Pendahuluan Klasifikasi
- Get link
- X
- Other Apps
Pendahuluan Klasifikasi
Hi, machine learning enthusiast!
Senang sekali bisa berjumpa kembali pada Modul 3! Bagaimana pengalaman belajar Anda pada Modul 1 dan 2? Kami harap materi yang sudah dipelajari memberikan landasan kokoh untuk melanjutkan ke topik yang lebih mendalam, ya. Pada modul-modul sebelumnya, kita telah membahas berbagai konsep dasar yang menjadi fondasi penting dalam memahami machine learning secara keseluruhan.
Pada Modul 1 dan 2, Anda telah diperkenalkan dengan definisi machine learning serta memahami alur kerja (workflow) yang terlibat dalam penerapan teknologi ini. Kini, pada Modul 3, kita akan fokus pada salah satu konsep yang paling penting dan sering digunakan dalam machine learning, yaitu "klasifikasi".
Kata "klasifikasi" mungkin sudah sering Anda dengar dan sekarang kita akan mengupas tuntas konsep ini, terutama dalam konteks data tabular. Klasifikasi merupakan salah satu teknik pada machine learning yang digunakan untuk mengategorikan atau mengelompokkan data ke dalam kelas-kelas tertentu berdasarkan karakteristiknya.
Pada modul ini, kita akan mempelajari berbagai metode dan algoritma yang digunakan dalam klasifikasi, memahami cara kerjanya, serta melihat contoh penerapannya dalam dunia nyata.
Stay focused and best of luck!
[Story] Cerita Si Coffee Enthusiast
Pada jam istirahat makan siang, Diana dan Bilqis memutuskan untuk bersantai di ruang belajar kampus yang ramai, tempat favorit mereka untuk beristirahat. Setelah seharian mempelajari berbagai topik tentang machine learning workflow, mereka merasa butuh rehat sejenak.
Dengan rasa haus yang mulai terasa, mereka memutuskan untuk membeli minuman favorit sebagai penyegar. Bilqis memilih kopi hitam yang kuat, sementara Diana lebih memilih matcha latte yang lembut. Mereka berjalan menuju stand kopi di dekat working space, sambil berdiskusi tentang materi yang baru dipelajari dan merencanakan cara menerapkan konsep-konsep tersebut dalam proyek mereka.

“Cis, kamu cariin tempat duduk kita, ya. Biar aku yang pesankan. Kamu mau apa?” tanya Diana.
“Oke siap. Aku pengin kopi hitam ukuran reguler, ya, Na,” jawab Bilqis.
“Siap,” kata Diana, lalu menuju stand kopi untuk memesan.
Diana berdiri di antrean sambil menunggu giliran untuk memesan. Dia melihat berbagai macam minuman di menu dan akhirnya memutuskan untuk memilih matcha latte yang menjadi favoritnya. Ketika tiba di depan kasir, Diana memberi tahu pesanan. Kasir kemudian mencatat pesanan tersebut dan memberitahukannya kepada barista. Setelah menerima informasi pesanan dari kasir, barista segera memulai proses pembuatan minuman.
Sementara itu, Bilqis sudah menemukan tempat duduk yang nyaman di sudut ruang belajar. Dia memilih meja dekat jendela dengan pemandangan yang menyegarkan, tempat mereka bisa menikmati kopi sambil membahas materi. Bilqis menyusun buku-bukunya dan membuka laptop, bersiap untuk melanjutkan pembelajaran setelah mereka minum kopi.
Tak lama kemudian, Diana kembali dengan dua gelas minuman. Satu gelas matcha latte untuk Diana dan satu gelas kopi hitam untuk Bilqis. Mereka berdua tersenyum dan saling bertukar minuman sebelum mulai menikmati minuman mereka.
“Wah, ini enak banget! Makasih, Na!” kata Bilqis sambil menyeruput kopi hitamnya dengan nikmat.
“Anytime, Cis! Semoga ini bikin kita lebih semangat. Minum kopi atau minuman yang kita suka siang-siang gini emang nikmat banget, ya,” jawab Diana sambil membuka catatan dan laptopnya.
Diana melirik ke arah Bilqis dengan penasaran. "Habis ini kita belajar apa, ya?"
Bilqis tersenyum, "Oh, kalau aku lihat silabus yang dibagikan dosen, kita bakal belajar tentang klasifikasi. Itu salah satu metode dari supervised learning."
Diana terlihat sedikit bingung. "Eh, gimana, sih, maksud klasifikasi itu?"

Dengan gelas kopi hitam di tangannya, Bilqis merasa terinspirasi. "Na, bayangkan kalau kita punya banyak biji kopi dengan berbagai jenis dan rasa. Nah, klasifikasi dalam machine learning itu mirip seperti kita mengidentifikasi dan mengelompokkan biji kopi tersebut berdasarkan jenisnya."
Diana penasaran, "Maksudnya gimana?"
Bilqis menjelaskan, "Misalnya, kita punya biji kopi Arabika, Robusta, dan Liberika. Kita tahu ciri-ciri dan rasa khas dari setiap jenis biji kopi ini. Klasifikasi akan membantu kita membuat model yang bisa memeriksa biji kopi baru dan mengidentifikasinya sebagai Arabika, Robusta, atau Liberika berdasarkan fitur-fitur, seperti ukuran, bentuk, dan aroma."
Diana mengangguk, "Jadi, seperti kita membuat sistem yang bisa mengenali jenis biji kopi hanya dengan melihatnya?"

"Indeed!" jawab Bilqis. "Kalau kita punya banyak data tentang berbagai jenis biji kopi dan ciri-cirinya, kita bisa melatih model klasifikasi untuk mengenali biji kopi baru dan mengategorikannya dengan akurat. Jadi, kalau kita punya campuran biji kopi, model kita bisa menentukan campuran apa yang kita punya hanya dengan melihat fitur-fitur tersebut."
“Ah, paham sekarang!” Diana tersenyum. “Jadi, klasifikasi ini membantu kita mengidentifikasi dan mengelompokkan data berdasarkan kategori yang sudah kita ketahui sebelumnya. Sama seperti kita mengidentifikasi biji kopi berdasarkan jenisnya. Seru banget, ya!”
Bilqis tersenyum sambil menyeruput kopinya, “Betul, Na. Dengan pemahaman ini, kita bisa lebih siap untuk belajar tentang bagaimana menerapkan klasifikasi dalam proyek kita.”
Sambil menyeruput minuman mereka, Diana melanjutkan percakapan dengan penuh rasa ingin tahu. "Oh, kalau kita bicara tentang klasifikasi biji kopi ini, berarti kita bisa juga membahas klasifikasi gambar, ya?"
Bilqis mengangguk. "Betul sekali! Misalnya, kalau kita punya berbagai gambar biji kopi dari jenis yang berbeda, kita bisa melatih model klasifikasi untuk membedakan antara biji kopi Liberika, Arabika, dan Robusta hanya dari gambar. Model akan belajar dari fitur-fitur visual, seperti bentuk, ukuran, dan warna biji kopi."
Diana semakin tertarik dan bertanya, "Jadi, kalau datanya dalam bentuk tabel, seperti tabel pelanggan sebuah perusahaan, bagaimana caranya model klasifikasi bekerja?"
Bilqis menjelaskan dengan antusias, sambil menyeruput kopinya yang tinggal setengah gelas, "Kalau datanya berupa tabel, model klasifikasi akan menggunakan kolom-kolom dalam tabel sebagai fitur untuk memprediksi kategori atau label. Misalnya, dalam tabel pelanggan, kita mungkin memiliki kolom, seperti usia, saldo rekening, jumlah produk yang dimiliki, dan status keanggotaan. Setiap baris di tabel mewakili satu pelanggan dan fitur-fitur tersebut membantu model memahami pola dan hubungan di antara data."

Diana merenung sejenak, lalu bertanya, "Jadi, apakah sama seperti saat kita mengidentifikasi jenis biji kopi berdasarkan fitur visualnya? Misalnya, kita bisa memprediksi jenis biji kopi dari warna dan bentuknya. Bagaimana dengan tabel, apakah kita juga mengidentifikasi atau mengelompokkan berdasarkan fitur-fitur dalam tabel?"
Bilqis mengangguk dengan senyum, "Tepat sekali! Prinsipnya sama. Dalam kasus tabel, fitur-fitur seperti usia atau saldo rekening digunakan untuk memprediksi label atau kategori. Misalnya, kita bisa memprediksi apakah seorang pelanggan kemungkinan besar akan berhenti berlangganan berdasarkan fitur-fitur tersebut. Jadi, baik itu gambar biji kopi atau data tabel, kita menggunakan fitur yang relevan untuk mengidentifikasi kategori atau hasil tertentu."
Diana tampak semakin bersemangat, "Oh, jadi meskipun datanya berbeda, prosesnya tetap tentang memanfaatkan fitur untuk memahami dan mengelompokkan data ke dalam kategori yang sudah ditentukan."
"Benar sekali!" kata Bilqis dengan penuh semangat. "Dengan pemahaman ini, kita siap untuk menggali lebih dalam tentang teknik klasifikasi dan bagaimana menerapkannya pada berbagai jenis data. Yuk, kita kembali ke materi dan terus eksplorasi teknik-teknik klasifikasi yang menarik ini!"
Diana penasaran dan bertanya, "Kok kamu bisa tahu, sih, Cis? Kan kita baru banget mau belajar?"
Bilqis tertawa kecil dan menjelaskan, "Ah, itu karena aku sempat baca-baca sedikit sebelum kelas. Juga, kemarin kita sempat ngobrol sama dosen tentang topik ini. Tapi, jangan khawatir, kita akan belajar semuanya dengan detail setelah ini. Jadi, kita bakal punya pemahaman yang lebih dalam tentang bagaimana klasifikasi bekerja dan bagaimana cara mengaplikasikannya."
Diana, yang semakin antusias, meminta Bilqis untuk mengajarinya nanti. Bilqis membalas dengan nada bercanda, "Aman, traktir kopi lagi, ya?"
Diana dengan senang hati setuju dan bertanya, "Aman itu mah! Kamu mau biji kopi yang mana? Hahaha!"
Mereka melanjutkan obrolan sambil menikmati minuman mereka, siap untuk memasuki materi berikutnya tentang klasifikasi dengan semangat yang baru.
Konsep Dasar Klasifikasi
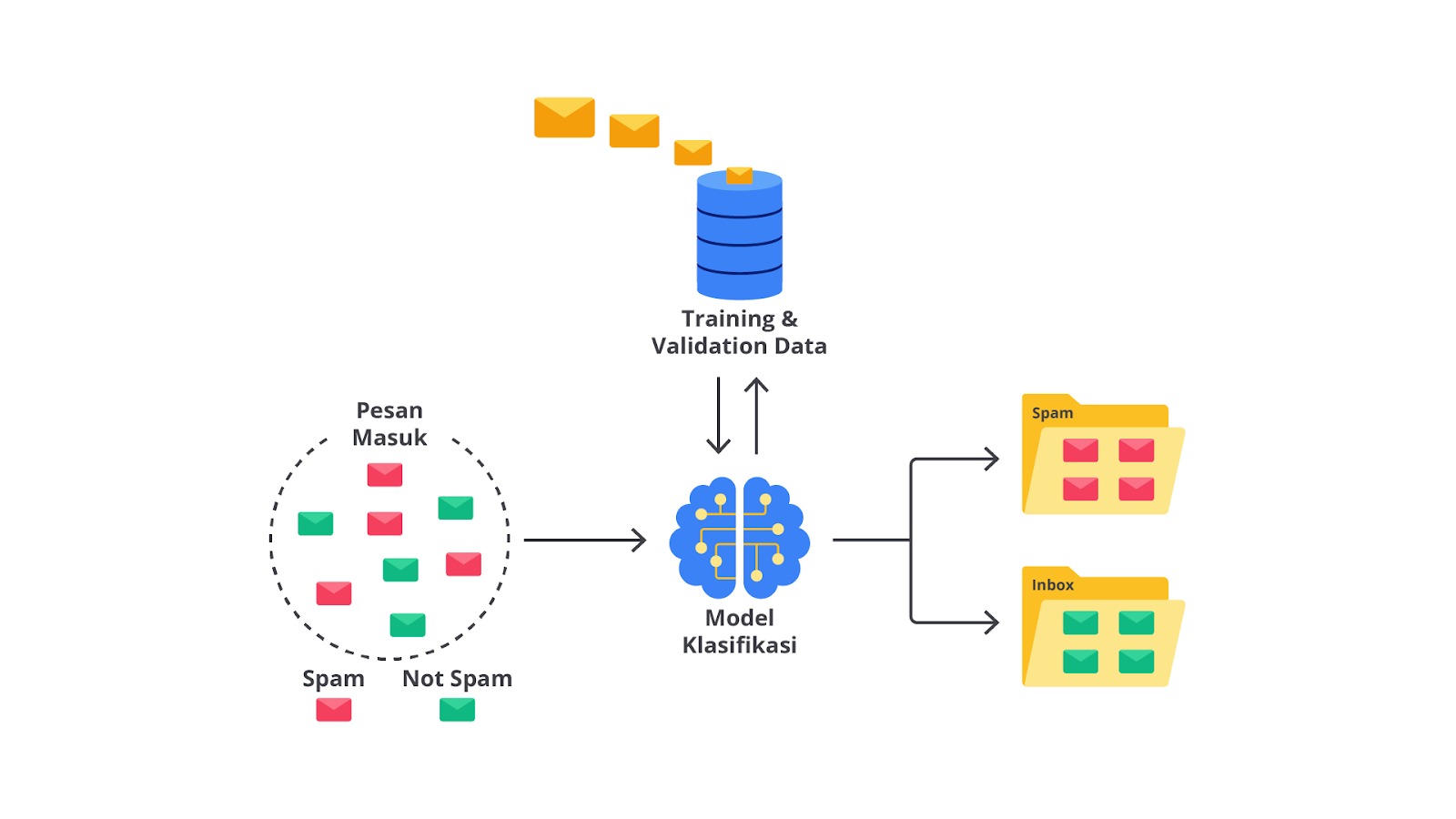
Klasifikasi adalah salah satu metode dalam machine learning yang berfungsi untuk mengelompokkan data ke dalam kategori atau kelas tertentu berdasarkan karakteristik atau fitur dari data tersebut. Metode ini adalah bagian dari supervised learning, yaitu model yang dilatih menggunakan data yang sudah diberi label atau kategori. Klasifikasi sangat berguna dalam berbagai aplikasi nyata, yaitu pengenalan wajah, filtering email spam, deteksi penipuan, diagnosis penyakit, dan banyak lagi.
Tujuan utama klasifikasi adalah memprediksi kelas atau label dari data baru yang belum pernah dilihat oleh model, berdasarkan pola yang telah dipelajari dari data yang ada. Misalnya, jika kita memiliki data tentang buah-buahan dengan fitur, seperti ukuran, warna, dan bentuk, model klasifikasi bisa dilatih untuk mengidentifikasi jenis buah tersebut dikategorikan sebagai apel, pisang, atau jeruk berdasarkan fitur-fitur tersebut.
Jika Anda perlu mengingat kembali konsep dasar dan cara kerja klasifikasi, jangan ragu untuk kembali ke materi Hi, Machine Learning, ya!
Proses Klasifikasi: Langkah Demi Langkah
Proses klasifikasi melibatkan beberapa tahapan yang penting untuk dipahami agar model yang dihasilkan dapat memberikan prediksi akurat. Berikut adalah langkah-langkah dalam proses klasifikasi.
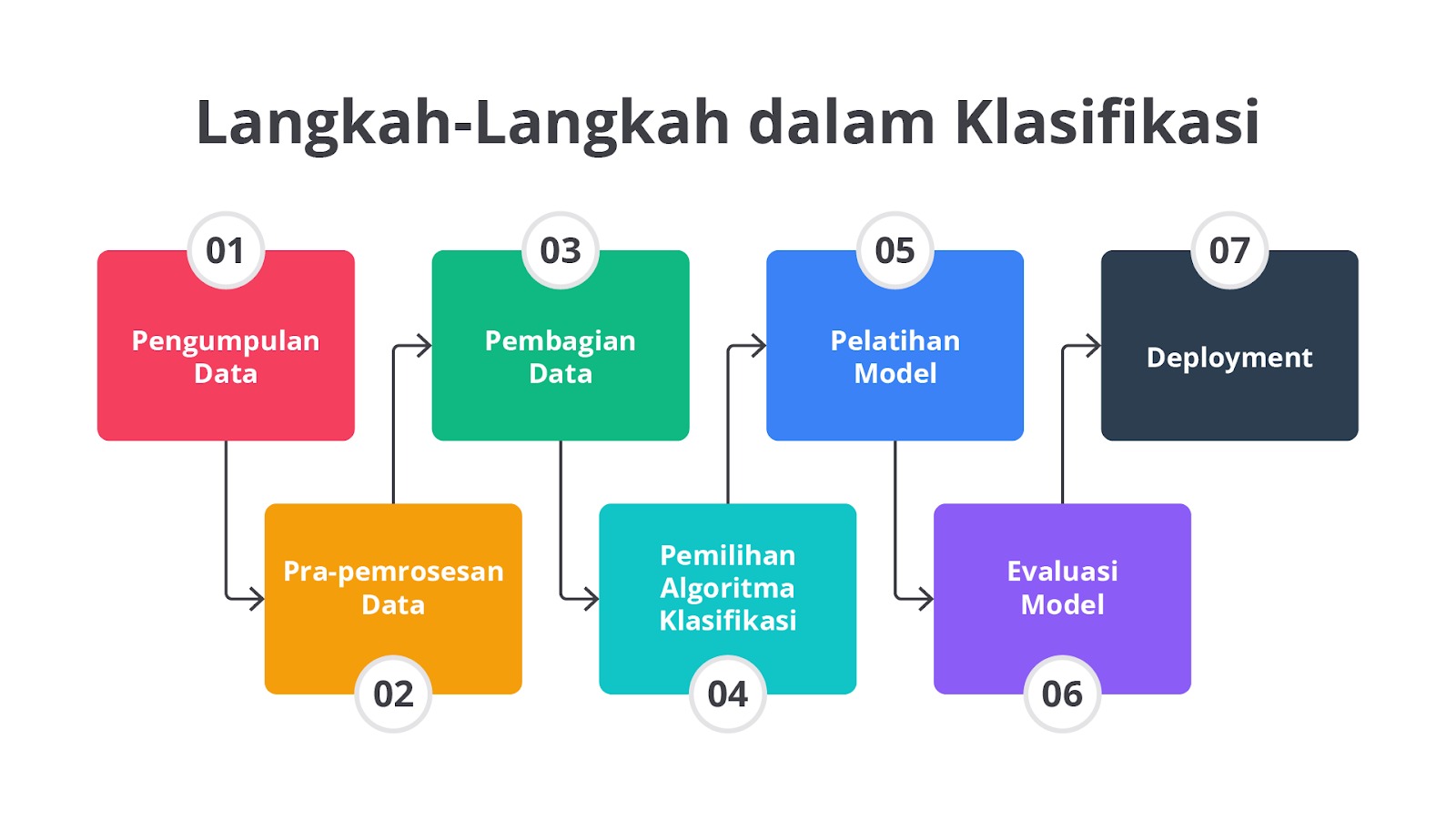
Nah, sekarang mari kita bahas setiap tahapan tersebut secara rinci!
Pengumpulan Data
Langkah pertama dalam proses klasifikasi adalah mengumpulkan data yang akan digunakan untuk melatih dan menguji model. Data ini harus relevan dengan masalah yang ingin diselesaikan serta memiliki kualitas yang baik, artinya data harus lengkap, akurat, dan representatif terhadap populasi data yang lebih luas.
Contoh: Kita ingin membangun model klasifikasi untuk mengidentifikasi jenis buah berdasarkan fitur, seperti ukuran, warna, dan bentuk. Berikut adalah beberapa contoh data yang kita kumpulkan.
| ID Buah | Ukuran (cm) | Warna | Bentuk | Label/Kategori |
|---|---|---|---|---|
1 | 8.5 | Merah | Bulat | Apel |
2 | 12 | Kuning | Lonjong | Pisang |
3 | 6 | Merah | Bulat | Apel |
4 | 7.5 | Oranye | Bulat | Jeruk |
… | … | … | … | … |
n | 9 | Merah | Bulat | Apel |
Pra-pemrosesan Data
Data yang dikumpulkan sering kali tidak langsung siap digunakan oleh model machine learning. Pra-pemrosesan data melibatkan serangkaian langkah untuk membersihkan dan mempersiapkan data. Langkah-langkah ini bisa mencakup penanganan data yang hilang, penghapusan duplikasi, menangani nilai yang tidak konsisten, mengonversi data ke format yang dapat diproses oleh algoritma, dan normalisasi atau standardisasi fitur.
Contoh: Dalam data buah di atas, kita perlu mengubah warna buah menjadi angka agar bisa digunakan oleh model, misalnya: Merah = 1, Kuning = 2, Hijau = 3, Oranye = 4. Data setelah pra-pemrosesan mungkin terlihat seperti ini.
| ID Buah | Ukuran (cm) | Warna | Bentuk | Label/Kategori |
|---|---|---|---|---|
1 | 8.5 | 1 | 1 | Apel |
2 | 12 | 2 | 2 | Pisang |
3 | 6 | 1 | 1 | Apel |
4 | 7.5 | 4 | 1 | Jeruk |
5 | 9 | 1 | 1 | Apel |
Pembagian Data
Setelah data diproses, langkah berikutnya adalah membagi data menjadi dua set utama, yaitu data pelatihan (training data) dan data pengujian (testing data). Biasanya, sekitar 70–80% dari data digunakan untuk melatih model, sedangkan sisanya digunakan untuk menguji kinerja model.
Namun, perlu diingat bahwa proporsi pembagian ini tidaklah mutlak. Terkadang, kita hanya menggunakan 1–10% data untuk pengujian atau validasi, tergantung pada jumlah data yang tersedia, kompleksitas model, dan kebutuhan spesifik dari proyek yang sedang dikerjakan.
Contoh: Dari 100 data buah yang kita miliki, kita membagi data tersebut menjadi 80 data untuk pelatihan dan 20 data untuk pengujian. Berikut adalah contoh data tersebut dibagi.
Data Pelatihan:
| ID Buah | Ukuran (cm) | Warna | Bentuk | Label/Kategori |
|---|---|---|---|---|
1 | 8.5 | 1 | 1 | Apel |
2 | 12 | 2 | 2 | Pisang |
3 | 6 | 3 | 1 | Apel |
… | … | … | … | … |
80 | 4 | 1 | 1 | Apel |
Data Pengujian:
| ID Buah | Ukuran (cm) | Warna | Bentuk | Label/Kategori |
|---|---|---|---|---|
81 | 9 | 1 | 1 | Apel |
82 | 7.5 | 4 | 1 | Jeruk |
83 | 10 | 2 | 2 | Pisang |
… | … | … | … | … |
n | 4 | 1 | 1 | Apel |
Pemilihan Algoritma Klasifikasi
Berbagai algoritma bisa digunakan untuk klasifikasi serta pemilihan algoritma bergantung pada jenis data, ukuran dataset, dan kompleksitas masalah. Setiap algoritma memiliki keunggulan dan kelemahan yang berbeda.
Pemilihan algoritma klasifikasi dipengaruhi oleh jenis data, ukuran dataset, dan kompleksitas masalah. Misalnya, data skala kecil sering cocok dengan algoritma sederhana, seperti Logistic Regression atau KNN, sementara dataset besar dan kompleks lebih sesuai untuk Random Forest atau SVM.
Kecepatan dan skalabilitas juga penting, terutama untuk aplikasi real time, seperti Naive Bayes atau Logistic Regression sering dipilih. Selain itu, interpretabilitas model perlu diperhatikan dalam domain sensitif dengan Decision Tree atau Logistic Regression menawarkan penjelasan yang lebih mudah dipahami dibandingkan model yang lebih kompleks.
Contoh: Kita memilih algoritma Decision Tree untuk mengklasifikasikan buah-buahan. Algoritma ini akan membuat keputusan berdasarkan fitur, seperti ukuran, warna, dan bentuk, untuk memutuskan bahwa suatu buah adalah apel, pisang, atau jeruk.
Decision Tree dipilih karena mudah diinterpretasikan; setiap keputusan yang dibuat oleh model dapat ditelusuri kembali melalui struktur pohon sehingga kita dapat dengan jelas memahami alasan suatu buah diklasifikasikan sebagai apel, pisang, atau jeruk. Selain itu, Decision Tree efektif dalam menangani data dengan fitur kategorikal dan numerik, serta mampu menangkap interaksi antara berbagai fitur secara baik.
Pelatihan Model
Pada tahap ini, data pelatihan model dilakukan untuk mengajarkan komputer mengenali pola dalam data dan membangun model klasifikasi berdasarkan algoritma yang digunakan. Algoritma bertugas untuk menganalisis hubungan antara fitur dan label untuk memprediksi kelas dari data baru.
Contoh: Model Decision Tree akan belajar bahwa buah dengan ukuran tertentu dan warna tertentu kemungkinan besar adalah apel. Selama pelatihan, model ini akan membangun struktur pohon keputusan yang memisahkan buah-buahan ke dalam kategori yang sesuai.
Evaluasi Model
Setelah model dilatih, kita perlu mengevaluasi kinerjanya menggunakan data pengujian. Evaluasi dilakukan menggunakan berbagai metrik, seperti akurasi, precision, recall, dan F1-Score.
Contoh: Jika model kita memprediksi 18 dari 20 buah dengan benar, akurasi model adalah 90%. Selain itu, kita juga akan memeriksa hasil klasifikasi untuk mengidentifikasi jenis buah yang sering salah diklasifikasikan oleh model. Dengan cara ini, kita dapat memahami kelemahan model dan memperbaikinya jika diperlukan.
Deployment
Setelah model diuji dan terbukti efektif, langkah terakhir adalah menerapkan model tersebut untuk memprediksi kelas dari data baru dalam aplikasi nyata.
Contoh: Model klasifikasi buah yang sudah dilatih dapat digunakan oleh pabrik untuk secara otomatis mengklasifikasikan buah-buahan yang baru dipanen berdasarkan ukuran dan warnanya, membantu proses penyortiran tanpa intervensi manusia.
Dengan mengikuti langkah-langkah ini secara sistematis, kita bisa memastikan bahwa model klasifikasi yang dibangun mampu memberikan prediksi akurat dan dapat diandalkan dalam situasi nyata.
Jenis-Jenis Klasifikasi
Klasifikasi merupakan salah satu fondasi utama dalam machine learning yang memungkinkan komputer untuk membuat keputusan cerdas berdasarkan data yang telah dipelajari. Dalam dunia yang semakin dipenuhi oleh data, kemampuan untuk mengklasifikasikan informasi dengan tepat menjadi sangat penting, baik dalam memahami pola tersembunyi maupun untuk membuat prediksi akurat.
Ada berbagai jenis klasifikasi yang dapat diterapkan. Pilihan jenis yang tepat sangat bergantung pada kompleksitas data serta tujuan spesifik yang ingin dicapai. Pemahaman mendalam tentang jenis-jenis klasifikasi ini tidak hanya memungkinkan kita untuk memilih pendekatan paling sesuai dengan sebuah masalah, tetapi juga membuka pintu inovasi dan peningkatan kinerja dalam implementasi machine learning yang lebih kompleks dan berdampak tinggi.
Berikut adalah jenis-jenis klasifikasi berdasarkan jumlah kelas atau label.
- Klasifikasi Biner
- Klasifikasi Multikelas
- Klasifikasi Multilabel
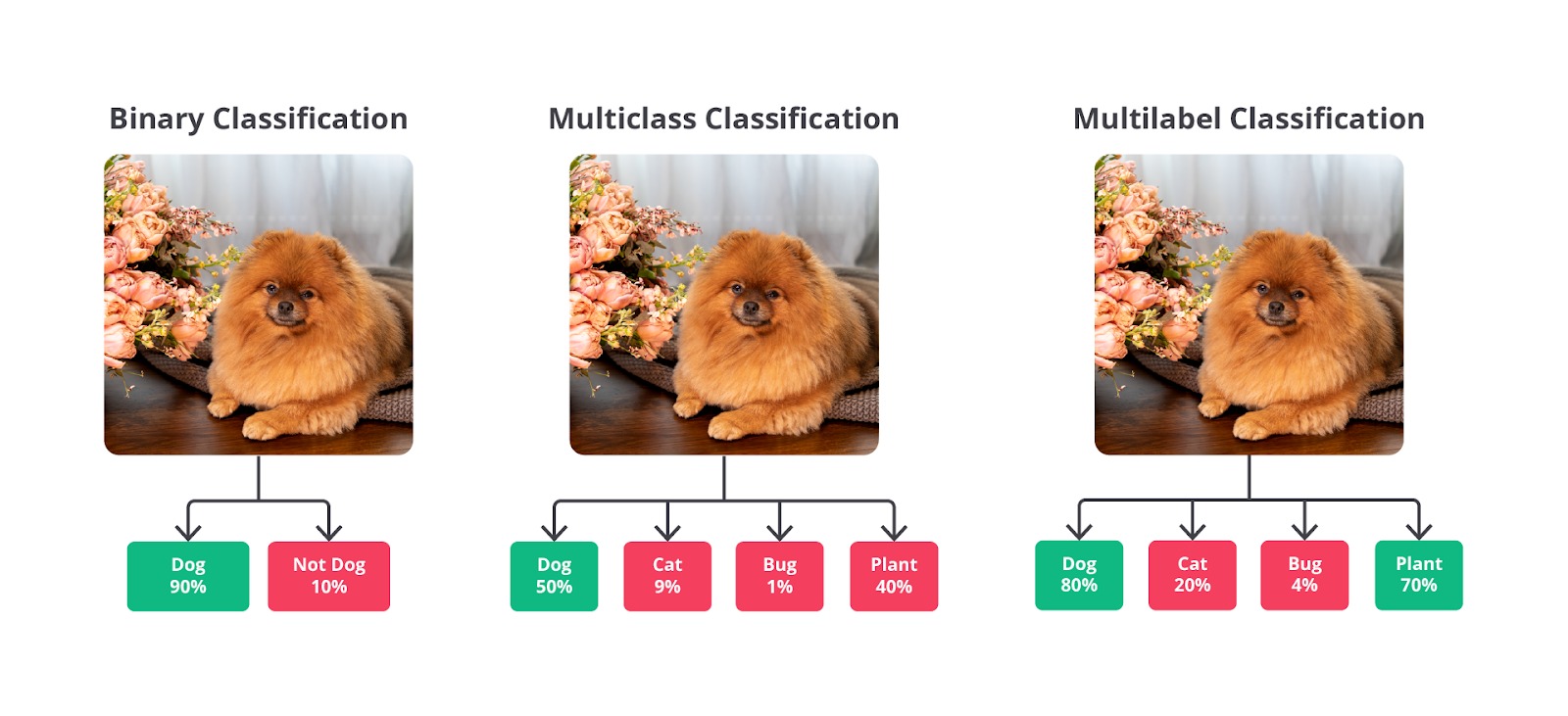 Nah, selanjutnya mari kita bahas setiap jenis tersebut secara rinci!
Nah, selanjutnya mari kita bahas setiap jenis tersebut secara rinci!
Klasifikasi Biner (Binary Classification)
Klasifikasi biner adalah tipe klasifikasi dengan mengelompokkan data ke dalam dua kategori atau label yang berbeda. Dengan kata lain, model hanya memiliki dua pilihan untuk mengelompokkan data, yaitu kategori pertama atau kategori kedua. Misalnya, sebuah sistem perlu menentukan jenis sebuah email termasuk spam atau bukan.
Proses klasifikasi biner dimulai dengan pelatihan model menggunakan dataset yang sudah diberi label. Artinya, setiap contoh data sudah diketahui kelasnya. Model ini kemudian belajar dari fitur-fitur dalam data tersebut untuk membedakan antara dua kelas.
Misalnya, dalam kasus deteksi email spam, fitur-fitur, seperti frekuensi kata tertentu, panjang subjek, atau adanya lampiran tertentu bisa digunakan untuk mempelajari pola yang membedakan email spam dari yang tidak spam.
Setelah dilatih, model klasifikasi biner digunakan untuk memprediksi kelas dari data baru yang belum dikenal. Setiap input data akan dianalisis oleh model dan memberikan output berupa salah satu dari dua kelas tersebut. Output ini bisa dalam bentuk keputusan yang pasti (misalnya, "spam" atau "tidak spam") atau probabilitas (contohnya, 70% spam, 30% tidak spam), tergantung pada implementasi model.
Klasifikasi biner sering kali digunakan dalam berbagai aplikasi dunia nyata karena kesederhanaannya dan efektivitasnya untuk menyelesaikan masalah yang memerlukan keputusan ya/tidak. Misalnya, dalam deteksi penipuan, sistem dapat memutuskan transaksi tertentu adalah penipuan atau tidak. Dalam diagnosis medis, model dapat membantu dokter dalam memutuskan sebuah status pasien apabila menunjukkan tanda-tanda penyakit tertentu.
Namun, meskipun sederhana, klasifikasi biner juga memiliki tantangan tersendiri, terutama ketika data tidak seimbang, yaitu salah satu kelas jauh lebih banyak dibandingkan kelas lainnya. Ini sering memerlukan teknik-teknik khusus, seperti oversampling, undersampling, atau penyesuaian threshold untuk memastikan model tidak hanya fokus pada kelas yang lebih dominan dan mengabaikan kelas minoritas.
Klasifikasi Multikelas (Multiclass Classification)
Klasifikasi multikelas (multiclass classification) adalah teknik klasifikasi yang digunakan ketika data harus dikelompokkan ke dalam lebih dari dua kategori. Berbeda dengan klasifikasi biner yang hanya memiliki dua kelas, klasifikasi multikelas mengharuskan model untuk memilih satu dari beberapa kelas yang mungkin ada.
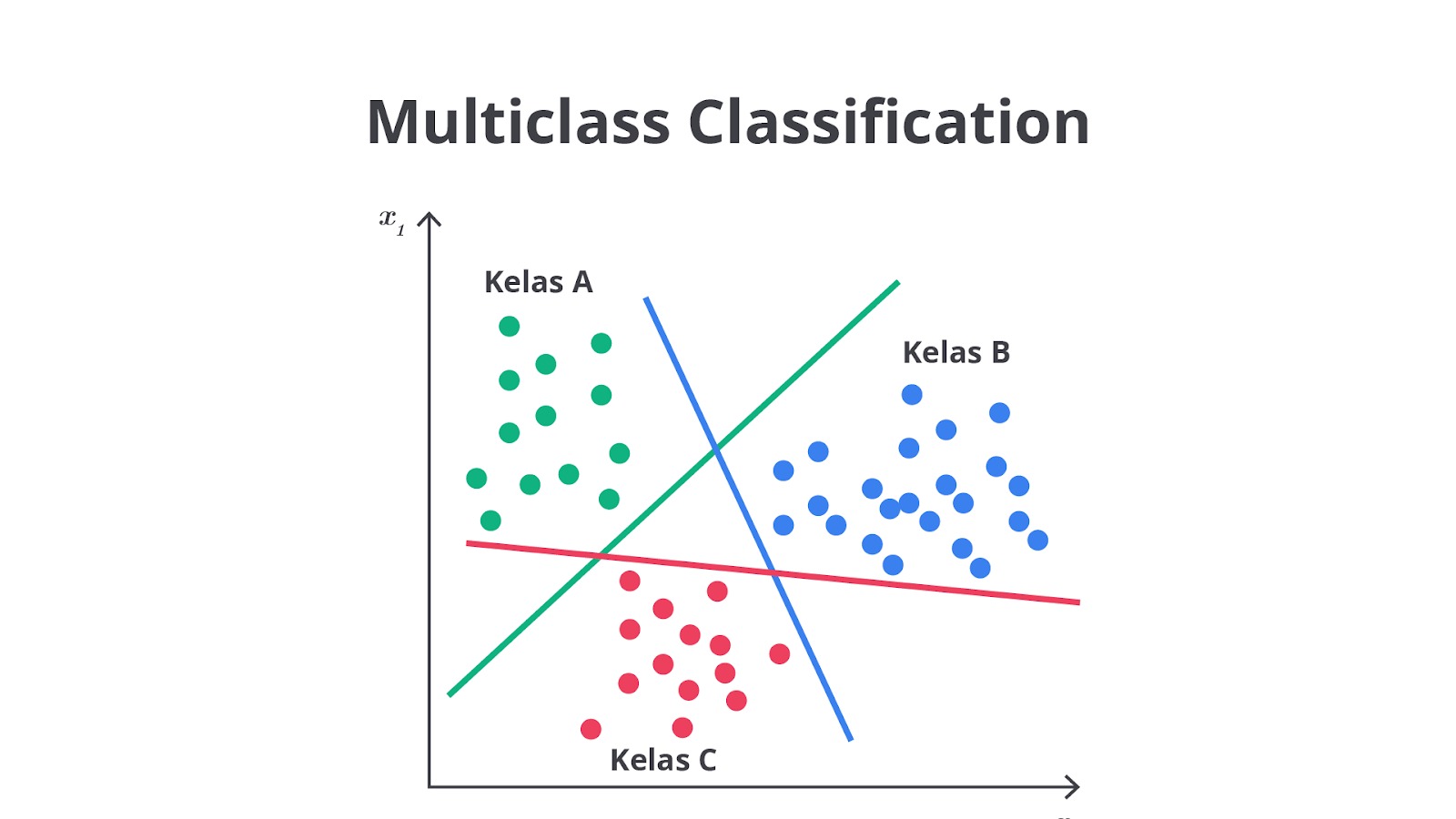
Ini berarti bahwa setiap data hanya bisa dimasukkan ke salah satu dari beberapa kategori yang sudah ditentukan. Artinya, sebuah data hanya bisa berada dalam satu kategori saja dan tidak bisa masuk kategori lain.
Untuk memecahkan masalah klasifikasi multikelas, model machine learning perlu belajar untuk membedakan antara banyak kelas yang berbeda. Misalnya, dalam pengenalan gambar, model mungkin harus memutuskan bahwa gambar tersebut adalah anjing, kucing, atau katak.
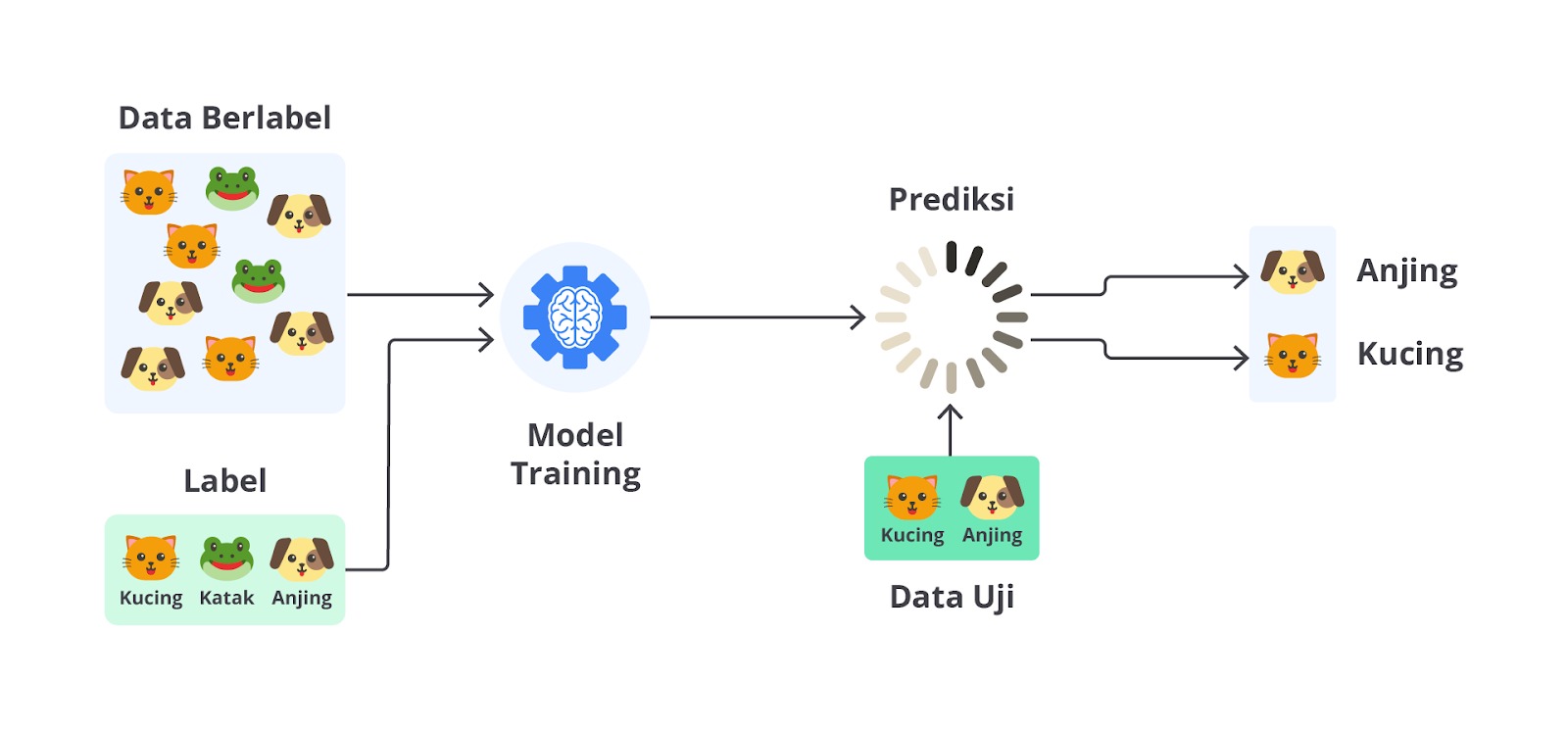
Setiap gambar pada dataset pelatihan diberi label sesuai dengan salah satu dari beberapa kategori ini. Model dilatih untuk mengenali fitur yang membedakan setiap kelas, seperti bentuk, tekstur, atau pola warna, kemudian digunakan untuk mengklasifikasikan gambar baru ke dalam kategori yang sesuai.
Proses pelatihan model untuk klasifikasi multikelas melibatkan beberapa langkah kunci.
- Persiapan Dataset: siapkan dataset pelatihan yang berisi contoh-contoh dari setiap kelas, termasuk fitur-fitur yang relevan dan label yang benar.
- Pemilihan Algoritma: pilih algoritma klasifikasi yang mampu menangani lebih dari dua kelas.
- Pelatihan Model: latih model menggunakan dataset tersebut, yakni model belajar mengidentifikasi pola dan fitur yang membedakan setiap kelas.
- Pengujian Model: uji model pada data yang belum pernah dilihat sebelumnya untuk menilai kemampuannya dalam mengklasifikasikan data ke dalam kategori yang benar.
Klasifikasi Multilabel (Multilabel Classification)
Klasifikasi multilabel (multilabel classification) adalah metode yang memungkinkan sebuah data dikategorikan ke dalam lebih dari satu label atau kategori sekaligus. Berbeda dengan klasifikasi multikelas yang membatasi data hanya pada satu kategori dari beberapa opsi, klasifikasi multilabel memberikan fleksibilitas lebih besar dengan memungkinkan satu sampel data untuk memiliki beberapa label.
Proses klasifikasi multilabel melibatkan pelatihan model menggunakan dataset yang setiap sampelnya memiliki beberapa label. Model belajar mengenali pola yang menghubungkan fitur-fitur data dengan berbagai label. Setelah dilatih, model dapat memprediksi beberapa label yang relevan untuk data baru. Klasifikasi multilabel sangat berguna untuk data yang tidak dapat dibatasi pada satu kategori dan memberikan kemampuan dalam menangani data lebih kompleks.
Pengenalan Algoritma Klasifikasi
Di dunia machine learning, algoritma klasifikasi adalah alat yang digunakan untuk mengelompokkan data ke dalam kategori atau kelas tertentu berdasarkan karakteristik pada data tersebut. Berbagai algoritma klasifikasi tersedia, masing-masing dengan pendekatan dan keunggulannya sendiri. Berikut adalah beberapa algoritma klasifikasi yang paling umum digunakan.
K-Nearest Neighbors (KNN)
KNN adalah algoritma yang mengklasifikasikan data berdasarkan kedekatannya dengan data lain yang sudah diberi label. Data baru diklasifikasikan ke dalam kelas yang paling umum di antara tetangga terdekatnya. KNN sangat sederhana, tetapi efektif, terutama ketika data memiliki pola yang jelas.
Decision Tree
Decision Tree menggunakan struktur pohon untuk membuat keputusan klasifikasi. Setiap cabang pohon mewakili tes pada fitur tertentu dan setiap daun mewakili keputusan atau prediksi. Algoritma ini populer karena mudah diinterpretasikan dan dapat menangani data yang tidak terstruktur dengan baik.
Random Forest
Random Forest adalah versi lanjutan dari Decision Tree yang menggunakan banyak pohon keputusan untuk meningkatkan akurasi prediksi. Algoritma ini menggabungkan hasil beberapa pohon keputusan yang dibangun dari sampel acak dataset sehingga mengurangi risiko overfitting dan memberikan hasil lebih stabil.
Support Vector Machine (SVM)
SVM adalah algoritma yang mencoba menemukan garis atau bidang optimal yang memisahkan data ke dalam dua kelas dengan margin paling besar. Algoritma ini sangat efektif untuk data yang terpisah dengan jelas dan dapat digunakan untuk klasifikasi biner ataupun multikelas.
Naive Bayes
Naive Bayes adalah algoritma probabilistik yang didasarkan pada Teorema Bayes. Algoritma ini mengasumsikan bahwa semua fitur dalam data independen satu sama lain meskipun pada kenyataannya hal ini jarang terjadi. Namun, asumsi sederhana ini sering kali cukup kuat untuk memberikan hasil yang baik, terutama dalam kasus klasifikasi teks.
Logistic Regression
Meskipun namanya menyiratkan regresi, logistic regression sebenarnya adalah algoritma klasifikasi. Algoritma ini digunakan untuk memprediksi probabilitas sebuah sampel masuk pada kategori tertentu. Logistic regression sangat umum digunakan dalam kasus klasifikasi biner.
Neural Networks
Neural networks, khususnya jaringan saraf dalam (deep neural networks), adalah algoritma yang meniru cara kerja otak manusia untuk mempelajari pola dalam data. Algoritma ini sangat kuat serta dapat digunakan untuk menangani masalah klasifikasi yang sangat kompleks, termasuk pengenalan gambar dan pengolahan bahasa alami.
Setiap algoritma ini memiliki kelebihan dan kekurangan masing-masing. Pemilihan algoritma yang tepat sering kali tergantung pada karakteristik data dan tujuan spesifik dari analisis. Memahami cara kerja setiap algoritma bekerja adalah langkah penting dalam membangun model machine learning yang efektif dan akurat.
[Story] Beda Algoritma Beda Juga Cara Kerjanya? Kok Bisa?
Setelah beberapa hari mempelajari klasifikasi di ruang belajar kampus, Diana dan Bilqis memutuskan untuk berpindah ke tempat yang berbeda untuk melanjutkan eksplorasi mereka. Mereka memilih sebuah coworking space yang terletak di tepi hutan kota dengan suasana alami serta memberikan ketenangan yang menyegarkan.

Saat mereka tiba di coworking space tersebut, mereka langsung disambut oleh suasana yang tenang dan pemandangan hijau yang menyegarkan. Ruang kerja yang sederhana, tetapi nyaman ini dikelilingi oleh jendela besar menghadap ke taman dengan pepohonan hijau dan rumput yang subur. Suasana ini benar-benar memberikan suasana segar untuk belajar.
Diana dan Bilqis memilih meja di dekat jendela agar bisa menikmati pemandangan sambil belajar. Dengan laptop di atas meja dan secangkir kopi hangat di sampingnya, mereka mulai mengerjakan materi tentang algoritma klasifikasi yang ingin mereka pelajari lebih lanjut.
"Wah, enaknya belajar di sini," kata Diana sambil menikmati udara segar. "Pemandangannya bikin betah, ya?"
“Betul! Berasa cuci mata,” jawab Bilqis.
Bilqis mulai menjelaskan, "Oke, mari kita mulai dengan K-Nearest Neighbors. Algoritma ini bekerja dengan mencari ‘K’ tetangga terdekat dari data yang ingin kita klasifikasikan. Misalnya, jika kita ingin mengetahui jenis biji kopi, KNN akan melihat biji kopi lain yang sudah dikenal jenisnya dan melihat mayoritas jenis dari tetangga terdekat."

Diana mengangguk, "Jadi, KNN itu seperti bertanya kepada teman-teman terdekat untuk menentukan jenis biji kopi kita?"
"Betul sekali!" Bilqis melanjutkan, "Sekarang, Decision Tree berbeda sedikit. Dia membagi data berdasarkan fitur-fitur tertentu untuk membuat keputusan. Bayangkan seperti pohon keputusan yang bercabang berdasarkan pertanyaan, seperti 'Apakah biji kopi ini memiliki ukuran lebih besar?' dan seterusnya."
"Menarik juga, ya!" kata Diana. "Kalau Random Forest, gimana?"
"Random Forest itu sebenarnya gabungan dari banyak Decision Tree. Jadi, daripada satu pohon keputusan, kita punya banyak pohon yang bekerja sama. Setiap pohon memberikan suara dan kita ambil suara mayoritas. Ini membuat model lebih stabil dan akurat," jelas Bilqis sambil menunjuk ke diagram yang ia buat di catatannya.
"Kalau SVM?" tanya Diana dengan antusias.
"SVM mencari hyperplane terbaik yang memisahkan data ke dalam kategori yang berbeda. Jadi, dia berusaha menemukan garis atau bidang yang paling baik memisahkan data dari dua kelas yang berbeda," jelas Bilqis. "Dan terakhir, Naive Bayes itu berdasarkan probabilitas. Dia menghitung kemungkinan setiap fitur muncul dalam suatu kelas dan memprediksi berdasarkan probabilitas tersebut."

Diana tampak penasaran, "Jadi, Naive Bayes itu bagaimana cara kerjanya?"
Bilqis menjelaskan sambil tersenyum, "Naive Bayes mengasumsikan bahwa setiap fitur dalam data independen satu sama lain. Jadi, dia menghitung probabilitas setiap fitur untuk setiap kelas dan menggabungkannya untuk memprediksi kelas mana yang paling mungkin. Misalnya, untuk biji kopi, kita akan menghitung probabilitas setiap fitur, seperti ukuran, warna, dan bentuk biji kopi untuk menentukan jenisnya."
Diana mengangguk sambil menutup laptopnya, "Keren! Aku rasa kita sudah siap untuk menerapkan algoritma-algoritma ini dalam proyek kita. Ayo kita coba dan lihat bagaimana hasilnya."
Bilqis setuju dan mereka berdua melanjutkan belajar dengan semangat baru. Suasana hijau di sekitar mereka membuat proses belajar semakin menyenangkan dan mereka siap untuk mengeksplorasi lebih dalam tentang algoritma klasifikasi pada proyek mereka yang akan datang.
K-Nearest Neighbors (KNN)
Algoritma K-Nearest Neighbors (KNN) adalah metode supervised learning yang digunakan untuk mengatasi masalah klasifikasi dan regresi. Evelyn Fix dan Joseph Hodges mengembangkan algoritma ini pada tahun 1951 yang kemudian diperluas oleh Thomas Cover. KNN merupakan salah satu algoritma klasifikasi yang paling sederhana dan intuitif dalam machine learning.
Algoritma ini digunakan untuk mengklasifikasikan data baru berdasarkan kedekatannya dengan data yang sudah diberi label dalam dataset pelatihan. KNN sering digunakan karena kemudahannya dalam pemahaman dan implementasi meskipun pada praktiknya, ia dapat menjadi sangat efektif untuk berbagai masalah klasifikasi.
Parameter Utama KNN
Dalam algoritma KNN, beberapa parameter utama perlu diatur untuk mengoptimalkan performa model. Inilah beberapa di antaranya.
- Jumlah Tetangga (K)
- Metric Jarak
- Bobot (Weights)
- Panjang Jarak (Distance Metric Parameters)
- Normalisasi Data
- Algoritma Pencarian Tetangga
Mari kita bahas lebih lengkap masing-masing parameternya!
Jumlah Tetangga (K) atau n_neighbors (default = 5)
Parameter ini menentukan jumlah tetangga terdekat yang akan dipertimbangkan ketika membuat prediksi. Misalnya, K = 5 maka algoritma akan mencari lima tetangga terdekat dari data baru dan menggunakannya untuk menentukan kelas atau nilai prediksi.
Berikut adalah beberapa kategori jenis nilai K-nya.
- Nilai K Kecil: Jika K terlalu kecil (misalnya, K = 1), model akan sangat sensitif terhadap noise dan outlier karena hanya mempertimbangkan satu tetangga. Ini sering menyebabkan overfitting karena model terlalu sesuai dengan data pelatihan dan kurang mampu generalisasi pada data baru.
- Nilai K Besar: Jika K terlalu besar (misalnya, K = 20), model akan lebih stabil dan kurang terpengaruh oleh noise, tetapi dapat terlalu umum (underfitting). Ini akan memengaruhi hasil berdasarkan tetangga yang lebih jauh dan mengabaikan detail penting dari data pelatihan.
Metric Jarak (default = minkowski)
Metrik jarak digunakan untuk mengukur seberapa dekat atau mirip dua titik dalam ruang fitur. Metrik yang berbeda dapat mengukur jarak atau kesamaan dengan cara berbeda. Ini memengaruhi pemilihan tetangga terdekat.
Pilihan metrik memengaruhi hasil jarak yang dihitung dari titik data dan tetangga terdekat. Metrik berbeda dapat memberikan hasil berbeda tergantung pada sifat data dan fitur yang ada.
Berikut adalah beberapa jenis metrik jarak pada KNN.
- Euclidean Distance: Ini mengukur jarak garis lurus antara dua titik dalam ruang fitur. Ini adalah jenis jarak yang paling umum digunakan. Berikut rumusnya.

- Manhattan Distance: Ini mengukur jarak berdasarkan jumlah perbedaan sepanjang sumbu koordinat. Berikut rumusnya.

- Minkowski Distance: Generalisasi dari Euclidean dan Manhattan Distance yang bergantung pada parameter p. Berikut rumusnya.

- Cosine Similarity: Ini mengukur kesamaan sudut antara dua vektor, biasanya digunakan untuk data teks. Berikut rumusnya.

Bobot (Weights) (default = uniform)
Bobot menentukan seberapa besar pengaruh setiap tetangga terdekat terhadap keputusan prediksi. Bobot yang diberikan akan memengaruhi keputusan akhir pada proses pelatihan. Ada dua jenis bobot yang umum digunakan.
- Uniform: Setiap tetangga dianggap memiliki pengaruh yang sama dalam menentukan hasil prediksi. Ini berarti semua tetangga, tidak peduli seberapa dekat atau jauhnya, memberikan kontribusi yang sama terhadap keputusan akhir.
- Distance: Tetangga yang lebih dekat mendapatkan bobot lebih besar, artinya, tetangga yang lebih dekat akan memberikan kontribusi lebih signifikan terhadap keputusan prediksi. Bobot dihitung terbalik sebanding dengan jarak sehingga semakin dekat tetangga, semakin besar pengaruhnya.
Panjang Jarak (Distance Metric Parameters)
Beberapa metrik jarak menggunakan parameter tambahan untuk mengatur cara perhitungan jarak. Ini memungkinkan penyesuaian metrik jarak dengan karakteristik data. Salah satu parameter yang sering digunakan adalah parameter p (power parameter) dalam minkowski distance.
Normalisasi Data
Normalisasi adalah proses menyesuaikan skala fitur sehingga fitur berada dalam rentang yang serupa agar perhitungan jarak menjadi adil. Normalisasi memastikan bahwa fitur dengan rentang nilai yang berbeda tidak mendominasi perhitungan jarak, yang membantu meningkatkan akurasi model KNN.
Ada dua teknik umum normalisasi data pada algoritma KNN sebagai berikut.
- Standardisasi: mengubah data sehingga memiliki mean 0 dan standar deviasi 1. Ini sering digunakan untuk membuat fitur memiliki skala yang konsisten.
- Normalisasi Min-Max: mengubah data sehingga berada dalam rentang 0 hingga 1. Ini berguna untuk data yang tidak terdistribusi secara normal.
Algoritma Pencarian Tetangga (default = auto)
Memilih algoritma pencarian yang tepat dapat memengaruhi kecepatan dan efisiensi model KNN, terutama untuk dataset besar atau dengan banyak fitur. Jenis-jenisnya berikut.
- Brute Force: Metode sederhana yang menghitung jarak antara data baru dan setiap titik dalam dataset pelatihan secara langsung. Ini bisa sangat lambat untuk dataset besar karena kompleksitas waktu yang tinggi.
- KD-Tree: Struktur data yang membagi ruang fitur menjadi beberapa area berdasarkan dimensi fitur. Ini mempercepat pencarian tetangga terdekat dengan mengurangi jumlah perhitungan jarak yang diperlukan untuk dataset berdimensi rendah hingga sedang.
- Ball-Tree: Struktur data yang membagi ruang fitur menggunakan volume berbasis partisi, cocok untuk data berdimensi tinggi dengan performa pencarian yang lebih baik dibandingkan KD-Tree.
Cara Kerja KNN
K-Nearest Neighbors (KNN) adalah algoritma yang sangat sederhana, tetapi efektif untuk masalah klasifikasi. KNN bekerja dengan cara mengklasifikasikan titik data baru berdasarkan mayoritas kelas dari beberapa tetangga terdekatnya dalam ruang fitur.
KNN efektif karena dapat digunakan dengan berbagai jenis data tanpa perlu asumsi rumit tentang distribusi data. Algoritma ini non-parametrik, artinya tidak perlu pelatihan khusus—hanya menyimpan data dan menghitung jarak saat prediksi. Hal ini membuat KNN fleksibel dan cocok untuk masalah klasifikasi dengan pola data yang beragam atau tidak linear.
Berikut adalah penjelasan cara kerja Algoritma KNN.
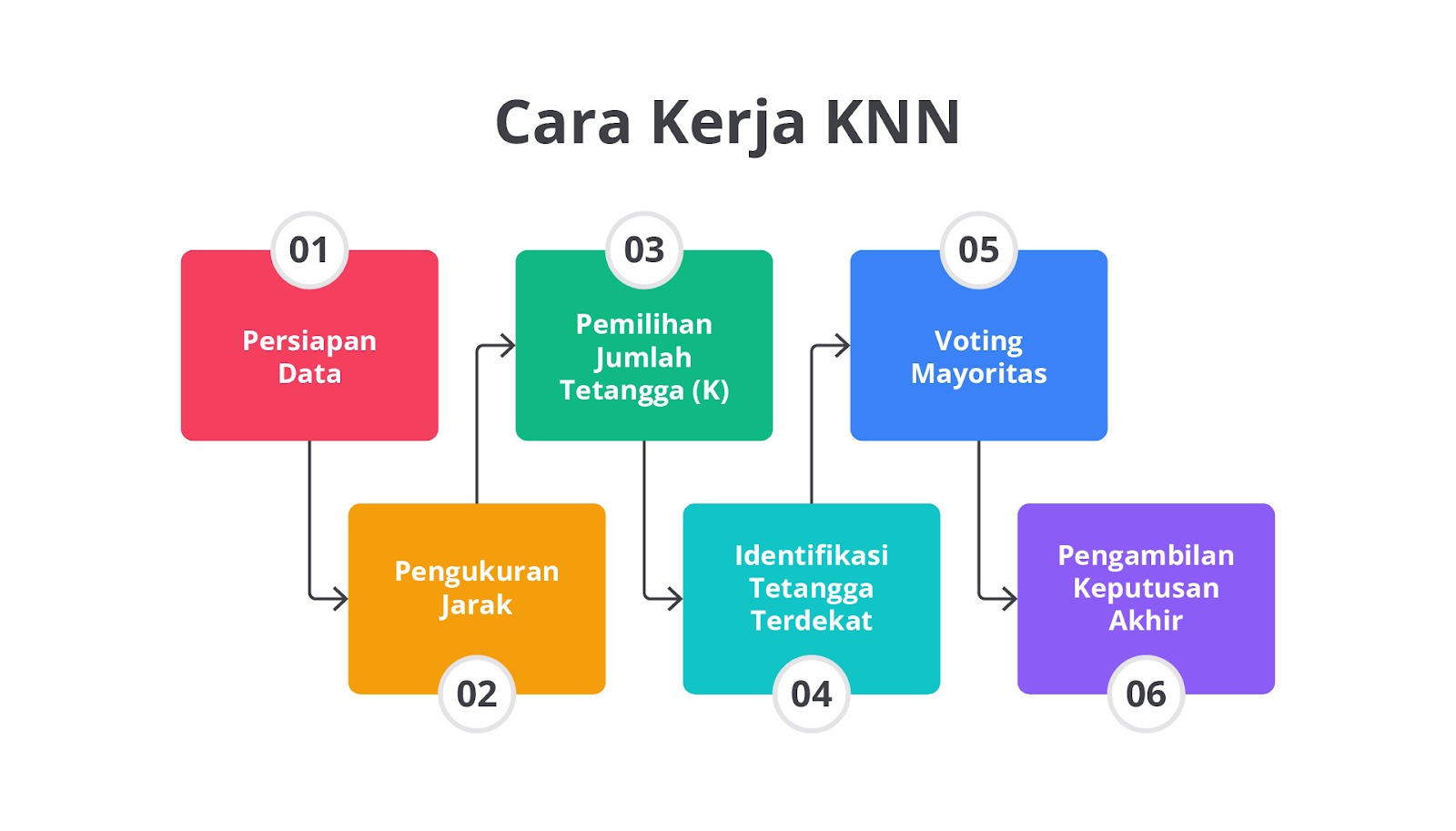
Langkah 1: Persiapan Data
Sebelum algoritma KNN dapat digunakan, langkah pertama adalah mempersiapkan dataset. Dataset ini terdiri dari contoh-contoh data yang sudah diberi label. Setiap contoh memiliki sejumlah fitur (atribut) dan label kelas (kategori) yang diketahui.
Misalkan kita memiliki dataset yang mencakup tinggi dan berat dari beberapa individu, serta label yang menunjukkan bahwa individu tersebut tergolong sehat atau tidak sehat.
Langkah 2: Pengukuran Jarak
Ketika ada data baru yang ingin diklasifikasikan, langkah pertama KNN adalah menghitung jarak antara data baru ini dengan setiap data lain dalam dataset pelatihan. Pengukuran jarak bertujuan untuk menentukan seberapa mirip data baru dengan data yang sudah ada.
Pengukuran jarak yang paling umum digunakan adalah euclidean distance, tetapi metode lain, seperti manhattan distance atau minkowski distance juga bisa digunakan tergantung pada jenis data.
Langkah 3: Pemilihan Jumlah Tetangga (K)
Nilai K adalah parameter penting dalam KNN. Ini menentukan berapa banyak tetangga terdekat yang akan dipertimbangkan untuk mengklasifikasikan data baru. Pemilihan K yang tepat sangat penting untuk kinerja model.
Langkah 4: Identifikasi Tetangga Terdekat
Setelah K ditentukan, KNN akan mengidentifikasi K tetangga terdekat dari data baru berdasarkan jarak yang telah dihitung. Tetangga terdekat adalah data-data dalam dataset pelatihan yang memiliki jarak paling kecil dengan data baru.
Contohnya, jika K = 3, KNN akan memilih tiga data yang paling dekat dengan data baru.
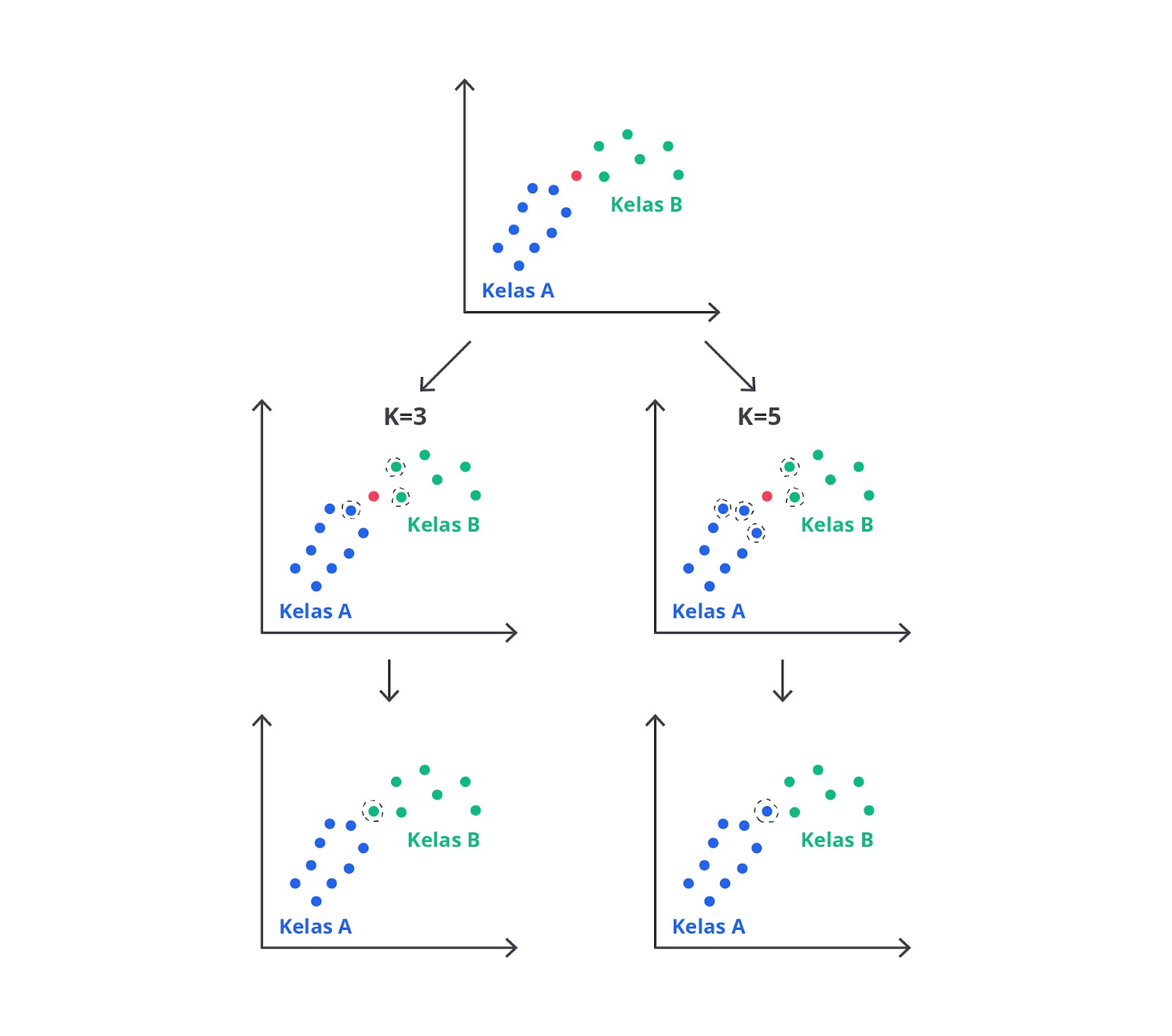
Langkah 5: Voting Mayoritas
Setelah K tetangga terdekat diidentifikasi, langkah berikutnya adalah melakukan voting untuk menentukan kelas dari data baru. Setiap tetangga akan “memilih” kelasnya dan kelas yang mendapat suara terbanyak akan menjadi prediksi untuk data baru.
Contohnya, jika dua dari tiga tetangga terdekat memiliki label "Sehat" dan satu tetangga memiliki label "Tidak Sehat", data baru tersebut akan diklasifikasikan sebagai "Sehat" karena mayoritas tetangga terdekatnya memiliki label tersebut.
Langkah 6: Pengambilan Keputusan Akhir
Kelas mayoritas dari tetangga terdekat inilah yang akan menjadi prediksi akhir KNN untuk data baru. Prediksi ini kemudian dapat digunakan untuk memberikan informasi atau mengambil tindakan lebih lanjut berdasarkan klasifikasi yang dilakukan.
Kelebihan dan Kekurangan KNN
Sebagaimana algoritma lainnya, KNN memiliki kelebihan dan kekurangan yang perlu dipertimbangkan sebelum diimplementasikan dalam suatu proyek. Memahami kekuatan dan kelemahan KNN sangat penting untuk menentukan algoritma ini sesuai atau tidak dengan kebutuhan spesifik dari masalah yang dihadapi.
| Kelebihan KNN | Kekurangan KNN |
|---|---|
Simpel dan Intuitif: mudah dipahami dan diimplementasikan tanpa banyak asumsi. | Komputasi Berat untuk Dataset Besar: perhitungan jarak untuk setiap prediksi membuat KNN lambat pada dataset besar. |
Non-parametrik: tidak mengasumsikan distribusi data tertentu, cocok untuk berbagai jenis data. | Sensitif terhadap Noise: data yang tidak sesuai atau fitur yang tidak relevan dapat menurunkan akurasi prediksi. |
Efektif untuk Dataset Kecil: ideal untuk dataset kecil dengan interpretasi langsung dan hasil cepat. | Memori Intensif: membutuhkan penyimpanan seluruh dataset pelatihan dalam memori, meningkatkan kebutuhan memori pada dataset besar. |
Dengan memahami waktu dan proses KNN bekerja dengan baik, pengguna dapat memanfaatkan kelebihan algoritma ini secara optimal sambil mengantisipasi tantangan yang mungkin timbul.
Decision Tree
Decision Tree adalah algoritma machine learning yang sering digunakan dalam tugas klasifikasi dan regresi. Struktur dari algoritma ini mirip dengan bentuk pohon dengan setiap cabang mewakili keputusan atau percabangan dari data berdasarkan fitur-fitur yang ada.
Struktur dasar dari Decision Tree melibatkan tiga komponen utama, yaitu akar (root node), node (decision node), dan daun (leaf node). Root node mewakili seluruh dataset dan menjadi titik awal untuk pemisahan data. Node-node di sepanjang cabang pohon mewakili keputusan yang diambil berdasarkan fitur tertentu, sedangkan leaf node adalah hasil akhir dari proses klasifikasi atau regresi, seperti label kelas atau nilai numerik.
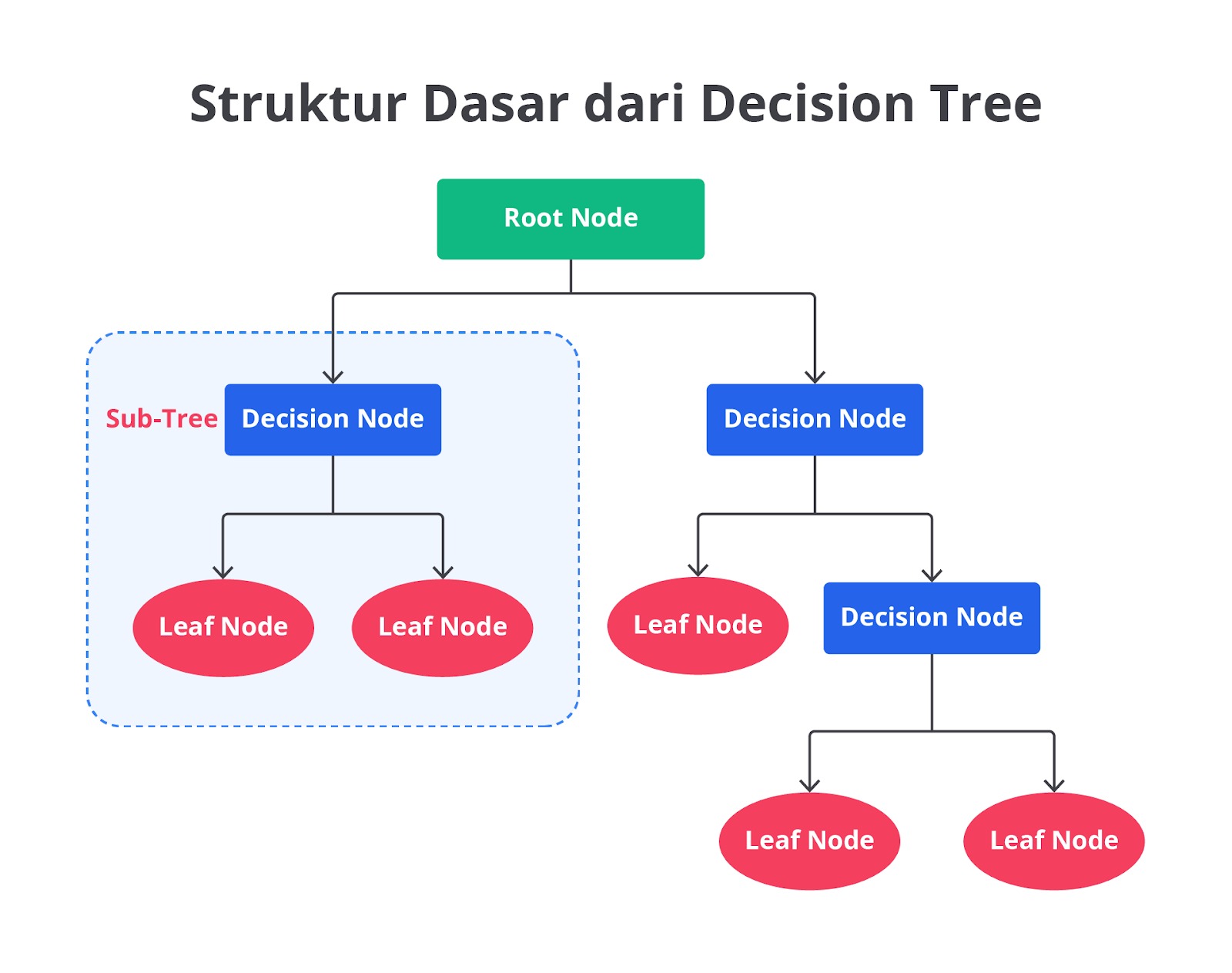
Parameter Utama Decision Tree
Dalam algoritma Decision Tree, beberapa parameter utama perlu diatur untuk mengoptimalkan performa model. Inilah beberapa di antaranya.
- Kriteria (Criterion)
- Maksimal Kedalaman (max_depth)
- Jumlah Minimum Sampel untuk Split (min_samples_split)
- Jumlah Minimum Sampel untuk Daun (min_samples_leaf)
- Jumlah Maksimum Fitur untuk Pembagian (max_features)
- Splitter
Mari kita bahas lebih lengkap masing-masing parameternya!
Kriteria (Criterion): {“gini”, “entropy”, “log_loss”}, default=”gini”
Kriteria (criterion) dalam algoritma Decision Tree adalah metode yang digunakan untuk menilai kualitas dari pembagian data pada setiap node dalam pohon keputusan. Kriteria ini membantu menentukan fitur yang harus digunakan untuk membagi data pada node tertentu dan cara terbaik pembagian tersebut dilakukan.
Ada dua jenis kriteria yang umum digunakan dan masing-masing memiliki cara unik dalam mengukur kualitas pembagian. Mari kita bahas lebih detail beberapa kriteria yang sering digunakan.
- Gini Impurity
Gini Impurity mengukur seberapa sering suatu data dalam satu kelompok bisa salah diklasifikasikan jika kita memilih label secara acak. Gini Impurity digunakan karena mudah dan cepat dihitung serta membantu memastikan bahwa pembagian data dalam pohon keputusan (Decision Tree) menghasilkan kelompok yang paling murni atau pasti. Dengan kata lain, Gini Impurity berusaha meminimalkan kemungkinan kesalahan dalam klasifikasi pada setiap node setelah data dibagi.
Rumus Gini Impurity sebagai berikut. Dalam interpretasinya, Gini Impurity dibagi menjadi dua sebagai berikut.
Dalam interpretasinya, Gini Impurity dibagi menjadi dua sebagai berikut.- Gini = 0: node sepenuhnya murni (hanya memiliki satu kelas).
- Gini > 0: node mengandung campuran beberapa kelas.
- Entropy
Entropy mengukur tingkat ketidakpastian atau keacakan data dalam sebuah node. Jika data dalam node tersebar merata pada berbagai kelas, Entropy akan tinggi, menunjukkan bahwa sulit untuk memprediksi kelas data. Sebaliknya, jika data lebih terfokus pada satu kelas, Entropy rendah, artinya lebih mudah untuk memprediksi kelas data dari node tersebut.
Dalam algoritma ID3 dan C4.5, Entropy digunakan untuk menentukan cara terbaik membagi data dengan mengurangi ketidakpastian sebanyak mungkin. Jadi, algoritma akan memilih pembagian yang membuat data pada node lebih teratur dan mudah diprediksi.
Rumus Entropy sebagai berikut.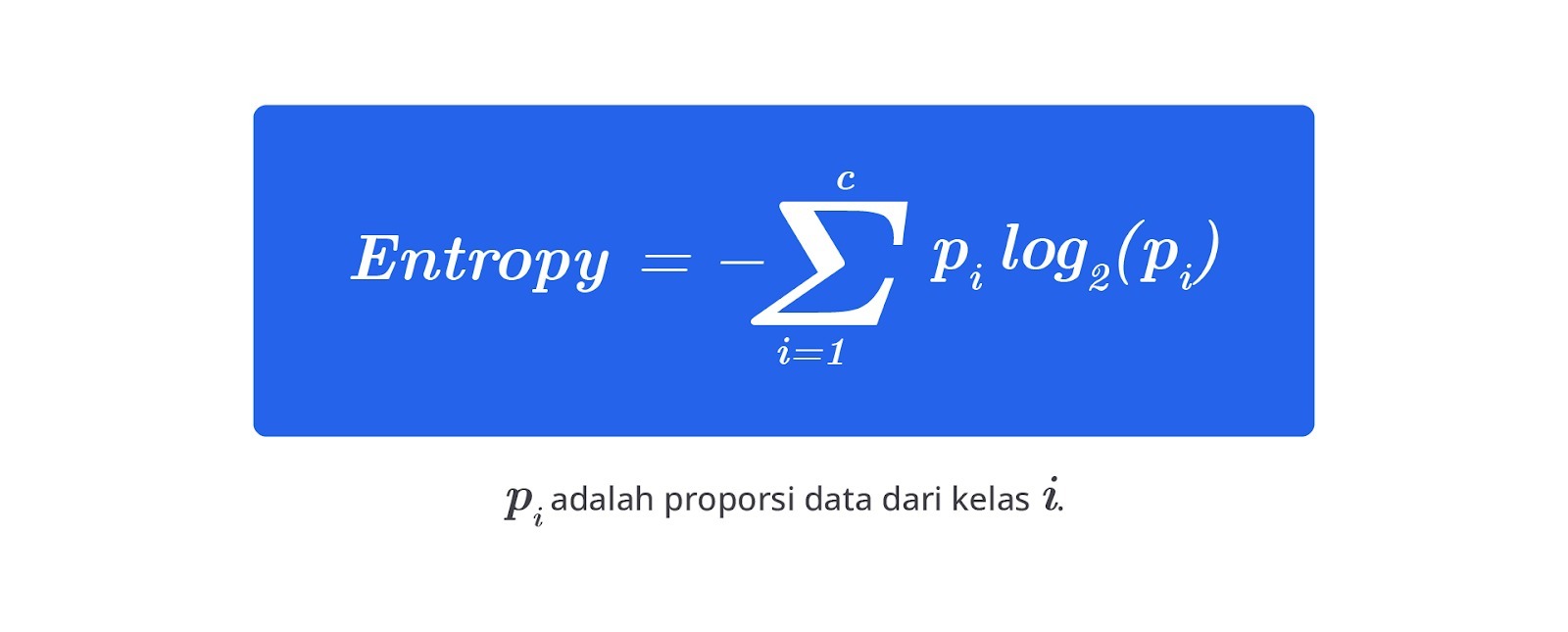
Dalam interpretasinya, Entropy dibagi menjadi dua sebagai berikut.- Entropy = 0: node sepenuhnya murni (hanya memiliki satu kelas).
- Entropy > 0: node memiliki campuran beberapa kelas.
Maksimal Kedalaman (max_depth): int, default=None
Parameter ini menentukan jumlah level atau "kedalaman" yang dapat dimiliki pohon keputusan. Jika nilai ini ditetapkan, pohon akan berhenti membelah data lebih lanjut setelah mencapai kedalaman yang ditentukan.
Max depth dibagi menjadi dua jenis sebagai berikut.
- Kedalaman Terbatas: Ini membatasi kedalaman pohon dapat membantu mencegah overfitting dengan menghindari pembelajaran yang terlalu spesifik terhadap data pelatihan.
- Kedalaman Tak Terbatas: Jika parameter ini diatur ke None, pohon keputusan akan terus tumbuh hingga mencapai batas alami, seperti ketika semua data pada node sudah berada di kelas yang sama atau tidak ada fitur lagi untuk dibagi.
Jumlah Minimum Sampel untuk Split (min_samples_split): int or float, default=2
Parameter ini menentukan jumlah minimum sampel yang diperlukan pada sebuah node sebelum pembagian (split) dapat dilakukan. Dengan kata lain, sebelum pohon keputusan memutuskan untuk membagi node menjadi dua anak, node tersebut harus memiliki setidaknya jumlah sampel yang ditentukan oleh parameter ini.
Parameter ini mengatur batas minimum jumlah data yang harus ada pada sebuah node agar pohon keputusan dapat membaginya lebih lanjut. Misalnya, jika Min Samples Split diatur ke 10, sebuah node harus memiliki setidaknya 10 sampel sebelum pohon dapat membaginya.
Berikut adalah beberapa kategori jenis nilai min samples split.
- Nilai Kecil (misalnya, 2): Dengan nilai kecil, pohon keputusan bisa membagi node meskipun hanya memiliki sedikit sampel.
- Nilai Besar (misalnya, 20 atau lebih): Dengan nilai yang lebih besar, pohon keputusan akan memerlukan lebih banyak sampel pada setiap node sebelum dapat membaginya.
Jumlah Minimum Sampel untuk Daun (min_samples_leaf): int or float, default=1
Parameter ini menentukan jumlah minimum sampel yang harus ada pada sebuah leaf node. Leaf node adalah node akhir dalam pohon keputusan yang memberikan prediksi akhir atau keputusan. Parameter ini membantu mengontrol ukuran minimum dari setiap ‘daun’.
Berikut adalah beberapa kategori jenis nilai min samples leaf.
- Nilai Kecil (misalnya, 1): Dengan nilai kecil, setiap leaf node bisa saja hanya berisi sedikit sampel, yang memungkinkan pohon untuk membagi data dengan sangat rinci.
- Nilai Besar (misalnya, 5 atau 10): Dengan nilai yang lebih besar, setiap leaf node harus berisi setidaknya jumlah sampel yang ditentukan.
Jumlah Maksimum Fitur untuk Pembagian (max_features): int, float or {“sqrt”, “log2”}, default=None
Parameter ini menentukan jumlah maksimum fitur yang akan dipertimbangkan untuk pembagian pada setiap node. Ini mengontrol seberapa banyak fitur yang dipertimbangkan untuk menentukan pemisahan terbaik pada node tertentu.
Berikut adalah beberapa kategori jenis nilai max features.
- Nilai Kecil (misalnya, 3 atau 5): Dengan nilai kecil, hanya sebagian fitur yang dipertimbangkan saat memilih pembagian terbaik.
- Nilai Besar (misalnya, semua fitur): Dengan nilai yang lebih besar atau setara dengan jumlah fitur total, pohon akan mempertimbangkan semua fitur untuk menentukan pembagian terbaik.
Splitter: {“best”, “random”}, default=”best”
Parameter ini menentukan metode yang digunakan untuk memilih pembagian terbaik pada setiap node. Berikut adalah beberapa kategori jenis nilai splitter.
- Best: Metode ini mencari pembagian yang memberikan hasil terbaik berdasarkan kriteria (seperti Gini Impurity atau Entropy). Ini memastikan bahwa setiap pembagian dilakukan untuk memaksimalkan informasi yang diperoleh dari split tersebut.
- Random: Metode ini memilih pembagian secara acak dari subset fitur. Ini bisa mempercepat proses pelatihan dengan mengurangi waktu yang diperlukan untuk memilih split terbaik, tetapi bisa kurang akurat dibandingkan dengan metode "Best".
Cara Kerja Decision Tree
Decision Tree adalah algoritma machine learning yang populer digunakan untuk klasifikasi dan regresi. Algoritma ini bekerja dengan membagi data menjadi subset yang lebih kecil berdasarkan fitur tertentu hingga mencapai keputusan akhir pada node daun. Proses ini berlangsung secara bertahap dan sistematis, menjadikannya alat yang kuat untuk memahami struktur data serta membuat keputusan berdasarkan fitur yang relevan.
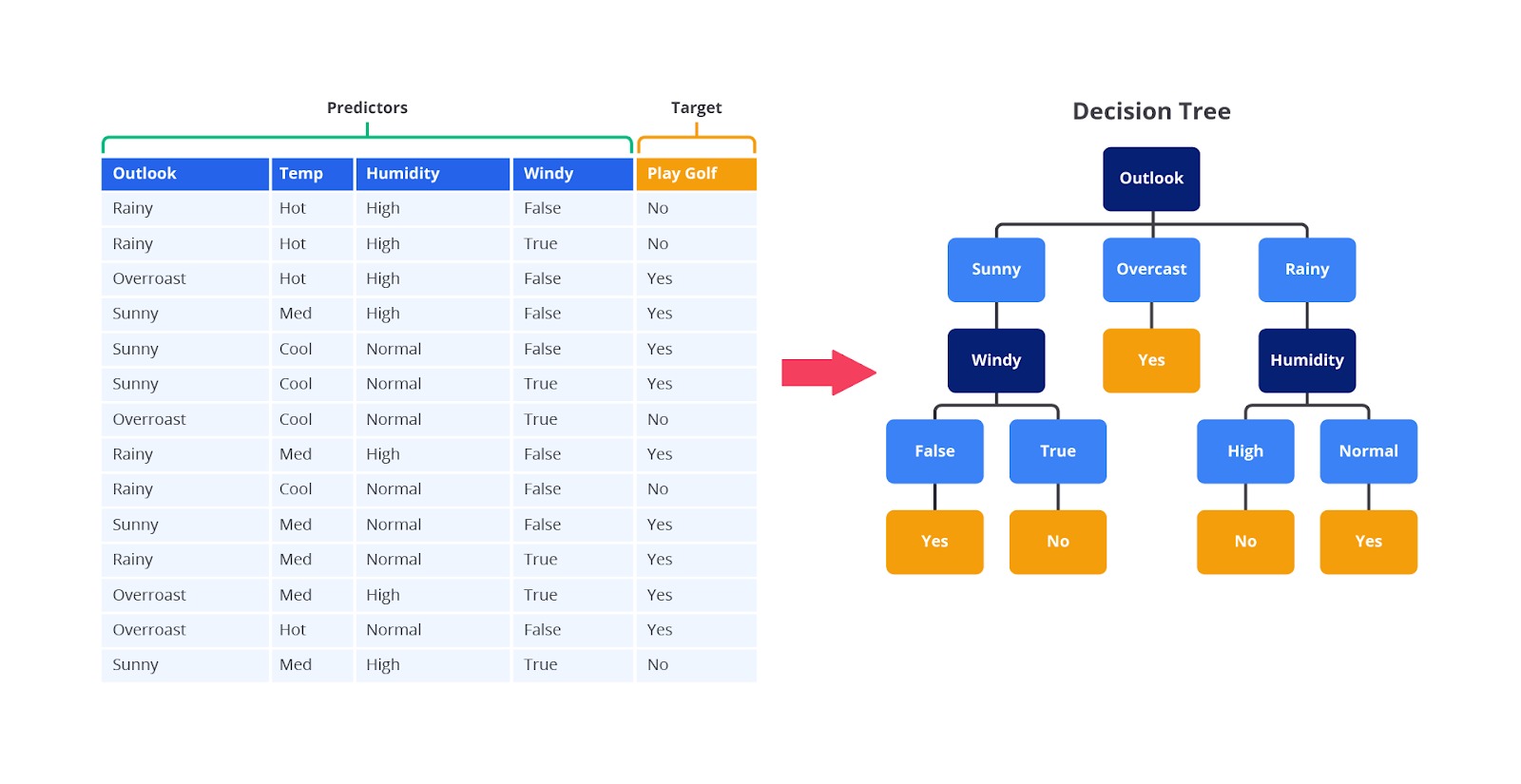
Langkah 1: Pemisahan Data Awal
Proses dimulai dengan memuat seluruh dataset yang akan digunakan untuk pelatihan. Data ini terdiri dari berbagai fitur (seperti ukuran, warna, atau harga) dan label atau target yang ingin diprediksi (seperti jenis buah atau status kredit). Decision Tree memulai dengan membagi data ini berdasarkan fitur-fitur untuk membentuk pohon keputusan.
Langkah 2: Pemilihan Fitur dan Pembagian Data
Setiap node dalam Decision Tree memilih fitur yang paling relevan untuk membagi data menjadi dua atau lebih subset. Pemilihan fitur ini dilakukan berdasarkan kriteria tertentu, seperti Gini Impurity, Entropy, atau variansi. Proses ini bertujuan untuk memaksimalkan pemisahan data yang bersih berdasarkan kelas atau nilai target.
Berikut adalah dua metode yang dapat digunakan.
- Gini Impurity: mengukur seberapa sering sampel yang dipilih secara acak dari subset akan dikelompokkan dengan salah jika label dipilih secara acak. Pohon akan memilih fitur yang meminimalkan Gini Impurity setelah split.
- Entropy: mengukur ketidakpastian dalam data. Pohon akan memilih fitur yang memaksimalkan pengurangan Entropy atau penurunan ketidakpastian.
Langkah 3: Pembentukan Cabang dan Node
Setelah fitur yang paling relevan dipilih, data dibagi berdasarkan nilai fitur tersebut. Setiap cabang dari node mewakili satu hasil pembagian ini. Proses ini diulang secara rekursif pada setiap subset yang dihasilkan hingga kondisi berhenti terpenuhi, seperti berikut.
- Jumlah Minimum Sampel untuk Daun: ketika jumlah sampel pada node mencapai angka minimum yang telah ditentukan.
- Kedalaman Maksimum Pohon: ketika kedalaman pohon mencapai batas yang telah ditetapkan.
- Semua Sampel dalam Node Memiliki Kelas yang Sama: ketika semua sampel dalam node memiliki label yang sama.
Langkah 4: Pembuatan Leaf Node
Setelah pohon mencapai kondisi berhenti, node terakhir pada pohon disebut leaf node. Leaf node memberikan hasil akhir dari prediksi atau keputusan. Untuk klasifikasi, ini adalah kelas yang paling sering muncul dalam data yang sampai pada node tersebut. Untuk regresi, ini adalah nilai rata-rata atau median dari target pada node tersebut.
Langkah 5: Penggunaan Model untuk Prediksi
Ketika ingin menggunakan pohon keputusan untuk membuat prediksi, kita mengikuti langkah-langkah berikut. Pertama, data baru dimulai dari bagian paling atas pohon, yang disebut root node.
Kemudian, kita periksa nilai fitur dari data baru dan mengikuti cabang yang sesuai dengan pohon berdasarkan nilai tersebut. Proses ini dilanjutkan hingga data mencapai leaf node di bagian bawah pohon. Leaf node ini memberikan hasil akhir dari prediksi. Jadi, untuk setiap data baru, pohon keputusan membantu menentukan kategori atau nilai dengan melihat ke bagian akhir pohon.
Langkah 6: Evaluasi dan Penyesuaian
Setelah pohon dibangun, model akan dievaluasi untuk memastikan bahwa ia memberikan hasil yang baik. Evaluasi dilakukan dengan menggunakan data uji dan berbagai metrik evaluasi, seperti akurasi, precision, recall, atau mean squared error.
Jika diperlukan, pohon dapat disesuaikan, misalnya, dengan melakukan pruning (memotong bagian pohon yang kurang penting) untuk meningkatkan generalisasi dan mengurangi risiko overfitting.
Dengan mengikuti langkah-langkah ini, Decision Tree dapat membagi data secara sistematis dan membuat keputusan yang didasarkan pada fitur-fitur paling relevan serta menghasilkan model untuk berbagai aplikasi dalam klasifikasi dan regresi.
Kelebihan dan Kekurangan Decision Tree
Decision Tree adalah salah satu algoritma machine learning yang populer, digunakan untuk berbagai tugas klasifikasi dan regresi. Seperti halnya algoritma lainnya, Decision Tree memiliki kelebihan dan kekurangan yang memengaruhi cara serta waktu algoritma ini paling efektif digunakan.
Memahami aspek-aspek ini sangat penting untuk memilih algoritma yang tepat berdasarkan karakteristik data dan tujuan analisis. Berikut adalah tabel yang merangkum kelebihan dan kekurangan dari Decision Tree untuk memberikan gambaran lebih jelas mengenai kekuatan dan batasan metode ini.
| Kelebihan Decision Tree | Kekurangan Decision Tree |
|---|---|
Mudah Dipahami dan Ditafsirkan: menghasilkan model mudah dipahami karena strukturnya yang berbentuk pohon. | Terlalu ‘Fleksibel’: sering kali menghasilkan model yang sangat kompleks sehingga menyebabkan overfitting. |
Dapat Menangani Data Kategorikal dan Numerik: dapat menangani berbagai jenis data, baik data numerik maupun kategorikal, tanpa memerlukan banyak pra-pemrosesan. | Sensitif terhadap Noise: dapat memengaruhi keputusan pohon, membuat model kurang akurat. |
Tidak Memerlukan Skala Fitur: tidak memerlukan normalisasi atau standardisasi fitur, yang memudahkan penggunaannya pada data tidak terstandardisasi. | Pohon yang Terlalu Besar: jika tidak dikendalikan, pohon bisa tumbuh sangat besar serta menjadi sangat rumit, yang dapat memperlambat proses prediksi dan interpretasi. |
Fleksibel dan Dapat Disesuaikan: dapat mudah disesuaikan untuk berbagai masalah dengan menyesuaikan parameter dan kriteria pembagian. | Pohon Tidak Stabil: perubahan kecil pada data pelatihan bisa menyebabkan perubahan besar dalam struktur pohon sehingga model bisa tidak stabil. |
Dengan mempertimbangkan kelebihan dan kekurangan ini, Anda dapat menentukan pilihan bahwa Decision Tree adalah algoritma yang tepat atau tidak untuk masalah klasifikasi atau regresi yang sedang dihadapi dan cara mengoptimalkan penggunaannya untuk hasil terbaik.
Random Forest
Random Forest adalah algoritma ensemble learning yang menggabungkan beberapa Decision Tree untuk meningkatkan akurasi prediksi dan mengurangi risiko overfitting. Setiap pohon dalam Random Forest dilatih menggunakan subset acak dari data pelatihan dan subset acak dari fitur yang tersedia. Hasil akhir prediksi ditentukan melalui voting (untuk klasifikasi) atau rata-rata (untuk regresi) dari hasil semua pohon dalam model.
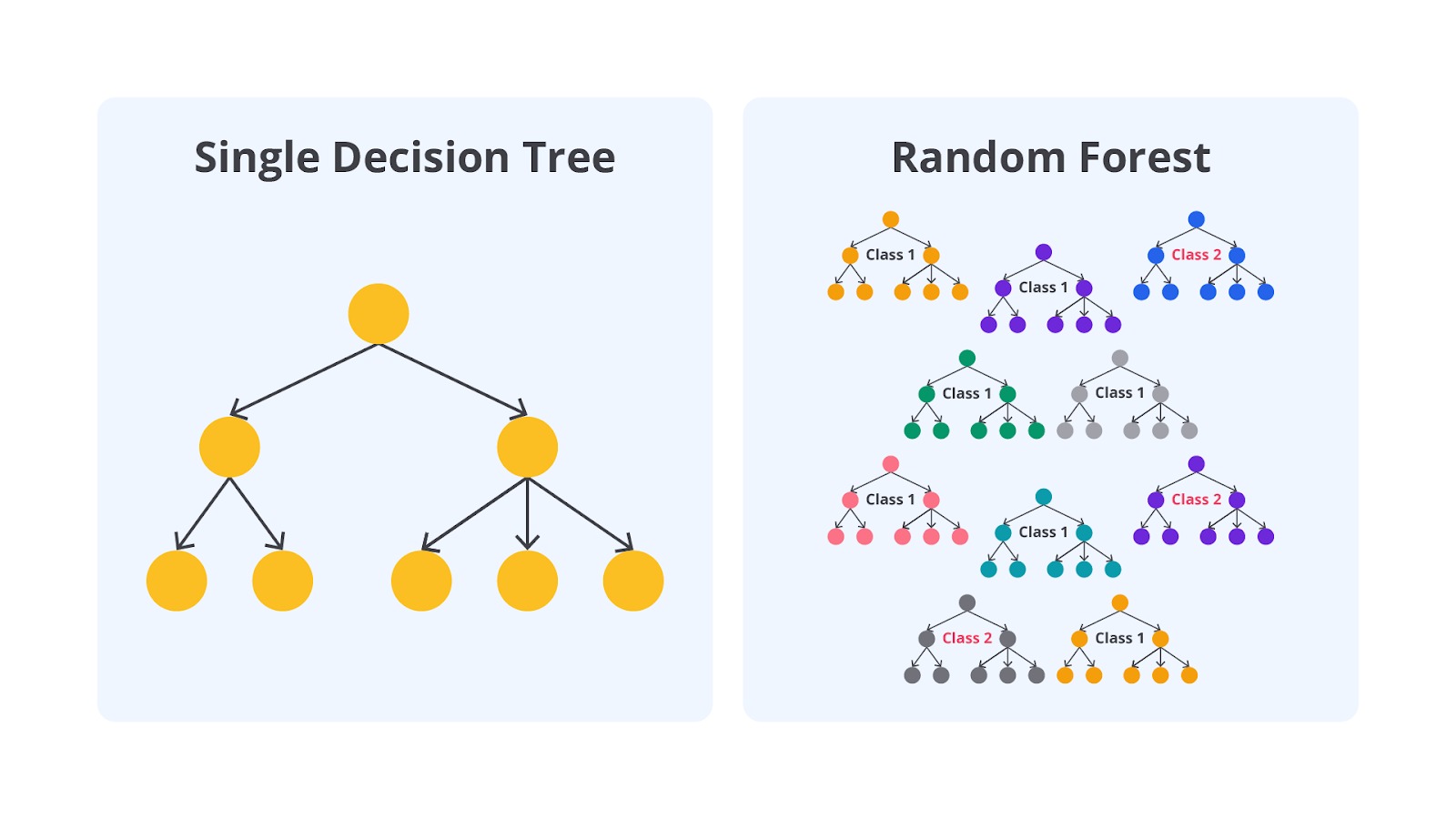
Tujuan utama Random Forest adalah mengatasi kelemahan Decision Tree yang cenderung overfit terhadap data pelatihan. Dengan menggabungkan prediksi dari banyak pohon, Random Forest mampu menghasilkan model yang lebih stabil, akurat, dan lebih general terhadap data baru.
Parameter Utama Random Forest
Dalam algoritma Random Forest, beberapa parameter utama perlu diatur untuk mengoptimalkan performa model. Inilah beberapa di antaranya.
- n_estimators
- Maksimal Kedalaman (max_depth)
- Jumlah Minimum Sampel untuk Split (min_samples_split)
- Jumlah Minimum Sampel untuk Daun (min_samples_leaf)
- Jumlah Maksimum Fitur untuk Pembagian (max_features)
- bootstrap
- random_state
Mari kita bahas lebih lengkap masing-masing parameternya!
n_estimators: int, default=100
n_estimators adalah parameter yang menentukan jumlah Decision Tree (pohon keputusan) yang akan dibangun dalam model Random Forest. Semakin banyak pohon yang digunakan, model cenderung lebih stabil dan akurat karena setiap pohon memberikan kontribusi pada hasil akhir melalui proses voting atau averaging. Nilai default-nya adalah 100.
Jika n_estimators terlalu rendah, model tidak cukup kuat untuk menangkap pola dalam data. Sebaliknya, jika terlalu tinggi, waktu komputasi dan penggunaan memori akan meningkat tanpa peningkatan yang signifikan dalam performa.
Disarankan untuk mengatur n_estimators menjadi nilai yang cukup tinggi, tetapi tidak terlalu tinggi sehingga mengorbankan efisiensi komputasi. Nilai yang disarankan adalah antara 100 hingga 300 karena sering mendapatkan hasil cukup baik dalam praktiknya.
Maksimal Kedalaman (max_depth): int, default=None
max_depth mengatur kedalaman maksimum dari setiap Decision Tree dalam Random Forest. Pohon yang lebih dalam dapat menangkap lebih banyak informasi dari data, tetapi jika terlalu dalam, pohon bisa overfit terhadap data pelatihan. Nilai default adalah None yang berarti pohon akan tumbuh sampai semua node adalah murni atau sampai jumlah sampel minimum pada node kurang dari min_samples_split.
Mengatur batas kedalaman dapat mencegah overfitting dan menghasilkan model yang lebih general. Namun, kedalaman yang terlalu dangkal dapat menyebabkan underfitting. Gunakan cross-validation untuk menemukan nilai max_depth yang optimal. Pohon dengan kedalaman 10–20 sering kali cukup dalam untuk menangkap informasi yang diperlukan tanpa terlalu overfitting.
Jumlah Minimum Sampel untuk Split (min_samples_split): int or float, default=2
min_samples_split adalah jumlah minimum sampel yang diperlukan untuk membagi sebuah node dalam Decision Tree. Jika jumlah sampel dalam sebuah node kurang dari nilai ini, node tersebut tidak akan dibagi lagi dan akan menjadi leaf node. Nilai default-nya adalah 2.
Nilai yang lebih tinggi dari min_samples_split membuat pohon lebih sederhana, mencegah pohon tumbuh terlalu kompleks, dan mengurangi risiko overfitting. Sebaliknya, nilai terlalu rendah dapat menghasilkan pohon yang terlalu terpecah, menangkap noise dari data. Nilai lebih besar dapat digunakan jika Anda memiliki data yang sangat besar atau data yang cenderung noisy.
Jumlah Minimum Sampel untuk Daun (min_samples_leaf): int or float, default=1
min_samples_leaf adalah jumlah minimum sampel yang diperlukan untuk berada pada leaf node (node daun). Sama seperti min_samples_split, tetapi berfungsi pada level leaf node. Ini membantu memastikan bahwa setiap leaf node berisi cukup sampel untuk memberikan prediksi yang dapat diandalkan.
Nilai default-nya adalah 1. Nilai antara 1 hingga 5 sering kali digunakan, tergantung pada ukuran dataset dan jumlah fitur. Nilai lebih tinggi mengarah pada pohon yang lebih halus dan generalisasi lebih baik, terutama untuk dataset yang sangat besar. Namun, terlalu besar dapat menyebabkan underfitting.
Jumlah Maksimum Fitur untuk Pembagian (max_features): {“sqrt”, “log2”, None}, int or float, default=”sqrt”
max_features menentukan jumlah maksimum fitur yang dipertimbangkan untuk pemisahan pada setiap node. Dengan memilih subset acak dari fitur, setiap pohon dalam Random Forest memiliki pohon yang sedikit berbeda, mengurangi korelasi antar pohon dan meningkatkan generalisasi. Default-nya adalah sqrt (akar kuadrat dari jumlah total fitur) untuk tugas klasifikasi dan log2 untuk tugas regresi.
Nilai default biasanya sudah cukup baik, tetapi jika memiliki data dengan banyak fitur, Anda bisa bereksperimen dengan nilai yang lebih tinggi atau lebih rendah untuk melihat dampaknya pada akurasi.
bootstrap: bool, default=True
bootstrap adalah parameter yang menentukan bahwa sampel akan diambil dengan penggantian ketika membangun setiap Decision Tree. Jika bootstrap=True, setiap pohon dilatih menggunakan subset acak dari data secara bergantian. Ini adalah esensi dari metode bagging.
Menggunakan bootstrap meningkatkan variasi antar pohon dan umumnya menghasilkan model yang lebih kuat. Jika bootstrap=False, setiap pohon akan dilatih pada seluruh dataset, yang dapat menghasilkan pohon yang lebih mirip satu sama lain. Default True hampir selalu digunakan karena menghasilkan model yang lebih general.
random_state: int, RandomState instance or None, default=None
random_state adalah parameter yang mengontrol pengacakan yang digunakan oleh algoritma. Dengan menetapkan random_state, Anda memastikan bahwa hasil model akan konsisten setiap kali dijalankan berdasarkan kondisi yang sama. Nilai default adalah None yang berarti pengacakan tidak dikendalikan dan hasilnya dapat berbeda setiap kali model dijalankan.
Cara Kerja Random Forest
Pada penjelasan ini, kita akan membahas cara kerja Random Forest dan alasan algoritma ini sangat efektif dalam menangani masalah machine learning yang kompleks.
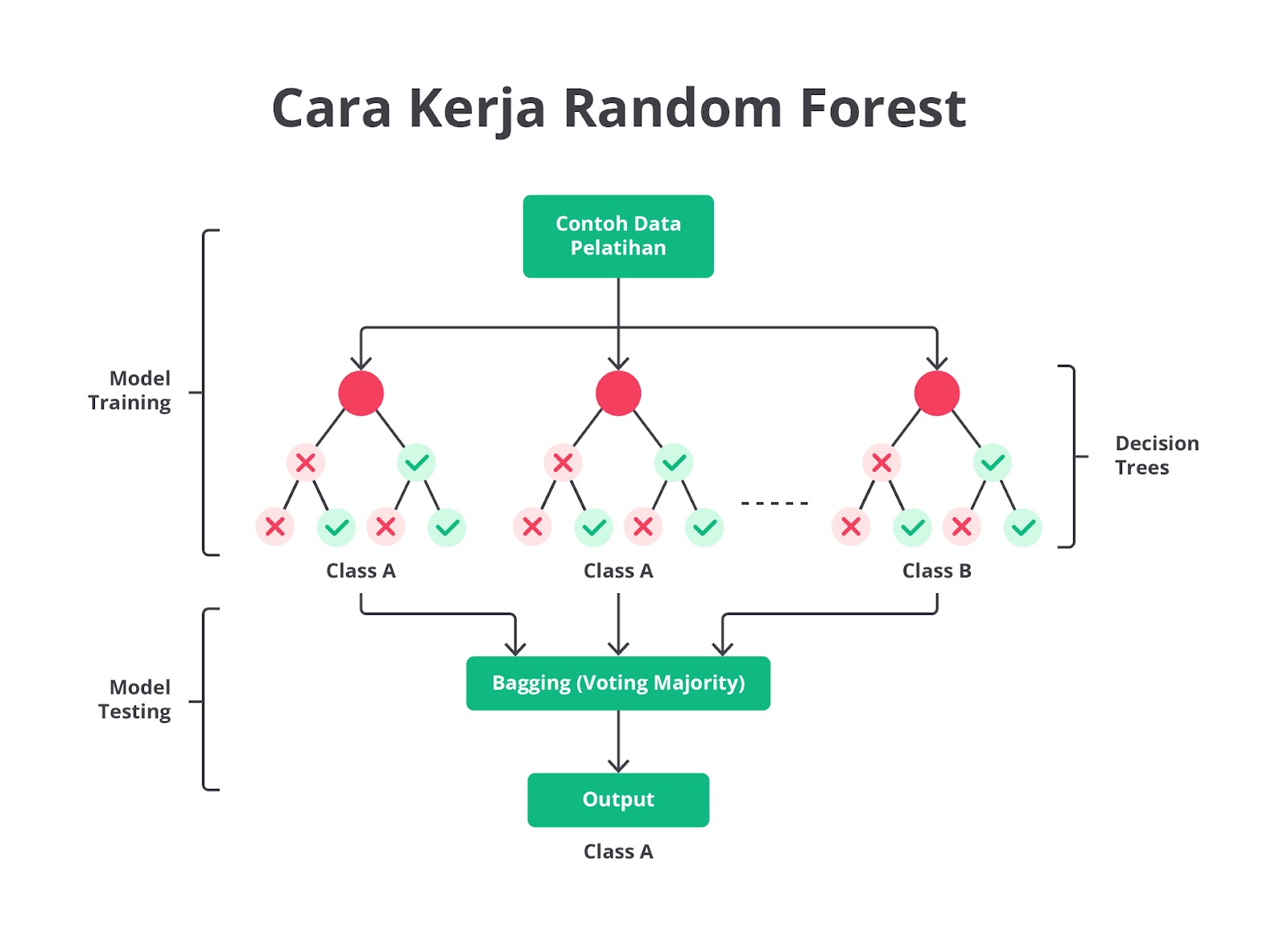
Langkah 1: Pengambilan Sampel Data
Random Forest memulai dengan mengambil beberapa sampel acak dari dataset pelatihan asli. Setiap sampel diambil dengan teknik bootstrap, yaitu pengambilan sampel dengan penggantian sehingga beberapa data bisa muncul lebih dari sekali dalam satu sampel.
Langkah 2: Pembentukan Decision Tree
Untuk setiap sampel data yang diambil, Random Forest membangun Decision Tree. Pada setiap node dalam pohon, subset acak dari fitur dipilih untuk menemukan fitur terbaik saat membagi data pada node tersebut. Pemilihan fitur ini dilakukan untuk memastikan bahwa setiap pohon dalam hutan sedikit berbeda satu sama lain.
Langkah 3: Proses Training/Pembelajaran
Setiap Decision Tree dibangun hingga mencapai kedalaman maksimum atau sampai tidak ada pembagian lebih lanjut yang mungkin dilakukan, tergantung pada parameter, seperti max_depth atau min_samples_split. Setiap pohon belajar dari data dengan membuat keputusan berdasarkan fitur-fitur yang dipilih secara acak.
Langkah 4: Agregasi Prediksi
Setelah semua pohon dibangun, Random Forest menggunakan hasil dari setiap pohon untuk membuat prediksi. Untuk tugas klasifikasi, setiap pohon memberikan suara (voting) untuk kelas tertentu, dan yang paling banyak dipilih akan menjadi prediksi akhir.
Langkah 5: Evaluasi Model
Model Random Forest kemudian dievaluasi berdasarkan performanya dalam data uji atau melalui teknik validasi silang. Karena Random Forest menggabungkan prediksi dari banyak pohon, model ini biasanya lebih akurat dan lebih tahan terhadap overfitting dibandingkan dengan Decision Tree tunggal.
Langkah 6: Penerapan Model
Setelah model dilatih dan dievaluasi, model Random Forest yang sudah terbentuk digunakan untuk membuat prediksi pada data baru. Data baru ini akan melewati semua pohon dalam hutan dan hasil akhir akan ditentukan berdasarkan agregasi prediksi dari semua pohon tersebut.
Melalui langkah-langkah ini, Random Forest menghasilkan model kuat serta fleksibel untuk berbagai tugas klasifikasi dan regresi dengan kelebihan berupa stabilitas serta kemampuan dalam menangani data yang memiliki kompleksitas tinggi.
Kelebihan dan Kekurangan Random Forest
Random Forest adalah algoritma machine learning yang populer serta banyak digunakan dalam berbagai aplikasi untuk tugas klasifikasi dan regresi. Metode ini menggabungkan kekuatan dari banyak pohon keputusan untuk menghasilkan model yang kuat dan akurat. Memahami kelebihan serta kekurangan Random Forest sangat penting untuk menentukan waktu dan cara algoritma ini dapat digunakan secara efektif dalam proyek machine learning. Berikut kelebihan dan kekurangannya.
| Kelebihan Random Forest | Kekurangan Random Forest |
|---|---|
Akurasi Tinggi: sering memberikan akurasi yang sangat baik karena menggabungkan banyak pohon keputusan. | Kebutuhan Memori yang Tinggi: memerlukan memori besar, terutama dengan banyak pohon. |
Robust terhadap Overfitting: mengurangi risiko overfitting dengan menggabungkan hasil dari banyak pohon keputusan. | Interpretabilitas yang Rendah: model sulit diinterpretasikan dibandingkan dengan pohon keputusan tunggal. |
Kemampuan Menangani Data Tidak Seimbang: dapat menangani data dengan kelas yang tidak seimbang secara baik. | Lambat pada Prediksi: prediksi bisa lambat jika model memiliki banyak pohon dan dataset besar. |
Menangani Data yang Hilang: dapat mengisi nilai yang hilang dengan rata-rata atau median. | Kurang Efektif pada Data Kecil: mungkin tidak memberikan manfaat signifikan pada dataset kecil. |
Fitur Penting: memberikan informasi tentang pentingnya fitur, membantu dalam feature selection. | Waktu Pelatihan yang Lama: tuning hyperparameter bisa memerlukan waktu dan usaha ekstra. |
Dengan mempertimbangkan kelebihan dan kekurangan ini, Anda dapat menentukan pilihan bahwa Random Forest adalah algoritma yang tepat atau tidak untuk masalah klasifikasi atau regresi yang sedang dihadapi. Anda juga dapat menentukan cara mengoptimalkan penggunaannya untuk hasil terbaik.
Support Vector Machine (SVM)
Support vector machine (SVM) adalah salah satu algoritma machine learning yang digunakan untuk klasifikasi dan regresi. Namun, SVM lebih sering digunakan pada masalah klasifikasi. SVM bekerja dengan mencari hyperplane yang optimal untuk memisahkan data ke dalam kelas-kelas yang berbeda. Hyperplane adalah garis (pada data dua dimensi) atau bidang (pada data tiga dimensi) yang memisahkan data dari kelas berbeda. Tujuan SVM adalah menemukan hyperplane yang memaksimalkan margin, yaitu jarak antara hyperplane dan titik data terdekat dari setiap kelas.
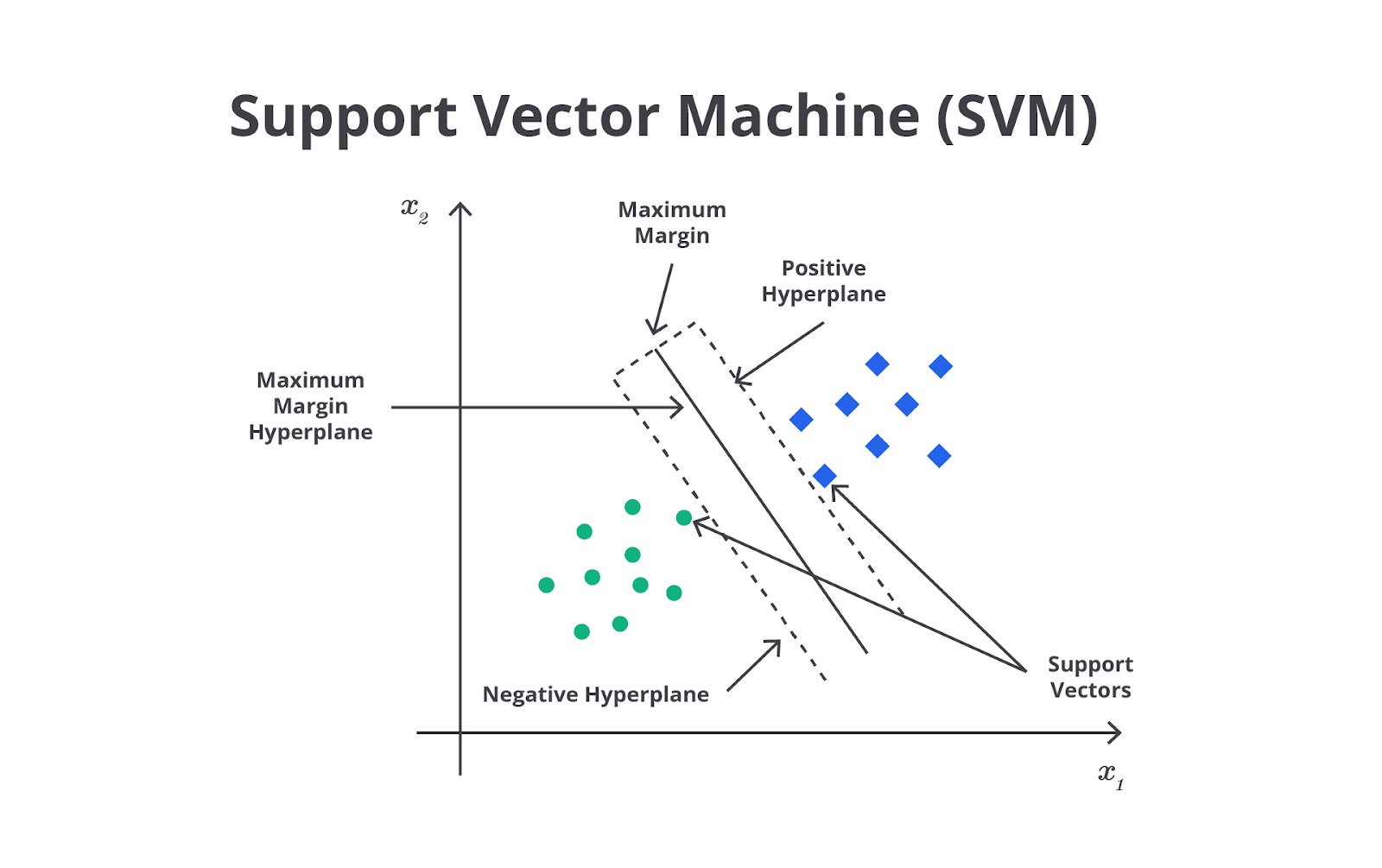
Parameter Utama SVM
Dalam algoritma SVM, beberapa parameter utama perlu diatur untuk mengoptimalkan performa model. Inilah beberapa di antaranya.
- Kernel
- Gamma
- Regularization (c)
- Degree
Mari kita bahas lebih lengkap masing-masing parameternya!
Kernel: {‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’} or callable, default=’rbf’
Kernel adalah fungsi yang memainkan peran penting dalam SVM, terutama ketika data tidak dapat dipisahkan secara linear di ruang aslinya. Kernel memungkinkan SVM untuk mengubah atau memetakan data dari ruang input berdimensi rendah ke ruang fitur berdimensi tinggi atau data tersebut bisa dipisahkan secara linear. Konsep ini dikenal sebagai kernel trick, yang memungkinkan perhitungan dilakukan di ruang fitur tanpa secara eksplisit menghitung koordinat dalam ruang tersebut.
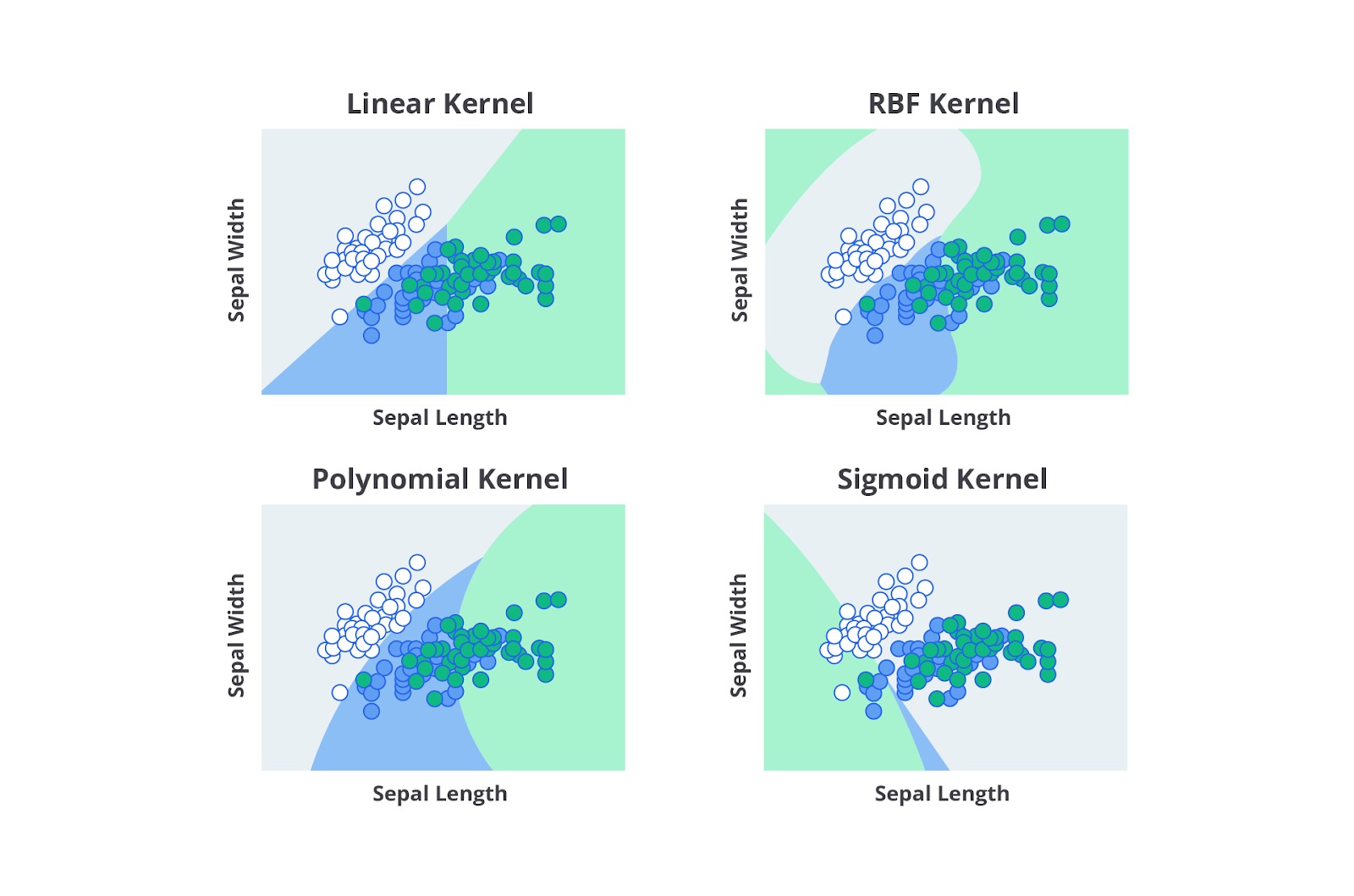
Berikut adalah penjelasan detail tentang beberapa jenis kernel yang sering digunakan.
- Linear Kernel
Linear kernel adalah pilihan sederhana yang tidak memetakan data ke ruang yang lebih tinggi, tetapi menggunakan data sebagaimana adanya. Kernel ini digunakan untuk data yang dapat dipisahkan secara linear. Berikut persamaannya.
Linear kernel biasanya digunakan ketika jumlah fitur jauh lebih besar daripada jumlah sampel, misalnya pada teks klasifikasi dengan ribuan fitur (kata-kata) dalam dokumen.
- Polynomial Kernel
Polynomial kernel mengubah data ke ruang berdimensi lebih tinggi menggunakan fungsi polinomial. Ini adalah generalisasi dari linear kernel dan dapat menangani interaksi non-linear antara fitur. Berikut persamaannya.
Kernel polinomial digunakan ketika hubungan antara kelas tidak linear dan dapat direpresentasikan oleh polinomial.
- Radial Basis Function (RBF) Kernel
RBF kernel (juga dikenal sebagai Gaussian kernel) adalah kernel yang sangat populer karena kemampuannya untuk menangani data yang tidak dapat dipisahkan secara linear. Kernel ini memetakan data ke ruang fitur berdimensi sangat tinggi. Berikut persamaannya.
Kernel RBF cocok untuk data yang memiliki batas pemisah non-linear, seperti dalam masalah klasifikasi dengan pola kompleks.
- Sigmoid Kernel
Sigmoid kernel sering dianggap sebagai fungsi aktivasi dalam jaringan saraf dan penggunaannya pada SVM memberikan perilaku yang mirip dengan model jaringan saraf. Berikut persamaannya.
Kernel sigmoid digunakan ketika data memiliki batas non-linear yang menyerupai perilaku aktivasi sigmoid dalam jaringan saraf.
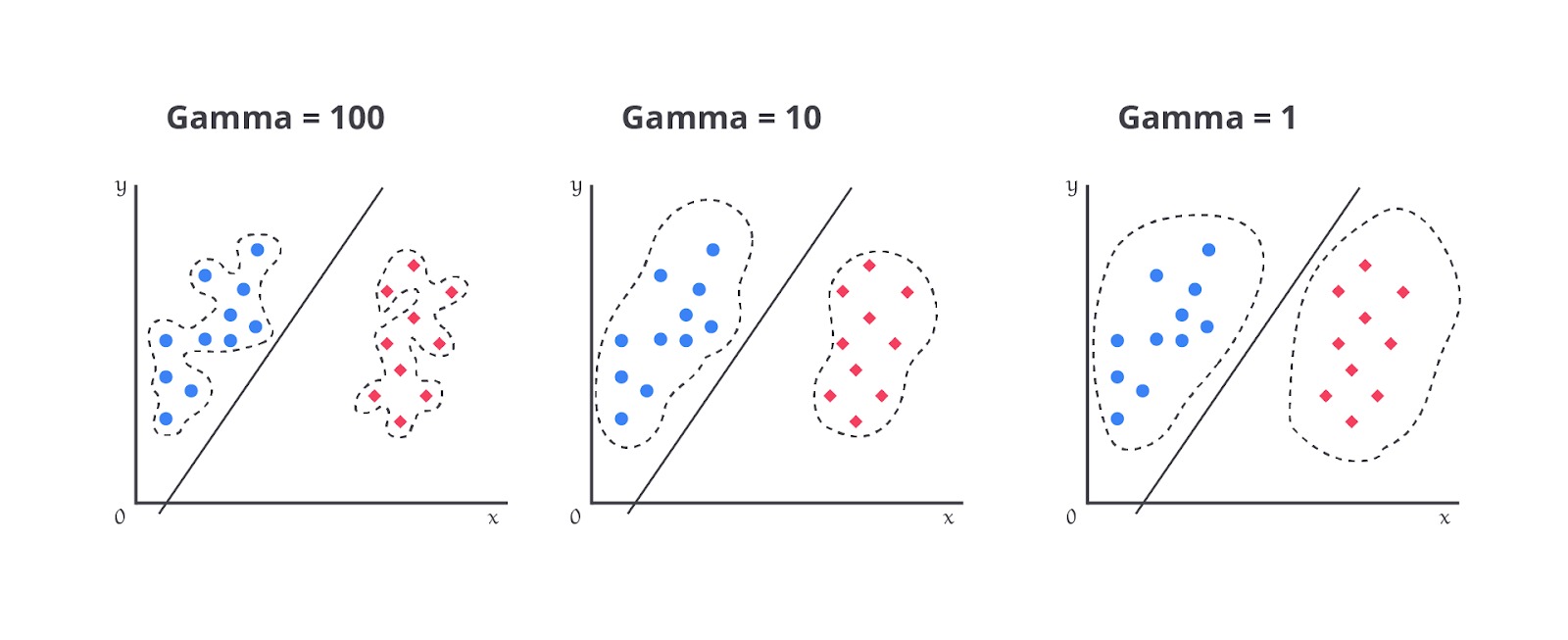
Gamma (): {‘scale’, ‘auto’} or float, default=’scale’
Parameter gamma pada SVM adalah faktor penting yang mengatur seberapa besar pengaruh setiap titik data dalam menentukan keputusan model, terutama saat menggunakan kernel, seperti RBF, polynomial, atau sigmoid.
Ada beberapa cara untuk mengatur nilai gamma.
- Gamma 'scale' (default): nilai gamma ini dihitung otomatis dengan mempertimbangkan jumlah fitur dan variasi dalam data. Pendekatan ini biasanya lebih stabil dan cocok untuk berbagai jenis data karena menyesuaikan nilai gamma berdasarkan distribusi data.
- Gamma 'auto': nilai gamma ini juga dihitung otomatis, tetapi hanya berdasarkan jumlah fitur dalam data. Meskipun sederhana, pendekatan ini mungkin kurang adaptif, terutama jika data memiliki skala fitur yang sangat berbeda.
- Gamma float: pengguna dapat menetapkan nilai gamma secara manual. Ini memberikan fleksibilitas penuh, memungkinkan penyesuaian yang spesifik untuk data tertentu, tetapi memerlukan eksperimen lebih lanjut untuk menemukan nilai optimal.
Dengan kata lain, gamma menentukan seberapa jauh dampak dari satu titik data akan terasa pada model SVM, yang sangat memengaruhi kemampuan model dalam mengklasifikasikan data secara akurat.
Regularization (C): float, default=1.0
Regularization Parameter (C) adalah parameter dalam SVM yang mengontrol kekuatan regularisasi pada model. Regularisasi adalah teknik yang digunakan untuk mencegah overfitting dengan menambahkan penalti pada kompleksitas model. Kekuatan regularisasi berbanding terbalik dengan nilai C.
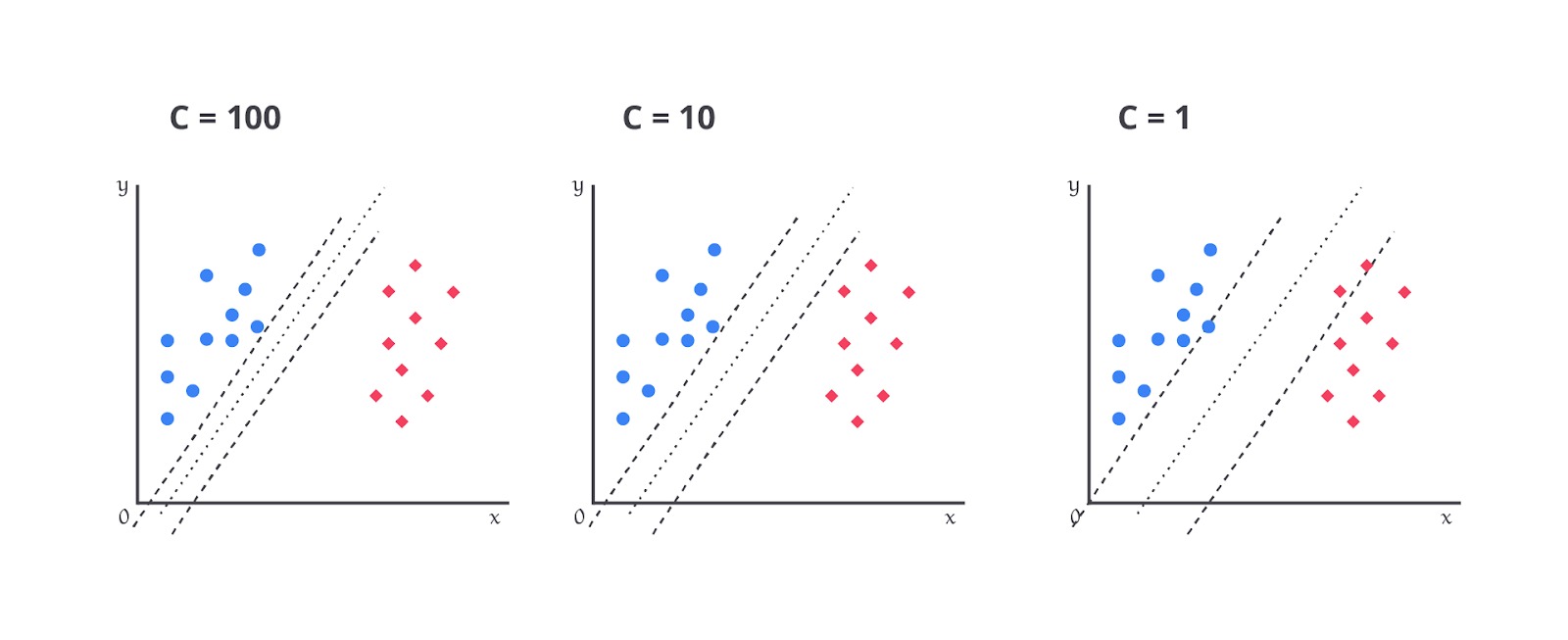
Dengan kata lain, semakin besar nilai C, semakin sedikit regularisasi yang diterapkan dan model akan berusaha keras untuk mengklasifikasikan semua data dengan benar. Bahkan, jika itu berarti memiliki margin yang lebih kecil. Sebaliknya, nilai C yang lebih kecil akan meningkatkan kekuatan regularisasi dan menghasilkan margin lebih besar dengan mengizinkan beberapa kesalahan dalam klasifikasi.
Degree
Parameter degree dalam SVM berlaku khusus untuk kernel polinomial. Parameter ini menentukan derajat polinomial untuk memetakan data dari ruang fitur asli ke ruang fitur yang lebih tinggi. Dengan kata lain, degree mengontrol kompleksitas dari fungsi polinomial yang digunakan dalam kernel polinomial.
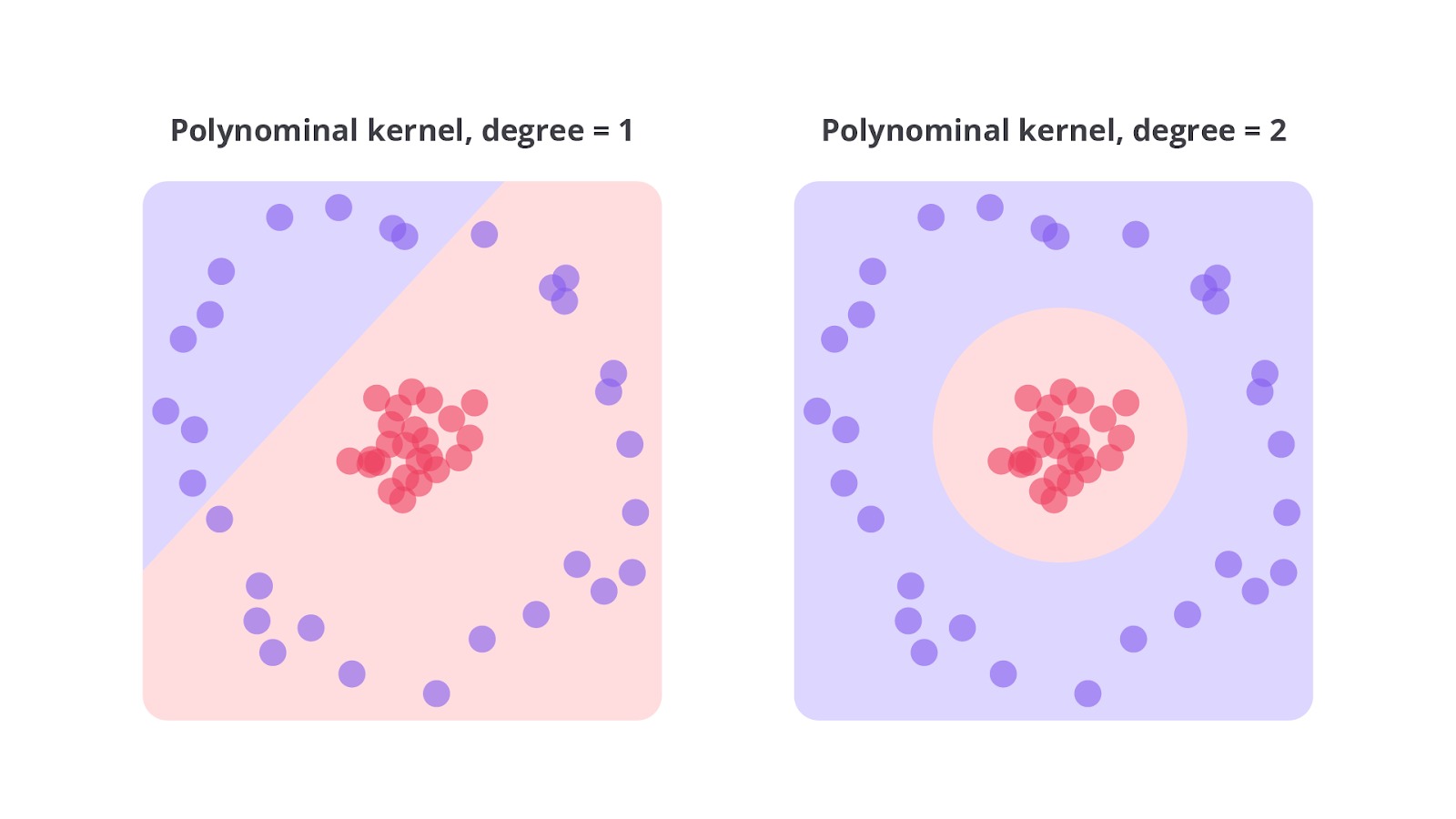
Dalam kernel polinomial pada SVM, perbedaan antara degree 1 dan degree 2 terletak pada kompleksitas fungsi polinomial untuk memetakan data ke ruang fitur yang lebih tinggi. Dengan degree 1, kernel polinomial menghasilkan fungsi linier yang sederhana, setara dengan menggunakan kernel linier sehingga cocok untuk data yang dapat dipisahkan secara linier.
Model ini lebih cepat dan cenderung menghindari overfitting karena kesederhanaannya. Sebaliknya, degree 2 menggunakan fungsi polinomial kuadrat. Ini memungkinkan model untuk menangkap hubungan non-linier yang lebih kompleks dalam data. Ini berguna untuk data dengan pola kuadratik atau hubungan non-linier lainnya.
Namun, peningkatan kompleksitas ini juga meningkatkan risiko overfitting, terutama jika data tidak cukup untuk mendukung model yang lebih rumit. Dengan demikian, pemilihan degree yang tepat bergantung pada karakteristik data dan tujuan analisis.
Cara Kerja SVM
Dalam penjelasan ini, kita akan menguraikan cara SVM membangun model klasifikasi secara optimal dan memperluas kemampuannya untuk menyelesaikan masalah klasifikasi yang lebih kompleks.
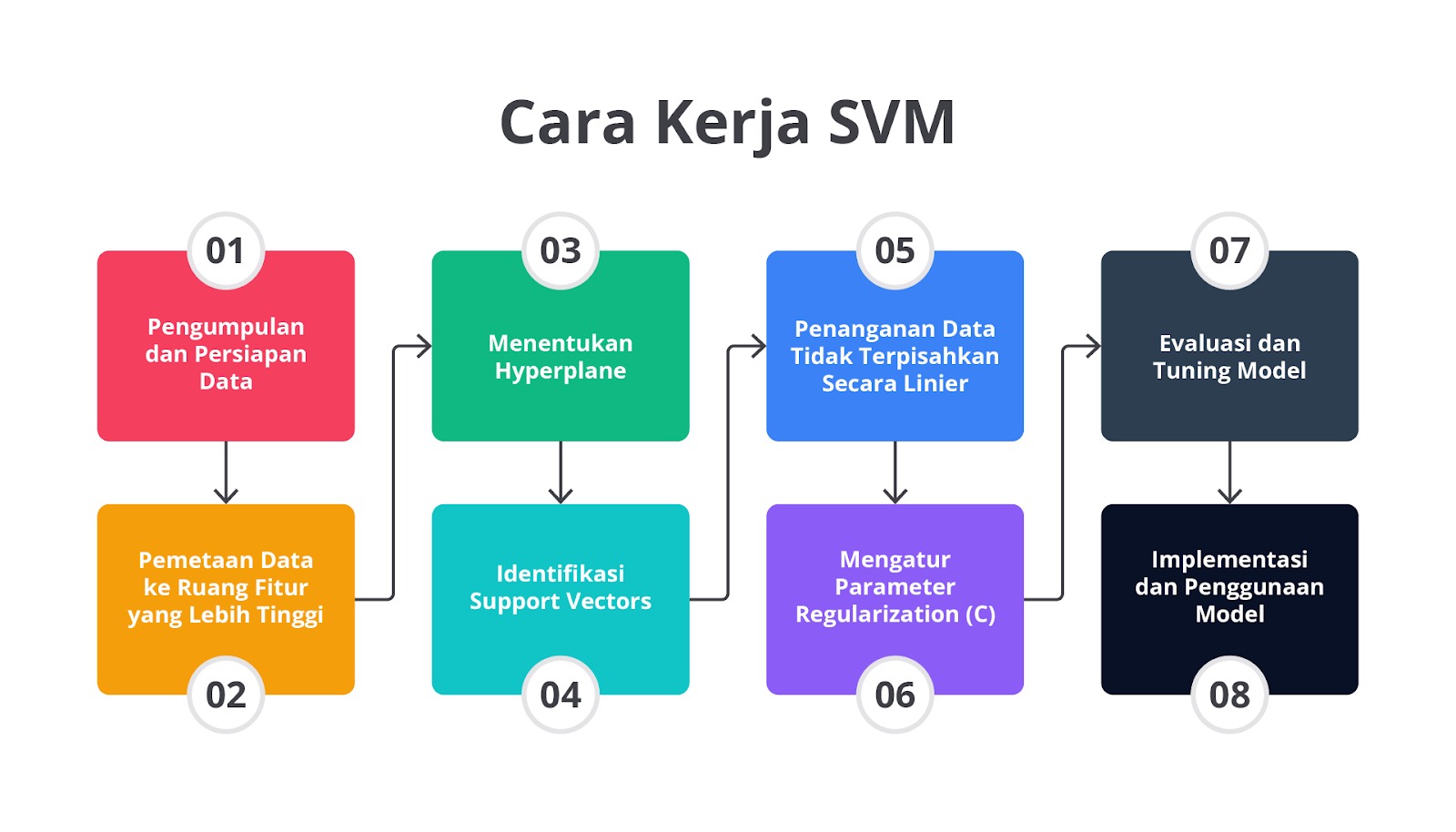
Langkah 1: Pengumpulan dan Persiapan Data
Proses SVM dimulai dengan pengumpulan data yang akan digunakan untuk melatih model. Data ini harus dipersiapkan dengan cermat melalui pra-pemrosesan, yang mencakup pembersihan data, penanganan nilai yang hilang, serta normalisasi atau standardisasi fitur untuk memastikan bahwa semua fitur berada dalam skala seragam. Selanjutnya, data dibagi menjadi set pelatihan dan set pengujian. Set pelatihan digunakan untuk melatih model dan set pengujian dalam mengevaluasi kinerjanya.
Langkah 2: Pemetaan Data ke Ruang Fitur yang Lebih Tinggi
SVM memulai dengan memetakan data ke ruang fitur yang lebih tinggi menggunakan fungsi kernel. Ini memungkinkan model untuk menangkap pola non-linier yang mungkin tidak terlihat dalam ruang fitur asli. Kernel, seperti polinomial, RBF (Radial Basis Function), atau sigmoid digunakan untuk mengubah data sehingga dapat dipisahkan secara linier dalam ruang fitur yang baru.
Langkah 3: Menentukan Hyperplane
Dalam ruang fitur yang lebih tinggi, SVM mencari hyperplane yang memisahkan data ke dalam kelas-kelas berbeda. Hyperplane adalah permukaan (atau garis dalam dimensi dua) yang memisahkan dua kelas dengan jarak maksimum. Tujuannya adalah menemukan hyperplane yang memaksimalkan margin, yaitu jarak antara hyperplane dan titik data terdekat dari masing-masing kelas.
Langkah 4: Identifikasi Support Vectors
Support vectors adalah titik data yang terletak paling dekat dengan hyperplane. Titik-titik ini berperan penting dalam menentukan posisi dan orientasi hyperplane. Hanya titik-titik ini yang memengaruhi pembentukan hyperplane sehingga mereka sangat penting dalam pelatihan model SVM.
Langkah 5: Penanganan Data Tidak Terpisahkan Secara Linier
Jika data tidak dapat dipisahkan secara linier di ruang fitur asli, kernel trick digunakan untuk mengubah data ke ruang fitur yang lebih tinggi. Di ruang ini, data bisa dipisahkan secara linier oleh hyperplane. Ini memungkinkan SVM untuk menangani masalah klasifikasi yang lebih kompleks dengan batas kelas non-linier.
Langkah 6: Mengatur Parameter Regularization (C)
Parameter regularization C mengontrol trade-off antara margin dan kesalahan klasifikasi. Nilai C yang tinggi akan memaksa model untuk mengklasifikasikan semua titik data dengan benar, mengorbankan margin yang lebih kecil. Sebaliknya, nilai C yang lebih rendah akan menghasilkan margin lebih besar, tetapi dengan beberapa kesalahan klasifikasi. Pengaturan parameter ini membantu menyeimbangkan kompleksitas model dan akurasi.
Langkah 7: Evaluasi dan Tuning Model
Setelah model dilatih, performanya dievaluasi menggunakan data uji. Metrik, seperti akurasi, precision, recall, dan F1-Score digunakan untuk mengukur seberapa baik model mengklasifikasikan data baru. Berdasarkan hasil evaluasi, parameter kernel, seperti gamma (untuk kernel RBF) dan degree (untuk kernel polinomial) disesuaikan untuk meningkatkan performa model.
Langkah 8: Implementasi dan Penggunaan Model
Dengan model yang telah dilatih dan dioptimalkan, model diimplementasikan dalam aplikasi atau sistem produksi. Model digunakan untuk membuat prediksi pada data baru yang belum pernah dilihat. Penting memantau kinerja model secara berkala serta melakukan pembaruan jika diperlukan untuk memastikan bahwa model tetap efektif dan relevan.
Kelebihan dan Kekurangan SVM
SVM memiliki berbagai kelebihan yang membuatnya populer dalam berbagai aplikasi, tetapi juga memiliki beberapa kekurangan yang perlu dipertimbangkan. Tabel berikut merangkum kelebihan dan kekurangan utama dari SVM untuk memberikan gambaran lebih jelas tentang waktu dan cara algoritma ini dapat digunakan secara efektif.
| Kelebihan | Kekurangan |
|---|---|
Margin Maksimal: SVM mencari hyperplane yang memisahkan kelas dengan margin maksimal, yang dapat meningkatkan generalisasi dan mengurangi risiko overfitting. | Kompleksitas Komputasi: untuk dataset besar atau fitur yang sangat banyak, pelatihan SVM bisa menjadi sangat lambat dan memerlukan banyak memori. |
Kemampuan Menangani Data Non-Linier: dengan penggunaan kernel trick, SVM dapat mengatasi data yang tidak dapat dipisahkan secara linier dengan baik. | Pemilihan Parameter: pemilihan parameter, seperti C, gamma, dan jenis kernel dapat memengaruhi kinerja model secara signifikan dan memerlukan tuning yang hati-hati. |
Kinerja yang Baik dengan Data Kecil: SVM sering kali memberikan hasil yang baik pada dataset dengan jumlah data relatif kecil jika dibandingkan dengan metode lain. | Tidak Biasa Menghasilkan Probabilitas: SVM tidak secara langsung memberikan probabilitas untuk kelas yang mungkin menjadi kendala jika probabilitas klasifikasi penting dalam aplikasi tertentu. |
Efektif pada Dimensi Tinggi: SVM dapat bekerja dengan baik pada data berdimensi tinggi, seperti dalam masalah teks dan bioinformatika, letak banyak fitur mungkin ada. | Interpretasi Model Sulit: hasil model SVM, terutama dengan kernel non-linier, sering kali sulit untuk diinterpretasikan atau dipahami secara intuitif. |
Dengan mempertimbangkan kelebihan dan kekurangan ini, Anda dapat menentukan bahwa SVM adalah algoritma yang tepat dalam masalah klasifikasi atau regresi yang sedang dihadapi serta cara mengoptimalkan penggunaannya untuk hasil terbaik.
Naive Bayes
Naive Bayes adalah algoritma klasifikasi berbasis probabilitas yang berdasarkan pada Teorema Bayes, dengan asumsi bahwa fitur-fitur dalam data bersifat independen satu sama lain. Nama "naive" (naif) merujuk pada asumsi independensi ini, yang sering kali tidak realistis. Namun, dalam praktiknya dapat menghasilkan model yang efektif. Naive Bayes menggunakan prinsip probabilitas untuk memprediksi kelas dari data baru berdasarkan pengamatan fitur yang ada.
Secara matematis, Naive Bayes bekerja dengan menghitung kemungkinan suatu data termasuk dalam kelas tertentu berdasarkan dua faktor: kemungkinan awal dari setiap kelas (probabilitas prior) dan kemungkinan fitur dalam data jika kelas tersebut benar (probabilitas likelihood).
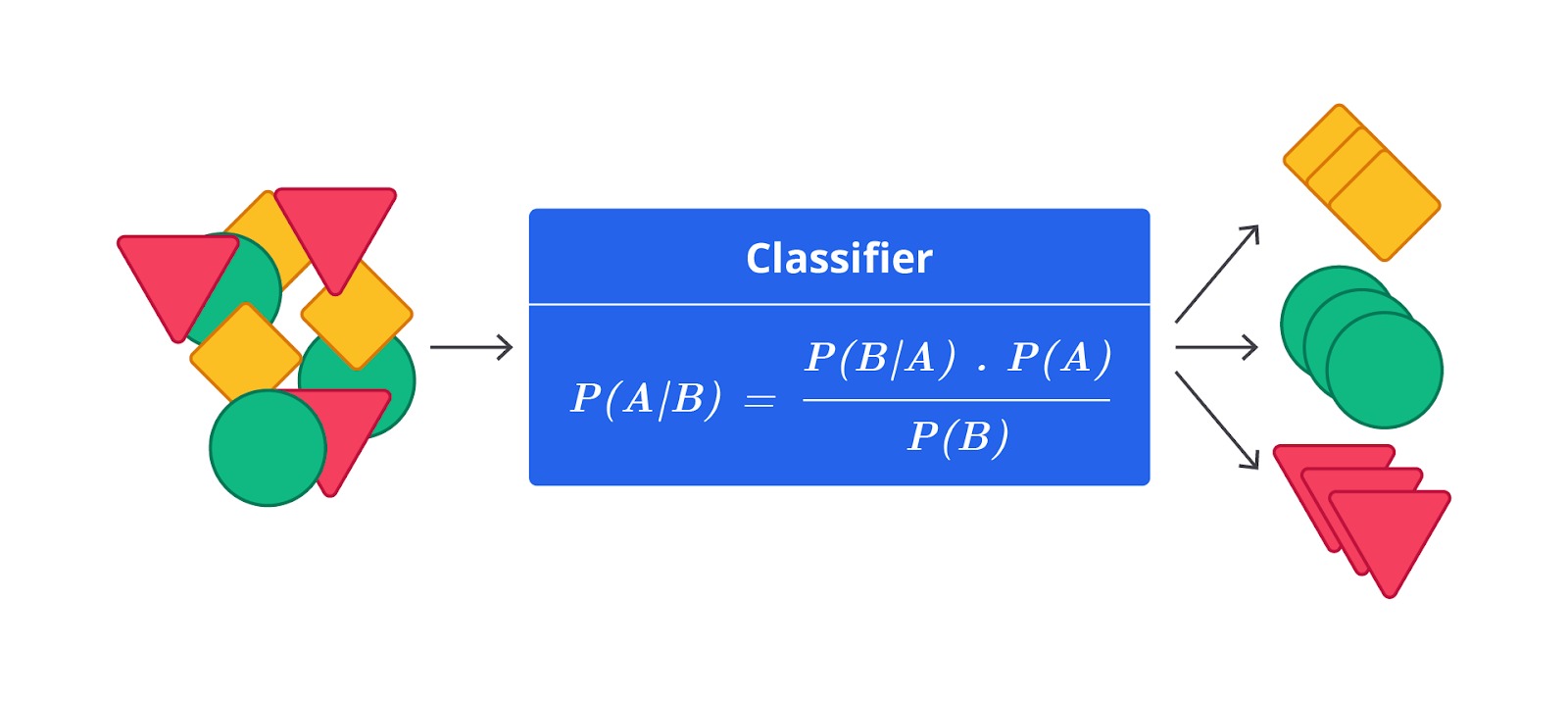
Rumus untuk menghitung probabilitas posterior P(A∣B) dalam konteks Teorema Bayes sebagai berikut.

Setelah menghitung kemungkinan untuk setiap kelas, model ini memilih kelas dengan kemungkinan tertinggi sebagai hasil klasifikasi. Naive Bayes bisa digunakan untuk berbagai jenis data, seperti teks, gambar, atau tabel dan sering dipakai dalam aplikasi, seperti filter spam, analisis sentimen, serta pengenalan pola.
Parameter Utama Naive Bayes
Dalam algoritma Naive Bayes, beberapa parameter utama perlu diatur untuk mengoptimalkan performa model. Inilah beberapa di antaranya.
- Laplace Smoothing
- Probabilitas Prior
- Probabilitas Likelihood
Mari kita bahas lebih lengkap masing-masing parameternya!
Laplace Smoothing
Laplace smoothing, juga dikenal sebagai smoothing atau add-one smoothing, adalah teknik yang digunakan untuk menangani masalah ketika fitur tertentu tidak muncul dalam data pelatihan untuk kelas tertentu. Ini sering disebut "smoothing" karena menambahkan nilai kecil untuk mencegah probabilitas nol.
Contoh: Jika kita tidak menambahkan smoothing dan kata "gratis" tidak muncul pada email spam, model akan menganggap bahwa kata "gratis" tidak ada dalam spam. Dengan smoothing, kita menambahkan sedikit nilai pada semua kata sehingga meskipun kata "gratis" tidak muncul, model tetap mempertimbangkan kemungkinan kecil bahwa kata ini bisa ada dalam spam.
Probabilitas Prior
Probabilitas prior adalah probabilitas awal dari setiap kelas sebelum mempertimbangkan fitur yang ada. Ini menggambarkan seberapa umum atau sering suatu kelas muncul dalam data pelatihan. Ini adalah cara untuk mengetahui jumlah umum sebuah kategori sebelum kita melihat fitur-fiturnya.
Contoh: Jika dalam 100 email yang kita miliki, 60 di antaranya spam, probabilitas prior untuk spam adalah 60%. Ini berarti kita sudah tahu spam adalah kategori yang lebih umum sebelum mulai menganalisis kata-katanya.
Probabilitas Likelihood
Probabilitas likelihood adalah probabilitas kemunculan fitur tertentu dalam data pelatihan untuk setiap kelas. Ini menunjukkan seberapa sering fitur muncul dalam data yang sudah diberi label dengan kelas tertentu.
Ini membantu kita mengerti seberapa umum fitur tersebut dalam kategori yang berbeda. Misalnya, jika kata "diskon" muncul banyak pada email yang dikategorikan sebagai spam dan jarang muncul dalam email non-spam, probabilitas likelihood kata "diskon" akan tinggi untuk spam dan rendah untuk non-spam. Ini membantu model memprediksi kategori email baru berdasarkan fitur yang ada.
Contoh: Jika kita menemukan kata "diskon" muncul sebanyak 30 kali dari 50 email spam, dan hanya sebanyak 10 dari 50 email non-spam, kata "diskon" lebih umum pada spam. Jadi, model akan memberikan bobot lebih pada kata ini saat memprediksi bahwa email baru adalah spam atau bukan.
Cara Kerja Naive Bayes
Naive Bayes adalah metode klasifikasi berbasis pada prinsip probabilitas dan Teorema Bayes yang digunakan untuk memprediksi kelas atau kategori dari data baru berdasarkan informasi yang telah ada.
Metode ini bekerja dengan cara menghitung probabilitas berbagai kelas berdasarkan fitur-fitur pada data pelatihan. Berikut adalah langkah kerja Naive Bayes.
Langkah 1: Mengumpulkan dan Menyiapkan Data
Langkah pertama adalah mengumpulkan data yang akan digunakan untuk melatih model Naive Bayes. Data ini harus mencakup berbagai contoh yang sudah diberi label dengan benar. Dalam konteks klasifikasi teks, data bisa berupa kumpulan dokumen dengan label kategori, seperti "spam" atau "non-spam."
Setelah pengumpulan data, proses pembersihan dilakukan untuk menghilangkan noise, kesalahan, atau data yang tidak relevan. Selanjutnya, fitur-fitur penting diidentifikasi dan diekstraksi. Pada kasus teks, fitur biasanya adalah kata-kata atau istilah yang muncul dalam dokumen. Data kemudian dibagi menjadi dua bagian, yaitu fitur (misalnya, kata-kata dalam email) dan label kelas (misalnya, spam atau non-spam), yang akan digunakan untuk pelatihan model.
Langkah 2: Menghitung Probabilitas Prior
Setelah data siap, langkah berikutnya adalah menghitung probabilitas prior untuk setiap kelas. Probabilitas prior adalah estimasi frekuensi kemunculan setiap kelas dalam data pelatihan tanpa mempertimbangkan fitur individual. Ini dihitung dengan membagi jumlah data untuk masing-masing kelas dengan total jumlah data.
Sebagai contoh, jika dari 100 email, 60 adalah spam, probabilitas prior untuk spam adalah 60% atau 0.6. Probabilitas prior memberikan informasi tentang kemungkinan awal setiap kelas sebelum mempertimbangkan fitur-fitur dalam data.
Langkah 3: Menghitung Probabilitas Likelihood
Langkah ini melibatkan perhitungan probabilitas likelihood, yaitu seberapa sering fitur tertentu muncul dalam data untuk setiap kelas. Probabilitas likelihood diukur dengan menghitung frekuensi kemunculan fitur dalam data yang telah dilabeli dengan kelas tertentu.
Misalnya, jika kata "diskon" muncul 15 kali dalam email yang dikategorikan sebagai spam dan 5 kali dalam email non-spam, probabilitas likelihood kata "diskon" diberikan untuk setiap kelas dihitung berdasarkan frekuensi tersebut. Ini membantu menentukan seberapa relevan fitur-fitur tertentu dalam konteks masing-masing kelas.
Langkah 4: Menerapkan Teorema Bayes
Teorema Bayes digunakan untuk menghitung probabilitas posterior, yaitu probabilitas bahwa suatu data termasuk dalam kelas tertentu berdasarkan fitur yang diberikan. Formula Teorema Bayes menggabungkan probabilitas prior dan probabilitas likelihood dari fitur untuk menghasilkan probabilitas posterior.
Langkah 5: Klasifikasi
Setelah menghitung probabilitas posterior untuk setiap kelas, langkah terakhir adalah menentukan kategori akhir untuk data uji. Kelas dengan probabilitas posterior tertinggi dipilih sebagai hasil klasifikasi. Ini berarti bahwa berdasarkan fitur yang diberikan dan probabilitas yang dihitung, kelas dengan probabilitas posterior tertinggi adalah yang paling mungkin untuk data uji tersebut.
Misalnya, jika probabilitas posterior untuk email lebih tinggi untuk kategori spam dibandingkan dengan non-spam, email tersebut diklasifikasikan sebagai spam. Dengan langkah-langkah ini, Naive Bayes menggunakan prinsip probabilitas sederhana untuk melakukan klasifikasi yang efektif pada berbagai jenis data.
Kelebihan dan Kekurangan Naive Bayes
Naive Bayes adalah algoritma klasifikasi yang terkenal karena kesederhanaan dan efektivitasnya dalam berbagai aplikasi. Meskipun model ini memiliki beberapa keunggulan, seperti kemudahan implementasi dan kemampuan bekerja dengan data besar, juga terdapat kekurangan yang perlu dipertimbangkan.
Naive Bayes memiliki kelebihan utama dalam menangani data dengan banyak fitur dan membuat model yang cepat serta efisien untuk pelatihan dan prediksi. Namun, kekurangan utamanya adalah asumsi bahwa fitur-fitur bersifat independen yang sering kali tidak sesuai dengan kenyataan, serta ketergantungan pada asumsi distribusi data yang bisa memengaruhi akurasi. Memahami kelebihan dan kekurangan ini membantu dalam menggunakan Naive Bayes dengan lebih efektif untuk klasifikasi. Berikut penjelasan lebih lengkapnya.
| Kelebihan | Kekurangan |
|---|---|
Kesederhanaan dan Kemudahan Implementasi: Naive Bayes mudah dipahami dan diimplementasikan karena dasar matematisnya yang sederhana. | Asumsi Independensi Fitur: Model ini mengasumsikan bahwa fitur-fitur dalam data bersifat independen satu sama lain, padahal pada praktiknya fitur sering kali saling terkait. |
Kecepatan dalam Pelatihan dan Prediksi: Algoritma ini sangat efisien dalam hal waktu pelatihan dan prediksi, bahkan dengan dataset yang besar. | Kinerja pada Data dengan Fitur Bergantung: Dalam kasus ketika fitur-fitur tidak independen, akurasi model bisa menurun karena model tidak menangkap interaksi antara fitur. |
Kemampuan untuk Bekerja dengan Data Besar: Naive Bayes dapat menangani data dengan jumlah fitur yang besar tanpa memerlukan banyak sumber daya komputasi. | Keterbatasan pada Data Tidak Seimbang: Model ini dapat memiliki performa buruk pada data yang sangat tidak seimbang, beberapa kelas jauh lebih jarang daripada kelas lainnya. |
Kemampuan Menangani Data Hilang: Naive Bayes dapat menangani data yang hilang dengan baik, sering kali menggunakan estimasi berbasis frekuensi. | Asumsi Distribusi Data: Algoritma ini mungkin tidak perform secara baik jika data tidak mengikuti distribusi yang diasumsikan, seperti distribusi Gaussian atau multinomial. |
Dengan memahami kelebihan dan kekurangan ini, pengguna dapat membuat keputusan yang lebih baik tentang waktu serta cara menggunakan Naive Bayes untuk masalah klasifikasi tertentu.
Evaluasi Model Klasifikasi
Evaluasi model klasifikasi adalah proses penting untuk menilai seberapa baik model yang dibangun dapat memprediksi atau mengklasifikasikan data. Ini melibatkan berbagai metrik dan teknik untuk mengukur performa model serta memastikan bahwa ia bekerja dengan baik pada data yang belum pernah dilihat sebelumnya. Berikut adalah beberapa metode dan metrik yang umum digunakan dalam evaluasi model klasifikasi.
Confusion Matrix
Confusion matrix adalah alat untuk mengevaluasi kinerja model klasifikasi dengan menunjukkan jumlah prediksi yang benar dan salah dalam format tabel. Ini memberikan pandangan yang lebih rinci tentang cara model berperforma di berbagai kelas.
Berikut adalah empat jenis evaluator dalam confusion matrix.
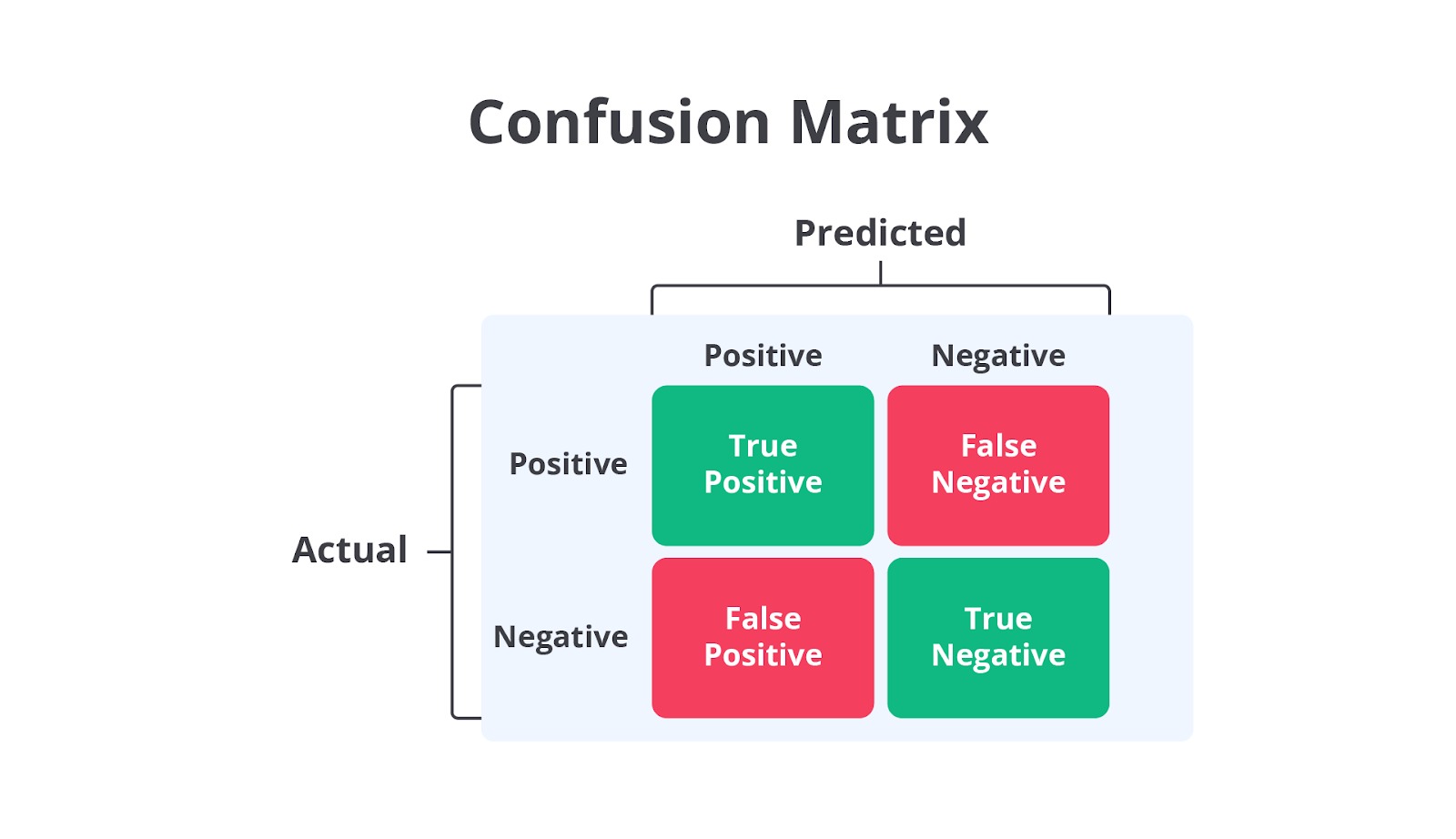
- True Positives (TP): jumlah kasus positif yang benar-benar diprediksi sebagai positif.
- True Negatives (TN): jumlah kasus negatif yang benar-benar diprediksi sebagai negatif.
- False Positives (FP): jumlah kasus negatif yang diprediksi sebagai positif (juga dikenal sebagai kesalahan tipe I).
- False Negatives (FN): jumlah kasus positif yang diprediksi sebagai negatif (juga dikenal sebagai kesalahan tipe II).
Contoh: Kita memiliki model untuk mendeteksi penyakit dan memiliki 100 sampel data dengan label sebenarnya sebagai positif atau negatif. Berikut adalah confusion matrix untuk model tersebut.

Di sini, model kita memprediksi 30 kasus sebagai positif dan benar-benar positif (TP), 10 kasus positif yang diprediksi sebagai negatif (FN), 55 kasus negatif yang diprediksi sebagai negatif (TN), dan 5 kasus negatif yang diprediksi sebagai positif (FP).
Berikut adalah analogi lainnya dari implementasi confusion matrix. Hehe, santai dulu dong!

Nah, bagaimana artinya?
- TP (True Positives): model benar memprediksi wanita yang hamil.
- TN (True Negatives): model benar memprediksi pria (atau wanita) yang tidak hamil.
- FP (False Positives): model salah memprediksi pria sebagai hamil atau wanita yang sebenarnya tidak hamil sebagai hamil.
- FN (False Negatives): model salah memprediksi wanita hamil sebagai tidak hamil.
Sampai di sini, apakah Anda sudah bisa memahami perbedaan masing-masing evaluatornya? Semoga lebih tercerahkan, ya!
Metrik Evaluasi Klasifikasi
Metrik evaluasi klasifikasi digunakan untuk menilai kinerja model saat mengklasifikasikan data ke dalam kategori tertentu. Berikut adalah penjelasan rinci mengenai beberapa metrik evaluasi yang sering digunakan.
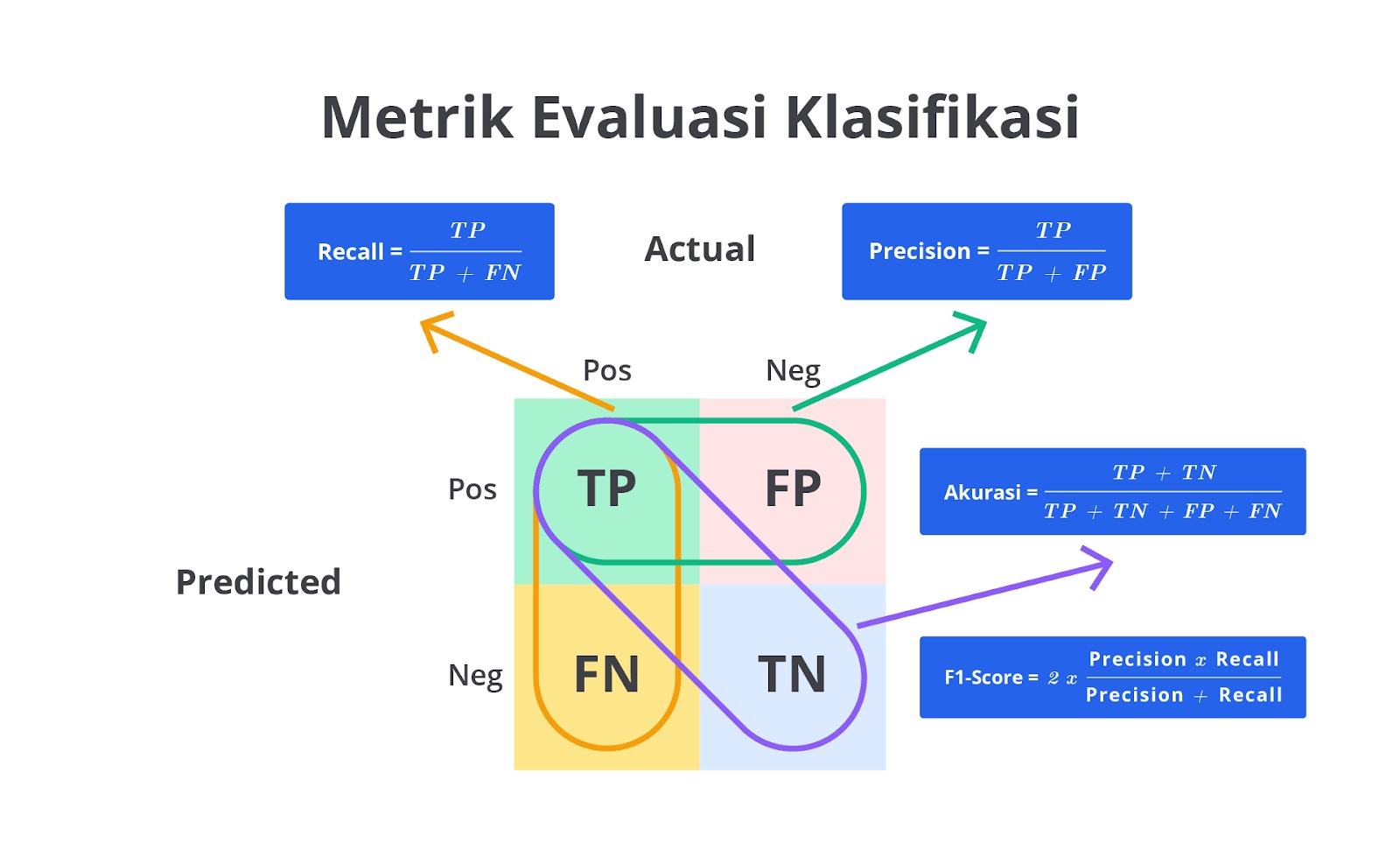
Akurasi
Akurasi adalah metrik yang paling sederhana dan sering digunakan untuk mengukur kinerja model klasifikasi. Akurasi dihitung sebagai proporsi dari prediksi benar (baik positif maupun negatif) terhadap seluruh prediksi yang dilakukan oleh model.
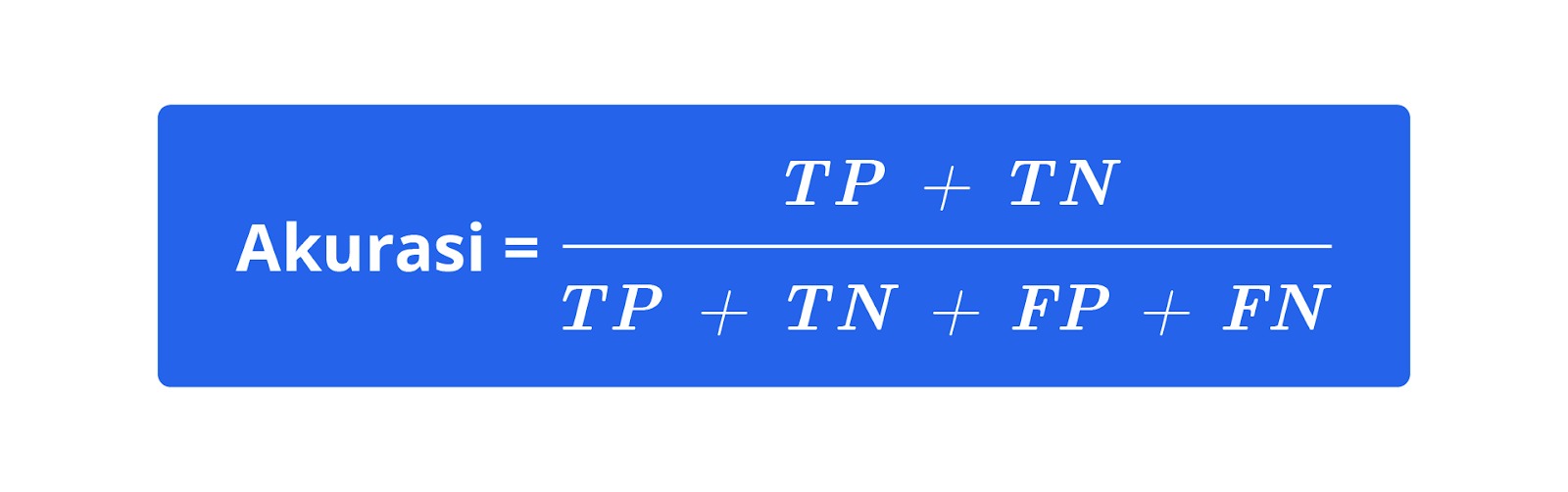
Contoh: Jika model Anda membuat 100 prediksi dan 90 di antaranya benar (baik positif maupun negatif), akurasi model tersebut adalah 90%. Namun, akurasi bisa menyesatkan jika ada ketidakseimbangan kelas (misalnya, jika ada lebih banyak contoh dari satu kelas dibandingkan dengan kelas lainnya).
Precision
Precision mengukur seberapa baik model menghindari positif palsu (false positives, FP). Ini adalah rasio prediksi positif yang benar terhadap semua prediksi positif yang dibuat oleh model.
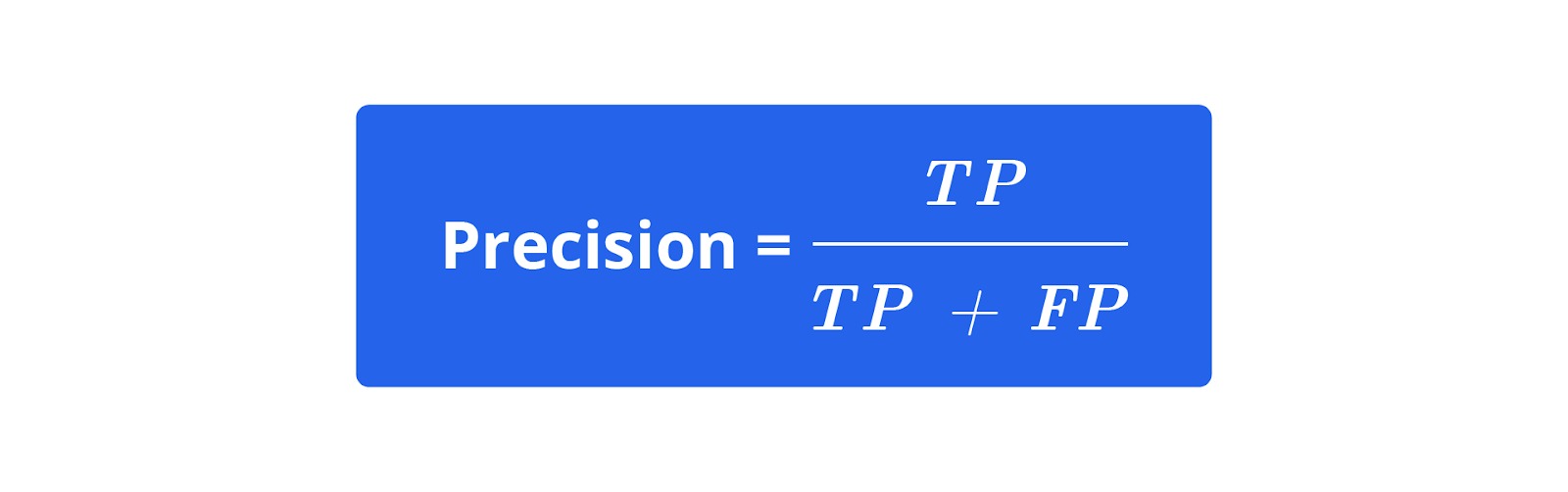
Contoh: Dalam sebuah model yang digunakan untuk mendeteksi penipuan, presisi tinggi berarti bahwa sebagian besar dari transaksi yang diklasifikasikan sebagai penipuan benar-benar merupakan penipuan, dan sangat sedikit transaksi yang tidak penipuan diklasifikasikan secara salah sebagai penipuan.
Recall (Sensitivitas)
Recall atau sensitivitas adalah metrik yang mengukur seberapa baik model dapat menangkap semua contoh positif. Ini adalah rasio prediksi positif yang benar terhadap semua kasus positif yang sebenarnya ada dalam data.
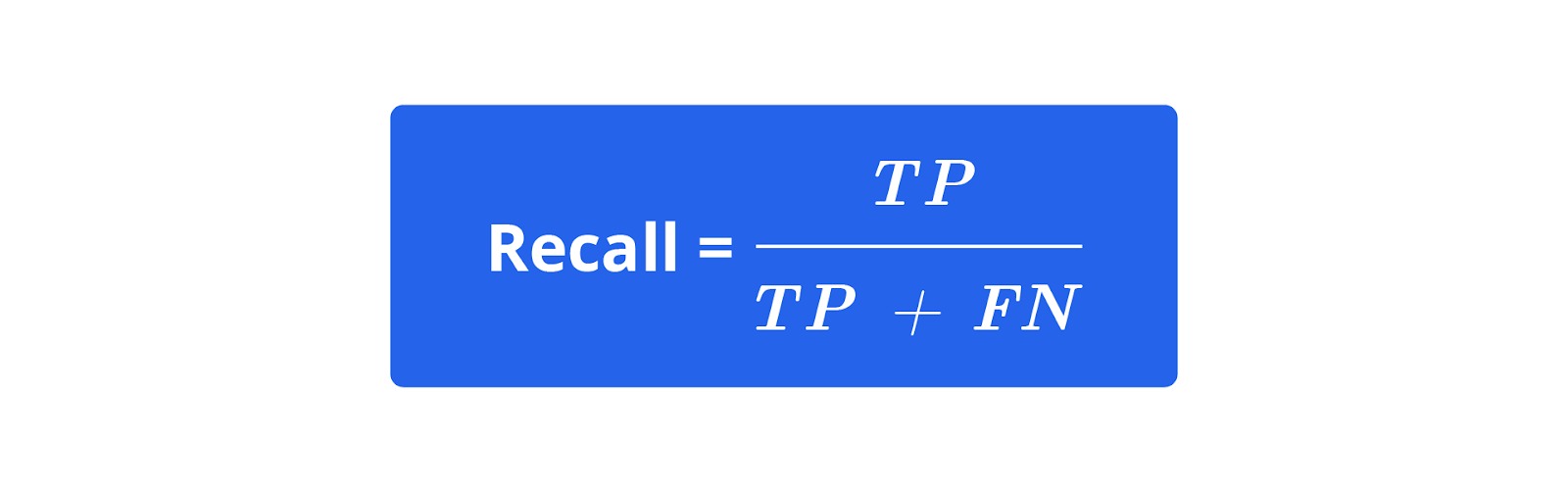
Contoh: Dalam konteks skrining kanker, recall yang tinggi berarti model mampu mendeteksi sebagian besar dari semua kasus kanker yang ada sehingga mengurangi risiko terlewatnya diagnosis.
F1-Score
F1-Score adalah metrik yang menggabungkan presisi dan recall menjadi satu nilai tunggal yang mempertimbangkan keduanya. F1-Score adalah rata-rata harmonis dari presisi dan recall, memberikan gambaran yang lebih baik ketika ada trade-off antara keduanya.

Contoh: F1-Score berguna dalam situasi jika ada ketidakseimbangan antara kelas positif dan negatif. Jika model memiliki presisi dan recall yang tidak seimbang, F1-Score dapat memberikan gambaran lebih akurat tentang performa keseluruhan model.
Memahami dan memilih metrik evaluasi yang tepat adalah langkah penting dalam menilai kinerja model klasifikasi. Setiap metrik, seperti akurasi, presisi, recall, dan F1-score, memberikan sudut pandang yang berbeda mengenai kinerja model dalam menangani data serta membuat prediksi. Menggunakan kombinasi metrik ini memungkinkan kita untuk mendapatkan gambaran yang lebih lengkap tentang kekuatan dan kelemahan model.
Contoh Perhitungan Confusion Matrix, Akurasi, Recall, Precision, dan F1-Score
Misalkan kita memiliki hasil prediksi model untuk sebuah dataset dengan 100 email yang diklasifikasikan sebagai spam atau bukan spam (ham). Data aktual dan prediksi model sebagai berikut.
- True Positives (TP): 30 (Email yang benar-benar spam dan diprediksi sebagai spam.)
- False Positives (FP): 10 (Email yang sebenarnya bukan spam, tetapi diprediksi sebagai spam.)
- True Negatives (TN): 50 (Email yang benar-benar bukan spam dan diprediksi sebagai bukan spam.)
- False Negatives (FN): 10 (Email yang sebenarnya spam, tetapi diprediksi sebagai bukan spam.)


[Story] Practice Makes Perfect
Di coworking space yang nyaman dengan pemandangan hijau nan asri, Diana dan Bilqis sudah siap untuk menyelesaikan proyek mereka. Setelah mempelajari algoritma klasifikasi, mereka akhirnya siap untuk mengaplikasikannya.
Diana membuka laptopnya dan melihat instruksi proyek yang diberikan dosen mereka. “Oke, Cis, jadi proyek kita kali ini adalah memprediksi apakah pelanggan bakal pergi atau tetap bertahan dengan layanan. Kita harus pakai lima algoritma klasifikasi yang udah kita pelajari.”

Bilqis sambil menyeruput kopi, bilang, “Yup, kita mulai dari data yang ada. Ada fitur-fitur kayak usia, saldo rekening, dan jumlah produk yang dimiliki. Langkah pertama, kita perlu bersihin data ini supaya siap dipakai.”
Diana setuju, “Iya, aku bakal urus pembersihan data. Kamu bisa mulai dengan mengubah fitur-fitur kategorikal ke format numerik. Gimana?”
Bilqis mengangguk sambil mempersiapkan encoding fitur, “Oke, siap! Nanti kita lihat hasil data ini kalau udah siap, baru deh kita masuk ke pemilihan dan pelatihan algoritma.”
Saat mereka mulai bekerja, suasana coworking space yang tenang dan pemandangan hijau di luar jendela membuat proses belajar jadi terasa lebih santai. Diana membersihkan data dari nilai yang hilang dan kesalahan, sementara Bilqis mengubah fitur-fitur kategorikal menjadi format numerik dengan menggunakan teknik encoding.
Bilqis kemudian mulai menjelaskan sambil mengetik kode pada laptopnya, “Jadi, kita bakal encode fitur-fitur kayak ‘Gender’ dan ‘Geography’ menjadi variabel numerik. Ini penting biar model klasifikasi kita bisa memproses data dengan benar.”
Diana mengangguk, “Oke, aku udah siap dengan pembersihan data. Setelah kita bersihin data, kita juga harus cek distribusi data untuk memastikan tidak ada ketidakseimbangan kelas yang signifikan.”

“Betul!” kata Bilqis. “Kita bakal periksa distribusi label ‘Exited’ untuk memastikan data kita seimbang atau butuh penyesuaian.”
Setelah data bersih dan siap, mereka beralih ke tahap berikutnya, yaitu menerapkan algoritma. Diana bilang, “Sekarang saatnya kita coba semua algoritma. Kita mulai dari K-Nearest Neighbors (KNN), lalu lanjut ke Decision Tree, Random Forest, SVM, dan Naive Bayes.”
Bilqis sambil mengetik kode pada laptopnya, menambahkan, “Betul, dan jangan lupa, kita harus evaluasi setiap model dengan metrik kayak akurasi, precision, recall, dan F1-Score. Ini penting buat nentuin model mana yang paling efektif.”
Diana membuka notebook dan mengatur visualisasi, “Kita juga harus siapkan visualisasi yang jelas buat laporan. Grafik-grafik ini bakal membantu kita menjelaskan hasil analisis ke dosen nanti.”
Setelah beberapa jam bekerja keras, mereka selesai melatih semua model. Diana melihat hasilnya lalu bilang, “Eh, Random Forest kayaknya paling oke deh. Precision dan F1-Score-nya tinggi.”
Bilqis setuju sambil melihat layar laptopnya, “Iya, dan kita juga harus tes model yang paling oke ini pada data uji buat memastikan modelnya bener-bener bisa diandalkan.”
Mereka memeriksa hasil akhir dan merasa puas dengan performa model yang sudah teruji. Diana kemudian mulai menyiapkan laporan akhir sambil menghela napas puas, “Wah, rasanya senang banget bisa selesaiin proyek ini dengan hasil yang bagus. Makasih banyak, Cis, udah jadi partner belajar yang keren!”
Bilqis tersenyum lebar sambil melihat pemandangan dari jendela, “Sama-sama, Na! Ini seru banget dan bermanfaat. Selain itu, pemandangan hijau ini bikin kerja jadi lebih enak. Ayo, kita nikmati sisa waktu kita di sini sebelum balik ke rutinitas kuliah!”
Mereka duduk santai sambil menikmati waktu mereka di coworking space. Bilqis mengeluarkan camilan kecil dari tasnya, “Eh, Na, kamu ada rencana akhir pekan ini?”
Diana tersenyum, “Rencananya sih mau istirahat, tapi mungkin bisa jalan-jalan bentar. Kenapa?”
Bilqis mengangguk sambil mengambil beberapa camilan, “Aku lagi mikir buat jalan-jalan ke tempat baru, mungkin bisa jadi tempat cari inspirasi berikutnya.”
Mereka melanjutkan obrolan sambil menikmati camilan dan memikirkan rencana ke depan, puas dengan hasil kerja keras mereka dan siap menghadapi tantangan berikutnya.
Latihan Studi Kasus: Klasifikasi Pelanggan untuk Churn pada Perusahaan XYZ
Hai, machine learning enthusiast!
Akhirnya kita sampai pada bagian terakhir, yaitu latihan studi kasus. Selamat, ya, Anda telah menyelesaikan modul ini dengan baik. Jangan lupa untuk mengucapkan terima kasih dan memberikan apresiasi kepada diri sendiri, ya! Anda luar biasa!
Pada bagian ini, kita akan menerapkan studi kasus yang telah dibahas oleh Diana dan Bilqis dalam cerita sebelumnya. Latihan ini berfokus pada penerapan algoritma klasifikasi dalam konteks nyata untuk membantu Perusahaan XYZ mengidentifikasi pelanggan yang berpotensi churn.
Dengan menggunakan dataset pelanggan dari perusahaan, kita akan mengimplementasikan beberapa algoritma klasifikasi yang telah dipelajari, seperti K-Nearest Neighbors, Decision Tree, Random Forest, dan Support Vector Machine. Tujuan utama adalah melatih model-model ini dan mengevaluasi kinerjanya dalam memprediksi kemungkinan churn sehingga memberikan wawasan yang berguna untuk tindakan preventif lebih efektif.
Mari kita mulai, ya!
Langkah 1: Mengimpor Library
Pada langkah pertama, berbagai library yang diperlukan untuk menganalisis data dan membangun model machine learning akan diimpor.
- import pandas as pd import numpy as np
- impor numpy sebagai np import seaborn as sns
- impor seaborn sebagai sns import matplotlib.pyplot as plt
- impor matplotlib.pyplot sebagai plt from sklearn.model_selection import train_test_split
- dari sklearn.model_selection impor train_test_split from sklearn.preprocessing import LabelEncoder, StandardScaler, MinMaxScaler
- dari sklearn.preprocessing impor LabelEncoder, StandardScaler, MinMaxScaler from sklearn.neighbors import KNeighborsClassifier
- dari sklearn.neighbors impor KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier
- dari sklearn.tree impor DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier
- dari sklearn.ensemble impor RandomForestClassifier from sklearn.svm import SVC
- dari sklearn.svm impor SVC from sklearn.naive_bayes import GaussianNB
- dari sklearn.naive_bayes impor GaussianNB from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
- dari sklearn.metrics impor confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
Berikut adalah penjelasan singkat dari masing-masing library yang diimpor.
- Pandas: Ini digunakan untuk memanipulasi dan menganalisis data dalam bentuk DataFrame. Library ini sangat berguna untuk membaca, menulis, dan mengelola data dalam berbagai format.
- numpy: Ini menyediakan dukungan untuk array dan operasi matematika tingkat tinggi. numpy sangat penting untuk perhitungan numerik yang efisien dalam machine learning.
- seaborn: seaborn adalah library untuk visualisasi data yang dibangun di atas matplotlib. Digunakan untuk membuat plot statistik yang lebih kompleks dan informatif.
- matplotlib.pyplot: Library dasar untuk membuat visualisasi data, seperti grafik dan plot. Sering digunakan bersama seaborn untuk memperindah visualisasi.
- sklearn.model_selection.train_test_split: Fungsi ini digunakan untuk membagi dataset menjadi data latih dan data uji, penting agar model yang dibangun dapat dievaluasi dengan data yang belum pernah dilihat sebelumnya.
- sklearn.preprocessing.LabelEncoder: Ini digunakan untuk mengubah data kategori menjadi bentuk numerik yang dapat diproses oleh algoritma machine learning.
- sklearn.preprocessing.StandardScaler: Ini digunakan untuk menstandardisasi fitur dengan menghilangkan rata-rata dan menyesuaikan skala ke unit varians. Ini sering diterapkan pada data sebelum dimasukkan ke model.
- sklearn.preprocessing.MinMaxScaler: Ini digunakan untuk mengubah fitur dengan membuat skala dari setiap fitur setiap fitur ke rentang yang ditentukan (biasanya antara 0 dan 1).
- sklearn.neighbors.KNeighborsClassifier: Ini merupakan algoritma K-Nearest Neighbors (KNN) yang digunakan untuk klasifikasi data berdasarkan kemiripan dengan tetangga terdekat.
- sklearn.tree.DecisionTreeClassifier: Algoritma Decision Tree digunakan untuk membuat model klasifikasi atau regresi dalam bentuk struktur pohon keputusan.
- sklearn.ensemble.RandomForestClassifier: Ini merupakan ensemble learning method yang menggabungkan beberapa Decision Tree untuk meningkatkan performa prediksi.
- sklearn.svm.SVC: Support Vector Machine digunakan untuk klasifikasi dengan mencari hyperplane yang memisahkan kelas-kelas data dengan margin terbesar.
- sklearn.naive_bayes.GaussianNB: Algoritma Naive Bayes digunakan untuk klasifikasi berdasarkan prinsip Teorema Bayes dengan asumsi sederhana bahwa fitur bersifat independen.
- sklearn.metrics: Library ini menyediakan berbagai fungsi untuk mengevaluasi performa model, seperti confusion_matrix, accuracy_score, precision_score, recall_score, dan f1_score.
Dengan mengimpor library ini, lingkungan kerja telah dipersiapkan untuk menganalisis data, membangun model, dan mengevaluasi hasilnya.
Langkah 2: Memuat Data
Pada langkah ini, data yang akan dianalisis diimpor dari Google Drive. Dimulai dengan menentukan ID unik file yang diunggah ke Google Drive, ID ini digunakan untuk membuat URL unduhan langsung yang memungkinkan akses file CSV melalui kode Python. Setelah URL terbentuk, file CSV dibaca dalam DataFrame menggunakan pustaka pandas, yang memungkinkan data disimpan dalam bentuk tabel dua dimensi.
Untuk memastikan bahwa data telah diimpor dengan benar, lima baris pertama dari DataFrame ditampilkan menggunakan perintah data.head(). Langkah ini memastikan bahwa data siap untuk proses eksplorasi dan analisis lebih lanjut.
- # Gantilah ID file dengan ID dari Google Drive URL
- file_id = '19IfOP0QmCHccMu8A6B2fCUpFqZwCxuzO'
- # Buat URL unduhan langsung
- download_url = f'https://drive.google.com/uc?id={file_id}'
- # Baca file CSV dari URL
- data = pd.read_csv(download_url)
- # Tampilkan DataFrame untuk memastikan telah dibaca dengan benar
- data.head()
Langkah awal dalam pengolahan data melibatkan pemeriksaan dan pembersihan dataset. Pertama, dilakukan peninjauan terhadap informasi umum dataset menggunakan fungsi data.info() untuk memahami jumlah entri, tipe data, serta memastikan tidak ada fitur yang memiliki data yang hilang.
- # Tampilkan informasi umum tentang dataset
- print("\nInformasi dataset:")
- data.info()
Disini kita akan dapat melihat anatomi dari data yang digunakan.
Berikut adalah penjelasan singkat setiap fitur dalam dataset.
- RowNumber: Nomor baris dalam dataset yang digunakan untuk identifikasi unik setiap entri. Fitur ini tidak memiliki makna analitis.
- CustomerId: ID unik yang mengidentifikasi setiap pelanggan dalam sistem. Ini berguna untuk referensi dan penggabungan data.
- Surname: Nama belakang pelanggan. Fitur ini tidak digunakan dalam analisis model karena tidak relevan.
- CreditScore: Skor kredit yang menunjukkan kelayakan kredit pelanggan. Skor ini dapat memengaruhi keputusan mereka untuk tetap atau berhenti menggunakan layanan.
- Geography: Lokasi geografis tempat tinggal pelanggan. Informasi ini dapat memengaruhi perilaku dan kebutuhan layanan pelanggan.
- Gender: Jenis kelamin pelanggan. Meskipun tidak selalu memengaruhi churn secara langsung, informasi ini berguna untuk analisis demografis.
- Age: Usia pelanggan. Usia dapat memengaruhi kebiasaan dan preferensi dalam menggunakan layanan.
- Tenure: Lama berlangganan pelanggan. Durasi berlangganan ini sering kali berhubungan dengan kemungkinan pelanggan untuk churn.
- Balance: Saldo rekening pelanggan. Saldo ini dapat memengaruhi kepuasan pelanggan dan kecenderungan mereka untuk tetap menggunakan layanan.
- NumOfProducts: Jumlah produk yang dimiliki pelanggan. Fitur ini membantu memahami keterlibatan pelanggan dengan berbagai produk.
- HasCrCard: Ini menunjukkan pelanggan memiliki kartu kredit atau tidak. Fitur ini dapat memengaruhi pengalaman pelanggan dengan layanan.
- IsActiveMember: Status keanggotaan aktif pelanggan. Ini menunjukkan pelanggan masih aktif atau tidak dalam menggunakan layanan.
- EstimatedSalary: Gaji yang diperkirakan dari pelanggan. Gaji dapat memengaruhi keputusan pelanggan untuk berlangganan atau berhenti dari layanan.
- Exited: Label target yang menunjukkan pelanggan telah keluar dari layanan (1) atau tidak (0). Fitur ini merupakan variabel yang ingin diprediksi dalam model klasifikasi.
Selanjutnya, pengecekan nilai yang hilang dilakukan pada setiap fitur menggunakan perintah data.isnull().sum() untuk mengidentifikasi bahwa ada fitur yang memerlukan penanganan khusus akibat kekurangan data.
- # Cek missing values
- print("\nMissing values per fitur:")
- print(data.isnull().sum())
Setelah itu, kolom-kolom yang dianggap tidak relevan untuk analisis lebih lanjut, seperti RowNumber, CustomerId, dan Surname, dihapus dari dataset. Langkah ini bertujuan untuk menghilangkan informasi yang tidak berkontribusi dalam prediksi sehingga model dapat lebih fokus pada fitur-fitur yang lebih penting.
Hasil akhir dari pembersihan ini ditinjau kembali dengan menampilkan beberapa baris pertama dataset untuk memastikan perubahan telah diterapkan dengan benar.
- # Hapus kolom 'RowNumber', 'CustomerId', dan 'Surname'
- data = data.drop(columns=['RowNumber', 'CustomerId', 'Surname'])
- # Tampilkan DataFrame untuk memastikan kolom telah dihapus
- data.head()
Langkah 3: Exploratory Data Analysis (EDA)
Exploratory Data Analysis (EDA) adalah tahap krusial dalam proses analisis data untuk memahami karakteristik, pola, dan hubungan antar fitur dalam dataset.
Dalam tahap ini, distribusi fitur numerik pertama-tama dianalisis. Setiap fitur numerik divisualisasikan menggunakan histogram yang menunjukkan distribusi nilai-nilai dalam fitur tersebut. Histogram ini dilengkapi dengan kurva densitas untuk memberikan gambaran lebih jelas tentang pola distribusi data: apakah data terdistribusi normal atau mengalami skewness?
- # Distribusi fitur numerik
- num_features = data.select_dtypes(include=[np.number])
- plt.figure(figsize=(14, 10))
- for i, column in enumerate(num_features.columns, 1):
- plt.subplot(3, 4, i)
- sns.histplot(data[column], bins=30, kde=True, color='blue')
- plt.title(f'Distribusi {column}')
- plt.tight_layout()
- plt.show()
Berikut adalah distribusi fitur numerik pada dataset ini. Setiap fitur numerik dianalisis melalui histogram yang menunjukkan sebaran nilai-nilai dalam fitur tersebut. Grafik-grafik ini membantu dalam memahami rentang nilai, kecenderungan pusat, serta potensi outliers pada setiap fitur numerik. Dengan memeriksa distribusi ini, wawasan penting mengenai karakteristik data yang akan memengaruhi pemodelan dan analisis selanjutnya dapat diperoleh.
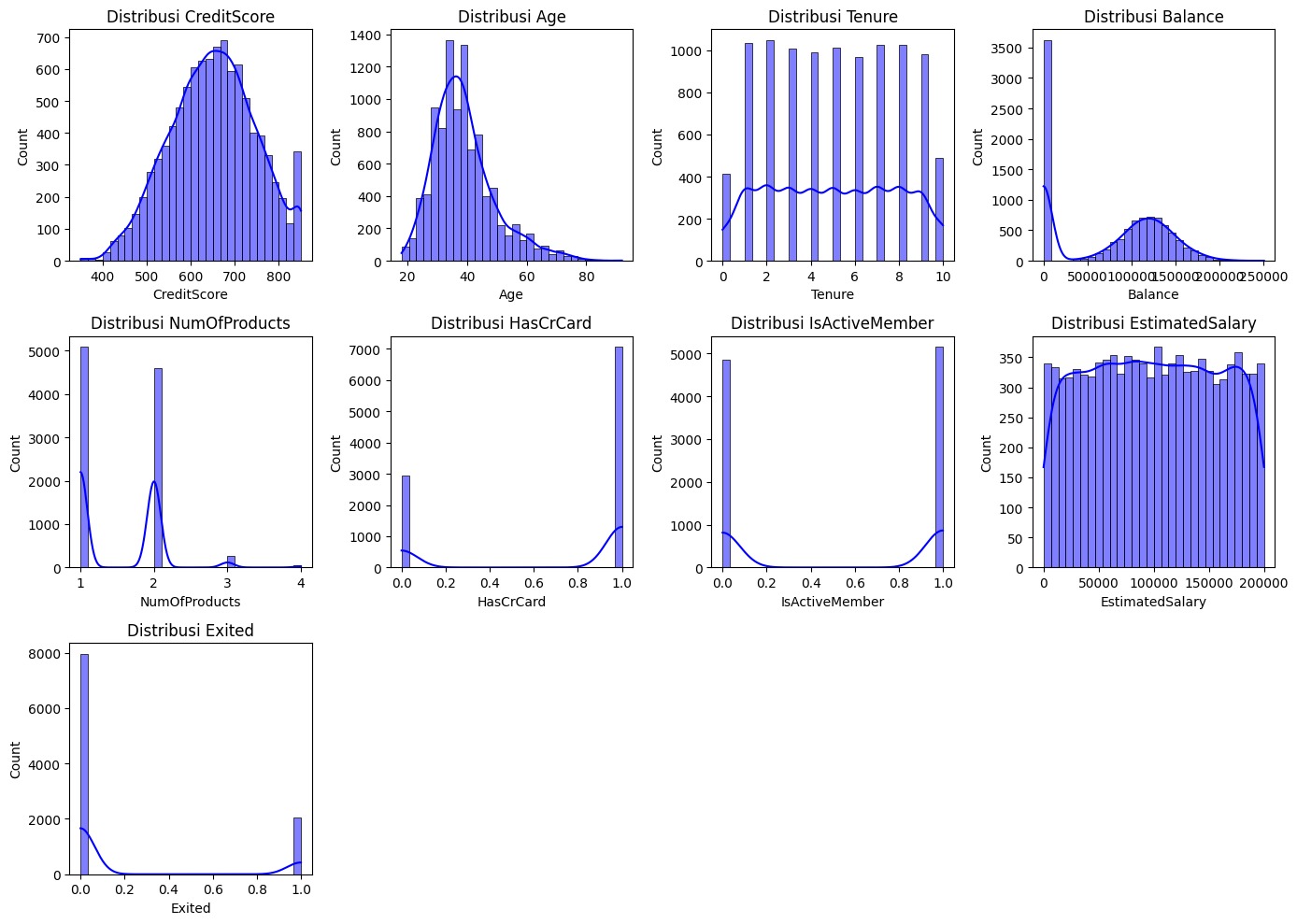
Selanjutnya, distribusi fitur kategorikal diperiksa dengan menggunakan grafik batang horizontal. Grafik ini memperlihatkan frekuensi setiap kategori dalam fitur kategorikal, membantu untuk memahami seberapa sering masing-masing kategori muncul dalam dataset.
- # Distribusi fitur kategorikal
- cat_features = data.select_dtypes(include=[object])
- plt.figure(figsize=(14, 8))
- for i, column in enumerate(cat_features.columns, 1):
- plt.subplot(2, 4, i)
- sns.countplot(y=data[column], palette='viridis')
- plt.title(f'Distribusi {column}')
- plt.tight_layout()
- plt.show()
Visualisasi ini berguna untuk mengidentifikasi kategori yang dominan atau langka, serta memberikan wawasan tentang sebaran data dalam kategori. Melalui EDA yang menyeluruh, pemahaman tentang dataset menjadi lebih mendalam, memfasilitasi pengambilan keputusan yang lebih baik dalam tahap pemodelan dan analisis lebih lanjut.
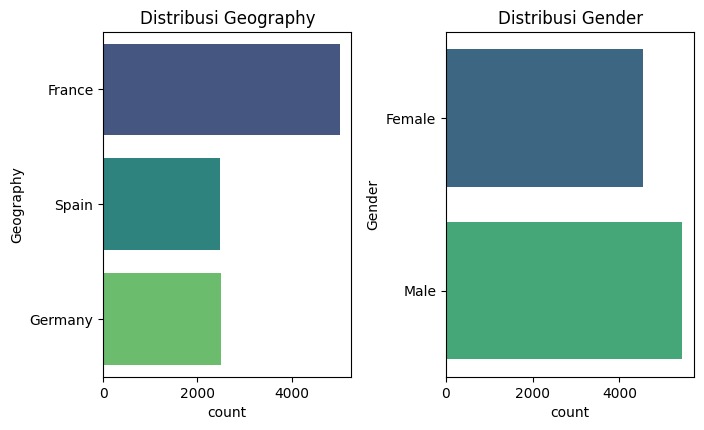
Kode ini menghasilkan heatmap korelasi yang memvisualisasikan hubungan antar fitur numerik dalam dataset. Dengan ukuran gambar 12 × 10 inci, heatmap ini menggunakan skema warna 'coolwarm' untuk menampilkan kekuatan korelasi antara fitur-fitur, dari korelasi negatif (biru) hingga positif (merah).
Nilai korelasi ditampilkan pada setiap sel dengan format dua desimal, sementara garis pembatas yang tipis antara sel memudahkan pembacaan. Matriks korelasi dihitung menggunakan fungsi corr() dari pandas yang mengukur hubungan linier antara fitur-fitur numerik.
- # Heatmap korelasi untuk fitur numerik
- plt.figure(figsize=(12, 10))
- correlation_matrix = num_features.corr()
- sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt='.2f', linewidths=0.5)
- plt.title('Heatmap Korelasi')
- plt.show()
Berikut adalah hasil dari heatmap.
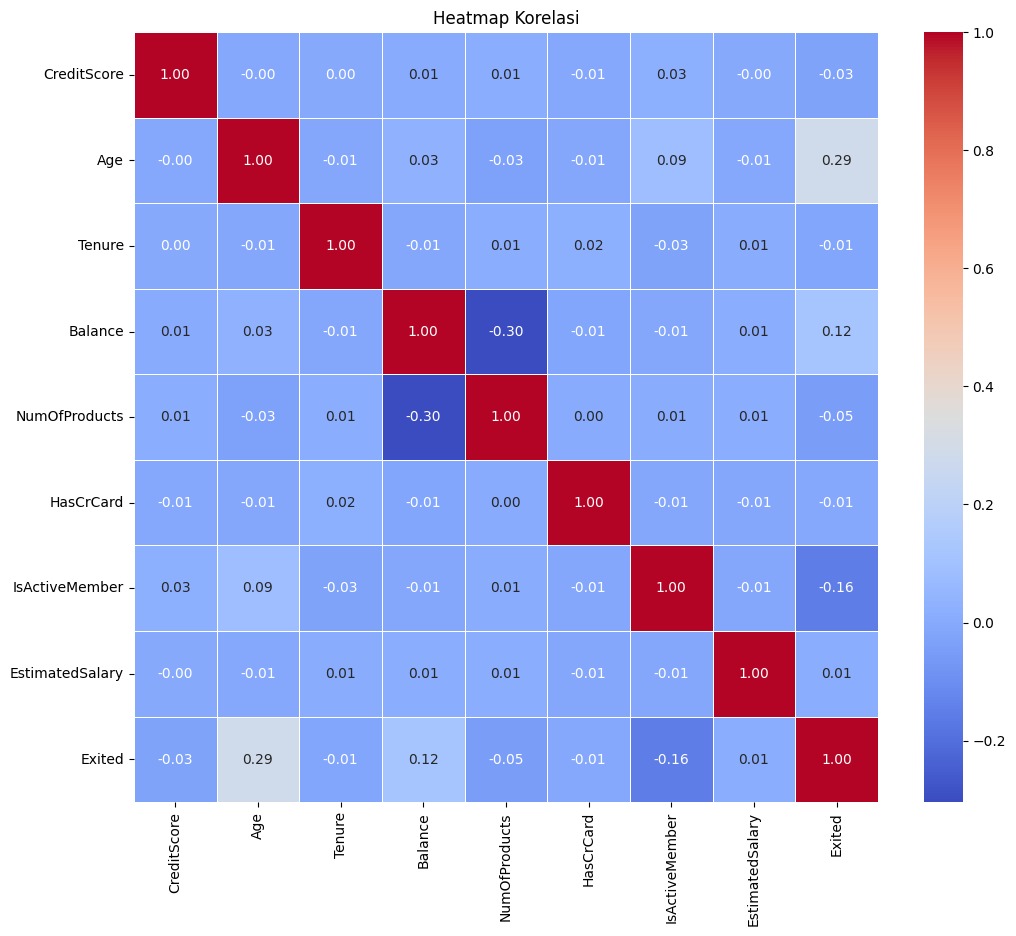
- # Pairplot untuk fitur numerik
- sns.pairplot(num_features)
- plt.show()
Kode ini menghasilkan pairplot untuk fitur-fitur numerik dalam dataset. Pairplot ini menyajikan grafik scatter plot untuk setiap pasangan fitur numerik yang memungkinkan visualisasi hubungan antara fitur-fitur tersebut. Selain itu, diagonal pairplot menampilkan histogram dari distribusi masing-masing fitur.
Dengan cara ini, pairplot membantu dalam mengidentifikasi pola, korelasi, dan distribusi di antara fitur-fitur numerik, serta mendeteksi potensi outlier atau hubungan non-linier yang mungkin ada. Berikut hasilnya.
Kode ini menampilkan visualisasi distribusi dari variabel target 'Exited' menggunakan plot hitung (count plot). Dengan menggunakan sns.countplot, grafik ini menunjukkan jumlah instance untuk masing-masing kelas dalam variabel target, yakni jumlah pelanggan yang keluar (churn) dan yang tidak keluar.
- # Visualisasi distribusi variabel target
- plt.figure(figsize=(8, 4))
- sns.countplot(x='Exited', data=data, palette='viridis')
- plt.title('Distribusi Variabel Target (Exited)')
- plt.show()
Warna pada grafik ditetapkan menggunakan palet 'viridis' untuk memperjelas perbedaan antar kelas. Visualisasi ini membantu memahami seberapa seimbang atau tidak seimbang distribusi kelas target dalam dataset.
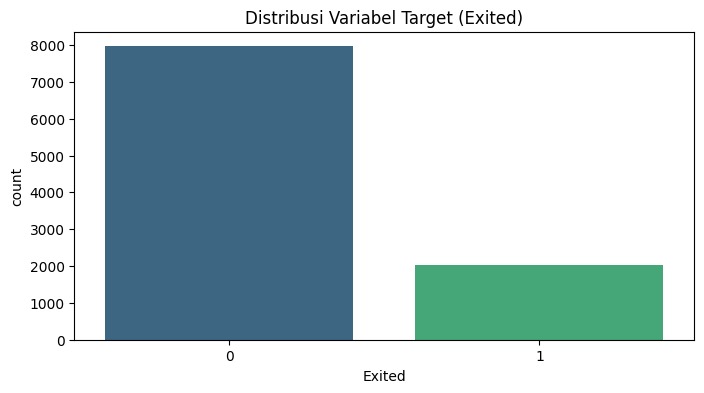
Pada bagian ini, terlihat adanya ketidakseimbangan antara jumlah pelanggan yang keluar (churn) dan yang tidak keluar dalam dataset. Ketidakseimbangan ini sering kali dapat memengaruhi performa model klasifikasi.
Meskipun demikian, permasalahan ini akan dibahas lebih lanjut dalam modul selanjutnya. Untuk latihan klasifikasi saat ini, fokus dapat tetap pada implementasi model tanpa harus memperhatikan ketidakseimbangan kelas ini terlebih dahulu.
Langkah 4: Label Encoder
Pada langkah ini, encoding diterapkan pada fitur kategorikal dalam dataset untuk mempersiapkan data bagi algoritma pembelajaran mesin. LabelEncoder digunakan untuk mengonversi nilai kategorikal menjadi format numerik yang dapat diproses oleh model.
- # Buat instance LabelEncoder
- label_encoder = LabelEncoder()
- # List kolom kategorikal yang perlu di-encode
- categorical_columns = ['Geography', 'Gender']
- # Encode kolom kategorikal
- for column in categorical_columns:
- data[column] = label_encoder.fit_transform(data[column])
- # Tampilkan DataFrame untuk memastikan encoding telah diterapkan
- data.head()
Kolom-kolom kategorikal, seperti 'Geography' dan 'Gender' diubah menjadi angka dengan menerapkan LabelEncoder. Setelah proses encoding, DataFrame ditampilkan kembali untuk memastikan bahwa perubahan telah diterapkan dengan benar. Berikut adalah hasil yang didapatkan.

Langkah 5: Data Splitting
Pada langkah ini, data numerik dinormalisasi menggunakan MinMaxScaler untuk memastikan bahwa semua fitur numerik berada dalam rentang yang sama, yang dapat meningkatkan performa model. Setelah normalisasi, data dibagi menjadi fitur (X) dan target (y).
Data kemudian dipisahkan menjadi set pelatihan dan set uji menggunakan train_test_split dengan 20% data digunakan untuk uji dan 80% untuk pelatihan. Bentuk dari set pelatihan dan set uji ditampilkan untuk memastikan bahwa pemisahan telah dilakukan dengan benar.
- # Buat instance MinMaxScaler
- scaler = MinMaxScaler()
- # Pisahkan fitur (X) dan target (y)
- X = data.drop(columns=['Exited'])
- y = data['Exited']
- # Split data menjadi set pelatihan dan set uji
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
- # Normalisasi semua kolom numerik
- numeric_columns = X_train.select_dtypes(include=['int64', 'float64']).columns
- X_train[numeric_columns] = scaler.fit_transform(X_train[numeric_columns])
- X_test[numeric_columns] = scaler.transform(X_test[numeric_columns])
- # Tampilkan bentuk set pelatihan dan set uji untuk memastikan split
- print(f"Training set shape: X_train={X_train.shape}, y_train={y_train.shape}")
- print(f"Test set shape: X_test={X_test.shape}, y_test={y_test.shape}")
Langkah 6: Pelatihan Model
Pada langkah ini, setiap algoritma klasifikasi dilatih secara terpisah dengan menggunakan data pelatihan. Model KNeighborsClassifier, DecisionTreeClassifier, RandomForestClassifier, SVC, dan GaussianNB dipersiapkan serta dilatih. Setelah proses pelatihan selesai, model-model ini siap untuk diuji dengan data uji. Pesan "Model training selesai." menandakan bahwa semua model sudah berhasil dilatih.
- # Bagian 1: Pelatihan Model
- # Definisikan setiap klasifikasi secara terpisah
- knn = KNeighborsClassifier().fit(X_train, y_train)
- dt = DecisionTreeClassifier().fit(X_train, y_train)
- rf = RandomForestClassifier().fit(X_train, y_train)
- svm = SVC().fit(X_train, y_train)
- nb = GaussianNB().fit(X_train, y_train)
- print("Model training selesai.")
Langkah 7: Evaluasi Model
Pada langkah ini, setiap model dievaluasi untuk mengukur kinerjanya. Fungsi evaluate_model digunakan untuk menghitung berbagai metrik performa, seperti matriks kebingungannya (confusion matrix), serta skor akurasi, presisi, recall, dan F1-Score.
Hasil evaluasi dari setiap model—yaitu K-Nearest Neighbors (KNN), Decision Tree (DT), Random Forest (RF), Support Vector Machine (SVM), dan Naive Bayes (NB)—dikumpulkan dalam sebuah DataFrame yang merangkum semua metrik penting tersebut. DataFrame ini kemudian ditampilkan untuk memberikan gambaran jelas mengenai kinerja masing-masing model.
- # Fungsi untuk mengevaluasi dan mengembalikan hasil sebagai kamus
- def evaluate_model(model, X_test, y_test):
- y_pred = model.predict(X_test)
- cm = confusion_matrix(y_test, y_pred)
- tn, fp, fn, tp = cm.ravel()
- results = {
- 'Confusion Matrix': cm,
- 'True Positive (TP)': tp,
- 'False Positive (FP)': fp,
- 'False Negative (FN)': fn,
- 'True Negative (TN)': tn,
- 'Accuracy': accuracy_score(y_test, y_pred),
- 'Precision': precision_score(y_test, y_pred),
- 'Recall': recall_score(y_test, y_pred),
- 'F1-Score': f1_score(y_test, y_pred)
- }
- return results
- # Mengevaluasi setiap model dan mengumpulkan hasilnya
- results = {
- 'K-Nearest Neighbors (KNN)': evaluate_model(knn, X_test, y_test),
- 'Decision Tree (DT)': evaluate_model(dt, X_test, y_test),
- 'Random Forest (RF)': evaluate_model(rf, X_test, y_test),
- 'Support Vector Machine (SVM)': evaluate_model(svm, X_test, y_test),
- 'Naive Bayes (NB)': evaluate_model(nb, X_test, y_test)
- }
- # Buat DataFrame untuk meringkas hasil
- summary_df = pd.DataFrame(columns=['Model', 'Accuracy', 'Precision', 'Recall', 'F1-Score'])
- # Isi DataFrame dengan hasil
- rows = []
- for model_name, metrics in results.items():
- rows.append({
- 'Model': model_name,
- 'Accuracy': metrics['Accuracy'],
- 'Precision': metrics['Precision'],
- 'Recall': metrics['Recall'],
- 'F1-Score': metrics['F1-Score']
- })
- # Konversi daftar kamus ke DataFrame
- summary_df = pd.DataFrame(rows)
- # Tampilkan DataFrame
- print(summary_df)
Langkah 8: Rangkuman Hasil dan Analisis
Pada tahap ini, hasil dari evaluasi berbagai model klasifikasi yang telah diterapkan pada dataset pelanggan dirangkum untuk memahami kinerja masing-masing model. Evaluasi ini mencakup metrik-metrik penting, seperti akurasi, presisi, recall, dan F1-Score, yang memberikan gambaran menyeluruh tentang kemampuan model dalam memprediksi pelanggan berpotensi churn.
Dengan menganalisis metrik-metrik tersebut, dapat diketahui model yang paling efektif dalam mengidentifikasi pelanggan yang akan berhenti berlangganan, serta kekuatan dan kelemahan masing-masing model.
Hasil Confusion Matrix Algoritma KNN
Model K-Nearest Neighbors (KNN) menunjukkan hasil evaluasi sebagai berikut. Matriks kebingungan mengungkapkan bahwa model berhasil mengidentifikasi 128 pelanggan yang sebenarnya churn (true positive) dengan benar, sementara 87 pelanggan yang sebenarnya tidak churn teridentifikasi sebagai churn (false positive).
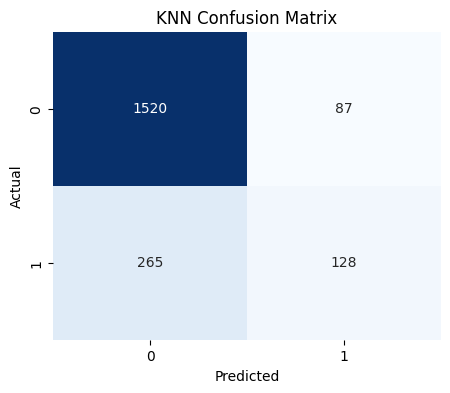
Sebaliknya, ada 265 pelanggan yang sebenarnya churn, tetapi tidak terdeteksi oleh model (false negative) dan 1520 pelanggan yang benar-benar tidak churn dan diprediksi dengan benar (true negative). Hasil ini memberikan gambaran tentang kemampuan model KNN dalam mengklasifikasikan pelanggan dengan tepat.
Hasil Confusion Matrix Algoritma Decision Tree
Untuk Decision Tree Classifier, hasil evaluasi menunjukkan distribusi prediksi sebagai berikut: ada 1360 true negative (TN) yang berarti pelanggan tidak churn terdeteksi dengan benar. Sebanyak 247 false positive (FP) menunjukkan bahwa pelanggan yang tidak churn salah diklasifikasikan sebagai churn.
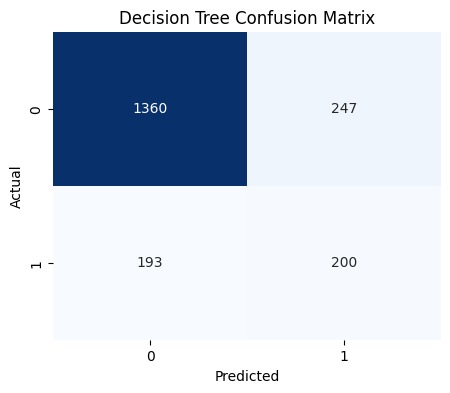
Selain itu, 193 false negative (FN) menggambarkan pelanggan yang sebenarnya churn, tetapi tidak teridentifikasi oleh model. Akhirnya, model berhasil mendeteksi 200 true positive (TP), yaitu pelanggan yang benar-benar churn. Analisis ini memberikan wawasan tentang kinerja model dalam memprediksi churn dan area yang perlu diperbaiki.
Hasil Confusion Matrix Algoritma Random Forest
Untuk Random Forest Classifier, hasil evaluasi menunjukkan distribusi prediksi sebagai berikut: ada 1557 true negative (TN) yang berarti pelanggan tidak churn terdeteksi dengan benar. Sebanyak 50 false positive (FP) menunjukkan pelanggan yang tidak churn salah diklasifikasikan sebagai churn.
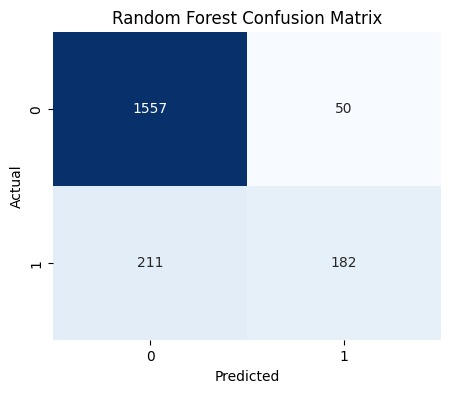
Model ini juga menghasilkan 211 false negative (FN) yang menggambarkan pelanggan yang sebenarnya churn, tetapi tidak teridentifikasi oleh model. Terakhir, ada 182 true positive (TP), yaitu pelanggan benar-benar churn yang berhasil terdeteksi oleh model. Hasil ini memberikan gambaran tentang seberapa baik Random Forest dalam memprediksi churn dan menunjukkan bahwa model menangani masing-masing kelas.
Hasil Confusion Matrix Algoritma SVM
Untuk Support Vector Machine (SVM) Classifier, hasil evaluasi menunjukkan distribusi prediksi sebagai berikut: ada 1581 true negative (TN), yang berarti pelanggan tidak churn terdeteksi dengan benar. Sebanyak 26 false positive (FP) menunjukkan pelanggan yang tidak churn salah diklasifikasikan sebagai churn.
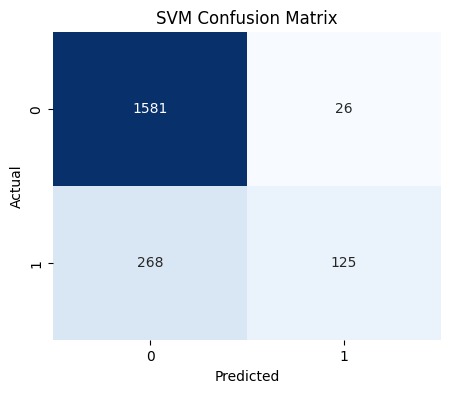
Model ini juga menghasilkan 268 false negative (FN), menggambarkan pelanggan yang sebenarnya churn, tetapi tidak teridentifikasi oleh model. Terakhir, ada 125 true positive (TP), yaitu pelanggan benar-benar churn yang berhasil terdeteksi oleh model. Hasil ini mencerminkan bahwa SVM mengelola prediksi churn dan performanya dalam klasifikasi.
Hasil Confusion Matrix Algoritma Naive Bayes
Untuk Naive Bayes Classifier, hasil evaluasi memberikan gambaran sebagai berikut: ada 1563 true negative (TN), menunjukkan jumlah pelanggan tidak churn yang terdeteksi dengan benar. Sebanyak 44 false positive (FP) menunjukkan pelanggan yang tidak churn salah diklasifikasikan sebagai churn.
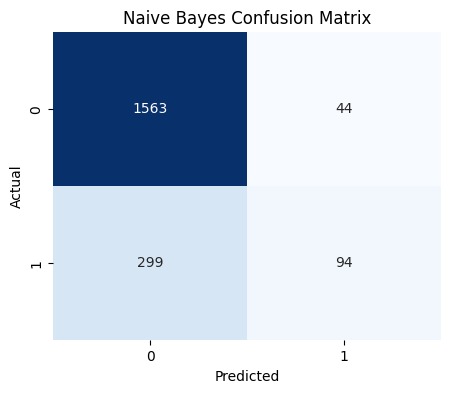
Model ini juga menghasilkan 299 false negative (FN), menunjukkan pelanggan yang sebenarnya churn, tetapi tidak teridentifikasi sebagai churn. Terakhir, ada 94 true positive (TP), yaitu pelanggan benar-benar churn yang berhasil terdeteksi oleh model. Hasil ini menggambarkan performa Naive Bayes dalam mengidentifikasi pelanggan yang akan churn.
Langkah 9: Rangkuman Hasil
Berikut adalah ringkasan hasil evaluasi untuk masing-masing model klasifikasi.
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
K-Nearest Neighbors | 0.8240 | 0.595349 | 0.325700 | 0.421053 |
Decision Tree | 0.7800 | 0.447427 | 0.508906 | 0.476190 |
Random Forest | 0.8695 | 0.784483 | 0.463104 | 0.582400 |
SVM | 0.8530 | 0.827815 | 0.318066 | 0.459559 |
Naive Bayes | 0.8285 | 0.681159 | 0.239186 | 0.354049 |
- K-Nearest Neighbors (KNN) menunjukkan akurasi sebesar 82.40%. Model ini memiliki precision 59.53%, recall 32.57%, dan F1-Score 42.11%. Angka precision yang relatif tinggi menunjukkan bahwa ketika model mengklasifikasikan seseorang sebagai churn, kemungkinan besar prediksi tersebut benar. Namun, recall yang rendah menunjukkan bahwa model ini sering gagal dalam mengidentifikasi pelanggan yang benar-benar churn.
- Decision Tree memperoleh akurasi sebesar 78.00%. Precision-nya adalah 44.74%, recall 50.89%, dan F1-Score 47.62%. Precision yang lebih rendah dibandingkan dengan KNN menunjukkan bahwa model ini kurang efektif dalam menghindari false positives. Meskipun recall-nya lebih baik, model ini masih kurang dalam hal ketepatan keseluruhan.
- Random Forest tampil dengan akurasi tertinggi sebesar 86.95%. Model ini memiliki precision 78.45%, recall 46.31%, dan F1-Score 58.24%. Tingginya precision menunjukkan model ini sangat baik dalam mengidentifikasi pelanggan yang churn dengan benar dan F1-Score yang baik menunjukkan keseimbangan yang baik antara precision dan recall.
- Support Vector Machine (SVM) memiliki akurasi 85.30%. Precision-nya mencapai 82.78%, recall 31.81%, dan F1-Score 45.96%. Precision yang sangat tinggi menandakan bahwa SVM efektif dalam mengklasifikasikan pelanggan yang churn. Namun, rendahnya recall menunjukkan bahwa model ini mungkin melewatkan banyak pelanggan churn yang sebenarnya.
- Naive Bayes menunjukkan akurasi 82.85%. Precision-nya adalah 68.12%, recall 23.92%, dan F1-Score 35.40%. Meskipun precision-nya relatif tinggi, recall yang sangat rendah menunjukkan bahwa model ini tidak efektif dalam mendeteksi banyak pelanggan churn.
Dalam rangkuman hasil evaluasi model, terlihat bahwa Random Forest adalah model dengan performa terbaik, mengungguli model lainnya dalam hal akurasi, precision, recall, dan F1-Score. Keunggulan ini menunjukkan kemampuannya dalam mengidentifikasi pelanggan yang churn dengan lebih baik dan akurat. Support Vector Machine (SVM) juga menunjukkan performa yang sangat baik dalam precision, tetapi memiliki recall lebih rendah, yang berarti model ini sering melewatkan beberapa pelanggan churn.
Sementara itu, K-Nearest Neighbors (KNN) dan Naive Bayes memiliki akurasi dan precision yang baik, tetapi kurang optimal dalam recall sehingga sering kali gagal dalam mendeteksi pelanggan churn yang sebenarnya. Decision Tree, meskipun memberikan hasil yang baik dalam recall, memiliki akurasi dan precision lebih rendah dibandingkan model-model lainnya.
Hasil ini memberikan wawasan berharga dalam memilih model yang paling sesuai untuk tugas klasifikasi churn dengan Random Forest sebagai kandidat utama pada implementasi lebih lanjut.
Sebagai penutup dari modul ini, berbagai aspek penting dalam klasifikasi data menggunakan algoritma machine learning telah dijelajahi.
Terima kasih sudah menyelesaikan modul klasifikasi ini dengan baik! Dalam modul dan latihan ini, berbagai algoritma klasifikasi serta cara menilai kinerja masing-masing model telah dipelajari.
Pengetahuan yang Anda dapatkan sangat berguna pada penerapan machine learning dalam kehidupan nyata dan akan menjadi fondasi kuat untuk eksplorasi lebih lanjut. Teruslah berlatih dan tingkatkan keterampilan Anda serta jangan ragu untuk mencoba teknik dan algoritma lainnya. Semangat terus dalam perjalanan belajar Anda! Sampai jumpa pada modul selanjutnya!
Rangkuman Supervised Learning - Klasifikasi
Berikut adalah rangkuman dari modul yang sudah kita pelajari.
Konsep Dasar Klasifikasi
Klasifikasi adalah teknik dalam machine learning untuk mengelompokkan data ke dalam kategori atau kelas tertentu berdasarkan karakteristik atau fitur dari data tersebut. Klasifikasi termasuk dalam supervised learning, yaitu model dilatih menggunakan data yang sudah diberi label. Contoh aplikasi klasifikasi termasuk pengenalan wajah, filter spam pada email, deteksi penipuan, dan diagnosis penyakit.
Tujuan utama klasifikasi adalah memprediksi kelas atau label dari data baru yang belum pernah dilihat oleh model berdasarkan pola yang telah dipelajari dari data latih. Misalnya, jika kita melatih model dengan data buah-buahan yang memiliki fitur ukuran, warna, dan bentuk, model tersebut bisa digunakan untuk mengidentifikasi jenis buah baru sebagai apel, pisang, atau jeruk.
Proses Klasifikasi: Langkah Demi Langkah
Proses klasifikasi terdiri dari beberapa tahapan penting. Berikut langkah-langkahnya.
- Pengumpulan Data
Data yang digunakan harus relevan, berkualitas baik, dan representatif terhadap masalah yang ingin diselesaikan. Data ini akan digunakan untuk melatih dan menguji model. - Pra-pemrosesan Data
Data mentah sering kali tidak siap digunakan oleh model. Pra-pemrosesan melibatkan membersihkan data, menangani data hilang, menghapus duplikasi, dan mengonversi data menjadi format yang bisa diproses oleh algoritma. - Pembagian Data
Data yang telah diproses kemudian dibagi menjadi dua set: data latih (training data) dan data uji (testing data). Biasanya, sekitar 70–80% digunakan untuk melatih model dan sisanya untuk menguji model. - Pemilihan Algoritma Klasifikasi
Pemilihan algoritma bergantung pada jenis data, ukuran dataset, dan kompleksitas masalah. Contoh algoritma klasifikasi yang populer adalah Decision Tree, K-Nearest Neighbors (KNN), Support Vector Machine (SVM), dan Random Forest. - Pelatihan Model
Model dilatih menggunakan data latih. Pada tahap ini, algoritma akan mempelajari pola dari data dan membangun model yang bisa digunakan untuk memprediksi kelas dari data baru. - Evaluasi Model
Setelah model dilatih, kinerjanya dievaluasi menggunakan data uji. Metrik seperti akurasi, precision, recall, dan F1-Score digunakan untuk menilai performa model. - Deployment
Setelah diuji dan terbukti efektif, model dapat digunakan dalam aplikasi nyata untuk memprediksi kelas dari data baru.
Jenis-Jenis Klasifikasi
Ada tiga jenis utama klasifikasi berdasarkan jumlah kelas atau label yang harus diprediksi.
- Klasifikasi Biner
Mengelompokkan data menjadi dua kategori atau kelas, seperti "spam" dan "bukan spam." - Klasifikasi Multikelas
Melibatkan lebih dari dua kelas. Misalnya, model harus memprediksi bahwa sebuah gambar termasuk kategori "anjing," "kucing," atau "burung." - Klasifikasi Multilabel
Sebuah data bisa dikategorikan ke lebih dari satu kelas sekaligus. Misalnya, sebuah artikel berita bisa diklasifikasikan sebagai "teknologi" dan "bisnis" sekaligus.
Contoh Aplikasi Klasifikasi
- Pengenalan Wajah: Mengklasifikasikan gambar wajah berdasarkan identitas individu.
- Deteksi Penipuan: Mengidentifikasi sebuah transaksi keuangan tergolong penipuan atau tidak.
- Filter Spam: Mengklasifikasikan email sebagai spam atau tidak spam.
K-Nearest Neighbors (KNN)
Algoritma K-Nearest Neighbors (KNN) adalah metode supervised learning yang digunakan untuk klasifikasi dan regresi. Dikembangkan oleh Evelyn Fix dan Joseph Hodges pada tahun 1951, dan kemudian diperluas oleh Thomas Cover, KNN dikenal sebagai salah satu algoritma klasifikasi yang paling sederhana serta intuitif dalam machine learning.
Parameter Utama KNN
- Jumlah Tetangga (K)
- Definisi: menentukan jumlah tetangga terdekat yang akan dipertimbangkan dalam klasifikasi.
- Nilai K Kecil: rentan terhadap noise dan outlier, berpotensi overfitting.
- Nilai K Besar: model lebih stabil, tetapi bisa underfitting karena pengaruh tetangga yang lebih jauh.
- Metric Jarak
- Euclidean Distance: jarak garis lurus antara dua titik.
- Manhattan Distance: jarak berdasarkan jumlah perbedaan sepanjang sumbu koordinat.
- Minkowski Distance: generalisasi dari Euclidean dan Manhattan dengan parameter p.
- Cosine Similarity: mengukur kesamaan sudut antara dua vektor, sering digunakan untuk data teks.
- Bobot (Weights)
- Uniform: semua tetangga memiliki pengaruh yang sama.
- Distance: tetangga yang lebih dekat memiliki bobot lebih besar.
- Panjang Jarak (Distance Metric Parameters)
- Contoh: parameter p dalam Minkowski Distance yang memungkinkan penyesuaian metrik jarak.
- Normalisasi Data
- Standardisasi: mengubah data sehingga memiliki mean 0 dan deviasi standar 1.
- Normalisasi Min-Max: mengubah data dalam rentang 0 hingga 1.
- Algoritma Pencarian Tetangga
- Brute Force: menghitung jarak antara data baru dan semua titik dalam dataset.
- KD-Tree: struktur data untuk mempercepat pencarian tetangga terdekat.
- Ball-Tree: struktur data untuk data berdimensi tinggi.
Cara Kerja KNN
- Persiapan Data: mengumpulkan dataset dengan fitur dan label.
- Pengukuran Jarak: menghitung jarak antara data baru dan setiap data dalam dataset.
- Pemilihan Jumlah Tetangga (K): menentukan berapa banyak tetangga yang akan dipertimbangkan.
- Identifikasi Tetangga Terdekat: menentukan K tetangga terdekat dari data baru.
- Voting Mayoritas: menentukan kelas berdasarkan mayoritas label dari tetangga terdekat.
- Pengambilan Keputusan Akhir: memberikan prediksi akhir berdasarkan voting mayoritas.
Kelebihan dan Kekurangan KNN
- Kelebihan
- Simpel dan intuitif.
- Non-parametrik dan cocok untuk berbagai jenis data.
- Efektif untuk dataset kecil.
- Kekurangan
- Komputasi berat untuk dataset besar.
- Sensitif terhadap noise dan data yang tidak relevan.
- Memori intensif karena menyimpan seluruh dataset.
Decision Tree
Decision Tree adalah algoritma machine learning yang digunakan dalam klasifikasi dan regresi. Struktur algoritma ini mirip dengan pohon dengan cabang yang mewakili keputusan berdasarkan fitur-fitur.
Parameter Utama Decision Tree
- Kriteria (Criterion)
- Gini Impurity: mengukur seberapa sering data dalam node bisa salah diklasifikasikan.
- Entropy: mengukur tingkat ketidakpastian atau keacakan data dalam node.
- Log Loss: alternatif lain untuk mengukur kualitas pembagian.
- Maksimal Kedalaman (max_depth)
- Kedalaman Terbatas: membantu mencegah overfitting.
- Kedalaman Tak Terbatas: pohon tumbuh hingga mencapai batas alami.
- Jumlah Minimum Sampel untuk Split (min_samples_split)
- Nilai Kecil: membagi node dengan sedikit sampel.
- Nilai Besar: memerlukan lebih banyak sampel untuk membagi node.
- Jumlah Minimum Sampel untuk Daun (min_samples_leaf)
- Nilai Kecil: leaf node bisa berisi sedikit sampel.
- Nilai Besar: setiap leaf node harus berisi minimal sampel yang ditentukan.
- Jumlah Maksimum Fitur untuk Pembagian (max_features)
- Nilai Kecil: hanya sebagian fitur yang dipertimbangkan untuk pembagian.
- Nilai Besar: semua fitur dipertimbangkan untuk pembagian.
- Splitter
- Best: memilih pembagian terbaik berdasarkan kriteria.
- Random: memilih pembagian secara acak dari subset fitur.
Cara Kerja Decision Tree
- Pemisahan Data Awal: memuat dataset dan membaginya berdasarkan fitur.
- Pemilihan Fitur dan Pembagian Data: memilih fitur untuk membagi data menggunakan kriteria, seperti Gini atau Entropy.
- Pembangunan Pohon: mengulangi proses pemilihan fitur dan pembagian hingga mencapai node daun.
Kelebihan dan Kekurangan Decision Tree
- Kelebihan
- Mudah dipahami dan diinterpretasikan.
- Memerlukan sedikit pra-pemrosesan data.
- Kekurangan
- Rentan terhadap overfitting.
- Pohon yang sangat dalam dapat menjadi kompleks dan sulit diinterpretasikan.
Random Forest
Random Forest adalah algoritma ensemble learning yang menggabungkan banyak Decision Trees untuk meningkatkan akurasi dan mengurangi risiko overfitting. Berikut adalah penjelasan mendetail tentang cara kerja dan parameter utama Random Forest.
Cara Kerja Random Forest
- Pengambilan Sampel Data
- Menggunakan teknik bootstrap, yaitu pengambilan sampel dengan penggantian dari dataset pelatihan asli.
- Setiap sampel data mungkin muncul lebih dari sekali dalam satu pohon.
- Pembentukan Decision Trees
- Untuk setiap sampel data, Decision Tree dibangun dengan memilih subset acak dari fitur pada setiap node.
- Proses Training
- Setiap Decision Tree dibangun hingga kedalaman maksimum yang ditentukan atau tidak ada pembagian lebih lanjut yang memungkinkan.
- Agregasi Prediksi
- Untuk klasifikasi: Hasil akhir ditentukan berdasarkan voting mayoritas dari semua pohon.
- Untuk regresi: Hasil akhir adalah rata-rata dari prediksi semua pohon.
- Evaluasi Model
- Diuji menggunakan data uji atau teknik validasi silang untuk mengevaluasi akurasi dan kemampuan generalisasi.
- Penerapan Model
- Model yang telah dilatih digunakan untuk membuat prediksi pada data baru.
Parameter Utama Random Forest
- n_estimators: jumlah Decision Trees dalam model. Semakin banyak pohon, semakin stabil model. Nilai default adalah 100, dan nilai yang disarankan berkisar antara 100 hingga 300.
- max_depth: kedalaman maksimum setiap pohon. Menetapkan nilai ini dapat membantu mencegah overfitting dan underfitting. Nilai sering digunakan adalah antara 10–20.
- min_samples_split: jumlah minimum sampel yang diperlukan untuk membagi node. Nilai default adalah 2. Nilai lebih tinggi membuat pohon lebih sederhana.
- min_samples_leaf: jumlah minimum sampel yang harus ada pada leaf node. Nilai default adalah 1 dengan nilai antara 1 hingga 5 sering digunakan untuk dataset besar.
- max_features: jumlah maksimum fitur yang dipertimbangkan untuk pemisahan setiap node. Nilai default adalah "sqrt" untuk klasifikasi dan "log2" untuk regresi.
- bootstrap: menentukan bahwa sampel diambil dengan penggantian. Default adalah True yang meningkatkan variasi antar pohon.
- random_state: parameter untuk kontrol pengacakan. Menetapkan nilai ini memastikan hasil yang konsisten setiap kali model dijalankan.
Kelebihan dan Kekurangan Random Forest
Kelebihan
- Akurasi tinggi.
- Robust terhadap overfitting.
- Kemampuan menangani data tidak seimbang.
- Menangani data hilang dengan baik.
- Menyediakan informasi tentang pentingnya fitur.
Kekurangan
- Kebutuhan memori yang tinggi.
- Interpretabilitas yang rendah.
- Lambat pada prediksi dengan banyak pohon.
- Kurang efektif pada data kecil.
- Waktu pelatihan yang lama.
Support Vector Machine (SVM)
Support Vector Machine (SVM) adalah algoritma machine learning yang digunakan terutama untuk klasifikasi. SVM mencari hyperplane yang optimal untuk memisahkan data ke dalam kelas berbeda dengan memaksimalkan margin antara hyperplane dan titik data terdekat dari setiap kelas.
Cara Kerja SVM
- Pengumpulan dan Persiapan Data
Data dipersiapkan melalui pra-pemrosesan, termasuk pembersihan, penanganan nilai hilang, dan normalisasi. - Pemetaan Data ke Ruang Fitur yang Lebih Tinggi
Menggunakan fungsi kernel untuk memetakan data ke ruang fitur yang lebih tinggi, ini memungkinkan data non-linier untuk dipisahkan secara linier. - Menentukan Hyperplane
Mencari hyperplane yang memisahkan kelas dengan margin maksimum. - Identifikasi Support Vectors
Titik data yang terletak paling dekat dengan hyperplane, ini menentukan posisi dan orientasi hyperplane. - Penanganan Data Tidak Terpisahkan Secara Linier
Kernel trick digunakan untuk menangani data yang tidak dapat dipisahkan secara linier dalam ruang fitur asli. - Mengatur Parameter Regularization ©
Mengontrol kekuatan regularisasi dengan nilai C yang lebih tinggi mengurangi regularisasi dan nilai C yang lebih rendah meningkatkan regularisasi. - Evaluasi dan Tuning Model
Evaluasi model menggunakan data uji dan tuning hyperparameter untuk meningkatkan performa. - Implementasi dan Penggunaan Model
Model yang sudah dilatih diterapkan untuk prediksi pada data baru.
Parameter Utama SVM
- Kernel: fungsi yang digunakan untuk mengubah data ke ruang fitur yang lebih tinggi. Tipe kernel termasuk linear, polynomial, RBF, sigmoid, dan precomputed.
- Gamma: faktor yang menentukan seberapa besar pengaruh setiap titik data pada keputusan model. Nilai dapat diatur dengan 'scale', 'auto', atau nilai float.
- Regularization (C): mengontrol kekuatan regularisasi untuk mencegah overfitting. Nilai yang lebih besar berarti kurang regularisasi dan nilai yang lebih kecil berarti lebih banyak regularisasi.
- Degree: hanya berlaku untuk kernel polinomial, ini menentukan derajat polinomial yang digunakan untuk memetakan data ke ruang fitur yang lebih tinggi.
Kelebihan SVM
- Margin Maksimal: meningkatkan generalisasi.
- Kemampuan Non-Linier: menggunakan kernel trick untuk data non-linier.
- Kinerja Baik pada Data Kecil: efektif dengan dataset kecil.
- Efektif pada Dimensi Tinggi: berfungsi baik dengan banyak fitur.
Kekurangan SVM
- Kompleksitas Komputasi: lambat dan memerlukan banyak memori untuk dataset besar.
- Pemilihan Parameter: memerlukan tuning parameter yang hati-hati.
- Tidak Biasa Menghasilkan Probabilitas: tidak memberikan probabilitas klasifikasi.
- Interpretasi Model Sulit: sulit dipahami, terutama dengan kernel non-linier.
Naive Bayes
Naive Bayes adalah algoritma klasifikasi berbasis probabilitas yang didasarkan pada Teorema Bayes. Algoritma ini mengasumsikan bahwa fitur-fitur dalam data bersifat independen satu sama lain (asumsi "naive"), meskipun dalam kenyataannya, fitur-fitur seringkali saling terkait. Naive Bayes menghitung probabilitas suatu data termasuk dalam kelas tertentu berdasarkan probabilitas prior (kemunculan kelas secara umum) dan probabilitas likelihood (kemunculan fitur tertentu dalam kelas tersebut).
Cara Kerja Naive Bayes
- Mengumpulkan dan Menyiapkan Data: mengumpulkan data yang diberi label, membersihkannya, dan mengidentifikasi fitur penting.
- Menghitung Probabilitas Prior: menghitung probabilitas kemunculan setiap kelas tanpa mempertimbangkan fitur.
- Menghitung Probabilitas Likelihood: mengukur frekuensi kemunculan fitur dalam setiap kelas.
- Menerapkan Teorema Bayes: menghitung probabilitas posterior berdasarkan probabilitas prior dan likelihood.
- Klasifikasi: memilih kelas dengan probabilitas tertinggi sebagai hasil klasifikasi.
- Evaluasi dan Tuning: menilai performa model dan melakukan penyempurnaan.
- Implementasi Model: menggunakan model untuk prediksi pada data baru.
Parameter Utama
- Laplace Smoothing: teknik untuk mencegah probabilitas nol dengan menambahkan nilai kecil pada fitur yang tidak muncul.
- Probabilitas Prior: probabilitas awal kemunculan kelas sebelum mempertimbangkan fitur.
- Probabilitas Likelihood: probabilitas kemunculan fitur tertentu dalam kelas.
Kelebihan Naive Bayes
- Mudah diimplementasikan dan sederhana secara matematis.
- Cepat dalam pelatihan dan prediksi, bahkan dengan dataset besar.
- Efisien untuk data dengan banyak fitur dan menangani data yang hilang.
Kekurangan Naive Bayes
- Asumsi independensi fitur sering tidak sesuai dengan kenyataan.
- Kinerja menurun pada data yang sangat tidak seimbang atau jika fitur saling bergantung.
- Terbatas pada distribusi data yang diasumsikan, misalnya Gaussian atau multinomial.
Naive Bayes cocok digunakan dalam aplikasi, seperti filter spam, analisis sentimen, dan pengenalan pola meskipun performanya bisa menurun jika asumsi model tidak terpenuhi.
Evaluasi Model Klasifikasi
Evaluasi model klasifikasi penting untuk menilai efektivitas model dalam memprediksi kategori yang benar. Berikut adalah metode dan metrik utama yang digunakan.
Confusion Matrix
Confusion matrix adalah tabel yang menunjukkan hasil prediksi model, ini memberikan pandangan rinci tentang kinerja model dalam berbagai kelas.
- True Positives (TP): kasus positif yang benar-benar diprediksi sebagai positif.
- True Negatives (TN): kasus negatif yang benar-benar diprediksi sebagai negatif.
- False Positives (FP): kasus negatif yang diprediksi sebagai positif (kesalahan tipe I).
- False Negatives (FN): kasus positif yang diprediksi sebagai negatif (kesalahan tipe II).
Contoh: Dalam model deteksi penyakit, dengan 100 sampel:
- TP: 30 kasus positif benar.
- FN: 10 kasus positif salah.
- TN: 55 kasus negatif benar.
- FP: 5 kasus negatif salah.
Metrik Evaluasi Klasifikasi
- Akurasi
- Definisi: Proporsi prediksi benar (positif dan negatif) terhadap total prediksi.
- Contoh: Jika dari 100 prediksi, 90 benar, akurasi adalah 90%. Akurasi dapat menyesatkan pada data tidak seimbang.
- Precision
- Definisi: Rasio prediksi positif yang benar terhadap semua prediksi positif.
- Contoh: Dalam deteksi penipuan, precision tinggi berarti sebagian besar transaksi yang diklasifikasikan sebagai penipuan benar-benar penipuan.
- Recall (Sensitivitas)
- Definisi: Rasio prediksi positif benar terhadap semua kasus positif yang sebenarnya.
- Contoh: Dalam skrining kanker, recall tinggi berarti model mendeteksi sebagian besar kasus kanker, ini mengurangi risiko terlewatnya diagnosis.
- F1-Score
- Definisi: Rata-rata harmonis dari precision dan recall, ini memberikan gambaran tentang trade-off antara keduanya.
- Contoh: F1-Score berguna untuk situasi dengan ketidakseimbangan kelas, ini memberikan penilaian yang lebih seimbang antara precision dan recall.
Menggunakan kombinasi metrik, seperti akurasi, precision, recall, dan F1-Score memberikan gambaran yang lebih lengkap tentang kinerja model klasifikasi serta membantu untuk memahami kekuatan dan kelemahan model dalam menangani data serta membuat prediksi.
Bersambung ke:
Pengantar Supervised Learning - Regresi
- Get link
- X
- Other Apps



Comments
Post a Comment