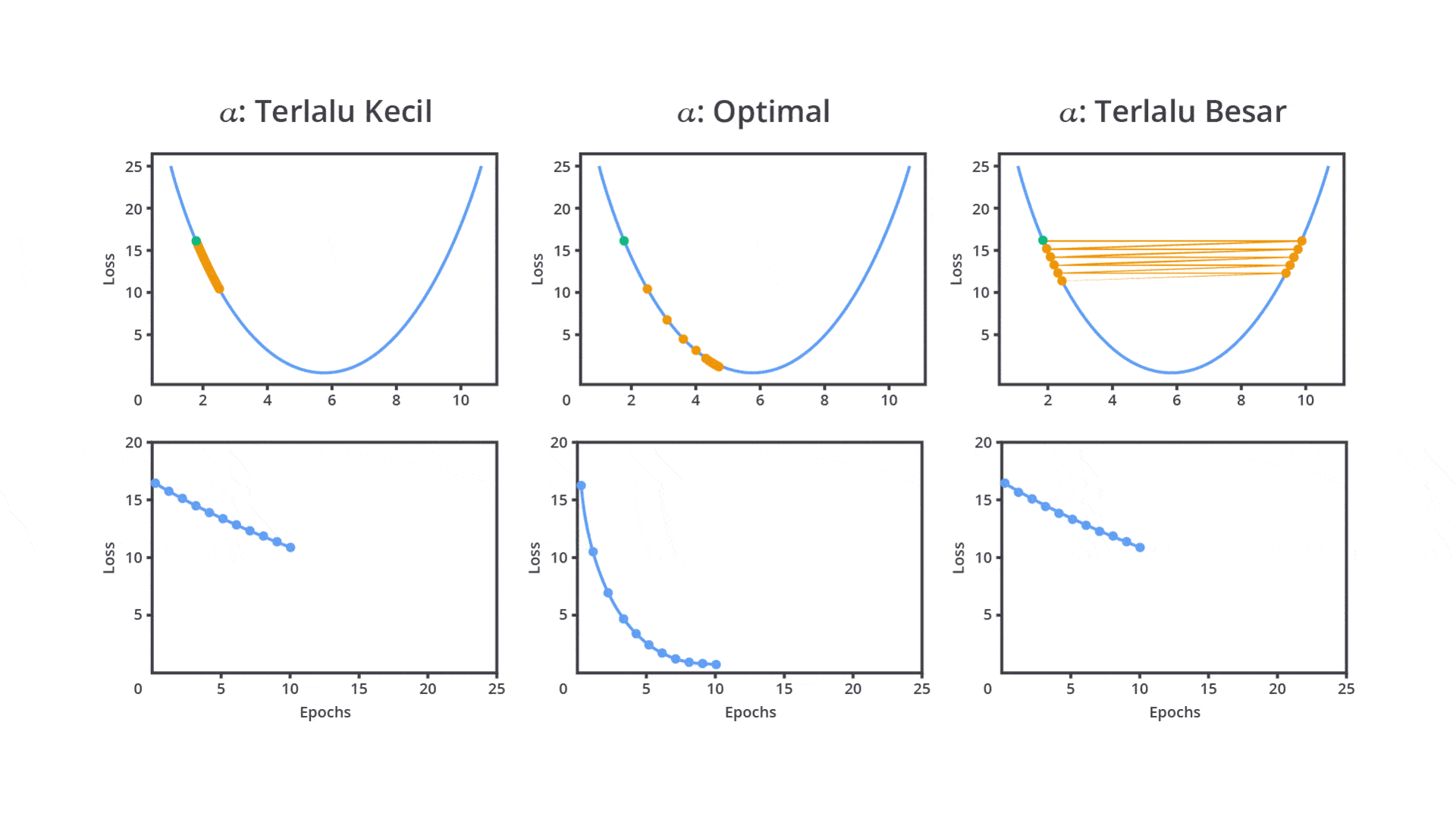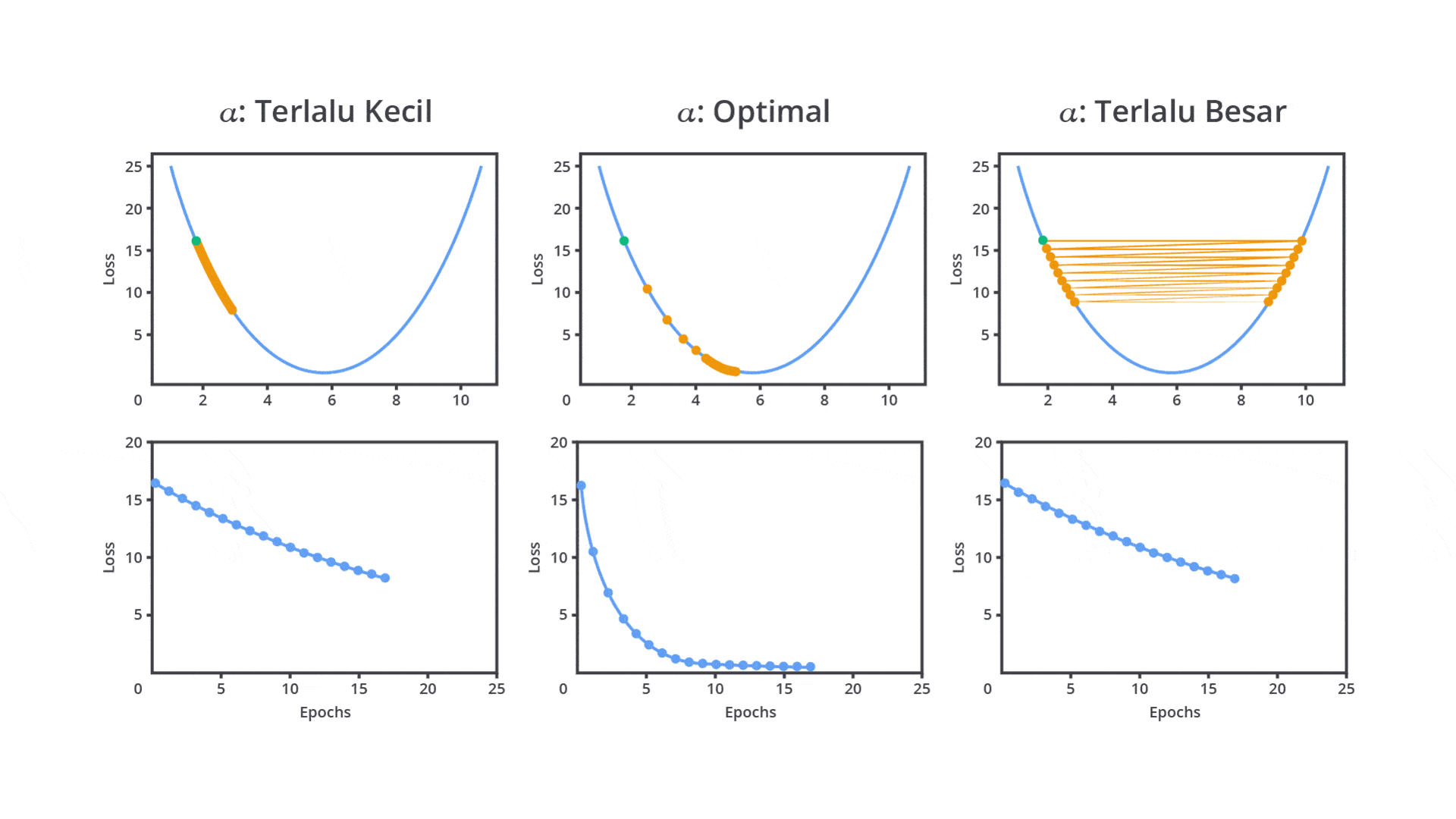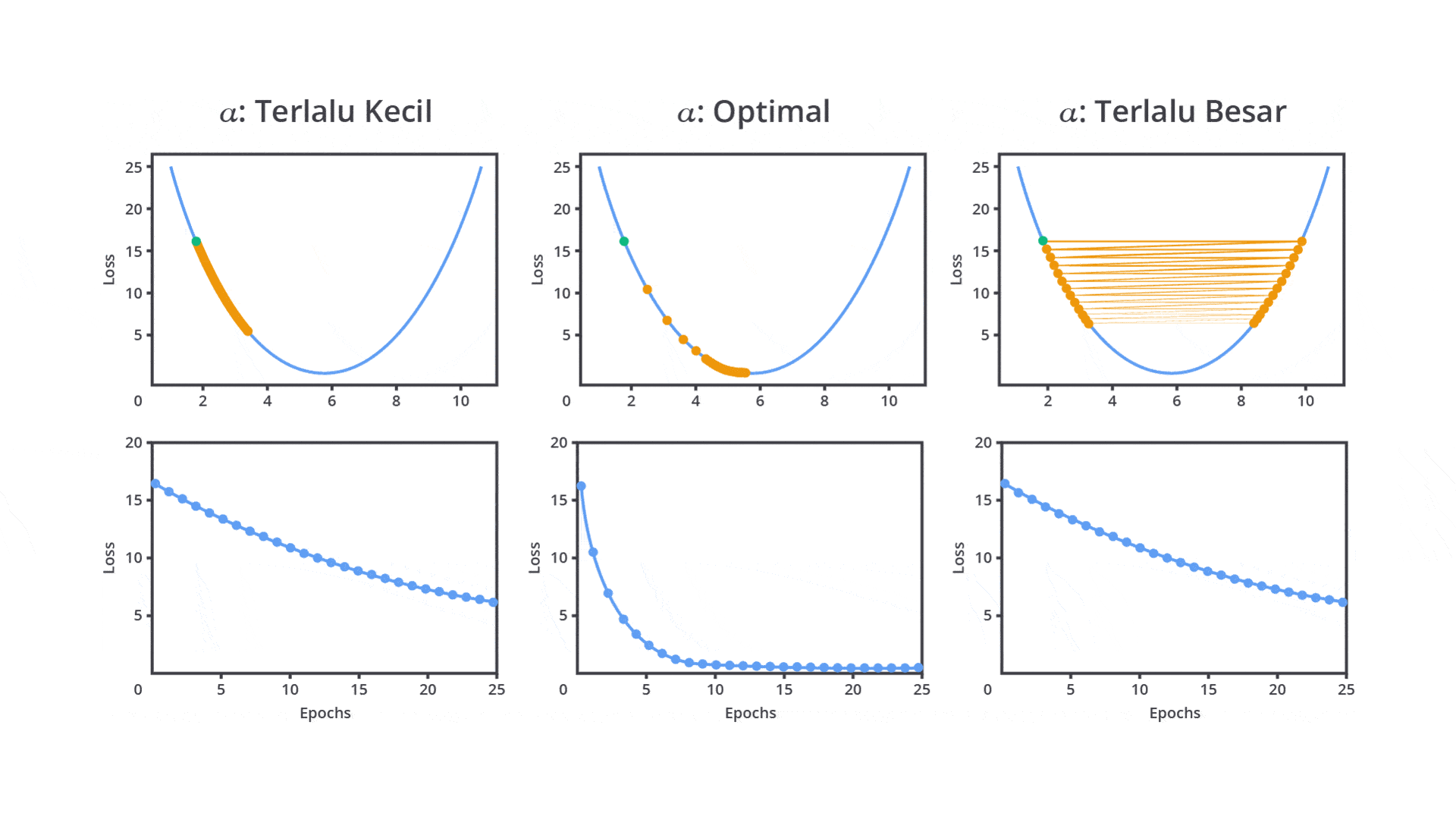
Berdasarkan gambar di atas, tentunya hyperparameter memiliki peran penting dalam menentukan bagaimana model akan belajar (dilatih) dan seberapa baik model tersebut menggeneralisasi data yang belum pernah dilihat sebelumnya. Dengan pemilihan nilai yang tepat, model yang Anda bangun akan menghasilkan performa terbaik dan dapat diandalkan pada lingkungan produksi.
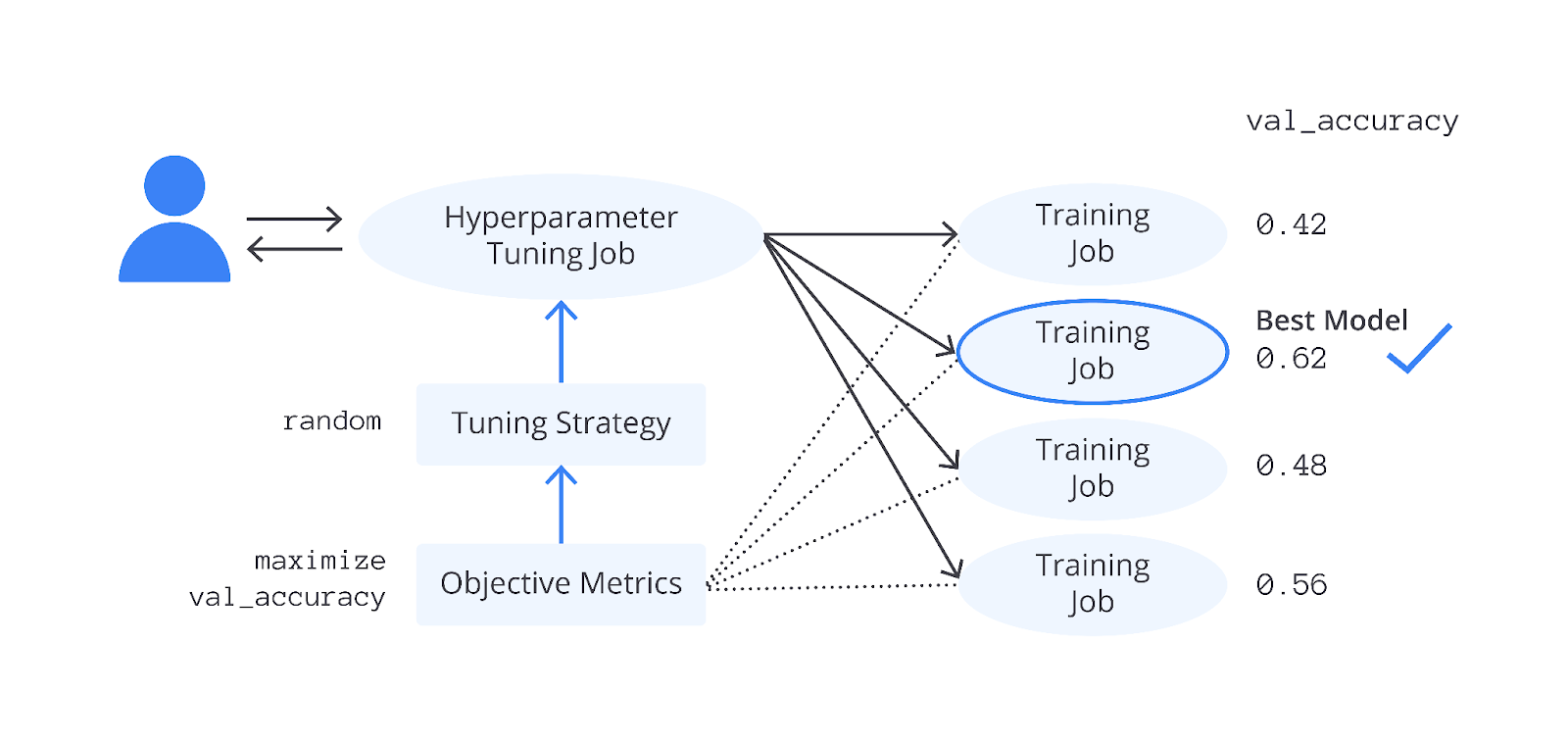
Lalu, bagaimana dengan parameter? Seperti yang Anda tahu, parameter merupakan nilai yang dihasilkan ketika model dilatih. Nilai tersebut dihasilkan dari perhitungan weight, bias, input, dan lain sebagainya. Sehingga, jika kita simpulkan, keduanya memiliki hubungan yang erat. Dengan pemilihan hyperparameter yang tepat Anda juga dapat menghasilkan parameter yang efisien. Agar lebih memahami hubungan antara keduanya tersebut, silakan perhatikan gambar proses pelatihan model berikut, ya.
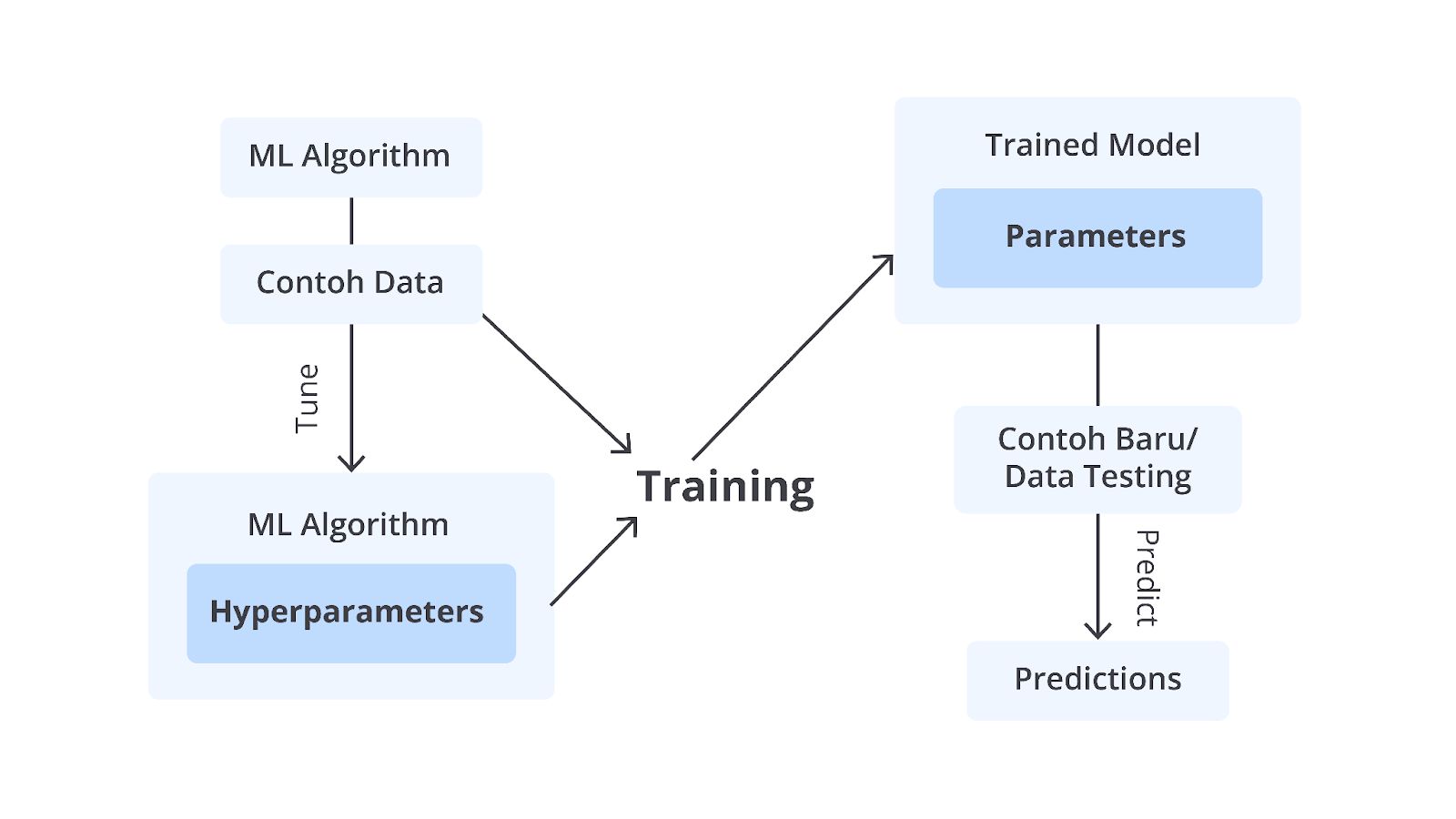
Berangkat dari gambar di atas maka proses hyperparameter tuning bertujuan untuk menemukan kombinasi hyperparameter yang menghasilkan kinerja model terbaik pada dataset tertentu. Hal ini dilakukan dengan menguji berbagai nilai hyperparameter, kemudian memilih yang memberikan hasil paling optimal berdasarkan metriks evaluasi.
Mari sedikit flashback pada modul Machine Learning Workflow. Masih ingatkah Anda bagaimana proses pembangunan model machine learning? Yes, proses tersebut diulang berkali-kali (iteratif) hingga menghasilkan performa terbaik.
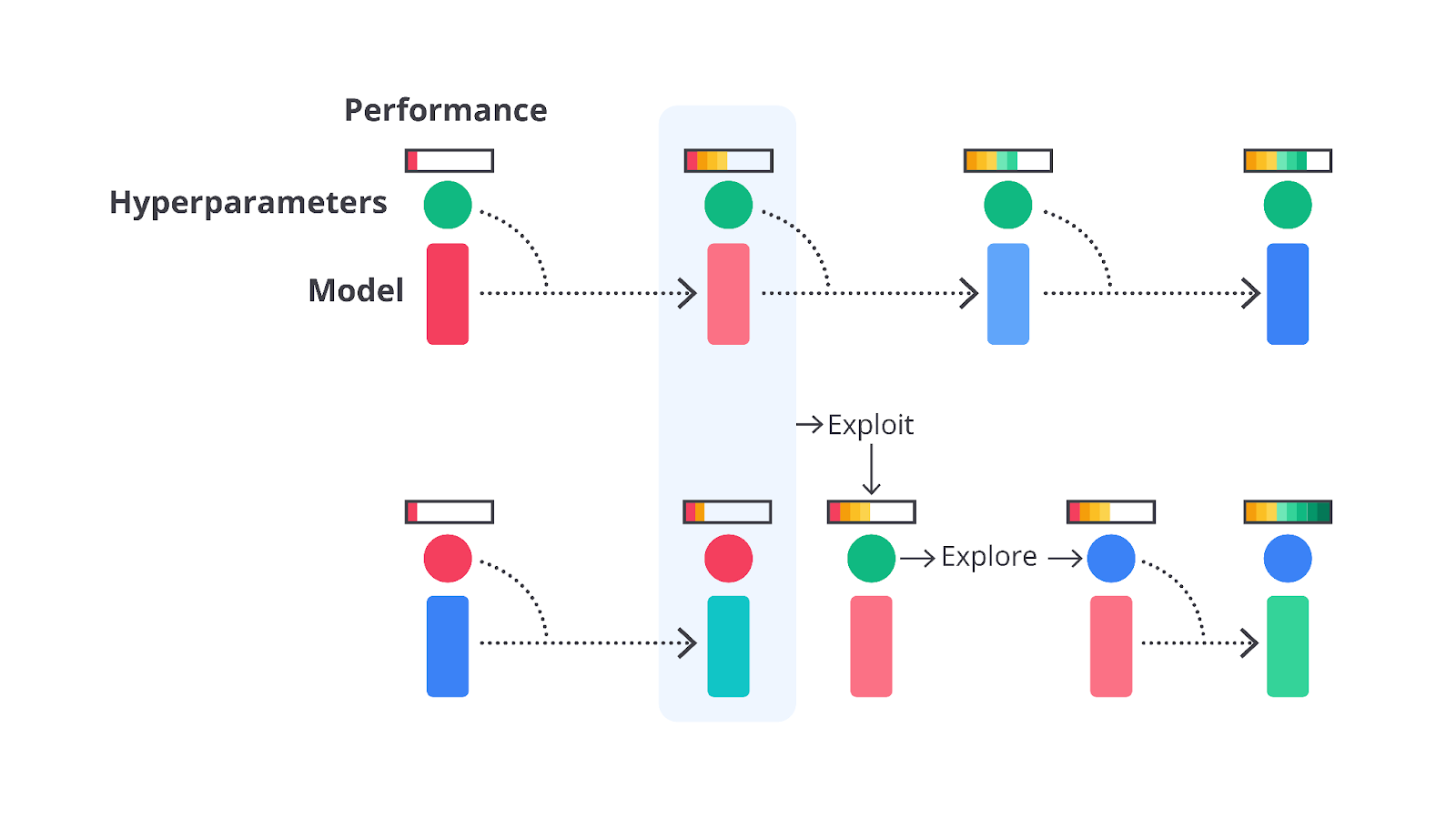
Jika Anda telisik, proses hyperparameter tuning ini merupakan bagian dari salah satu tahapan model selection. Proses yang terjadi pada tahapan tersebut akan terlihat seperti gambar di bawah ketika dijelaskan dengan lebih detail.
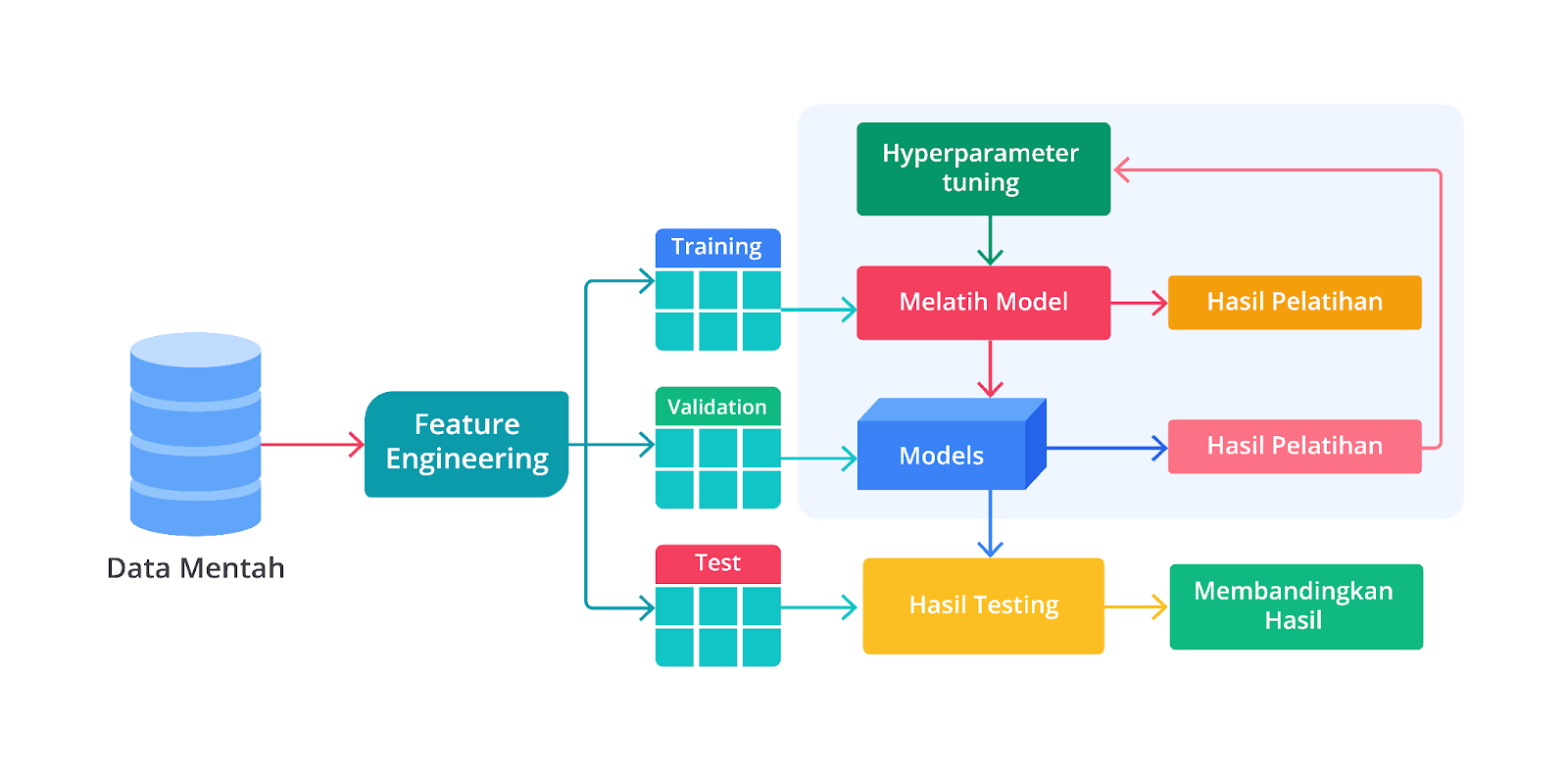
Seperti yang Anda tahu, pemilihan fitur atau hyperparameter tuning menggunakan langkah iteratif untuk menghasilkan parameter terbaiknya. Sayangnya, sampai saat ini belum ada guideline khusus untuk menentukan nilai dari masing-masing hyperparameter.
Biasanya, Anda perlu berlatih sebanyak mungkin untuk meningkatkan intuisi dalam mengatur hyperparameter. Sehingga, dari proses trial and error tersebut, Anda memiliki pengalaman yang baik ketika menginisialisasi nilai hyperparameter.
Walaupun sudah mempelajari berbagai macam hyperparameter Anda tetap harus mencari nilai hyperparameter terbaik secara manual. Hal tersebut karena machine learning tidak dapat dibangun menggunakan penyelesaian yang sama. Hal ini berlandaskan dari materi yang sudah Anda ketahui pada modul Machine Learning Workflow bahwa tidak ada model yang cocok secara universal untuk data dan tujuan apa pun.
Sampai di sini harusnya Anda sudah mengetahui peran dan alasan mengapa hyperparameter tuning ini menjadi salah satu tahapan yang cukup krusial.
Secara garis besar, hyperparameter tuning ini menjadi penting karena setiap algoritma machine learning memiliki hyperparameter yang berbeda dan pilihan hyperparameter yang tepat dapat secara signifikan meningkatkan performa model. Perhatikan beberapa contoh hyperparameter dari algoritma di bawah.
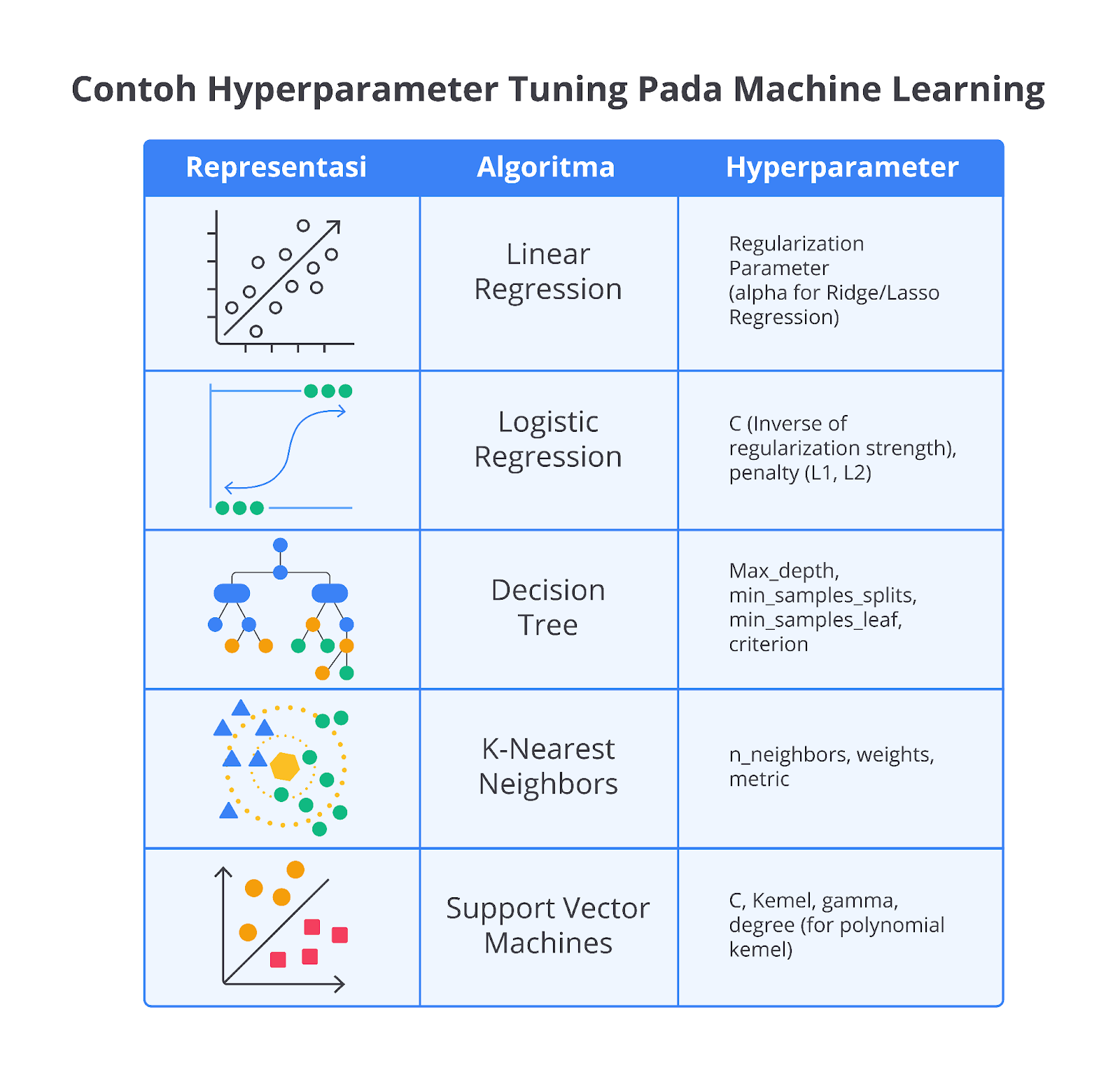
Jadi, permasalahan akan muncul ketika hyperparameter tidak diatur dengan baik sehingga model cenderung mengalami overfitting atau underfitting. Masih ingatkan apa itu overfitting atau underfitting? Tenang, salah satu pionir machine learning yaitu Andrew N.G pernah berkata, “Don’t worry if you don’t understand.”
Oleh karena itu, kita akan sedikit me-refresh materi tersebut agar Anda dapat belajar dengan lebih santai. Berikut penjelasan singkat dari overfitting dan underfitting.
- Overfitting terjadi ketika model terlalu kompleks dan terlalu "menghafal" data latih sehingga tidak dapat menggeneralisasi pada data baru.
- Underfitting terjadi ketika model terlalu sederhana sehingga tidak cukup menangkap pola-pola dalam data.
Dengan demikian, tujuan utama hyperparameter tuning adalah untuk menemukan keseimbangan yang tepat antara bias dan varians (bias-variance tradeoff) sehingga model mampu mempelajari pola dengan baik tanpa kehilangan kemampuan untuk menggeneralisasi pada data baru.
Strategi Hyperparameter Tuning
Sebelum Anda mengetahui langkah-langkah yang biasanya dilakukan pada tahap hyperparameter tuning, alangkah lebih baiknya Anda memahami dahulu bagaimana memilih hyperparameter yang tepat untuk model machine learning yang akan dibangun. Pemilihan hyperparameter ini bertujuan untuk meminimalisasi ukuran dan komputasi yang dilakukan oleh komputer.
Bayangkan jika Anda melakukan metode brute force terhadap seluruh hyperparameter pada suatu algoritma, tentunya akan memakan biaya komputasi dan waktu yang cukup banyak ‘kan? Oleh karena itu, Anda perlu memilih hyperparameter terbaik dari masing-masing algoritma yang akan digunakan.
Dari sekian banyak hyperparameter tentunya tidak semuanya memiliki dampak yang sama pada model tertentu sehingga penting untuk memilih dan mengatur hyperparameter yang relevan untuk mencapai performa optimal.
Berikut adalah panduan umum tentang pemilihan hyperparameter yang relevan, termasuk cara untuk mengidentifikasi dan mengatur prioritas dalam tuning.
- Penggunaan Default Hyperparameter
Pada tahap awal, Anda dapat memulai dengan nilai default dari hyperparameter yang sering kali sudah diatur sedemikian rupa oleh library yang digunakan agar memberikan hasil yang baik pada kebanyakan kasus. Nilai ini dapat memberikan baseline yang cukup baik sebelum mulai melakukan tuning secara manual maupun otomatis.
Namun, penting untuk diingat bahwa nilai default cenderung tidak selalu optimal untuk dataset tertentu sehingga tetap diperlukan tuning terutama jika hasil baseline tidak memadai.
- Memahami Algoritma yang Digunakan
Setiap algoritma machine learning memiliki hyperparameter yang berbeda-beda dan dapat memengaruhi model machine learning. Oleh karena itu, langkah pertama dalam pemilihan hyperparameter yang relevan adalah memahami algoritma yang digunakan, termasuk apa saja hyperparameter penting yang tersedia.
Selain hyperparameter yang sudah Anda ketahui pada materi sebelumnya, berikut adalah beberapa contoh hyperparameter yang sering kali Anda temui ketika mempelajari dasar machine learning.- Regresi Linier / Regresi Logistik
Regularisasi (L2 atau L1) dan C atau lambda adalah hyperparameter utama yang perlu diperhatikan. - K-Nearest Neighbors (KNN)
Jumlah tetangga terdekat (k) dan jarak metrik (Euclidean, Manhattan) adalah hyperparameter yang paling penting. - Decision Tree
Kedalaman pohon (max_depth), jumlah sampel minimum untuk membagi simpul (min_samples_split), dan criterion (impurity measure seperti Gini atau Entropy) sangat memengaruhi performa model. - Random Forest
Jumlah pohon (n_estimators), kedalaman pohon (max_depth), dan ukuran minimum sampel di setiap daun (min_samples_leaf) adalah hyperparameter yang perlu dipertimbangkan. - Support Vector Machine (SVM)
Regularisasi parameter (C) dan jenis kernel (linear, rbf, polynomial), serta parameter kernel seperti gamma (untuk rbf kernel) sangat penting. - Neural Networks (Jaringan Saraf Tiruan)
Jumlah lapisan tersembunyi (hidden layer), jumlah neuron (units) di setiap lapisan, learning rate, batch size, dan optimizer sangat memengaruhi kinerja model.
- Regresi Linier / Regresi Logistik
- Identifikasi Hyperparameter yang Paling Berpengaruh
Tidak semua hyperparameter memiliki pengaruh besar terhadap performa model. Oleh karena itu, langkah kedua adalah mengidentifikasi hyperparameter mana yang paling berpengaruh secara signifikan terhadap kinerja model. Fokus pada hyperparameter yang paling penting akan menghemat waktu dan sumber daya selama proses tuning. Salah satu cara terbaik untuk mengidentifikasi hyperparameter yang relevan adalah sebagai berikut.- Riset Literatur dan Dokumentasi: memahami dari dokumentasi atau penelitian yang relevan untuk mencari hyperparameter terpenting pada algoritma yang digunakan.
- Pengalaman adalah Guru Terbaik: pengalaman mengembangkan model sering kali memberikan wawasan tentang hyperparameter mana yang layak untuk difokuskan.
- Eksperimen Awal: lakukan eksperimen awal dengan nilai default untuk semua hyperparameter, kemudian lakukan analisis untuk memahami hyperparameter mana yang paling memengaruhi kinerja.
- Prioritaskan Tuning Hyperparameter yang Krusial
Setelah mengidentifikasi hyperparameter yang relevan, langkah selanjutnya adalah memprioritaskan tuning hyperparameter yang paling krusial. Ini berarti, Anda sebaiknya tidak mencoba menyetel semua hyperparameter sekaligus, tetapi memfokuskan eksplorasi pada hyperparameter yang berpotensi memberikan dampak paling besar terlebih dahulu.
Sebagai contoh pada model Random Forest, Anda bisa mulai dengan tuning n_estimators dan max_depth terlebih dahulu karena kedua parameter ini biasanya berpengaruh besar pada kompleksitas dan kinerja model.
- Memahami Hubungan antara Hyperparameter
Beberapa hyperparameter memiliki hubungan yang saling terkait sehingga pengaruhnya pada model tergantung pada pengaturan hyperparameter lainnya. Misalnya, dalam jaringan saraf tiruan, learning rate dan momentum sering kali berinteraksi bersamaan.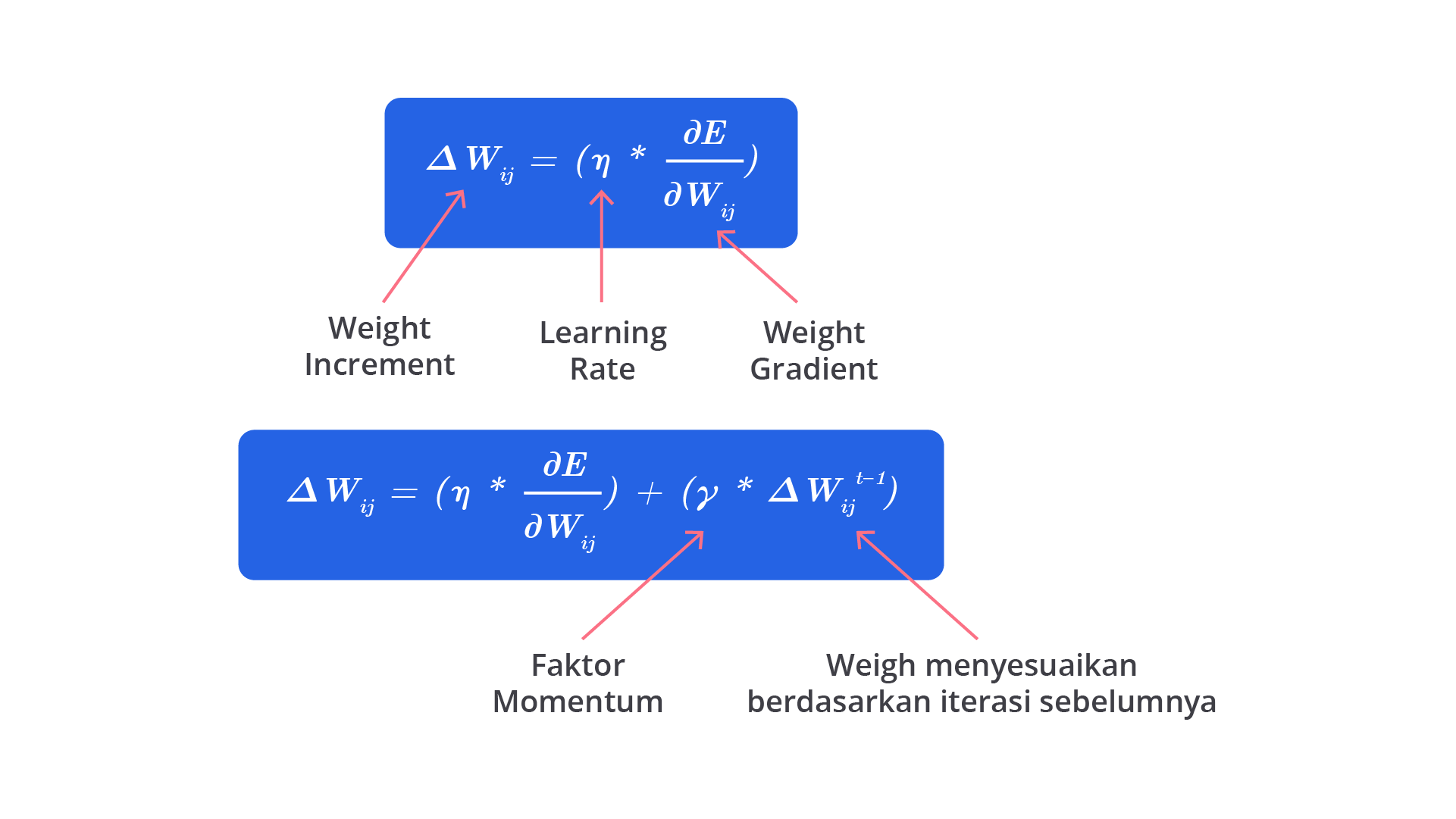 Dari salah satu contoh di atas, dengan melakukan tuning salah satu hyperparameter tanpa mempertimbangkan yang lain, dapat menyebabkan kinerja buruk karena keduanya saling berkaitan.
Dari salah satu contoh di atas, dengan melakukan tuning salah satu hyperparameter tanpa mempertimbangkan yang lain, dapat menyebabkan kinerja buruk karena keduanya saling berkaitan.
- Menyesuaikan Hyperparameter Berdasarkan Data
Hyperparameter yang relevan tidak hanya bergantung pada algoritma yang digunakan tetapi juga pada karakteristik data yang dilatih. Beberapa pertimbangan yang biasanya dilakukan yaitu seperti berikut.- Ukuran Dataset: pada dataset besar, batch size yang lebih besar bisa membuat pelatihan lebih efisien. Sementara pada dataset kecil, batch size yang kecil mungkin lebih tepat untuk mencegah overfitting.
- Dimensi Data: pada dataset berdimensi tinggi, model seperti SVM sering kali membutuhkan tuning yang lebih intensif pada hyperparameter gamma untuk menangani kompleksitas data.
- Jumlah Noise: jika data mengandung banyak noise, regularization parameter misalnya C pada SVM atau alpha pada Ridge Regression mungkin harus diperhatikan supaya terhindar dari overfitting.
- Evaluasi Kinerja Model dengan Cross-Validation
Untuk setiap kombinasi hyperparameter yang diuji, Anda perlu melakukan evaluasi kinerja model secara menyeluruh (tidak hanya satu kali pengujian). Penggunaan teknik seperti cross-validation akan sangat membantu karena memungkinkan mengevaluasi performa model pada berbagai subset data dalam satu waktu sehingga hasil tuning hyperparameter dapat divalidasi dengan lebih cermat.
Dengan pendekatan yang tepat, tahapan hyperparameter tuning dapat membantu model menghindari masalah seperti overfitting atau underfitting sehingga menghasilkan prediksi yang lebih akurat dan model yang dapat diandalkan.
Memilih hyperparameter yang tepat sangat penting karena hyperparameter memiliki pengaruh langsung terhadap seberapa baik model dapat belajar dari data, kecepatan proses pelatihan, dan kemampuan model untuk menggeneralisasi pada data yang belum pernah dilihat sebelumnya.
Lalu, apa sih sebenarnya pengaruh dari hyperparameter tuning ini? Sedari tadi, kita hanya berbicara perihal peningkatan performa, tetapi kita tidak mengetahui apa yang terjadi di baliknya. Oleh karena itu, mari kita bahas sedikit lebih dalam pengaruh hyperparameter tuning.
Salah satu hyperparameter paling penting dalam banyak algoritma machine learning terutama dalam jaringan saraf tiruan dan gradient-based learning adalah learning rate. Learning rate menentukan seberapa besar langkah yang diambil oleh algoritma optimasi setiap kali memperbarui bobot atau parameter model berdasarkan gradient error.
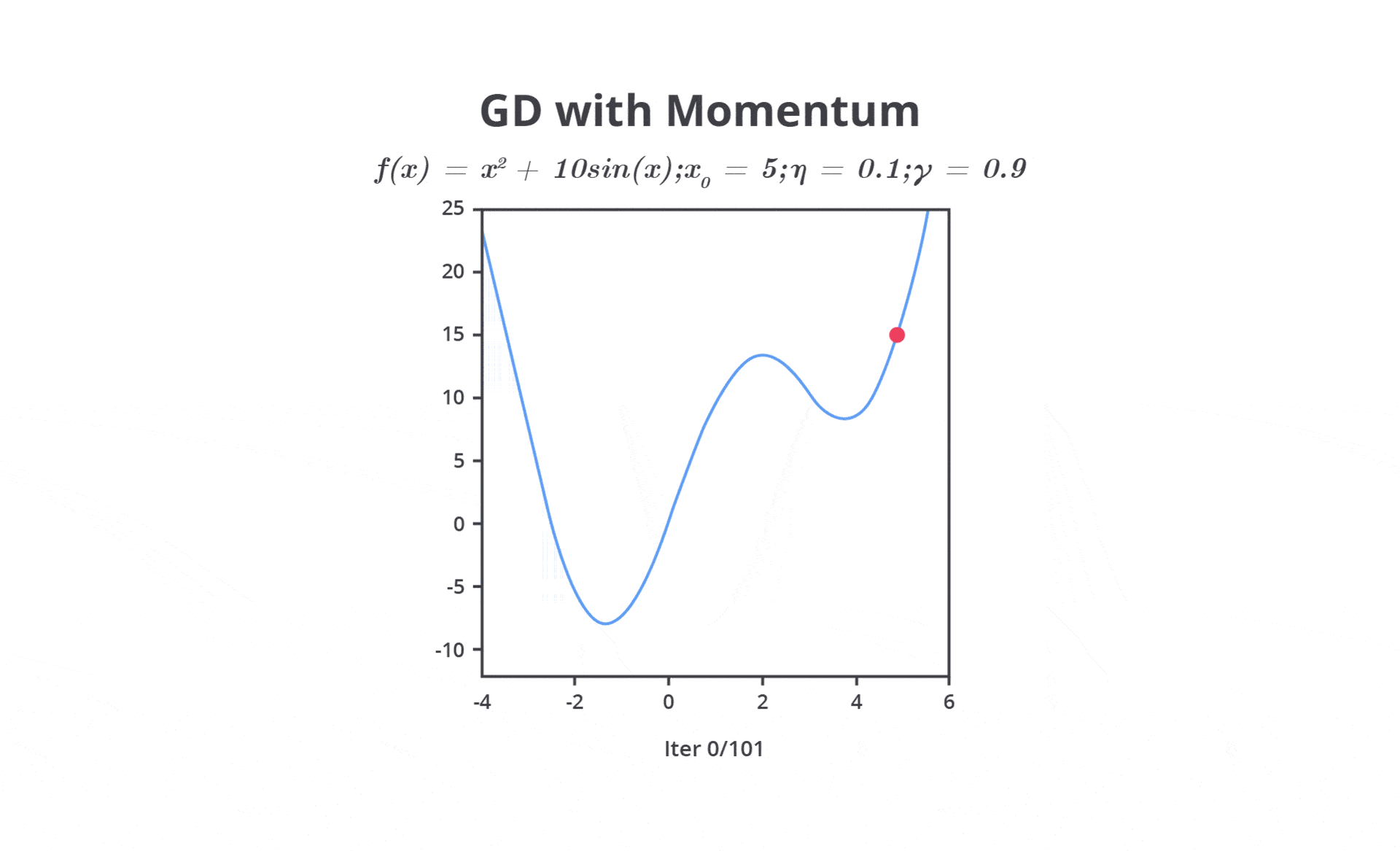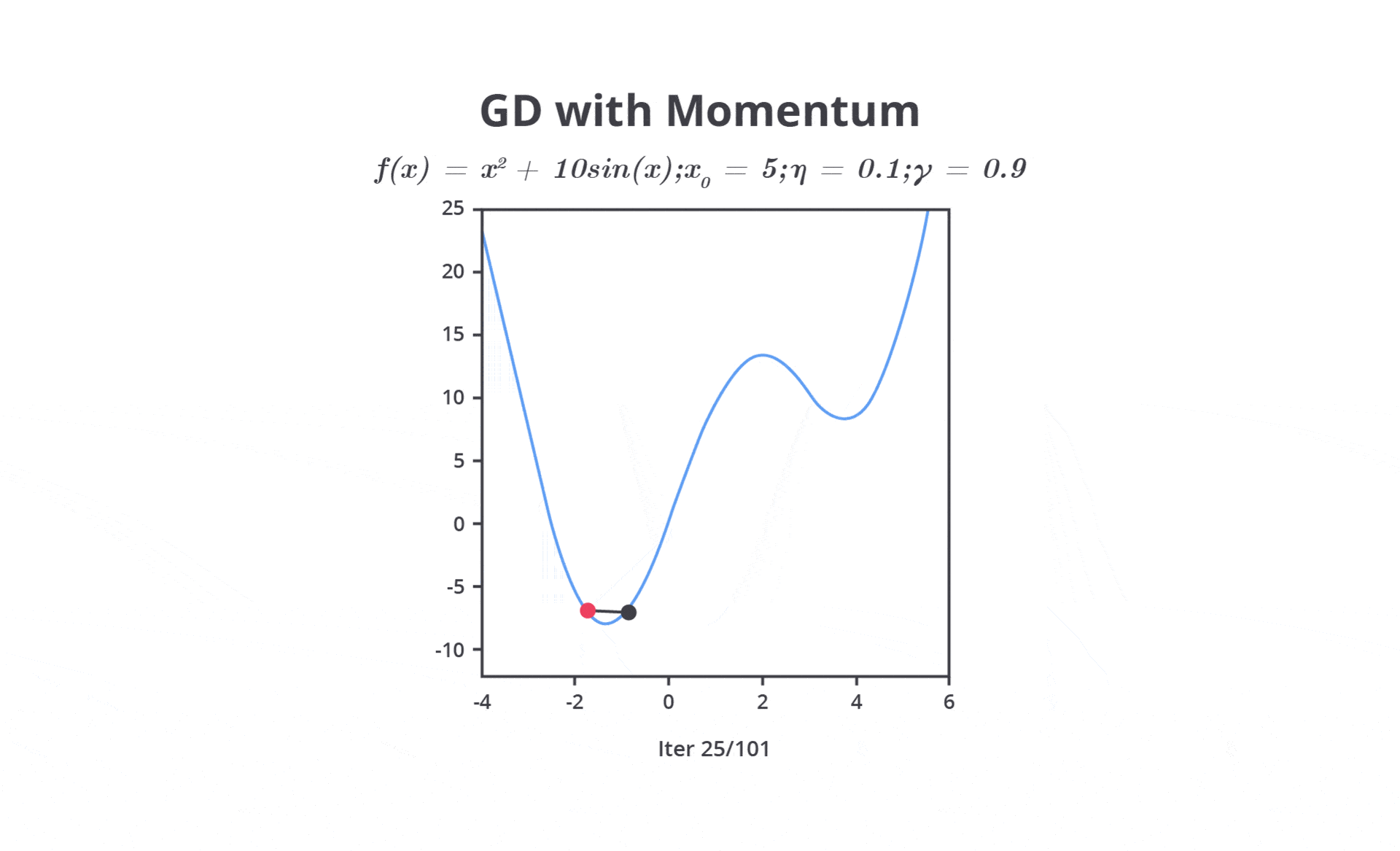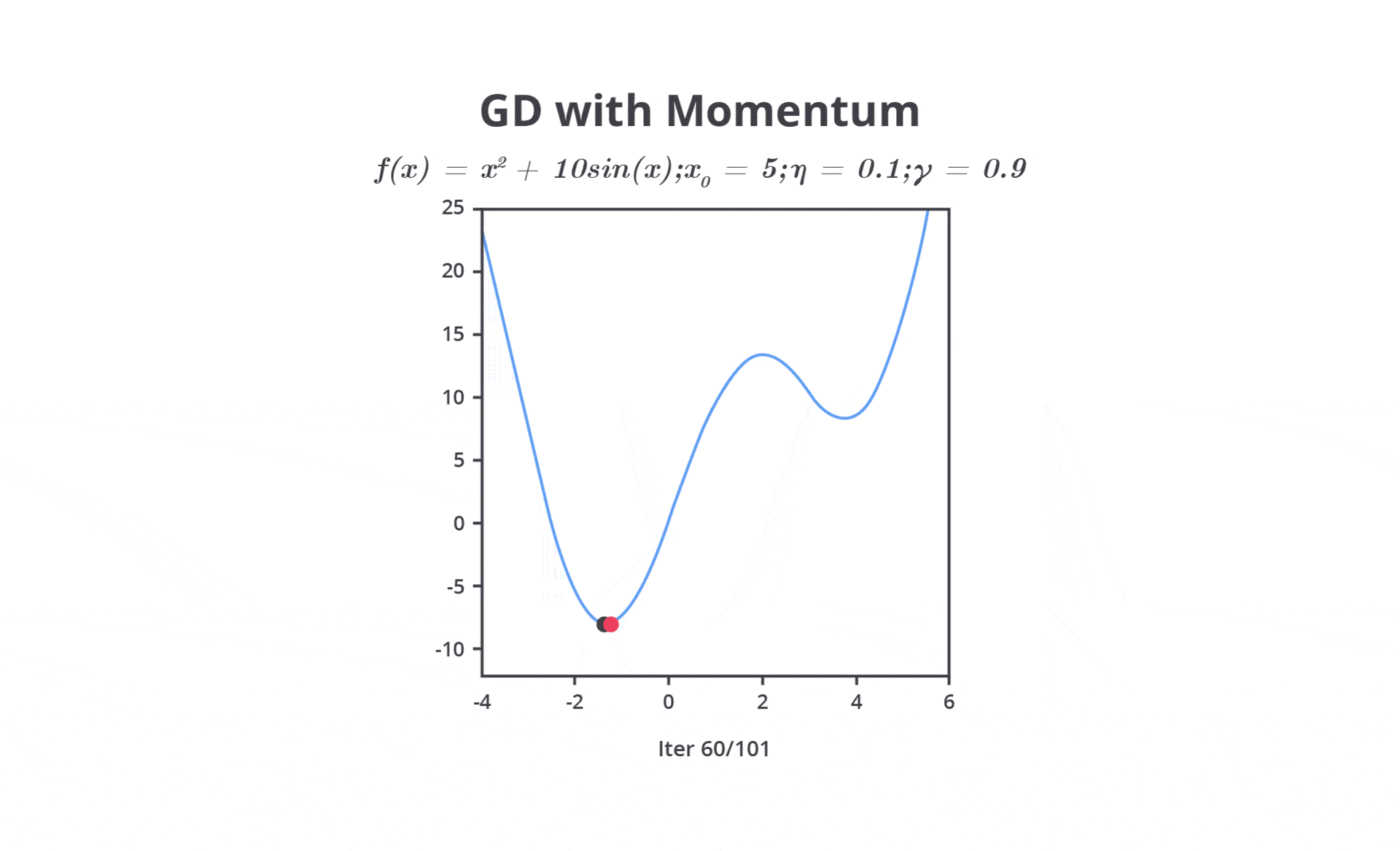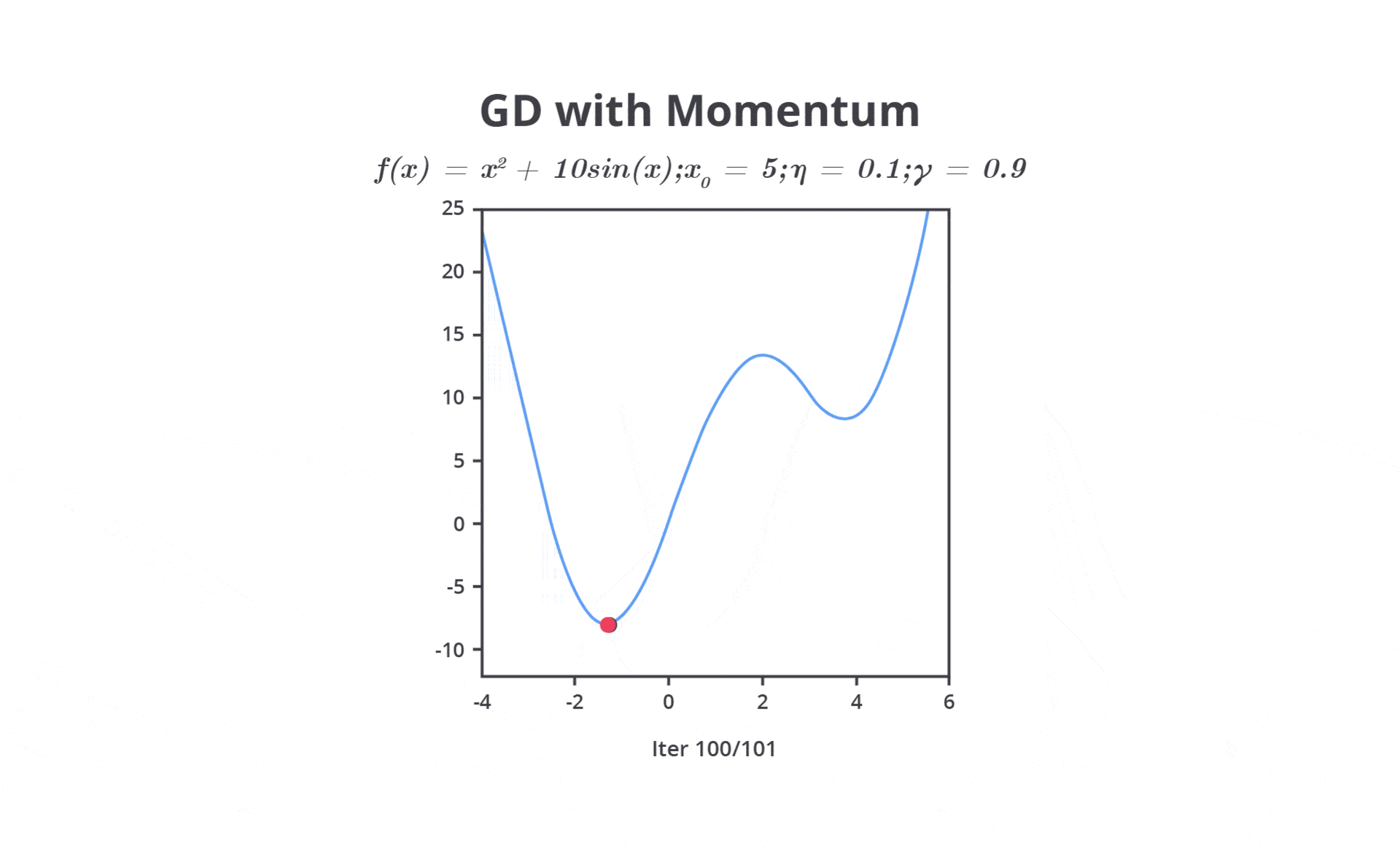
Pada tahap ini, Anda perlu mengatur learning rate dengan mempertimbangkan dua pilihan yaitu nilai learning rate yang besar atau kecil. Keduanya tentu memiliki kelebihan dan kekurangannya masing-masing.
Nilai learning rate yang cenderung besar dapat menyebabkan model belajar terlalu cepat sehingga memungkinkan model melewati performa optimal. Hal ini dapat menyebabkan osilasi dalam proses optimasi, di mana model tidak dapat menemukan titik minimum dari fungsi kerugian (loss function).
Sebaliknya, jika Anda mengatur nilai learning rate terlalu kecil akan menyebabkan pelatihan menjadi sangat lambat karena langkah yang terlalu kecil untuk menghasilkan perubahan sehingga tidak memberikan pembaharuan yang signifikan pada parameter. Meskipun ini dapat membantu model lebih mendekati solusi optimal, waktu pelatihan yang dibutuhkan akan sangat lama atau bahkan tidak sama sekali.
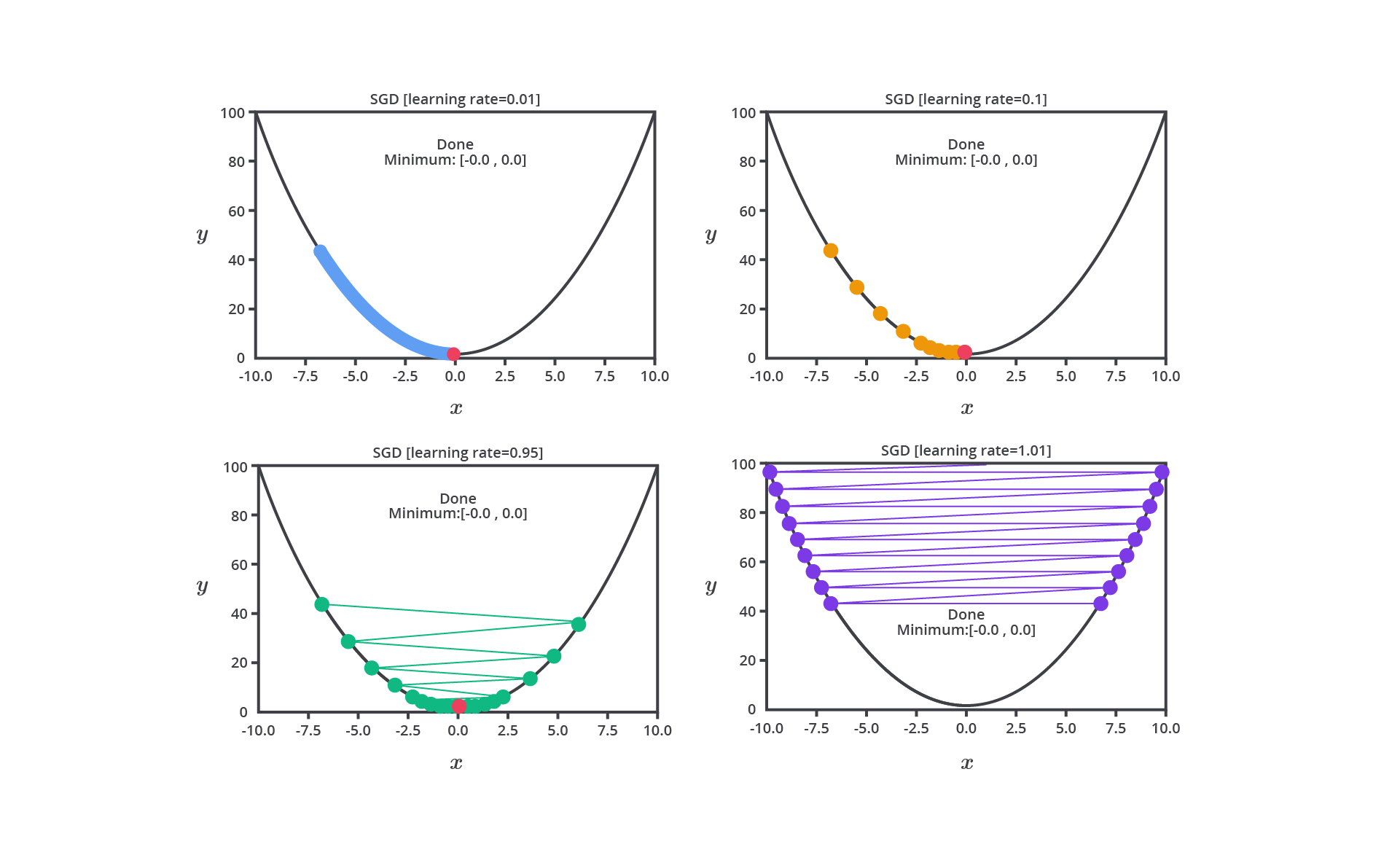
Oleh karena itu, learning rate perlu diatur dengan cermat untuk mencapai keseimbangan antara kecepatan konvergensi dan kualitas model machine learning yang dibangun. Psstt, tenang kita tidak perlu melakukan semuanya secara manual karena pada kelas ini kita juga akan mempelajari materi optimasi dengan menggunakan library yang sudah ada.
Selain memengaruhi proses pembelajaran, Anda juga dapat menghindari permasalahan overfitting atau underfitting dengan melakukan hyperparameter tuning. Salah satu alasannya karena Anda juga dapat mengatur variabel regularisasi ketika melakukan hyperparameter tuning. Regularisasi melibatkan penambahan penalti terhadap loss function untuk mencegah model menjadi terlalu rumit. Ada berbagai macam teknik regularisasi yang sudah Anda pelajari pada kelas ini, tetapi Anda tidak perlu kembali ke modul sebelumnya. Mari kita recap sedikit materi yang sudah Anda kuasai pada modul sebelumnya.
- L1 Regularization (Lasso): menambahkan penalti terhadap nilai absolut dari bobot parameter. Hal ini menyebabkan banyak parameter menjadi nol, sehingga menciptakan model yang lebih sederhana dan mengurangi overfitting. L1 juga berguna untuk seleksi fitur karena secara efektif menghilangkan fitur-fitur yang kurang penting.
- L2 Regularization (Ridge): menambahkan penalti dengan melakukan perhitungan kuadrat dari bobot parameter. L2 mendorong bobot parameter untuk menjadi kecil, tetapi tidak menjadi nol sehingga membantu mengurangi varian tanpa kehilangan informasi penting.
- Dropout (untuk jaringan saraf tiruan): pada setiap iterasi pelatihan, sebagian neuron akan dihilangkan secara acak dari jaringan untuk mencegah keterhubungan berlebih (co-adaptation) antar neuron. Dropout secara efektif mencegah overfitting dan menghasilkan jaringan yang lebih kuat dalam menggeneralisasi data baru.
Namun, ada dua hal yang perlu Anda pertimbangkan ketika mengatur nilai regularisasi yaitu kondisi ketika pengaturan terlalu tinggi atau pun terlalu rendah.
- Pengaturan Terlalu Tinggi: jika tingkat regularisasi terlalu tinggi, model mungkin tidak memiliki cukup kapasitas untuk mempelajari pola dalam data, menyebabkan underfitting.
- Pengaturan Terlalu Rendah: jika regularisasi terlalu rendah atau tidak diterapkan sama sekali, model mungkin menjadi sangat kompleks, yang menyebabkan overfitting pada data pelatihan dan kinerja yang buruk pada data pengujian.
Parameter selanjutnya yaitu ukuran dari batch_size yang Anda tentukan. Parameter ini memiliki peran yang cukup krusial karena berdampak terhadap penggunaan memori dari komputer yang Anda gunakan. Wait wait wait, jangan bilang Anda lupa apa itu batch_size? Agar kita memiliki pemahaman yang sama mari kita ulas sedikit penjelasannya terlebih dahulu.
Batch size adalah jumlah sampel yang diproses sebelum model memperbarui bobotnya dalam setiap iterasi pelatihan. Bayangkan Anda memiliki 1000 data yang akan dilatih, untuk mempermudah pemahaman, perhatikan visualisasi pembagian batch_size dengan nilai yang berbeda-beda.
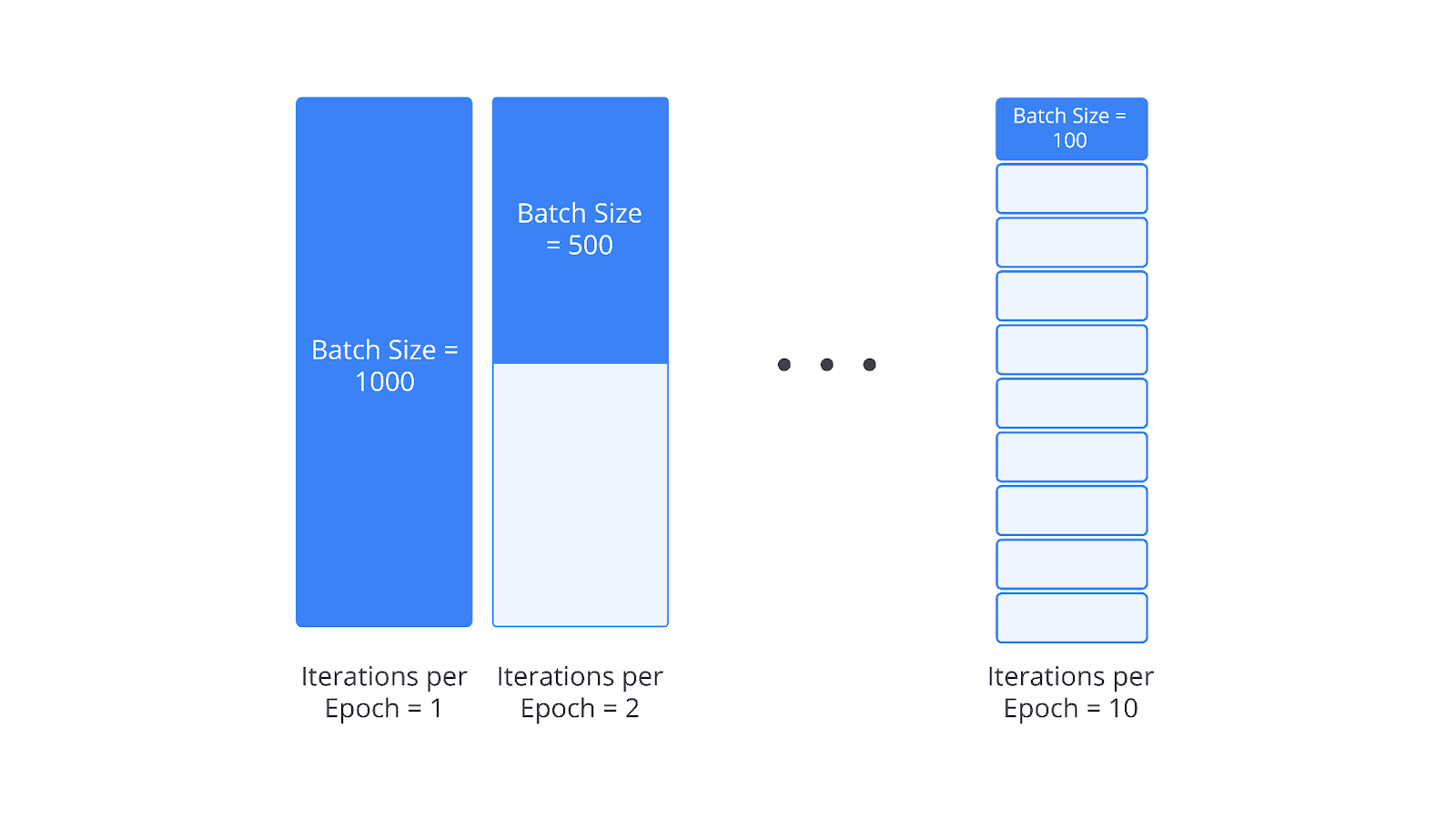
Lalu, apa hubungannya jumlah sampel dengan penggunaan memori? Tenang, mari kita pelajari penjelasan singkat terkait pengaruh nilai batch_size terhadap memori dan proses pelatihan.
- Batch size kecil
- Memperbarui bobot lebih sering sehingga memberikan perubahan parameter yang lebih granular dan memungkinkan model untuk lebih cepat merespons terhadap setiap data sampel.
- Pelatihan menjadi lebih tidak stabil, karena setiap batch kecil dapat menghasilkan estimasi gradient yang sangat bervariasi.
- Membutuhkan lebih sedikit memori sehingga cocok untuk sistem dengan keterbatasan memori.
- Batch size besar
- Memberikan estimasi gradient yang lebih stabil dan cenderung membuat pembaruan bobot lebih halus dan stabil.
- Membutuhkan lebih banyak memori dan waktu komputasi, tetapi dapat mempercepat proses pelatihan dalam hal iterasi per epoch.
Setelah menentukan ukuran batch_size, tentunya Anda sudah paham tahapan yang akan kita lakukan berikutnya, ‘kan? Benar, kita akan mengatur nilai epochs pada proses pelatihan machine learning. Epoch adalah jumlah perulangan yang dilakukan selama proses pelatihan model machine learning atau deep learning. Hyperparameter ini penting dalam mengatur kapan proses pelatihan dihentikan.
Umumnya ketika menggunakan library Scikit-Learn, Anda tidak akan bertemu dengan variabel epochs karena biasanya namanya akan berganti menjadi max_iter tergantung pada algoritma yang Anda gunakan.
Woah, banyak sekali istilah baru pada materi kali ini. Sampai di sini mungkin tebersit di benak Anda sebuah pertanyaan, “Apa sih bedanya batch_size, iteration, dan epochs?” Wajar, karena ketiganya memiliki dependensi yang berhubungan. Simak gambar berikut untuk melihat perbedaannya secara detail.
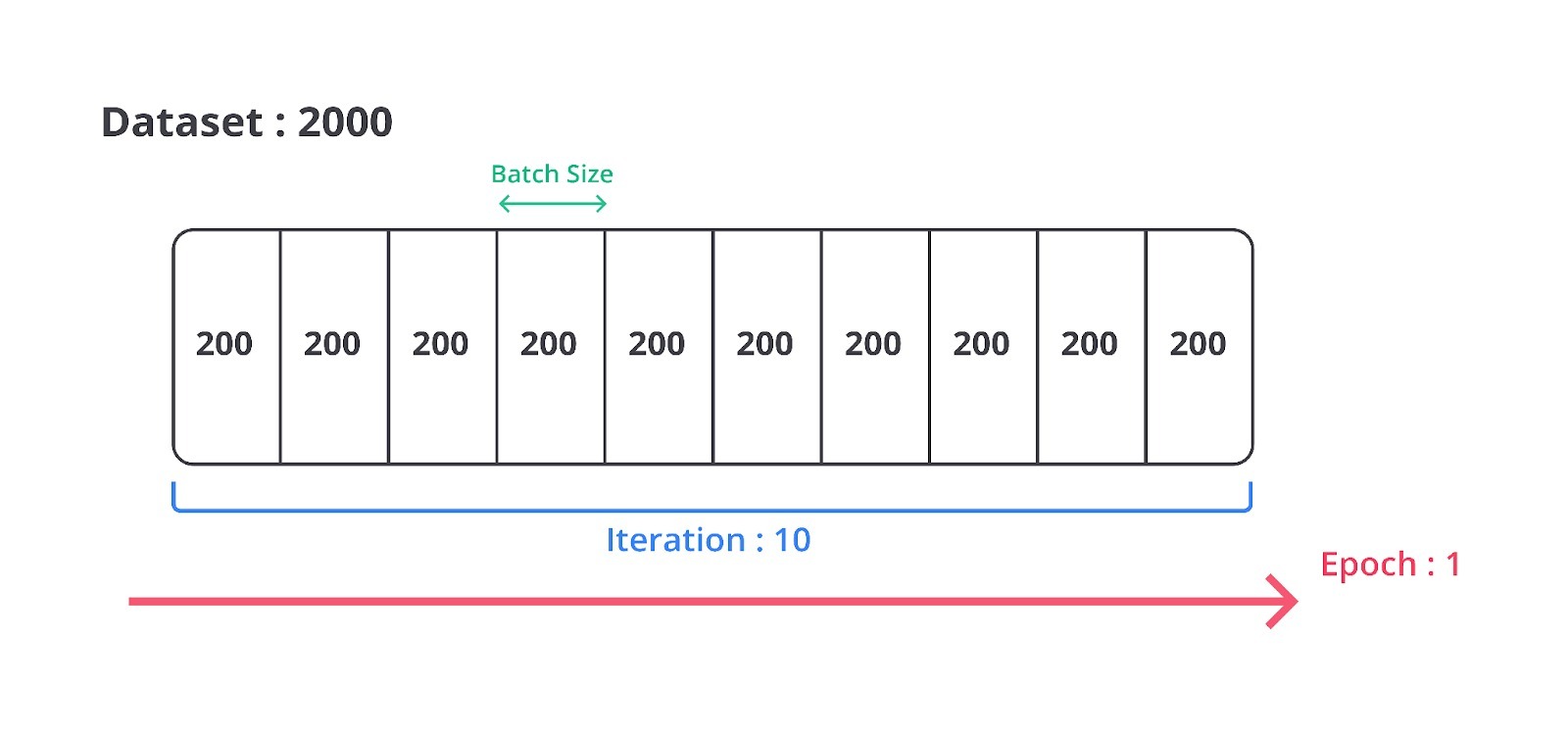
Ketika Anda memiliki 2000 data kemudian membagi dataset menjadi 10 iterasi, ukuran batch_size akan menjadi 200 data, begitu juga sebaliknya. Nah, proses pelatihan machine learning akan dilakukan sebanyak x epochs dengan ketentuan satu epochs harus mengulang sebanyak 10 iterasi di mana satu iterasi berisikan 200 buah data.
Ketika Anda mengatur jumlah epochs terlalu kecil, model cenderung memiliki performa yang tidak cukup baik. Hal ini dapat menyebabkan underfitting karena parameter belum mencapai nilai optimal. Sebaliknya, Anda juga tidak dapat mengatur epochs setinggi-tingginya karena model berpotensi overfitting pada data pelatihan karena terus belajar bahkan setelah mencapai titik optimal. Ini akan membuat model kurang mampu menggeneralisasi pada data baru.
“Serba salah dong, ya?” Tentu, tetapi tenang saja karena permasalahan tersebut dapat diselesaikan dengan menggunakan callbacks. Salah satu callbacks yang sering digunakan pada proses pembangunan model machine learning adalah early stopping. Early stopping adalah teknik untuk menghentikan pelatihan lebih awal ketika kinerja pada data validasi mulai menurun yang menunjukkan bahwa model mulai overfitting. Early stopping memungkinkan kita untuk menyetel jumlah epoch yang tepat secara otomatis.
Materi di atas merupakan contoh-contoh pengaruh hyperparameter tuning mulai dari pengaruh terhadap penggunaan memori, kompleksitas model, optimisasi model, hingga cara mengatasi overfitting atau underfitting.
Sejujurnya, di luar sana masih banyak sekali pengaruh hyperparameter tuning berdasarkan pengaturan yang Anda lakukan. Namun, tenang saja, dari berbagai macam hyperparameter tuning yang Anda lakukan kelak semuanya memiliki dampak yang sama dari materi yang sudah dipelajari pada kelas ini. Oleh karena itu, kami sangat menyarankan Anda untuk melakukan eksplorasi menggunakan algoritma lainnya dan temukan sensasi kebahagiaan ketika menemukan kombinasi terbaik pada model machine learning yang Anda buat.
Untuk memperdalam pengetahuan dan pengalaman Anda dalam proses hyperparameter tuning, mari kita pelajari beberapa metode untuk melakukan hyperparameter tuning sehingga tidak lagi menggunakan metode brute force.
Mari asumsikan brute force ini seperti Anda sedang mencari tahu kombinasi kata sandi pada laptop orang tua yang sudah lama tidak digunakan.

Tentunya semakin panjang kata sandi yang diatur, semakin lama juga proses yang dilalui dengan metode brute force ‘kan? Nah! Begitu juga pada kasus pemilihan hyperparameter ketika Anda membangun model machine learning.
Semakin banyak hyperparameter yang Anda gunakan pada suatu algoritma, semakin banyak juga kemungkinan yang bisa Anda implementasikan. Tentunya, proses tersebut akan memakan waktu yang sangat lama ‘kan?
Bayangkan juga ketika Anda membangun sebuah model yang memakan waktu 30 menit sekali pelatihan, lalu butuh waktu berapa lama untuk Anda mencoba semua kemungkinan yang ada? Mungkin selamanya jika Anda merupakan tipe orang yang tidak cepat puas dan selalu ingin mencoba.
Nah, dengan menggunakan metode optimasi pada hyperparameter tuning Anda dapat menghemat banyak waktu karena metode seperti grid search, random search, dan bayesian optimization akan mencari hyperparameter yang paling cocok untuk data yang Anda gunakan.
Alih-alih mencari semua kemungkinan yang ada, metode tersebut akan mencari hyperparameter terbaik dengan efisien. Tidak sabar, bukan? Tanpa berlama-lama mari kita pelajari satu per satu metode yang umum digunakan untuk melakukan hyperparameter tuning.
Grid Search
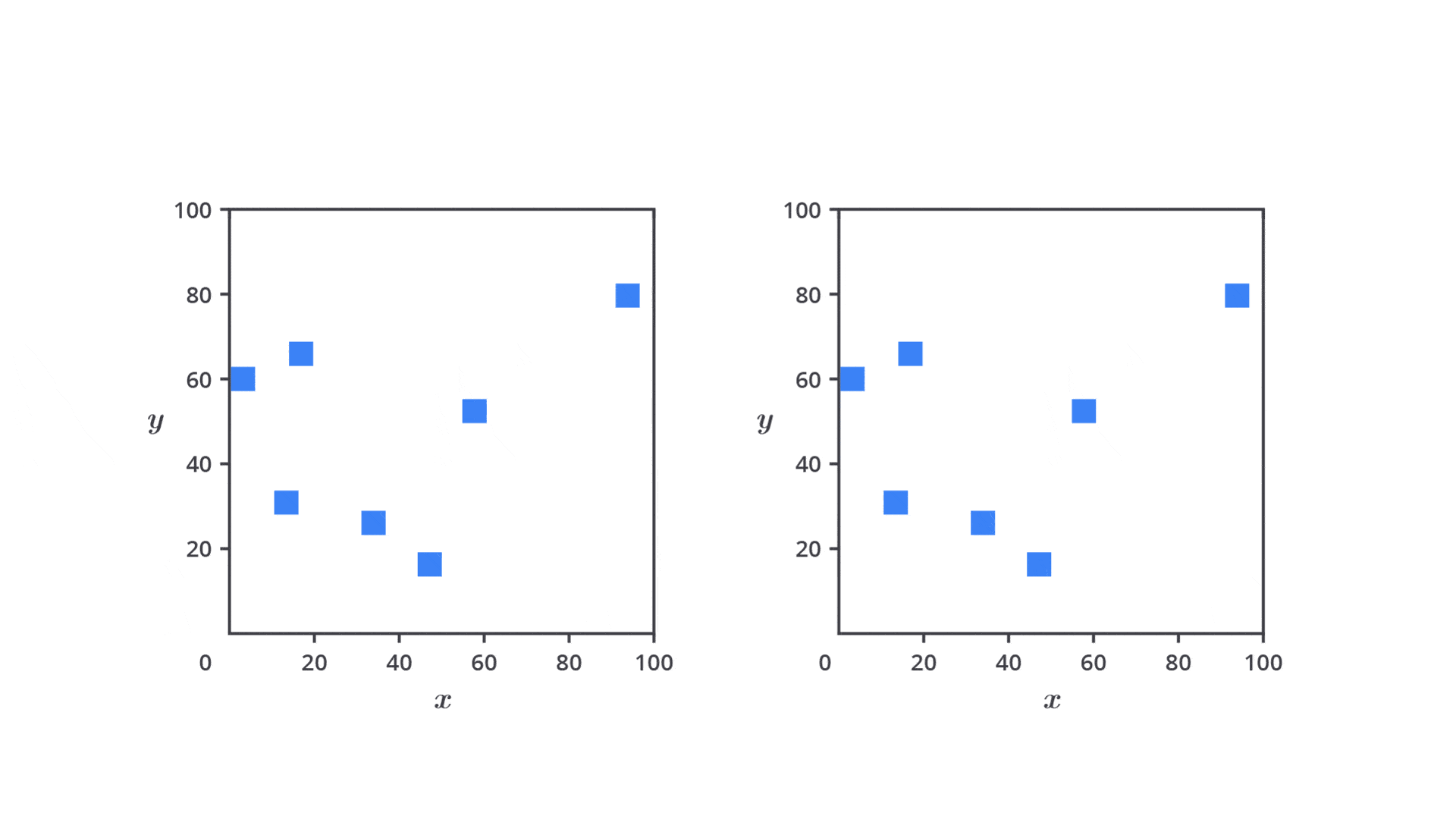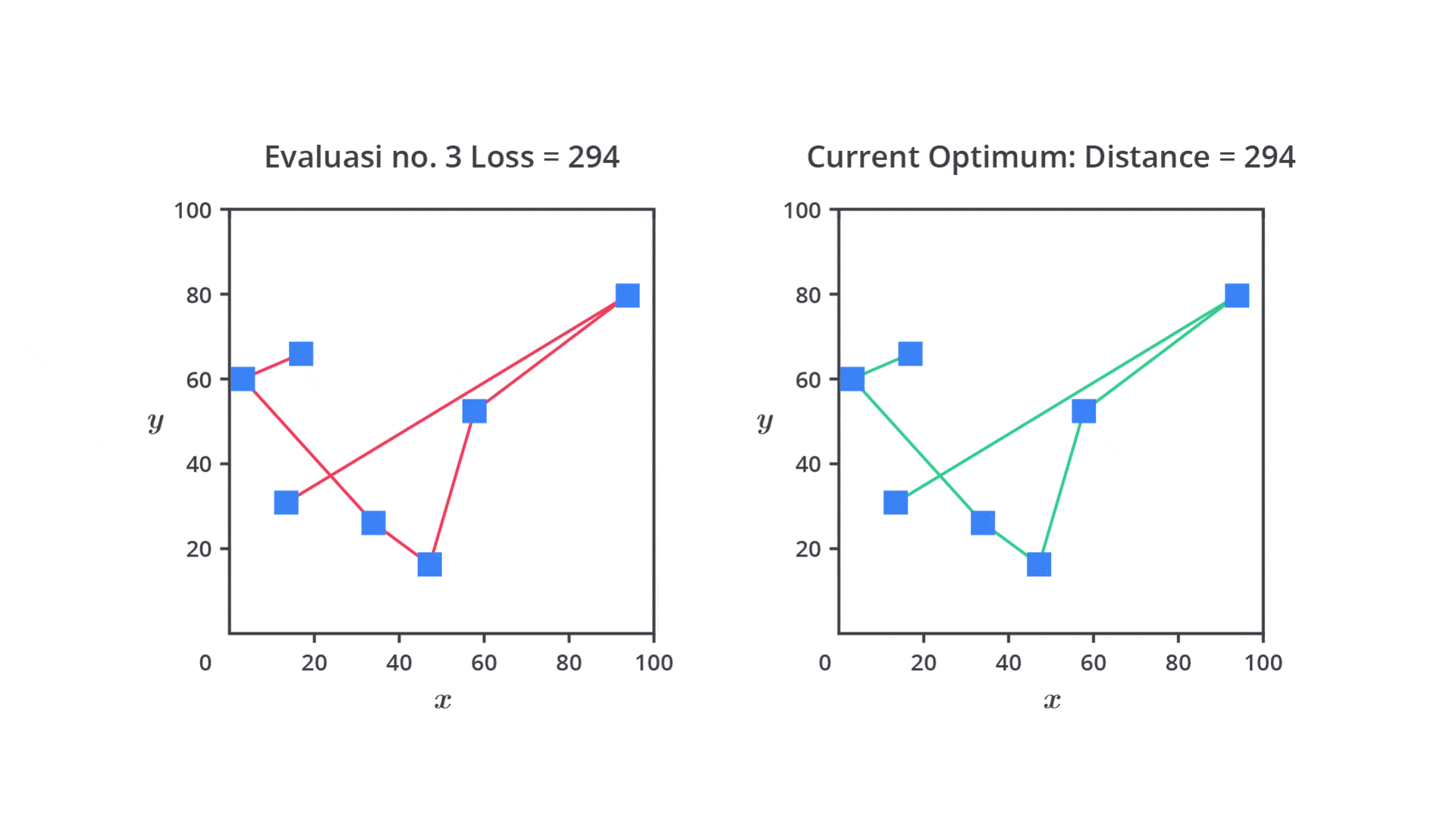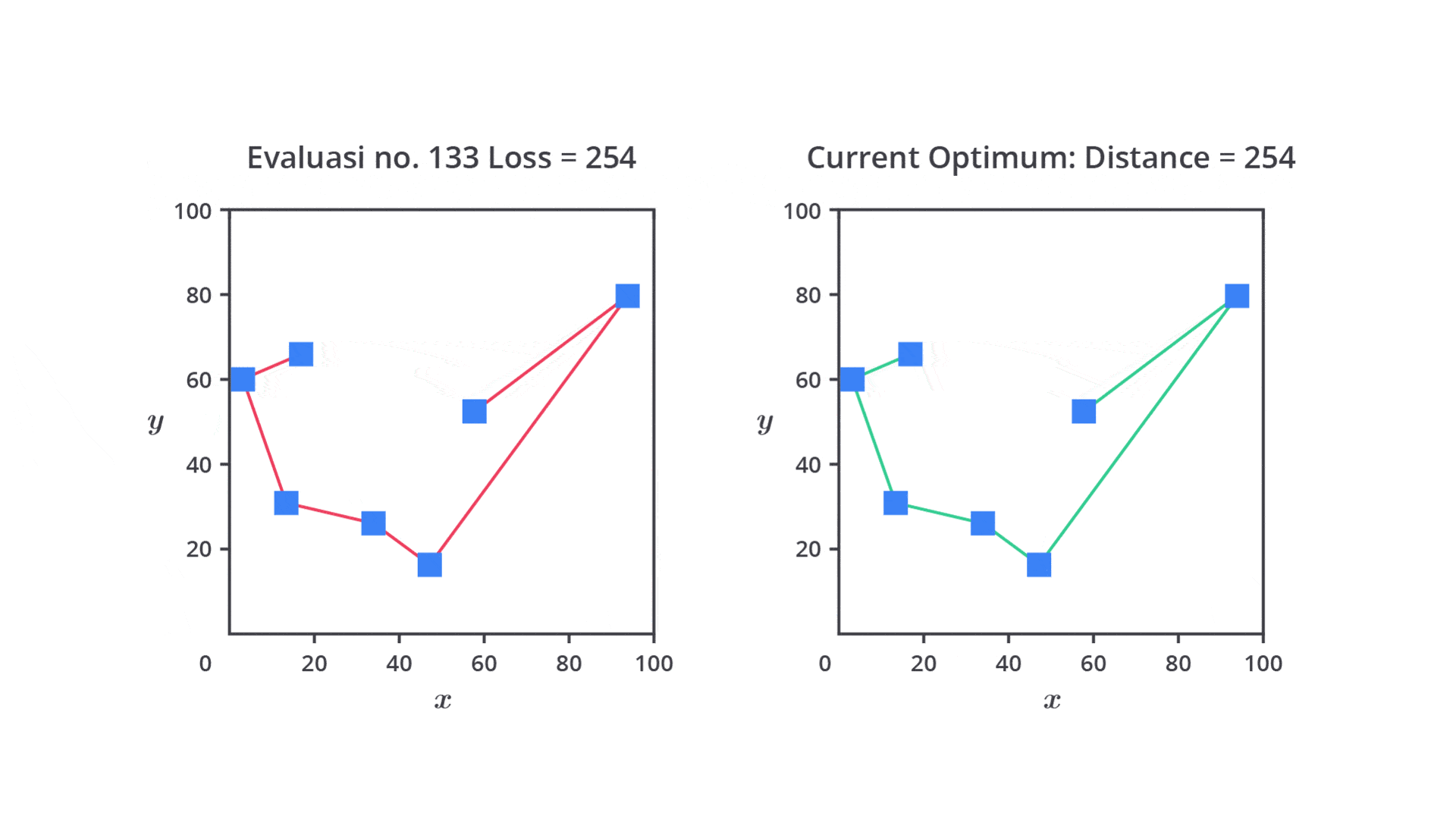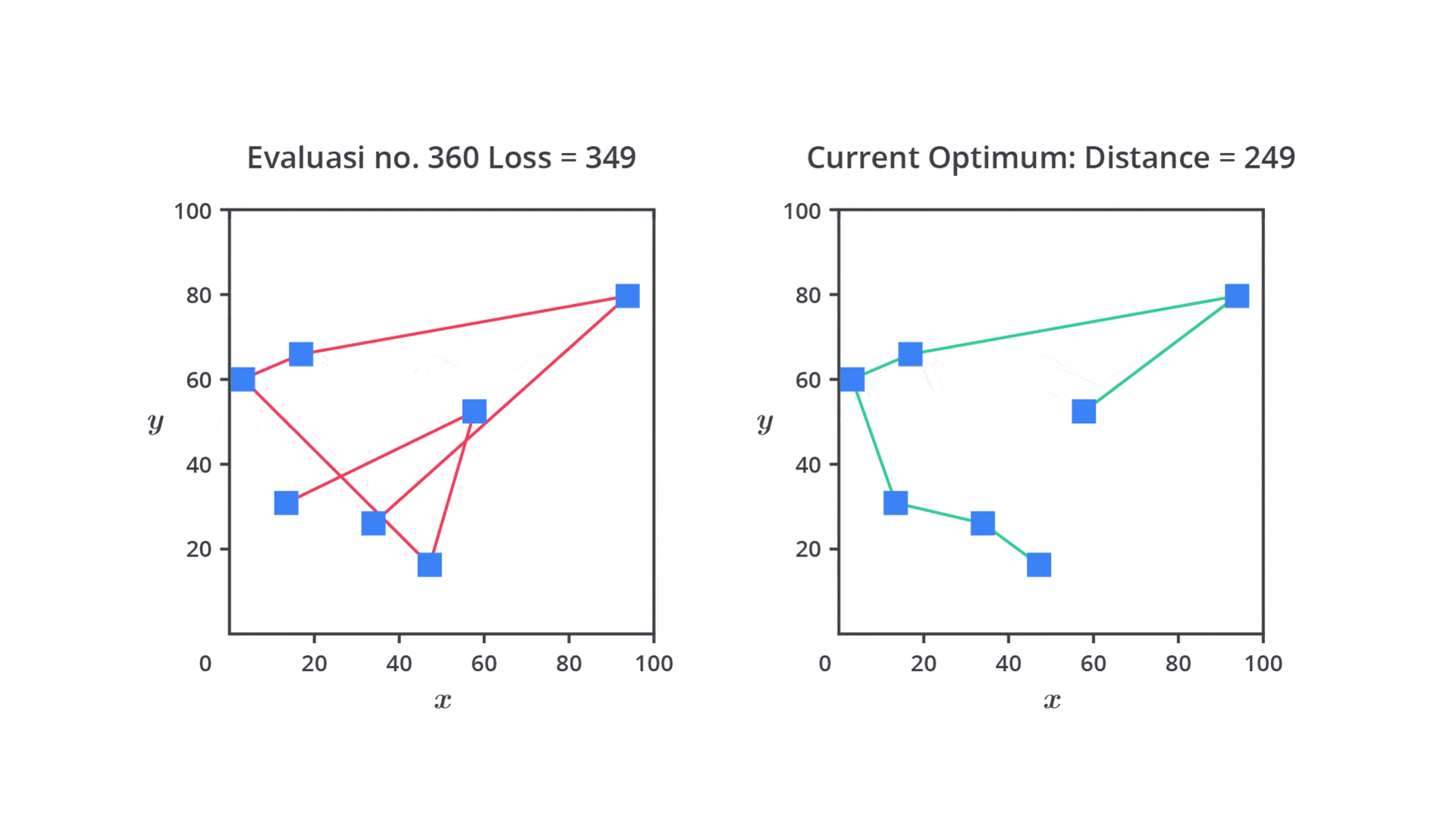
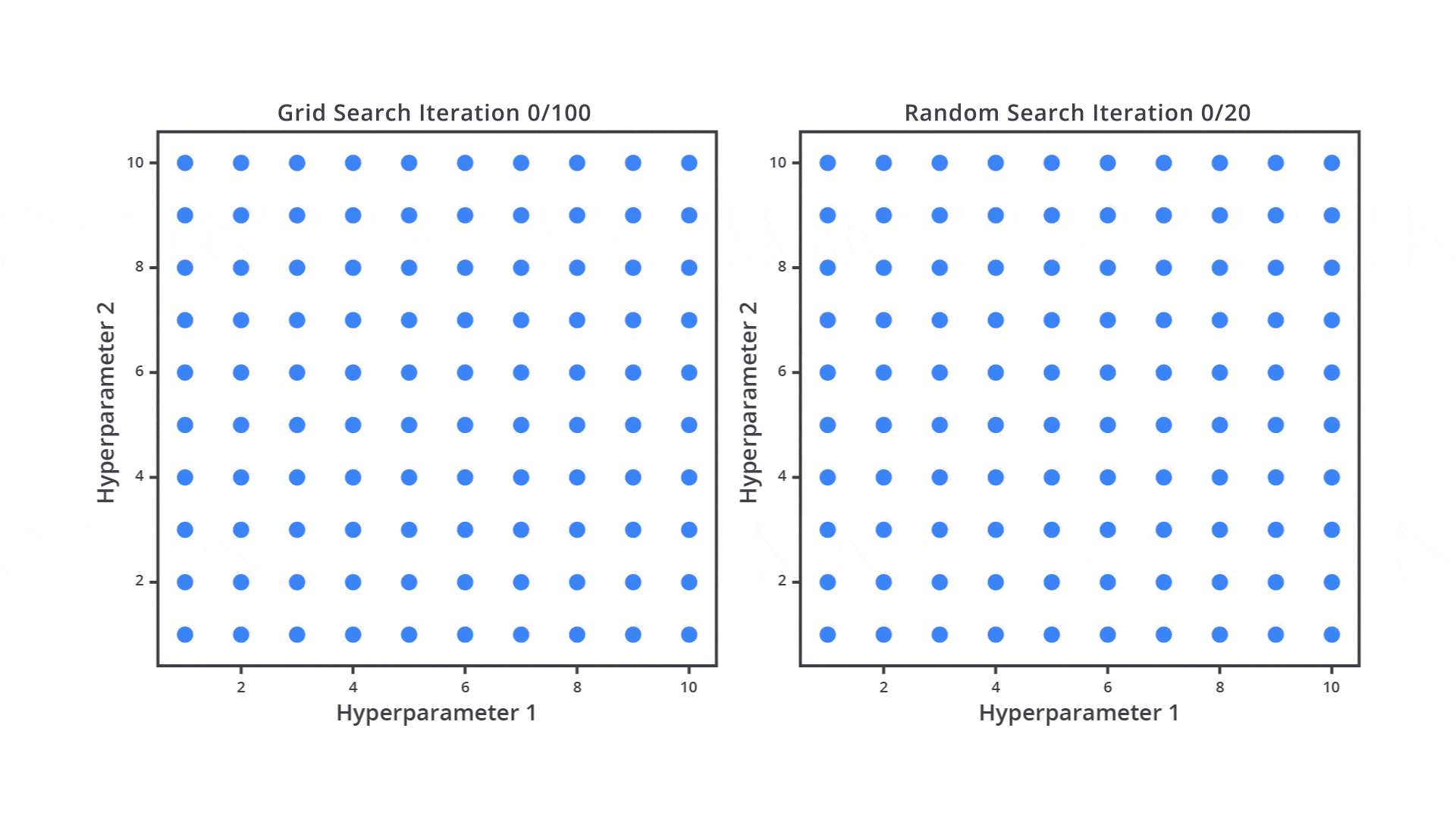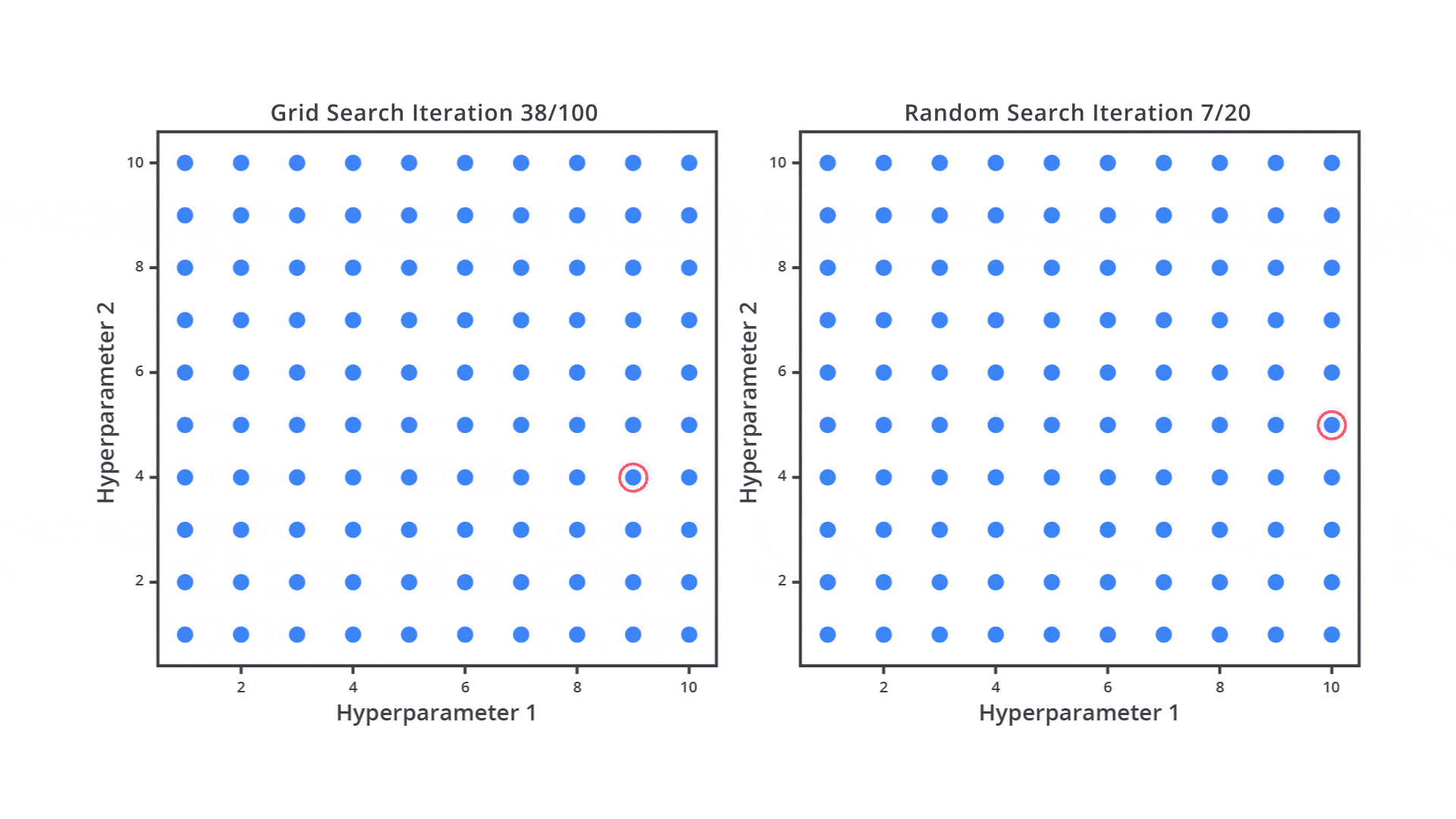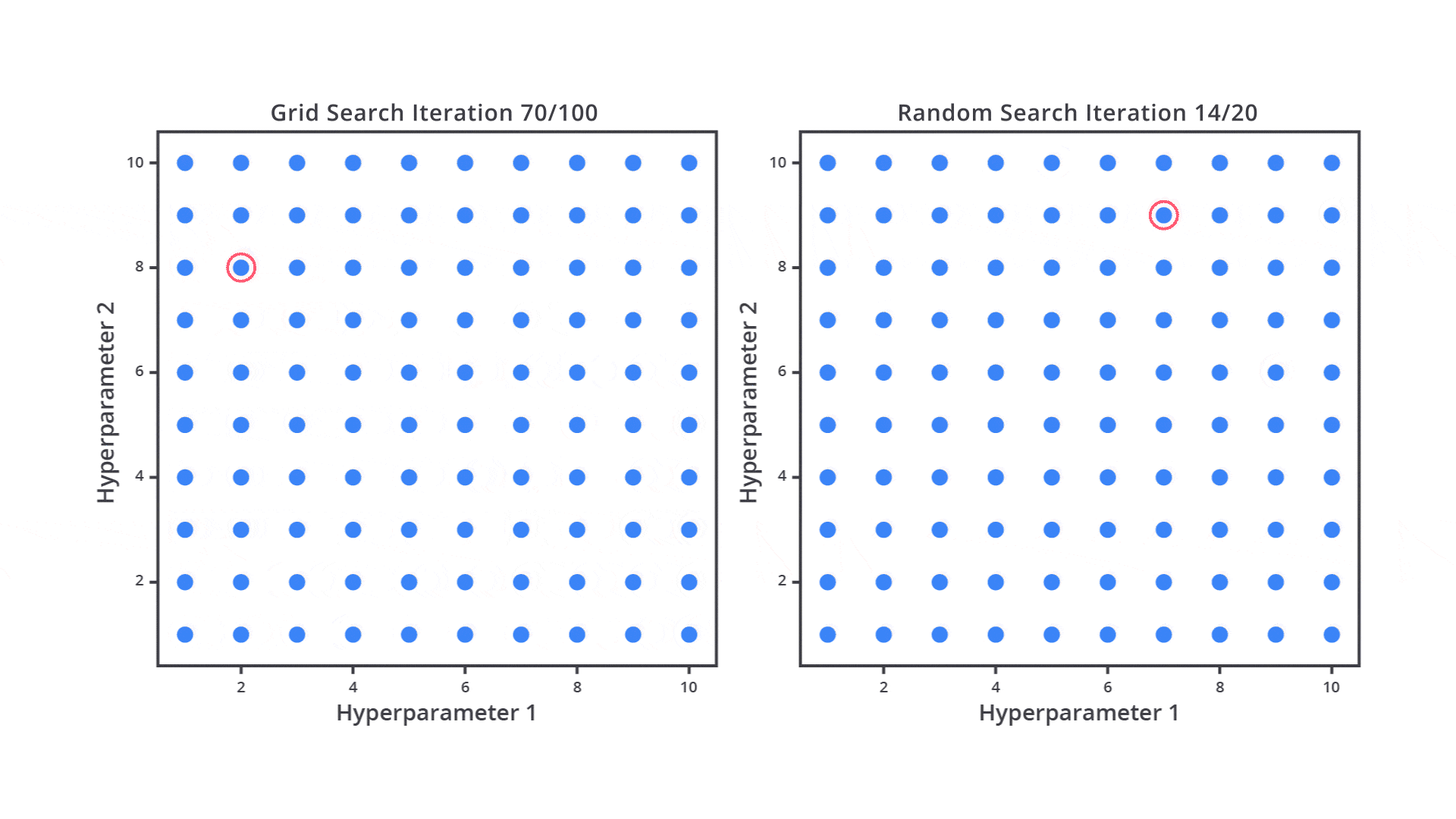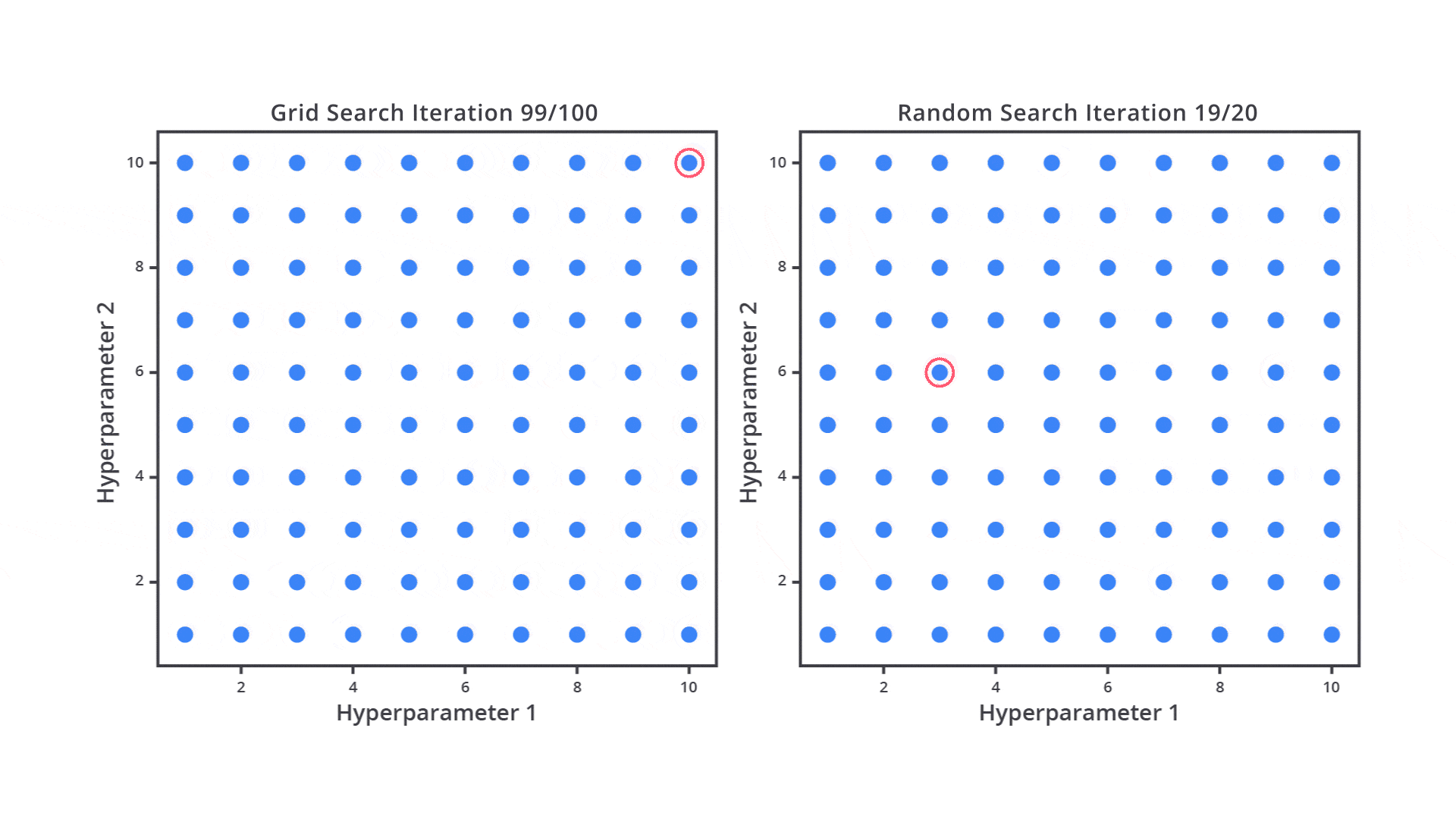
Grid Search adalah salah satu metode hyperparameter tuning yang digunakan untuk menemukan kombinasi hyperparameter optimal pada model machine learning. Grid Search bekerja dengan mencoba semua kombinasi dari nilai hyperparameter yang telah Anda tentukan dan mengevaluasi performa model untuk setiap kombinasi tersebut.
Tujuan dari Grid Search adalah untuk mengidentifikasi set hyperparameter yang menghasilkan performa terbaik berdasarkan metrik evaluasi yang dipilih (misalnya akurasi, F1-score, atau MSE).
Grid Search dikenal karena pendekatannya yang komprehensif, di mana setiap kombinasi hyperparameter akan di coba berurutan tanpa pengaturan manual. Meskipun ini memberikan hasil yang terjamin, tetapi metode ini bisa sangat lambat dan memakan banyak sumber daya saat jumlah pencarian hyperparameter besar.
Metode Grid Search sebenarnya memiliki tahapan yang sederhana layaknya pencarian manual. Alih-alih mengubah satu per satu hyperparameter dan melatih model, Grid Search akan melakukan semua tahapan secara otomatis. Kurang lebih tahapan yang dilakukan Grid Search mencakup hal berikut.
- Menentukan Ruang Hyperparameter: pengguna menentukan hyperparameter yang ingin diatur dan menetapkan rentang nilai untuk setiap hyperparameter. Nilai-nilai ini akan membentuk grid (sebuah "tabel kombinasi" dari semua kemungkinan).
- Mencoba Semua Kombinasi: Grid Search mencoba semua kombinasi hyperparameter yang mungkin, melatih model dengan setiap kombinasi tersebut, dan mengevaluasi performa berdasarkan metrik tertentu.
- Memilih Kombinasi Terbaik: setelah semua kombinasi diuji, Grid Search akan memilih kombinasi hyperparameter yang menghasilkan performa terbaik.
Misalnya, jika Anda memiliki dua hyperparameter yaitu learning rate dan jumlah neuron. Lalu Anda menentukan masing-masing 3 nilai yang ingin diuji seperti data berikut.
- param_grid = {
- 'Learning Rate': [0.01, 0.1, 1],
- 'Jumlah Neuron': [10, 50, 100]
- }
Sehingga, grid search akan menghasilkan 9 kombinasi yang harus diuji kurang lebih seperti berikut.
- Learning Rate = 0.01, Jumlah Neuron = 10
- Learning Rate = 0.01, Jumlah Neuron = 50
- Learning Rate = 0.01, Jumlah Neuron = 100
- Learning Rate = 0.1, Jumlah Neuron = 10
- Learning Rate = 0.1, Jumlah Neuron = 50
- Learning Rate = 0.1, Jumlah Neuron = 100
- Learning Rate = 1, Jumlah Neuron = 10
- Learning Rate = 1, Jumlah Neuron = 50
- Learning Rate = 1, Jumlah Neuron = 100
Berdasarkan seluruh kemungkinan yang dapat terjadi di atas, model machine learning akan menyimpan kombinasi terbaik sehingga Anda tidak perlu melatih model secara manual. Dengan kata lain, metode ini cenderung lebih cocok digunakan ketika memenuhi setidaknya tiga kriteria berikut.
- Ruang hyperparameter relatif kecil. Artinya, jumlah hyperparameter yang perlu disetel tidak terlalu banyak, dan setiap hyperparameter memiliki beberapa nilai yang bisa dicoba.
- Karena Grid Search mencoba semua kombinasi, ini memerlukan waktu dan komputasi yang lebih besar daripada metode lain seperti Random Search. Sehingga, Anda perlu mengalokasikan sumber daya komputasi yang cukup besar.
- Untuk model yang kompleks dengan banyak hyperparameter, metode ini bisa tidak praktis karena waktu pelatihan yang meningkat secara eksponensial dengan jumlah kombinasi hyperparameter.
Tentunya metode ini akan memberikan beberapa keuntungan ketika Anda membangun sebuah model machine learning. Salah satunya karena Grid Search memastikan bahwa setiap kombinasi hyperparameter yang mungkin diuji akan dilatih sehingga kita bisa yakin bahwa tidak ada kombinasi yang terlewat dan memberikan performa yang terbaik. Selain itu, meskipun membutuhkan waktu yang cenderung lebih lama Grid Search sangat mudah digunakan dan diimplementasikan, terutama dengan bantuan library seperti Scikit-learn.
Namun, di dunia ini tidak ada yang sempurna begitu juga dengan metode ini. Seperti yang sudah Anda ketahui bahwa Grid Search membutuhkan komputasi yang cukup besar dan waktu yang cenderung lebih lama terutama jika ruang pencarian hyperparameter luas dan model yang digunakan sangat kompleks. Di lain sisi, metode ini juga memiliki risiko overfitting ketika Anda terlalu banyak menguji kombinasi hyperparameter yang berbeda pada dataset pelatihan karena model bisa saja membuat pola yang terlalu cocok dengan data pelatihan.
Berdasarkan kekurangan tersebut maka bisa kita simpulkan bahwa metode ini kurang efisien jika memiliki jumlah hyperparameter yang banyak. Misalnya, jika ada 3 hyperparameter yang masing-masing memiliki 10 nilai, ini berarti 1000 kombinasi yang harus diuji. Proses ini bisa memakan banyak waktu dan sumber daya, terlebih jika Anda tidak memiliki komputer yang memadai.
Sampai di sini, Anda sudah memahami salah satu metode untuk melakukan hyperparameter tuning. Bagaimana sangat menarik ‘kan? Harapannya dengan memahami bagaimana Grid Search bekerja dan kapan sebaiknya digunakan, Anda dapat mengoptimalkan model machine learning secara lebih efektif untuk meningkatkan performa tanpa perlu mencoba hyperparameter secara manual.
Random Search
Random Search adalah salah satu metode hyperparameter tuning yang cenderung lebih efisien dibandingkan Grid Search. Alih-alih mencoba semua kombinasi hyperparameter seperti dalam Grid Search, Random Search memilih beberapa kombinasi hyperparameter secara acak dari ruang pencarian yang sudah ditentukan. Proses ini memungkinkan model untuk diuji dengan kombinasi acak yang dipilih secara independen untuk setiap iterasi.
Tujuan Random Search adalah menghemat waktu dan sumber daya dengan tetap melatih sejumlah kombinasi yang cukup representatif dari ruang pencarian, tanpa perlu menguji semua kombinasi yang mungkin terjadi.
Berbeda dari Grid Search yang mencoba semua kombinasi hyperparameter, Random Search hanya memilih sejumlah kombinasi yang dipilih secara acak dari ruang pencarian hyperparameter. Ini berarti kita menentukan jumlah iterasi (kombinasi) yang ingin dicoba, dan setiap iterasi memilih satu set hyperparameter secara acak.
Misalnya, jika Anda memiliki dua hyperparameter, learning rate dan jumlah neuron, Anda bisa mendefinisikan ruang pencarian yang besar tanpa perlu mengatur nilainya satu per satu. Random Search kemudian memilih beberapa kombinasi secara acak dan menguji model untuk setiap kombinasi tersebut.
Mari kita asumsikan Anda memiliki tiga buah hyperparameter yaitu C, gamma, dan kernel dengan ketentuan seperti berikut.
- param_dist = {
- 'C': np.logspace(-2, 2, 10), # C = 0.01 sampai 100
- 'gamma': np.logspace(-4, 1, 10), # Gamma = 0.0001 sampai 10
- 'kernel': ['rbf'] # Kernel tetap menggunakan 'rbf'
- }
Rentang nilai C didefinisikan sebagai logaritmik menggunakan np.logspace(-2, 2, 10), yang berarti kita mencari nilai C dalam rentang dari 10-2 hingga 102. Nilai tersebut akan menghasilkan 10 nilai yang dipilih dalam rentang logaritmik dari 0.01 hingga 100. Nilai yang mungkin untuk C adalah [0.01, 0.027, 0.072, 0.193, 0.52, 1.38, 3.59, 9.33, 24.59, 100.0].
Gamma juga didefinisikan dalam rentang logaritmik menggunakan np.logspace(-4, 1, 10), yang berarti nilai gamma akan berkisar dari 10-4 hingga 101. Nilai yang mungkin untuk gamma adalah [0.0001, 0.000278, 0.000774, 0.00215, 0.00599, 0.01668, 0.04642, 0.12915, 0.35938, 10.0]
Terakhir hanya ada satu nilai untuk kernel, yaitu ‘rbf’. Jadi, kernel selalu akan menggunakan Radial Basis Function (RBF) yang merupakan jenis kernel yang populer untuk SVM (algoritma yang akan kita coba pada kasus ini).
Jika Anda perhatikan saat ini Anda memiliki 100 kombinasi yang terdiri dari C dan gamma masing-masing memiliki 10 nilai. Dari mana 100 kombinasi tersebut didapat? Tenang, Anda dapat menghitung jumlah kombinasi dengan sederhana menggunakan rumus berikut.
Total Kombinasi = Jumlah Nilai C * Jumlah Nilai Gamma * Jumlah Nilai Kernel Total Kombinasi = 10 * 10 * 1 Total Kombinasi = 100 |
Dengan menggunakan Random Search komputer tidak mencoba semua kombinasi seperti yang dilakukan pada Grid Search. Sebaliknya, kita menentukan berapa banyak kombinasi yang ingin diuji. Salah satunya dengan menentukan nilai parameter n_iter dalam RandomizedSearchCV. Sehingga, setiap iterasi dalam Random Search memilih satu kombinasi hyperparameter secara acak dari ruang pencarian yang tersedia.
Misalnya, jika Anda menetapkan n_iter=10, Random Search akan secara acak memilih 10 kombinasi dari total 100 kombinasi yang mungkin terjadi di ruang pencarian. Tidak semua kombinasi akan dicoba sehingga kita bisa menghemat waktu komputasi.
Dari penjelasan di atas, tentunya sudah terlihat jelas kan salah satu kelebihan dari Random Search ini? Agar kita memiliki pemahaman yang sama, mari kita bahas bersama beberapa kelebihan Random Search.
- Efisiensi Waktu: pada penggunaan Grid Search komputer akan menguji semua kombinasi. Namun, dengan Random Search, Anda bisa menentukan untuk mencoba sebagian dari kombinasi tersebut misalnya 10, 20, 30, atau x kombinasi.
- Kecepatan Komputasi: Random Search lebih cepat jika waktu dan sumber daya komputasi terbatas, karena kita hanya mencoba sejumlah iterasi yang sudah ditetapkan.
- Fleksibilitas: kita dapat mengontrol seberapa banyak kombinasi yang ingin diuji tanpa perlu menguji setiap kemungkinan kombinasi sehingga bisa menghemat waktu. Kekurangannya, Anda bisa saja kehilangan peluang untuk menemukan kombinasi hyperparameter terbaik.
Meskipun lebih cepat dan efisien daripada Grid Search, Random Search juga memiliki keterbatasan seperti berikut.
- Tidak Menjamin Hasil Terbaik: karena hanya beberapa kombinasi yang diuji, tidak ada jaminan bahwa Random Search akan menemukan kombinasi hyperparameter terbaik.
- Ketergantungan pada Jumlah Iterasi: semakin sedikit iterasi yang dilakukan, semakin kecil kemungkinan Random Search menemukan hyperparameter yang optimal. Jika n_iter terlalu kecil, kemungkinan mendapatkan hasil suboptimal lebih besar.
Berangkat dari kekurangan dan kelebihan Random Search di atas, kita tidak bisa menggunakan salah satu metode hyperparameter tuning untuk seluruh proyek yang sedang dibangun. Jika kita bandingkan secara garis besar, perbedaan dari Grid Search dan Random Search dapat disimpulkan sebagai berikut.

Walaupun Random Search membutuhkan komputasi yang lebih ringan, terkadang untuk beberapa kasus tertentu seperti skripsi Anda perlu menggunakan Grid Search. Hal itu karena ketika menulis thesis, Anda perlu mendapatkan performa terbaik dari penelitian sebelumnya atau penelitian baru yang sedang dilakukan.
Dengan menggunakan Grid Search Anda akan lebih mudah menemukan kombinasi hyperparameter terbaik pada algoritma yang digunakan. Dengan begitu, Anda bisa menjawab dengan yakin bahwa model machine learning yang dibangun sudah optimal dan memiliki performa terbaik.
Namun, perlu Anda ingat contoh di atas hanya salah satu dari berbagai kasus yang biasa terjadi. Oleh karena itu, Anda perlu menentukan sendiri metode yang paling relevan dengan studi kasus dan objektif yang akan dicapai.
Anyway, jangan overthinking memikirkan kedua metode tersebut, ya. Pada materi berikutnya, kita akan mempelajari salah satu metode yang memiliki beberapa kelebihan signifikan dibandingkan dengan Grid Search dan Random Search dalam proses hyperparameter tuning. Penasaran dengan metode tersebut? Kuy, tanpa berlama-lama lagi, mari kita melangkah ke materi berikutnya, yaitu Bayesian Optimization.
Bayesian Optimization
Bayesian Optimization adalah salah satu teknik hyperparameter tuning yang efisien dan kompleks. Metode ini digunakan untuk menemukan kombinasi hyperparameter yang optimal dengan melakukan lebih sedikit percobaan dibandingkan Grid Search atau Random Search.
Bayesian Optimization sangat berguna untuk masalah yang memerlukan tuning hyperparameter pada ruang pencarian yang besar, di mana mencoba semua kombinasi hyperparameter akan sangat tidak efisien dan memakan waktu.
Bayesian Optimization tidak melakukan pencarian secara acak atau mencoba semua kombinasi, melainkan menggunakan pendekatan probabilistik untuk secara cermat memilih kombinasi hyperparameter yang paling mungkin memberikan hasil terbaik berdasarkan percobaan sebelumnya. Dengan demikian, metode ini sangat efektif dalam mengurangi jumlah percobaan yang diperlukan untuk menemukan hyperparameter terbaik.
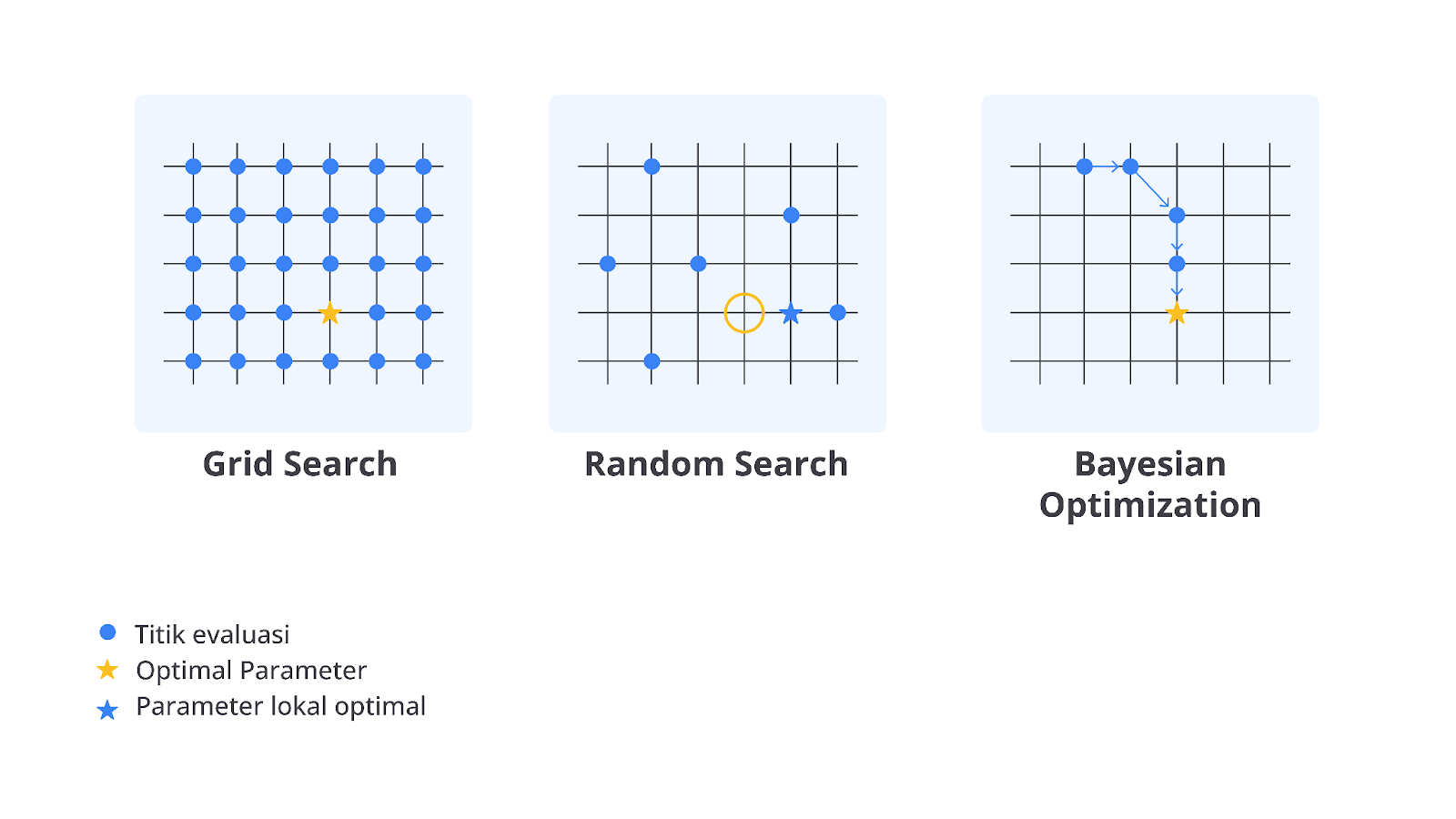
Bayesian Optimization bekerja dengan membangun model probabilistik dari fungsi objektif yang ingin kita optimalkan, misalnya akurasi model atau nilai error. Model probabilistik ini digunakan untuk memperkirakan bagaimana performa model akan berubah dengan kombinasi hyperparameter yang berbeda. Bayesian Optimization kemudian menggunakan prediksi ini untuk memilih kombinasi hyperparameter berikutnya yang memiliki performa lebih baik.
Alih-alih mencoba kombinasi hyperparameter secara acak, Bayesian Optimization menggunakan pendekatan berdasarkan data. Metode ini memanfaatkan informasi dari percobaan sebelumnya untuk terus memperbaiki pencarian sehingga hanya kombinasi terbaik yang diuji.
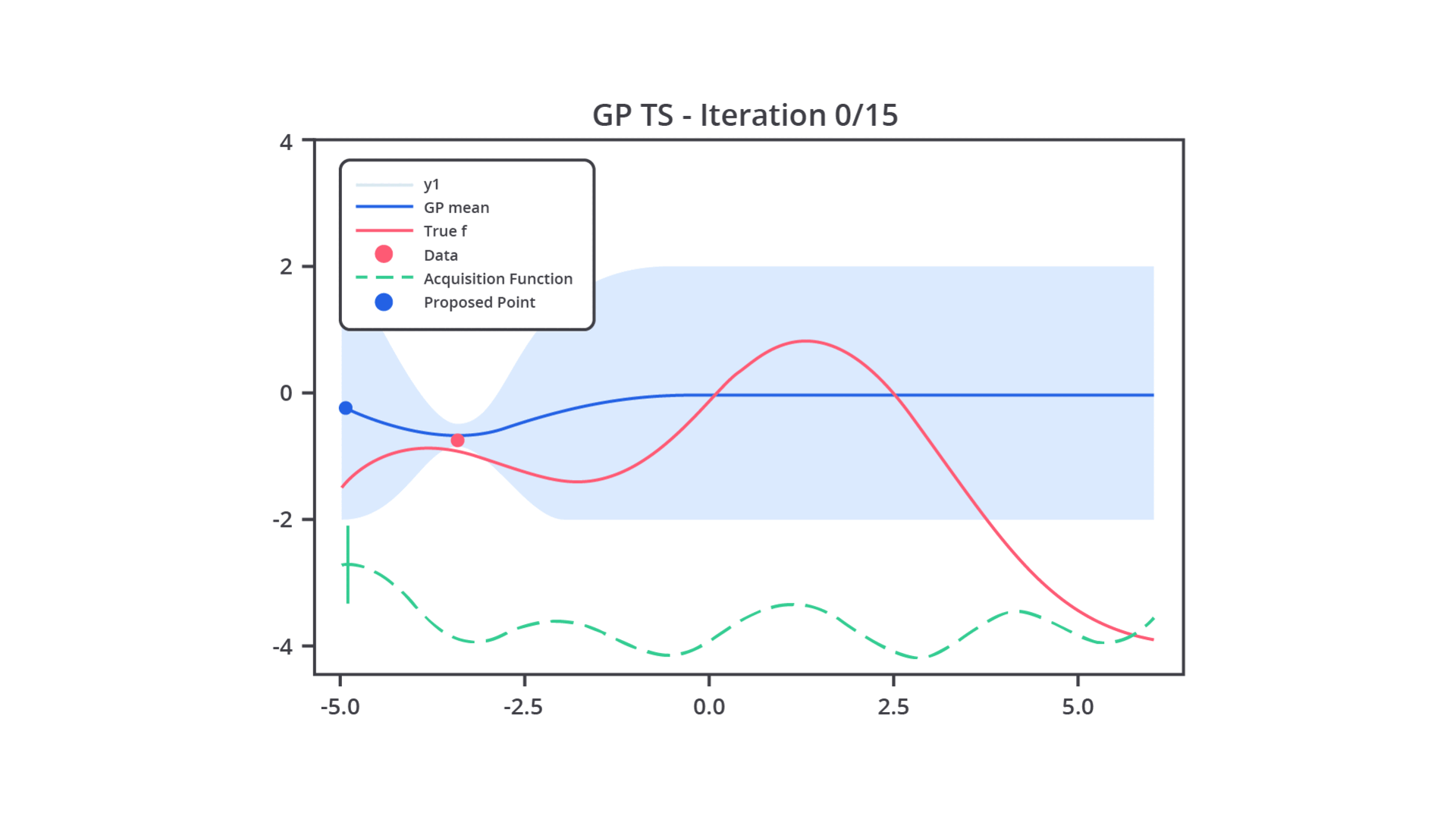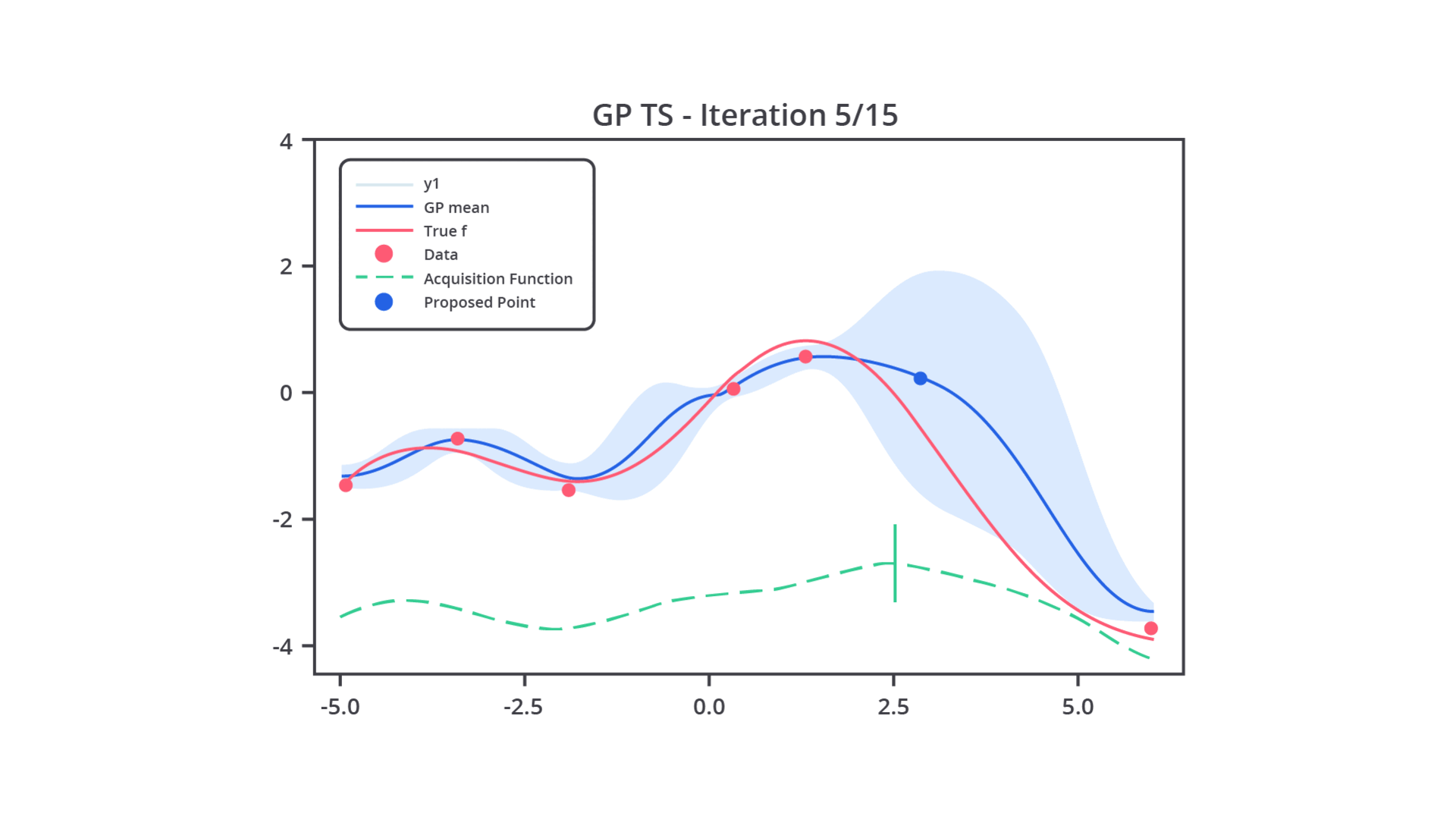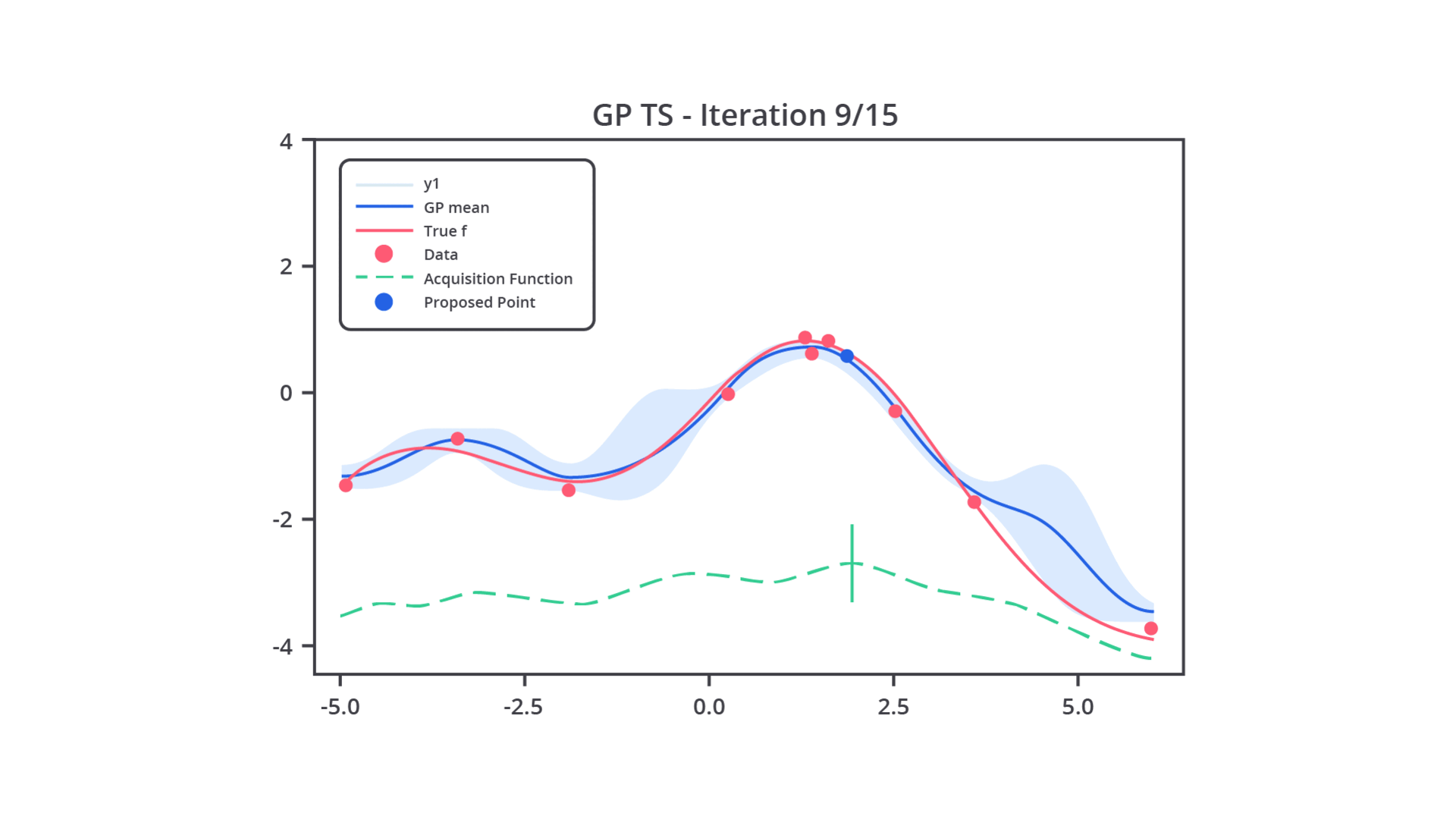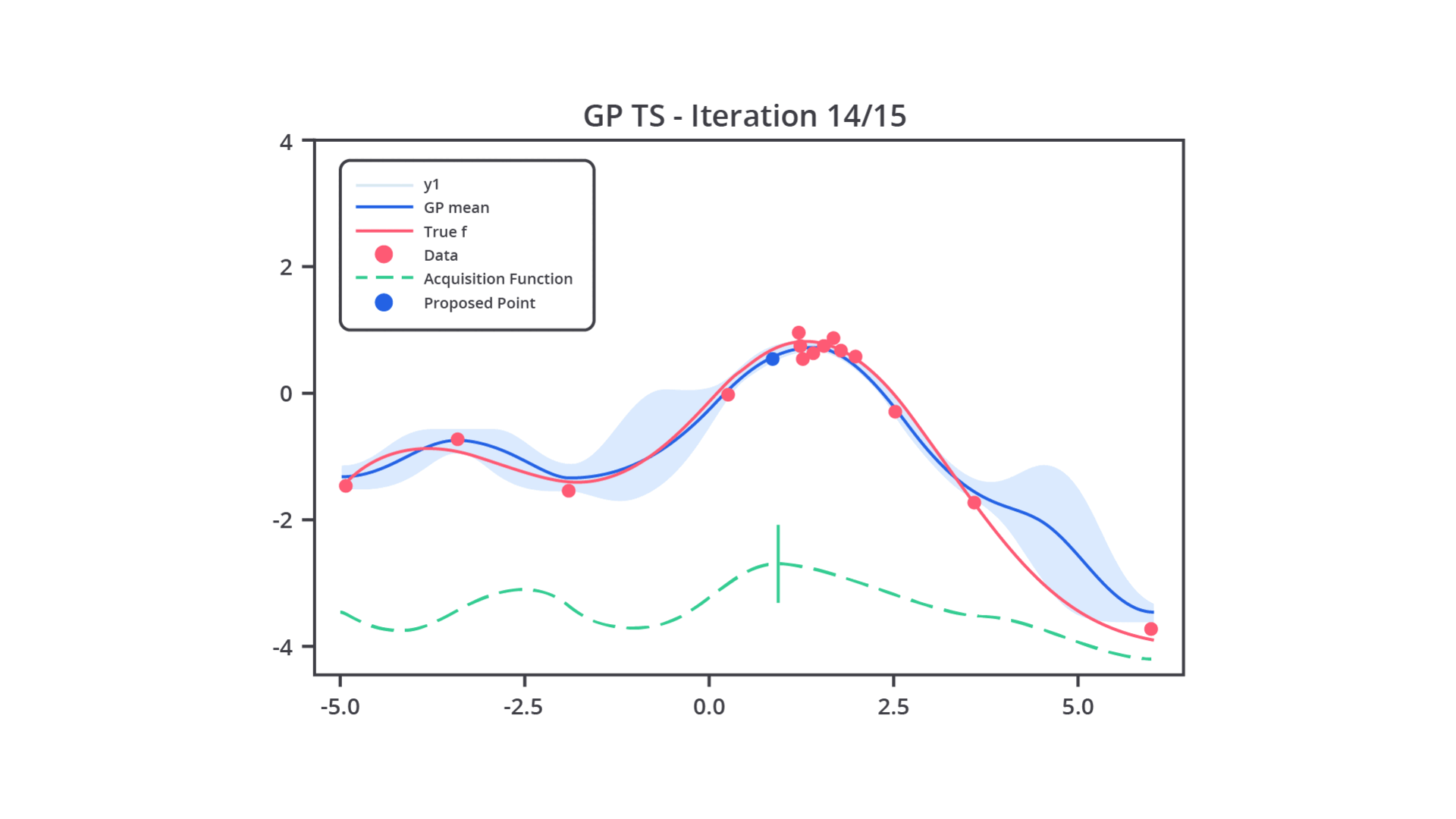
Pada intinya, Bayesian Optimization menggunakan model probabilistik yang disebut surrogate model untuk memperkirakan fungsi objektif yang tidak diketahui. Model surrogate biasanya adalah Gaussian Process (GP) atau kadang Random Forest. Fungsi ini digunakan karena evaluasi langsung dari fungsi objektif bisa sangat mahal secara komputasi.
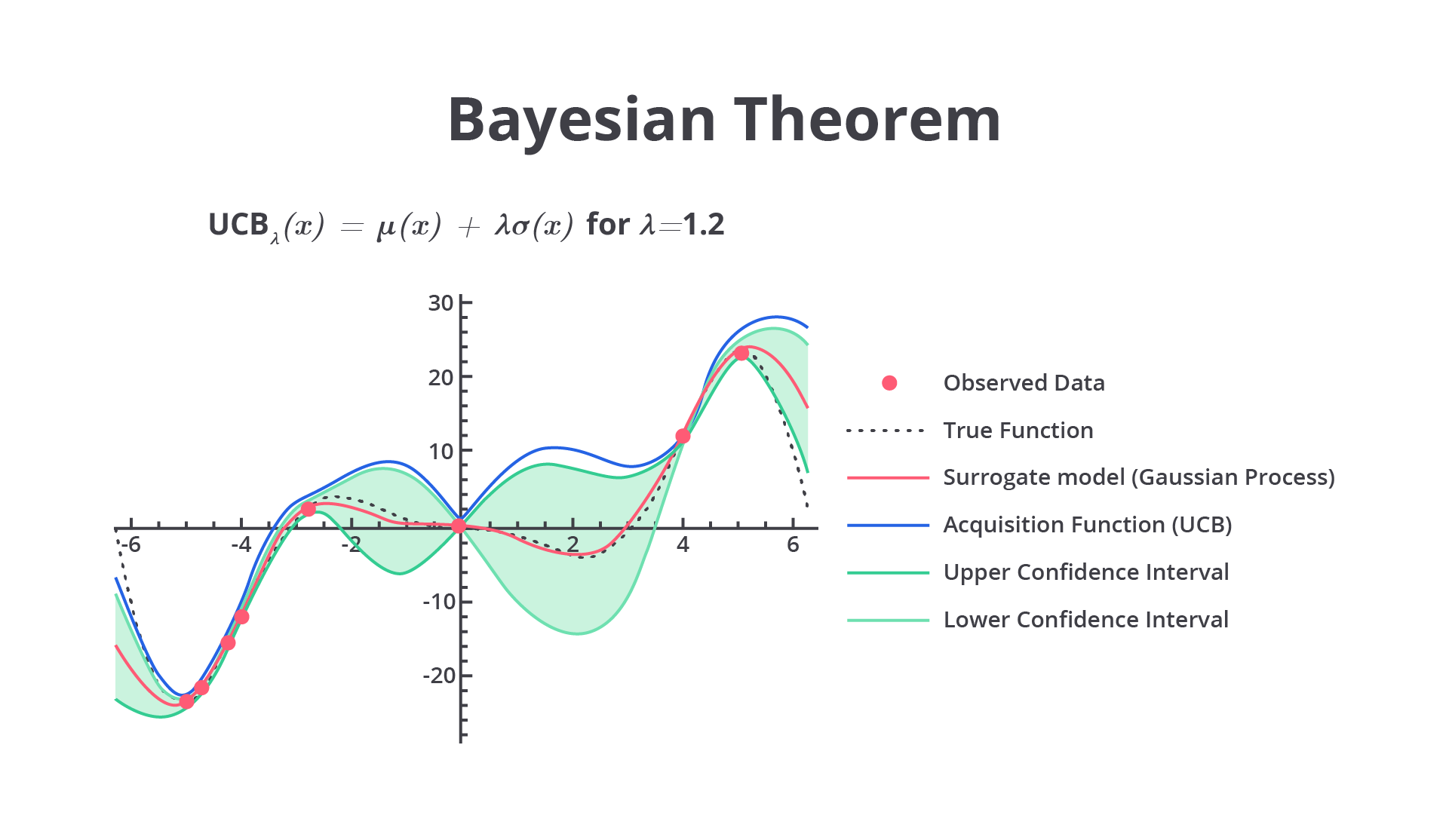
Setelah model probabilistik dibangun, Bayesian Optimization menggunakan fungsi akuisisi untuk menentukan hyperparameter mana yang akan diuji pada iterasi berikutnya. Fungsi akuisisi menentukan trade-off antara eksploitasi dan eksplorasi. Mari kita bahas sedikit terkait kedua nilai trade-off tersebut.
- Eksploitasi: mencoba kombinasi hyperparameter yang sudah diketahui memberikan hasil yang baik (berdasarkan model probabilistik).
- Eksplorasi: mencoba kombinasi hyperparameter baru yang belum pernah diuji sebelumnya.
Fungsi akuisisi mengukur potensi performa dengan cara menguji hyperparameter baru menggunakan estimasi dari model probabilistik. Secara umum terdapat tiga fungsi akuisisi yang biasa digunakan yaitu Expected Improvement, Probability of Improvement, dan Upper Confidence Bound.
- Expected Improvement (EI): mengukur ekspektasi peningkatan performa model.
- Probability of Improvement (PI): mengukur probabilitas bahwa percobaan berikutnya akan meningkatkan kinerja.
- Upper Confidence Bound (UCB): menggabungkan perkiraan performa dan kesalahan untuk mengeksplorasi dan mengeksploitasi secara bersamaan.
Setelah Anda menentukan fungsi akuisisi yang akan digunakan, Bayesian Optimization akan menerapkan fungsi tersebut untuk menentukan hyperparameter berikutnya yang akan diuji. Kombinasi hyperparameter ini dipilih berdasarkan estimasi dari model probabilistik (Gaussian Process) yang dibangun dari percobaan sebelumnya.
Lalu, apa kelebihan metode ini? Tenang, pada tahap ini Anda akan memahami kelebihan utama dari metode ini. Pada metode ini, setiap kali sebuah kombinasi hyperparameter baru diuji, hasil dari percobaan tersebut akan digunakan untuk memperbarui model probabilistik (Gaussian Process). Hal ini memastikan bahwa model terus belajar dari setiap percobaan dan dapat memberikan estimasi yang lebih baik pada iterasi berikutnya.
Proses ini berulang hingga tercapai jumlah percobaan yang diinginkan atau performa model sudah tidak mengalami peningkatan yang signifikan.
Sedari tadi kita membahas dan menyebutkan Gaussian Process, tetapi tahukah Anda apa itu Gaussian Process? Gaussian Process (GP) adalah model yang digunakan untuk memperkirakan hubungan antara hyperparameter dan kinerja model. Gaussian Process menghasilkan distribusi probabilistik dari fungsi yang diperkirakan, bukan hanya nilai tunggal.
Setiap kali kita memberikan input (kombinasi hyperparameter), Gaussian Process memperkirakan distribusi kemungkinan nilai keluaran dan kesalahan terkait.
Ini memungkinkan Gaussian Process untuk memperhitungkan kesalahan dalam prediksinya. Jika kesalahan tinggi, fungsi akuisisi mungkin memilih untuk mengeksplorasi kombinasi baru untuk mengurangi kesalahan tersebut.
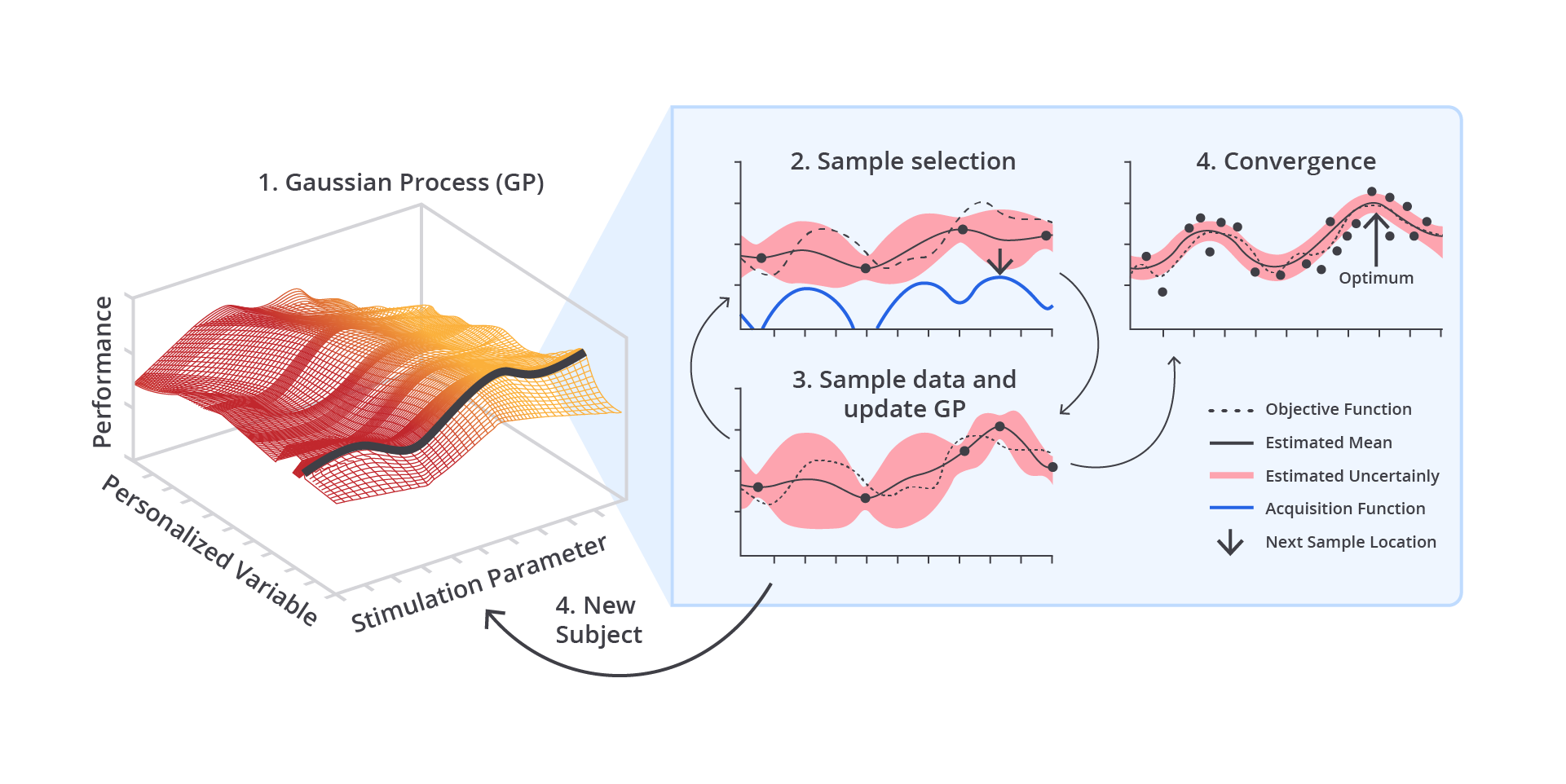
Jika dibandingkan dengan Grid Search dan Random Search, metode ini memiliki beragam kelebihan yang dapat Anda pertimbangkan ketika memilih metode optimasi model machine learning.
- Efisiensi Komputasi
Seperti yang Anda tahu bahwa metode ini sangat efisien dalam menemukan hyperparameter optimal, terutama untuk ruang pencarian yang besar. Dibandingkan dengan Grid Search yang memerlukan evaluasi setiap kombinasi dan Random Search yang memilih kombinasi secara acak, Bayesian Optimization secara otomatis memilih kombinasi terbaik berdasarkan hasil percobaan sebelumnya. Ini mengurangi jumlah percobaan yang diperlukan untuk menemukan hyperparameter terbaik.
- Memanfaatkan Informasi dari Percobaan Sebelumnya
Tidak seperti Random Search yang mengabaikan hasil percobaan sebelumnya, Bayesian Optimization menggunakan model probabilistik yang diperbarui pada setiap iterasi. Setiap percobaan baru menambah informasi yang digunakan untuk memprediksi kombinasi hyperparameter berikutnya, sehingga pencarian lebih terarah.
- Fleksibel untuk Ruang Pencarian Kompleks
Karena metode ini memanfaatkan model probabilistik untuk memperkirakan hasil, ia dapat mengeksplorasi dan mengeksploitasi ruang pencarian dengan lebih efisien.
- Kemampuan Menangani Ketidakpastian
Dengan menggunakan Gaussian Process, Bayesian Optimization tidak hanya memberikan perkiraan nilai kinerja model, tetapi juga membantu mengurangi kesalahan dalam prediksi. Hal ini memungkinkan algoritma untuk secara otomatis mengeksplorasi area ruang pencarian yang belum pasti sehingga dapat memberikan peningkatan kinerja yang signifikan.
Namun, seperti metode lainnya yang memiliki kekurangan, Bayesian Optimization juga tak luput dari kekurangan. Dengan metode yang powerful, bukan berarti Anda juga bisa menggunakan Bayesian Optimization terhadap semua kasus yang dihadapi. Berikut beberapa kekurangan dari metode ini.
- Kompleksitas Implementasi
Gaussian Process yang sering digunakan sebagai model probabilistik memerlukan pengetahuan teknis yang lebih dalam untuk diimplementasikan dengan benar, terutama pada ruang pencarian yang besar.
- Waktu Komputasi untuk Gaussian Process
Walaupun Bayesian Optimization membutuhkan lebih sedikit percobaan secara keseluruhan, waktu komputasi untuk membangun dan memperbarui model Gaussian Process bisa meningkat ketika jumlah hyperparameter dan datanya juga meningkat. Ini bisa menjadi kendala jika ruang pencarian terlalu besar atau terlalu banyak data yang harus diproses.
- Efisiensi Berkurang untuk Hyperparameter dalam Dimensi Tinggi
Untuk masalah dengan dimensi hyperparameter yang sangat tinggi, Bayesian Optimization bisa menjadi kurang efisien karena model probabilistik cenderung bekerja lebih baik pada ruang pencarian yang lebih kecil atau dengan dimensi yang lebih rendah. Dalam kasus seperti ini, metode lain seperti Random Search mungkin lebih cocok.
Sampai di sini, Anda sudah mengetahui kelebihan serta kekurangan dari metode ketiga yaitu Bayesian Optimization.
Meskipun lebih kompleks dalam hal implementasi, keunggulannya dalam efisiensi komputasi dan waktu membuatnya menjadi pilihan yang sangat baik untuk masalah tuning hyperparameter pada model yang kompleks. Kedepannya, Anda perlu menentukan sendiri metode mana yang cocok dengan kasus yang sedang dihadapi.
Hufftt, akhirnya Anda selesai mempelajari berbagai macam metode hyperparameter tuning dengan lancar. Mungkin setelah ini tebersit sebuah pertanyaan di benak Anda, “Lalu, bagaimana cara kita mengevaluasi model machine learning setelah melakukan hyperparameter tuning?” Pertanyaan yang bagus karena selanjutnya kita akan mengulas materi evaluasi model machine learning untuk membedakan model dasar dengan model yang telah melalui proses hyperparameter tuning.
Evaluasi Model setelah Hyperparameter Tuning
Setelah proses hyperparameter tuning selesai dan kita telah menemukan kombinasi hyperparameter optimal, langkah berikutnya yang sangat penting adalah melakukan evaluasi model. Evaluasi model bertujuan untuk mengukur performa model setelah tuning dilakukan dan memastikan bahwa model menggeneralisasi dengan baik pada data baru (data yang belum pernah dilihat oleh model). Evaluasi ini tidak hanya mengukur akurasi atau performa di data pelatihan, tetapi juga kemampuan model dalam memprediksi hasil pada data pengujian.
Pada materi ini, kita akan membahas tujuan evaluasi, metrik evaluasi umum, teknik evaluasi yang sering digunakan, dan bagaimana memastikan bahwa model tidak overfitting setelah tuning hyperparameter.
Selain bertujuan mengetahui performa model terdapat dua objektif atau tujuan yang membuat proses evaluasi menjadi sangat penting yaitu menguji generalisasi model dan memastikan model tidak overfitting atau underfitting.
Model harus diuji pada data baru (data uji) untuk memastikan bahwa model tidak hanya bekerja baik pada data latih tetapi juga dapat menggeneralisasi dengan baik pada data yang belum pernah dilihat. Selain itu, evaluasi bertugas untuk memastikan model tidak overfitting atau underfitting: Hyperparameter tuning yang buruk dapat menyebabkan model overfitting (terlalu cocok dengan data latih dan berkinerja buruk pada data uji) atau underfitting (tidak mampu menangkap pola dalam data latih maupun data uji).
Secara umum evaluasi model machine learning dapat dilakukan terhadap dua data yaitu data training dan data testing.
- Data Latih (Training Data): data yang digunakan untuk melatih model. Evaluasi pada data latih menunjukkan seberapa baik model belajar dari data ini.
- Data Uji (Testing Data): data yang tidak digunakan selama pelatihan, yang digunakan untuk mengevaluasi generalisasi model. Evaluasi pada data uji menunjukkan seberapa baik model mampu bekerja pada data baru yang tidak pernah dilihat.
Lalu, bagaimana cara kita menguji model machine learning terhadap dua data tersebut? Cara paling umum yang biasa dilakukan yaitu dengan menggunakan train_test_split. Teknik ini akan membagi data menjadi dua bagian yaitu training set dan testing set.
Model dilatih pada training set, kemudian performanya diuji pada testing set. Ini adalah teknik evaluasi yang paling sederhana tetapi bisa menghasilkan hasil yang lebih variatif, terutama jika dataset kecil. Kekurangannya, Anda perlu mengatur proporsi data secara manual walaupun terdapat rule of thumb atau nilai rekomendasi yaitu 80% untuk data latih dan 20% untuk data uji. Sayangnya, angka tersebut bukanlah angka pasti yang dapat Anda gunakan terhadap seluruh permasalahan pada machine learning.
Selain menggunakan train_test_split, Scikit Learn memiliki sebuah fungsi lain yang dapat membantu proses evaluasi mampu memberikan informasi performa dengan lebih baik yaitu cross-validation atau K-fold cross-validation. cross-validation adalah metode pembagian dataset menjadi beberapa subset (folds). Model dilatih pada sebagian dari subset ini dan diuji pada subset yang tersisa. Proses ini diulang hingga setiap subset digunakan sebagai set uji, dan hasil akhirnya adalah rata-rata dari semua evaluasi.
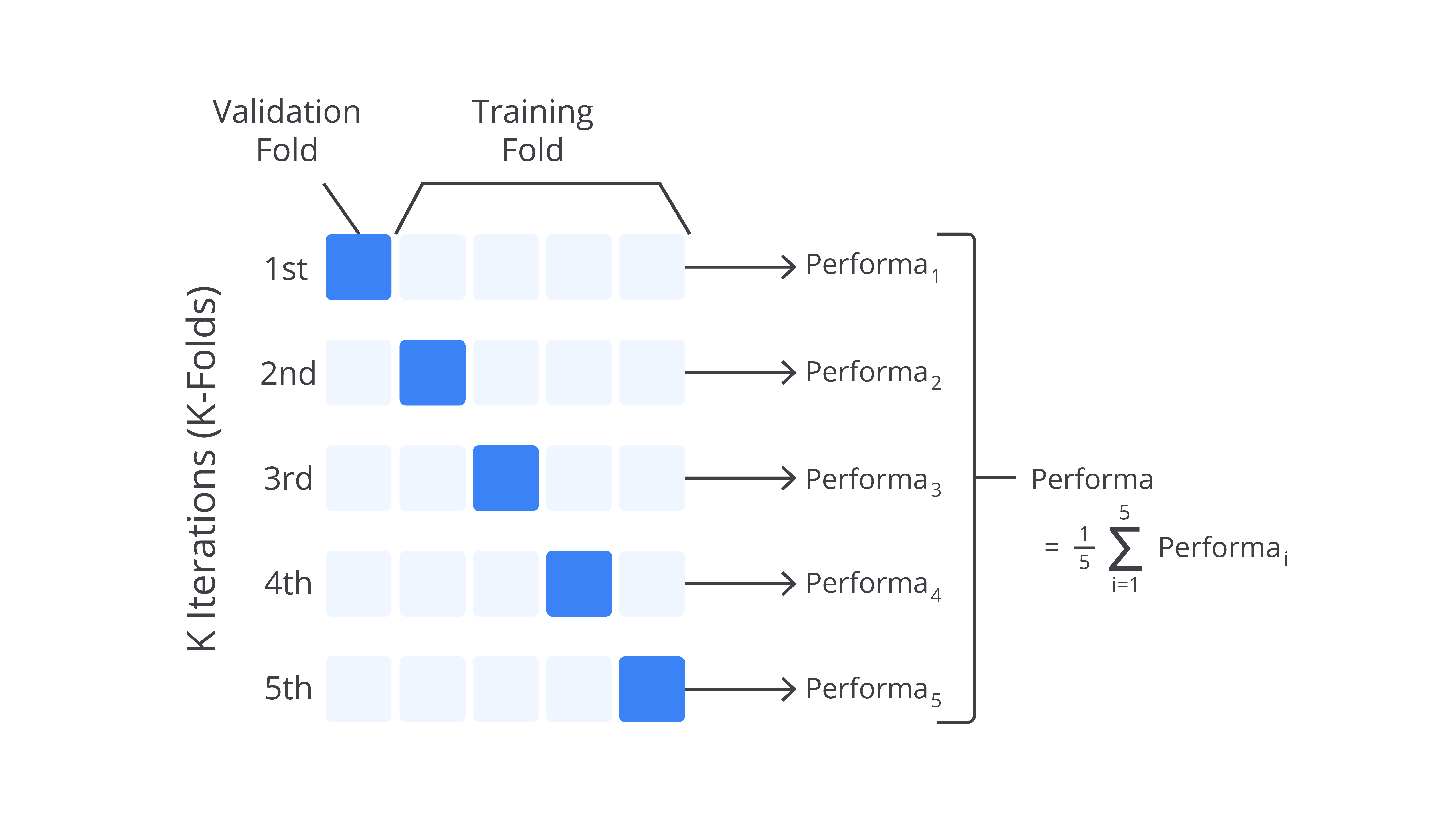
Metode ini memiliki kelebihan untuk mengurangi bias evaluasi dan membagi data dengan lebih efisien. Dengan menggunakan cross-validation, model akan dievaluasi pada berbagai subset sehingga hasilnya lebih stabil. Selain itu, cross-validation dapat memaksimalkan penggunaan dataset kecil dengan mengevaluasi model pada beberapa bagian dataset.
Namun, metode ini memiliki satu kekurangan yang cukup fatal. Metode cross-validation akan membagi data apa adanya. Lalu, apa masalahnya? Jika Anda memiliki data yang tidak seimbang atau imbalance dataset, metode ini tidak akan berjalan dengan baik karena pembagian yang tidak pasti.
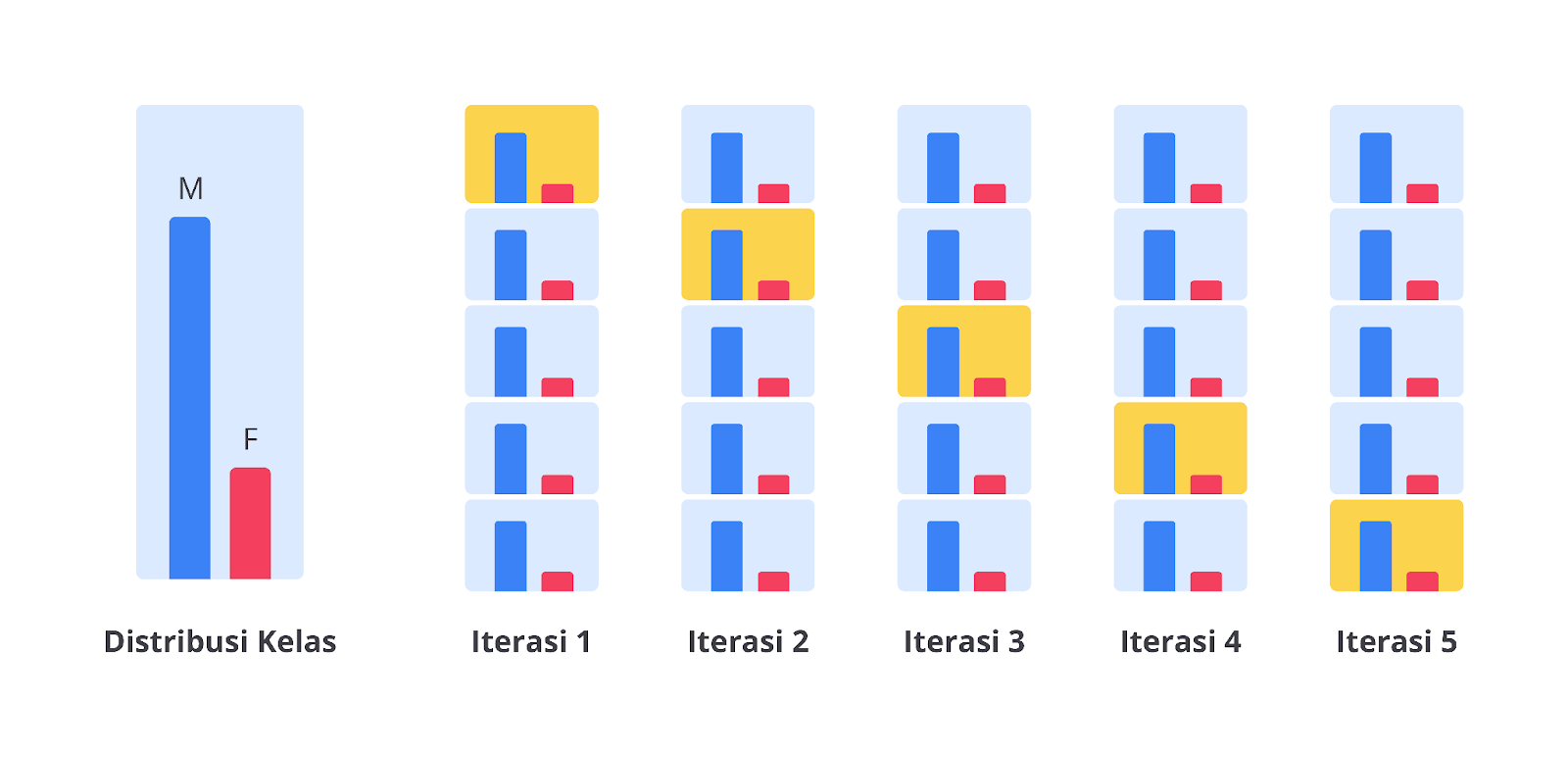
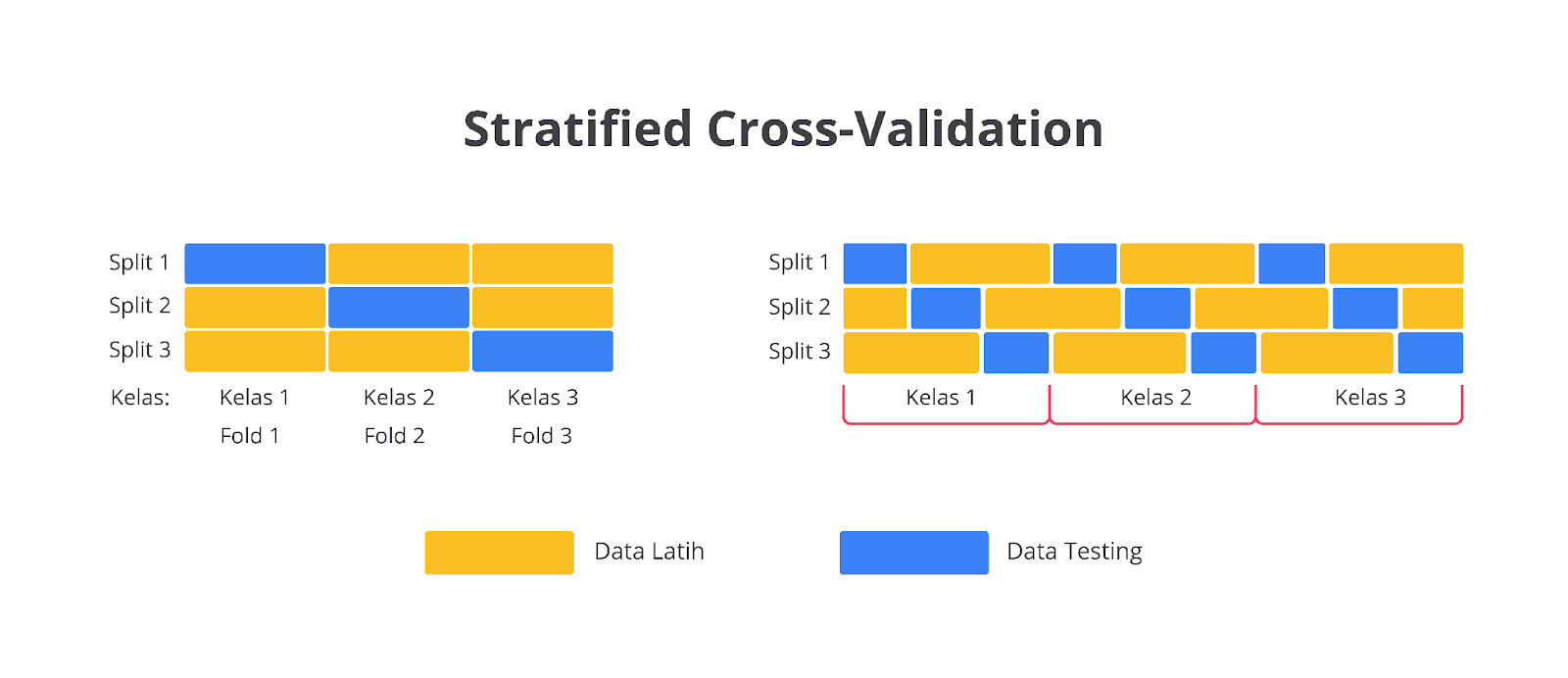
Sehingga, performa yang diuji bisa saja mengalami overfitting atau underfitting karena bias ketika proses pelatihan. Lalu bagaimana cara mengatasinya? Chill out, Scikit Learn saat ini menyediakan sebuah fungsi lanjutan dari cross-validation yang bernama stratified cross-validation. Teknik ini memastikan bahwa proporsi kelas di setiap fold tetap terjaga sehingga memberikan evaluasi yang lebih representatif.
Setelah memilih metode yang cocok Anda perlu melakukan menguji performa dengan menggunakan metrik evaluasi yang sering digunakan pada model machine learning. Metrik ini bergantung pada jenis masalah yang kita hadapi (klasifikasi, regresi, atau lainnya), metrik evaluasi yang digunakan bisa berbeda-beda. Tentunya, Anda masih ingatkan berbagai macam metrik evaluasi yang sudah dipelajari pada modul-modul sebelumnya? Bagus. Kini, kita dapat melanjutkan proses belajar ke tahap berikutnya yaitu kesimpulan.
Setelah melakukan evaluasi model setelah hyperparameter tuning, Anda dapat membuat beberapa kesimpulan penting yang nantinya akan berguna untuk membantu membuat keputusan. Berikut beberapa hal yang dapat membantu Anda membuat kesimpulan.
- Apakah hyperparameter tuning meningkatkan performa model? Bandingkan metrik performa sebelum dan sesudah tuning untuk memastikan bahwa tuning memberikan peningkatan signifikan.
- Apakah model overfitting atau underfitting? Pastikan bahwa model bekerja baik pada data uji dan tidak hanya pada data latih.
- Apakah ada metrik lain yang harus dipertimbangkan? Terkadang, akurasi saja tidak cukup. Gunakan metrik lain seperti precision, recall, atau F1-score untuk mendapatkan gambaran performa model yang lebih lengkap.
- Evaluasi yang menyeluruh memastikan bahwa model yang dihasilkan setelah tuning tidak hanya bekerja baik pada dataset pelatihan, tetapi juga dapat menggeneralisasi dengan baik pada data baru.
Dengan melakukan evaluasi yang menyeluruh Anda dapat memastikan bahwa model yang dihasilkan setelah tuning tidak hanya bekerja baik pada dataset pelatihan, tetapi juga dapat menggeneralisasi dengan baik pada data baru.
Woaaaah, perjalanan panjang telah Anda lalui hingga akhir materi yang ada pada kelas Machine Learning untuk Pemula.
Semoga seluruh materi yang ada di kelas ini dapat membantu Anda untuk membuat model machine learning andal dan dapat digunakan oleh masyarakat umum baik itu dalam segi bisnis atau non-commercial purpose.
Eiitss sebelum melangkah ke kelas berikutnya, ada satu hal lagi yang perlu Anda lakukan. Kami sangat percaya bahwa teori akan membantu Anda membuka wawasan yang sangat luas, tetapi jangan lupakan praktikum karena hal tersebut harus dilakukan bersamaan agar Anda memiliki keterampilan yang sempurna.
Materi berikutnya merupakan langkah terakhir pada kelas ini. Mari kita bakar semangat sampai titik darah penghabisan karena Anda akan melakukan hyperparameter tuning pada sebuah studi kasus. Penasaran kan bagaimana praktiknya? Yuk, kita mulai praktiknya.
Studi Kasus Hyperparameter Tuning
Pada modul-modul sebelumnya, kita telah mempelajari penggunaan test set untuk mengevaluasi model sebelum masuk ke tahap produksi.
Sekarang bayangkan ketika kita bertugas untuk mengembangkan sebuah proyek machine learning. Kita bimbang kala memilih model yang akan dipakai dari 10 jenis model yang tersedia. Salah satu opsinya adalah dengan melatih semua model tersebut lalu membandingkan tingkat errornya pada test set. Setelah membandingkan performa semua model, Anda mendapati model regresi linier memiliki tingkat error yang paling kecil katakanlah sebesar 5% dan membawa model tersebut ke tahap produksi.
Kemudian ketika model diuji pada tahap produksi, tingkat error ternyata sebesar 15%. Kenapa ini terjadi? Masalah ini terjadi karena kita mengukur tingkat error berulang kali pada test set. Secara tidak sadar, kita telah memilih model yang hanya bekerja dengan baik pada test set tersebut. Hal ini menyebabkan model tidak bekerja dengan baik ketika menemui data baru. Solusi paling umum dari masalah ini adalah dengan melakukan hyperparameter tuning pada model machine learning.
Untuk memperdalam pengetahuan Anda, pada materi ini kita akan melakukan dua percobaan hyperparameter tuning pada kasus regresi dan klasifikasi.
Latihan Regresi
Pada latihan pertama kita akan menggunakan dataset fetch_california_housing dari Scikit-learn untuk melakukan regresi menggunakan Random Forest Regressor. Dataset California Housing adalah dataset yang berisi informasi harga rumah berdasarkan berbagai fitur, dan tujuan model ini adalah memprediksi harga rata-rata rumah di wilayah tertentu.
Dalam studi kasus ini, kita akan melakukan hyperparameter tuning pada model Random Forest Regressor dan membandingkan performa serta efisiensi antara Grid Search, Random Search, dan Bayesian Optimization.
Pertama-tama, mari kita muat dataset yang akan digunakan. Pada latihan ini, kita tidak akan membahas pre-processing terlalu dalam dengan anggapan Anda sudah menguasai materi tersebut pada modul-modul sebelumnya.
- from sklearn.datasets import fetch_california_housing from sklearn.model_selection import train_test_split
- dari sklearn.model_selection impor train_test_split from sklearn.preprocessing import StandardScaler
- dari sklearn.preprocessing impor StandardScaler
- # Mengunduh dataset California Housing
- #Mendownload kumpulan data Perumahan California X, y = fetch_california_housing(return_X_y=True)
- X, y = ambil_perumahan_kalifornia(kembalikan_X_y=True)
- # Membagi dataset menjadi training set dan testing set (70% training, 30% testing)
- # Membagi dataset menjadi set pelatihan dan set pengujian (70% pelatihan, 30% pengujian) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
- # Melakukan scaling pada data (penting untuk regresi)
- # Melakukan scaling pada data (penting untuk regresi) scaler = StandardScaler()
- scaler = StandardScaler()
- X_train = scaler.fit_transform(X_train)
- X_test = scaler.transform(X_test)
- print("Shape of training data:", X_train.shape)
- print("Shape of testing data:", X_test.shape)

Output di atas memiliki 14.448 data latih dan 6192 data uji. Kemudian, mari kita latih model machine learning agar dapat memprediksi nilai kontinu karena kita akan membuat sebuah model regresi.
- from sklearn.ensemble import RandomForestRegressor
- from sklearn.metrics import mean_squared_error
- # Inisialisasi model Random Forest Regressor
- rf = RandomForestRegressor(random_state=42)
- rf.fit(X_train, y_train)
- # Evaluasi awal model tanpa tuning
- y_pred = rf.predict(X_test)
- initial_mse = mean_squared_error(y_test, y_pred)
- print(f"Initial MSE on test set (without tuning): {initial_mse:.2f}")

Nilai MSE pada model regresi ini 0.26 tanpa melakukan hyperparameter tuning. Nilai ini sudah cukup bagus mengingat kita menggunakan salah satu algoritma ensemble yaitu RandomForestRegressor. Anda dapat melakukan eksplorasi menggunakan algoritma lainnya juga, ya.
Selanjutnya, mari kita lakukan hyperparameter tuning dimulai dengan grid search.
- import time
- from sklearn.model_selection import GridSearchCV
- start_time = time.time() # Mencatat waktu mulai
- # Definisikan parameter grid untuk Grid Search
- param_grid = {
- 'n_estimators': [100, 200, 300],
- 'max_depth': [10, 20, 30],
- 'min_samples_split': [2, 5, 10],
- 'min_samples_leaf': [1, 2, 4],
- 'bootstrap': [True, False]
- }
- # Inisialisasi GridSearchCV
- grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=3, n_jobs=-1, verbose=2)
- grid_search.fit(X_train, y_train)
- # Output hasil terbaik
- print(f"Best parameters (Grid Search): {grid_search.best_params_}")
- best_rf_grid = grid_search.best_estimator_
- # Evaluasi performa model setelah Grid Search
- y_pred_grid = best_rf_grid.predict(X_test)
- grid_search_mse = mean_squared_error(y_test, y_pred_grid)
- print(f"MSE after Grid Search: {grid_search_mse:.2f}")
- end_time = time.time() # Mencatat waktu selesai
- execution_time = end_time - start_time # Menghitung selisih waktu
- print(f"Waktu eksekusi: {execution_time:.4f} detik")

Nilai MSE setelah melalui grid search berkurang 0.02 menjadi 0.21, hal ini berarti hyperparameter pada foundation model belum mencapai titik optimalnya. Sebagai catatan, Anda juga dapat menambahkan lebih banyak kombinasi hyperparameter seperti berikut.
- param_grid = {
- 'n_estimators': [100, 200, 300, 400],
- 'max_depth': [10, 20, 30, 40],
- 'min_samples_split': [2, 5, 10, 15],
- 'min_samples_leaf': [1, 2, 4, 8],
- 'bootstrap': [True, False]
- }

Namun, perlu Anda ingat dengan menambahkan kombinasi hyperparameter akan meningkatkan jumlah kombinasi secara signifikan. Hal ini menyebabkan konsumsi memori akan meningkat jauh lebih besar bahkan dapat menyebabkan crash atau error ketika proses tuning dilakukan.
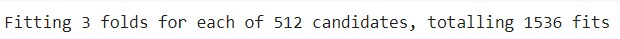
Ini menjadi salah satu kelemahan grid search yang sudah kita bahas pada materi sebelumnya karena metode ini akan melatih seluruh kombinasi dari hyperparameter yang kita tentukan.
Selanjutnya, mari kita lakukan optimasi dengan menggunakan random search menggunakan kode berikut.
- from sklearn.model_selection import RandomizedSearchCV
- import numpy as np
- start_time = time.time() # Mencatat waktu mulai
- # Definisikan ruang pencarian untuk Random Search
- param_dist = {
- 'n_estimators': np.arange(100, 500, 100),
- 'max_depth': [None] + list(np.arange(10, 50, 10)),
- 'min_samples_split': np.arange(2, 11, 2),
- 'min_samples_leaf': np.arange(1, 5),
- 'bootstrap': [True, False]
- }
- # Inisialisasi RandomizedSearchCV
- random_search = RandomizedSearchCV(estimator=rf, param_distributions=param_dist, n_iter=5, cv=3, n_jobs=-1, verbose=2, random_state=42)
- random_search.fit(X_train, y_train)
- # Output hasil terbaik
- print(f"Best parameters (Random Search): {random_search.best_params_}")
- best_rf_random = random_search.best_estimator_
- # Evaluasi performa model setelah Random Search
- y_pred_random = best_rf_random.predict(X_test)
- random_search_mse = mean_squared_error(y_test, y_pred_random)
- print(f"MSE after Grid Search: {random_search_mse:.2f}")
- end_time = time.time() # Mencatat waktu selesai
- execution_time = end_time - start_time # Menghitung selisih waktu
- print(f"Waktu eksekusi: {execution_time:.4f} detik")

Pada output di atas nampak jelas sebuah perbedaan yang signifikan yaitu pada waktu eksekusi. Dengan menggunakan random search, komputer hanya mencari n kombinasi sesuai jumlah kombinasi yang ingin dicari. Semakin banyak nilai yang Anda tentukan, semakin lama juga waktu yang diperlukan, begitu juga sebaliknya.
Last but not least, mari kita lakukan optimasi dengan menggunakan bayesian optimization.
- from skopt import BayesSearchCV
- start_time = time.time() # Mencatat waktu mulai
- # Definisikan ruang pencarian untuk Bayesian Optimization
- param_space = {
- 'n_estimators': (100, 500),
- 'max_depth': (10, 50),
- 'min_samples_split': (2, 10),
- 'min_samples_leaf': (1, 4),
- 'bootstrap': [True, False]
- }
- # Inisialisasi BayesSearchCV
- bayes_search = BayesSearchCV(estimator=rf, search_spaces=param_space, n_iter=32, cv=3, n_jobs=-1, verbose=2, random_state=42)
- bayes_search.fit(X_train, y_train)
- # Output hasil terbaik
- print(f"Best parameters (Bayesian Optimization): {bayes_search.best_params_}")
- best_rf_bayes = bayes_search.best_estimator_
- # Evaluasi performa model setelah Random Search
- y_pred_bayes = best_rf_bayes.predict(X_test)
- bayes_mse = mean_squared_error(y_test, y_pred_bayes)
- print(f"MSE after Grid Search: {bayes_mse:.2f}")
- end_time = time.time() # Mencatat waktu selesai
- execution_time = end_time - start_time # Menghitung selisih waktu
- print(f"Waktu eksekusi: {execution_time:.4f} detik")

Berbeda dengan grid search dan random search, output yang diberikan oleh bayesian optimization hanya memiliki satu kandidat kombinasi yang berulang kali dihitung. Perulangan ini akan terus dilakukan hingga performa model machine learning sudah tidak ada perubahan.
Kesimpulan dari ketiga metode ini dapat kita rangkum seperti berikut.
- Grid Search memberikan hasil optimal tetapi membutuhkan waktu komputasi yang lebih lama karena mencoba semua kombinasi hyperparameter yang ada.
- Random Search memberikan hasil yang baik dengan waktu komputasi yang lebih cepat, tetapi bisa saja kehilangan kombinasi hyperparameter yang optimal.
- Bayesian Optimization memberikan keseimbangan terbaik antara efisiensi komputasi dan hasil optimal, memanfaatkan informasi dari iterasi sebelumnya untuk mencari kombinasi hyperparameter terbaik.
Dengan dataset California Housing, kita dapat melihat perbedaan performa model secara lebih signifikan setelah dilakukan hyperparameter tuning. Bayesian Optimization adalah pilihan yang baik jika Anda ingin mengoptimalkan model secara lebih efisien, sementara Grid Search memberikan hasil yang lebih pasti dengan menguji semua kombinasi.
Ada sebuah fun fact ketika Anda mencoba mengimplementasikan hyperparameter tuning terhadap sebuah model machine learning. Kelak ketika Anda mencoba melakukan tuning jangan heran jika performa model tidak berubah sama sekali atau bahkan menurun.
Penurunan akurasi setelah hyperparameter tuning adalah hal yang umum terjadi dalam pembangunan model machine learning. Agar Anda memahami perbedaan tersebut, mari kita coba gunakan latihan klasifikasi sebagai playground untuk eksplorasi segala kemungkinan yang bisa terjadi ketika melakukan hyperparameter tuning.
Latihan Klasifikasi
Pada latihan kedua ini, Anda akan membangun sebuah model klasifikasi dengan dataset yang berisi informasi tentang klasifikasi kredit. Dataset ini memiliki sekitar 1.000 baris dan sejumlah fitur yang menjelaskan profil pelanggan, seperti riwayat kredit, status pekerjaan, pendapatan, dan sebagainya. Seperti biasa, mari kita lakukan loading dataset dan sedikit preprocessing agar data dapat dilatih dengan baik.
- from sklearn.datasets import fetch_openml
- import pandas as pd
- from sklearn.model_selection import train_test_split
- from sklearn.preprocessing import LabelEncoder
- # Mengunduh dataset German Credit dari OpenML
- X, y = fetch_openml(name='credit-g', version=1, return_X_y=True, as_frame=True)
- # Konversi target menjadi numerik
- le = LabelEncoder()
- y = le.fit_transform(y) # Mengubah 'good' menjadi 1 dan 'bad' menjadi 0
- # Melakukan One-Hot Encoding pada fitur kategorikal
- X_encoded = pd.get_dummies(X, drop_first=True) # Konversi fitur kategorikal menjadi numerik
- # Membagi dataset menjadi training set dan testing set (70% training, 30% testing)
- X_train, X_test, y_train, y_test = train_test_split(X_encoded, y, test_size=0.3, random_state=42)
- print("Shape of training data:", X_train.shape)
- print("Shape of testing data:", X_test.shape)

Mari kita asumsikan sampai pada titik ini dataset yang digunakan sudah siap dilatih sehingga Anda hanya perlu membangun sebuah foundation model dengan menggunakan kode berikut.
- from sklearn.ensemble import RandomForestClassifier
- # Inisialisasi model Random Forest tanpa hyperparameter tuning
- rf = RandomForestClassifier(random_state=42)
- rf.fit(X_train, y_train)
- # Evaluasi awal model tanpa tuning
- initial_score = rf.score(X_test, y_test)
- print(f"Initial accuracy on test set (without tuning): {initial_score:.2f}")
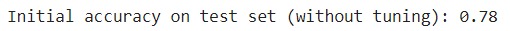
Sama halnya dengan latihan pada kasus regresi tahap berikutnya Anda hanya perlu membangun sebuah model dengan menggunakan hyperparameter tuning dimulai dari grid search.
- from sklearn.model_selection import GridSearchCV
- # Definisikan parameter grid untuk Grid Search
- param_grid = {
- 'n_estimators': [100, 200, 300],
- 'max_depth': [10, 20, 30],
- 'min_samples_split': [2, 5, 10],
- 'criterion': ['gini', 'entropy']
- }
- # Inisialisasi GridSearchCV
- grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=3, n_jobs=-1, verbose=2)
- grid_search.fit(X_train, y_train)
- # Output hasil terbaik
- print(f"Best parameters (Grid Search): {grid_search.best_params_}")
- best_rf_grid = grid_search.best_estimator_
- # Evaluasi performa model pada test set
- grid_search_score = best_rf_grid.score(X_test, y_test)
- print(f"Accuracy after Grid Search: {grid_search_score:.2f}")

Langkah berikutnya, lakukan hal yang sama dengan sebelumnya, tetapi menggunakan random search.
- from sklearn.model_selection import RandomizedSearchCV
- import numpy as np
- # Definisikan ruang pencarian untuk Random Search
- param_dist = {
- 'n_estimators': np.linspace(100, 500, 5, dtype=int),
- 'max_depth': np.linspace(10, 50, 5, dtype=int),
- 'min_samples_split': [2, 5, 10],
- 'criterion': ['gini', 'entropy']
- }
- # Inisialisasi RandomizedSearchCV
- random_search = RandomizedSearchCV(estimator=rf, param_distributions=param_dist, n_iter=20, cv=3, n_jobs=-1, verbose=2, random_state=42)
- random_search.fit(X_train, y_train)
- # Output hasil terbaik
- print(f"Best parameters (Random Search): {random_search.best_params_}")
- best_rf_random = random_search.best_estimator_
- # Evaluasi performa model pada test set
- random_search_score = best_rf_random.score(X_test, y_test)
- print(f"Accuracy after Random Search: {random_search_score:.2f}")

Whoops, jika Anda perhatikan, kedua metode di atas memiliki performa yang sama dengan foundation model yang sudah kita bangun di awal latihan. Sebagai pembuktian, mari kita gunakan bayesian optimization untuk melakukan hyperparameter tuning.
- from skopt import BayesSearchCV
- # Definisikan ruang pencarian untuk Bayesian Optimization
- param_space = {
- 'n_estimators': (100, 500),
- 'max_depth': (10, 50),
- 'min_samples_split': (2, 10),
- 'criterion': ['gini', 'entropy']
- }
- # Inisialisasi BayesSearchCV
- bayes_search = BayesSearchCV(estimator=rf, search_spaces=param_space, n_iter=32, cv=3, n_jobs=-1, verbose=2, random_state=42)
- bayes_search.fit(X_train, y_train)
- # Output hasil terbaik
- print(f"Best parameters (Bayesian Optimization): {bayes_search.best_params_}")
- best_rf_bayes = bayes_search.best_estimator_
- # Evaluasi performa model pada test set
- bayes_search_score = best_rf_bayes.score(X_test, y_test)
- print(f"Accuracy after Bayesian Optimization: {bayes_search_score:.2f}")

Voilaa, ternyata dengan menggunakan metode apa pun, hasil yang diberikan cenderung sama saja dan bahkan terdapat performa yang menurun. Hal ini merupakan fun fact yang telah kita bahas sebelumnya. Pertanyaannya, mengapa hal ini bisa terjadi?
Seperti yang sudah kita bahas penurunan akurasi setelah hyperparameter tuning adalah hal yang umum terjadi dalam pembangunan model machine learning, dan beberapa faktor yang berkontribusi terhadap masalah ini antara lain seperti berikut.
- Overfitting: tuning hyperparameter secara berlebihan bisa menyebabkan model terlalu sesuai dengan data pelatihan (overfit). Hal ini dapat menyebabkan performa model yang baik pada data pelatihan tetapi buruk pada data pengujian.
- Underfitting: sebaliknya, jika model tidak cukup kompleks setelah tuning, model bisa gagal menangkap pola penting dari data (underfit).
- Pemilihan Ruang Pencarian yang Tidak Tepat: jika rentang atau ruang hyperparameter yang dicari terlalu kecil atau tidak mencakup area yang optimal, hasil tuning dapat merugikan performa model.
- Evaluasi yang Tidak Konsisten: cross-validation yang kurang efektif atau ruang pencarian hyperparameter yang terlalu besar juga dapat membuat tuning kurang efektif.
Dari berbagai macam penjelasan di atas, salah satu alasan model yang kita bangun tidak berubah karena dataset yang digunakan terlalu kecil atau dummy. Hal ini sengaja kami lakukan agar Anda dapat memahami perbedaan dari kedua latihan yang telah dilakukan.
Untuk melakukan tuning yang lebih baik, Anda dapat menerapkan beberapa saran berikut.
- Memastikan bahwa dataset yang digunakan sudah baik.
- Memperluas ruang pencarian hyperparameter.
- Memfokuskan tuning pada hyperparameter kunci yang paling berdampak pada performa model, seperti n_estimators, max_depth, dan min_samples_split.
- Menggunakan cross-validation dengan lebih banyak fold untuk membuat evaluasi performa lebih stabil.
- Memperhatikan keseimbangan antara eksplorasi dan eksploitasi hyperparameter dengan menggunakan metode seperti Bayesian Optimization yang lebih efisien dalam memprediksi kombinasi optimal.
Sebagai bentuk eksplorasi, Anda dapat melihat beberapa contoh penerapan hyperparameter tuning pada notebook berikut: Update MLP - Modul 8 Optimasi dengan Hyperparameter Tuning. Selain itu, Anda juga dapat menerapkan metode ini pada studi kasus lainnya ya. Psst, jangan lupa juga untuk menerapkan hyperparameter tuning pada submission akhir, ya!
Sungguh tidak terasa sekarang Anda sudah mencapai akhir dari pembelajaran yang ada di kelas ini. Lika-liku pembangunan model machine learning telah Anda lewati dimulai dari pembangunan model, ragam model machine learning hingga bersahabat dengan error yang terjadi. Semua itu Anda lalui dengan gagah dan berani hingga akhirnya dapat membangun beragam model machine learning yang andal.
Selamat, Anda telah menyelesaikan kelas Machine Learning untuk Pemula, You did something big! Jika Anda masih ingin bermain-main di kelas ini, silakan baca-baca kembali modul yang sudah ada, ya. Oiya, kami juga sangat menanti cerita sukses Anda dalam perjalanan sebagai seorang machine learning engineer yang andal. Jangan lupa untuk membagikan cerita sukses Anda kelak, ya. Sampai jumpa lagi champs!
Rangkuman Optimasi Model dengan Hyperparameter Tuning
Pendahuluan Hyperparameter Tuning
Hyperparameter tuning adalah proses dalam machine learning untuk mengoptimalkan kinerja model berdasarkan suatu nilai tertentu. Singkatnya, parameter model adalah nilai yang dipelajari oleh model selama proses pelatihan, seperti bobot (weight) dalam jaringan saraf tiruan. Di lain sisi, hyperparameter merupakan nilai yang tidak dipelajari selama pelatihan, tetapi dapat ditentukan sebelum pelatihan model dimulai.
Strategi Hyperparameter Tuning
Dari sekian banyak hyperparameter tentunya tidak semuanya memiliki dampak yang sama pada model tertentu sehingga penting untuk memilih dan mengatur hyperparameter yang relevan untuk mencapai performa optimal.
Berikut adalah panduan umum tentang pemilihan hyperparameter yang relevan, termasuk cara untuk mengidentifikasi dan mengatur prioritas dalam tuning.
- Penggunaan Default Hyperparameter
Pada tahap awal, Anda dapat memulai dengan nilai default dari hyperparameter yang sering kali sudah diatur sedemikian rupa oleh library yang digunakan agar memberikan hasil yang baik pada kebanyakan kasus. Nilai ini dapat memberikan baseline yang cukup baik sebelum mulai melakukan tuning secara manual maupun otomatis.
- Memahami Algoritma yang Digunakan
Setiap algoritma machine learning memiliki hyperparameter yang berbeda-beda dan dapat memengaruhi model machine learning. Oleh karena itu, langkah pertama dalam pemilihan hyperparameter yang relevan adalah memahami algoritma yang digunakan, termasuk apa saja hyperparameter penting yang tersedia.
- Identifikasi Hyperparameter yang Paling Berpengaruh
Salah satu cara terbaik untuk mengidentifikasi hyperparameter yang relevan adalah sebagai berikut.- Riset Literatur dan Dokumentasi: memahami dari dokumentasi atau penelitian yang relevan untuk mencari hyperparameter terpenting pada algoritma yang digunakan.
- Pengalaman adalah Guru Terbaik: pengalaman mengembangkan model sering kali memberikan wawasan tentang hyperparameter mana yang layak untuk difokuskan.
- Eksperimen Awal: lakukan eksperimen awal dengan nilai default untuk semua hyperparameter, kemudian lakukan analisis untuk memahami hyperparameter mana yang paling memengaruhi kinerja.
- Prioritaskan Tuning Hyperparameter yang Krusial
Setelah mengidentifikasi hyperparameter yang relevan, langkah selanjutnya adalah memprioritaskan tuning hyperparameter yang paling krusial. Ini berarti, Anda sebaiknya tidak mencoba menyetel semua hyperparameter sekaligus, tetapi memfokuskan eksplorasi pada hyperparameter yang berpotensi memberikan dampak paling besar terlebih dahulu.
- Memahami Hubungan antara Hyperparameter
Beberapa hyperparameter memiliki hubungan yang saling terkait sehingga pengaruhnya pada model tergantung pada pengaturan hyperparameter lainnya. Misalnya, dalam jaringan saraf tiruan, learning rate dan momentum sering kali berinteraksi bersamaan.
- Menyesuaikan Hyperparameter Berdasarkan Data
Hyperparameter yang relevan tidak hanya bergantung pada algoritma yang digunakan tetapi juga pada karakteristik data yang dilatih. Beberapa pertimbangan yang biasanya dilakukan yaitu seperti berikut.- Ukuran Dataset: pada dataset besar, batch size yang lebih besar bisa membuat pelatihan lebih efisien. Sementara pada dataset kecil, batch size yang kecil mungkin lebih tepat untuk mencegah overfitting.
- Dimensi Data: pada dataset berdimensi tinggi, model seperti SVM sering kali membutuhkan tuning yang lebih intensif pada hyperparameter gamma untuk menangani kompleksitas data.
- Jumlah Noise: jika data mengandung banyak noise, regularization parameter misalnya C pada SVM atau alpha pada Ridge Regression mungkin harus diperhatikan supaya terhindar dari overfitting.
- Evaluasi Kinerja Model dengan Cross-Validation
Untuk setiap kombinasi hyperparameter yang diuji, Anda perlu melakukan evaluasi kinerja model secara menyeluruh (tidak hanya satu kali pengujian). Penggunaan teknik seperti cross-validation akan sangat membantu karena memungkinkan mengevaluasi performa model pada berbagai subset data dalam satu waktu sehingga hasil tuning hyperparameter dapat divalidasi dengan lebih cermat.
Grid Search
Grid Search adalah salah satu metode hyperparameter tuning yang digunakan untuk menemukan kombinasi hyperparameter optimal pada model machine learning. Grid Search bekerja dengan mencoba semua kombinasi dari nilai hyperparameter yang telah Anda tentukan dan mengevaluasi performa model untuk setiap kombinasi tersebut.
Tujuan dari Grid Search adalah untuk mengidentifikasi set hyperparameter yang menghasilkan performa terbaik berdasarkan metrik evaluasi yang dipilih (misalnya akurasi, F1-score, atau MSE).
Random Search
Random Search adalah salah satu metode hyperparameter tuning yang cenderung lebih efisien dibandingkan Grid Search. Alih-alih mencoba semua kombinasi hyperparameter seperti dalam Grid Search, Random Search memilih beberapa kombinasi hyperparameter secara acak dari ruang pencarian yang sudah ditentukan. Proses ini memungkinkan model untuk diuji dengan kombinasi acak yang dipilih secara independen untuk setiap iterasi.
Tujuan Random Search adalah menghemat waktu dan sumber daya dengan tetap melatih sejumlah kombinasi yang cukup representatif dari ruang pencarian, tanpa perlu menguji semua kombinasi yang mungkin terjadi.
Bayesian Optimization
Bayesian Optimization adalah salah satu teknik hyperparameter tuning yang efisien dan kompleks. Metode ini digunakan untuk menemukan kombinasi hyperparameter yang optimal dengan melakukan lebih sedikit percobaan dibandingkan Grid Search atau Random Search.
Bayesian Optimization sangat berguna untuk masalah yang memerlukan tuning hyperparameter pada ruang pencarian yang besar, di mana mencoba semua kombinasi hyperparameter akan sangat tidak efisien dan memakan waktu.
Bayesian Optimization tidak melakukan pencarian secara acak atau mencoba semua kombinasi, melainkan menggunakan pendekatan probabilistik untuk secara cermat memilih kombinasi hyperparameter yang paling mungkin memberikan hasil terbaik berdasarkan percobaan sebelumnya. Dengan demikian, metode ini sangat efektif dalam mengurangi jumlah percobaan yang diperlukan untuk menemukan hyperparameter terbaik.
Evaluasi Model setelah Hyperparameter Tuning
Setelah proses hyperparameter tuning selesai dan kita telah menemukan kombinasi hyperparameter optimal, langkah berikutnya yang sangat penting adalah melakukan evaluasi model. Evaluasi model bertujuan untuk mengukur performa model setelah tuning dilakukan dan memastikan bahwa model menggeneralisasi dengan baik pada data baru (data yang belum pernah dilihat oleh model). Evaluasi ini tidak hanya mengukur akurasi atau performa di data pelatihan, tetapi juga kemampuan model dalam memprediksi hasil pada data pengujian.
Setelah melakukan evaluasi model setelah hyperparameter tuning, Anda dapat membuat beberapa kesimpulan penting yang nantinya akan berguna untuk membantu membuat keputusan. Berikut beberapa hal yang dapat membantu Anda membuat kesimpulan.
- Apakah hyperparameter tuning meningkatkan performa model? Bandingkan metrik performa sebelum dan sesudah tuning untuk memastikan bahwa tuning memberikan peningkatan signifikan.
- Apakah model overfitting atau underfitting? Pastikan bahwa model bekerja baik pada data uji dan tidak hanya pada data latih.
- Apakah ada metrik lain yang harus dipertimbangkan? Terkadang, akurasi saja tidak cukup. Gunakan metrik lain seperti precision, recall, atau F1-score untuk mendapatkan gambaran performa model yang lebih lengkap.
- Evaluasi yang menyeluruh memastikan bahwa model yang dihasilkan setelah tuning tidak hanya bekerja baik pada dataset pelatihan, tetapi juga dapat menggeneralisasi dengan baik pada data baru.
- Get link
- X
- Other Apps



Comments
Post a Comment