Pendahuluan Clustering
- Get link
- X
- Other Apps
Pendahuluan Clustering
Hi, machine learning enthusiast!
Selamat datang pada Modul 5, di sini kita akan menjelajahi salah satu konsep yang menarik dalam dunia unsupervised learning, yaitu clustering!
Namun, sebelum itu, bagaimana pengalaman belajar Anda sejauh ini? Kami harap Anda sudah merasa siap untuk memperdalam pemahaman mengenai teknik-teknik yang akan kita bahas pada modul ini.
Clustering adalah proses pengelompokan data ke dalam kelompok-kelompok berdasarkan kesamaan atau karakteristik tertentu. Berbeda dengan teknik klasifikasi yang memerlukan label untuk setiap data, clustering memungkinkan kita untuk menemukan struktur dalam data tanpa bantuan label. Hal ini membuatnya sangat berguna dalam berbagai aplikasi, mulai dari segmentasi pasar hingga pengelompokan dokumen, analisis citra, dan banyak lagi.
Dalam Modul 5 ini, kita akan membahas berbagai metode clustering, termasuk hierarchical clustering dan non-hierarchical clustering. Kita juga akan mempelajari algoritma populer, seperti K-Means dan DBSCAN yang dapat membantu meningkatkan kinerja model clustering.
Jadi, siap-siap saja untuk menyelami dunia clustering yang seru ini dan menemukan cara-cara keren buat menganalisis serta memahami data Anda! Kita akan membahas berbagai metode clustering yang bisa membuat Anda lebih jago dalam mengelompokkan data.
Bayangkan Anda sedang bermain detektif data, mencari pola dan struktur tersembunyi di antara tumpukan informasi yang ada. Keren, kan? Semoga sukses, tetap semangat, dan terus fokus!
[Story] Jalan-Jalan di Hari Weekend. Cakeep
Pada suatu sore menjelang akhir pekan, setelah kelas terakhir yang cukup melelahkan, Diana dan Bilqis memilih untuk bersantai di kantin kampus. Meskipun tampak lelah, keduanya terlihat senang karena akhirnya bisa menikmati akhir pekan yang sudah di depan mata.
Diana dengan nada santai membuka percakapan, “Cis, besok ada rencana keluar, enggak?”
Bilqis menjawab, “Belum ada sih, Na. Kayaknya aku mau menikmati slow morning dulu, hehehe. Emang kenapa?”
Diana kemudian mengusulkan, “Gimana kalau besok kita jalan-jalan ke mal?”
Bilqis menjawab lagi, “Emangnya mau ngapain ke mal?”
“Mumpung lagi weekend, aku mau belanja beberapa keperluanku yang udah habis. Sekalian cuci mata, siapa tahu ada yang menarik, hahaha,” jawab Diana.
Tawaran tersebut langsung menarik perhatian Bilqis. “Wah, boleh, tuh. Jam berapa kita pergi? Jangan pagi, ya, agak siangan gitu.” sahut Bilqis penuh semangat.
Diana berpikir sejenak dan berkata, “Gimana kalau habis makan siang? Jam 1 aja, ya, nanti aku jemput kamu pakai motor aku. Jangan lupa bawa helm!”
Bilqis tertawa kecil dan menjawab, “Siap, Bu Bos!”

Keesokan harinya, seperti yang dijanjikan, Diana tiba tepat waktu di rumah Bilqis untuk menjemputnya. Mereka pun berangkat bersama menuju mal dengan motor Diana. Sesampainya di mal, suasana yang ramai dan penuh semangat langsung terasa, menambah antusiasme mereka. Bagi banyak orang, apalagi perempuan, berjalan-jalan di mal bisa menjadi cara tersendiri untuk healing dari rutinitas. Setuju enggak, girls? Hehehe.
“Kamu mau beli apa, Na?” tanya Bilqis sambil tersenyum saat mereka mulai memasuki area belanja.
Diana, dengan nada bercanda, menjawab, “Aku sih awalnya cuma mau nyari sabun dan sampo yang udah habis. Tapi ya, enggak tau deh, kalau nanti ada barang lain yang tiba-tiba ikut masuk ke keranjang, hahaha.”
Bilqis tertawa mendengar jawaban itu, “Sudah kuduga! Mana mungkin kamu ke mal cuma buat beli sabun dan sampo doang. Itu mah belanja di online shop juga beres.”
Setelah tertawa bersama, Diana mengambil keranjang belanja dari dekat pintu masuk supermarket. Sambil berjalan menyusuri lorong-lorong, mereka memperhatikan tanda-tanda diskon yang menggoda pada berbagai produk.
“Eh, banyak diskon, ya, Cis,” kata Diana sambil melihat beberapa produk yang dipajang dengan harga lebih murah.
Bilqis mengangguk, “Iya, tapi diskonnya beda-beda. Ada yang 20%, ada juga yang cuma 10%.”
Rasa penasaran muncul di benak Diana. “Kok bisa gitu, ya? Gimana sih mereka nentuin barang apa yang dikasih diskon dan kenapa diskonnya bisa beda-beda?”
Mereka berdua sejenak terdiam, merenung mencari jawabannya.

Sambil melanjutkan belanja, Bilqis mencoba menganalisis, “Mungkin mereka punya cara tertentu buat nentuin produk mana yang enggak terlalu laku atau stoknya kebanyakan, jadi dikasih diskon biar cepat habis.”
Diana setuju, “Iya, atau mungkin mereka pakai data penjualan buat nentuin barang mana yang sering dibeli bersamaan, terus kasih diskon biar pelanggan tergoda buat beli lebih banyak.”
Percakapan ini membuat mereka teringat pada pelajaran clustering yang mereka dapatkan di kelas. Bilqis kemudian menyadari, “Eh, ini kayak clustering, ya? Mungkin mereka pakai teknik clustering buat mengelompokkan produk yang punya karakteristik mirip, terus dikasih diskon buat menarik perhatian pembeli.”
Diana menanggapi, “Kayaknya sih iya, masuk akal banget.”
Setelah berdiskusi tentang diskon, mereka melanjutkan perjalanan menyusuri rak-rak yang dipenuhi berbagai produk. Mata mereka kemudian tertuju pada bagian tertentu yang diatur dengan cara yang tampak strategis.

“Eh, Cis, lihat deh,” kata Diana sambil menunjuk ke sebuah rak. “Perhatiin enggak, produk di sini disusun dengan cara tertentu. Pada bagian skincare, ada satu rak yang isinya produk-produk buat kulit berminyak dan di sebelahnya langsung produk buat kulit kering.”
Bilqis mulai memperhatikan lebih saksama, “Iya, ya. Pada bagian lain, ada rak yang isinya produk-produk yang dikelompokkan sesuai dengan karakteristiknya, kayak sampo sama conditioner dari merek yang sama. Terus, coba lihat rak lainnya di sebelah sana, ada banyak macam body lotion yang sesuai untuk beragam tipe kulit tertentu.”
Mereka berdua kembali terdiam sejenak, memikirkan pengamatan mereka. Diana tersenyum dan berkata, “Fix sih, ini mirip banget sama konsep clustering yang kita pelajari. Supermarket ini kayaknya pakai teknik clustering buat mengelompokkan produk-produk yang punya karakteristik sama.”
Bilqis setuju, “Benar juga! Mereka mengelompokkan produk berdasarkan pola belanja pelanggan. Misalnya, pelanggan yang sering beli produk untuk kulit berminyak kemungkinan juga akan tertarik sama produk lain yang membantu mengatasi minyak berlebih. Jadi, mereka susun produk-produk itu di rak yang sama supaya lebih mudah dicari.”

Diana menambahkan, “Iya, dan ini juga memudahkan pelanggan buat menemukan produk yang mereka butuhkan tanpa harus keliling-keliling. Selain itu, ini bisa ningkatin penjualan, karena kalau orang lihat produk yang saling melengkapi dipajang barengan, mereka bisa tergoda buat beli lebih banyak.”
Semakin mereka berjalan, semakin mereka tertarik dengan cara produk-produk diatur di supermarket. Diana pun berkata, “Kayaknya ini bisa jadi ide bagus buat tugas kita nanti. Kita bisa coba analisis data belanja dari bisnis skincare kamu, Cis, dan lihat gimana kita bisa mengelompokkan produk-produk yang punya karakteristik sama.”

Bilqis tersenyum penuh antusiasme, “Setuju, Na! Ide ini menarik banget. Siapa tahu, kita bisa bantu ningkatin penjualan di olshop-ku juga.”
Setelah berbelanja, mereka duduk di food court, melanjutkan diskusi tentang cara mereka bisa menerapkan konsep clustering di toko online skincare milik Bilqis. Mereka merasa sangat bersemangat dengan ide baru ini, yang tidak hanya berguna untuk tugas kuliah, tetapi juga bisa membawa manfaat nyata bagi bisnis Bilqis.
Di penghujung hari, mereka pulang dengan perasaan puas dan bahagia. Selain membawa pulang belanjaan lebih banyak dari rencana, mereka juga mendapatkan pemahaman lebih dalam tentang konsep yang mereka pelajari di kelas dapat diaplikasikan dalam kehidupan sehari-hari. Siapa sangka, dari sekadar jalan-jalan di supermarket, mereka bisa menemukan analogi yang jelas untuk memahami konsep clustering yang diajarkan di kelas
Konsep Dasar Clustering
Clustering adalah metode analisis data yang digunakan untuk mengelompokkan objek-objek data ke dalam grup-grup atau cluster berdasarkan kemiripan atau kesamaan fitur. Pada clustering, tujuan utamanya adalah mengidentifikasi struktur atau pola tersembunyi dalam data tanpa memerlukan label atau informasi yang telah ditentukan sebelumnya. Ini berarti clustering termasuk teknik unsupervised learning, yakni model tidak dilatih dengan data berlabel, tetapi hanya dengan data fitur untuk menemukan pola.
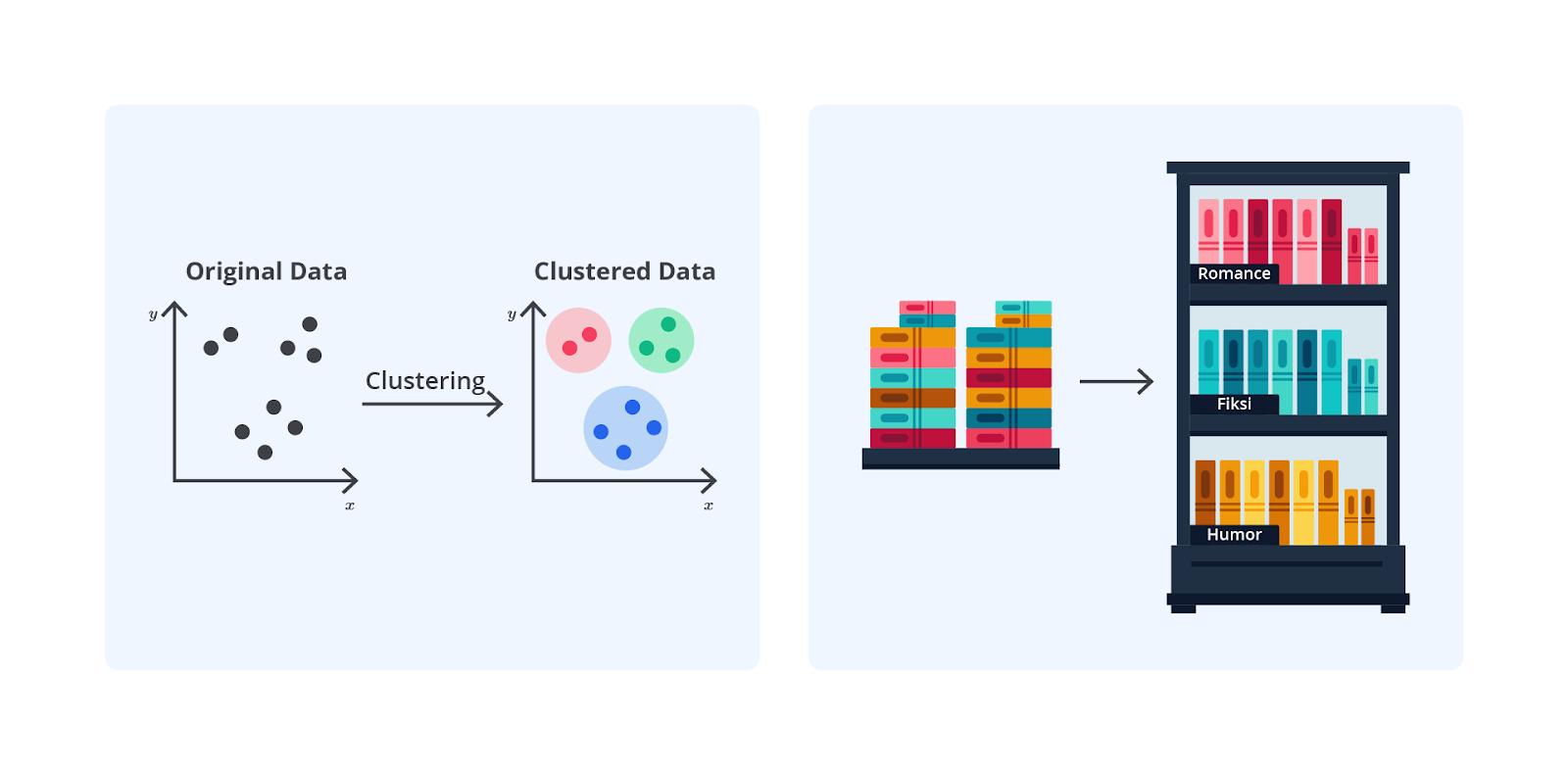
Bayangkan Anda seorang pustakawan yang baru menerima koleksi buku untuk perpustakaan. Tugas Anda adalah mengatur buku-buku tersebut dalam rak-rak tanpa mengetahui sebelumnya kategori yang ada. Anda mulai dengan mengumpulkan semua buku baru, yang mencakup berbagai genre, seperti fiksi, non-fiksi, dan ilmiah.
Selanjutnya, Anda memutuskan untuk mengelompokkan buku berdasarkan genre sebagai fitur utama sehingga buku-buku dengan genre yang sama akan dikelompokkan bersama. Dengan metode ini, buku-buku fiksi akan berada pada rak yang sama, sementara buku non-fiksi dan ilmiah akan diletakkan dalam rak berbeda.
Proses ini mirip dengan clustering, yaitu pengelompokan data berdasarkan kemiripan atau kesamaan fitur untuk mempermudah pengorganisasian dan pemahaman, tanpa memerlukan informasi tambahan mengenai kategori yang sudah ada.
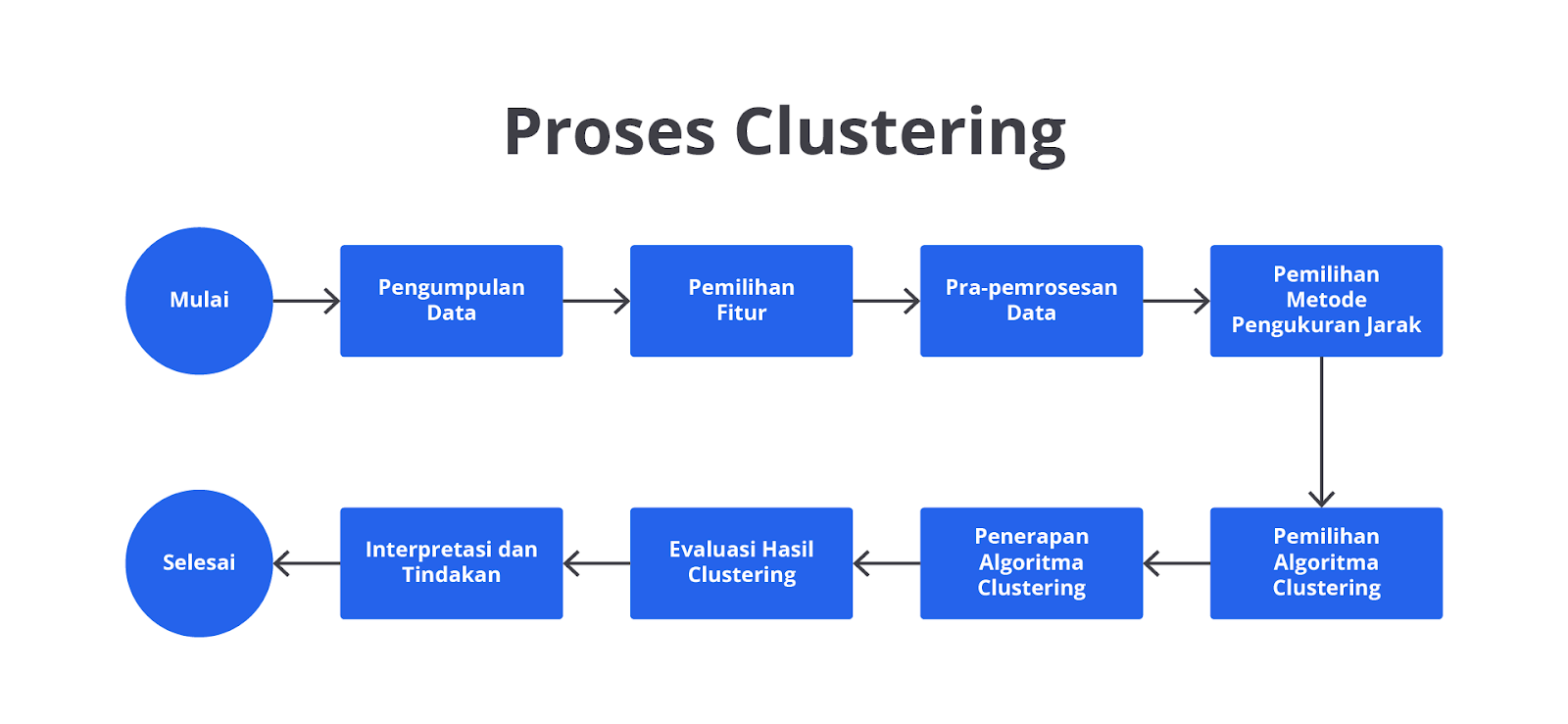
Proses Clustering: Langkah Demi Langkah
Clustering adalah proses yang sangat berguna dalam analisis data untuk mengelompokkan data ke dalam grup-grup berdasarkan kemiripan atau kesamaan fitur. Berikut adalah langkah-langkah dalam proses clustering.
- Pengumpulan Data
- Pemilihan Fitur
- Pra-pemrosesan Data
- Pemilihan Metode Pengukuran Jarak
- Pemilihan Algoritma Clustering
- Penerapan Algoritma Clustering
- Evaluasi Hasil Clustering
- Interpretasi dan Tindakan
Nah, sekarang mari kita bahas setiap tahapan tersebut secara rinci!
Pengumpulan Data
Pengumpulan data adalah langkah pertama dalam proses clustering melibatkan pengumpulan semua data relevan yang akan dianalisis. Data ini bisa berupa berbagai jenis informasi, seperti data numerik, kategorikal, atau teks, tergantung pada tujuan analisis clustering.
Misalnya, jika tujuan Anda adalah menganalisis segmen pelanggan, data dari database pelanggan akan dikumpulkan, seperti usia, pendapatan, dan riwayat pembelian. Data yang dikumpulkan harus valid dan cukup untuk memungkinkan identifikasi pola atau struktur secara signifikan dalam proses clustering.
Contoh Data Pelanggan
| ID Pelanggan | Usia | Pendapatan (Juta IDR) | Riwayat Pembelian |
|---|---|---|---|
1 | 25 | 5.0 | Elektronik |
2 | 30 | 8.0 | Pakaian |
3 | 22 | 4.5 | Elektronik |
4 | 35 | 0.0 | Pakaian |
5 | 29 | 6.0 | Elektronik |
Pemilihan Fitur
Setelah data dikumpulkan, langkah berikutnya adalah pemilihan fitur, yaitu atribut yang akan digunakan untuk mengelompokkan data. Fitur harus dipilih berdasarkan relevansinya dengan tujuan analisis dan kemampuannya dalam membedakan antar kelompok.
Misalnya, dalam analisis pelanggan, fitur yang relevan adalah usia dan pendapatan. Pemilihan fitur yang tepat sangat penting karena fitur tidak relevan atau berlebihan dapat mengaburkan hasil clustering dan membuat interpretasi menjadi kurang akurat.
Contoh Fitur yang Dipilih untuk Clustering
| ID Pelanggan | Usia | Pendapatan (Juta IDR) |
|---|---|---|
1 | 25 | 5.0 |
2 | 30 | 8.0 |
3 | 22 | 4.5 |
4 | 35 | 0.0 |
5 | 29 | 6.0 |
Pra-pemrosesan Data
Pra-pemrosesan data adalah tahap ketika data yang telah dikumpulkan akan dibersihkan dan dinormalisasi untuk memastikan kualitas serta konsistensinya. Ini mencakup beberapa aktivitas, seperti menangani nilai yang hilang, menghapus duplikasi, dan menormalisasikan skala fitur.
Misalnya, Anda perlu menormalkan data pendapatan dan usia agar berada pada skala yang sama sehingga semua fitur memberikan kontribusi setara dalam proses clustering. Pra-pemrosesan membantu memastikan bahwa data siap digunakan dalam algoritma clustering tanpa adanya gangguan dari masalah kualitas data.
Contoh Data Setelah Pra-pemrosesan
| ID Pelanggan | Usia (Normalisasi) | Pendapatan (Normalisasi) |
|---|---|---|
1 | 0.231 | 0.625 |
2 | 0.615 | 1.000 |
3 | 0.000 | 0.563 |
4 | 1.000 | 0.000 |
5 | 0.538 | 0.750 |
Pemilihan Metode Pengukuran Jarak
Pemilihan metode pengukuran jarak adalah langkah penting untuk Anda menentukan cara mengukur kemiripan atau jarak antara objek dalam data. Metode ini memengaruhi cara data dikelompokkan dan hasil clustering yang diperoleh.
Misalnya, jarak Euclidean sering digunakan untuk data numerik karena mengukur jarak linier antara dua titik dalam ruang fitur. Untuk data teks, cosine similarity lebih sesuai karena mengukur seberapa mirip dua dokumen berdasarkan isi kata-katanya. Pemilihan metode pengukuran jarak secara tepat adalah kunci untuk mendapatkan hasil clustering yang akurat.
Contoh Pengukuran Jarak Euclidean
| ID Pelanggan 1 | ID Pelanggan 2 | Pendapatan (Normalisasi) |
|---|---|---|
1 | 2 | 0.537 |
1 | 3 | 0.239 |
1 | 4 | 0.722 |
1 | 5 | 0.322 |
2 | 3 | 0.429 |
2 | 4 | 0.708 |
2 | 5 | 0.422 |
3 | 4 | 0.671 |
3 | 5 | 0.341 |
4 | 5 | 0.809 |
Berikut adalah contoh rincian untuk beberapa pasangan.
 Lakukan perhitungan serupa untuk pasangan pelanggan lainnya menggunakan data normalisasi yang telah disediakan.
Lakukan perhitungan serupa untuk pasangan pelanggan lainnya menggunakan data normalisasi yang telah disediakan.
Pemilihan Algoritma Clustering
Pemilihan algoritma clustering melibatkan keputusan tentang metode yang akan digunakan untuk mengelompokkan data. Berbagai algoritma clustering, seperti K-Means, DBSCAN, atau hierarchical clustering, memiliki pendekatan yang berbeda dalam mengelompokkan data. Pilihan algoritma bergantung pada jenis data yang Anda miliki dan tujuan analisis.
Misalnya, K-Means dipilih jika Anda sudah mengetahui jumlah cluster yang diinginkan, sedangkan DBSCAN lebih cocok jika ingin mengidentifikasi cluster dengan bentuk yang tidak teratur dan juga menangani noise dalam data.
Penerapan Algoritma Clustering
Setelah algoritma clustering dipilih, langkah berikutnya adalah menerapkannya pada data. Pada tahap ini, algoritma yang telah dipilih diterapkan untuk mengelompokkan data ke dalam cluster berdasarkan fitur yang telah ditentukan.
Misalnya, dengan K-Means, algoritma akan membagi data pelanggan ke dalam jumlah cluster yang telah ditentukan berdasarkan kemiripan fitur, seperti usia dan pendapatan. Penerapan algoritma ini menghasilkan cluster yang mencerminkan kelompok-kelompok data dengan karakteristik serupa.
Contoh Hasil Penerapan K-Means
| ID Pelanggan | Usia | Pendapatan (Juta IDR) | Riwayat Pembelian | Cluster |
|---|---|---|---|---|
1 | 25 | 5.0 | Elektronik | 1 |
2 | 30 | 8.0 | Pakaian | 2 |
3 | 22 | 4.5 | Elektronik | 1 |
4 | 35 | 0.0 | Pakaian | 2 |
5 | 29 | 6.0 | Elektronik | 1 |
Evaluasi Hasil Clustering
Evaluasi hasil clustering adalah proses untuk menilai seberapa baik data telah dikelompokkan setelah algoritma diterapkan. Berbagai metrik digunakan untuk mengevaluasi kualitas cluster, seperti silhouette score yang mengukur seberapa baik setiap objek berada dalam cluster-nya sendiri dibandingkan dengan cluster lainnya atau Davies-Bouldin Index yang mengukur keterpisahan antara cluster. Evaluasi ini membantu memastikan bahwa cluster yang terbentuk adalah valid dan sesuai dengan tujuan analisis.
Contoh Evaluasi dengan Silhouette Score
| ID Pelanggan 1 | Silhouette Score |
|---|---|
1 | 0.68 |
2 | 0.77 |
3 | 0.71 |
4 | 0.72 |
5 | 0.65 |
Interpretasi dan Tindakan
Langkah terakhir adalah interpretasi dan tindakan berdasarkan hasil clustering. Setelah clustering selesai, hasilnya perlu dianalisis untuk memahami pola atau struktur yang muncul dalam data. Berdasarkan temuan ini, langkah-langkah tindak lanjut dapat diambil, seperti pengembangan strategi bisnis, pembuatan laporan, atau penelitian lebih lanjut.
Misalnya, jika clustering mengidentifikasi segmen pelanggan baru, Anda mungkin akan merancang strategi pemasaran yang lebih terarah untuk setiap segmen. Interpretasi yang baik dari hasil clustering memungkinkan Anda untuk membuat keputusan lebih informatif dan strategis berdasarkan analisis data.
Contoh Interpretasi dan Tindakan
Interpretasi Hasil
- Cluster 1: terdiri dari pelanggan dengan usia lebih muda dan pendapatan menengah, lebih suka membeli elektronik.
- Cluster 2: terdiri dari pelanggan dengan usia lebih tua dan pendapatan lebih tinggi, lebih suka membeli pakaian.
Tindakan
- Rancang kampanye pemasaran yang ditargetkan untuk masing-masing cluster, seperti promosi produk elektronik untuk Cluster 1 dan penawaran eksklusif pakaian untuk Cluster 2.
Dengan menerapkan metode clustering yang sesuai dan melakukan evaluasi secara cermat, kita dapat mengidentifikasi pola-pola tersembunyi dan membuat keputusan lebih strategis. Misalnya, dalam konteks pemasaran, hasil clustering dapat digunakan untuk merancang kampanye yang lebih terarah dan efektif berdasarkan karakteristik masing-masing kelompok pelanggan.
Clustering tidak hanya membantu dalam segmentasi pasar serta analisis data, tetapi juga dalam berbagai aplikasi lain, seperti deteksi anomali dan pengelompokan dokumen. Dengan memahami dan menerapkan teknik clustering secara efektif, kita dapat memanfaatkan data dengan lebih baik serta mendukung pengambilan keputusan yang lebih informatif dan berbasis data.
Hierarchical Clustering (HC)
Metode clustering umumnya dibagi menjadi dua kategori utama: hierarchical clustering dan non-hierarchical clustering. Pertama, mari kita bahas hierarchical clustering.
Hierarchical clustering adalah teknik clustering yang digunakan untuk mengelompokkan data dalam bentuk hierarki bertingkat berdasarkan kemiripan atau jarak antar objek. Metode ini membangun struktur yang menggambarkan cara cluster dibentuk atau dipecah secara bertahap. Hierarchical clustering memiliki dua pendekatan utama, yaitu agglomerative (bottom-up) dan divisive (top-down).
Agglomerative hierarchical clustering, atau clustering hierarkis aglomeratif, dimulai dengan pendekatan bottom-up dengan setiap objek dianggap sebagai cluster individu pada tahap awal. Jika ada n objek, ada pula n cluster yang terpisah, masing-masing berisi satu objek.
Proses ini melibatkan penggabungan, yaitu ketika jarak atau kemiripan antara semua pasangan cluster dihitung menggunakan metrik jarak, seperti Euclidean, Manhattan, atau Minkowski. Dua cluster dengan jarak terdekat atau kemiripan tertinggi digabungkan menjadi satu cluster baru.
Penggabungan ini berlanjut pada setiap langkah hingga seluruh objek bergabung menjadi satu cluster besar. Selama proses ini, dendrogram—sebuah diagram pohon—dibuat untuk menunjukkan hubungan hierarkis antar cluster. Pada dendrogram, sumbu vertikal menunjukkan jarak atau kemiripan saat penggabungan, sementara sumbu horizontal menunjukkan cluster yang digabung.
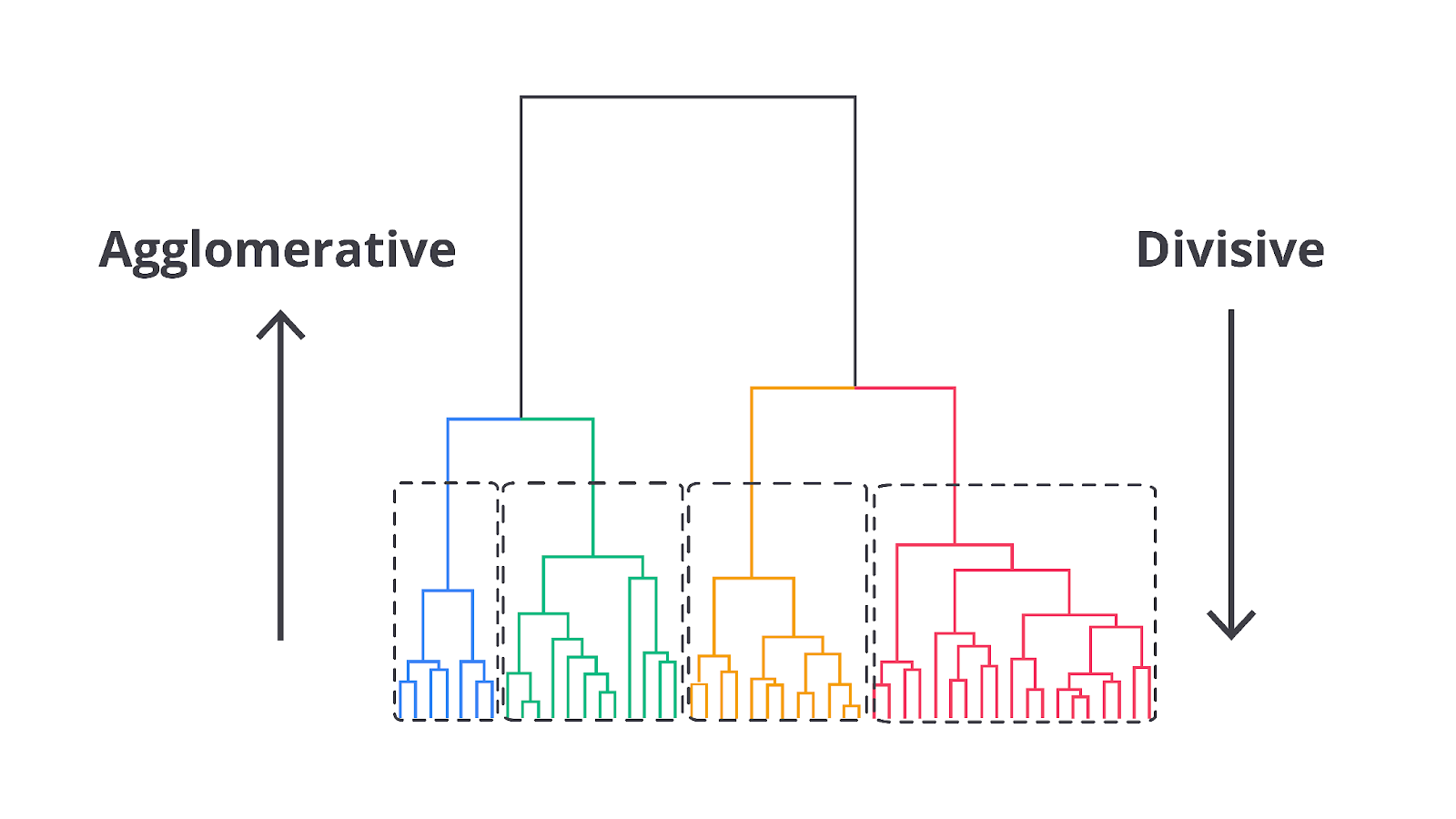
Divisive hierarchical clustering, atau clustering hierarkis divisif, mengikuti pendekatan top-down, dimulai dengan satu cluster besar yang mencakup semua objek dalam dataset. Proses ini melibatkan pembagian cluster besar menjadi dua sub-cluster yang lebih kecil berdasarkan kriteria kemiripan atau jarak.
Pembagian ini dilakukan dengan menggunakan metode yang sama dengan penerapan dalam agglomerative clustering, tetapi dilakukan secara terbalik—dari cluster besar menjadi lebih kecil. Pada setiap langkah, cluster yang ada dibagi menjadi dua bagian lebih kecil hingga akhirnya mencapai keadaan bahwa setiap objek berada dalam cluster terpisah.
Hasil dari proses ini juga digambarkan dalam dendrogram yang menunjukkan proses cluster besar dibagi menjadi sub-cluster yang lebih kecil dari waktu ke waktu. Dendrogram ini memberikan panduan visual tentang proses pembagian dan struktur hierarkis yang terbentuk dalam dataset.
Berikut adalah ilustrasi lain terkait agglomerative dan divisive.
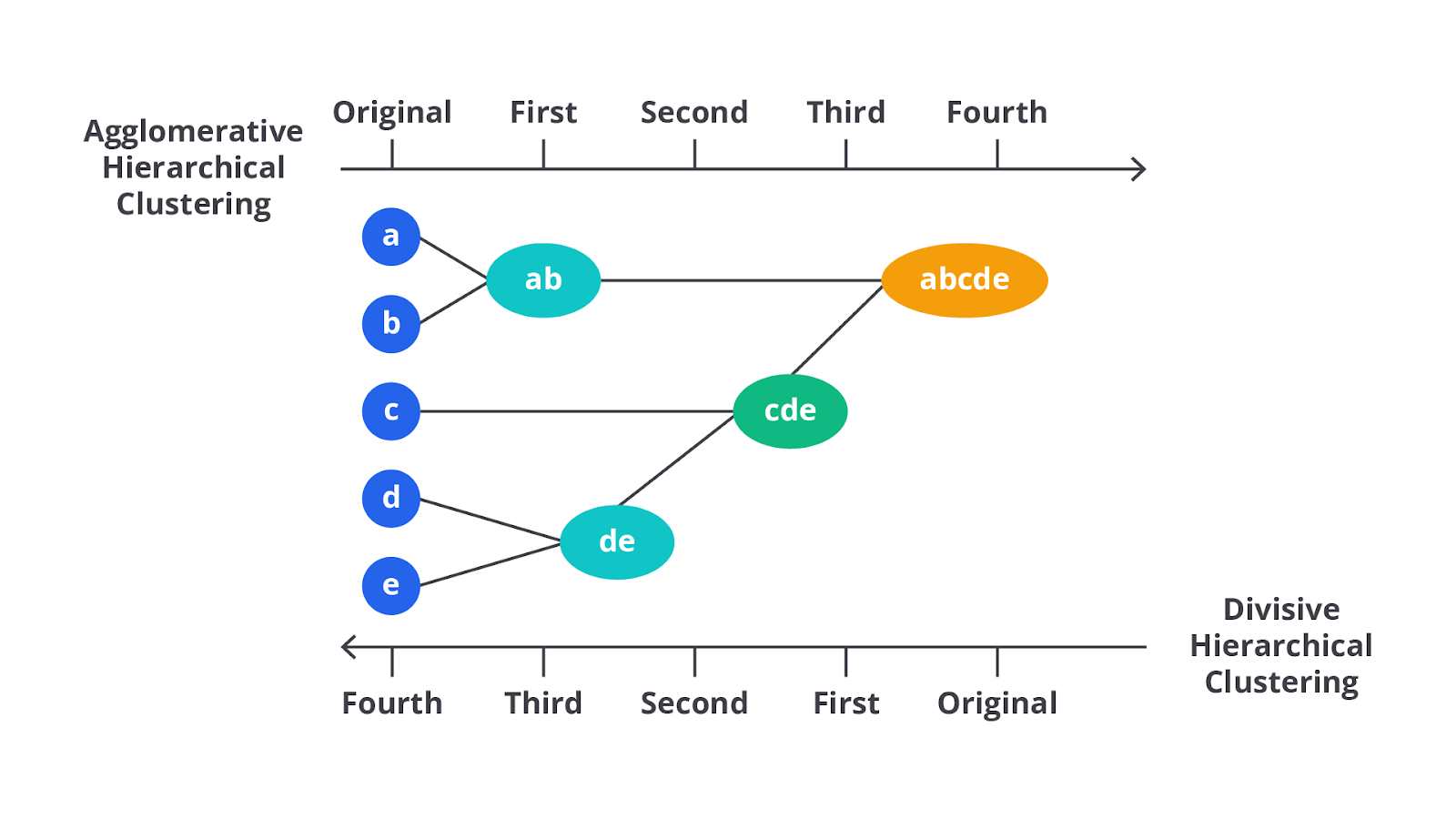
Ilustrasi ini membantu memahami perbedaan antara pendekatan agglomerative dan divisive dalam clustering hierarkis.
- Agglomerative: dimulai dari setiap objek sebagai cluster terpisah (a, b, c, d, e), lalu secara bertahap cluster-cluster ini digabungkan menjadi satu cluster besar (abcde).
- Divisive: dimulai dengan satu cluster besar yang mencakup semua objek (abcde), lalu secara bertahap cluster ini dipecah menjadi cluster-cluster lebih kecil hingga setiap objek berdiri sendiri (a, b, c, d, e).
Metode Linkage dalam Hierarchical Clustering
Dalam hierarchical clustering, metode linkage digunakan untuk menentukan cara jarak antar cluster dihitung saat proses penggabungan atau pembagian cluster. Berikut adalah penjelasan lebih detail tentang masing-masing metode linkage.
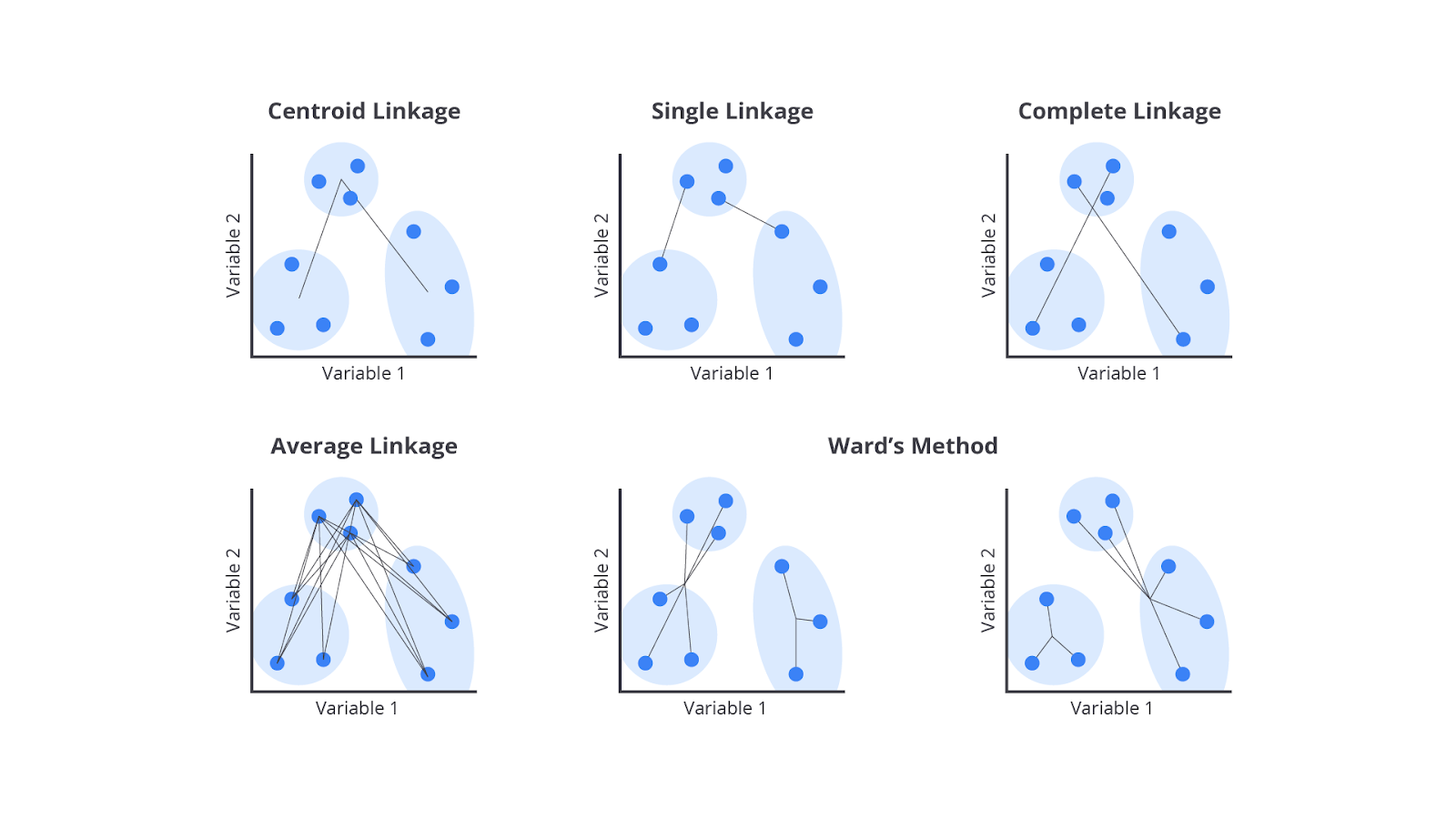
Single Linkage (Nearest Neighbor)
Metode single linkage, juga dikenal sebagai nearest neighbor, menghitung jarak antara dua cluster sebagai jarak terpendek antara anggota dari kedua cluster. Misalnya, jika kita memiliki dua cluster, jarak antara cluster tersebut adalah jarak terpendek antara anggota dari cluster pertama dengan anggota dari cluster kedua.
Metode ini bisa menyebabkan "efek rantai", yaitu ketika dua cluster yang terhubung dengan jarak terpendek mungkin membentuk rantai panjang jika mereka memiliki anggota yang tersebar jauh dari pusatnya. Akibatnya, cluster bisa menjadi tidak teratur dan berantakan, tergantung pada cara objek tersebar dalam ruang fitur.
Complete Linkage (Farthest Neighbor)
Metode complete linkage, atau farthest neighbor, menghitung jarak antara dua cluster sebagai jarak terjauh antara anggota dari kedua cluster. Dengan kata lain, jarak antara dua cluster adalah jarak terjauh antara satu anggota dari cluster pertama dan satu anggota dari cluster kedua.
Metode ini cenderung menghasilkan cluster lebih kompak dan terpisah dengan jelas karena hanya dua objek terjauh dari kedua cluster yang menentukan jarak antar cluster. Ini membantu memastikan bahwa semua anggota cluster berada dalam jarak relatif dekat satu sama lain untuk menghasilkan cluster yang lebih homogen.
Average Linkage
Dalam metode average linkage, jarak antara dua cluster dihitung sebagai rata-rata jarak antara semua pasangan anggota dari kedua cluster. Jadi, kita menghitung jarak antara setiap anggota pada cluster pertama dengan setiap anggota dalam cluster kedua, kemudian mengambil rata-ratanya.
Metode ini memberikan gambaran lebih umum tentang jarak antara cluster dan sering kali menghasilkan cluster yang lebih seimbang dibandingkan dengan metode single linkage atau complete linkage. Average linkage sering kali digunakan untuk menghindari masalah ekstrem yang mungkin muncul dengan metode lain, seperti efek rantai pada single linkage atau kompresi cluster yang sangat padat pada complete linkage.
Centroid Linkage
Metode centroid linkage adalah teknik dalam hierarchical clustering yang menggunakan centroid (pusat) dari cluster untuk menentukan jarak antar cluster. Dalam metode ini, jarak antara dua cluster diukur sebagai jarak antara centroid (rata-rata) dari kedua cluster tersebut. Ketika dua cluster digabungkan, centroid dari cluster gabungan dihitung ulang berdasarkan rata-rata posisi semua anggota dalam cluster gabungan.
Pendekatan ini memastikan bahwa penggabungan cluster didasarkan pada posisi pusatnya dan perubahan centroid menggambarkan perubahan jarak yang terjadi selama proses penggabungan. Karena jarak antar cluster dihitung berdasarkan centroid, metode ini cenderung menghasilkan cluster yang relatif seimbang dan terpisah dengan jelas. Centroid linkage sering digunakan untuk analisis data yang memerlukan pemahaman mendalam tentang posisi relatif dan kesamaan antar cluster.
Ward’s Linkage
Metode ward’s linkage adalah teknik yang mencoba meminimalkan jumlah kuadrat perbedaan di dalam cluster saat menggabungkan dua cluster. Dengan kata lain, metode ini memilih untuk menggabungkan dua cluster yang jika digabungkan akan menghasilkan peningkatan terkecil dalam variasi total pada cluster yang baru terbentuk.
Variasi total ini diukur sebagai jumlah kuadrat deviasi dari setiap anggota cluster terhadap rata-rata cluster tersebut. Ward’s linkage cenderung menghasilkan cluster yang lebih homogen dan lebih kompak karena algoritma secara aktif berusaha meminimalkan variasi di dalam cluster. Teknik ini sangat berguna ketika ingin memastikan bahwa hasil cluster memiliki anggota yang sangat mirip satu sama lain.
Dengan memahami kekuatan dan kelemahan masing-masing metode, Anda dapat memilih teknik yang paling sesuai untuk mengelompokkan data secara efektif, menghasilkan cluster yang relevan dan mudah diinterpretasikan. Penggunaan metode linkage secara tepat memastikan bahwa hasil clustering mencerminkan struktur data yang sebenarnya, memungkinkan analisis lebih mendalam dan keputusan lebih baik dalam berbagai aplikasi praktis.
Metode Pengukuran Jarak dalam Hierarchical Clustering
Dalam hierarchical clustering, metode pengukuran distance antara objek atau cluster sangat penting untuk menentukan cara data dikelompokkan. Beberapa metode distance yang umum digunakan adalah Euclidean Distance, Manhattan Distance, dan Minkowski Distance, masing-masing dengan karakteristik serta rumus matematis yang berbeda.
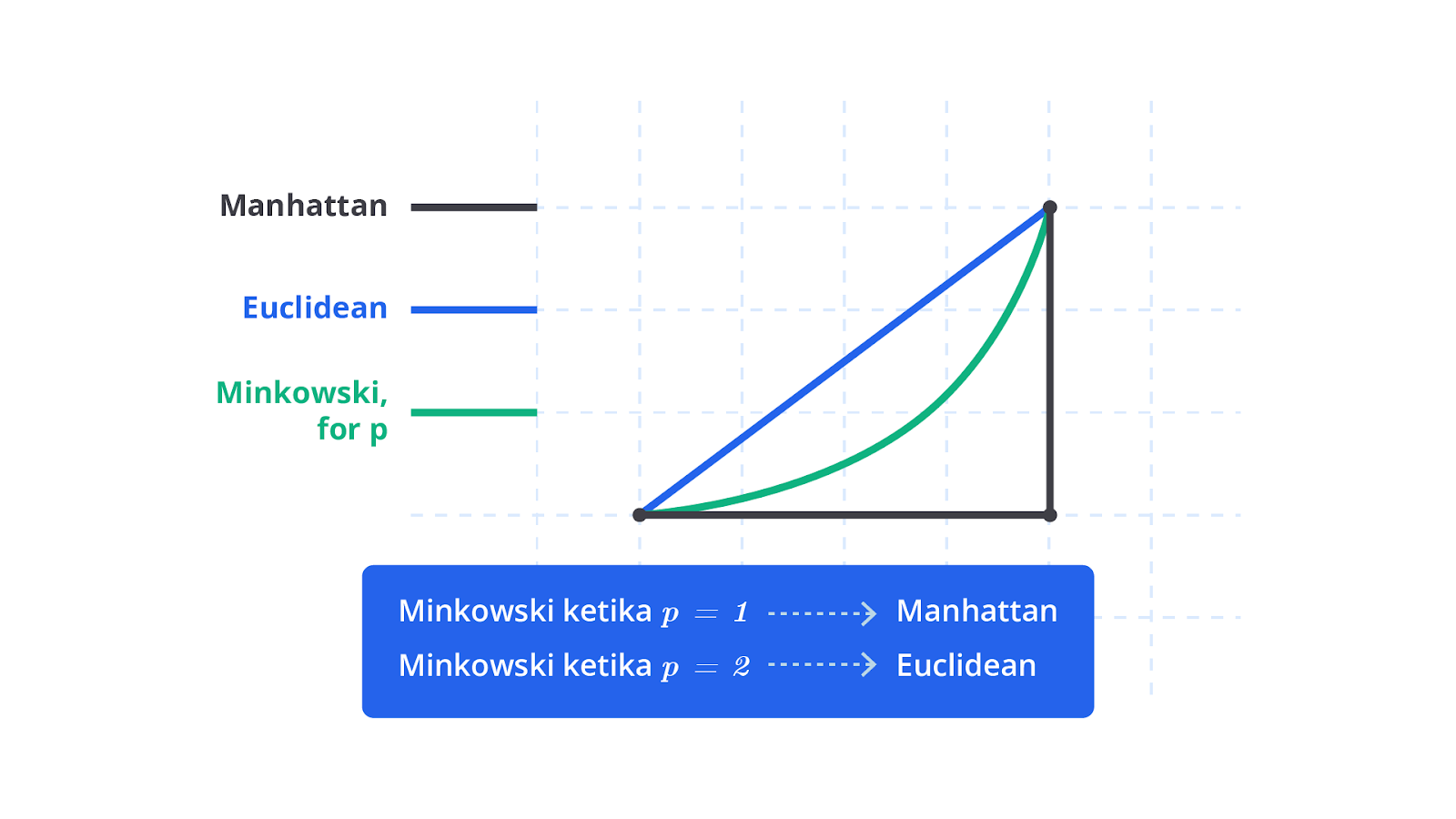
Euclidean Distance
Metode ini adalah yang paling sering digunakan untuk mengukur jarak linier antara dua titik dalam ruang fitur. Distance ini dihitung sebagai akar kuadrat dari jumlah kuadrat perbedaan antara nilai-nilai fitur dari dua titik data.
Rumus untuk Euclidean Distance antara dua titik dalam ruang fitur n-dimensi adalah berikut.

Dalam kata lain, Euclidean Distance dihitung dengan menguadratkan perbedaan antara nilai-nilai fitur dari dua titik, menjumlahkan hasil kuadratnya, dan kemudian mengambil akar kuadrat dari jumlah tersebut. Metode ini memberikan ukuran jarak langsung yang sering kali digunakan dalam banyak aplikasi analisis data dan machine learning.
Manhattan Distance
Metode ini juga dikenal sebagai distance "city block" yang mengukur jarak berdasarkan jumlah perbedaan absolut pada setiap dimensi. Dalam hal ini, jarak dihitung sebagai jumlah dari selisih absolut antara nilai-nilai fitur.
Rumus untuk Manhattan Distance antara dua titik dalam ruang fitur n-dimensi sebagai berikut.
 Manhattan Distance diukur dengan menjumlahkan nilai absolut dari perbedaan antara nilai-nilai fitur pada setiap dimensi. Ini memberikan ukuran jarak yang memperhitungkan perbedaan pada setiap dimensi secara terpisah dan sering digunakan ketika jarak di sepanjang garis grid lebih relevan daripada jarak diagonal.
Manhattan Distance diukur dengan menjumlahkan nilai absolut dari perbedaan antara nilai-nilai fitur pada setiap dimensi. Ini memberikan ukuran jarak yang memperhitungkan perbedaan pada setiap dimensi secara terpisah dan sering digunakan ketika jarak di sepanjang garis grid lebih relevan daripada jarak diagonal.
Minkowski Distance
Perhitungan jarak ini adalah generalisasi dari Euclidean Distance dan Manhattan Distance yang memperkenalkan parameter (p) untuk mengontrol jenis jarak yang dihitung. Rumus untuk Minkowski Distance antara dua titik dalam ruang fitur n-dimensi dengan parameter (p) adalah berikut.

Untuk nilai tertentu dari p, Minkowski Distance menjadi berikut.

Memilih metode pengukuran jarak yang tepat sangat penting karena dapat memengaruhi hasil clustering. Jarak yang diukur harus mencerminkan kemiripan atau perbedaan data dengan akurat untuk mendapatkan hasil clustering yang bermanfaat.
Hierarchical clustering adalah teknik yang efektif untuk mengelompokkan data dan memahami struktur data dengan detail. Kelebihannya dalam memberikan struktur hierarkis yang jelas, visualisasi melalui dendrogram, dan fleksibilitas tanpa memerlukan spesifikasi awal jumlah cluster membuatnya berguna pada berbagai aplikasi.
Namun, kekurangan seperti skalabilitas terbatas, sensitivitas terhadap noise dan outliers, serta tantangan dalam menentukan jumlah cluster yang optimal memerlukan perhatian dan pertimbangan saat menerapkan metode ini. Dengan memahami cara kerja dan karakteristiknya, Anda dapat memanfaatkan hierarchical clustering untuk analisis data lebih baik dan pengambilan keputusan berbasis data yang lebih informatif.
Non-hierarchical Clustering (NHC)
Non-hierarchical clustering (NHC) adalah metode pengelompokan data yang berbeda dari hierarchical clustering karena tidak membentuk struktur hierarkis atau dendrogram. Sebaliknya, NHC berfokus pada pembentukan cluster yang terpisah berdasarkan kriteria tertentu tanpa memperhitungkan hubungan antara cluster dalam bentuk hierarki.
Metode ini sering digunakan ketika jumlah cluster yang diinginkan telah ditentukan sebelumnya atau ketika pendekatan yang lebih sederhana diperlukan. Berikut adalah penjelasan tentang metode non-hierarchical clustering, termasuk berbagai algoritma dan proses yang terlibat.
Metode Non-hierarchical Clustering
Metode non-hierarchical clustering (NHC) adalah teknik pengelompokan data yang tidak membangun struktur hierarkis, tetapi fokus pada pembentukan cluster terpisah berdasarkan kriteria tertentu. Berikut adalah penjelasan rinci tentang beberapa metode NHC yang umum digunakan.
K-Means Clustering
K-Means clustering adalah metode clustering yang membagi data ke dalam k cluster berdasarkan jarak terdekat dari centroid, yaitu titik pusat cluster yang dihitung sebagai rata-rata titik data pada cluster tersebut. Metode ini sangat populer karena kesederhanaannya dan kecepatan dalam proses implementasinya.
Ini cocok untuk studi kasus dengan data besar serta bentuk cluster yang relatif bulat dan terpisah. Misalnya, segmentasi pelanggan dalam pemasaran ketika jumlah segmen diketahui atau diperkirakan.
Cara Kerja Singkat
- Inisialisasi: tentukan jumlah cluster (k) dan inisialisasi centroid secara acak atau menggunakan metode tertentu.
- Penugasan Cluster: assign setiap titik data ke cluster terdekat berdasarkan jarak Euclidean ke centroid.
- Pembaruan Centroid: hitung ulang centroid sebagai rata-rata dari semua titik data dalam cluster.
- Iterasi: ulangi langkah penugasan dan pembaruan centroid hingga posisi centroid stabil atau konvergen.
Kelebihan
- Simplicity: mudah diimplementasikan dan dipahami.
- Efisiensi: cepat dalam komputasi, terutama untuk dataset besar.
Kekurangan
- Pemilihan Jumlah Cluster: memerlukan penentuan jumlah cluster (k) sebelumnya, yang bisa sulit tanpa informasi awal.
- Sensitivitas terhadap Outliers: dapat terpengaruh oleh outliers yang memengaruhi posisi centroid.
K-Medoids Clustering
K-Medoids clustering adalah varian dari K-Means yang menggunakan titik data nyata sebagai pusat cluster (medoids) dan bukan rata-rata. Ini membuatnya lebih robust terhadap noise dan outliers. Cocok untuk data yang mengandung banyak outliers atau noise, seperti clustering dalam data medis atau data sensor saat ketepatan pusat cluster itu penting.
Cara Kerja Singkat
- Inisialisasi: tentukan jumlah cluster (k) dan pilih medoids secara acak dari data.
- Penugasan Cluster: assign setiap titik data ke medoid terdekat.
- Pemilihan Medoid Baru: pilih medoid baru dari titik data dalam cluster untuk meminimalkan total jarak pada cluster.
- Iterasi: ulangi langkah penugasan dan pemilihan medoid hingga tidak ada perubahan signifikan.
Kelebihan
- Robust terhadap Outliers: lebih tahan terhadap outliers karena medoids adalah titik data nyata.
- Kualitas Cluster: menghasilkan cluster dengan pusat yang lebih representatif.
Kekurangan
- Kompleksitas: lebih lambat dibandingkan K-Means karena proses pemilihan medoid yang lebih rumit.
- Pemilihan Jumlah Cluster: masih memerlukan penentuan jumlah cluster (k) sebelumnya.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
DBSCAN adalah metode clustering berbasis kepadatan yang mengelompokkan data berdasarkan kepadatan dan dapat mengidentifikasi cluster dengan bentuk arbitrer tanpa memerlukan jumlah cluster yang ditentukan sebelumnya. Cocok untuk data dengan bentuk cluster tidak teratur atau memiliki noise yang signifikan, seperti pengelompokan titik-titik lokasi geografis atau deteksi anomali.
Cara Kerja Singkat
- Penentuan Parameter: tentukan parameter jarak maksimum (ε) dan jumlah minimum titik (MinPts) untuk membentuk cluster.
- Pengelompokan: identifikasi titik-titik yang cukup dekat satu sama lain untuk membentuk cluster dan tetapkan titik yang tidak memenuhi kriteria sebagai noise.
- Ekspansi Cluster: ekspansi cluster dilakukan dengan menambahkan titik tetangga yang memenuhi kriteria kepadatan.
Kelebihan
- Tidak Memerlukan Jumlah Cluster: tidak perlu menentukan jumlah cluster sebelumnya.
- Menangani Noise: dapat mengidentifikasi noise dan cluster dengan bentuk arbitrer.
Kekurangan
- Pemilihan Parameter: memerlukan pemilihan parameter secara tepat (ε dan MinPts) serta bisa memengaruhi hasil clustering.
- Skalabilitas: dapat menjadi kurang efisien pada dataset yang sangat besar.
Mean Shift Clustering
Mean shift clustering adalah metode berbasis kepadatan dengan mengelompokkan data menggunakan cara mencari titik-titik yang berkumpul di sekitar jendela pencarian tanpa memerlukan jumlah cluster awal. Ini cocok untuk data dengan cluster yang memiliki bentuk kompleks atau tidak teratur, seperti analisis pola dalam citra atau pengelompokan dalam data berbasis spasial.
Cara Kerja Singkat
- Inisialisasi: tentukan jendela pencarian atau kernel.
- Pindah Titik: hitung rata-rata posisi titik di sekitar jendela pencarian untuk setiap titik data dan geser titik ke posisi rata-rata tersebut.
- Konsolidasi: titik yang telah berpindah ke posisi yang sama dan dikelompokkan bersama untuk membentuk cluster.
Kelebihan
- Tidak Memerlukan Jumlah Cluster: tidak memerlukan penentuan jumlah cluster sebelumnya.
- Menangani Bentuk Arbitrer: efektif dalam menemukan cluster dengan bentuk arbitrer.
Kekurangan
- Pemilihan Ukuran Jendela: pemilihan ukuran jendela pencarian yang tepat dapat memengaruhi hasil clustering.
- Kompleksitas: bisa memerlukan waktu komputasi yang lebih lama pada dataset besar.
Dengan memahami berbagai metode non-hierarchical clustering, Anda dapat memilih teknik yang paling sesuai berdasarkan karakteristik data dan tujuan analisis. Setiap metode membawa keunggulan khusus yang dapat dioptimalkan untuk studi kasus tertentu serta memberikan alat berharga dalam eksplorasi dan pemahaman data.
Pada materi berikutnya, kita akan menggali lebih dalam tentang dua metode yang sangat dikenal pada non-hierarchical clustering, yaitu K-Means dan DBSCAN. Keduanya memiliki keunikan dan keunggulan masing-masing yang akan kita bahas lebih mendetail.
Jadi, tetap semangat dan siap untuk eksplorasi yang seru,ya!
K-Means Clustering
K-Means clustering adalah algoritma unsupervised learning untuk mengelompokkan data yang tidak berlabel ke dalam beberapa kelompok atau cluster. Setiap data dalam cluster memiliki karakteristik yang mirip satu sama lain, sedangkan data pada cluster berbeda memiliki karakteristik berbeda pula.
Misalnya, bayangkan Anda seorang pemilik toko mainan yang ingin mengelompokkan mainan di toko berdasarkan ukuran dan harga. Anda memutuskan untuk membuat tiga kelompok: mainan kecil murah, mainan sedang, dan mainan besar mahal.
Pertama, Anda memilih tiga titik awal acak sebagai pusat kelompok (centroid). Kemudian, Anda mengalokasikan setiap mainan ke kelompok dengan centroid terdekat berdasarkan ukuran dan harga. Setelah semua mainan dikelompokkan, Anda menghitung ulang posisi centroid berdasarkan rata-rata ukuran dan harga mainan dalam setiap kelompok serta mengulangi proses ini hingga posisi centroid stabil.
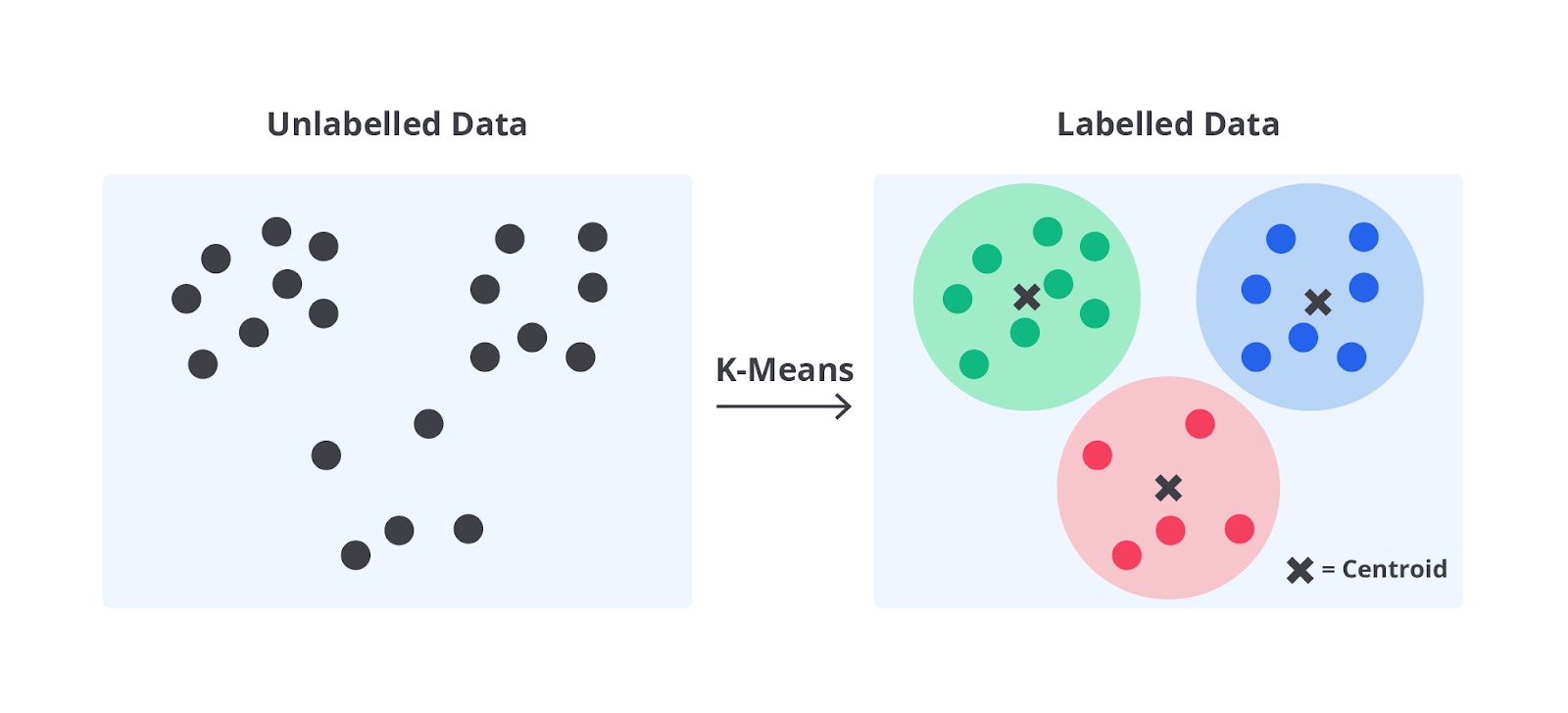
Melalui cara ini, mainan-mainan di toko Anda akan berkelompok secara rapi ke dalam kategori yang relevan, tentunya akan memudahkan untuk menata rak dengan lebih efisien dan merancang strategi pemasaran yang sesuai. K-Means clustering memudahkan kita untuk mengidentifikasi pola dalam data, tetapi perlu diperhatikan bahwa pemilihan jumlah kelompok (K) dan pengaruh dari data ekstrem (outlier) dapat memengaruhi hasil akhir.
Langkah Kerja K-Means Clustering
Berikut adalah contoh lengkap yang mengikuti semua tahapan K-Means clustering dengan dataset mainan fiktif.
| ID | Ukuran (cm) | Harga (IDR) |
|---|---|---|
1 | 10 | 50,000 |
2 | 15 | 75,000 |
3 | 5 | 20,000 |
4 | 12 | 65,000 |
5 | 30 | 150,000 |
6 | 8 | 40,000 |
7 | 20 | 100,000 |
8 | 25 | 120,000 |
9 | 18 | 80,000 |
10 | 7 | 30,000 |
Langkah 1: Menentukan Jumlah Cluster (K)
Pada tahap ini, Anda harus menentukan jumlah kelompok (K) yang ingin Anda buat dari data. Jumlah ini harus dipilih berdasarkan pemahaman tentang data atau dengan menggunakan metode analisis, seperti elbow method atau silhouette score.
Misalnya, jika Anda memiliki data tentang berbagai jenis mainan serta ingin mengelompokkan mereka dalam 3 kategori (misalnya, mainan kecil, menengah, dan besar), K akan diatur menjadi 3. Pilihan jumlah cluster ini akan memengaruhi hasil akhir dari pengelompokan sehingga penting untuk memilih K yang sesuai dengan tujuan analisis.
Langkah 2: Inisialisasi Centroid
Inisialisasi centroid adalah langkah ketika Anda memilih K titik awal dari dataset yang akan menjadi pusat sementara untuk masing-masing cluster. Ada beberapa metode untuk inisialisasi centroid, seperti berikut.
- Random Initialization: memilih K titik acak dari dataset sebagai centroid awal.
- K-Means++ Initialization: metode lebih canggih yang memilih centroid awal dengan cara lebih terdistribusi untuk mengurangi kemungkinan hasil yang buruk. Misalnya, jika K=3, Anda mungkin secara acak memilih tiga mainan dengan ukuran dan harga berbeda sebagai centroid awal.
Contoh:
Kita memilih tiga titik acak sebagai centroid awal. Misalnya berikut.
- Centroid 1: (10 cm, 50,000 IDR)
- Centroid 2: (30 cm, 150,000 IDR)
- Centroid 3: (5 cm, 20,000 IDR)
Langkah 3: Pengalokasian Data
Pada tahap ini, setiap titik data (misalnya, mainan) dihitung jaraknya ke setiap centroid. Biasanya, jarak dihitung menggunakan Euclidean Distance. Titik data kemudian dialokasikan pada centroid yang terdekat. Proses ini mengelompokkan data berdasarkan kemiripan fitur.
Contoh:
Hitung jarak setiap mainan ke setiap centroid menggunakan Euclidean Distance dan alokasikan pada centroid yang terdekat. Berikut adalah perhitungan jarak untuk mainan ID 1 dengan centroid.
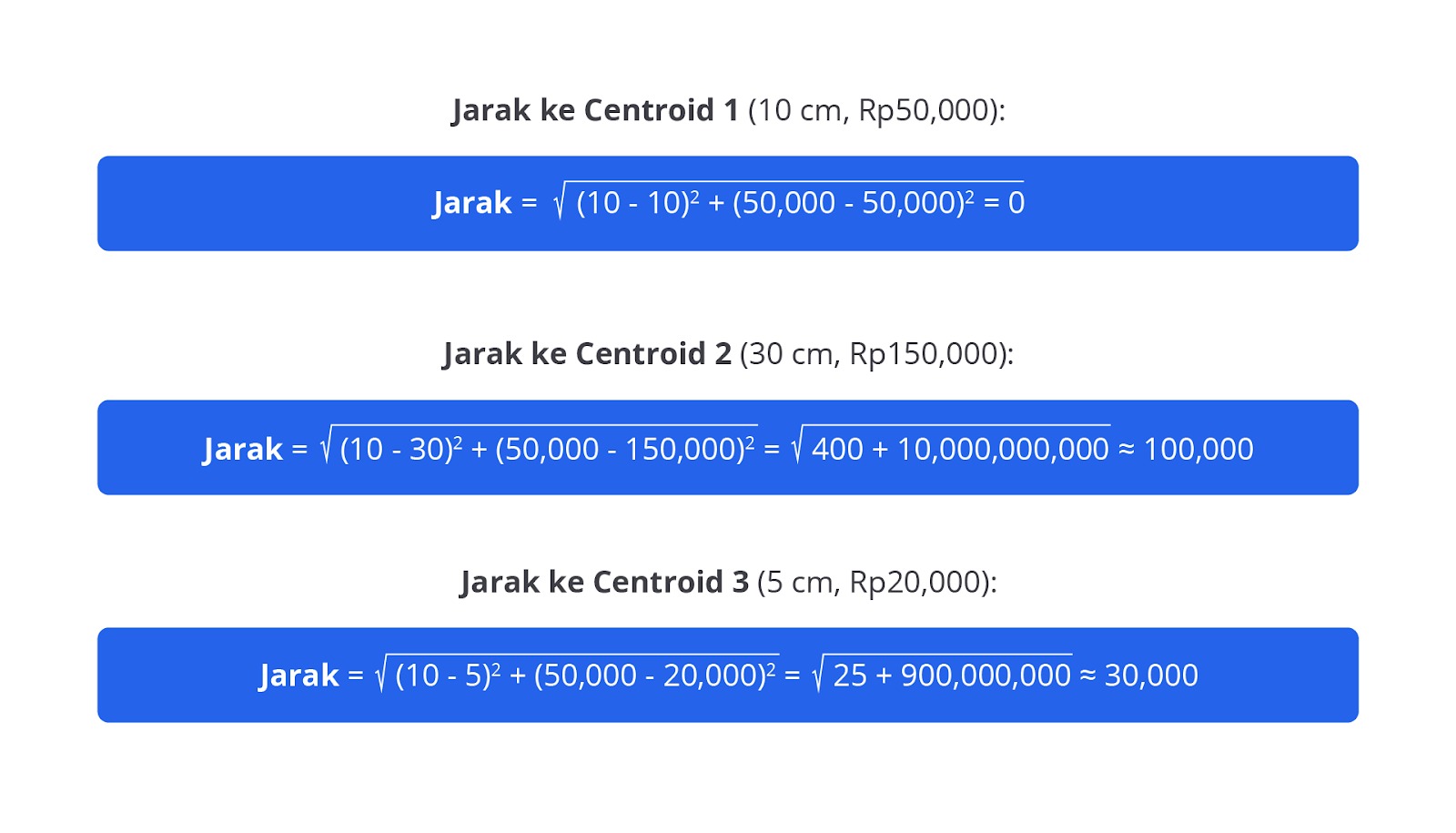 Mainan ID 1 dialokasikan ke Cluster 1 karena jaraknya ke Centroid 1 yang paling dekat.
Mainan ID 1 dialokasikan ke Cluster 1 karena jaraknya ke Centroid 1 yang paling dekat.
Langkah 4: Menghitung Ulang Centroid
Setelah data dialokasikan ke kelompok yang sesuai, centroid baru dihitung. Untuk setiap cluster, centroid baru ditentukan sebagai rata-rata dari semua titik data yang termasuk dalam cluster tersebut.
Misalnya, setelah pengalokasian awal, hasil pengelompokan seperti ini.
- Cluster 1: (10 cm, 50,000 IDR), (15 cm, 75,000 IDR), (12 cm, 65,000 IDR), (8 cm, 40,000 IDR)
- Cluster 2: (30 cm, 150,000 IDR), (25 cm, 120,000 IDR), (20 cm, 100,000 IDR), (18 cm, 80,000 IDR)
- Cluster 3: (5 cm, 20,000 IDR), (7 cm, 30,000 IDR)
Hitung centroid baru.
Cluster 1
Titik data sebagai berikut:
- (10 cm, 50,000 IDR)
- (15 cm, 75,000 IDR)
- (12 cm, 65,000 IDR)
- (8 cm, 40,000 IDR)

Cluster 2
Titik data sebagai berikut:
- (30 cm, 150,000 IDR)
- (25 cm, 120,000 IDR)
- (20 cm, 100,000 IDR)
- (18 cm, 80,000 IDR)

Cluster 3
Titik data sebagai berikut:
- (5 cm, 20,000 IDR)
- (7 cm, 30,000 IDR)

Dengan menghitung centroid baru untuk setiap cluster berdasarkan rata-rata ukuran dan harga dari titik data dalam cluster tersebut, kita dapat memastikan bahwa centroid mencerminkan posisi rata-rata data pada kelompoknya. Proses ini kemudian diulang hingga centroid stabil.
Langkah 5: Iterasi
Proses pengalokasian data dan perhitungan ulang centroid diulang hingga centroid tidak lagi bergerak atau perubahan posisi centroid sangat kecil. Setiap iterasi memperbarui posisi centroid dan memperbaiki pengelompokan.
Algoritma berhenti ketika pergeseran centroid antara iterasi menjadi kurang signifikan atau setelah jumlah iterasi maksimum tercapai. Tujuan dari iterasi ini adalah untuk memastikan bahwa centroid berada pada posisi optimal yang mencerminkan data dalam cluster dengan baik.
Langkah 6: Hasil Akhir
Setelah proses iterasi selesai dan centroid stabil, hasil akhir dari K-Means clustering adalah pengelompokan data ke dalam K cluster yang stabil. Data yang dikelompokkan akan menunjukkan struktur atau pola signifikan berdasarkan penggunaan fitur (misalnya, ukuran dan harga). Hasil ini memungkinkan untuk analisis lebih lanjut, seperti visualisasi data, perencanaan strategi pemasaran, atau pengambilan keputusan berdasarkan kelompok yang terbentuk.
Contoh:
Setelah beberapa iterasi, centroid akhirnya stabil, dan hasil akhir pengelompokan mungkin seperti berikut.
Cluster 1: mainan dengan ukuran dan harga menengah. Cluster 2: mainan dengan ukuran besar dan harga tinggi. Cluster 3: mainan besar dengan ukuran kecil dan harga murah.
| ID | Ukuran (cm) | Harga (IDR) | Kelompok |
|---|---|---|---|
1 | 10 | 50,000 | 1 |
2 | 15 | 75,000 | 1 |
3 | 5 | 20,000 | 3 |
4 | 12 | 65,000 | 1 |
5 | 30 | 150,000 | 2 |
6 | 8 | 40,000 | 1 |
7 | 20 | 100,000 | 2 |
8 | 25 | 120,000 | 2 |
9 | 18 | 80,000 | 2 |
10 | 7 | 30,000 | 3 |
Proses ini memberikan pengelompokan yang jelas berdasarkan ukuran dan harga mainan. Ini membantu dalam penataan serta analisis lebih lanjut. Namun, ketika jumlah data sangat besar, pencarian centroid secara manual tentu akan menjadi sangat sulit dan memakan waktu.
Untuk mengatasi masalah ini, kita bisa menggunakan library K-Means yang memudahkan implementasi algoritma secara otomatis dan efisien, seperti scikit-learn pada Python. Library ini menyediakan fungsi K-Means yang dapat menangani data dalam skala besar dengan cepat dan akurat. Kita akan membahas penggunaan library ini lebih dalam pada materi selanjutnya. Tetap semangat, ya!
Kelebihan dan Kekurangan
Dengan prinsip kerja yang sederhana, K-Means menawarkan kemudahan dalam implementasi dan pemahaman. Ini menjadikannya pilihan yang sering digunakan dalam berbagai aplikasi analisis data. Algoritma ini efisien dan dapat menangani data besar dengan cepat berkat kompleksitas waktu yang relatif rendah.
Namun, meskipun K-Means memiliki banyak kelebihan, seperti kesederhanaan dan efisiensi, ia juga memiliki beberapa kekurangan. Menentukan jumlah cluster yang optimal bisa menantang dan hasil clustering dapat dipengaruhi oleh inisialisasi centroid serta outlier.
Memahami kelebihan dan kekurangan K-Means sangat penting untuk memanfaatkan algoritma ini secara efektif dalam segmentasi data, analisis pasar, serta pengelompokan pelanggan. Berikut penjelasan lengkapnya.
| Kelebihan K-Means | Kekurangan K-Means |
|---|---|
Sederhana dan Mudah Dipahami: K-Means mudah diimplementasikan dan dipahami. | Sensitif terhadap Inisialisasi: Hasil akhir bisa dipengaruhi oleh inisialisasi centroid. K-Means membantu mengurangi masalah ini. |
Efisien: Artinya, ini cocok untuk dataset besar dengan kompleksitas yang juga tinggi. | Terpengaruh oleh Outlier: Outlier dapat memengaruhi posisi centroid secara signifikan yang bisa merusak hasil clustering. |
Scalable: Ini berarti dapat menangani data yang besar dengan relatif cepat. | Kebutuhan untuk Data Numerik: K-Means memerlukan data numerik dan jarak Euclidean sehingga tidak cocok untuk data kategorikal tanpa preprocessing tambahan. |
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
DBSCAN (density-based spatial clustering of applications with noise) adalah algoritma clustering yang mengelompokkan data berdasarkan kepadatan titik-titik di ruang fitur tanpa memerlukan jumlah cluster yang ditentukan sebelumnya.
Algoritma ini menggunakan dua parameter utama: Epsilon (ε) dan MinPts. Epsilon adalah jarak maksimum yang digunakan untuk menentukan bahwa dua titik dianggap saling berdekatan dan berada dalam satu cluster. Misalnya, jika Anda membayangkan sebuah lingkaran di sekitar setiap titik data, ε menentukan jari-jari lingkaran tersebut.
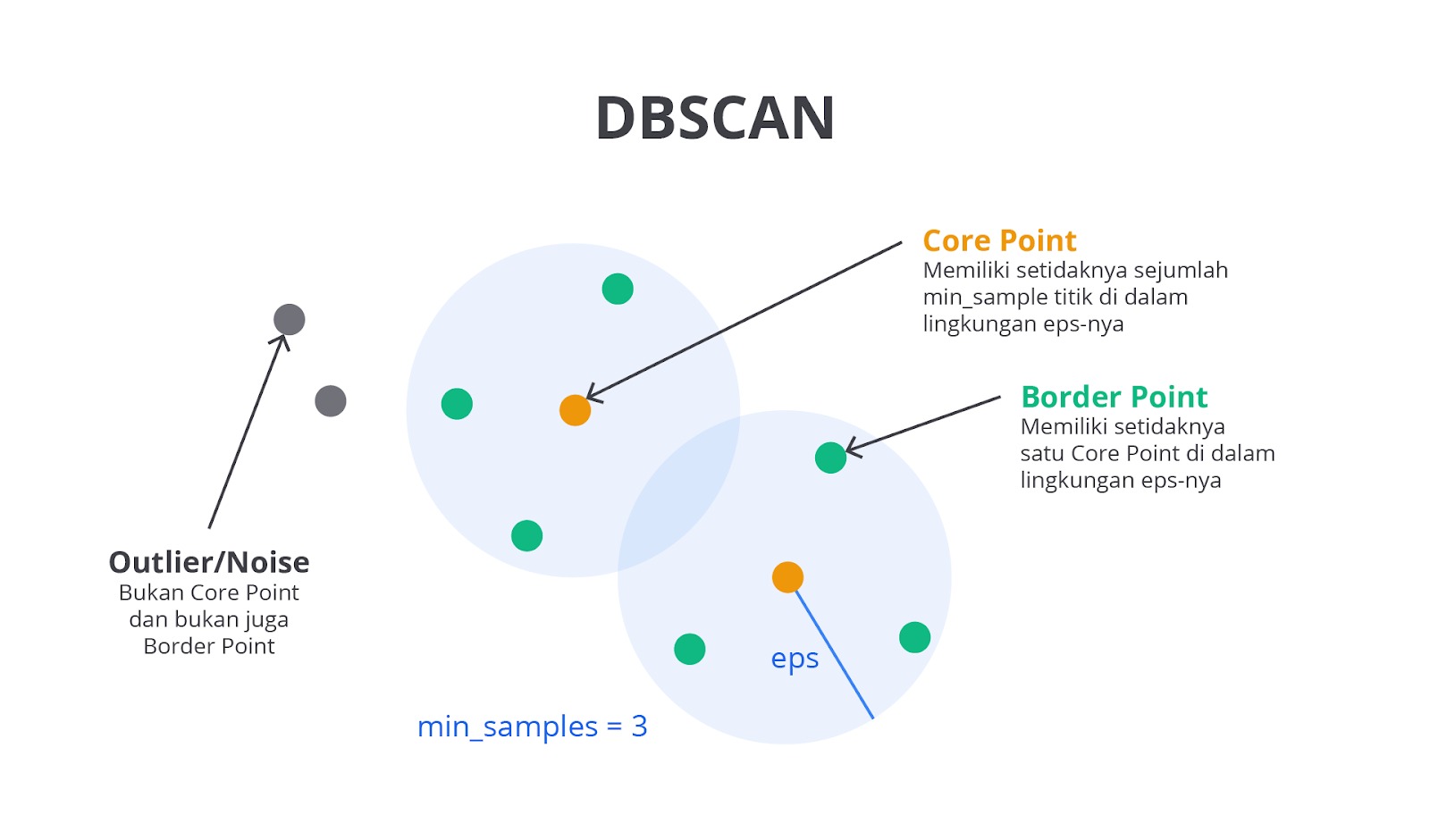
Adapun MinPts adalah jumlah minimum titik yang diperlukan di dalam lingkaran ε untuk membentuk cluster secara valid. Jika jumlah titik dalam lingkaran tersebut memenuhi atau melebihi MinPts, titik tersebut dianggap sebagai pusat cluster. Melalui cara ini, DBSCAN dapat mengidentifikasi cluster dengan bentuk kompleks dan tidak teratur serta mengatasi noise atau titik yang tidak termasuk dalam cluster mana pun.
Sebagai analogi, bayangkan sebuah taman yang penuh dengan kelompok orang. Epsilon adalah radius dari lingkaran imajiner di sekitar seseorang dan MinPts adalah jumlah minimum orang yang harus berada dalam lingkaran tersebut untuk membentuk kelompok. Titik yang tidak berada pada kelompok ini atau tidak memiliki cukup banyak tetangga di dalam radius ε dianggap sebagai noise. DBSCAN sangat berguna pada situasi bahwa cluster tidak berbentuk bulat dan ada banyak outlier dalam data.
Langkah Kerja DBSCAN
Berikut adalah contoh data dan langkah-langkah pada setiap tahapan algoritma DBSCAN dengan data tabular yang sederhana. Misalnya, kita memiliki dataset 2D berikut.
| Titik | X | Y |
|---|---|---|
1 | 2 | 3 |
2 | 3 | 3 |
3 | 4 | 3 |
4 | 2 | 4 |
5 | 3 | 4 |
6 | 8 | 7 |
7 | 9 | 7 |
8 | 8 | 8 |
9 | 9 | 8 |
10 | 10 | 8 |
Langkah 1: Inisialisasi
Mulailah dengan memilih sebuah titik acak dari dataset sebagai titik pusat (core point). Tentukan parameter epsilon (ε) yang akan digunakan sebagai jarak maksimum untuk mengidentifikasi tetangga dan MinPts yang menentukan jumlah minimum titik dalam radius ε untuk membentuk cluster.
Contoh: Kita memiliki dataset dengan titik-titik yang terdistribusi di ruang 2D. Kita memilih titik (3,3) sebagai titik pusat dengan ε = 1 dan MinPts = 3.
Langkah 2: Penentuan Titik-Titik Tetangga
Untuk setiap titik dalam dataset, hitung jarak ke titik-titik lainnya menggunakan parameter ε. Jarak ini biasanya dihitung menggunakan jarak Euclidean. Jika jumlah titik yang berada dalam radius ε dari titik pusat lebih besar atau sama dengan MinPts, titik tersebut dianggap sebagai titik pusat. Titik-titik yang berada dalam radius ε, tetapi jumlahnya kurang dari MinPts tidak dianggap sebagai titik pusat.
Contoh:
Hitung jarak antara titik (3, 3) dan titik-titik lainnya dengan menggunakan jarak Euclidean. Titik-titik yang berada dalam jarak ε = 1 dari (3, 3) adalah berikut.
- Jarak (3, 3) ke (2, 3): 1
- Jarak (3, 3) ke (4, 3): 1
- Jarak (3, 3) ke (3, 4): 1
- Jarak (3, 3) ke (2, 4): 1.414
Titik-titik dalam radius ε = 1 dari (3, 3) adalah (2, 3), (3, 4), dan (4, 3). Total ada 3 titik yang merupakan jumlah minimum (MinPts).
Karena ada 3 titik dalam radius ε dari (2, 3), (2, 3) adalah titik pusat.
Langkah 3: Pembentukan Cluster
Semua titik pada radius ε dari titik pusat akan digabungkan ke dalam cluster yang sama. Titik-titik yang berada dalam jangkauan ε dari titik pusat, tetapi tidak memenuhi syarat MinPts akan dianggap sebagai titik tepi (border point) dan dimasukkan dalam cluster jika mereka terhubung dengan titik pusat.
Contoh:
Gabungkan titik-titik dalam radius ε dari titik pusat (2, 3) ke dalam cluster berikut.
- Titik pusat: (3, 3)
- Anggota cluster: (2, 3), (3, 4), (4, 3)
Dengan demikian, cluster pertama adalah {(2, 3), (3, 3), (3, 4), (4, 3)}.
Langkah 4: Penanganan Noise
Titik-titik yang tidak memenuhi syarat untuk menjadi titik pusat dan tidak memiliki cukup tetangga untuk bergabung dengan cluster mana pun dianggap sebagai noise (outliers). Titik-titik ini tidak dimasukkan ke dalam cluster apa pun.
Contoh:
Cek titik-titik lainnya untuk cluster baru atau noise.
- Titik (9, 7), (8, 8), dan (10, 8) memiliki jarak Euclidean yang sama dengan atau lebih kecil dari ε = 1 dari titik (9, 8).
- Titik (9, 8) memiliki lebih dari MinPts (3) tetangga dalam radius ε = 1.
- Titik (9, 8) adalah titik pusat dan titik-titik lainnya di sekitar (9, 8) membentuk cluster yang sama.
Dengan cluster kedua adalah {(9, 7), (8, 8), (9, 8), (10, 8)}.
Titik-titik yang tidak berada dalam radius ε dari kedua cluster ini, seperti titik (2, 4) dan (8, 7) dan titik-titik lainnya dianggap sebagai noise.
Langkah 5: Iterasi
Proses ini diulang untuk semua titik dalam dataset. Titik-titik yang sudah terkelompok tidak akan diproses lagi. Lalu, algoritma akan melanjutkan ke titik berikutnya yang belum dikelompokkan. Proses berlanjut hingga semua titik dalam dataset dikelompokkan atau dikategorikan sebagai noise.
Contoh:
Proses ini diulang untuk semua titik yang belum dikelompokkan.
- Titik (2, 4) dan (8, 7) dan titik-titik lainnya yang tidak termasuk dalam cluster akan diidentifikasi sebagai noise.
Berikut adalah contoh data setelah clustering menggunakan DBSCAN.
| Titik | X | Y | Cluster |
|---|---|---|---|
1 | 2 | 3 | Cluster 1 |
2 | 3 | 3 | Cluster 1 |
3 | 4 | 3 | Cluster 1 |
4 | 2 | 4 | Noise |
5 | 3 | 4 | Cluster 1 |
6 | 8 | 7 | Noise |
7 | 9 | 7 | Cluster 2 |
8 | 8 | 8 | Cluster 2 |
9 | 9 | 8 | Cluster 2 |
10 | 10 | 8 | Cluster 2 |
Dengan langkah-langkah ini, DBSCAN mengidentifikasi dua cluster dan titik-titik yang dianggap sebagai noise berdasarkan parameter yang ditentukan.
Metode Evaluasi: Elbow Method
Metode elbow adalah teknik evaluasi yang digunakan untuk menentukan jumlah cluster optimal dalam analisis clustering, khususnya pada algoritma K-Means. Mari kita jelaskan metode ini secara mendetail dan memberikan analogi untuk memudahkan pemahaman.
Definisi dan Prinsip Dasar
Metode elbow adalah teknik untuk menentukan jumlah cluster (k) yang ideal dengan cara menganalisis hubungan antara jumlah cluster dan total kesalahan kuadrat dalam cluster (sum of squared errors atau SSE). SSE mengukur seberapa baik titik data dalam cluster mendekati centroid cluster mereka. Semakin kecil nilai SSE, semakin baik titik data dikelompokkan ke dalam cluster mereka.
Bayangkan Anda sedang mengatur sebuah pesta dan ingin membagi tamu dengan jumlah 20 orang ke dalam beberapa meja makan. Anda harus menentukan berapa banyak meja yang akan digunakan. Jika Anda hanya memiliki satu meja, tamu akan duduk terlalu berdesakan, dan suasananya menjadi tidak nyaman. Jika Anda menggunakan dua meja, mungkin tamu masih terasa agak berdesakan, tetapi lebih baik daripada hanya satu meja. Saat Anda menambah meja lebih banyak, tamu semakin merasa nyaman dan tidak berdesakan.
Namun, pada titik tertentu, menambah meja lebih banyak tidak memberikan banyak tambahan kenyamanan. Misalnya, jika Anda sudah memiliki empat meja, menambah meja kelima hanya akan sedikit mengurangi kerumunan dan tidak memberikan banyak manfaat tambahan dibandingkan dengan meja keempat.
Dalam konteks metode elbow, SSE berfungsi sebagai ukuran kerumunan tamu. Jumlah meja (cluster) yang Anda pilih seharusnya mengurangi kerumunan (SSE) sampai titik bahwa menambah meja lebih banyak hanya memberikan sedikit peningkatan kenyamanan tambahan. Titik letak peningkatan kenyamanan mulai melambat adalah "elbow" atau titik optimal untuk jumlah meja, yakni jumlah cluster ideal dalam analisis clustering.
Metode elbow sangat berguna ketika Anda perlu menentukan jumlah cluster yang optimal untuk algoritma seperti K-Means. Dengan menggunakan metode elbow, Anda dapat memastikan bahwa pemilihan jumlah cluster memberikan representasi terbaik dari struktur data tanpa membuat terlalu banyak cluster yang bisa menyebabkan overfitting.
Langkah-Langkah Metode Elbow
Langkah-langkah metode elbow adalah proses sistematis yang dirancang untuk menentukan jumlah cluster secara optimal dalam analisis clustering, khususnya menggunakan algoritma K-Means. Dengan memahami serta menerapkan langkah-langkah ini, Anda dapat memilih jumlah cluster yang memberikan keseimbangan terbaik antara kompleksitas model dan kualitas pengelompokan. Ini membantu mengungkap struktur data dengan cara yang lebih informatif dan akurat.
Berikut langkah-langkahnya.
- Tentukan Rentang
k
Pilih rentang nilaikyang akan diuji, misalnya dari 1 hingga 10. Rentang ini mencakup berbagai kemungkinan jumlah cluster yang dapat diuji.
- Jalankan K-Means untuk Setiap
k
Untuk setiap nilai k dalam rentang yang telah ditentukan, jalankan algoritma K-Means clustering pada dataset Anda. K-Means akan membagi data ke dalam k cluster dan menghitung SSE untuk setiap nilaik. SSE dihitung dengan menjumlahkan kuadrat jarak antara setiap titik data dan centroid cluster mereka.
- Plot Grafik SSE vs.
k
Plotkan nilai k pada sumbu x dan SSE pada sumbu y. Grafik ini biasanya menunjukkan penurunan SSE seiring dengan bertambahnya jumlah cluster. Hal ini terjadi karena lebih banyak cluster memungkinkan titik data lebih dekat ke centroid mereka sehingga mengurangi SSE.
- Identifikasi Titik Elbow
Perhatikan grafik yang dihasilkan dan cari titik letak penurunan SSE mulai melambat secara signifikan. Titik ini terlihat seperti siku pada grafik yang disebut sebagai "elbow". Titik elbow ini menunjukkan jumlah cluster optimal karena menambahkan lebih banyak cluster setelah titik ini memberikan penurunan SSE yang tidak signifikan.
Berikut adalah contoh kode Python untuk menerapkan metode elbow dalam menentukan jumlah cluster optimal menggunakan algoritma K-Means dengan pustakascikit-learndanmatplotlibuntuk visualisasi. Contoh ini menggunakan datasetirisdari pustakasklearnsebagai data contoh.Hasilnya berikut.- from sklearn.cluster import KMeans
- from yellowbrick.cluster import KElbowVisualizer # Mengimpor KElbowVisualizer untuk visualisasi metode Elbow
- from sklearn.datasets import make_blobs
- # Membuat dataset buatan
- X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
- kmeans = KMeans()
- visualizer = KElbowVisualizer(kmeans, k=(1, 10))
- visualizer.fit(X)
- visualizer.show()
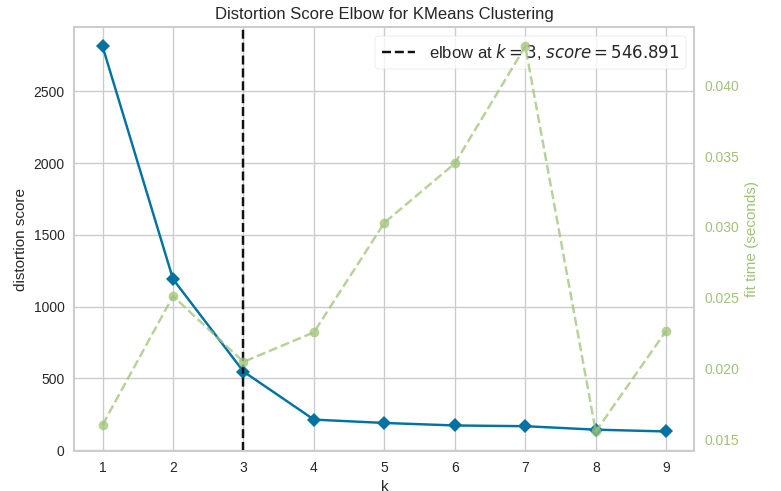
Titik elbow menunjukkan bahwa jumlah cluster yang paling optimal untuk data ini adalah 3. Ini adalah titik letak penurunan SSE mulai melambat secara signifikan. Ini menunjukkan bahwa menambah jumlah cluster lebih lanjut tidak memberikan peningkatan signifikan dalam pengurangan SSE.
Nilai SSE pada jumlah cluster 3 adalah 546.891. Ini adalah ukuran seberapa baik cluster yang dihasilkan sesuai dengan data; semakin rendah nilai SSE, semakin baik data berkelompok.
Evaluasi Model Clustering
Evaluasi model clustering adalah tahap krusial dalam analisis data, ibarat mengevaluasi hasil karya seni untuk memastikan bahwa setiap elemen menyatu dengan harmonis dan sesuai dengan visi awal. Sama seperti seorang kritikus seni yang menilai jika sebuah lukisan mencerminkan komposisi, teknik, serta pesan yang diinginkan, evaluasi model clustering bertujuan menentukan seberapa baik model telah mengelompokkan data menjadi cluster yang bermakna dan sesuai dengan tujuan analisis.
Proses evaluasi ini menggunakan berbagai metrik untuk mengukur kualitas dan efektivitas clustering yang dihasilkan, seperti mengukur sejauh mana cluster yang terbentuk terpisah dengan jelas dan seberapa baik data dalam satu cluster saling berdekatan.
Setiap metrik memberikan perspektif unik tentang cara model clustering bekerja. Ini memungkinkan penilaian yang mendalam dan perbaikan yang diperlukan. Berikut adalah beberapa metode evaluasi utama yang digunakan untuk menilai hasil clustering.
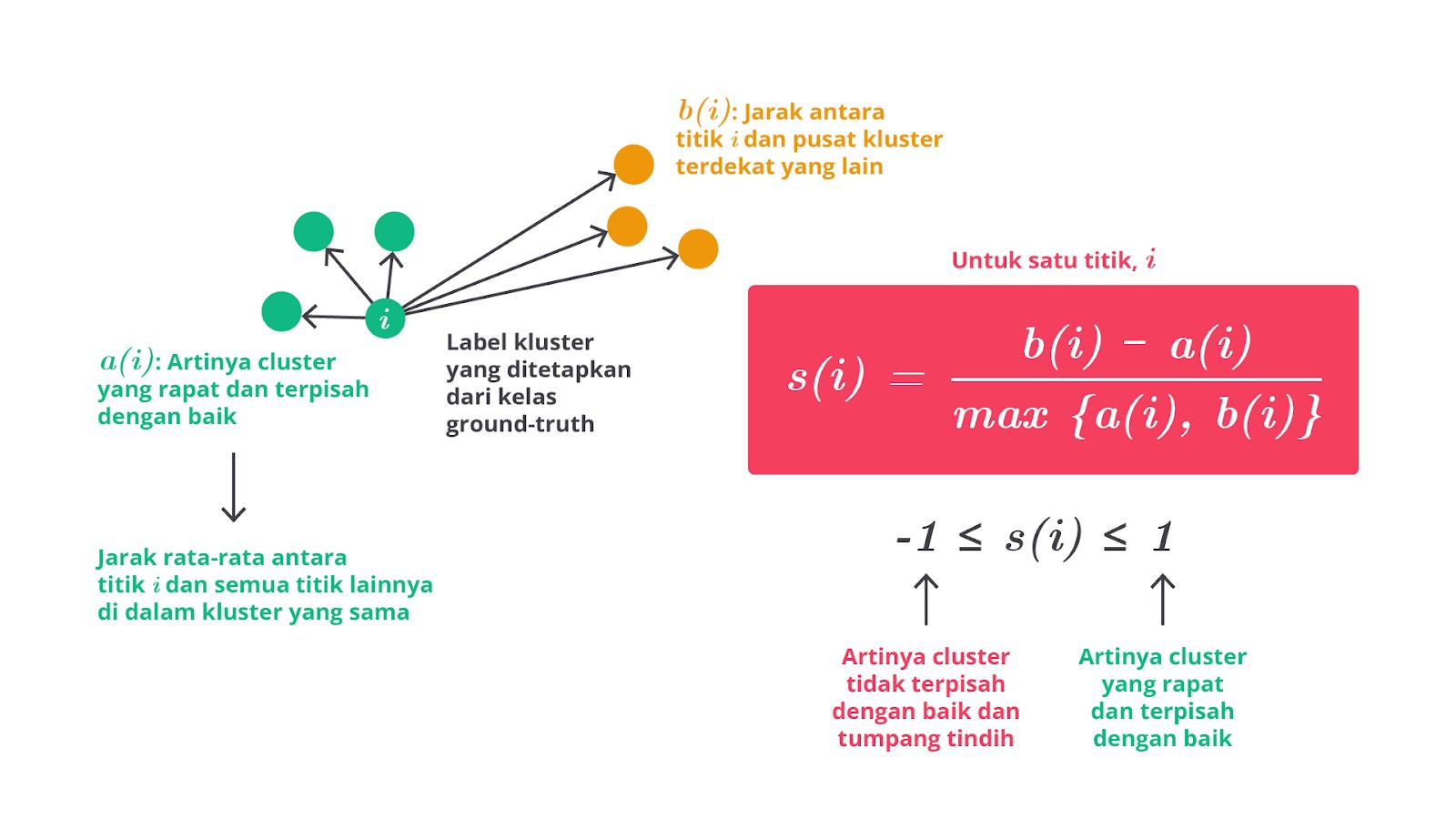
Silhouette Score
Silhouette score adalah metrik yang mengukur seberapa baik setiap data point diklasifikasikan dalam cluster-nya sendiri dibandingkan dengan cluster lain. Nilai ini memberikan informasi tentang kualitas clustering dengan memperhitungkan kepadatan dan jarak antar cluster.
Interpretasi Nilai Silhouette
Nilai berkisar antara -1 dan 1 dengan penjelasan lengkap sebagai berikut.
- Nilai 1: Menunjukkan bahwa data point sangat sesuai dengan cluster-nya sendiri dan terpisah dengan baik dari cluster lain. Ini adalah indikasi clustering yang sangat baik.
- Nilai 0: Menunjukkan bahwa data point berada pada perbatasan antara dua cluster. Ini bisa menunjukkan bahwa data point tersebut tidak sepenuhnya cocok dengan cluster mana pun.
- Nilai -1: Menunjukkan bahwa data point lebih cocok berada pada cluster lain dibanding cluster-nya sendiri. Ini menunjukkan bahwa clustering mungkin perlu penyesuaian.
Silhouette score memiliki beberapa kelebihan utama dalam evaluasi clustering. Pertama, metrik ini memberikan indikasi yang jelas mengenai kualitas clustering untuk setiap data point sehingga memudahkan identifikasi data point yang mungkin tidak sesuai dengan cluster-nya. Selain itu, silhouette score juga membantu dalam mengidentifikasi cluster yang mungkin terlalu besar atau terlalu kecil. Ini memungkinkan penyesuaian lebih lanjut untuk meningkatkan hasil clustering.
Namun, ada beberapa kekurangan, terutama ketika data memiliki cluster dengan bentuk yang sangat berbeda. Dalam kasus tersebut, silhouette score tidak mencerminkan kualitas clustering dengan akurat karena jarak antar cluster tidak selalu mencerminkan struktur cluster yang sebenarnya.
Within-Cluster Sum of Squares (WCSS)
WCSS (within-cluster sum of squares) mengukur total jarak kuadrat antara titik data dan centroid-nya dalam cluster. Metrik ini sering digunakan untuk menilai seberapa baik data dikelompokkan dalam cluster.
WCSS dihitung dengan menjumlahkan jarak kuadrat antara setiap titik data dan centroid cluster-nya melalui persamaan matematis sebagai berikut.

Semakin rendah nilai WCSS, semakin baik clustering-nya karena menunjukkan jarak yang lebih kecil antara data point dan centroid cluster-nya serta mengindikasikan kepadatan cluster dengan lebih baik.
Kelebihan WCSS adalah kemudahan perhitungannya dan kemampuannya memberikan indikasi jelas tentang kepadatan cluster. Namun, WCSS tidak mempertimbangkan jarak antara cluster yang berbeda, hanya fokus pada jarak dalam cluster. Ini berarti WCSS tidak menunjukkan seberapa terpisah cluster satu sama lain dan cenderung menurun seiring bertambahnya jumlah cluster.
Oleh karena itu, WCSS harus digunakan bersama metrik lain, seperti metode elbow, untuk menentukan jumlah cluster optimal dengan menganalisis perubahan WCSS seiring bertambahnya jumlah cluster.
[Story] Diskon adalah Kecintaannya Kita Semua
Diana dan Bilqis akhirnya sampai pada tahap yang paling dinantikan dalam perjalanan belajar mereka, yaitu penerapan teori clustering dalam studi kasus nyata. Setelah berhari-hari mempelajari berbagai aspek clustering dari konsep dasar hingga teknik-teknik lanjutan, seperti hierarchical clustering dan DBSCAN, mereka merasa yakin untuk mengaplikasikan pengetahuan mereka dalam proyek yang penuh tantangan ini.
Selama proses belajar, Diana dan Bilqis telah dengan tekun membahas semua aspek teori clustering. Mereka memahami betapa pentingnya teknik ini dalam mengelompokkan data yang tidak dilabeli menjadi segmen-segmen yang dapat memberikan wawasan berharga. Setiap konsep dan teknik yang dipelajari semakin memperdalam pemahaman mereka tentang penerapan clustering untuk menyelesaikan masalah dunia nyata.
Inspirasi untuk menerapkan clustering datang saat mereka melakukan perjalanan beberapa minggu lalu. Dalam perjalanan tersebut, mereka mengunjungi beberapa supermarket dan terkesan dengan beragam diskon yang ditawarkan oleh berbagai toko. Anda masih ingat juga, bukan?
Setiap supermarket tampaknya memiliki strategi diskon berbeda yang secara jelas ditujukan untuk menarik kelompok pelanggan dengan karakteristik berbeda. Diana dan Bilqis menyadari bahwa ada pola-pola tertentu dalam menentukan diskon-diskon tersebut. Ini membuat mereka berpikir bahwa clustering yang telah mereka pelajari bisa diterapkan untuk menganalisis dan memahami pola tersebut.
Suatu hari, saat mereka duduk santai di lobi gedung kampus setelah kelas, Diana tiba-tiba teringat momen beberapa minggu lalu dan dengan semangat berkata, "Cis, ingat enggak waktu kita jalan-jalan ke mal? Aku jadi kepikiran, kenapa, ya, diskon-diskon itu kayaknya dikelompokkan berdasarkan tipe pelanggan yang berbeda-beda? Menurutku ini contoh nyata, deh, tentang bagaimana clustering bisa diterapkan!"
Bilqis yang juga bersemangat menanggapi, "Oh iya, Na! Aku juga mikir gitu. Bayangkan kalau kita bisa aplikasikan clustering untuk menganalisis pola diskon dan kebiasaan belanja pelanggan. Misalnya, supermarket bisa ngelihat berapa sering seseorang belanja dan berapa banyak yang mereka belanjakan. Kemudian, mereka bisa mengelompokkan pelanggan berdasarkan kebiasaan itu dan kemudian ngasih diskon yang sesuai dengan karakter pelanggan mereka. Ini pasti bakal bikin strategi diskon lebih efektif. Jadi gak ngasal aja."
Diana mengangguk dan menambahkan, "Betul banget! Kita bisa ambil data dari berbagai mal dan analisis pola diskon yang diberikan. Misalnya, kita bisa lihat diskon apa yang lebih sering diberikan ke kelompok pelanggan tertentu atau jenis diskon apa yang paling efektif. Pastinya bakal jadi proyek yang seru dan bermanfaat banget, ya! Apakah ini yang disebut sebagai customer segmentation?"

Bilqis dengan semangat setuju, "I think so! Great idea! Kita bisa mulai dengan ngumpulin data tentang pengeluaran dan preferensi pelanggan dari berbagai mal. Setelah itu, kita bisa pakai teknik clustering yang udah kita pelajari untuk menganalisis data tersebut. Dengan hasil analisis ini, kita bisa kasih insight yang berguna buat strategi diskon yang lebih tepat sasaran."
Diana tambah bersemangat, "Jadi, gimana kalau kita jadikan ini sebagai tugas besar kita? Kita bisa bener-bener praktekkin ilmu yang udah kita pelajari dan akan bantu dunia bisnis kita. Seru banget, kan?"
Bilqis tersenyum lebar, "Indeed! Ini bakal jadi tantangan yang menyenangkan dan kesempatan besar untuk kita. Aku enggak sabar buat mulai proyek ini dan lihat hasilnya. Ayo kita buat rencana dan langsung eksekusi!"
Diana dan Bilqis merasa antusias dan siap menghadapi tantangan ini. Mereka yakin bahwa proyek ini tidak hanya akan mengasah keterampilan analitis mereka, tetapi juga memberikan dampak positif bagi banyak pihak.
Dengan rencana yang matang dan tekad kuat, mereka siap untuk memulai proyek ini sebagai tugas besar mereka. Ini bukan hanya kesempatan untuk menerapkan ilmu yang telah mereka pelajari, tetapi juga untuk menghadapi tantangan yang relevan dan bermanfaat dalam dunia nyata.
Ayo, ikuti terus perjalanan seru Diana dan Bilqis saat mereka mengerjakan latihan pengelompokan pelanggan dalam materi berikutnya. Siapkan semangat Anda dan tetap fokus, ya!Jangan lupa sesekali nikmati seruput kopi dan kunyahan coklat biar mood dan fokus Anda semakin baik. Semangat terus dan selamat belajar, ya!
Latihan Studi Kasus Clustering
Halo! Selamat telah menyelesaikan materi clustering hingga tuntas. Jangan lupa untuk memberi apresiasi pada diri sendiri karena sudah mempelajari banyak hal baru. Namun, tentu saja rasanya kurang sempurna jika kita hanya berfokus pada teori saja, bukan? Sekarang, saatnya kita mempraktikkan cara membangun model clustering menggunakan data sekunder.
Tanpa menunggu lama, mari kita bahas setiap stepnya, check it out!
Import Library
Pertama, seperti biasa, kita akan mengimpor semua pustaka atau library yang dibutuhkan pada proyek clustering ini. Library ini digunakan untuk manipulasi data, membangun model, dan melakukan evaluasi akhir. Berikut adalah kode dan penjelasan masing-masing library-nya.
- import pandas as pd # Mengimpor pustaka pandas untuk manipulasi dan analisis data
- import matplotlib.pyplot as plt # Mengimpor pustaka matplotlib untuk visualisasi grafik
- from yellowbrick.cluster import KElbowVisualizer # Mengimpor KElbowVisualizer untuk visualisasi metode Elbow
- from sklearn.cluster import KMeans, DBSCAN # Mengimpor algoritma KMeans dan DBSCAN untuk clustering
- from sklearn.metrics import silhouette_score # Mengimpor silhouette_score untuk mengevaluasi hasil clustering
Dalam proyek clustering, kita akan sering menggunakan library scikit-learn, yang merupakan salah satu library paling populer di dunia machine learning pada Python. Scikit-learn menyediakan berbagai alat untuk analisis data dan machine learning, termasuk algoritma clustering, seperti K-Means, DBSCAN, dan agglomerative clustering. Selain itu, scikit-learn juga menawarkan berbagai fungsi untuk preprocessing data, pemilihan model, evaluasi, serta cross-validation, yang membuatnya sangat berguna untuk berbagai tahapan dalam pipeline machine learning.
Data Loading
Sip! Selanjutnya, kita akan memuat data yang akan digunakan dalam proyek ini. Pada latihan ini, kita akan menggunakan data Mall Customer yang bisa diakses melalui link berikut. Data ini didapatkan dari Kaggle dan bisa kita sebut sebagai data sekunder karena data ini sudah dikumpulkan dan dipublikasikan oleh pihak lain untuk keperluan analisis.
Data Mall Customer ini biasanya digunakan untuk mengeksplorasi perilaku belanja pelanggan berdasarkan berbagai fitur, seperti usia, jenis kelamin, pendapatan tahunan, dan skor pengeluaran. Dengan menggunakan data ini, kita dapat mencoba berbagai teknik clustering untuk mengelompokkan pelanggan ke dalam segmen-segmen yang berbeda berdasarkan karakteristik mereka.
- # Membaca dataset pelanggan mall dari URL dan menampilkan 5 baris pertama
- df = pd.read_csv('https://raw.githubusercontent.com/dicodingacademy/dicoding_dataset/main/ML%20Pemula/Mall_Customers.csv')
- df.head()
Kita mulai dengan membaca dataset pelanggan mal dari URL yang disediakan menggunakan pd.read_csv. Setelah itu, kita menampilkan lima baris pertama dari dataset ini untuk melihat sekilas struktur data yang akan digunakan. Berikut adalah tampilan lima data pertama yang akan digunakan.
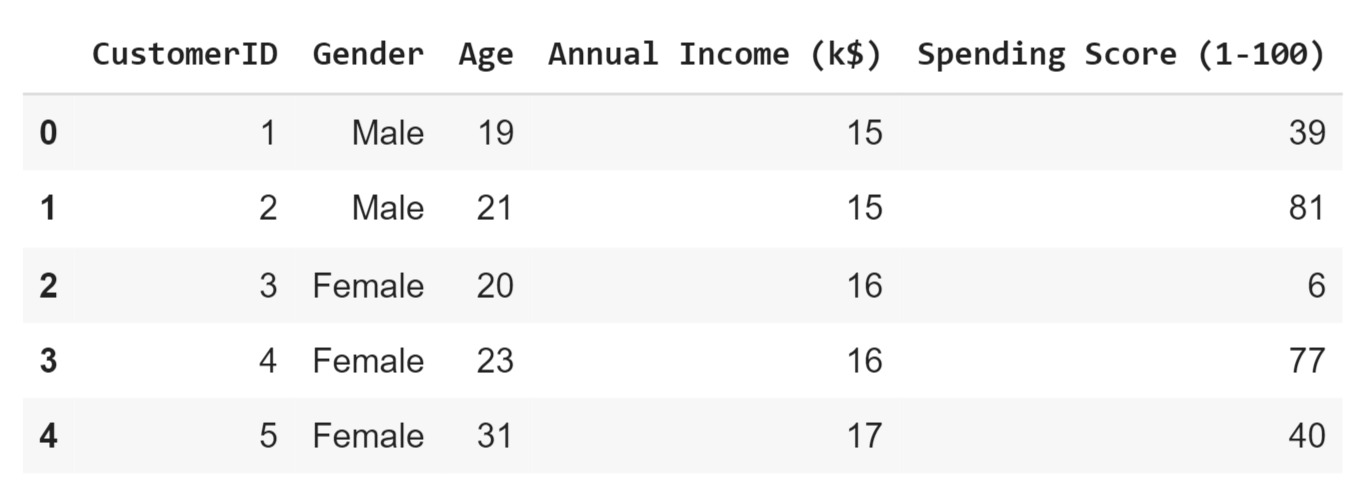
Selanjutnya, kita akan menampilkan informasi umum tentang dataset menggunakan df.info(). Ini akan memberikan gambaran mengenai jumlah baris dan kolom, tipe data setiap kolom, serta jumlah nilai non-null yang ada. Informasi ini penting untuk memahami struktur dataset dan memastikan tidak ada missing values yang perlu ditangani.
- # Menampilkan informasi tentang dataset, termasuk jumlah baris, kolom, tipe data, dan jumlah nilai non-null
- df.info()

Dari hasil output df.info(), kita dapat melihat bahwa dataset ini terdiri atas 200 baris dan 5 kolom. Berikut adalah detail dari setiap kolom.
- CustomerID: Ini berisi ID unik untuk setiap pelanggan, bertipe data int64.
- Gender: Ini menunjukkan jenis kelamin pelanggan, bertipe data object (kategori).
- Age: Ini menampilkan usia pelanggan dalam tahun, bertipe data int64.
- Annual Income (k$): Ini berisi pendapatan tahunan pelanggan dalam ribuan dolar, bertipe data int64.
- Spending Score (1-100): Ini menunjukkan skor pengeluaran pelanggan, mulai dari 1 hingga 100, bertipe data int64.
Semua kolom memiliki nilai non-null, artinya tidak ada missing values yang perlu ditangani. Dataset ini siap untuk dianalisis lebih lanjut.
- # Menampilkan statistik deskriptif dari dataset untuk kolom numerik
- df.describe()
Selanjutnya, kita akan menampilkan statistik deskriptif dari dataset menggunakan df.describe(). Fungsi ini memberikan ringkasan statistik untuk kolom-kolom numerik, seperti jumlah data, nilai rata-rata, standar deviasi, serta nilai minimum dan maksimum. Ini membantu kita memahami distribusi data dan mengidentifikasi outlier atau anomali yang mungkin ada.
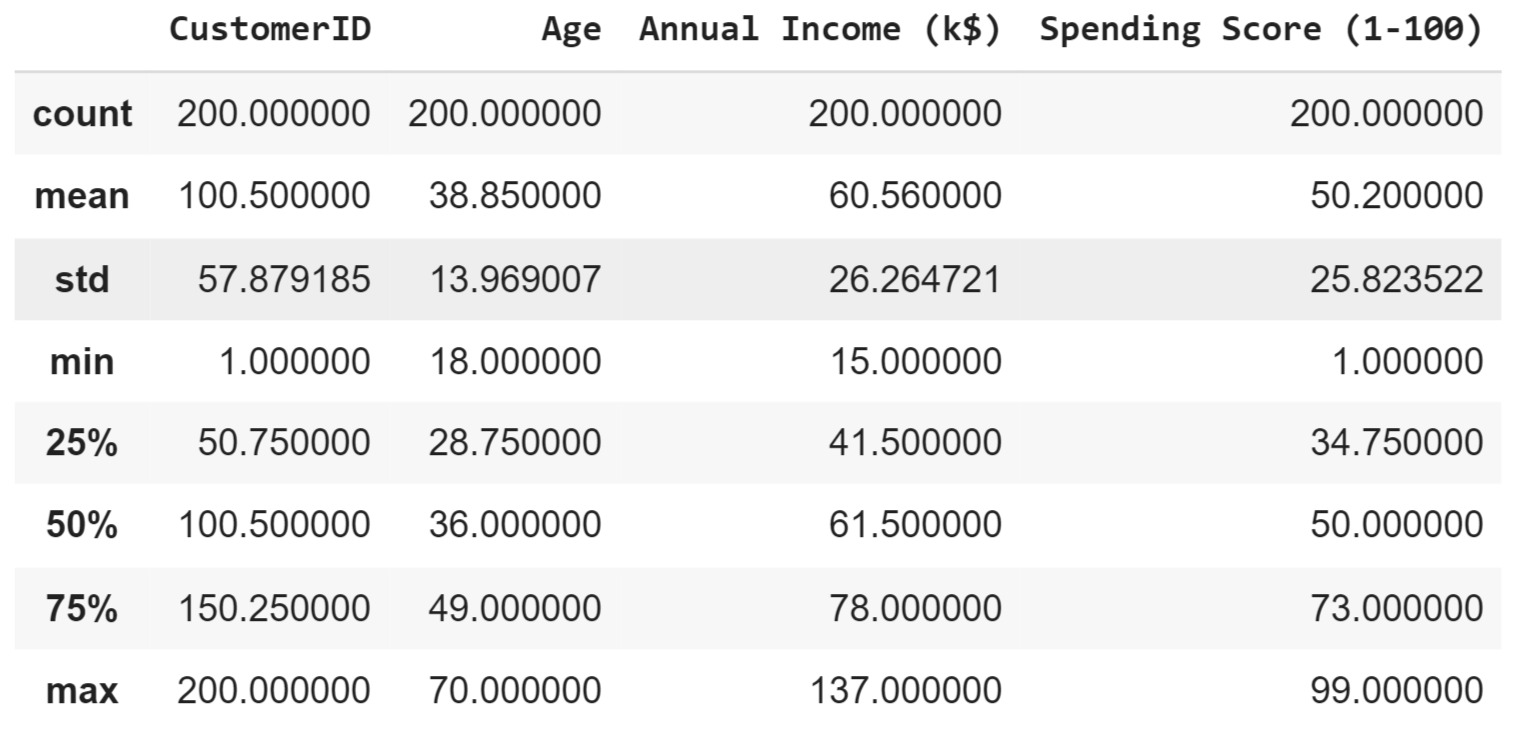
Berdasarkan hasil statistik deskriptif yang ditampilkan oleh df.describe(), kita dapat melihat beberapa informasi penting mengenai kolom-kolom numerik dalam dataset.
- CustomerID
- Ini terdiri dari 200 data unik dengan nilai rata-rata 100.5.
- ID pelanggan bervariasi dari 1 hingga 200.
- Age (Usia)
- Usia pelanggan berkisar antara 18 hingga 70 tahun dengan rata-rata 38.85 tahun.
- Sebagian besar pelanggan berada pada rentang usia 28.75 hingga 49 tahun (kuartil ke-1 hingga ke-3).
- Annual Income (k$) (Pendapatan Tahunan)
- Pendapatan tahunan pelanggan bervariasi antara 15 hingga 137 ribu dolar dengan rata-rata 60.56 ribu dolar.
- Sebagian besar pelanggan memiliki pendapatan tahunan antara 41.5 hingga 78 ribu dolar.
- Spending Score (1–100) (Skor Pengeluaran)
- Skor pengeluaran pelanggan bervariasi dari 1 hingga 99 dengan rata-rata skor pengeluaran sebesar 50.2.
- Sebagian besar pelanggan memiliki skor pengeluaran antara 34.75 hingga 73.
Statistik ini memberikan gambaran awal tentang distribusi dan variasi data pada dataset, yang sangat penting untuk analisis lebih lanjut, terutama dalam mengidentifikasi cluster pelanggan berdasarkan karakteristik, seperti usia, pendapatan, serta perilaku belanja.
Exploratory Data Analysis
Tahap ketiga yang paling penting dalam analisis data adalah exploratory data analysis (EDA). Pada tahap ini, kita melakukan eksplorasi mendalam terhadap dataset untuk memahami pola, hubungan, dan anomali yang ada. EDA memungkinkan kita untuk mendapatkan wawasan awal yang penting untuk analisis lebih lanjut dan mempersiapkan data sebelum membangun model.
Aktivitas utama dalam EDA mencakup visualisasi data melalui grafik dan plot untuk melihat distribusi serta hubungan antar fitur, analisis korelasi dalam mengidentifikasi hubungan antara fitur-fitur numerik, serta deteksi anomali dan outlier yang dapat memengaruhi model.
- # Menghitung distribusi gender dan menampilkan pie chart untuk visualisasi
- plt.figure(figsize=(7, 7))
- plt.pie(df['Gender'].value_counts(), labels=['Female', 'Male'], autopct='%1.1f%%', startangle=90)
- plt.title('Gender Distribution')
- plt.show()
Untuk memvisualisasikan distribusi gender pada dataset, kita menghitung jumlah masing-masing kategori gender menggunakan value_counts() dan menampilkan hasilnya dalam diagram lingkaran (pie chart). Diagram ini, yang dihasilkan dengan plt.pie(), menggambarkan proporsi gender dengan label 'Female' dan 'Male', serta menampilkan persentase setiap kategori. Grafik ini memudahkan kita untuk melihat distribusi gender secara visual serta memahami perbandingan antara jumlah wanita dan pria dalam dataset. Hasilnya berikut.
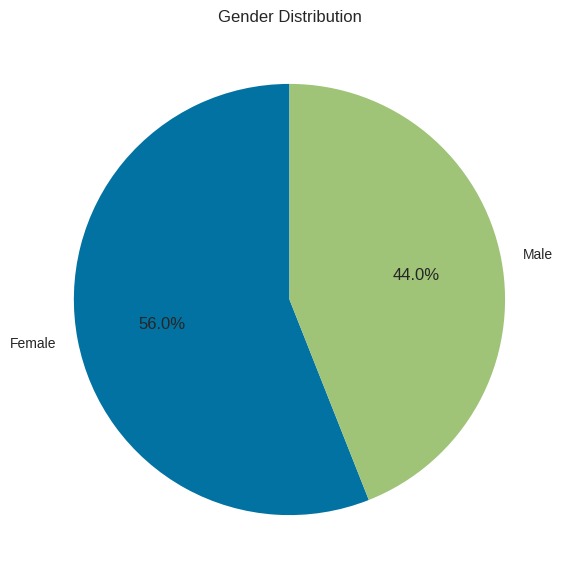
Dari pie chart yang ditampilkan, kita dapat ketahui bahwa persentase perempuan lebih besar dibandingkan laki-laki dengan proporsi sebesar 56% untuk perempuan dan 44% untuk laki-laki.
Untuk menganalisis distribusi usia pelanggan, kita mengelompokkan usia ke dalam beberapa kategori dan menghitung jumlah pelanggan pada setiap kategori. Usia dibagi menjadi lima kategori: 18–25, 26–35, 36–45, 46–55, dan 55 ke atas. Setelah menghitung jumlah pelanggan pada setiap kategori, data tersebut digunakan untuk membuat diagram batang (bar chart) yang menunjukkan distribusi usia pelanggan.
Ya, proses ini disebut sebagai binning. Ini adalah teknik untuk mengelompokkan nilai-nilai numerik ke dalam interval atau kategori yang disebut bins. Dalam kasus ini, usia pelanggan dikelompokkan ke dalam beberapa rentang usia yang telah ditentukan, dan jumlah pelanggan pada setiap rentang dihitung. Hasilnya kemudian divisualisasikan menggunakan bar chart untuk memudahkan analisis distribusi usia. Binning membantu menyederhanakan data dan memudahkan interpretasi pola-pola dalam dataset.
Tenang, binning akan kita pelajari pada materi selanjutnya, kok!
- # Mengelompokkan usia pelanggan ke dalam kategori dan menghitung jumlah pelanggan di setiap kategori
- age18_25 = df.Age[(df.Age >= 18) & (df.Age <= 25)]
- age26_35 = df.Age[(df.Age >= 26) & (df.Age <= 35)]
- age36_45 = df.Age[(df.Age >= 36) & (df.Age <= 45)]
- age46_55 = df.Age[(df.Age >= 46) & (df.Age <= 55)]
- age55above = df.Age[df.Age >= 56]
- # Menyusun data untuk plotting
- x = ["18-25", "26-35", "36-45", "46-55", "55+"]
- y = [len(age18_25.values), len(age26_35.values), len(age36_45.values), len(age46_55.values), len(age55above.values)]
- # Membuat bar chart untuk distribusi usia pelanggan
- plt.figure(figsize=(15, 6))
- plt.bar(x, y, color=['red', 'green', 'blue', 'cyan', 'yellow'])
- plt.title("Customer and Their Ages")
- plt.xlabel("Age")
- plt.ylabel("Number of Customers")
- # Menambahkan label jumlah pelanggan di atas setiap bar
- for i in range(len(x)):
- plt.text(i, y[i], y[i], ha='center', va='bottom')
- plt.show()
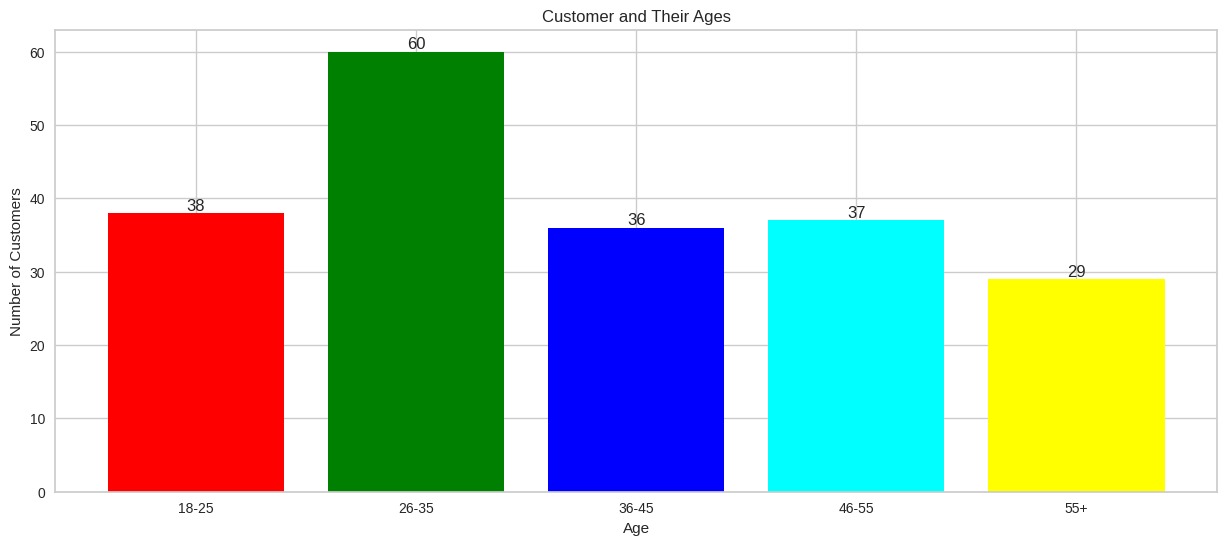
Berikut adalah visualisasi distribusi usia pelanggan berdasarkan kategori yang telah ditentukan.
- 18–25 tahun: ada 38 pelanggan dalam rentang usia ini.
- 26–35 tahun: kategori ini memiliki jumlah pelanggan terbanyak, yaitu 60.
- 36–45 tahun: ada 36 pelanggan dalam rentang usia ini.
- 46–55 tahun: ada 37 pelanggan yang termasuk dalam kategori ini.
- 55 tahun ke atas: rentang usia ini memiliki 29 pelanggan.
Visualisasi ini menunjukkan bahwa kelompok usia 26–35 tahun adalah yang terbesar di antara pelanggan, sementara kelompok usia 55 tahun ke atas memiliki jumlah pelanggan paling sedikit. Distribusi usia ini memberikan wawasan penting tentang demografi pelanggan serta dapat membantu dalam perencanaan strategi pemasaran dan layanan.
Untuk menganalisis distribusi pendapatan tahunan pelanggan, kita mengelompokkan pendapatan ke dalam beberapa kategori dan menghitung jumlah pelanggan pada setiap kategori. Pendapatan tahunan dikelompokkan ke dalam lima rentang.
- $0–30,000
- $30,001–60,000
- $60,001–90,000
- $90,001–120,000
- $120,001–150,000
Setelah menghitung jumlah pelanggan dalam setiap kategori, data tersebut divisualisasikan melalui bar chart. Grafik ini memperlihatkan jumlah pelanggan dalam setiap rentang pendapatan dengan warna berbeda untuk masing-masing kategori.
- # Mengelompokkan pendapatan tahunan pelanggan ke dalam kategori dan menghitung jumlah pelanggan di setiap kategori
- ai0_30 = df["Annual Income (k$)"][(df["Annual Income (k$)"] >= 0) & (df["Annual Income (k$)"] <= 30)]
- ai31_60 = df["Annual Income (k$)"][(df["Annual Income (k$)"] >= 31) & (df["Annual Income (k$)"] <= 60)]
- ai61_90 = df["Annual Income (k$)"][(df["Annual Income (k$)"] >= 61) & (df["Annual Income (k$)"] <= 90)]
- ai91_120 = df["Annual Income (k$)"][(df["Annual Income (k$)"] >= 91) & (df["Annual Income (k$)"] <= 120)]
- ai121_150 = df["Annual Income (k$)"][(df["Annual Income (k$)"] >= 121) & (df["Annual Income (k$)"] <= 150)]
- # Menyusun data untuk plotting
- aix = ["$ 0 - 30,000", "$ 30,001 - 60,000", "$ 60,001 - 90,000", "$ 90,001 - 120,000", "$ 120,001 - 150,000"]
- aiy = [len(ai0_30.values), len(ai31_60.values), len(ai61_90.values), len(ai91_120.values), len(ai121_150.values)]
- # Membuat bar chart untuk distribusi pendapatan tahunan pelanggan
- plt.figure(figsize=(15, 6))
- plt.bar(aix, aiy, color=['red', 'green', 'blue', 'cyan', 'yellow'])
- plt.title("Customer and Their Annual Income")
- plt.xlabel("Annual Income")
- plt.ylabel("Number of Customers")
- plt.xticks(rotation=45) # Memutar label sumbu x agar lebih mudah dibaca
- # Menambahkan label jumlah pelanggan di atas setiap bar
- for i in range(len(aix)):
- plt.text(i, aiy[i], aiy[i], ha='center', va='bottom')
- plt.show()
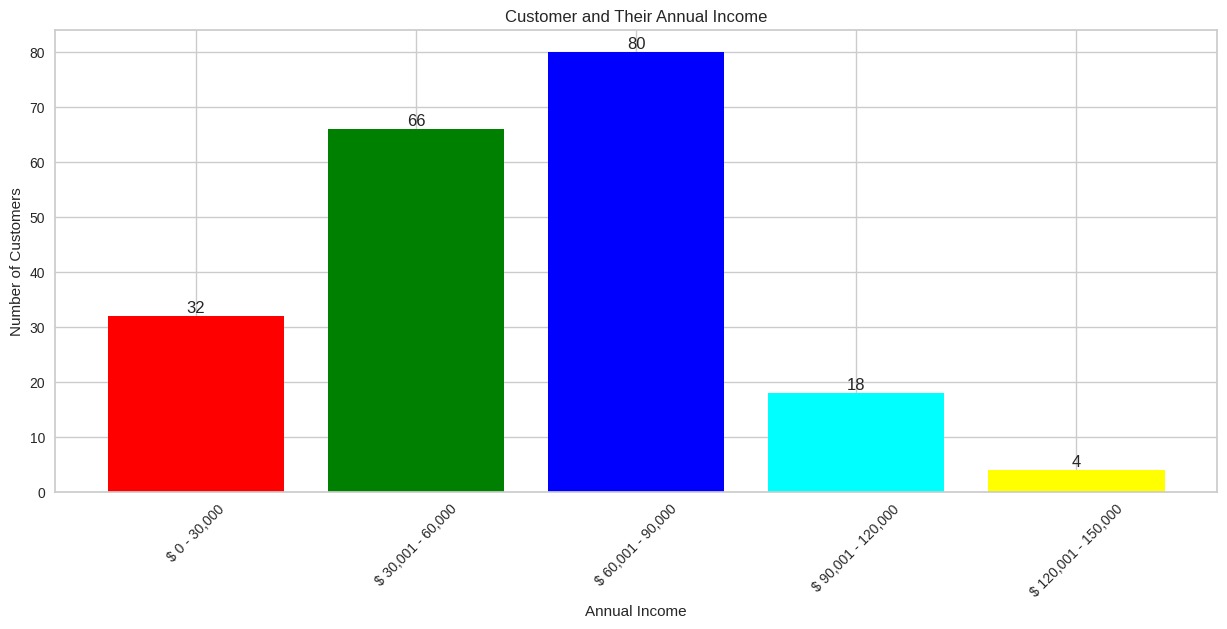
Hasil visualisasi menunjukkan distribusi pendapatan tahunan pelanggan sebagai berikut.
- $0–30,000: ada 32 pelanggan dalam rentang pendapatan ini.
- $30,001–60,000: kategori ini memiliki jumlah pelanggan terbanyak, yaitu 66.
- $60,001–90,000: ada 80 pelanggan dalam rentang pendapatan ini dan menjadikannya kategori dengan jumlah pelanggan terbesar.
- $90,001–120,000: rentang ini memiliki 18 pelanggan.
- $120,001–150,000: kategori ini mencakup 4 pelanggan yang merupakan jumlah paling sedikit di antara semua kategori.
Bar chart ini menunjukkan bahwa pelanggan paling banyak berada dalam rentang pendapatan $60,001–90,000, sedangkan kategori pendapatan tertinggi $120,001–150,000 memiliki jumlah pelanggan yang paling sedikit. Grafik ini memberikan wawasan tentang distribusi pendapatan pelanggan dan dapat membantu dalam merencanakan strategi pemasaran yang lebih efektif.
Data Splitting
Selanjutnya, kita mengambil dua kolom penting dari dataset: Annual Income (k$) dan Spending Score (1-100). Data dari kedua kolom ini disimpan dalam array X untuk analisis lebih lanjut. Setelah itu, kita menampilkan data yang diambil dalam format DataFrame dengan nama kolom yang sesuai, yaitu Annual Income (k$) dan Spending Score (1-100). Ini memungkinkan kita untuk melihat serta memeriksa nilai-nilai pendapatan tahunan dan skor pengeluaran pelanggan dengan cara yang lebih terstruktur serta mudah dibaca.
- # Mengambil kolom 'Annual Income (k$)' dan 'Spending Score (1-100)' dari dataset dan menyimpannya dalam array X
- X = df.iloc[:, [3, 4]].values
- # Menampilkan data yang diambil dalam format DataFrame dengan nama kolom yang sesuai
- print(pd.DataFrame(X, columns=['Annual Income (k$)', 'Spending Score (1-100)']))
Berikut adalah hasil variabel X yang terdiri dari 2 kolom, yaitu Annual Income (k$) dan Spending Score (1-100).
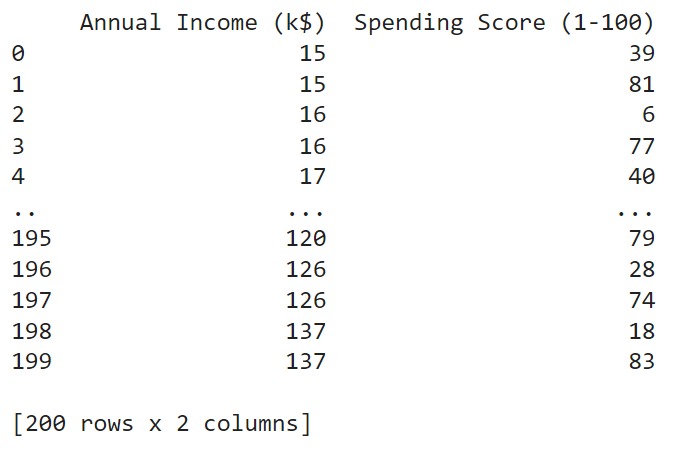
Dengan data yang telah disiapkan, kita sekarang siap untuk memasuki tahapan pembangunan model clustering. Pada tahap ini, kita akan menggunakan teknik clustering untuk mengelompokkan pelanggan berdasarkan pendapatan tahunan dan skor pengeluaran mereka. Mari kita lanjutkan ke proses selanjutnya untuk membangun dan menganalisis model clustering.
Elbow Method
Sebelum melanjutkan ke pembangunan model clustering, kita perlu menentukan jumlah cluster yang optimal untuk data kita. Untuk itu, kita akan menggunakan metode elbow method. Metode ini berfungsi seperti "cenayang" yang membantu kita memilih jumlah cluster terbaik dengan melihat perubahan total within-cluster sum of squares (WCSS) saat jumlah cluster bertambah.
Dengan menggunakan elbow method, kita akan menggambar grafik WCSS terhadap jumlah cluster dan mencari "siku" pada grafik tersebut. Titik letak penurunan WCSS mulai melambat, atau sikunya, biasanya menunjukkan jumlah cluster yang optimal. Ini membantu kita menghindari overfitting dengan memilih jumlah cluster yang sesuai dengan struktur data.
- # Inisialisasi model KMeans tanpa parameter awal
- kmeans = KMeans()
- # Inisialisasi visualizer KElbow untuk menentukan jumlah cluster optimal
- visualizer = KElbowVisualizer(kmeans, k=(1, 10))
- # Fit visualizer dengan data untuk menemukan jumlah cluster optimal
- visualizer.fit(X)
- # Menampilkan grafik elbow untuk analisis
- visualizer.show()
Untuk menentukan jumlah cluster yang optimal, kita menggunakan metode elbow dengan model KMeans. Pertama, kita menginisialisasi model KMeans tanpa menetapkan jumlah cluster awal. Selanjutnya, kita menggunakan KElbowVisualizer untuk mengevaluasi berbagai jumlah cluster dari 1 hingga 10.
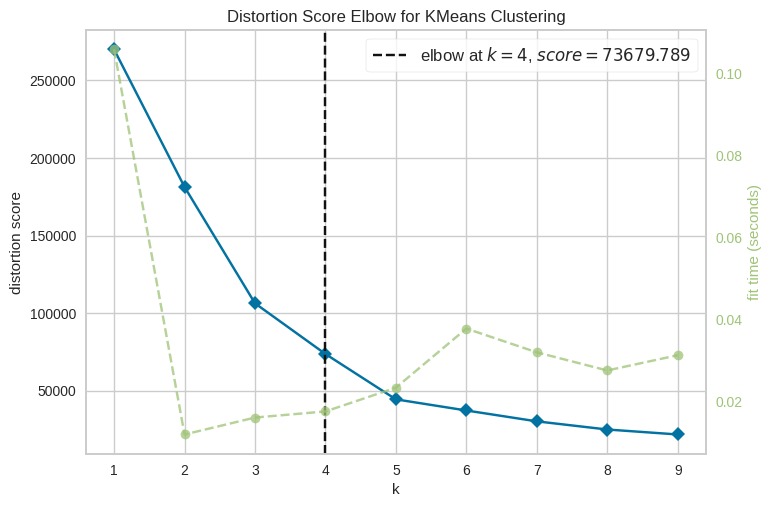
Hasil analisis metode elbow menunjukkan bahwa jumlah cluster optimal adalah 4 dengan nilai total within-cluster sum of squares (WCSS) sebesar 73,679.789. Ini berarti bahwa membagi data menjadi 4 cluster memberikan keseimbangan terbaik antara meminimalkan jarak di dalam cluster dan memaksimalkan jarak antar cluster.
Cluster Modeling (K-Means Clustering)
Great! Dengan jumlah cluster yang sudah ditentukan sebanyak 4, kita dapat melanjutkan dengan membangun model clustering menggunakan KMeans.
Dalam kode ini, kita melakukan analisis karakteristik cluster setelah melatih model KMeans dengan jumlah cluster yang telah ditetapkan, yaitu 4. Pertama, kita menginisialisasi model KMeans dengan parameter n_clusters=4 dan random_state=0 untuk memastikan hasil yang konsisten. Setelah melatih model dengan data X, kita memperoleh label cluster untuk setiap titik data.
Fungsi analyze_clusters kemudian digunakan untuk menganalisis karakteristik dari setiap cluster. Fungsi ini mengambil data dari masing-masing cluster berdasarkan label yang diberikan oleh model. Untuk setiap cluster, fungsi ini menghitung rata-rata dari dua fitur: pendapatan tahunan (Annual Income) dan skor belanja (Spending Score). Hasil analisis dicetak untuk setiap cluster menunjukkan rata-rata pendapatan tahunan dan skor belanja yang memberikan wawasan tentang profil pelanggan dalam setiap cluster.
- from sklearn.cluster import KMeans
- # Inisialisasi dan melatih model KMeans dengan jumlah cluster = 4
- kmeans = KMeans(n_clusters=4, random_state=0)
- kmeans.fit(X)
- # Mendapatkan label cluster
- labels = kmeans.labels_
- # Mendapatkan jumlah cluster
- k = 4
- # Fungsi untuk analisis karakteristik cluster
- def analyze_clusters(X, labels, k):
- print("Analisis Karakteristik Setiap Cluster:")
- for cluster_id in range(k):
- # Mengambil data untuk cluster saat ini
- cluster_data = X[labels == cluster_id]
- # Menghitung rata-rata untuk setiap fitur dalam cluster
- mean_income = cluster_data[:, 0].mean() # Rata-rata Annual Income
- mean_spending = cluster_data[:, 1].mean() # Rata-rata Spending Score
- print(f"\nCluster {cluster_id + 1}:")
- print(f"Rata-rata Annual Income (k$): {mean_income:.2f}")
- print(f"Rata-rata Spending Score (1-100): {mean_spending:.2f}")
- # Analisis karakteristik setiap cluster
- analyze_clusters(X, labels, k)
Dalam kode ini, kita melakukan visualisasi hasil clustering yang telah dilakukan dengan model KMeans serta menampilkan posisi centroid dari setiap cluster. Pertama, kita menentukan posisi centroid dengan menggunakan atribut cluster_centers_ dari model KMeans.
Visualisasi dimulai dengan plot scatter untuk menampilkan data pelanggan yang telah dikelompokkan ke dalam cluster dengan warna berbeda pada setiap cluster berdasarkan pemberian label. Centroid dari setiap cluster digambarkan dengan marker 'X' berwarna merah dan ukuran yang lebih besar. Label ditambahkan pada setiap centroid untuk menandai posisinya.
Selain itu, kita menambahkan judul serta label pada sumbu X dan Y untuk memberikan konteks pada plot yang menunjukkan distribusi pendapatan tahunan serta skor belanja pelanggan dalam setiap cluster. Setelah visualisasi, nilai centroid untuk setiap cluster ditampilkan. Ini menunjukkan pendapatan tahunan dan skor belanja rata-rata yang mewakili pusat dari masing-masing cluster.
- import matplotlib.pyplot as plt
- # Menentukan posisi centroid
- centroids = kmeans.cluster_centers_
- # Visualisasi cluster
- plt.figure(figsize=(12, 8))
- # Plot data
- plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', s=50, alpha=0.6, edgecolors='w', marker='o')
- # Plot centroid
- plt.scatter(centroids[:, 0], centroids[:, 1], c='red', s=200, marker='X', label='Centroids')
- # Menambahkan label centroid pada plot
- for i, centroid in enumerate(centroids):
- plt.text(centroid[0], centroid[1], f'Centroid {i+1}', color='red', fontsize=12, ha='center', va='center')
- # Menambahkan judul dan label
- plt.title('Visualisasi Cluster dengan Centroid')
- plt.xlabel('Annual Income (k$)')
- plt.ylabel('Spending Score (1-100)')
- plt.legend()
- plt.show()
- # Menampilkan nilai centroid
- print("Nilai Centroids:")
- for i, centroid in enumerate(centroids):
- print(f"Centroid {i+1}: Annual Income = {centroid[0]:.2f}, Spending Score = {centroid[1]:.2f}")
Berikut adalah visualisasi penyebaran cluster yang kita dapatkan.
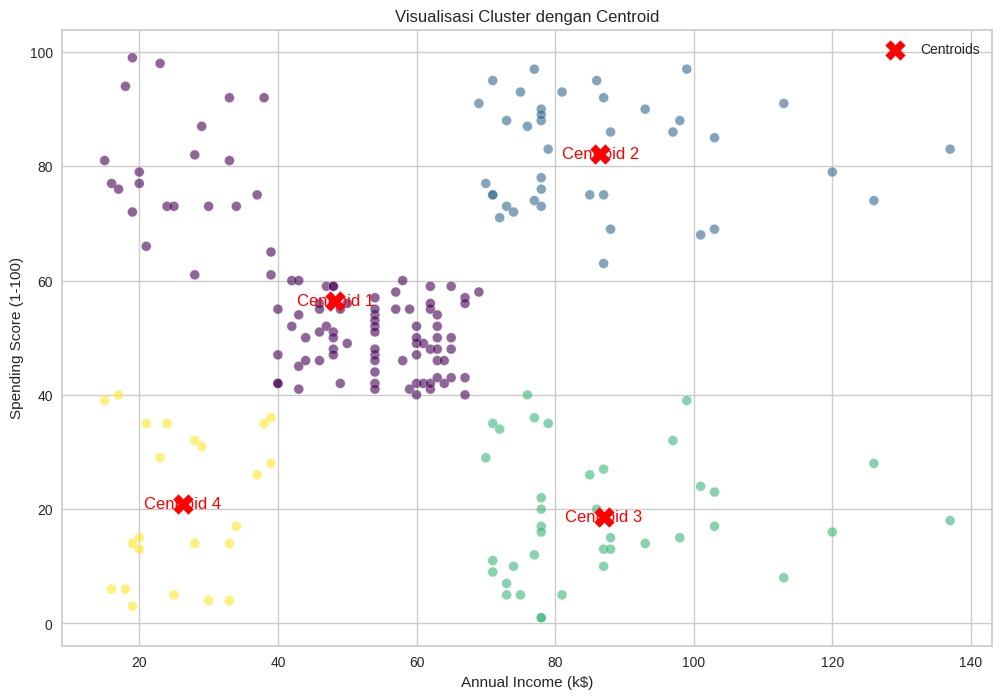
Nilai centroid untuk setiap cluster sebagai berikut.
- Centroid 1: pendapatan tahunan $48,260 serta skor belanja 56.48 menunjukkan pelanggan dengan pendapatan menengah dan belanja tinggi.
- Centroid 2: pendapatan tahunan $86,540 serta skor belanja 82.13 menggambarkan pelanggan dengan pendapatan tinggi dan belanja intensif.
- Centroid 3: pendapatan tahunan $87,000 serta skor belanja 18.63 menunjukkan pelanggan berpendapatan tinggi dan berbelanja sedikit.
- Centroid 4: pendapatan tahunan $26,300 serta skor belanja 20.91 menunjukkan pelanggan dengan pendapatan dan belanja rendah.
Ini memberikan gambaran tentang karakteristik pusat dari masing-masing cluster pelanggan dan membantu dalam merancang strategi pemasaran yang lebih efektif.
Nah, lalu, bagaimana ringkasan karakteristik masing-masing cluster sehingga kita dapat memahami kondisi setiap kelompok pelanggan?
Rangkuman Unsupervised Learning - Clustering
Konsep Dasar dan Proses Clustering
Clustering adalah teknik unsupervised learning untuk mengelompokkan data ke dalam grup berdasarkan kesamaan fitur tanpa memerlukan label. Proses ini bermanfaat untuk menemukan pola atau struktur tersembunyi dalam data.
Tahapan dalam Proses Clustering
- Pengumpulan Data: data relevan dikumpulkan untuk dianalisis, misalnya data pelanggan, seperti usia, pendapatan, dan riwayat pembelian.
- Pemilihan Fitur: fitur penting dipilih berdasarkan relevansi dengan tujuan analisis, misalnya usia dan pendapatan.
- Pra-pemrosesan Data: data dibersihkan, dihapus duplikasinya, dan dinormalisasi agar setiap fitur memiliki skala yang sama.
- Pemilihan Metode Pengukuran Jarak: digunakan metode seperti jarak Euclidean untuk mengukur kesamaan antara objek data.
- Pemilihan Algoritma Clustering: algoritma seperti K-Means, DBSCAN, atau hierarchical clustering dipilih berdasarkan kebutuhan analisis.
- Penerapan Algoritma Clustering: algoritma diterapkan untuk membagi data ke dalam cluster berdasarkan kemiripan fitur.
- Evaluasi Hasil Clustering: metrik seperti silhouette score digunakan untuk menilai kualitas cluster.
- Interpretasi dan Tindakan: hasil clustering dianalisis untuk menemukan pola dan diambil tindakan, seperti perancangan strategi pemasaran berdasarkan segmentasi pelanggan.
Hierarchical Clustering (HC)
HC adalah teknik clustering yang membentuk struktur hierarki antara cluster. Ada dua pendekatan dalam HC:
- Agglomerative (bottom-up): setiap objek dimulai sebagai cluster terpisah dan digabungkan hingga menjadi satu cluster besar.
- Divisive (top-down): dimulai dengan satu cluster besar yang dibagi menjadi cluster lebih kecil.
Hierarchical clustering digambarkan dalam dendrogram untuk menunjukkan proses penggabungan atau pemecahan cluster.
Non-hierarchical Clustering (NHC)
Non-hierarchical Clustering (NHC) adalah metode clustering yang membagi data menjadi cluster tanpa membentuk struktur hierarkis. Ini berbeda dari hierarchical clustering, yang membangun struktur pohon (dendrogram) untuk menggambarkan hubungan antar cluster. NHC berfokus pada pembentukan cluster terpisah berdasarkan kriteria tertentu, seperti jarak atau kepadatan, tanpa memperhatikan hubungan hierarkis.
Metode Non-hierarchical Clustering
Berikut adalah beberapa metode NHC yang sering digunakan:
K-Means Clustering
K-Means Clustering adalah metode yang membagi data menjadi k cluster berdasarkan jarak terdekat dari centroid (titik pusat cluster). Ini adalah salah satu metode yang paling umum digunakan karena kesederhanaannya dan efisiensinya.
Cara Kerja
- Inisialisasi: Pilih jumlah cluster kkk dan inisialisasi centroid secara acak atau menggunakan metode seperti K-Means++.
- Penugasan Cluster: Alokasikan setiap titik data ke centroid terdekat berdasarkan jarak Euclidean.
- Pembaruan Centroid: Hitung ulang centroid sebagai rata-rata titik data dalam cluster.
- Iterasi: Ulangi langkah penugasan dan pembaruan hingga centroid stabil atau konvergen.
Kelebihan
- Simplicity: mudah diimplementasikan dan dipahami.
- Efisiensi: cepat dalam komputasi, terutama untuk dataset besar.
Kekurangan
- Pemilihan Jumlah Cluster: membutuhkan penentuan jumlah cluster kkk sebelumnya.
- Sensitivitas terhadap Outliers: dapat terpengaruh oleh outliers yang memengaruhi posisi centroid.
K-Medoids Clustering
K-Medoids Clustering adalah varian dari K-Means yang menggunakan titik data nyata sebagai pusat cluster (medoids), bukan rata-rata. Ini membuatnya lebih robust terhadap noise dan outliers.
Cara Kerja
- Inisialisasi: Tentukan jumlah cluster kkk dan pilih medoids secara acak.
- Penugasan Cluster: Alokasikan setiap titik data ke medoid terdekat.
- Pemilihan Medoid Baru: Pilih medoid baru untuk meminimalkan total jarak dalam cluster.
- Iterasi: Ulangi langkah penugasan dan pemilihan medoid hingga tidak ada perubahan signifikan.
Kelebihan
- Robust terhadap Outliers: lebih tahan terhadap outliers.
- Kualitas Cluster: medoids memberikan pusat yang lebih representatif.
Kekurangan
- Kompleksitas: proses pemilihan medoid lebih rumit dan lambat dibandingkan K-Means.
- Pemilihan Jumlah Cluster: masih memerlukan penentuan jumlah cluster kkk sebelumnya.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
DBSCAN adalah metode clustering berbasis kepadatan yang mengidentifikasi cluster berdasarkan kepadatan titik. Ini tidak memerlukan jumlah cluster yang ditentukan sebelumnya dan dapat menemukan cluster dengan bentuk arbitrer.
Cara Kerja
- Penentuan Parameter: Tentukan parameter jarak maksimum (ε) dan jumlah minimum titik (MinPts).
- Pengelompokan: Identifikasi titik-titik yang cukup dekat satu sama lain untuk membentuk cluster. Titik yang tidak memenuhi kriteria dianggap sebagai noise.
- Ekspansi Cluster: Tambahkan titik tetangga yang memenuhi kriteria kepadatan.
Kelebihan
- Tidak Memerlukan Jumlah Cluster: tidak perlu menentukan jumlah cluster sebelumnya.
- Menangani Noise: dapat mengidentifikasi noise dan cluster dengan bentuk arbitrer.
Kekurangan
- Pemilihan Parameter: memerlukan pemilihan parameter yang tepat (ε dan MinPts).
- Skalabilitas: kurang efisien pada dataset yang sangat besar.
Mean Shift Clustering
Mean Shift Clustering adalah metode berbasis kepadatan yang mencari titik-titik yang berkumpul di sekitar jendela pencarian (kernel) tanpa memerlukan jumlah cluster awal.
Cara Kerja
- Inisialisasi: Tentukan ukuran jendela pencarian atau kernel.
- Pindah Titik: Hitung rata-rata posisi titik di sekitar jendela dan geser titik ke posisi rata-rata tersebut.
- Konsolidasi: Titik-titik yang berpindah ke posisi yang sama dikelompokkan bersama untuk membentuk cluster.
Kelebihan
- Tidak Memerlukan Jumlah Cluster: tidak perlu menentukan jumlah cluster sebelumnya.
- Menangani Bentuk Arbitrer: efektif dalam menemukan cluster dengan bentuk arbitrer.
Kekurangan
- Pemilihan Ukuran Jendela: ukuran jendela pencarian dapat memengaruhi hasil clustering.
- Kompleksitas: memerlukan waktu komputasi lebih lama pada dataset besar.
- Get link
- X
- Other Apps



Comments
Post a Comment